Материалы по тегу: cpu
|
04.08.2022 [15:54], Владимир Мироненко
Разработчик серверных чипов Prodigy с невероятными характеристиками обвинил в своих бедах CadenceКак сообщает The Register, cтартап Tachyum подал в суд на Cadence Design Systems, обвинив компанию в саботаже при выполнении контракта на поставку IP-блоков для будущих 5-нм серверных процессоров Prodigy. По словам Tachyum, старшие 128-ядерные CPU Prodigy с частотой 5,7 ГГц будут втрое быстрее AMD EPYC 7763 и NVIDIA H100. В иске утверждается, что заключённая в 2019 году сделка на предоставление решений Cadence для процессоров Prodigy, была сорвана, поскольку Cadence не смогла предоставить необходимые технологии для вывода продукта на рынок. Заказанные Tachyum блоки не относятся к разряду новшеств, и инженеры Cadence уверяли Tachyum, что стандартные компоненты могли быть без труда интегрированы в процессор. Однако график поставок был нарушен, и дошло даже до того, что Cadence посоветовала Tachyum не использовать её компоненты или вообще приобрести аналоги у других поставщиков. 
Источник изображения: Tachyum Стартап добавил в иске, что Cadence усугубила ущерб, прекратив доступ Tachyum к ПО eDAcard, тем самым вынудив понести расходы на лицензирование другого ПО и переобучение своих инженеров. Срыв сроков и прочие препятствия привели к задержке выхода Prodigy примерно на два года. Tachyum потребовал возместить упущенную выгоду в размере $206 млн и ещё $27 млн дополнительных затрат на поиск альтернативных решений в сжатые сроки. 
Источник изображения: Tachyum Tachyum также указала, что из-за срыва сроков она потеряла возможность получения заказов на поставку чипов для испанского суперкомпьютера MareNostrum 5 стоимостью €151,41 млн. В итоге Барселонский суперкомпьютерный центр (BSC), с которым был подписан меморандум о взаимопонимании, предпочёл компанию Atos. Последняя выбрала ускорители NVIDIA и процессоры Intel, поскольку ни одна европейская компания не могла бы поставить чипы, отвечающие ключевым критериям отбора. В иске Tachyum отмечает, что тогдашний генеральный директор Cadence Лип-Бу Тан (Lip-Bu Tan) входил в совет директоров двух конкурентов Tachyum — SambaNova и Nuvia (поглощена Qualcomm) — и активно участвовал в фондах Walden International и Walden Catalyst, которые инвестировали в другие «кремниевые» стартапы. Ещё один член совета директоров Cadence, Янг Сон (Young Sohn), также является директором одного из этих инвестфондов. По мнению Tachyum, налицо явный конфликт интересов.
13.07.2022 [16:13], Алексей Степин
128-ядерный Arm-процессор Alibaba T-Head Yitian 710 показал отличные результаты в SPEC CPU2017Не секрет, что китайские гиганты, такие, как Huawei и Alibaba Cloud, разрабатывают собственные серверные процессоры на базе архитектуры Arm. Однако информации об этих чипах, как правило, не очень много и пользоваться общепринятыми на западе тестами и рейтингами разработчики не спешат, что, к слову, характерно и для китайских суперкомпьютеров. Alibaba Cloud представила чип Yitian 710 ещё осенью прошлого года. Этот процессор построен на базе архитектуры Armv9 и максимально может иметь 128 ядер с частотой до 3,2 ГГц. Однако результаты проверки чипа в популярном тесте SPEC CPU2017 были опубликованы только сейчас. 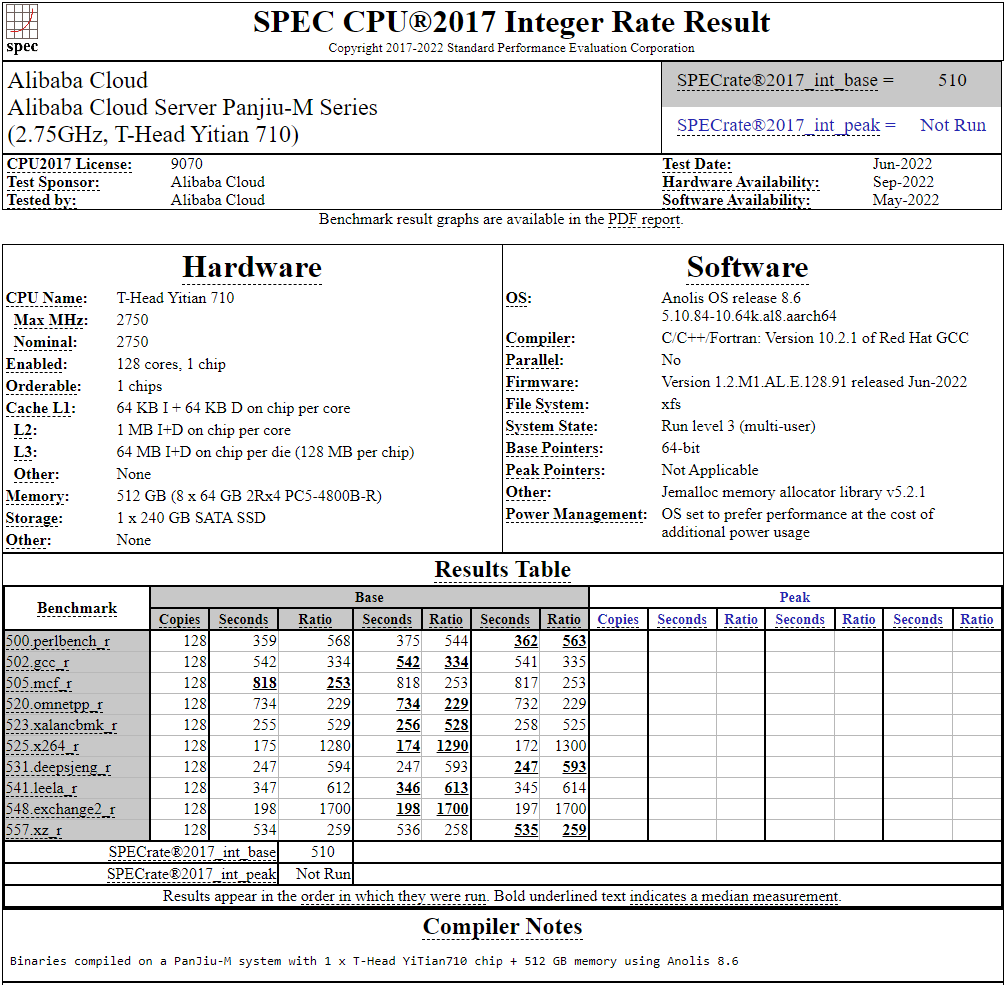 Процессор тестировался в составе референс-сервера Panjiu. Применялась 128-ядерная версия с частотой 2,75 ГГц, 1 Мбайт кеша L2 на ядро и 64 Мбайт кеша L3 на кристалл (128 Мбайт на сборку). Последнее позволяет говорить о том, что Alibaba также использует в своих процессорах чиплетную компоновку. 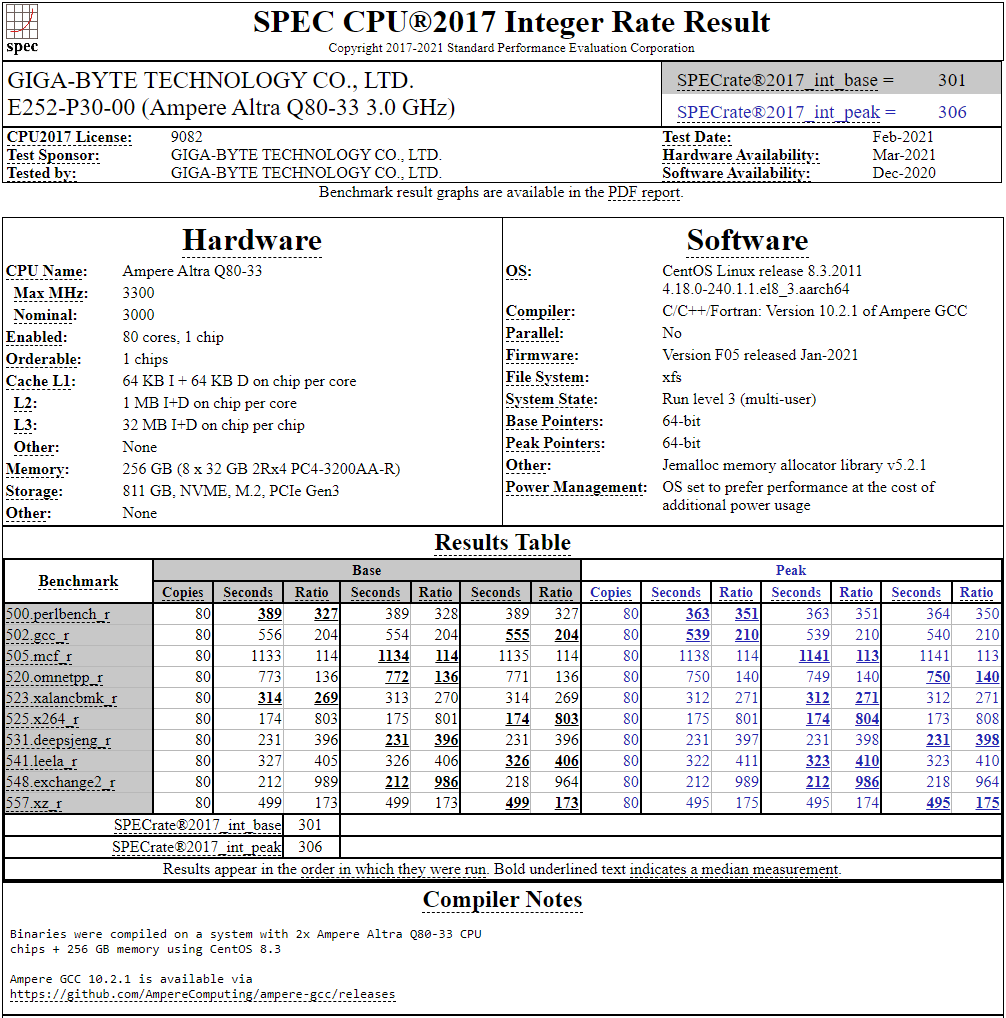 Результаты оказались существенно более высокими, нежели у Ampere Altra Q80-33; правда, стоит сделать скидку на то, что у Ampere использовалась 80-ядерная версия, а не более новая 128-ядерая Altra Max. Но в аутсайдерах оказался также и AMD EPYC 7773X (64 ядер/128 потоков, 2,2-3,5 ГГц, 768 Мбайт L3), показавший 440 очков против 510 у Yitian 710. Увеличенный объём кеша не слишком помог детищу «красных». 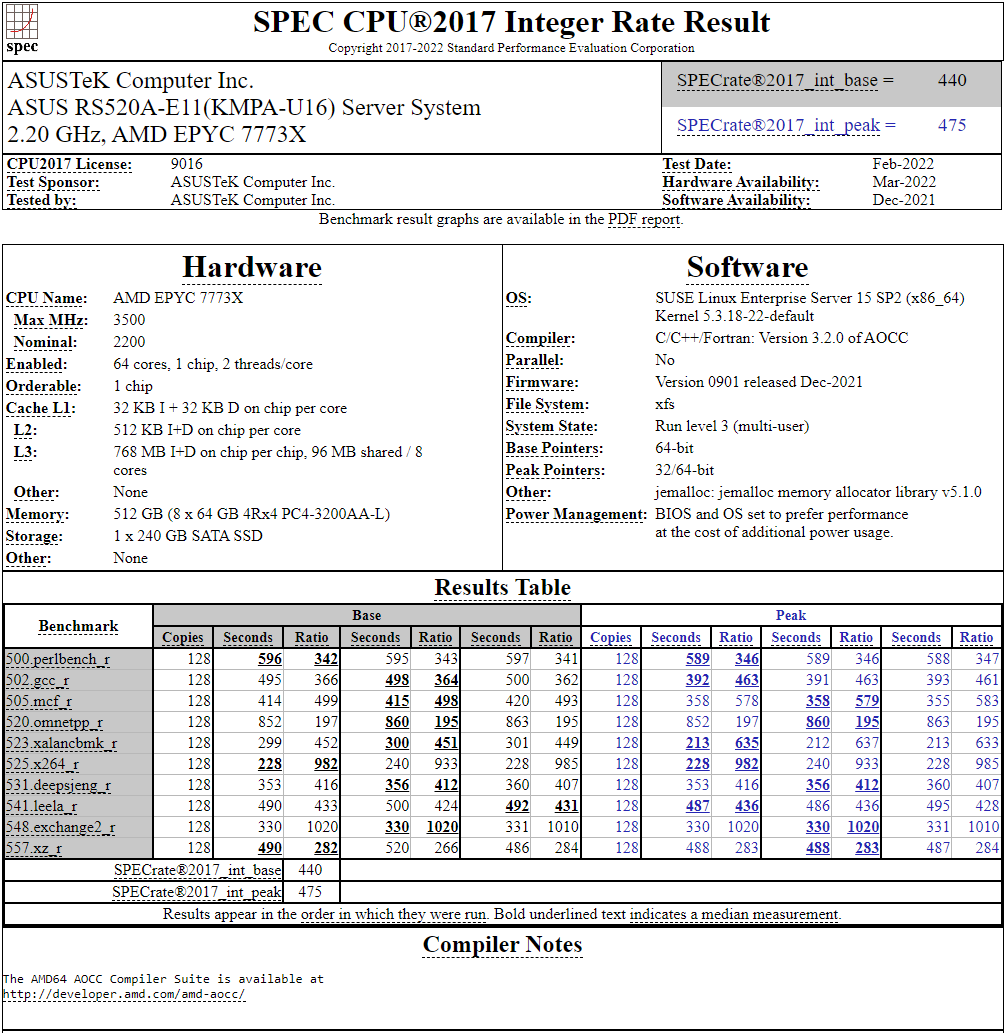 Таким образом, процессор на базе архитектуры Armv9 занял первое место там, где традиционно господствовали решения с архитектурой x86 — достаточно взглянуть на Топ-20 в рейтинге CPU2017 Integer. Можно сказать, что 128-ядерный процессор не вполне корректно сравнивать с 64-ядерным с поддержкой SMT, однако если технологии и архитектура позволяют разместить вдвое больше полноценных ядер в сопоставимом по размеру с AMD EPYC корпусе, так ли это важно? 
Текущий Tоп-20 целочисленной производительности в SPEC CPU2017 К сожалению, пока речь идёт только о целочисленных вычислениях. По неизвестной причине, Alibaba Cloud не опубликовала результаты CPU2017 Floating Point, где сравнение вышло бы существенно интереснее. В любом случае, монополия AMD на первые места пошатнулась; что же касается Intel, то в классе однопроцессорных систем самым мощным вариантом является 36-ядерный Xeon Platinum 8351N, который заведомо проиграет 64-128 ядерным монстрам AMD, Ampere, а теперь уже и Alibaba Cloud.
21.06.2022 [14:32], Алексей Степин
AMD представила индустриальные процессоры Ryzen Embedded R2000: до четырёх ядер Zen+Семейство процессоров AMD Ryzen Embedded довольно консервативно: серия R1000 была представлена еще в 2019 году и включала в себя лишь двухъядерные модели на базе архитектуры Zen первого поколения, а представленные в 2020 году чипы V2000 предлагали до восьми ядер Zen2. Сегодня Advanced Micro Devices объявила о выпуске новых процессоров R2000 с теплопакетом от 12 до 54 Вт и чуть более современной (по сравнению с R1000) архитектурой Zen+. Эти максимально экономичные процессоры предназначены для индустриального применения, в том числе в системах машинного зрения, IoT, тонких клиентах, видеостенах, киосках и тому подобном оборудовании. В серию вошли модели R2544, R2514, R2314 и R2312. 
Источник: AMD В сравнении с R1000 производительность новинок выросла на 81%, и неудивительно — количество процессорных ядер возросло с двух до четырёх. Соответственно, с 1 до 2 Мбайт увеличился объём кеша L2, а также появилась поддержка памяти DDR4-3200 (два канала). Нового в Ryzen Embedded R2000 немного, за исключением более совершенной архитектуры ядер, но в количественном отношении новые процессоры во всём лучше старых: больше ядер, вдвое более производительная подсистема памяти, возросшее с 8 до 16 количество линий PCI Express 3.0. Также доступно до двух портов SATA-3 и до шести портов USB (3.2 Gen2 и 2.0). 
Текущий модельный ряд AMD Ryzen Embedded. Источник: AMD С трёх до четырёх возросло и количество подключаемых дисплеев с поддержкой разрешения 4К, хотя поддержка HDMI по-прежнему ограничена версией 2.0b. Но есть и DisplayPort 1.4 с eDP 1.3. Можно отметить наличие встроенного сопроцессора безопасности AMD Secure Processor, позволяющего шифровать содержимое оперативной памяти на лету. Поскольку новая серия относится к промышленной, срок сопровождения составляет 10 лет. В число поддерживаемых ОС вошли Windows 10/11 и Ubuntu LTS. В число партнёров AMD, которые представили или собираются представить свои решения на базе Ryzen Embedded R2000, входят компании Advantech, DFI, IBASE и Sapphire Technology. Среди анонсированных продуктов есть платформы для игровых автоматов, цифровые киоски, промышленные системные платы, платформы SD-WAN и многое другое.
20.06.2022 [23:39], Игорь Осколков
Джим Келлер назвал глупостью отказ AMD от развития серверных Arm-процессоровМы уже рассказывали краткую историю развития серверных Arm-процессоров в обзоре Ampere Altra. Среди неудачных проектов был и AMD Opteron A1100 (Seattle), выход которого задержался на два года. Но вместе с анонсом этого CPU компания AMD озвучила планы по дальнейшему развитию Arm-решений, которые включали Project SkyBridge (ARM Cortex-A57) и K12 (кастомная реализация ARMv8-A). Над последним параллельно с разработкой x86-ядер Zen трудился Джим Келлер (Jim Keller). 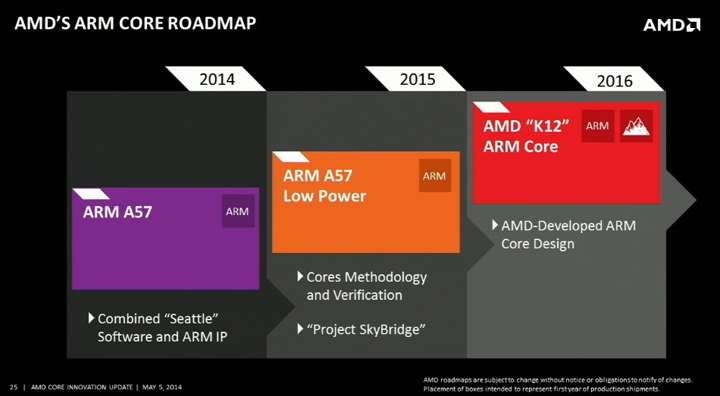
Изображения: AMD В своём майском докладе на конференции Future of Compute Келлер сообщил, что во время планирования Zen 3 он и другие инженеры обратили внимание на значительное сходство в реализации архитектур x86 и Arm, поскольку «внутри все современные компьютеры на самом деле являются RISC-машинами». По словам Келлера, отличия по большому счёту кроятся в декодерах инструкций, так что он с командой постарался сделать решение, которое могло бы работать с обоими архитектурами. «Они [AMD] по глупости отменили этот проект» — приводит слова Келлера The Register. Сам Келлер в своё время назвал работу над Zen более приоритетной, но после его ухода из AMD в 2016 году компания полностью забросила K12.  K12 должен был стать процессором, ориентированным на энергоэффективность и способным работать на высоких частотах. Он был предназначен для высокоплотных систем, а также для встраиваемых решений и заказных чипов. В конце концов, AMD добьётся этого с помощью, например, Zen 4c (EPYC Bergamo), но к этому моменту появится очередное поколение Arm-чипов Ampere Computuing, CPU которой уже доступны в облаках Oracle, Microsoft и других крупных игроков. А Amazon с Alibaba и вовсе пошли по пути создания собственных Arm-процессоров. Впрочем, и без подобных чипов сейчас дела на серверном рынке у AMD идут прекрасно.
10.06.2022 [03:30], Игорь Осколков
AMD анонсировала серверные процессоры EPYC Genoa-X, Siena и TurinНа прошедшем этим вечером отчётном мероприятии Financial Analysts Day 2022 компания AMD поделилась планами по дальнейшему развитию серверных процессоров EPYC. Речь шла как об уже анонсированных продуктах, так и о совершенно новых, предназначенных для неосвоенных ранее компанией сегментов. Наиболее значимым, хотя и наименее детальным, стал официальный анонс пятого поколения AMD EPYC под кодовым именем Turin (EPYC 7005), которое должно появиться до конца 2024 года. Они будут основаны на существенно переработанной архитектуре Zen 5 и изготавливаться по смешанному 3- и 4-нм техпроцессу. Обещано три разновидности кристаллов: обычные, с 3D V-Cache и «облачные» (Zen 5c), оптимизированные для повышения плотности размещения. Важно тут то, что таким образом сохранится преемственность между поколениями, что определённо порадует заказчиков. 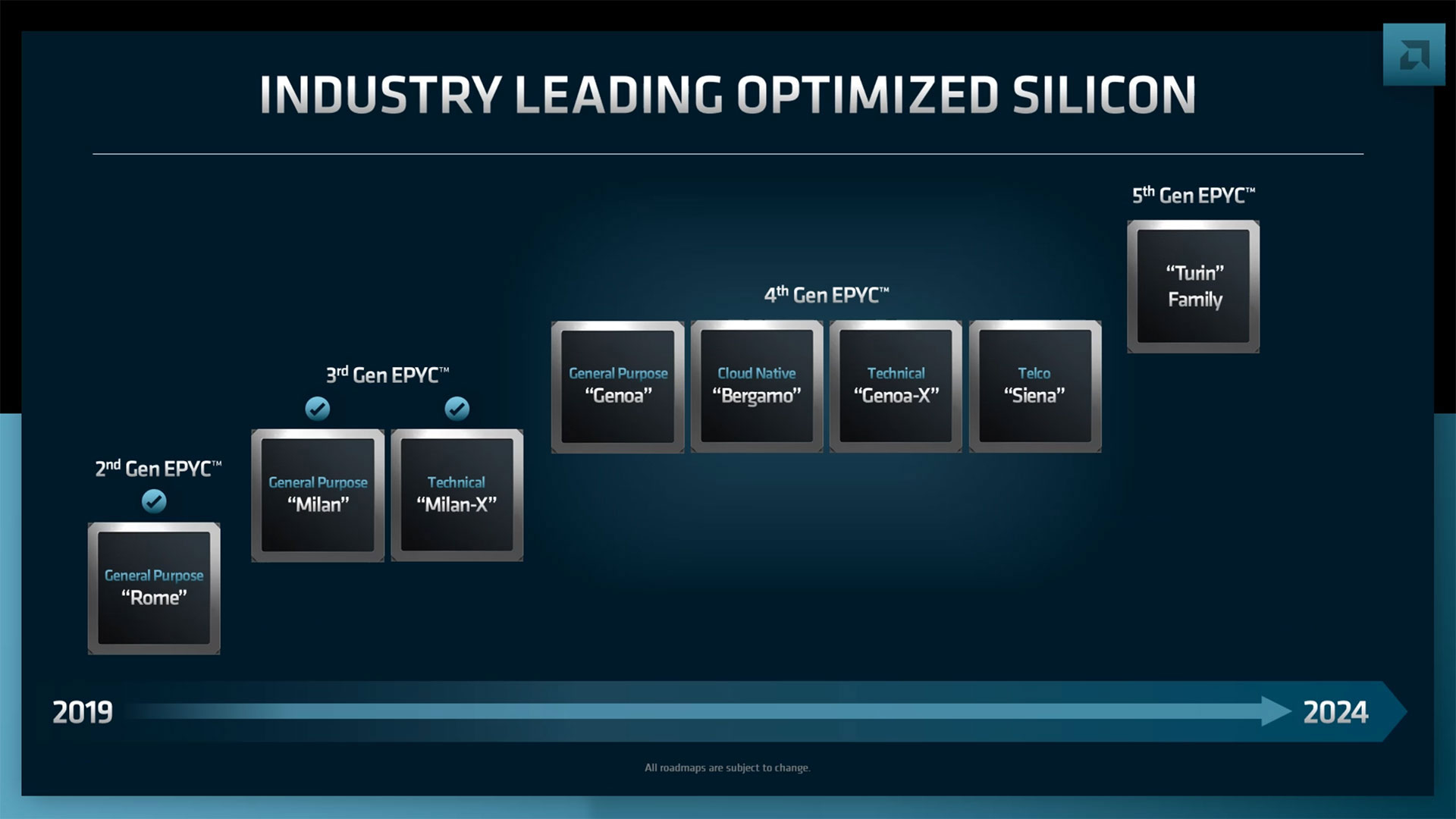
Изображения: AMD (via Tom's Hardware) Но в ближайшее время нас ждёт выход AMD EPYC Genoa, который должен состояться в IV квартале текущего года. Эти 5-нм процессоры получат до 96 ядер Zen 4, 12 каналов DDR5, поддержку PCIe 5.0 и CXL. Причём сейчас уже явно говорится о возможности расширения системной памяти с помощью CXL. Переход на новый техпроцесс и увеличившееся в 1,5 раза количество ядер дали прирост производительности до +75% (в пример приводится тест Java SPECjbb).  Для Genoa потребуется новый сокет SP5 (LGA6096). Он же будет готов принять ещё два варианта процессоров. Первый — это новенький Genoa-X, по названию которого легко догадаться, что это тот же Genoa (тоже до 96 ядер), снабжённый расширенным L3-кешем 3D V-Cache (от 1 Гбайт и более). Как и Milan-X, он будет ориентирован на специфический класс нагрузок, которые выигрывают от увеличения доступного объёма кеша. Это, например, расчётные задачи и СУБД.  Genoa-X появятся в 2023 году. Тогда же стоит ждать и особую серию Bergamo. Эти процессоры, как и было обещано ранее, получат до 128 ядер (и 256 потоков), сохранив совместимость с сокетом SP5. Основаны они будут на 5-нм ядрах Zen 4c, который чем-то напоминают E-ядра в исполнении Intel. Однако набор команд у Zen 4c будет одинаков с Zen 4. Деталей устройства c-ядер AMD снова не раскрыла, но можно предположить, что у них переработана иерархия кешей. Предназначены они для гиперскейлеров, которым важна плотность размещения ресурсов, а не только производительность  В 2023 году появятся и «малые» EPYC’и под кодовым названием Siena. Они оптимизированы с точки зрения энергоэффективности и предлагают до 64 ядер Zen 4. Siena ориентированы на периферийные вычисления и телеком-сегмент. Подробностей о них пока тоже мало. Не исключено, что мы увидим и гибриды наподобие Ice Lake-D, включающие интегрированные «умные» сетевые контроллеры. 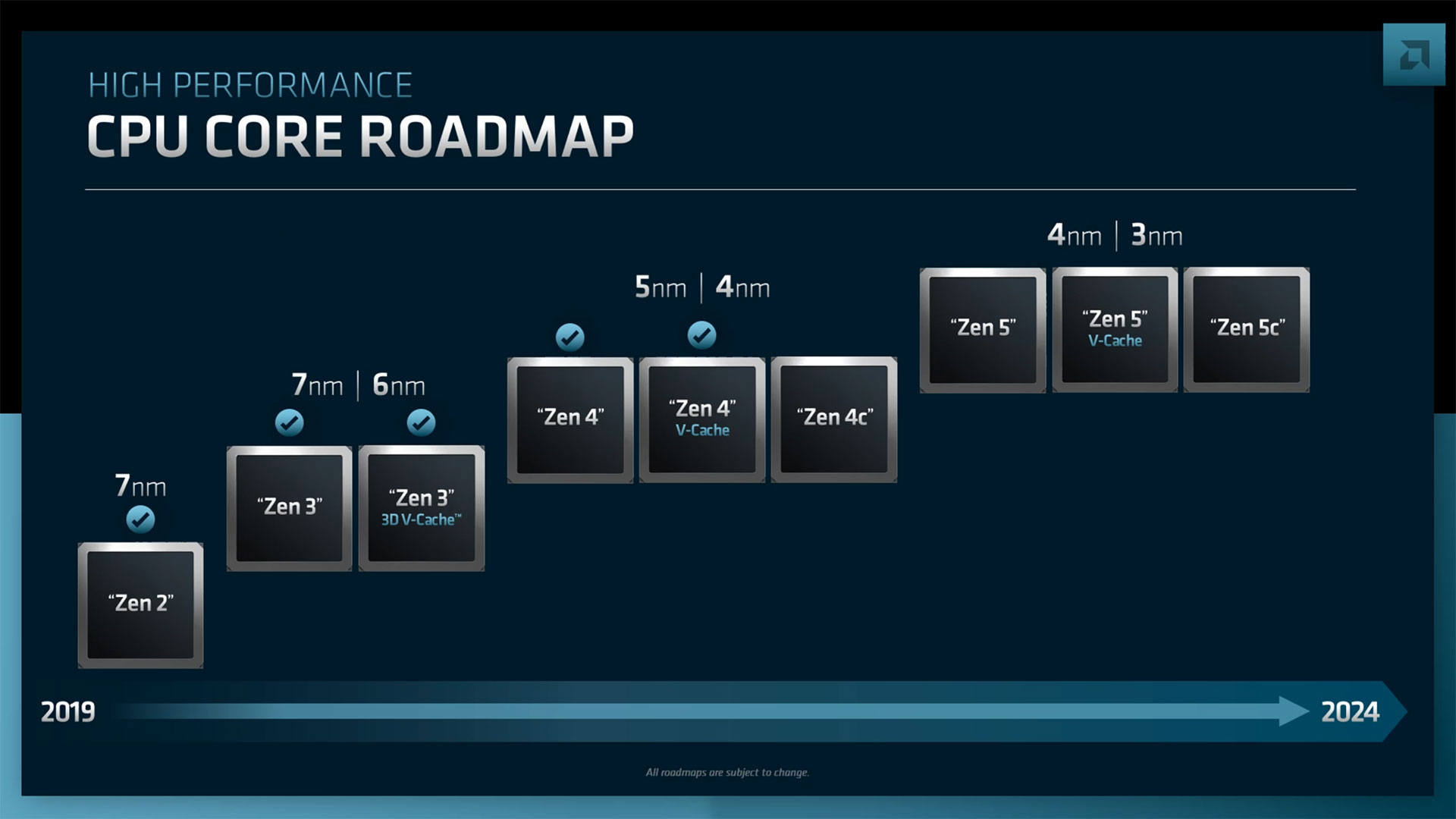 Существенным для всех новинок станет использование архитектуры Zen 4 (4 и 5 нм), которая, помимо ожидаемого прироста производительности, получит новые возможности. Среди них — поддержка AVX-512 (возможно, не самого полного набора) и новых инструкций для ИИ-нагрузок, которыми Intel хвасталась в течение нескольких лет. Но что ещё более важно, Zen 4 получат четвёртое поколение интерконнекта Infinity Architecture, который позволит более плотно связать различные чиплеты, причём и на уровне «кремния» (2.5D- и 3D-упаковка).  А это открывает путь к эффективной компоновке различных функциональных модулей с поддержкой когерентности на уровне всего чипа — AMD подтвердила возможность интеграции FPGA Xilinx и IP-блоков сторонних компаний. Новый интерконнект также совместим с CXL 2.0, что важно для работы с памятью, а будущие версии получат поддержку CXL 3.0 и UCIE. Именно четвёртое поколение Infinity позволило AMD создать свои первые серверные APU Instinct MI300.
09.06.2022 [21:00], Алексей Степин
Серия процессоров Intel Atom P5000 Snow Ridge пополнилась новыми моделямиКорпорация Intel на этой неделе уделила немало внимания серии экономичных процессоров Atom. Помимо новых моделей в серии C5000 Parker Ridge появились и новые чипы в семействе P5000 Snow Ridge. Эта 10-нм SoC-платформа дебютировала в 2020 году, её главное назначение — использование в беспроводном 5G-оборудовании, а главной отличительной особенностью можно назвать развитую сетевую подсистему. Последняя предлагает тесную интеграцию со 100GbE-контроллером Intel Ethernet 800 с поддержкой коммутации и технологии QAT. Изначально в серии было всего четыре модели с номерами серии P5900, количеством ядер Tremont от 8 до 24 и литерой B в названии — от «Base Station». Теперь семейство пополнилось девятью новыми моделями с индексами от P5300 до P5700. Сравнить характеристики всех чипов P5000 можно на сайте Intel, воспользовавшись этой ссылкой. 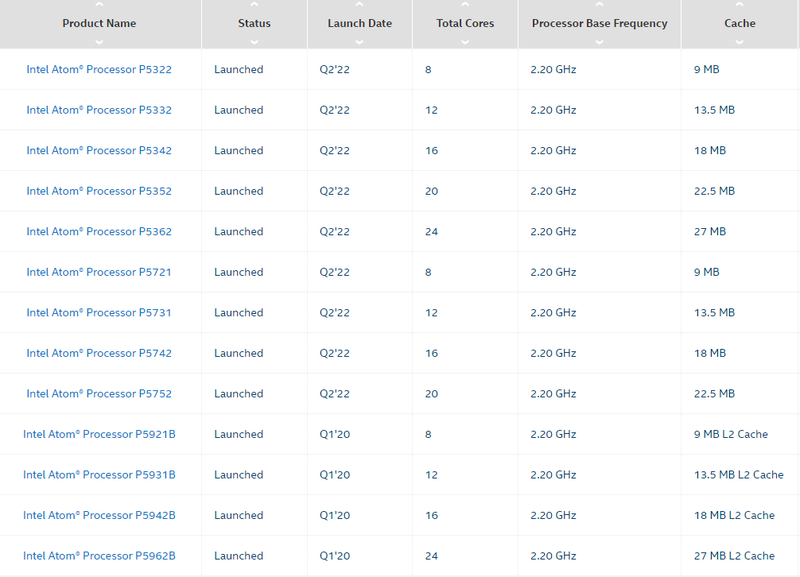
Модельный ряд Intel Atom P5000. Источник: Intel Хотя базовая частота у всех новинок осталась прежней и составляет 2,2 ГГц, объём кеша на кластер из четырёх ядер равен 4,5 Мбайт, а количество линий PCIe составляет 32 шт., есть и отличия. Для новых моделей заявлена поддержка вдвое большего максимального объёма оперативной памяти, 256 Гбайт против 128 Гбайт у чипов с литерой B. Есть и некоторые изменения в подсистеме памяти: младшие версии с номерами P5300 поддерживают либо DDR4-2400, либо 2666, тогда как для P5700 сохранена поддержка DDR4-2933. 
Intel NetSec Accelerator card. Источник: Intel (via ServeTheHome) Теплопакеты достаточно высокие, от 48 до 83 Вт, что отчасти продиктовано наличием продвинутой сетевой подсистемы. Она может быть сконфигурирована в различных режимах, у P5300 это от 8×10GbE до 1×100GbE, P5700 может поддерживать от 8 портов 25GbE с шифрованием, а в режиме 2×100GbE один порт обязательно будет резервным. Сетевой движок QAT третьего поколения сохранился у всех моделей. Режим коммутатора доступен только для P5700. 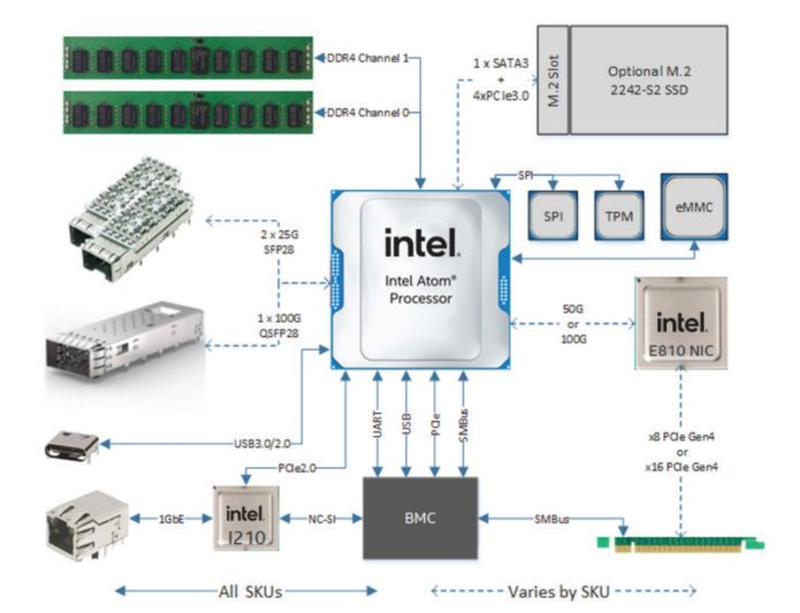
Intel NetSec — полноценная x86-система в виде PCIe-адаптера. Источник: Intel (via ServeTheHome) Новые процессоры Intel Atom P5000 могут служить и основой для современных сетевых ускорителей — компания продемонстрировала плату NetSec Accelerator, спроектированную Silicom и несущую на борту 8-ядерный P5721 или 16-ядерный P5742. Ускоритель имеет либо 2 корзины SFP28 (25GbE), либо корзину QSFP28 (100GbE), свой BMC и опциональный накопитель M.2 2242 в дополнение к 256 Гбайт набортной eMMC. По сути, это полноценная x86-платформа в форм-факторе PCIe-платы. Интерфейс, в зависимости от модели, PCIe 4.0 x8, либо x16, теплопакет у старшего варианта может достигать 115 Вт, поэтому плата использует дополнительное питание. Производительность в дуплексном режиме с полноценным шифрованием в реальном времени — 25 и 50 Гбит/с. Интересно, что новинка не позиционируется как IPU, но и термин DPU компанией не используется.
09.06.2022 [16:37], Сергей Карасёв
Intel представила первые процессоры серии Atom C5000 Parker RidgeКорпорация Intel анонсировала первые шесть процессоров семейства Atom C5000 (Parker Ridge), предназначенных для применения в серверном и сетевом оборудовании. Дебютировали изделия с обозначениями C5325, C5320, C5315, C5310, C5125 и C5115, которые изготавливаются по 10-нм техпроцессу. В зависимости от модификации чипы содержат четыре или восемь ядер (Tremont). Технология многопоточности не поддерживается. Тактовая частота модели C5310 составляет 1,6 ГГц. Версии C5325, C5320 и C5315 функционируют на частоте 2,4 ГГц, а C5125 и C5115 — 2,8 ГГц. Поддерживается работа с двухканальной оперативной памятью DDR4, частота которой может составлять 2400 или 2933 МГц (см. характеристики отдельных моделей в таблице ниже). Максимально поддерживаемый объём ОЗУ у всех решений равен 256 Гбайт. Все изделия наделены 9 Мбайт кеша второго уровня. Показатель TDP варьируется от 32 до 50 Вт. Это, как отмечает ресурс ServeTheHome, заметивший появление новинок в базе Intel, довольно много для изделий такого класса. 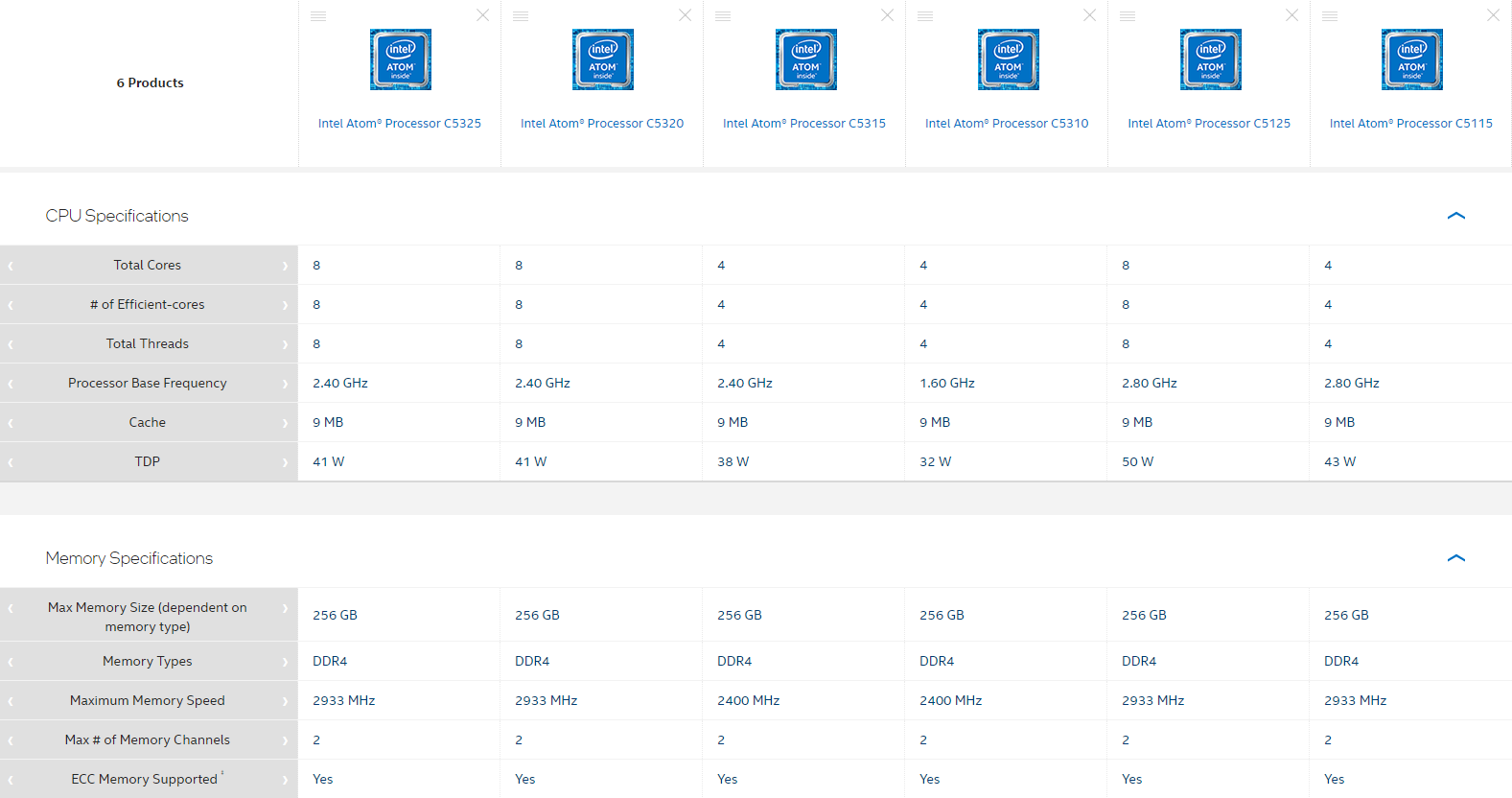
Источник: Intel Процессоры различаются количеством поддерживаемых линий PCIe — 12, 16 или 32. Чипы позволяют задействовать 12 или 16 портов SATA и восемь USB-портов в конфигурации 4 × USB 2.0 и 4 × USB 3.0. Все процессоры поддерживают технологию Intel QuickAssist (QAT) второго поколения (шифрование 20 Гбит/с), средства виртуализации Virtualization Technology (VT-x), инструкции AES, технологии Intel Trusted Execution и Enhanced Intel SpeedStep. Отличительной же чертой серии являются встроенные сетевые интерфейсы (до 8 шт., до 50GbE), которые есть в четырёх из шести представленных моделей.
22.03.2022 [18:48], Игорь Осколков
NVIDIA анонсировала 144-ядерные Arm-процессоры Grace и гибрид Grace HopperГлавным событием GTC 2022 стал анонс новых ускорителей H100 (Hopper), которые станут доступны в III квартале 2022 года. Вслед за ними в первой половине 2023 года появятся давно обещанные CPU Grace и гибридная система Grace Hopper, сочетающие, как понятно из названия, процессоры Grace (ARMv9) и ускорители Hopper. Как и было сказано ранее, для связи всех компонентов между собой будет использоваться mesh-сеть на базе всё той же шины NVLink 4.0 (900 Гбайт/с) с кеш-когерентностью. А сочетание LPDDR5X (с ECC, конечно) и HBM даст суммарный объём памяти до 600 Гбайт с общей полосой пропускания порядка 2 Тбайт/с. Для Grace Hopper компания подготовит полный стек ПО, благо портированием на Arm она начала заниматься ещё 3 года назад. 
NVIDIA Grace (Изображения: NVIDIA) Двухчиповый процессор Grace Superchip для ИИ- и HPC-нагрузок имеет 144 ядра, результат которых в SPECrate2017_int_base составляет 740, что, по словам компании, в полтора раза выше, чему у пары AMD EPYC, использующихся в DGX A100. И это, честно говоря, не такой уж и впечатляющий результат.  Но NVIDIA утверждает, что новые CPU вдвое лучше по отношению производительности к энергопотреблению, чем «традиционные серверы» — использование LPDDR5X позволяет добиться пропускной способности памяти в 1 Тбайт/с, а вся сборка CPU+RAM будет потреблять менее 500 Вт. 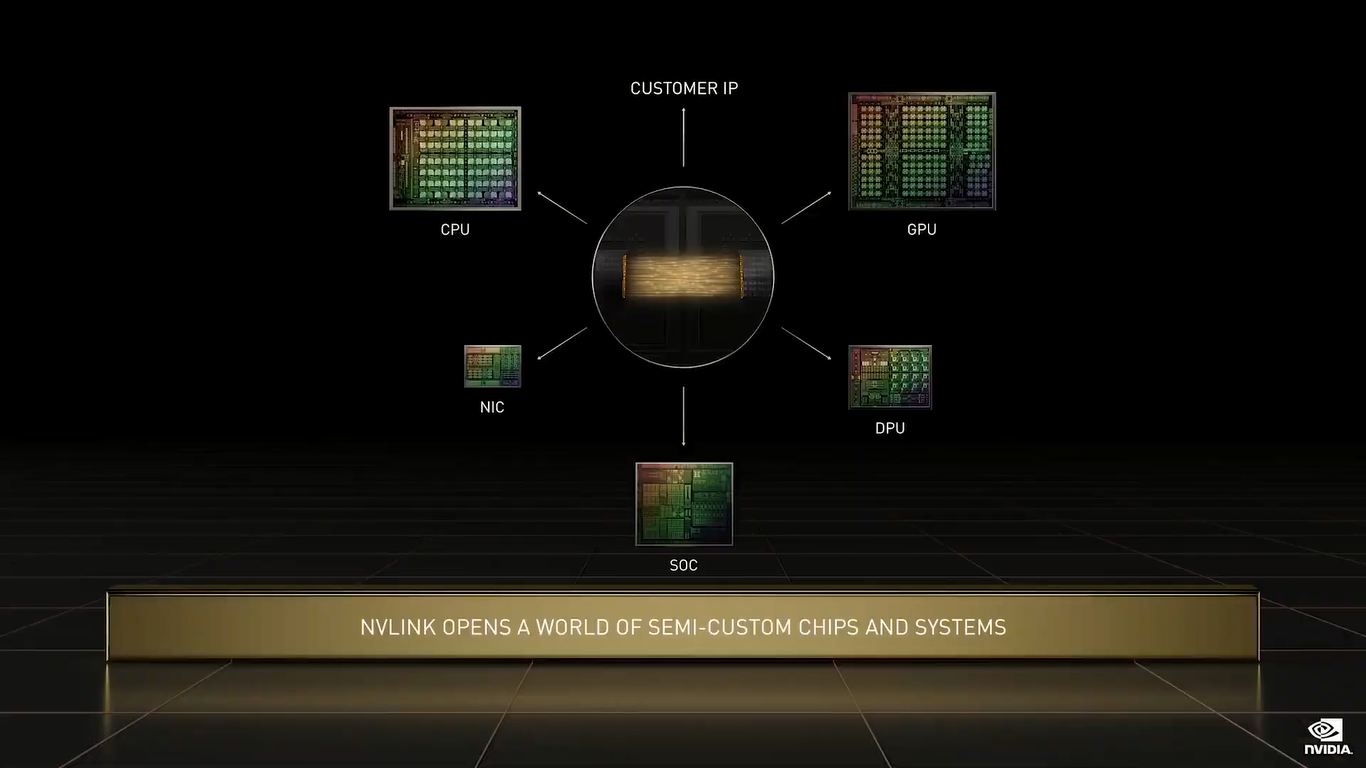 Чипы (или чиплеты, если хотите) в Grace Superchip тоже объединены посредством NVLink, только в данном случае этот интерконнект называется NVLink-C2C (Chip-to-Chip). И его NVIDIA предлагает использовать другим компаниям для создания кастомных сборок, объединяющих необходимые кристаллы, да и сама готова масштабировать и адаптировать свои решения под нужды заказчика. 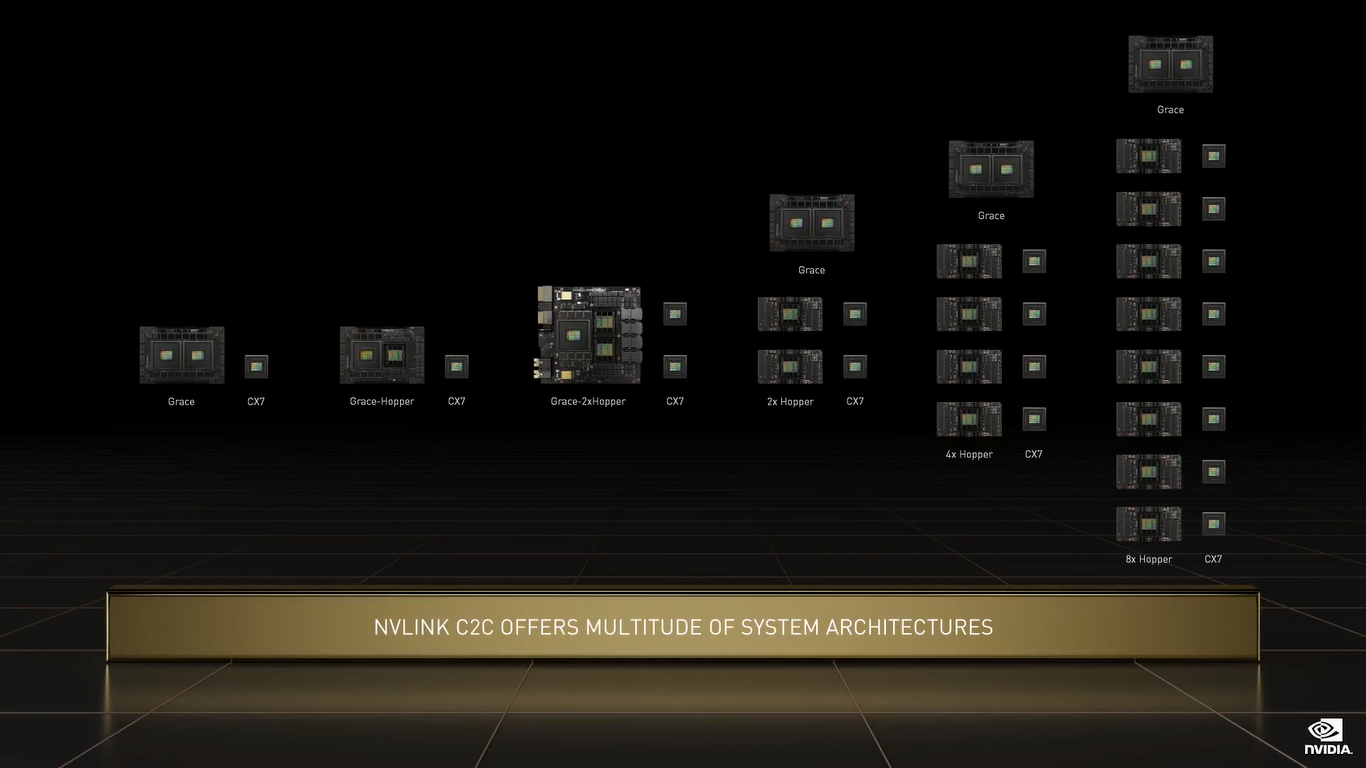 По словам NVIDIA, NVLink-C2C в 25 раз энергоэффективнее PCIe 5.0, а для его реализации нужна в 90 раз меньшая площадь кремния. Шина предлагает высокую скорость (да-да, всё те же 900 Гбайт/с), низкий уровень задержек, поддержку атомарных операций и совместимость с Arm AMBA CHI, CXL и UCIe.
24.02.2022 [19:00], Алексей Степин
Intel анонсировала процессоры Xeon D-1700 и D-2700: Ice Lake-SP + 100GbEКонцепция периферийных вычислений сравнительно молода и до недавнего времени зачастую её реализации были вынуждены обходиться стандартными процессорами, разработанными для применения в серверах, или даже в обычных ПК и ноутбуках. Intel, достаточно давно имеющая в своём арсенале серию процессоров Xeon D, обновила модельный ряд этих CPU, которые теперь специально предназначены для использования на периферии. 
Изображения: Intel Анонс выглядит очень своевременно, поскольку по оценкам Intel, к 2025 году более 50% всех данных будет обрабатываться вне традиционных ЦОД. Новые серии процессоров Xeon D-1700 и D-2700 обладают рядом свойств, востребованных именно на периферии — особенно на периферии нового поколения. 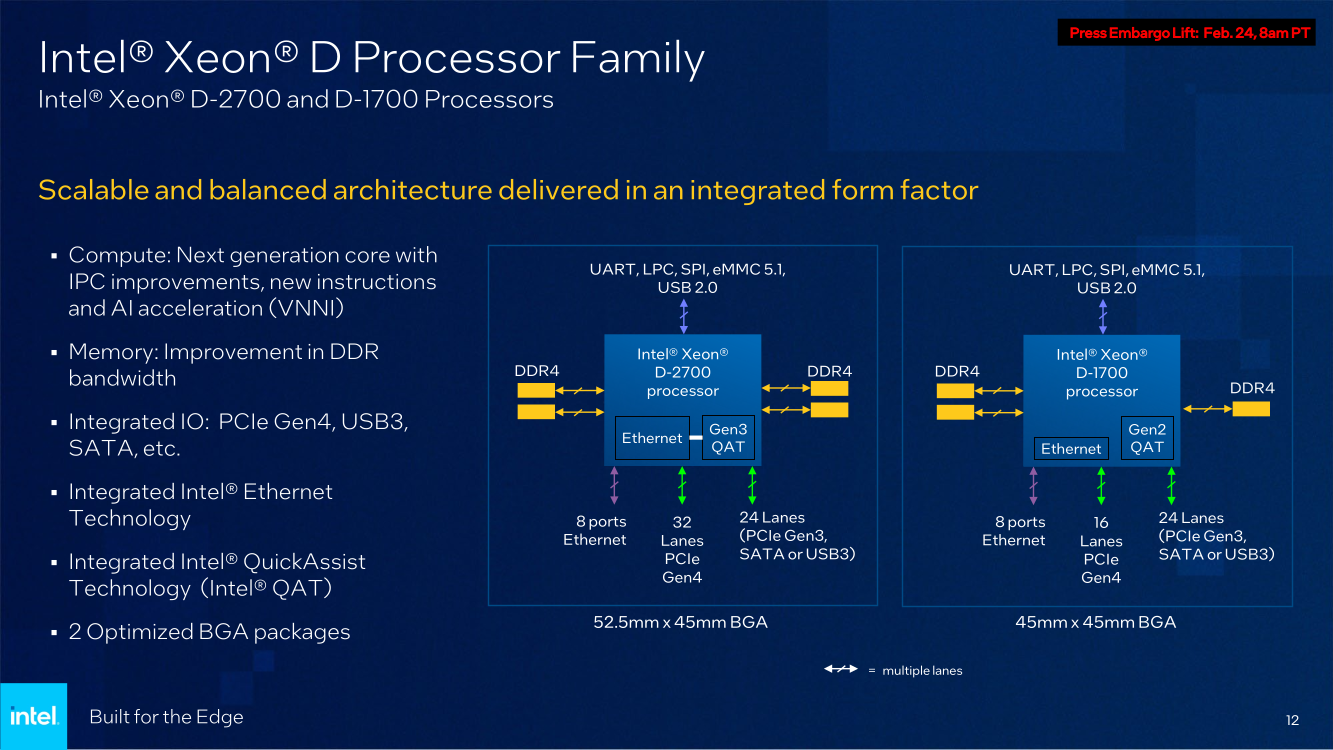 Новинки имеют следующие особенности:
Последний пункт ранее был реализован в процессорах серий Atom x6000E, Xeon W-1100E и некоторых процессорах Core 11-го поколения. Вкратце это технология, позволяющая координировать вычисления с точностью менее 200 мкс в режиме TCC за счёт точной синхронизации таймингов внутри платформы. И здесь у Xeon D, как у высокоинтегрированной SoC, есть преимущество в реализации подобного класса точности. Помогает этому и наличие специального планировщика для общего кеша L3, позволяющего добиться более консистентного доступа к кешу и памяти. 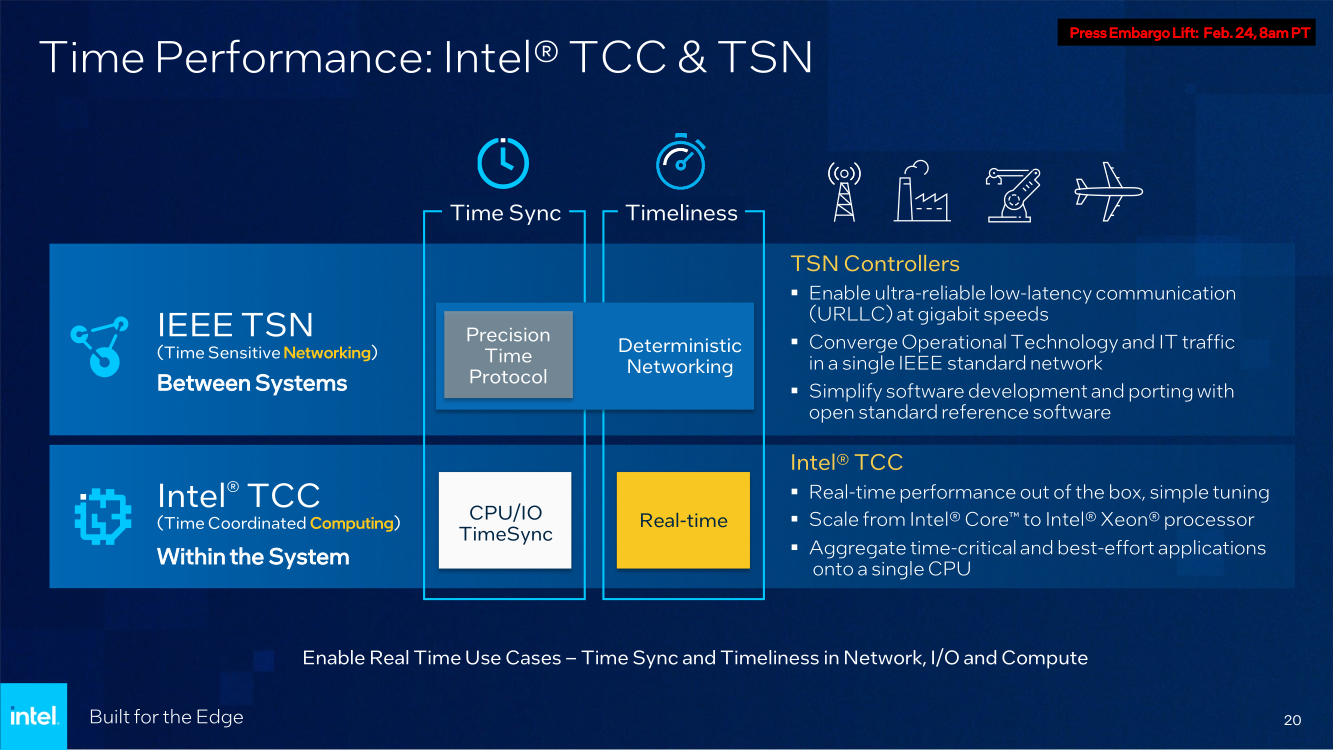 Это незаменимая возможность для систем, обслуживающих сверхточные промышленные процессы, тем более что Intel предлагает хорошо документированный набор API и средств разработки для извлечения из режима TCC всех возможностей. Важной также выглядит наличие поддержки пакета технологий Intel QuickAssist (QAT) для ускорения задач (де-)шифрования и (де-)компрессии. 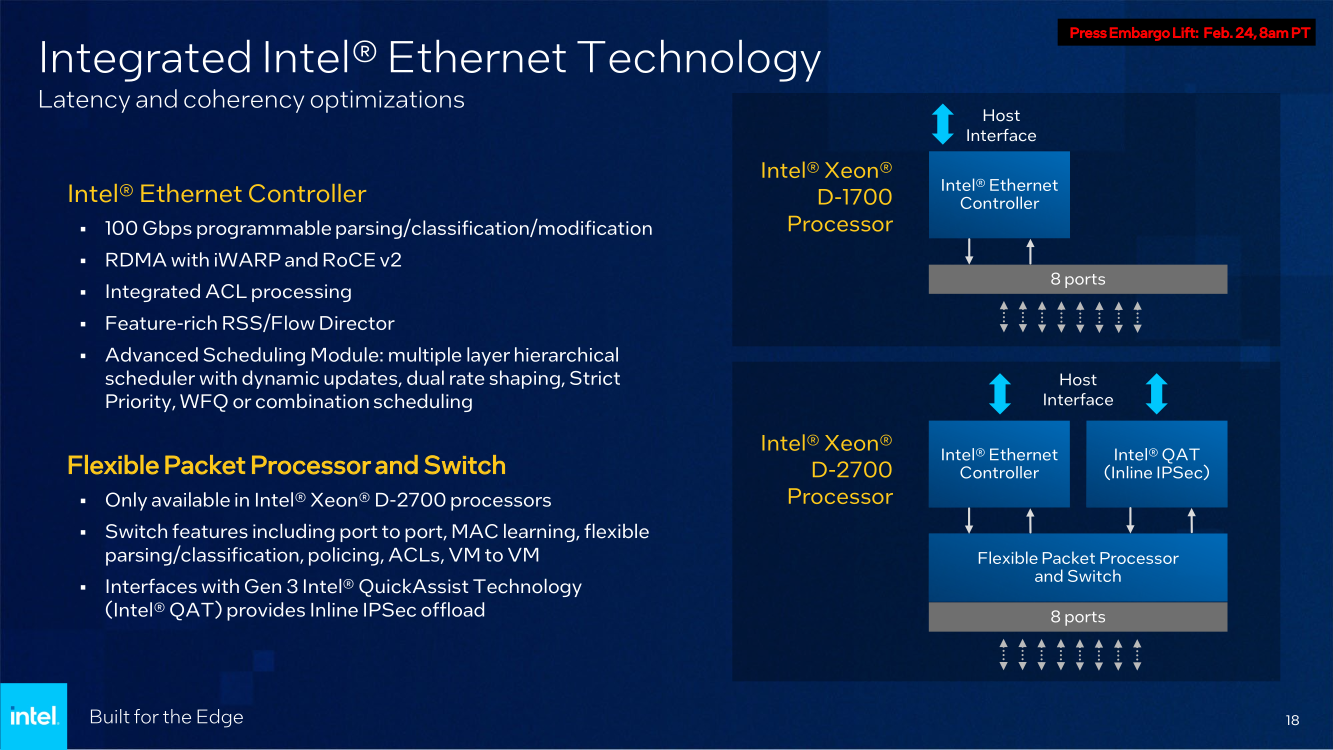 Третье поколение QAT, доступное, правда, только в Xeon D-2700, в отличие от второго (и это случай D-1700), связано в новых SoC непосредственно с контроллером Ethernet и встроенным программируемым коммутатором. В частности, поддерживается, и IPSec-шифрование на лету (inline) на полной скорости, и классификация (QoS) трафика. Также реализована поддержка новых алгоритмов, таких, как Chacha20-Poly1305 и SM3/4, имеется собственный движок для публичных ключей, улучшены алгоритмы компрессии. 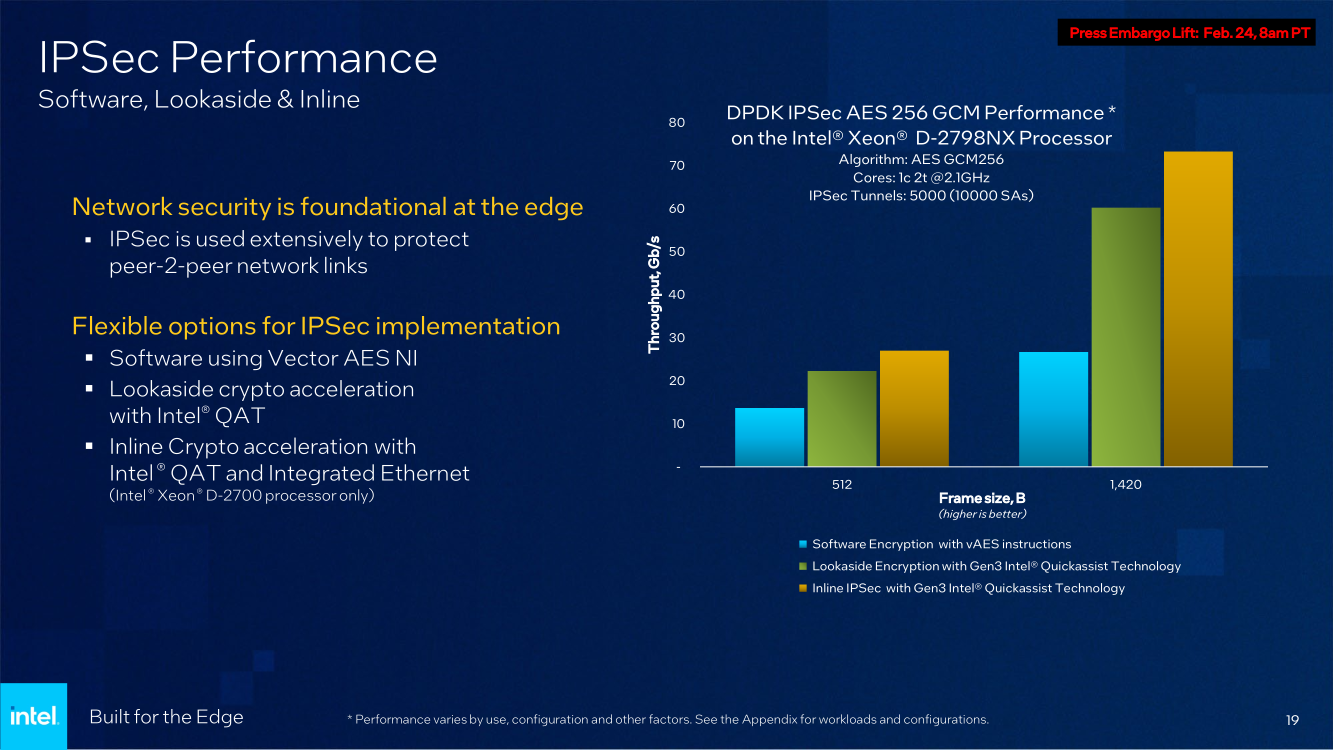 Но QAT может работать и совместно с CPU (lookaside-разгрузка), а можно и вовсе обойтись без него, воспользовавшись AES-NI. Поддержке безопасности помогает и полноценная поддержка защищённых вычислительных анклавов SGX, существенно ограничивающая векторы атак как со стороны ОС и программного обеспечения, так и со стороны гипервизора виртуальных машин. Это важно, поскольку на периферии уровень угрозы обычно выше, чем в контролируемом окружении в ЦОД, но для использования SGX требуется модификация ПО.  В целом, «ядерная» часть новых Xeon-D — это всё та же архитектура Ice Lake-SP. Так что Intel в очередной раз напомнила про поддержку DL Boost/VNNI для работы с форматами пониженной точности и возможности эффективного выполнения инференс-нагрузок — новинки почти в 2,5 раза превосходят Xeon D-1600. Есть и прочие стандартные для платформы функции вроде PFR или SST. Из важных дополнений можно отметить поддержку Intel Slim BootLoader. 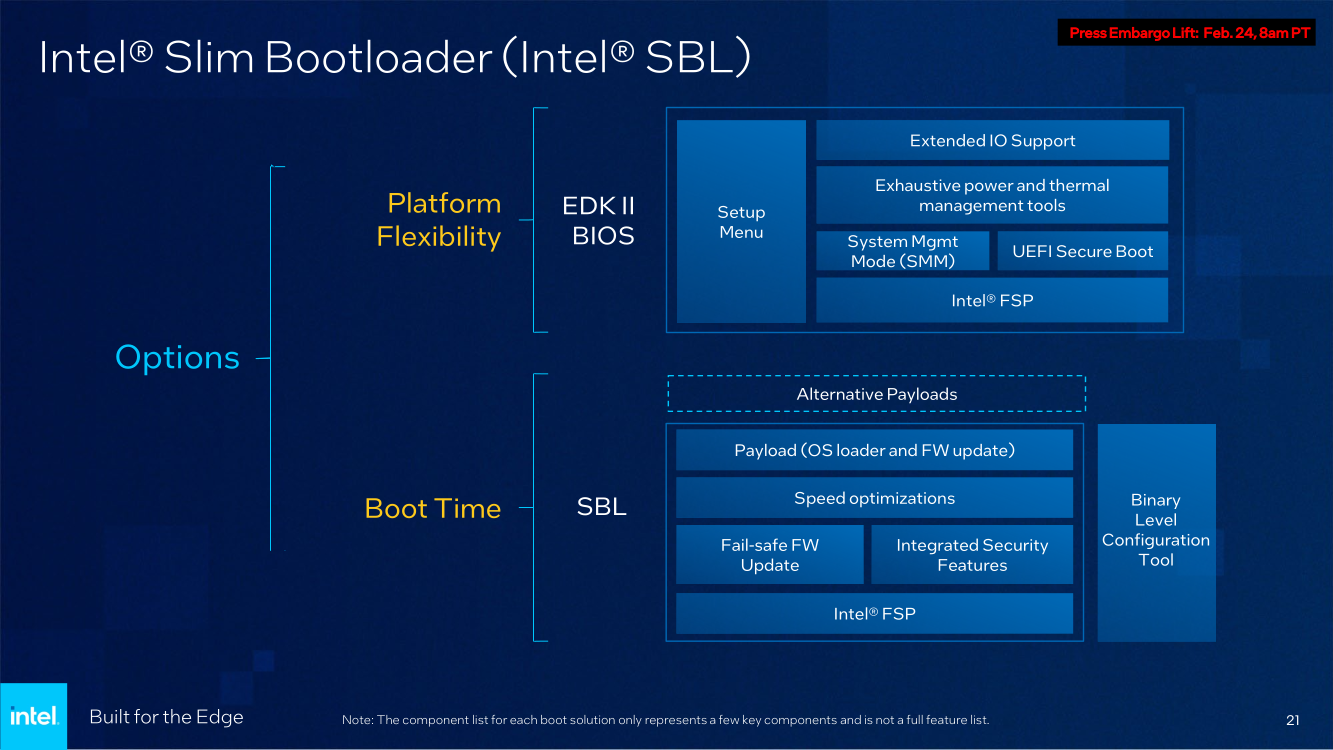 Масштабируемость у новой платформы простирается от 2 до 10 (D-1700) или 20 (D-2700) ядер, а TDP составляет 25–90 и 65–129 Вт соответственно. В зависимости от модели поддерживается работа в расширенном диапазоне температур (до -40 °C). У обоих вариантов упаковка BGA, но с чуть отличными размерами — 45 × 45 мм против 45 × 52,5 мм. На этом различия не заканчиваются. У младших Xeon D-1700 поддержка памяти ограничена тремя каналами DDR4-2933, а вот у D-2700 четыре полноценных канала DDR4-3200. 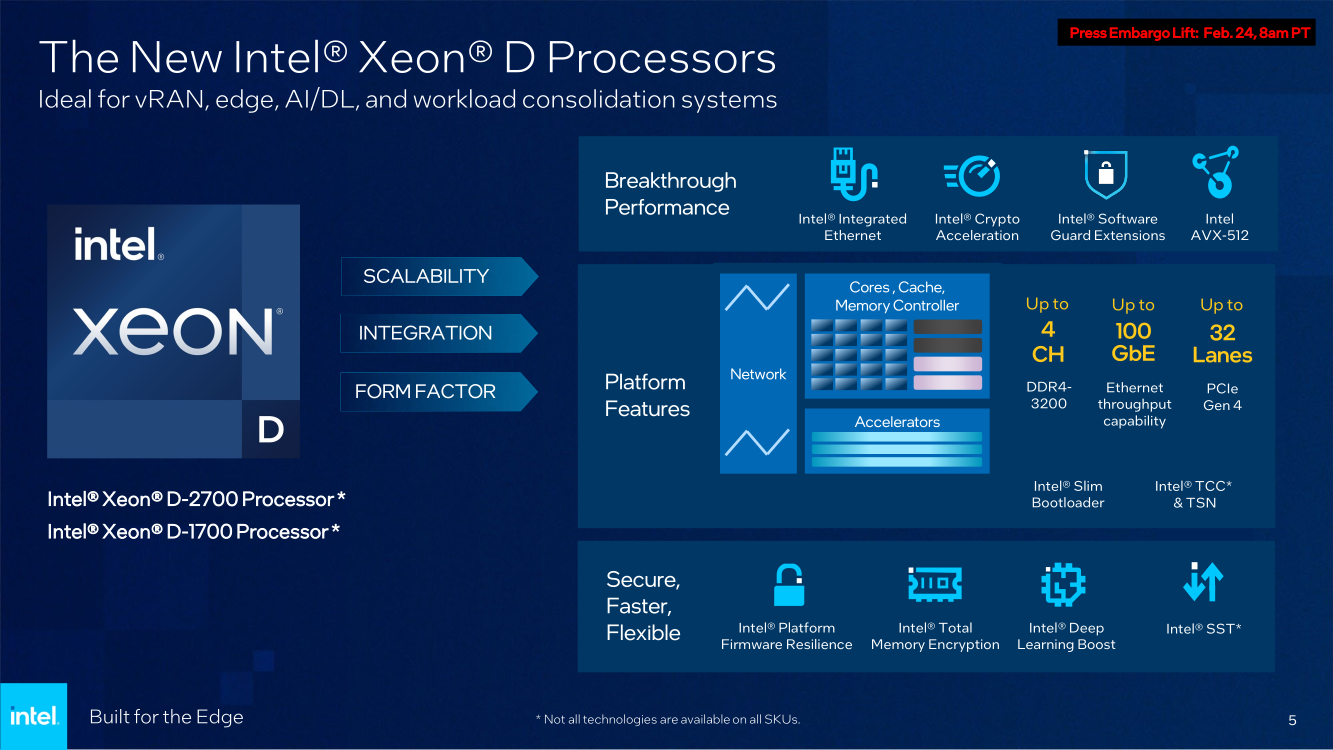 Однако возможности работы с Optane PMem обе модели лишены, несмотря на то, что контроллер памяти их поддерживать должен. Представитель Intel отметил, что если будет спрос со стороны заказчиков, то возможен выпуск вариантов CPU с поддержкой PMem. Дело в том, что прошлые поколения Xeon-D использовались и для создания СХД, а наличие 100GbE-контроллера с RDMA делает новинки не менее интересными для этого сегмента. 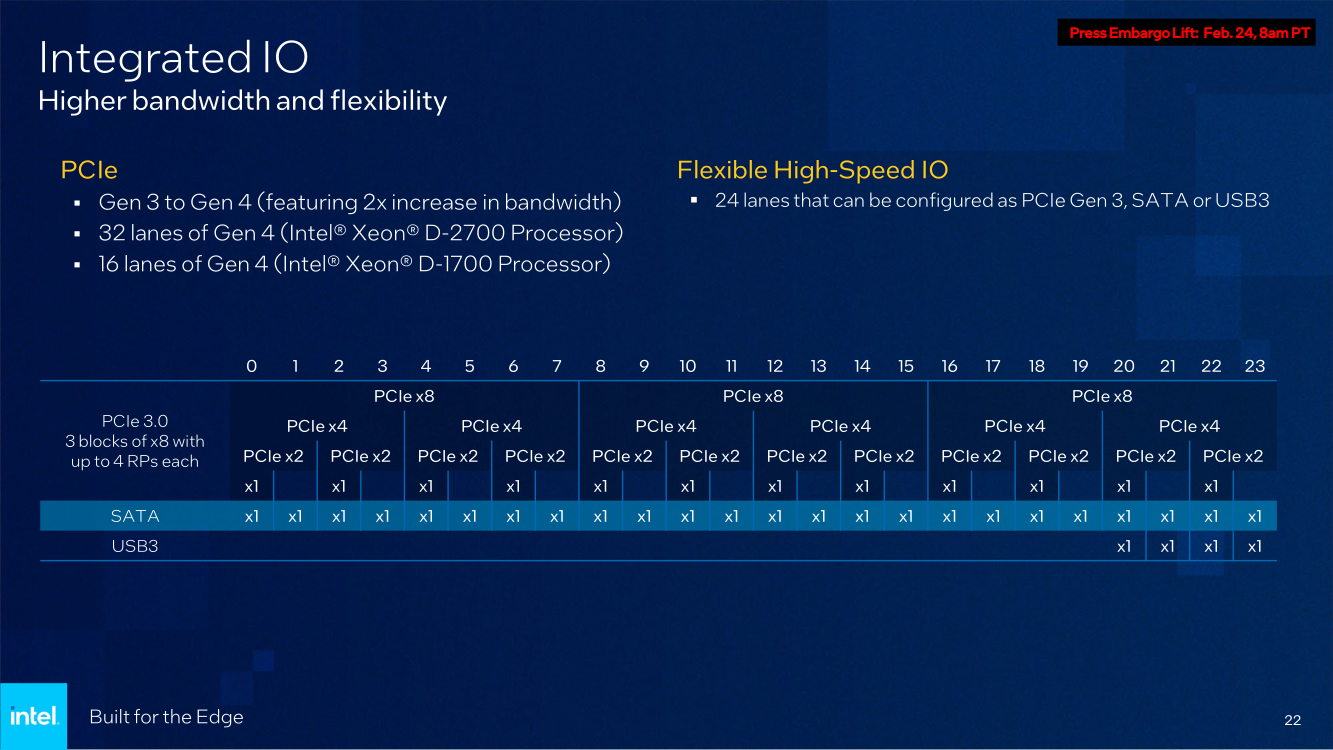 Кроме того, есть и поддержка NTB, да и VROC с VMD вряд ли исчезли. Для подключения периферии у D-2700 доступно 32 линии PCIe 4.0, а у D-1700 — 16. У обоих серий CPU также есть 24 линии HSIO, которые на усмотрение производителя можно использовать для PCIe 3.0, SATA или USB 3.0. Впрочем, пока Intel предлагает использовать всё это разнообразие интерфейсов для подключения ускорителей и различных адаптеров.  Поскольку в качестве одной из основных задач для новых процессоров компания видит их работу в качестве контроллеров программно-определяемых сетей, включая 5G, она разработала для этой цели референсную платформу. В ней предусматривается отдельный модуль COM-HPC с процессором и DIMM-модулями, что позволяет легко модернизировать систему. А базовая плата предусматривает наличие радиотрансиверов, что актуально для сценария vRAN.  Поскольку речь идёт не столько о процессорах, сколько о полноценной платформе, Intel серьезное внимание уделила программной поддержке, причём, в основе лежат решения с открытым программным кодом. Это позволит заказчикам систем на базе новых Xeon D разворачивать новые точки и комплексы периферийных вычислений быстрее и проще. Многие производители серверного аппаратного обеспечения уже готовы представить свои решения на базе Xeon D-1700 и 2700.
08.02.2022 [00:30], Владимир Мироненко
Ventana, разработчик серверных процессоров RISC-V, объявил о стратегическом партнёрстве с IntelСтартап Ventana Micro Systems Inc., разработчик высокопроизводительных серверных процессоров на базе архитектуры RISC-V, объявил о стратегическом партнёрстве с Intel — ядра и чиплеты Ventana будут доступны в рамках Intel Foundry Services (IFS) для крупных клиентов ЦОД, операторов сетей 5G, потребителей в областях ИИ и машинного обучения, автомобильной индустрии и т. д. Ventana разрабатывает серверные CPU с расширяемыми возможностями, поставляемые в виде SoC с чиплетной компоновкой или IP-блоков. Процессоры предназначены для обеспечения лучшей в своём классе однопоточной производительности и могут быть оптимизированы для высокопроизводительных и облачных вычислений, ЦОД-нагрузок, 5G и периферийных вычислений, выполнения задач ИИ и машинного обучения, автомобильных и клиентских приложений. 
Источник изображения: ventanamicro.com Модульная и масштабируемая продуктовая стратегия Ventana, основанная на использовании чиплетов, позволяет обеспечить быстрое коммерческое внедрение со значительной экономией времени и стоимости разработки по сравнению с преобладающими на рынке IP-моделями. Собственные ядра CPU компания намерена выпускать на TSMC по 5-нм нормам, но для остальных блоков могут использоваться сторонние производства. В рамках партнёрства с Intel ядра Ventana можно будет интегрировать в SoC конечных заказчиков. Кроме того, Ventana планирует предложить масштабируемую вычислительную платформу, которая позволит гиперскейлерам и крупным OEM-производителям гибко подбирать и настраивать функциональные блоки у заказываемых чипов, значительно сокращая время и стоимость разработки. Боб Бреннан (Bob Brennan), вице-президент Intel Foundry Services по разработке клиентских решений отметил, что у Ventana «самая совершенная и хорошо разработанная платформа» на базе Open Chiplet, которая полностью соответствует видению Intel. По его словам, чиплеты Ventana позволят IFS предоставлять модульные решения, повышающие производительность, снижающие энергопотребление и затраты на разработку, и ускоряющие время выхода продуктов на рынок. |
|

