Материалы по тегу: hbm
|
30.06.2026 [23:10], Владимир Мироненко
Южная Корея инвестирует почти $3 трлн в полупроводники и ИИЮжная Корея анонсировала масштабный инвестиционный план с целью ускорения технологического развития страны, включающий три мегапроекта, которые направлены на укрепление цепочек поставок полупроводников, создание инфраструктуры ИИ и развитие индустрии физического ИИ. Об этом сообщил президент Ли Чжэ Мён (Lee Jae Myung) в ходе брифинга с участием глав Samsung Electronics и SK hynix, а также ряда других компаний. «Мы должны создать основные строительные блоки ИИ быстрее, чем любая другая страна, — сказал Ли. — Полупроводники, физический ИИ и ИИ ЦОД — это три столпа нашего следующего большого шага вперёд». Он подчеркнул, что синергия между полупроводниками, ЦОД и физическим ИИ позволит Южной Корее стать мировым лидером в революции ИИ. «Когда эти три столпа будут работать вместе, как взаимосвязанные шестерни, Корея станет ведущей мировой промышленной державой в эпоху ИИ», — сообщил президент. Согласовывая расширение производства полупроводников с ростом мощностей ИИ ЦОД и развитием физического ИИ, Южная Корея стремится создать вертикально интегрированную экосистему ИИ. Национальные цели включают удвоение производства DRAM в течение пяти лет и расширение вычислительных мощностей для ИИ примерно до 18,4 ГВт к 2035 году. Президент назвал программу «стратегией выживания нации» в эпоху ИИ, с корпоративными инвестиционными обязательствами на общую сумму более ₩3,755 квадрлн (приблизительно $2,74 трлн) в течение следующих десятилетий в области инфраструктуры ИИ, производства полупроводников и передовых технологий. Ли Чжэ Мён отметил, что что существующие производственные мощности по выпуску чипов в Йонгине (Yongin) и Пхёнтхэке (Pyeongtaek), центре южнокорейского «полупроводникового пояса» к югу от Сеула, «уже достигли своего предела», и призвал компании ускорить инвестиции в создание производственных мощностей на юго-западе страны. 
Источник изображения: Daniel Bernard / Unsplash Сообщается, что Samsung Electronics и SK hynix инвестируют в общей сложности ₩800 трлн ($518 млрд) в строительство четырёх заводов по производству микросхем памяти в юго-западном регионе страны Хонам (Honam), при этом каждая компания построит по два завода. Ещё ₩81 трлн ($52 млрд) будет направлено на создание крупномасштабного комплекса по упаковке HBM в центральном регионе страны. Председатель правления Samsung Ли Чжэ Ён (Lee Jae-yong) заявил, что город Кванджу (Gwangju) является вероятным местом для новых заводов Samsung, в то время как производственные мощности HBM будут сосредоточены в Чхонане (Cheonan) и Оньяне (Onyang) в регионе Чхунчхон (Chungcheong). Кроме того, до 2035 года корейские технологические и энергетические гиганты, такие как SK, GS и Naver, планируют выделить еще ₩550 трлн ($356 млрд) на строительство ИИ ЦОД общей мощностью 8,4 ГВт в Ульсане (Ulsan), Донхэ (Donghae), Седжоне (Sejong) и других регионах. В понедельник Samsung также опубликовала пресс-релиз, в котором объявила о планах инвестировать ₩2,655 квадрлн (около $1,7 трлн) в технологические проекты в стране в течение следующего десятилетия. Из этой суммы ₩2,03 квадрлн (около $1,48 трлн) предполагается направить в развитие кластеров полупроводниковой промышленности, включая кампус в Пхёнтхэке (Pyeongtaek Campus) и Национальный промышленный комплекс в Йонгине (Yongin National Industrial Complex), а ₩625 трлн ($0,22 трлн) — на развитие регионов Хонам, Чхунчхон и Йонгнам (Yeongnam), сосредоточив усилия на полупроводниках для ИИ, робототехнике, батареях, а также компонентах и материалах для IT-индустрии. Samsung назвала предлагаемые правительством льготы в сфере электроснабжения, водоснабжения, рабочей силы и условий жизни ключевыми факторами при выборе Кванджу, расположенного примерно в 300 км к югу от Сеула, для размещения нового завода по производству полупроводников, а также ИИ ЦОД в Хэнаме (Haenam), на южной оконечности полуострова. Не все уверены в том, что юго-западный регион сможет обеспечить производство микросхем мирового класса, пишет The Wall Street Journal. Эксперты указывают на удалённость региона от существующих сетей поставок полупроводников и на трудности с привлечением квалифицированных кадров из столицы. В свою очередь, SK Group, как пишет TechCrunch, объявила о среднесрочной и долгосрочной инвестиционной стратегии на сумму ₩2,1 квадрлн (около $1,4 трлн), из которых ₩1100 трлн пойдут на расширение мощностей по производству полупроводников и ₩1 квадрлн ($0,65 трлн) — на создание ИИ ЦОД по всей стране. SK hynix займётся расширением производства чипов, а SK Telecom — строительством ИИ ЦОД на 15 ГВт.
25.06.2026 [16:11], Владимир Мироненко
Qualcomm анонсировала HBC — альтернативу HBM на базе LPDDRQualcomm анонсировала High Bandwidth Compute (HBC), гибридное решение для вычислений и памяти, разработанное в качестве альтернативы памяти HBM и обеспечения большей производительности, эффективности и пропускной способности. В нём используется трёхмерная архитектура Near-Memory Computing (NMC), обеспечивающая предельно близкое расположение быстрой памяти к вычислительным ядра. В HBC используется память LPDDR, размещённая вертикально в несколько слоёв, соединённых сквозными кремниевыми контактами (TSV). Такой подход обеспечивает лучшую энергоэффективность, чем традиционная HBM, в которой в вертикальных слоях размещается память DDR, поскольку микросхемы LPDDR потребляют меньше энергии, обеспечивая при этом аналогичную пропускную способность и ёмкость. При этом в основании HBC лежит вычислительный кристалл, который берёт на себя часть обработки данных основного процессора, тем самым разгружая его. Как отметил ресурс Techpowerup, эта технология аналогична используемой в памяти HBM4, где базовый кристалл представляет собой логический кристалл для лучшей интеграции вычислительных решений, таких как трассировка пакетов и подготовка данных для ввода и вывода из HBM. 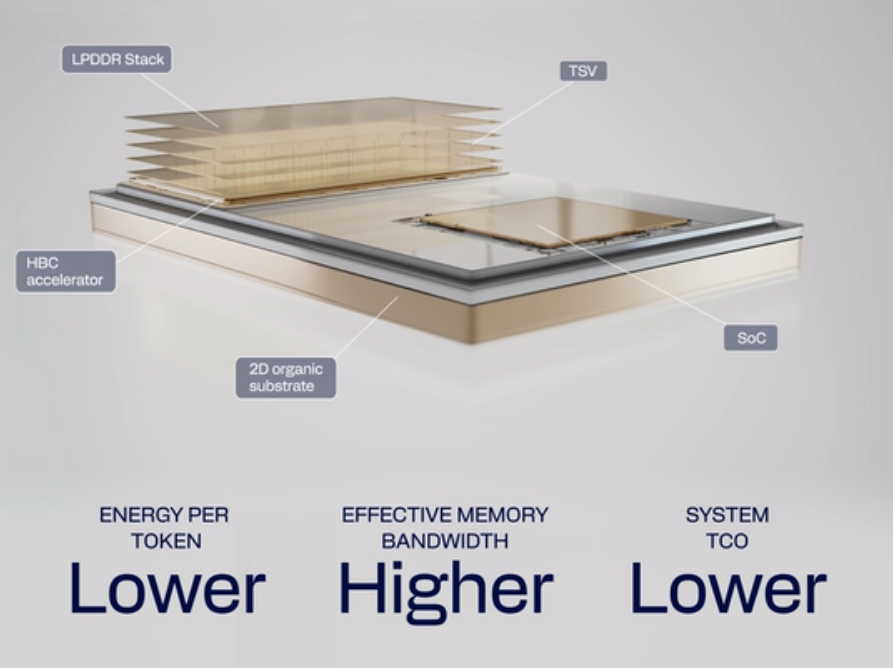
Источник изображений: Qualcomm Qualcomm сообщила, что HBC обеспечивает шестикратное увеличение пропускной способности на Вт по сравнению с HBM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне платы, а также 200-кратное увеличение ёмкости на Вт по сравнению с SRAM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне стойки.  HBC первого поколения (HBC Gen 1) достигла пропускной способности 133 Тбайт/с на ускорителе AI250, что в 18 раз больше, чем у AI200 на базе LPDDR5X. Коммерческое тестирование HBC1 с AI250 ожидается в середине 2027 года. Компания планирует выпуск решения HBC Gen 2 в 2028 году. Это решение выйдет с ИИ-ускорителем Qualcomm Dragonfly AI300 и обеспечит 54-кратное увеличение эффективной пропускной способности по сравнению с AI200 и семикратное увеличения пропускной способности на Вт по сравнению с HBM.  Dragonfly AI300 интегрирует HBC2, обеспечив высокую пропускную способность и низкую задержку для инференса больших языковых и мультимодальных моделей (LLM, LMM) и агентного ИИ. По данным Qualcomm, ожидается в 4–8 раз более высокая производительность по сравнению с существующими архитектурами на базе GPU по пропускной способности памяти на Вт на карту. Масштабирование решения будет осуществляться с помощью интерконнектов UALink и ESUN с использованием медных и оптических кабелей. Коммерческое производство образцов Dragonfly AI300 начнётся в 2028 году.
03.05.2026 [23:30], Владимир Мироненко
Поборы Broadcom вынудили Google обратиться к MediaTek для создания ИИ-ускорителей TPUСогласно свежему отчёту Foundry Quarterly and Monthly Intelligence от Counterpoint Research, благодаря сотрудничеству с Google доля компании MediaTek на рынке ИИ-серверов на базе кастомных ускорителей (ASIC) может вырасти к 2028 году до 26 %. В результате MediaTek может выйти на второе место, уступив лишь Broadcom. Google представила в апреле два TPU восьмого поколения: TPU 8t (Sunfish) для обучения ИИ и TPU 8i (Zebrafish) для ИИ-инференса. Как сообщается в отчёте Counterpoint Research, TPU v8t занимает ключевое место в стратегии Google в области ИИ. «Мы рассматриваем это поколение как переломный момент с точки зрения цепочки поставок, поскольку оно знаменует собой первый важный шаг в диверсификации Google от простой модели ASIC Broadcom “под ключ”», — отметили в Counterpoint Research. Что касается основной причины соглашения Google с MediaTek, в рамках которого Google разрабатывает вычислительный кристалл, а MediaTek предоставляет кристалл I/O, то Counterpoint Research объясняет это экономикой закупок HBM. В рамках модели поставок «под ключ» Broadcom сама занимается поиском поставщиков HBM, прибавляя к стоимости памяти ещё 15–20 %. С учётом того, что на HBM приходится всё более значительная доля в себестоимости ASIC, такая наценка становится всё более обременительной для Google, которая к тому же наращивает темпы развёртывания TPU в ЦОД. Взяв на себя разработку чипов и закупку HBM, начиная с TPU 8t, Google устраняет поборы посредников и снижает себестоимость своих чипов. 
Источник изображения: Google Объём производства MediaTek значительно возрастёт после того, как начнётся выпуск TPU 8t в конце 2026 года и его преемника TPU v8e (Humufish) в период до 2028 года. Исходя из последнего прогноза глобальных поставок ASIC для ИИ-вычислений, аналитики ожидают, что совокупные поставки TPU v8t и v8e приблизятся к 5 млн единиц в 2028 году, что более чем в 10 раз больше по сравнению с отгрузкой примерно 400 тыс. чипов в 2026 году. Это станет возможным благодаря ускоренному внедрению TPU Google как для внутренних рабочих нагрузок, так и для облачных клиентов. Комментируя прогноз, Counterpoint Research уточняет, что он не учитывает реализацию проекта Meta✴ MTIA. Кроме того, достижение прогнозируемого объёма зависит от наличия достаточных мощностей по упаковке TSMC CoWoS и Intel EMIB-T. Основной риск для реализации прогноза связан с TPU v8e, для которого MediaTek предлагает упаковку Intel EMIB-T: «В настоящее время компания находится на стадии проектирования и квалификации, а массовое производство запланировано не ранее конца 2027 года, и этот переход сопряжён с весьма специфическими рисками для исполнения». К числу ключевых факторов отнесены необходимое для этого увеличение производительности Intel Foundry Services (IFS) и готовность поставщиков подложек, что в конечном итоге может повлиять на объём поставок MediaTek.
17.02.2026 [11:08], Сергей Карасёв
SK hynix предлагает гибридную память HBM/HBF для ускорения ИИ-инференсаКомпания SK hynix, по сообщению ресурса Blocks & Files, разработала концепцию гибридной памяти, объединяющей на одном интерпозере HBM (High Bandwidth Memory) и флеш-чипы с высокой пропускной способностью HBF (High Bandwidth Flash). Предполагается, что такое решение будет подключаться к GPU для повышения скорости ИИ-инференса. Современные ИИ-ускорители на основе GPU оснащаются высокопроизводительной памятью HBM. Однако существуют ограничения по её ёмкости, из-за чего операции инференса замедляются, поскольку доступ к данным приходится осуществлять с использованием более медленных SSD. Решить проблему SK hynix предлагает путём применения гибридной конструкции HBM/HBF под названием H3. Архитектура HBF предусматривает монтаж кристаллов NAND друг над другом поверх логического кристалла. Вся эта связка располагается на интерпозере рядом с контроллером памяти, а также GPU, CPU, TPU или SoC — в зависимости от предназначения конечного изделия. В случае H3 на интерпозере будет дополнительно размещён стек HBM. Отмечается, что время доступа к HBF больше, чем к HBM, но вместе с тем значительно меньше, нежели к традиционным SSD. Таким образом, HBF может служить в качестве быстрого кеша большого объёма. 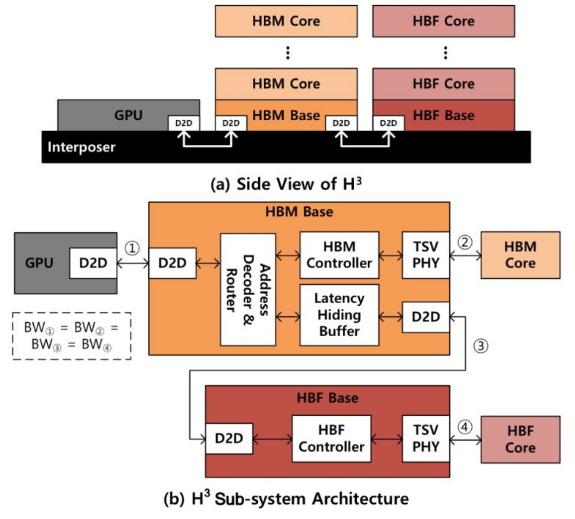
Источник изображения: SK hynix По заявлениям SK hynix, стеки HBF могут иметь до 16 раз более высокую ёмкость по сравнению с HBM, обеспечивая при этом сопоставимую пропускную способность. С другой стороны, HBF обладает меньшей износостойкостью при записи, до 4 раз более высоким энергопотреблением и большим временем доступа. HBF выдерживает около 100 тыс. циклов записи, а поэтому лучше всего подходит для рабочих нагрузок с интенсивным чтением. В результате, как утверждается, гибридная конструкция сможет эффективно решать задачи инференса при использовании больших языковых моделей (LLM) с огромным количеством параметров. В ходе моделирования работы H3, проведенного специалистами SK hynix, рассматривался ускоритель NVIDIA Blackwell B200 с восемью стеками HBM3E и таким же количеством стеков HBF. В пересчете на токены в секунду производительность системы с памятью H3 оказалась в 1,25 раза выше при использовании 1 млн токенов и в 6,14 раза больше при использовании 10 млн токенов по сравнению с решениями, оборудованными только чипами HBM. Более того отмечено 2,69-кратное повышение производительности в расчёте на 1 Вт затрачиваемой энергии по сравнению с конфигурациями без HBF. К тому же связка HBM и HBF может обрабатывать в 18,8 раз больше одновременных запросов, чем только HBM.
29.12.2025 [14:09], Руслан Авдеев
Fujitsu поможет SoftBank в создании дешёвой и доступной альтернативы HBMКомпания Fujitsu присоединится к проекту, возглавляемому японской инвестиционной группе SoftBank. Партнёры намерены разрабатывать память нового поколения для ИИ и суперкомпьютеров, сообщает Nikkei Asian Review. Япония намерена восстановить компетенции, в своё время позволившие стране стать одним из лидеров в сфере производства модулей памяти. «Командным центром» для реализации государственно-частного проекта должна стать компания Saimemory, основанная SoftBank; участие, помимо Fujitsu, примут и другие партнёры. Saimemory рассчитывает разработать высокопроизводительную память, способную стать альтернативой HBM. Проект предусматривает инвестиции в ¥8 млрд ($51,2 млн) в 2027 финансовом году для завершения создания прототипа. Массовое производство должно начаться к 2029 финансовому году. Сама SoftBank к 2027 финансовому году выделит Saimemory ¥3 млрд, Fujitsu и японский научно-исследовательский институт Riken в совокупности вложат около ¥1 млрд. Часть расходов, как ожидается, должно компенсировать японское правительство посредством программ поддержки разработки полупроводников нового поколения. В своё время Fujitsu была ключевым игроком в некогда ведущей в мире японской полупроводниковой индустрии. Хотя она со временем отказалась от производства памяти, у неё накоплен богатый опыт в области массового производства модулей и контроля их качества. Сейчас компания продолжает заниматься разработкой энергоэффективных CPU и сохраняет прочные связи с клиентами. 
Источник изображения: Fujitsu Saimemory намерена наладить масовое производство памяти с ёмкостью вдвое или втрое больше, чем у HBM при энергопотреблении вдвое ниже, при этом цена будет сопоставимой или даже более привлекательной. Компания рассчитывает использовать полупроводниковые технологии, разработанные Intel и Токийским университетом, а Shinko Electric Industries и тайваньская Powerchip Semiconductor Manufacturing помогут с производством и созданием прототипов. Intel обеспечит базовую технологию вертикального штабелирования, разработанную при поддержке американского военного ведомства DARPA, которая позволит увеличить количество чипов памяти на единицу площади и сократить расстояние передачи данных. Также будут применяться технологии Токийского университета и других компаний для рассеивания тепла и упрощения передачи данных. Saimemory будет специализироваться на управлении интеллектуальной собственностью и разработке чипов, передавая заказы на производство сторонним компаниям. С распространением систем генеративного ИИ, требуемая вычислительная мощность в Японии, по некоторым оценкам, увеличится более чем в 300 раз между 2020 и 2030 гг. Тем не менее Япония, некогда бывшая одним из лидеров в производстве полупроводников, теперь сильно зависит от зарубежных компаний. В результате существуют риски перебоев с поставками и вероятность неконтролируемого роста цена на них. На южнокорейские компании приходится около 90 % доли выпуска HBM-памяти. По данным Nikkei, в своё время японский бизнес постепенно прекратил производство собственной памяти приблизительно в 2000 году. Появление и развитие ИИ-технологий может изменить положение. SoftBank движется к строительству собственных больших дата-центров, а Fujitsu уже выпускает CPU для ЦОД и инфраструктуру связи, практическое применение которым, вероятно, найдут уже в 2027 году.
04.11.2025 [16:35], Сергей Карасёв
SK hynix разрабатывает AI-D — память для устранения узких мест в ИИ-системахКомпания SK hynix, по сообщению ресурса Blocks & Files, проектирует память нового типа AI DRAM (AI-D) для высокопроизводительных ИИ-платформ. Изделия нового типа будут предлагаться в трёх модификациях — AI-D O (Optimization), AI-D B (Breakthrough) и AI-D E (Expansion), что, как ожидается, позволит устранить узкие места современных систем. SK hynix является одним из лидеров рынка памяти HBM (Hgh Bandwidth Memory) для ИИ-ускорителей. Однако достижения в данной сфере отстают от развития GPU, из-за чего возникает препятствие в виде «стены памяти»: наблюдается разрыв между объёмом и производительностью HBM и вычислительными возможностями ускорителей. Проще говоря, GPU простаивают в ожидании данных. Одним из способов решения проблемы является создание кастомизированных чипов HBM, предназначенных для удовлетворения конкретных потребностей клиентов. Вторым вариантом SK hynix считает выпуск специализированной памяти AI-D, спроектированной для различных ИИ-нагрузок. 
Источник изображений: SK hynix В частности, вариант AI-D O предполагает разработку энергосберегающей высокопроизводительной DRAM, которая позволит снизить общую стоимость владения ИИ-платформ. Для таких изделий предусмотрено применение технологий MRDIMM, SOCAMM2 и LPDDR5R. Продукты семейства AI-D B помогут решить проблему нехватки памяти. Такие изделия будут отличаться «сверхвысокой ёмкостью с возможностью гибкого распределения». Упомянуты технологии CMM (Compute eXpress Link Memory Module) и PIM (Processing-In-Memory). Это означает интеграцию вычислительных возможностей непосредственно в память, что позволит устранить узкие места в перемещении данных и повысить общее быстродействие ИИ-систем.  Ёмкость AI-D B составит до 2 Тбайт — в виде массива из 16 модулей SOCAMM2 на 128 Гбайт каждый. Причём память отдельных ускорителей сможет объединяться в общее адресное пространство объёмом до 16 Пбайт. Любой GPU сможет заимствовать свободную память из этого пула для расширения собственных возможностей по мере роста нагрузки. Наконец, архитектура AI-D E подразумевает использование памяти, включая HBM, за пределами дата-центров. SK hynix планирует применять DRAM в таких областях, как робототехника, мобильные устройства и платформы промышленной автоматизации.
15.09.2025 [11:44], Сергей Карасёв
SK hynix завершила разработку памяти HBM4 для ИИ-системКомпания SK hynix объявила о том, что она первой среди участников отрасли завершила разработку памяти с высокой пропускной способностью HBM4 для ИИ-систем. В настоящее время готовится организация массового производства таких изделий. HBM4 — это шестое поколение памяти данного типа после оригинальных решений HBM, а также HBM2, HBM2E, HBM3 и HBM3E. Ожидается, что чипы HBM4 будут применяться в продуктах следующего поколения AMD, Broadcom, NVIDIA и др. Стеки памяти HBM4 от SK hynix оснащены 2048-бит IO-интерфейсом: таким образом, разрядность интерфейса HBM удвоилась впервые с 2015 года. Заявленная скорость передачи данных превышает 10 Гбит/с, что на 25 % превосходит значение в 8 Гбит/с, определённое официальным стандартом JEDEC. Пропускная способность HBM4 увеличилась вдвое по сравнению с предыдущим поколением НВМ, тогда как энергоэффективность повысилась на 40 %. 
Источник изображения: SK hynix При изготовлении чипов HBM4 компания SK hynix будет применять 10-нм технологию пятого поколения (1bnm) и методику Advanced Mass Reflow Molded Underfill (MR-MUF). Последняя представляет собой способ объединения нескольких чипов памяти на одной подложке посредством спайки: сразу после этого пространство между слоями DRAM, базовым кристаллом и подложкой заполняется формовочным материалом для фиксации и защиты структуры. Технология Advanced MR-MUF позволяет выдерживать высоту HBM-стеков в пределах спецификации и улучшать теплоотвод энергоёмких модулей памяти. SK hynix не раскрывает ни количество слоёв DRAM в своих изделиях HBM4, ни их ёмкость. Как отмечает ресурс Tom's Hardware, по всей видимости, речь идёт об 12-Hi объёмом 36 Гбайт, которые будут использоваться в ускорителях NVIDIA Rubin. По заявлениям SK hynix, внедрение HBM4 позволит увеличить производительность ИИ-ускорителей на 69 % по сравнению с нынешними решениями. Это поможет устранить узкие места в обработке информации в ИИ ЦОД.
08.08.2025 [01:05], Владимир Мироненко
Sandisk и SK hynix разработают спецификации высокоскоростной флеш-памяти HBFSandisk объявила о подписании Меморандума о взаимопонимании (МОВ) с SK hynix, предусматривающего совместную разработку спецификации высокоскоростной флеш-памяти (HBF). В рамках сотрудничества компании планируют стандартизировать спецификацию, определить технологические требования и изучить возможность создания технологической экосистемы для высокоскоростной флеш-памяти. Технология HBF, анонсированная Sandisk в феврале этого года, обеспечит ускорители быстрым доступом к большим объёмам памяти NAND, что позволит ускорить обучение и инференс ИИ без длительных обращений к PCIe SSD. Как и HBM, чип HBF состоит из слоёв, в данном случае NAND, с TSV-каналами, соединяющими каждый слой с базовым интерпозером, что обеспечивает быстрый доступ к памяти — на порядки быстрее, чем в SSD. При сопоставимой с HBM пропускной способности и аналогичной цене HBF обеспечит в 8–16 раз большую, чем у HBM, ёмкость на стек. Вместе с тем HBF имеет более высокую задержку, чем DRAM, что ограничивает её применение определёнными рабочими нагрузками. На этой неделе Sandisk представила прототип памяти HBF, созданный с использованием фирменных технологий BiCS NAND и CBA (CMOS directly Bonded to Array). 
Источник изображения: Sandisk Меморандум о взаимопонимании подразумевает, что SK hynix может производить и поставлять собственные модули памяти HBF. Как отметил ресурс Blocks & Files, это подтверждает тот факт, что Sandisk осознаёт необходимость наличия рынка памяти HBF с несколькими поставщиками. Такой подход позволит гарантировать клиентам, что они не будут привязаны к одному поставщику. Также это обеспечит конкуренцию, которая ускорит разработку HBF. Sandisk планирует выпустить первые образцы памяти HBF во II половине 2026 года и ожидает, что образцы первых устройств с HBF для инференса появятся в продаже в начале 2027 года. Это могут быть как портативные устройства, так и ноутбуки, десктопы и серверы.
05.07.2025 [15:16], Алексей Разин
Повальный спрос на HBM тормозит внедрение CXL- и PIM-памятиОтраслевые аналитики уже не раз отмечали, что бурное развитие отрасли искусственного интеллекта, сопряжённое с ростом спроса на память типа HBM, ограничивает ресурсы производителей памяти на других направлениях. Помимо DDR, от этого страдают и перспективные виды памяти, которые производители хотели бы вывести на рынок. Об этом сообщило издание Business Korea, приведя в пример задержки с внедрением памяти типа CXL компанией Samsung Electronics и памяти типа PIM (Processing-in-Memory) компанией SK hynix. В последнем случае речь идёт о микросхемах памяти, способных самостоятельно выполнять специфические вычисления. Оба типа памяти могли бы в известной мере дополнить HBM в сегменте систем искусственного интеллекта. 
Источник изображения: SK hynix Samsung рассчитывала приступить к продвижению CXL-памяти ещё во II половине 2024 года, но её сертификация ключевыми клиентами до сих пор не завершена. SK hynix разрабатывает GDDR6-AiM с 2022 года, но до её фактического выпуска дело так и не дошло из-за неготовности рыночной экосистемы. Кроме того, сами производители памяти ограничены в свободных ресурсах, поскольку все силы бросили на выполнение заказов по производству HBM. Всё доступное оборудование задействовано для выпуска именно HBM, не давая производителям шанса заняться подготовкой к выпуску других перспективных типов памяти. 
Источник изображения: SK hynix На этом фоне у южнокорейских игроков рынка даже возникают опасения, что китайские конкуренты быстрее справятся с выводом на рынок модулей CXL и PIM. В этой ситуации корейские производители начали всё сильнее рассчитывать на поддержку государства, причём не столько финансовую, сколько регуляторную. С технической точки зрения к выводу на рынок CXL и PIM всё уже почти готово, но по факту на память этих типов пока нет достаточного спроса.
23.06.2025 [16:53], Владимир Мироненко
SK hynix выпустит кастомную HBM4E-память для NVIDIA, Microsoft и BroadcomСогласно данным The Korea Economic Daily, южнокорейская компания SK hynix заключила контракты на поставку кастомной памяти HBM с NVIDIA, Microsoft и Broadcom, опередив конкурента Samsung Electronics на рынке кастомной HBM, который, по прогнозам TrendForce и Bloomberg Intelligence к 2033 году вырастет до $130 млрд с $18,2 млрд в 2024 году. Ожидается, что поставки SK hynix кастомных чипов начнутся во второй половине 2025 года. По данным отраслевых источников, Samsung также ведёт переговоры с Broadcom и AMD о поставках кастомной HBM4. Ранее, в ходе квартального отчёта в апреле компания сообщила, что начнёт поставки памяти HBM4 в I половине 2026 года. Для наращивания производства HBM и передовой памяти DRAM компания SK hynix переоборудовала свой завод M15X в Чхонджу (Cheongju), изначально предназначенный для производства флеш-памяти NAND. Объём запланированных инвестиций составляет ₩20 трлн ($14,5 млрд). Кастомные HBM, предназначенные для удовлетворения конкретных потребностей клиентов, пользуются всё большим спросом, поскольку крупные технологические компании, стремясь оптимизировать производительность своих ИИ-решений, отказываются от использования универсальной памяти. О заключении контрактов стало известно примерно через 10 месяцев после того, как SK hynix объявила о получении запросов на поставку кастомной HBM от «Великолепной семёрки»: Apple, Microsoft, Google, Amazon, NVIDIA, Meta✴ и Tesla. 
Источник изображения: SK hynix По словам источника The KED в полупроводниковой отрасли, «учитывая производственные мощности SK hynix и сроки запуска ИИ-сервисов крупными технологическими компаниями, удовлетворить все запросы “Великолепной семёрки” не представляется возможным». Тем не мене, он допустил, что SK hynix с учётом условий рынка может заключить контракты ещё с несколькими клиентами. Ранее SK hynix сообщила, что с поколением HBM4E она полностью перейдет на модель индивидуального производства. Текущее массовое внедрение сосредоточено вокруг HBM3E, а отрасль готовится в ближайшем будущем к переходу на шестое поколение памяти HBM — HBM4. По словам источников, выпуск кастомной памяти седьмого поколения HBM4E компания освоит во II половине 2026 года, а массовое производство HBM4 начнёт во второй II 2025 года. Начиная с HBM4, логические кристаллы для памяти SK hynix выпускает TSMC, поскольку усовершенствованный чип требует более продвинутых техпроцессов. До этого компания обходилась собственными мощностями. По данным TrendForce, SK hynix контролирует половину мирового рынка HBM, за ней следуют Samsung и Micron с долями рынка в размере 30 % и 20 % соответственно. |
|

