Материалы по тегу: интерконнект
|
27.06.2024 [23:57], Алексей Степин
Intel представила фотонный интерконнект OCI: по 2 Тбит/с в обе стороны на расстоянии 100 мIntel ведет исследования в области интегрированной фотоники уже много лет, поскольку успех в этой сфере критически важен для HPC-систем нового поколения. Два года назад компания сообщила о создании технологии, использующей существующие техпроцессы обработки 300-мм кремниевых пластин для формирования массива лазеров вкупе с модуляторами. А сейчас можно говорить о достижении новой важной вехи в этой области. На OFC 2024 Intel продемонстрировала опытный образец CPU, оснащённый 64-канальным фотонным интерконнектом OCI (Optical Compute Interconnect). Каждый канал позволяет передавать данные на скорости 32 Гбит/с на расстоянии до 100 м, что позволит решить проблему масштабирования HPC-систем и ИИ-комплексов: пропускной способности 2 Тбит/с (256 Гбайт/с) в каждом направлении хватит на многое. А в перспективе скорость будет доведена до 32 Тбит/с. 
Источник изображений: Intel В настоящее время в системах подобного класса для высокоскоростного соединения узлов используются либо решения с внешними оптическими трансиверами, что серьёзно увеличивает стоимость и энергопотреблению в целом, либо классическую «медь», серьёзно ограниченную по максимальной длине кабеля. OCI позволяет избежать обеих проблем.  Чиплет использует DWDM (восемь длин волн на волокно) и при этом экономичен: энергозатраты на передачу информации составляют всего 5 пДж/бит против 15 пДж/бит у решений с внешними оптическими трансиверами. Ранее заявленную цифру 3 пДж/бит пришлось немного увеличить, что связано с интеграцией интерфейса PCIe.  Внешне продемонстрированный образец чипа напоминает выпускавшиеся когда процессоры Xeon с поддержкой Omni-Path, но вместо электрического разъёма у него теперь оптический соединитель на восемь пар волокон. С помощью простого пассивного переходника к нему в демонстрационной системе Inel был подключен типовой оптоволоконный кабель.  Поскольку речь идёт о чиплете, теоретически ничто не мешает разместить модуль OCI в составе GPU/NPU, FPGA, DPU/IPU и вообще любой модульной SoC. При этом чиплет совместим с PCIe 5.0, так что проблем с интеграцией быть не должно, хотя это и не самый оптимальный вариант. А на уровне упаковки поддерживается и UCIe. 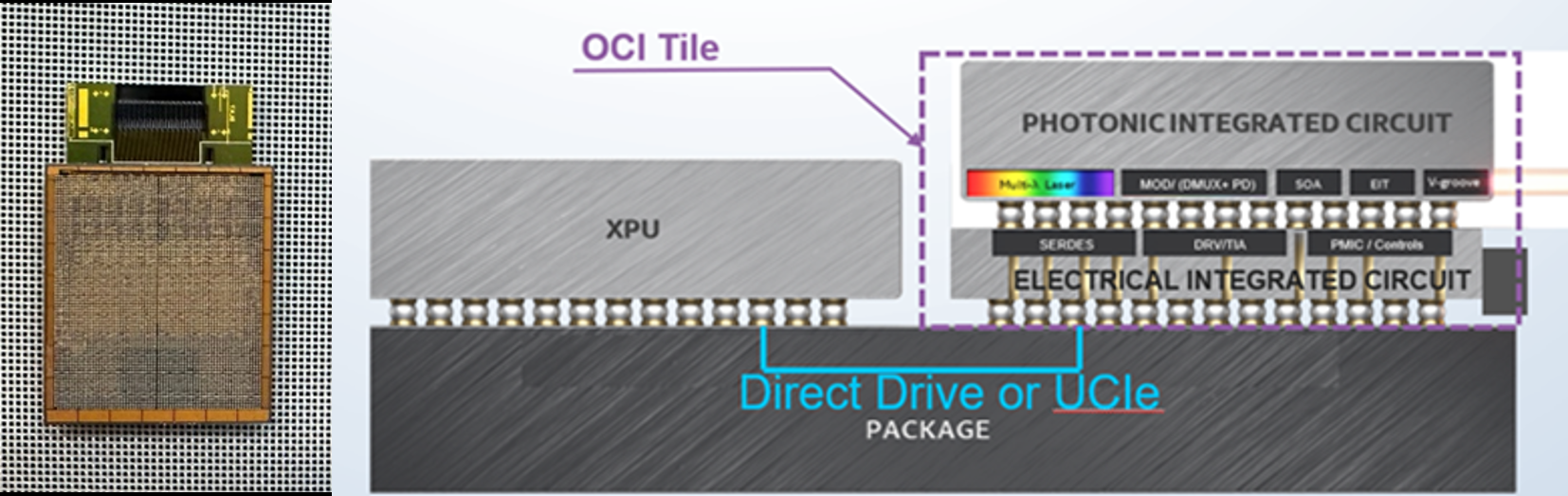 Вкупе с предельной дистанцией до 100 м новый чиплет существенно упростит системы интерконнекта: за редкими исключениями, вроде NVIDIA NVLink или Intel Gaudi 3 с его массивом Ethernet-контроллеров, связь организуется посредством PCIe-адаптера InfiniBand, либо Ethernet, в которые устанавливаются оптические трансиверы. Впрочем, и у PCI Express вскоре появится поддержка оптических подключений, что будет на руку Ultra Accelerator Link (UALink).  В следующем поколении пропускная способность каждой линии OCI возрастёт с 32 до 64 Гбит/с, после чего Intel планирует довести число одновременно используемых длин волн до 16. Затем, в промежутке между 2030 и 2035 годами планируется достигнуть 128 Гбит/с на линию, уже с 16 длинами волн и 16 парами волокон. Но без конкуренции здесь не обойдётся. NVLink, который уже сейчас существенно быстрее (1,8 Тбайт/с в нынешнем поколении), вскоре тоже обзаведётся оптической версией. Похожие решения развивают Celestial AI, MediaTek и Ranovus, Lightmatter и Ayar Labs.
30.05.2024 [23:56], Игорь Осколков
NVLink для экономных — AMD, Intel и другие IT-гиганты объединились для создания UALink и противостояния NVIDIAЛетом прошлого года AMD, Arista, Broadcom, Cisco, Eviden/Atos, HPE, Intel, Meta✴ и Microsoft сформировали консорциум Ultra Ethernet (UEC), призванный составить конкуренцию технологии InfiniBand, которая фактически единолично контролируется NVIDIA после покупки Mellanox, и стандартизировать Ethernet-решения для современных ИИ- и HPC-платформ. А теперь AMD, Broadcom, Cisco, Google, HPE, Intel, Meta✴ и Microsoft сформировали альянс Ultra Accelerator Link (UALink), который должен составить конкуренцию NVLink. К UEC за год присоединились ещё полсотни компаний, кроме, конечно, NVIDIA, которая, впрочем, про Ethernet тоже не забывает, хотя периодически получает критику со стороны Broadcom. Единственной альтернативой в деле построения фабрик для более-менее крупных кластеров остаётся Omni-Path Express, развиваемый Cornelis Networks, которая тоже присоединилась к UEC, но доля этой технологии на фоне Ethernet и InfiniBand мизерная. Кроме того, ни одна из этих технологий не может предложить то, что может NVIDIA NVLink — возможность напрямую объединить сотни ускорителей (точнее, их память) сверхбыстрым соединением с низким уровнем задержки. 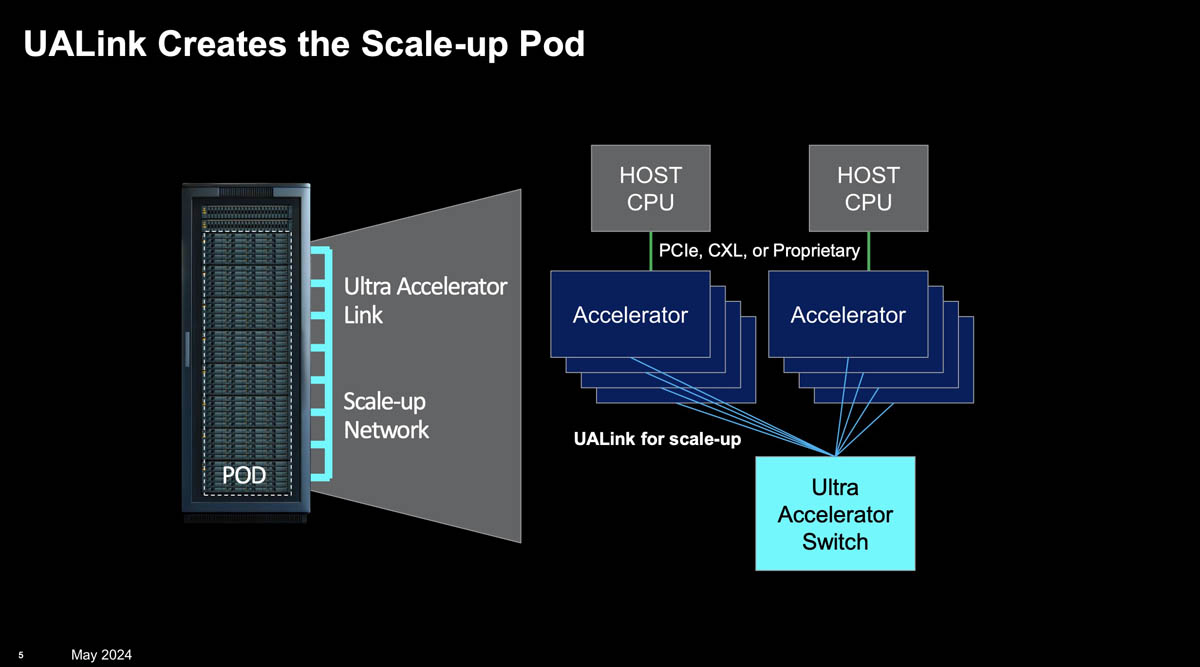
Источник изображений: UALink via ServeTheHome NVLink 4 достиг скорости 900 Гбайт/с на ускоритель и впервые вышел за пределы узла, позволив объединить в домен до 256 ускорителей, что NVIDIA и предложила в рамках DGX SuperPod H100. NVLink 5 удвоил пропускную способность до 1,8 Тбайт/с и теоретически позволит объединить до 576 ускорителей в одном домене. Именно NVLink позволил создать высокоплотные суперускорители GH200 NVL32 и GB200 NVL72. И именно их NVIDIA считает минимальной эффективной единицей кластеров ближайшего будущего, предлагая крупным заказчикам на меньшее даже не размениваться.  Intel в семействе Gaudi использует Ethernet (1,2 Тбайт/с на ускоритель) как для вертикального, так и для горизонтального масштабирования. AMD же полагается на Infinity Fabric (896 Гбайт/с на ускоритель) на базе PCIe и xGMI, которые до недавнего времени за пределы узла не выходили. Однако в конце 2023 года было объявлено, что в 2025 году AMD и Broadcom выпустят коммутатор на базе PCIe 7.0 (стандарт планируют только-только утвердить в этом же году), который будет поддерживать технологию, которая теперь называется AFL (Accelerated Fabric Link) — это и будет выходом Infinity Fabric за пределы узла.  И именно совместными наработками AMD и Broadcom поделятся в рамках UALink. Первую версию нового интерконнекта альянс обещает представить уже в III квартале 2024 года, а в IV квартале — версию 1.1. При этом пока прямо не говорится, будет ли основным транспортом PCIe или Ethernet, и какой протокол будет использоваться для работы с памятью. Но уже обещано, что UALink 1.0 позволит объединить до 1024 ускорителей в одном домене с возможностью прямых load/store-запросов к их памяти. Для дальнейшего масштабирования кластеров по-прежнему предлагается использовать Ultra Ethernet.  При этом UALink, строго говоря, не обещает возможности беспрепятственного общения ускорителей разных вендоров, зато позволяет упростить инфраструктуру и сделать её дешевле благодаря открытости и конкуренции. Хотя было бы приятно увидеть UALink в качестве аппаратной основы и для стандарта UXL, который намерен побороться с NVIDIA CUDA. Что касается CXL, то этот стандарт, тоже использующий PCIe в качестве транспорта, вероятно, останется «привязанным» к CPU и внутриузловым коммуникациям, хотя возможности его гораздо шире.
01.05.2024 [17:00], Сергей Карасёв
Внутри и снаружи: PCI-SIG обнародовала спецификации кабелей CopprLink для PCIe 5.0/6.0Организация PCI Special Interest Group (PCI-SIG) обнародовала спецификации электрических кабелей и разъёмов CopprLink для внешних и внутренних подключений PCIe 5.0/6.0. Новые соединения на основе меди позволят заменить существующие кабели OCuLink в тех случаях, когда требуется более высокая пропускная способность. Стандарт CopprLink был анонсирован в конце 2023 года. Кабели данного типа обеспечат высокоскоростные подключения в пределах отдельных систем, а также между различными узлами в составе стойки. Кроме того, как отмечалось ранее, разрабатываются варианты для межстоечного соединения. Спецификация CopprLink для внутренних подключений:

Источник изображений: PCI-SIG Спецификация CopprLink для внешних подключений:
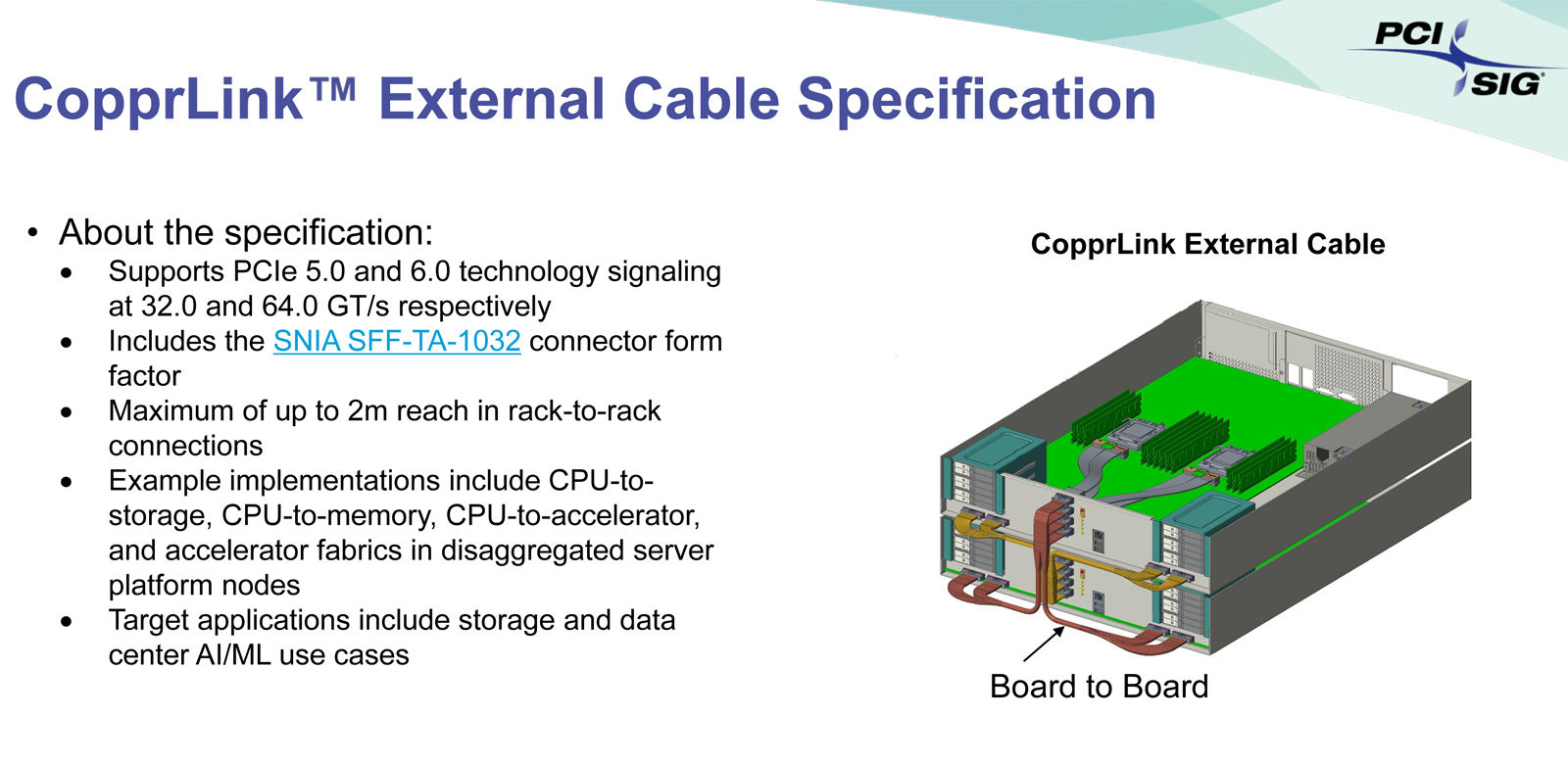 Отмечается, что в дальнейшем кабели CopprLink будут развиваться с учётом возможностей интерфейса PCIe следующих поколений. Технология CopprLink, как ожидается, будет востребована в сферах, где необходимы небольшие задержки, включая дата-центры, производительные СХД, сети и пр. В будущем ожидается появление оптических кабелей PCIe. 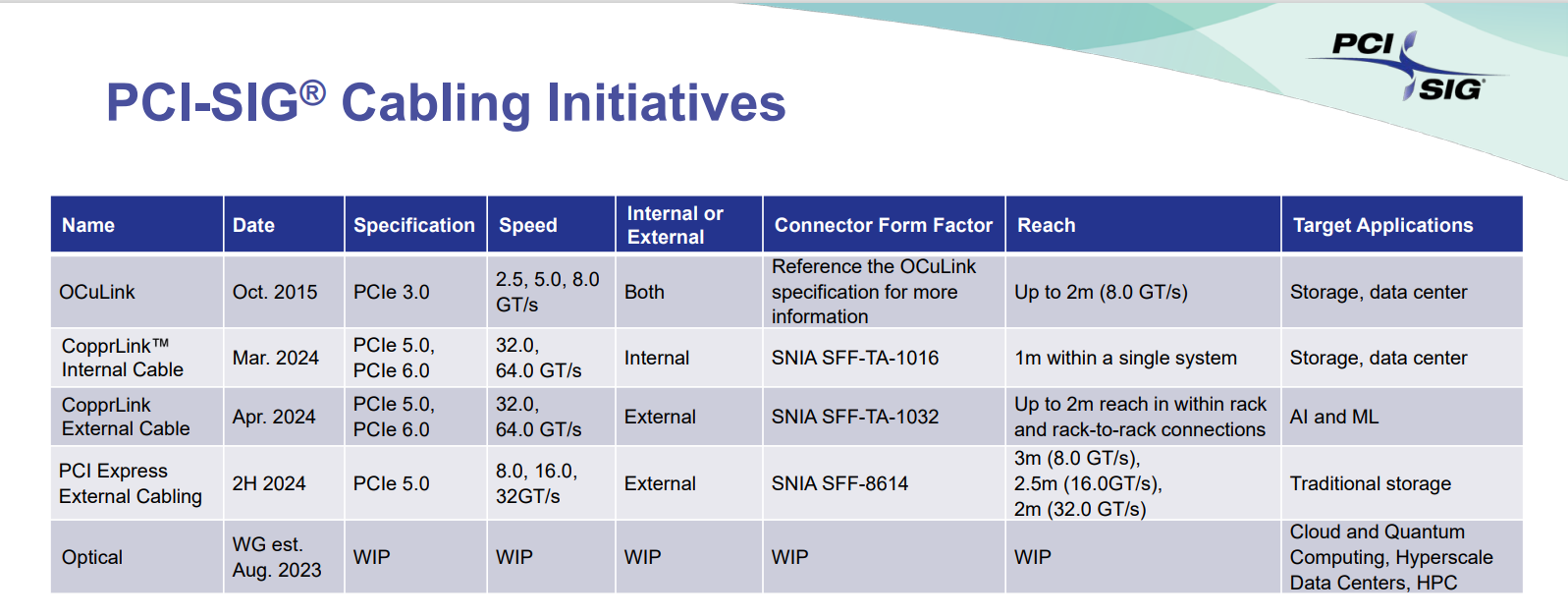
27.03.2024 [23:40], Сергей Карасёв
Coherent представила оптические коммутаторы для дата-центров, ориентированных на задачи ИИCoherent анонсировала специализированные оптические коммутаторы для ИИ-кластеров высокой плотности. В основу устройств Optical Circuit Switch (OCS) положена фирменная платформа кросс-коммутации Lightwave Cross-Connect (DLX). В изделиях, в отличие от традиционных коммутаторов, не применяются приемопередатчики для преобразования фотонов в электроны и обратно. Вместо этого все операции осуществляются в оптическом тракте: импульсы поступают в один порт и выходят из другого (конечно, с небольшим ослаблением). Coherent выделяет несколько ключевых преимуществ своей технологии. Прежде всего значительно возрастает производительность, что важно при решении ресурсоёмких задач, связанных с приложениями ИИ. Кроме того, благодаря отказу от преобразования среды сокращаются энерозатраты. Наконец, отпадает необходимость в обновлении собственно коммутаторов при установке в ЦОД оборудования следующего поколения. Это значительно повышает окупаемость капитальных затрат. 
Источник изображения: Coherent Представленное решение насчитывает 300 входных и 300 выходных оптических портов. Коммутаторы OCS помогают решить проблемы масштабируемости и надёжности дата-центров, ориентированных на приложения ИИ. Аналитики Dell'Oro Group отмечают, что для ИИ-задач требуется более высокий уровень отказоустойчивости, нежели для традиционных приложений. Крайне важно, чтобы коммутаторы, используемые в составе ИИ-платформ, не провоцировали никаких перебоев во время обучения или эксплуатации больших языковых моделей. Устройства Coherent, как сообщается, обеспечивают необходимый уровень надёжности. Массовые поставки новых коммутаторов планируется организовать в 2025 году. При этом Google уже использует в своих дата-центрах оптические коммутаторы (OCS) собственной разработки на базе MEMS-переключателей для формирования ИИ-кластеров, а Meta✴ совместно с MIT разработала систему TopoOpt, представляющую собой оптическую патч-панель с манипулятором, который позволяет менять топологию сети.
22.03.2024 [21:10], Сергей Карасёв
Консорциум Ultra Ethernet пополнился 45 участниками, но NVIDIA среди них так и нетКонсорциум Ultra Ethernet объявил о том, что в его состав вошли 45 новых участников. Таким образом, на сегодняшний день общее количество членов этой организации достигает 55. К участию в Ultra Ethernet приглашаются и другие заинтересованные компании и институты. Напомним, консорциум был создан в июле 2023 года. Его задача заключается в разработке основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Изначально в состав Ultra Ethernet входили AMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft. Позднее к консорциуму присоединилась компания Cornelis Networks, поставщик HPC-интерконнекта на базе Omni-Path. 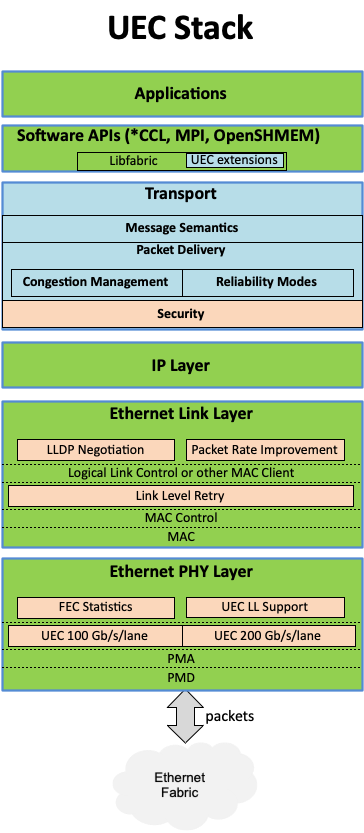
Источник изображения: Ultra Ethernet С ноября 2023-го организация начала принимать новых участников в массовом порядке. С тех пор инициативу поддержали Nokia, Lenovo, Baidu, Dell, Huawei, IBM, Supermicro, Tencent и многие другие компании. Примечательно, что в списке участников так и нет AWS, Google и NVIDIA. Последняя по-прежнему считает InfinBand лучшим интерконнектом для HPC/ИИ-кластеров и является фактически единственным поставщиком данной технологии. Более того, даже Ethernet-решения NVIDIA подвергаются критике со стороны конкурентов. 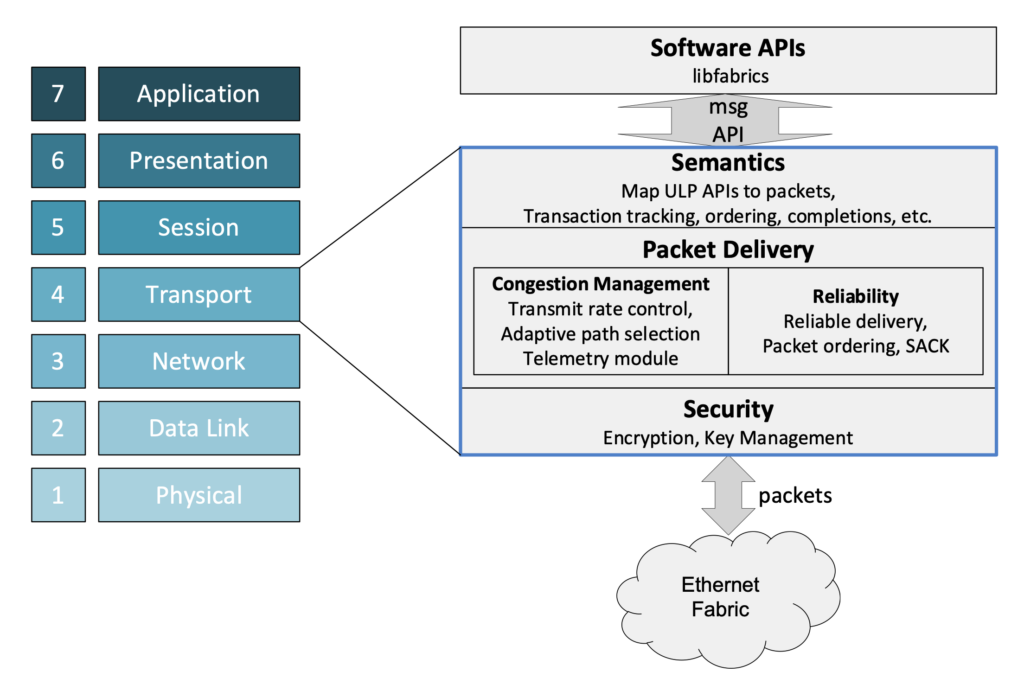
Источник изображения: Ultra Ethernet Для тех, кто заинтересован в работах в рамках проекта, Ultra Ethernet предлагает различные варианты участия через восемь технических групп. В их число, в частности, входят физический, транспортный и программный уровни, хранение, управление, отладка и пр. В настоящее время ведётся активная работа над спецификацией Ultra Ethernet версии 1.0: представить её планируется в III квартале текущего года. Ожидается, что совместная работа десятков IT-компаний в перспективе позволит создать революционные коммуникационные платформы.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
08.03.2024 [00:03], Алексей Степин
Broadcom готовит чипы для PCIe 6.0/7.0 с поддержкой AMD Infinity FabricОдним из столпов, на которых зиждется господство NVIDIA в мире ускорителей, является NVLink — высокоскоростной интерконнект, позволяющий чипам общаться напрямую не только в составе одного узла, но и за его пределами. AMD пытается ответить на это продвижением XGMI/Infinity Fabric, и в предварительном обзоре Instinct MI300 были затронуты вопросы топологии серверов в исполнении «красных». Ещё тогда, в момент анонса MI300, компания Broadcom объявила о поддержке данного интерконнекта в будущих поколениях своих PCIe-коммутаторов, а сейчас ресурс ServeTheHome поделился новыми подробностями. XGMI действительно станет коммутируемым, что упростит масштабирование систем на базе ускорителей AMD Instinct. Интерконнект получил официально название AFL (Accelerated Fabric Link). В основе AFL по-прежнему будет лежать PCI Express, в данном случае речь идёт уже о PCI Express 7.0. Поддержка данной технологии дебютирует в PCIe-коммутаторах Broadcom Atlas 4. В дополнение к ним будут выпущены и новые ретаймеры Vantage 7, которые также получат поддержку CXL 4.0. 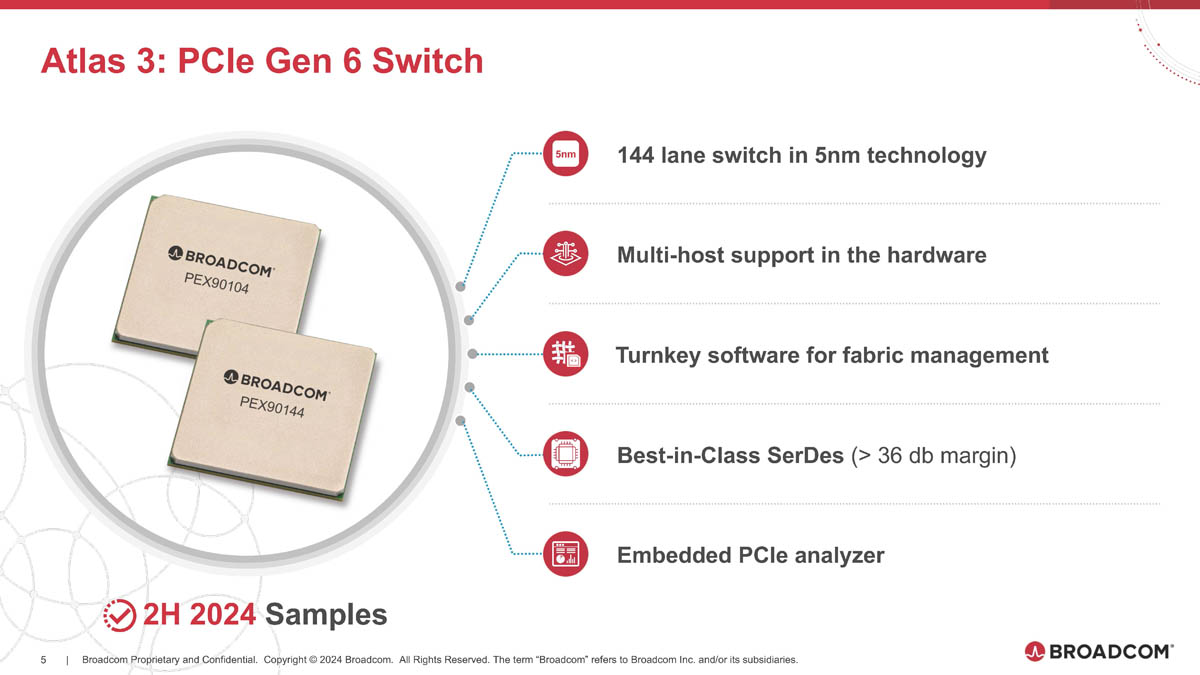
Источник здесь и далее: Broadcom via ServeTheHome Но перед этим Broadcom начнёт поставки образцов чипов-коммутаторов Atlas 3 со 144 линиями PCIe 6.0 во II половине 2024 года, а серверы с такими коммутаторами появятся в 2025 году. Поддержка CXL здесь будет расширена до версии 3.1.  Что касается ретаймеров, то здесь Broadcom уже нанесла ответный удар Astera Labs, анонсировав чипы серий Vantage 5 и Vantage 6 для экосистем PCI Express 5.0 и PCI Express 6.0 соответственно. Они будут выпускаться в вариантах с 8 и 16 линиями с опцией бифуркации и поддержкой CXL 2.0 и 3.1. Broadcom заявляет о более низком энергопотреблении, достигнутом за счёт применения 5-нм техпроцесса, лучших в индустрии блоках SerDes и расширенных средствах диагностики, интегрированных в новые ретаймеры. 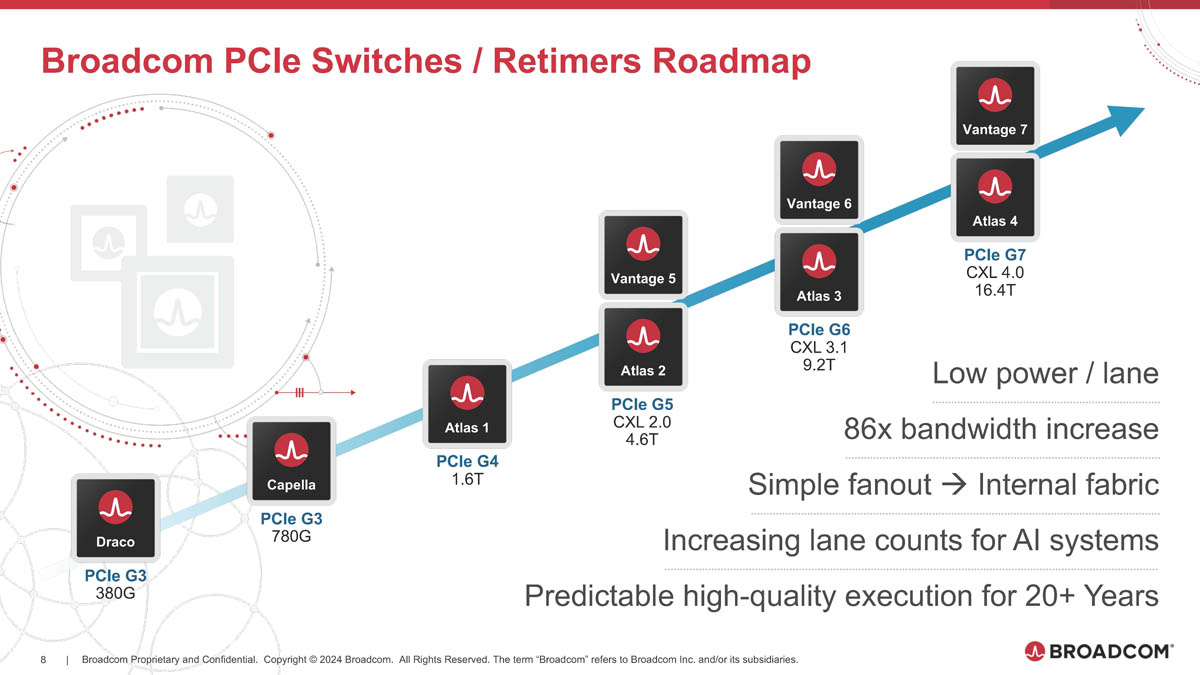 Экономичность здесь играет важную роль: хотя даже 7-нм ретаймер потребляет немного, таких микросхем в составе каждого GPU-сервера несколько, что при дальнейшем масштабировании выливается весьма серьёзные цифры. К тому же меньшая нагрузка ляжет и на систему охлаждения, ведь если CPU и ускорители могут обслуживаться СЖО, то остальные компоненты в таких серверах по-прежнему охлаждаются обычными вентиляторами.  Что касается SerDes-блоков, то они позволят на 40 % удлинить соединения при сохранении стабильной работы. Ну а наличие продвинутого диагностического программного обеспечения с расширенными возможностями упростит разработку, отладку и ремонт систем нового поколения.  Ретаймеры Vantage 5 будут использоваться в комплекте с коммутаторами Atlas 2 в решениях Broadcom уже сегодня, они обеспечат поддержку CXL 2.0, ну а системы с Vantage 6 и поддержкой CXL 3.1, как уже упоминалось, должны увидеть свет в следующем году.  Astera Labs есть о чём беспокоиться: если на данный момент её ретаймерам почти нет альтернативы, то уже в ближайшем будущем ситуация может коренным образом измениться, поскольку Broadcom явно осознала всю важность этого компонента в экосистеме PCI Express и оценила солидный объём потенциальной клиентской базы.
09.08.2023 [18:28], Алексей Степин
Lightelligence представила оптический CXL-интерконнект PhotowaveКомпания Lightelligence, специализирующаяся в области фотоники и оптических вычислений, анонсировала любопытную новинку — систему оптического интерконнекта для ЦОД нового поколения. Решение под названием Photowave реализовано на базе стандарта CXL и призвано упростить и сделать более надёжными системы с композитной инфраструктурой, заменив традиционные медные кабели оптоволокном. Решение Photowave — дальнейшее развитие парадигмы Lightelligence, уже представившей ранее первый оптический ускоритель Hummingbird для ИИ-систем. Сердцем Photowave является оптический трансивер oNET на базе фирменных технологий компании. Согласно заявлениям Lightelligence, уровень задержки составляет менее 20 нс на уровне адаптера, кабель добавляет к этой цифре менее 1 нс. 
Источник изображений здесь и далее: Lightelligence Серия Photowave включает в себя трансиверы в разных форм-факторах — как в виде традиционной платы расширения PCI Express, так и в виде карты OCP 3.0 SFF. Платы трансиверов поддерживают CXL 2.0/PCIe 5.0 с числом линий от 2 до 16. Пропускная способность каждой линии составляет 32 Гбит/с.  Как уже упоминалось, главная задача Photowave — создание эффективных и надёжных композитных инфраструктур в ЦОД нового поколения, где благодаря всесторонней поддержки CXL будет достигнута высокая степень дезагрегации вычислительных ресурсов, а также памяти и хранилищ.
02.08.2023 [18:00], Сергей Карасёв
Светлое будущее: у PCIe появится версия с оптическими соединениями — создана рабочая группа для разработки технологииКонсорциум PCI-SIG объявил о формировании рабочей группы PCI-SIG Optical Workgroup, которая займётся реализацией интерфейса PCI Express (PCIe) по оптическим соединениям. Это, как ожидается, станет важным этапом развития соответствующей экосистемы. Внедрение оптических соединений для PCIe по сравнению с существующими решениями обеспечит более высокую пропускную способность, пониженное энергопотребление, увеличенную дальность действия и меньшие задержки. 
Источник изображения: pixabay.com Новая технология, как ожидается, будет востребована в облачных дата-центрах, системах НРС и на площадках гиперскейлеров. Речь идёт о создании системы, поддерживающей широкий спектр оптических технологий. Консорциум PCI-SIG призывает всех своих участников присоединиться к Optical Workgroup, поделиться опытом и помочь определить конкретные цели рабочей группы и требования к аппаратным компонентам. Новая рабочая группа сосредоточит усилия над тем, чтобы сделать архитектуру PCIe более подходящей для оптических сетей. Между тем, как отмечается, продолжаются работы над спецификацией PCIe 7.0, которая предусматривает увеличение производительности до 128 ГТ/с по одной линии.
20.07.2023 [23:30], Игорь Осколков
AMD, Broadcom, Cisco, Intel и другие вендоры создадут интерконнект Ultra Ethernet для HPC и ИИAMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft в рамках Linux Foundation сформировали новый консорциум Ultra Ethernet Consortium, который намерен создать на базе Ethernet новый масштабируемый и эффективный с точки зрения стоимости коммуникационный стек, ориентированный на высокопроизводительные вычисления (HPC) и ИИ. Иными словами, речь идёт о создании спецификаций интерконнекта нового поколения на базе Ethernet для современных кластеров, облаков и иных платформ. UEC сформировал четыре рабочих группы, ответственных за физический, канальный и транспортный уровни, а также за уровень ПО. Целью же является создание современного сетевого стека, который учитывает потребности HPC- и ИИ-нагрузок, включая новые методы борьбы с заторами в сети, высокий уровень утилизации канала (в том числе 800G/1.6T), многопутевую и гарантированную доставку, сквозную телеметрию, консистентность и низкий уровень задержек, автоматизацию, безопасность и защищённость, масштабируемость, стабильность, надёжность, снижение TCO и так далее. 
Источник: Ultra Ethernet Consortium Фактически отдельные вендоры уже наделили рядом перечисленных свойств свои продукты, однако унификация и объединение усилий, как считается, должны пойти на пользу всем. Всем, кроме, по-видимому, NVIDIA, которой в списке основателей UEC нет (как и Marvell, к слову). NVIDIA после поглощения Mellanox фактически стала монополистом на рынке InfiniBand, который она активно продвигает, не забывая, впрочем, и о своём проприетарном интерконнекте NVLink, который в последней своей версии выбрался за пределы узла. Справедливости ради — про Ethernet компании тоже не забывает. В обзоре UEC аккуратно критикуется и InfiniBand, и его адаптация в виде RoCE. Авторы указывают на правильность и успешность идеи RDMA, но жалуются на не слишком высокую практичность и удобство современных реализаций. И именно поэтому они первым делом предлагают внедрить новый транспортный протокол Ultra Ethernet Transport (UET), который и позволит реализовать интерконнект будущего, а заодно ещё раз доказать эффективность и гибкость технологии Ethernet, которой в этом году исполнилось 50 лет. Впрочем, это только один из кирпичиков UEC. Примечательно, что первые продукты на базе новых спецификаций обещали показать уже в 2024 году. |
|


{kind=link}