Материалы по тегу: интерконнект
|
28.02.2025 [12:35], Сергей Карасёв
Broadcom представила новые решения PCIe 6.0 — чип-коммутатор и ретаймерыВ марте прошлого года Astera Labs анонсировала чипы Aries 6 для PCIe 6.0. Теперь компания Broadcom объявила о доступности собственных решений PCIe 6.0: дебютировали чип-коммутатор PEX 90144, а также ретаймеры BCM85668 и BCM85667. Отмечается, что изделия с поддержкой PCIe 6.0 являются «критически важными высокопроизводительными строительными блоками», необходимыми для развёртывания передовой инфраструктуры ИИ. В тестировании продуктов приняли участие такие компании, как Micron и Teledyne LeCroy. 
Источник изображений: Broadcom Ретаймеры BCM85668 и BCM85667 поддерживают соответственно 8 и 16 линий PCIe 6. При производстве применяется 5-нм технология. Говорится об обратной совместимости с PCIe поколений 5/4/3/2/1, а также о совместимости с Compute Express Link (CXL 3.1). Возможна работа в режимах 64, 32, 16, 8, 5 и 2,5 GT/s (млрд пересылок в секунду). Изделие BCM85668 поддерживает бифуркацию x8, 2 x4 и 4 x2. В случае BCM85667 возможны конфигурации 1 x16, 4 x4 и 8 x2. Заявлена поддержка режимов с низким энергопотреблением и проприетарных режимов с малой задержкой (LL).  Чип-коммутатор PEX 90144, в свою очередь, имеет 144 линии. Изделие предназначено для координации потоков трафика. Полностью технические характеристики на данный момент не раскрываются. Год назад также упоминались чипы PEX 90104 и говорилось о разработке коммутаторов PCI Express 7.0 с поддержкой AMD AFL (Accelerated Fabric Link), коммутируемого варианта Infinity Fabric.
17.02.2025 [17:42], Руслан Авдеев
Исследователи DeepMind предложили распределённое обучение больших ИИ-моделей, которое может изменить всю индустриюПосле того, как ИИ-индустрия немного отошла от шока, вызванного неожиданным триумфом китайской DeepSeek, эксперты пришли к выводу, что отрасли, возможно, придётся пересмотреть методики обучения моделей. Так, исследователи DeepMind заявили о модернизации распределённого обучения, сообщает The Register. Недавно представившая передовые ИИ-модели DeepSeek вызвала некоторую панику в США — компания утверждает, что способна обучать модели с гораздо меньшими затратами, чем, например, OpenAI (что оспаривается), и использованием относительно небольшого числа ускорителей NVIDIA. Хотя заявления компании оспариваются многими экспертами, индустрии пришлось задуматься — насколько эффективно тратить десятки миллиардов долларов на всё более масштабные модели, если сопоставимых результатов можно добиться в разы дешевле, с использованием меньшего числа энергоёмких ЦОД. Дочерняя структура Google — компания DeepMind опубликовала результаты исследования, в котором описывается методика распределённого обучения ИИ-моделей с миллиардами параметров с помощью удалённых друг от друга кластеров при сохранении необходимого уровня качества обучения. В статье «Потоковое обучение DiLoCo с перекрывающейся коммуникацией» (Streaming DiLoCo with overlapping communication) исследователи развивают идеи DiLoCo (Distributed Low-Communication Training или «распределённое обучение с низким уровнем коммуникации»). Благодаря этому модели можно будет обучать на «островках» относительно плохо связанных устройств. 
Источник изображения: Igor Omilaev/unsplash.com Сегодня для обучения больших языковых моделей могут потребоваться десятки тысяч ускорителей и эффективный интерконнект с большой пропускной способностью и низкой задержкой. При этом расходы на сетевую часть стремительно растут с увеличением числа ускорителей. Поэтому гиперскейлеры вместо одного большого кластера создают «острова», скорость сетевой коммуникации и связность внутри которых значительно выше, чем между ними. DeepMind же предлагает использовать распределённые кластеры с относительно редкой синхронизацией — потребуется намного меньшая пропускная способность каналов связи, но при этом без ущерба качеству обучения. Технология Streaming DiLoCo представляет собой усовершенствованную версию методики с синхронизацией подмножеств параметров по расписанию и сокращением объёма подлежащих обмену данных без потери производительности. Новый подход, по словам исследователей, требует в 400 раз меньшей пропускной способности сети. 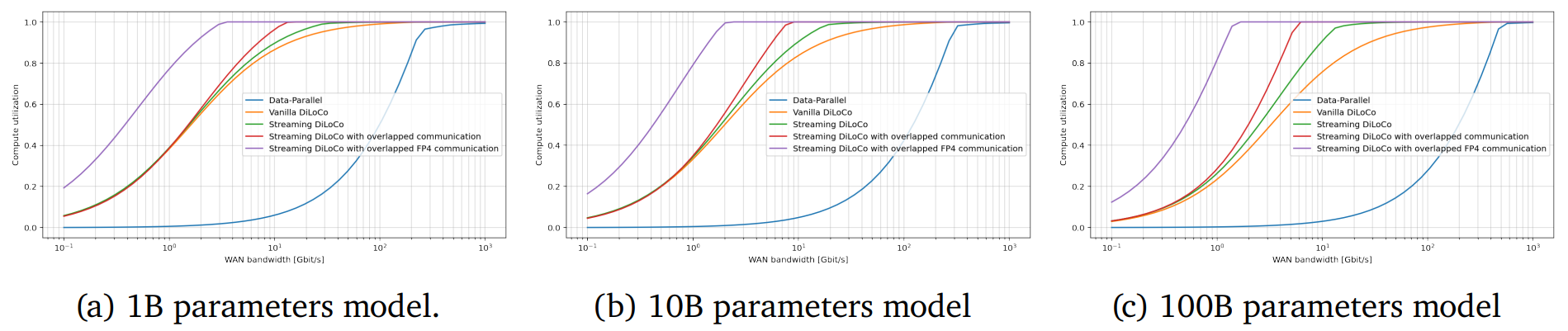
Источник изображения: DeepMind Важность и потенциальную перспективность DiLoCo отмечают, например, и в Anthropic. В компании сообщают, что Streaming DiLoCo намного эффективнее обычного варианта DiLoCo, причём преимущества растут по мере масштабирования модели. В результате допускается, что обучение моделей в перспективе сможет непрерывно осуществляться с использованием тысяч разнесённых достаточно далеко друг от друга систем, что существенно снизит порог входа для мелких ИИ-компаний, не имеющих ресурсов на крупные ЦОД. В Gartner утверждают, что методы, уже применяемые DeepSeek и DeepMind, уже становятся нормой. В конечном счёте ресурсы ЦОД будут использоваться всё более эффективно. Впрочем, в самой DeepMind рассматривают Streaming DiLoCo лишь как первый шаг на пути совершенствования технологий, требуется дополнительная разработка и тестирование. Сообщается, что возможность объединения многих ЦОД в единый виртуальный мегакластер сейчас рассматривает NVIDIA, часть HPC-систем которой уже работает по схожей схеме.
15.01.2025 [11:24], Владимир Мироненко
В совет директоров UALink вошли представители Alibaba, Apple и SynopsysКонсорциум Ultra Accelerator Link (UALink) объявил о расширении состава совета директоров представителями Alibaba Cloud, Apple и Synopsys. Новые члены совета будут использовать свои отраслевые знания для продвижения разработки и внедрения в отрасли UALink — высокоскоростного масштабируемого интерконнекта для производительных ИИ-кластеров следующего поколения, указано в пресс-релизе. Фактически UALink занят созданием более открытой альтернативы NVLink. С момента основания в конце октября 2024 года количество участников UALink выросло до более чем 65 компаний, сообщил Куртис Боуман (Kurtis Bowman), председатель совета директоров UALink. Новые участники совета директоров заявили, что совместная работа над интерконнектом для ускорителей будет способствовать повышению эффективности выполнения рабочих нагрузок ИИ. Представитель Apple отметил, что UALink демонстрирует большие перспективы в решении проблем подключения и создании новых возможностей ИИ-индустрии. В консорциум входит широкий круг компаний, от поставщиков облачных услуг и OEM-производителей до разработчиков ПО и полупроводниковых компонентов во главе с AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft, представляющих основные области разработки решений для повышения производительности нагрузок ИИ. 
Источник изображения: UALink Ожидается, что выпуск спецификации UALink 1.0 состоится в I квартале 2025 года. Она предусматривает пропускную способность до 200 Гбит/с на линию и возможность объединения до 1024 ИИ-ускорителей в пределах одного домена.
16.12.2024 [11:19], Сергей Карасёв
Раскрыты характеристики сетевых устройств Eviden с технологией BXI v3В ноябре текущего года компания Eviden (дочерняя структура Atos) представила интерконнект третьего поколения BullSequana eXascale Interconnect (BXI v3) для рабочих нагрузок ИИ и HPC. Теперь, как сообщает ресурс Next Platform, раскрыты некоторые характеристики устройств с поддержкой данной технологии. BXI v3 в качестве базового протокола связи использует Ethernet. Технология BXI v3 ляжет в основу интеллектуального сетевого адаптера (Smart NIC) и соответствующего коммутатора. Говорится, что для изготовления чипов ASIC с поддержкой BXI v3 компания Eviden рассматривает возможность применения 3-нм или 4-нм методики TSMC. Коммутатор BXI v3 располагает 64 портами, работающими на скорости 800 Гбит/с. Их можно переконфигурировать в 128 портов с пропускной способностью 400 Гбит/с. В свою очередь, адаптер Smart NIC функционирует на скорости 400 Гбит/с. Он будет предлагаться в виде двухслотовой карты расширения PCIe или OCP-3 (с интерфейсом PCIe 5.0). Возможны варианты адаптеров с двумя портами 400 Гбит/с. Карта BXI v3 способна управлять пакетами объёмом до 9 Мбайт, что полезно в нагруженных инфраструктурах ИИ. 
Источник изображения: Eviden Платформа BXI v3 поддерживает топологии fat tree и dragonfly+, а также fat tree с оптимизацией маршрутов (используется при обучении больших языковых моделей). Для BXI v3 заявлена поддержка до 64 тыс. конечных точек, а задержка составляет менее 200 нс от порта к порту. Изделия с поддержкой BXI v3 поступит в продажу в 2025 году. Осенью 2027 года ожидается появление интерконнекта BXI v4, который предусматривает повышение пропускной способности портов на сетевых картах и коммутаторах до 1,6 Тбит/с. При этом сетевые адаптеры получат поддержку интерфейса PCIe 6.0. В 2029-м планируется переход на интерконнект BXI v5: он обеспечит скорость портов на коммутаторах до 3,2 Тбит/с, тогда как сетевые адаптеры продолжат работать на скоростях до 1,6 Тбит/с, но получат поддержку PCIe 7.0.
27.11.2024 [17:31], Владимир Мироненко
Китайцы создали Ethernet для ИИ- и HPC-кластеровНа прошлой неделе китайские технологические гиганты объявили о выпуске чипа для поддержки технологии Global Scheduling Ethernet, предназначенной для сетевого протокола, который должен обеспечить запуск приложений ИИ и других требовательных рабочих нагрузок, сообщил ресурс The Register. Как полагает ресурс, China Mobile является движущей силой этой технологии, поскольку ещё в 2023 году она опубликовала описание технической структуры GSE Ethernet. Цель китайского проекта совпадает с задачей, поставленной консорциумом Ultra Ethernet Consortium (UEC) — оптимизировать Ethernet для приложений ИИ и HPC. В UEC входят Intel, AMD, HPE, Arista, Broadcom, Cisco, Meta✴ и Microsoft. Протокол Ethernet создавался без учёта сегодняшних рабочих нагрузок и при его использовании сложно организовать пути для трафика, перемещающегося по очень большим и загруженным сетям, что приводит к высоким задержкам. 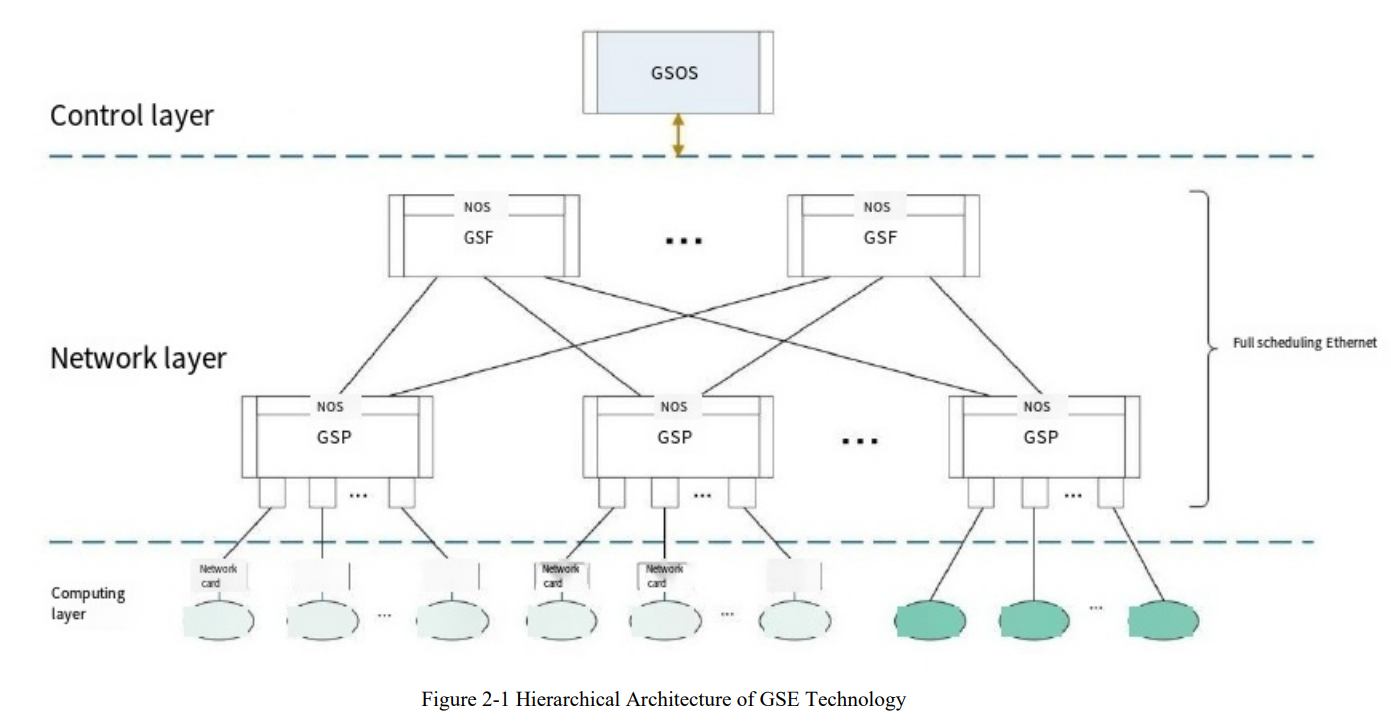
Источник изображения: China Mobile Communications Research Institute В «Белой книге» China Mobile указаны похожие задачи, которые возможно решить с помощью таких методов, как контейнеры пакетов фиксированного размера и «динамическая глобальная очередь планирования», которая не привязана к физическим портам, но учитывает состояние порта целевого устройства перед организацией оптимального соединения с использованием таких способов, как многопутевая доставка (multi-path spraying). Кстати, UEC тоже считает перспективным этот способ. На прошлой неделе китайские СМИ сообщили, что в разработке чипа, который делает GSE Ethernet реальностью, участвовало более 50 провайдеров облачных услуг, производителей оборудования, производителей микросхем и университетов внутри и за пределами Китая. Согласно сообщениям, можно предположить, что GSE Ethernet уже развёрнут в кластере из тысячи серверов в ЦОД China Mobile, где он, по-видимому, обеспечил существенное улучшение производительности сети во время обучения большой языковой модели. Если Китай решил создать и использовать собственную версию Ethernet для некоторых приложений — и его крупные технологические компании готовы её применять — это означает, что членам UEC будет сложнее ориентироваться на китайский рынок (и страны, где доминируют китайские поставщики), пишет The Register. А несколько лет назад Huawei предложила отказаться от TCP/IP в пользу разработанного ей стека New IP.
23.11.2024 [12:38], Сергей Карасёв
Стартап Enfabrica выпустил чип ACF SuperNIC для ИИ-кластеров на базе GPUКомпания Enfabrica, занимающаяся разработкой инфраструктурных решений в сфере ИИ, объявила о доступности чипа Accelerated Compute Fabric (ACF) SuperNIC, предназначенного для построения высокоскоростных сетей в рамках кластеров ИИ на основе GPU. Кроме того, стартап провёл очередной раунд финансирования. Напомним, Enfabrica предлагает CXL-платформу ACF на базе ASIC собственной разработки, которая позволяет напрямую подключать друг к другу любую комбинацию GPU, CPU, DDR5 CXL и SSD, а также предоставляет 800GbE-интерконнект. Утверждается, что ACF SuperNIC может обеспечить улучшенную масштабируемость и производительность с более низкой совокупной стоимостью владения для распределённых рабочих нагрузок ИИ по сравнению с другими решениями, доступными на рынке. Изделие ACF SuperNIC (ACF-S) позволяет использовать от четырёх до восьми самых современных ускорителей в расчёте на серверную систему. Чип обеспечивает поддержку 800GbE, 400GbE и 100GbE, 32 сетевых портов и 160 линий PCIe. Благодаря этому становится возможным формирование ИИ-кластеров, насчитывающих более 500 тыс. GPU. 
Источник изображения: Enfabrica Программный стек ACF-S поддерживает стандартные коммуникационные и сетевые операции RDMA через набор библиотек, совместимых с существующими интерфейсами. Фирменная технология Resilient Message Multipathing (RMM) повышает отказоустойчивость кластера ИИ и удобство обслуживания. RMM устраняет простои из-за сбоев и отказов сетевых соединений, повышая эффективность. Функция Collective Memory Zoning обеспечивает снижение задержек. Поставки чипов ACF SuperNIC начнутся в I квартале 2025 года. Что касается нового раунда финансирования, то по программе Series C привлечено $115 млн. Раунд возглавила фирма Spark Capital с участием новых инвесторов — Maverick Silicon и VentureTech Alliance. Кроме того, средства предоставили существующие инвесторы в лице Atreides Management, Sutter Hill Ventures, Alumni Ventures, IAG Capital и Liberty Global Ventures.
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 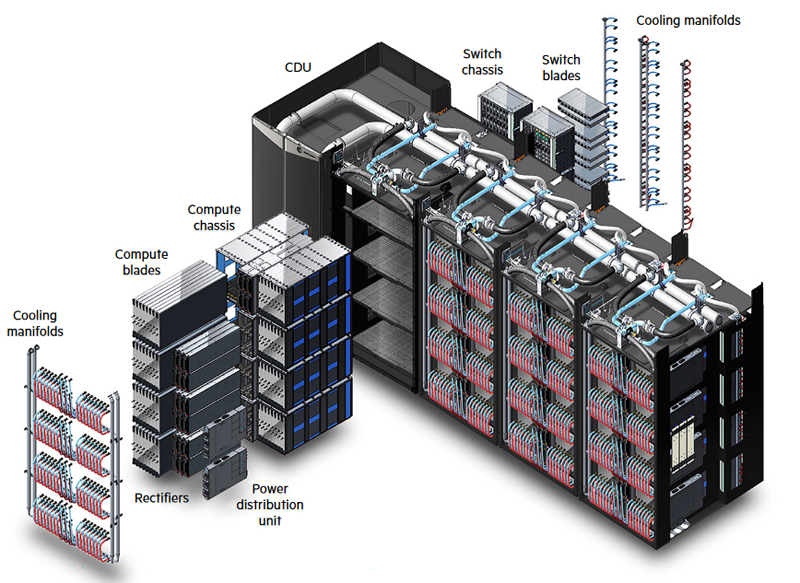 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
15.11.2024 [10:31], Сергей Карасёв
Eviden представила интерконнект BullSequana eXascale третьего поколения для ИИ-системКомпания Eviden (дочерняя структура Atos) анонсировала BullSequana eXascale Interconnect (BXI v3) — интерконнект третьего поколения, специально разработанный для рабочих нагрузок ИИ и HPC. Технология станет доступа на рынке во II половине 2025 года. Отмечается, что существующие высокоскоростные сетевые решения недостаточно эффективны, поскольку не устраняют критическое узкое место, известное как «сетевая стена». По заявлениям Eviden, зачастую при крупномасштабном обучении ИИ компании наращивают количество ускорителей, однако на самом деле ограничивающим фактором является интерконнект. Хотя поставщики сетевых решений продолжают удваивать пропускную способность каждые несколько лет, этого недостаточно для решения проблемы. В результате, до 70 % времени GPU простаивают, ожидая получения данных из-за задержек, утверждает Eviden. Технология BXI v3 призвана устранить этот недостаток. 
Источник изображений: Eviden Новый интерконнект использует стандарт Ethernet в качестве базового протокола связи. При этом реализованы функции, которые обычно характерны для масштабируемых сетей высокого класса, таких как Infiniband. Отмечается, что BXI v3 обеспечивает низкие задержки (менее 200 нс от порта к порту), высокую пропускную способность, упорядоченную (in order) доставку пакетов, расширенное управление перегрузками и масштабируемость. Технология BXI v3 ляжет в основу интеллектуального сетевого адаптера (Smart NIC) нового поколения, который поможет снизить влияние задержек сети на GPU и CPU. При использовании такого решения ускоритель ИИ выгружает данные на сетевой адаптер и сразу же переходит к другим задачам, что устраняет неэффективность, связанную с простоями. Подчёркивается, что протокол BXI v3 интегрируется непосредственно в Smart NIC, благодаря чему оборудование работает сразу после установки, а в приложения не требуется вносить какие-либо изменения.  Кроме того, новая технология предоставляет ряд дополнительных функций, ориентированных на повышение производительности путём оптимизации системных операций и обработки данных. В частности, BXI v3 обеспечивает прозрачную трансляцию виртуальных адресов в физические, что позволяет приложениям напрямую отправлять запросы в SmartNIC с использованием виртуальных адресов без необходимости системных вызовов. Такой подход повышает эффективность, обеспечивая бесперебойное управление памятью при сохранении высокой производительности. Технология BXI v3 также позволяет регистрировать до 32 млн приёмных буферов, которые SmartNIC выбирает с помощью ключей сопоставления на основе атрибутов сообщения. Благодаря этому уменьшается нагрузка на CPU, что повышает общую эффективность системы. Кроме того, сетевой адаптер способен выполнять математические атомарные операции, что дополнительно высвобождает ресурсы CPU. Впрочем, деталей пока мало, зато говорится об участии в консорциуме Ultra Ethernet (UEC) и партнёрстве с AMD.
05.11.2024 [11:17], Сергей Карасёв
Создан консорциум UALink по разработке альтернативы NVIDIA NVLinkВ мае нынешнего года был сформирован альянс Ultra Accelerator Link (UALink) по разработке технологии, призванной составить конкуренцию NVIDIA NVLink. А теперь участники отрасли объявили о создании соответствующего консорциума — UALink Consortium. Новую структуру возглавляют представители AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft. В состав консорциума также входят Cadence, Lenovo, H3C, Centec, Anapass и пр. Кроме того, к участию приглашаются другие заинтересованные стороны. Фактически участники заняты созданием более открытой альтернативы NVLink. 
Источник изображения: UALink «Стандарт UALink определяет высокоскоростную связь с низкими задержками для масштабируемых систем ИИ в дата-центрах. Заинтересованные компании могут присоединиться к консорциуму и поддержать нашу миссию: создание открытого и высокопроизводительного интерконнекта для рабочих нагрузок ИИ», — сказал Вилли Нельсон (Willie Nelson), президент UALink. Отмечается, что компании, входящие в совет консорциума, охватывают широкий спектр отраслей — от поставщиков облачных услуг и OEM-производителей до разработчиков ПО и полупроводниковых компонентов. В I квартале 2025 года планируется представить общедоступную спецификацию UALink 1.0, которая предусматривает пропускную способность до 200 Гбит/с на соединение. В пределах одного домена при этом могут быть объединены до 1024 ускорителей ИИ. Выпуск спецификации UALink 1.0 станет важной вехой, поскольку она определит открытый отраслевой стандарт, позволяющий ускорителям и коммутаторам ИИ взаимодействовать более эффективно. Это откроет новые возможности в плане развития и внедрения крупных ИИ-моделей.
20.10.2024 [11:06], Сергей Карасёв
Стартап Xscape Photonics получил $44 млн на создание фотонных решений для ИИ-дата-центровСтартап Xscape Photonics, создающий решения на основе кремниевой фотоники, вышел из скрытного режима, объявив о проведении раунда финансирования Series A на сумму в $44 млн. Таким образом, как отмечается, общий объём привлечённых компанией средств на сегодняшний день достиг $57 млн. Xscape Photonics была основана в 2022 году. В число её учредителей входят доктора наук и специалисты с опытом работы в области полупроводников в различных компаниях, таких как Broadcom, Cerebras, InPhi, Intel, Juniper, Lumentum, Marvell и Neophotonics. Среди основателей — доктора Вивек Рагхунатхан (Vivek Raghunathan) и Йоши Окавачи (Yoshi Okawachi), а также профессоры Александр Гаэта (Alexander Gaeta), Михал Липсон (Michal Lipson) и Керен Бергман (Keren Bergman). 
Источник изображения: Xscape Photonics Xscape Photonics ставит своей целью решение проблемы ширины полосы пропускания, которая является узким местом платформ для рабочих нагрузок ИИ. Стартап разрабатывает фотонные чипы для организации высокоскоростных соединений в дата-центрах. «Исторически проблемы производительности и масштабируемости при обучении больших языковых моделей решались путём создания более крупных ЦОД. Такой подход является неэффективным и порождает множество дополнительных сложностей, связанных с потреблением энергии и стоимостью. Мы стремимся помочь клиентам полностью переосмыслить то, как они решают эти проблемы», — говорит Рагхунатхан, занимающий пост генерального директора Xscape Photonics. Компания создаёт многоволновую фотонную платформу ChromX, которая позволяет повысить пропускную способность в системах на основе GPU-ускорителей при одновременном снижении энергопотребления. В результате, улучшается общая производительность при выполнении задач инференса. Раунд финансирования Series A проведён под руководством IAG Capital Partners с участием Altair, Cisco Investments, Fathom Fund, Kyra Ventures, LifeX Ventures, NVIDIA и OUP. Деньги будут направлены на ускорение разработки платформы ChromX. |
|

