Материалы по тегу: к
|
12.11.2024 [12:00], Сергей Карасёв
«Рикор» представила российские мини-ПК для бизнеса на платформе Intel Alder LakeКомпания «Рикор» анонсировала компьютеры небольшого форм-фактора Rikor MSK и Rikor Pro для корпоративных клиентов. Устройства, как утверждается, стали первыми серийными мини-ПК, корпус которых полностью произведён в России: это сокращает время поставки, уменьшает стоимость, а также даёт дополнительную гибкость при заказе. В основу новинок положена аппаратная платформа Intel Alder Lake, но позже появится модификация на платформе AMD. Сейчас доступен выбор из процессоров Core i3-12100 (4С/8Т; 3,3–4,3 ГГц; 60 Вт) и Core i5-12400 (6С/12Т; 2,5–4,4 ГГц; 65 Вт). Доступны два слота SO-DIMM для модулей DDR4-3200 суммарным объёмом до 64 Гбайт. 
Источник изображения: «Рикор» Устройства заключены в корпус с габаритами 180 × 178 × 39 мм (объём около 1,25 л). Есть коннектор М.2 для SSD с интерфейсом PCIe 3.0 или SATA-3 и ещё один разъём М.2 для SSD SATA-3. Кроме того, может быть установлен SFF-накопитель SATA-3. В оснащение входят адаптеры Wi-Fi 6 и Bluetooth 5.2, сетевой контроллер 1GbE. Изображение может выводиться одновременно на несколько мониторов через интерфейсы D-Sub, HDMI 1.4b и DisplayPort 1.4. Доступны четыре порта USB 3.2 Gen1 Type-A, два порта USB 3.2 Gen1 Type-С и два порта USB 2.0 Type-A, гнездо RJ-45 для сетевого кабеля и набор аудиогнёзд на 3,5 мм. За питание отвечает внешний блок мощностью 90 Вт. Упомянут модуль ТРМ 2.0. Ключевым преимуществом устройств «Рикор» называет максимальную локализацию производства. Инженеры компании разработали конструкцию объёмом немногим более 1 л, которая, как отмечается, не только не уступает зарубежным аналогам по ключевым характеристикам, но и превосходит их по прочности и лёгкости. Полный цикл производства внутри страны позволяет снизить стоимость устройств благодаря экономии на логистике и материалах, а также ускоряет поставки клиентам.
02.11.2024 [12:04], Руслан Авдеев
ParTec обвинила NVIDIA и Microsoft в нарушении патентов на ИИ-суперкомпьютерыНемецкий разработчик и интегратор HPC-решений ParTec выступил с иском к NVIDIA, обвинив последнюю в нарушении патентных прав. По данным The Register, компания требует запретить продажи ускорителей NVIDIA в 18 странах, участвующих в общей для ЕС патентной системе. ParTec, принимающая участие в создании первой в Европе экзафлопсной машины JUPITER и других суперкомпьютеров вроде MareNostrum5, подтвердила, что предметом спора являются те же самые патенты, из-за которых Partec уже подала иск против Microsoft в США. Впрочем, не исключено, что ParTec намерена добиваться не запрета продаж, а подписания с NVIDIA лицензионного договора — иначе блокировка сбыта в Европе ускорителей NVIDIA может повлиять на реализацию проектов с участием самой ParTec. Оба иска касаются патентов, связанных с динамической модульной системной архитектурой (dMSA). Именно она имеет важнейшее значение для построения высокопроизводительных вычислительных кластеров и обеспечивает оптимальное взаимодействие CPU, GPU и прочей электроники в составе систем, применяемых как для обучения ИИ-моделей, так и для инференса. Ранее в ParTec сообщали, что Microsoft незаконно использовала именно эту интеллектуальную собственность при создании облачной платформы Azure AI. 
Источник изображения: Tingey Injury Law Firm/unsplash.com Иск к NVIDIA ParTec и её лицензионный агент BF exaQC AG подали в Единый патентный суд Евросоюза 27 октября. В ParTec намерены добиваться запрета для NVIDIA распространять свои ускорители в странах Евросоюза, в которых действуют патенты, а также возмещения ущерба. По имеющимся данным, речь идёт о патентах EP2628080 и EP3743812, причём последний действует во всех странах ЕС, являющихся частью Единой патентной системы. Речь идёт о 18 государствах, в том числе Германии, Франции и Италии. Если истцы выиграют суд, продажа ряда продуктов NVIDIA в этих странах будет запрещена. В компании утверждают, что давно предвидели перспективы ПО для масштабирования вычислений, поэтому и занялись разработкой dMSA. Компания также утверждает, что вела переговоры с NVIDIA, продемонстрировав свою модульную архитектуру, ПО ParaStation и ключевые патенты. NVIDIA якобы проявила большой интерес к технологии и даже объявила о готовности разрабатывать суперкомпьютеры с использованием ParaStation, но впоследствии эти планы так и не были реализованы. Сейчас компании так или иначе сотрудничают над созданием других суперкомпьютеров, где NVIDIA выступает «предпочтительным поставщиком» ускорителей для ЦОД. В ParTec заявили, что иск был неизбежен, поскольку NVIDIA отказалась вести переговоры о поставках ускорителей. Последняя якобы поступила так из-за иска ParTec к Microsoft — одного из ключевых клиентов NVIDIA. В ParTec подчёркивают, что благодаря её технологиям Германия и Европа в целом получат возможность развить собственную «суверенную индустрию». Однако мир сегодня зависит от нарушителей патентов, т.е. NVIDIA и Microsoft, распространяющих решения, представляющие угрозу для Германии и европейской IT-индустрии, говорит ParTec.
01.11.2024 [12:31], Сергей Карасёв
ASUS анонсировала мини-компьютеры NUC 14 Essential на платформе Intel Alder Lake-N RefreshКомпания ASUS, по сообщению ресурса CNX-Software, готовит к выпуску компьютеры небольшого форм-фактора NUC 14 Essential, ориентированные на использование в том числе в бизнес-сфере. В основу устройств лягут процессоры поколения Intel Alder Lake-N Refresh, которые пока официально не представлены. В частности, упомянуты версии с чипами Intel Processor N150 (четыре ядра; до 3,6 ГГц; 6 Вт), Intel Processor N250 (четыре ядра; до 3,8 ГГц; 6 Вт) и Core i3-N355 (восемь ядер; до 3,9 ГГц; 15 Вт). Все эти изделия содержат встроенный ускоритель Intel Graphics. Кроме того, будет доступна модификация с чипом Intel Processor N97 (четыре ядра; до 3,6 ГГц; 12 Вт) серии Alder Lake-N. 
Источник изображения: ASUS Габариты NUC 14 Essential составляют 135 × 115 × 36 мм, масса — 470 г. Есть один слот SO-DIMM для модуля DDR5-4800 объёмом до 16 Гбайт. Может быть установлен SSD формата M.2 2280/2242 вместимостью до 2 Тбайт с интерфейсом PCIe 3.0 x4 или SATA-3. В оснащение входят адаптеры Intel Wi-Fi 6E (Gig+) и Bluetooth 5.3, а также сетевой контроллер Realtek RTL8125BG-CG стандарта 2.5GbE и звуковой кодек Realtek ALC3251. Возможен одновременный вывод изображения на три независимых монитора через интерфейсы HDMI 2.1, DisplayPort 1.4 и USB 3.2 Gen2 Type-C (DisplayPort 1.4 alt. Mode). Кроме того, есть ещё один порт USB 3.2 Gen 2 Type-C, четыре порта USB 3.2 Gen2 Type-A, один разъём USB 2.0, гнездо RJ45 для сетевого кабеля, комбинированный аудиоразъём на 3,5 мм и гнездо для блока питания (19 В / 3,42 A).
22.10.2024 [13:28], Руслан Авдеев
VMware выплатит инвесторам $102,5 млн, чтобы избежать дальнейших обвинений в манипуляциях с бухгалерской отчётностьюVMware достигла соглашения с инвесторами, подавшими против неё коллективный иск. По информации Channel Insider, истцы обвиняли компанию в заявлениях, вводивших в заблуждение, из-за чего ценность её акций оказалась завышенной. Компания согласилась выплатить $102,5 млн компенсации в рамках мирового соглашения. Иск был подан в марте 2020 года от лица инвесторов, купивших около 55 млн акций VMware за 18 месяцев, с августа 2018-го по февраль 2020-го. После уплаты судебных издержек, группа истцов должна получить $75,6 млн, а иск будет отозван. Впрочем, предложение об урегулировании пока ждёт одобрения федерального суда в Северной Калифорнии. Согласно судебным документам, компания не признаёт своей вины и отклоняет все обвинения. Это уже не первый случай с VMware подобного рода. В сентябре 2022 года VMware удалось добиться соглашения с Комиссии по ценным бумагам и биржам США (SEC). Тогда компанию обвинили в манипуляция с финансовой отчётностью — она умышленно откладывала поставку продуктов для «переноса» выручки на более поздние кварталы, вводя инвесторов в заблуждение относительно показателей бизнеса. 
Источник изображения: DISRUPTIVO/unsplash.com В новом деле главный истец, пенсионный фонд Eastern Atlantic States Carpenters, заявил, что VMware нарушила закон Securities Exchange Act от 1934 года и правило SEC Rule 10b-5, сделав ложные и вводящие в заблуждения заявления. По данным фонда, это привело к искусственному росту цены акций компании. Речь снова идёт о переносе выручки на следующие кварталы. По данным фонда, компания манипулировала с отчётностью о продажах за 2019 год и ввела инвесторов в заблуждение относительно того, сможет ли она добиться своих финансовых целей по итогам фискального года. Фактически VMware создала в 2019 году резервный фонд на $500 млн, позволивший продемонстрировать значительный рост выручки в следующем году, несмотря на проблемы в бизнесе. 27 февраля 2020 года VMware сообщила о трёх ключевых проблемах: портфель заказов сократился год к году на 96 %, переход на продукты по подписке проходил с заметными трудностями, не удалось добиться плановых финансовых показателей в IV квартале и 2020 фискальном году. В тот же день SEC начала расследование в отношении компании из-за подозрений в манипуляциях с заказами в декабре 2019 года. Случилось это вскоре после того, как свой пост неожиданно покинул главный бухгалтер VMware. В сентябре 2022 года SEC обвинила компанию во введении инвесторов в заблуждение. В иске указывается, что обнародование данных об этих проблемах привело к значительному падению цены акций VMware. Это привело к финансовым потерям всех, кто приобретал ценные бумаги компании в указанный выше период. После того, как Broadcom поглотила VMware, структура последней была изменена. Broadcom отменила бессрочные лицензии и перевела все продукты на подписную схему, ассортимент ПО подвергся радикальному сокращению, были упразднены скидки и изменён подход к взаимодействию с партнёрами. Всё это породило недовольство со стороны ряда клиентов, некоторые из которых начали изучать возможность перехода на альтернативные решения.
21.10.2024 [18:06], Владимир Мироненко
«Инфосистемы Джет» и «Аэродиск» с успехом протестировали первый российский метрокластер на устойчивость к различным отказам
hardware
аквариус
аэродиск
инфосистемы джет
кластер
резервирование
резервное копирование
сделано в россии
схд
«Инфосистемы Джет» и «Аэродиск» сообщили об успешных испытаниях первого отечественного метрокластера на базе СХД с использованием сценариев эмуляции различных отказов и сбоев. В «Инфосистемы Джет» отметили, что протестированный метрокластер является первым отечественным решением такого класса. Метрокластер представляет собой отказоустойчивую ИТ-инфраструктуру на базе синхронной репликации данных средствами СХД. Метрокластер включает две идентичные СХД, размещённые в разных локациях с зеркалированием данных в синхронном режиме. Выход из строя одной СХД или целой площадки не отражается на сохранности данных, которые остаются доступны на второй СХД, а функционирование прикладных систем продолжается. Работа такого кластера полностью автоматизирована и не требует вмешательства администратора в случае сбоя. Тестируемая конфигурация была построена на отечественных решениях «Аквариуса»: две СХД «Аэродиск» Engine AQ 440, соединённые между собой оптическими каналами связи через 25GbE-коммутаторы AQ-N5001, и ферма виртуализации на серверах T50 с использованием отечественного ПО. В ходе испытания проводилась эмуляции прикладной тестовой нагрузки на СХД со стороны СУБД PostgreSQL, запущенной в виртуальной машине. Также вносились сетевые задержки для эмуляции протяжённой линии связи межу ЦОД. 
Источник изображения: «Инфосистемы Джет» Как сообщается, сначала работу кластера проверили при смоделированном отказе СХД на одной площадке из-за аварийного отключения электропитания. Для миграции виртуального интерфейса (VIP) метрокластера на другую СХД потребовалось 30 секунд, что не отразилось на стабильности работы виртуальной машины. Затем провели эмуляцию отказа всей площадки из-за отключения электропитания оборудования (сервер, коммутатор, СХД). В этом случае помимо переключения VIP СХД метрокластера на другую СХД произошло переключение виртуальной машины из-за отказа хоста виртуализации. После этого тестовая нагрузка была перезапущена на второй площадке. Всего на восстановление нагрузки после крушения системы ушло не более трёх минут. В третьем тесте проверили работу метрокластера при сбое каналов связи, который приводит к изоляции узлов кластера. В ходе теста эксперты проверили работу механизма арбитража между двумя СХД при участии сервера-арбитра. В этом случае СХД, сохраняющая с ним связь, становится основной и принимает на себя нагрузку, а вторая СХД исключается из кластера.
21.10.2024 [15:11], Руслан Авдеев
Главе американского ЦОД грозит до 65 лет тюрьмы за подделку сертификатов Tier IV ради контракта с SECГлава одной из IT-компаний из Мэриленда, по данным Минюста США (DoJ), подделал документы о получении сертификата надёжности ЦОД уровня Tier IV в Белтсвилле (Мэриленд). The Register сообщает, что это было сделано ради контракта на размещение оборудования Комиссии по ценным бумагам и биржам США (SEC). Хотя такие сертификаты Uptime Institute выдаёт только после проверки, обвиняемый Дипак Джайн (Deepak Jain) выбрал другой путь. Его компания, по мнению властей, предоставила SEC поддельные документы о сертификации. Причём обвиняемый не просто скорректировал документы Uptime Institute, а «изобрёл» некую организацию Uptime Council, которая, похоже, вообще не существует. В Министерстве юстиции США заявили, что не потерпят схем, ставящих под угрозу безопасность данных правительства. Как власти выяснили, что Джайн сертификацию буквально выдумал, не говорится, но сообщается, что SEC столкнулась с проблемами с безопасностью, охлаждением и энергоснабжением в ЦОД. В своё время сотрудник компании помешал осмотру Beltsville Data Center до заключения контракта в 2012 году. После того, как срок сделки истёк в 2018 году, SEC отказалась продлевать договор. Всего Комиссия потратила на услуги данного ЦОД $10,7 млн. 
Источник изображения: Bermix Studio/unsplash.com За подобную «изобретательность» Джайну грозит по 10 лет тюрьмы за каждое из шести обвинений в крупном мошенничестве, а также до пяти лет в связи с обвинением в ложных заявлениях. Хотя сама компания в судебных документах не называется, в Сети есть информация, что Дипак Джайн является основателем и генеральным директором белтсвилльской AiNET (именно она управляет ЦОД). Впрочем, доказательств того, что вся компания в целом замешана в махинациях, пока нет. При этом на сайте AiNET неоднократно упоминается, что её ЦОД имеет сертификацию Tier IV. Представляющие интересы Джайна юристы сообщили журналистам, что клиент отрицает вину, и говорят, что его компания выполнила все условия контракта с SEC, а доказательства утери данных или их компрометации по вине владельца ЦОД отсутствуют. Случай примечателен тем, что финансовые махинации, в том числе связанные с ЦОД, происходят довольно часто, но о столь наглых попытках подделать Tier-сертификаты известно немного.
21.10.2024 [11:24], Сергей Карасёв
Wiwynn расширила перечень обвинений в отношении X (Twitter) в рамках дела на $61 млнТайваньский поставщик серверного оборудования для гиперскейлеров Wiwynn (подразделение Wistron), по сообщению The Register, добавил ещё два пункта в список обвинений в отношении компании X (бывшая Twitter). Социальной сети Илона Маска (Elon Musk) вменяется преднамеренное искажение фактов (Intentional Misrepresentation) и небрежное искажение фактов (Negligent Misrepresentation). Напомним, Wiwynn подала в суд на Х в августе 2024 года. Утверждается, что в 2014-м Wiwynn заключила контракт с тогдашней Twitter на поставку «уникальных, специально разработанных продуктов для IT-инфраструктуры, включая стоечные решения». В рамках договора были закуплены комплектующие для серверов на сумму $120 млн. 
Источник изображения: pixabay.com В жалобе говорится, что «компоненты, используемые при создании заказанных систем, в значительной степени уникальны», а поэтому их поставка занимает много времени. Wiwynn взяла на себя расходы на приобретение необходимых комплектующих. Но после того как Маск стал владельцем Twitter, соцсеть, согласно заявлениям Wiwynn, прекратила оплачивать счета в рамках поставки серверов и не отвечала на запросы о просроченных платежах. Более того, утверждалось, что Маск полтора года не платит даже за поставленные серверы. Wiwynn заявила, что отгрузила готовую продукцию на сумму более $32 млн, а также закупила и оплатила компоненты, за которые X (Twitter) обязалась взять на себя ответственность. Чтобы минимизировать убытки Wiwynn отменила часть заказов и вернула комплектующие на сумму приблизительно $59 млн. Ещё $61 млн Wiwynn хочет взыскать с Х через суд. В новых обвинениях Wiwynn утверждает, что «X отказалась и проигнорировала неоднократные просьбы о компенсации расходов». Сама соцсеть обвинения в свой адрес отрицает. Дело рассматривается в Окружном суде США по Северному округу Калифорнии.
18.10.2024 [09:35], Сергей Карасёв
Сбербанк полностью перевёл хранилища данных на собственное решение SberData PlatformВ рамках масштабной программы импортозамещения Сбербанк успешно осуществил перенос хранилищ данных на собственное решение SberData Platform. При этом программно-аппаратные комплексы Teradata выведены из эксплуатации. Платформа по работе с данными SberData Platform объединяет ряд ключевых сервисов. Это SDP DataFlow (загрузка и преобразование данных), SDP Hadoop (хранение и обработка больших данных), SDP Analytics (анализ и визуализация информации), SDP DataLab (разработка моделей машинного обучения) и пр. Дополнительные сервисы — SDP Data Quality (контроль качества данных), Platform V Pangolin (реляционная СУБД на базе PostgreSQL) и SDP AnalyticDB (аналитическое хранилище данных). Как отмечается, Сбербанк начал переводить хранилища данных на SberData Platform в 2022 году. В 2023-м на использование собственного решения мигрировала основная часть служб кредитной организации, а в 2024 году процесс полностью завершился. В проекте были задействованы 205 команд, представляющих все подразделения банка. При этом количество активных участников проекта превысило 2 тыс. человек. 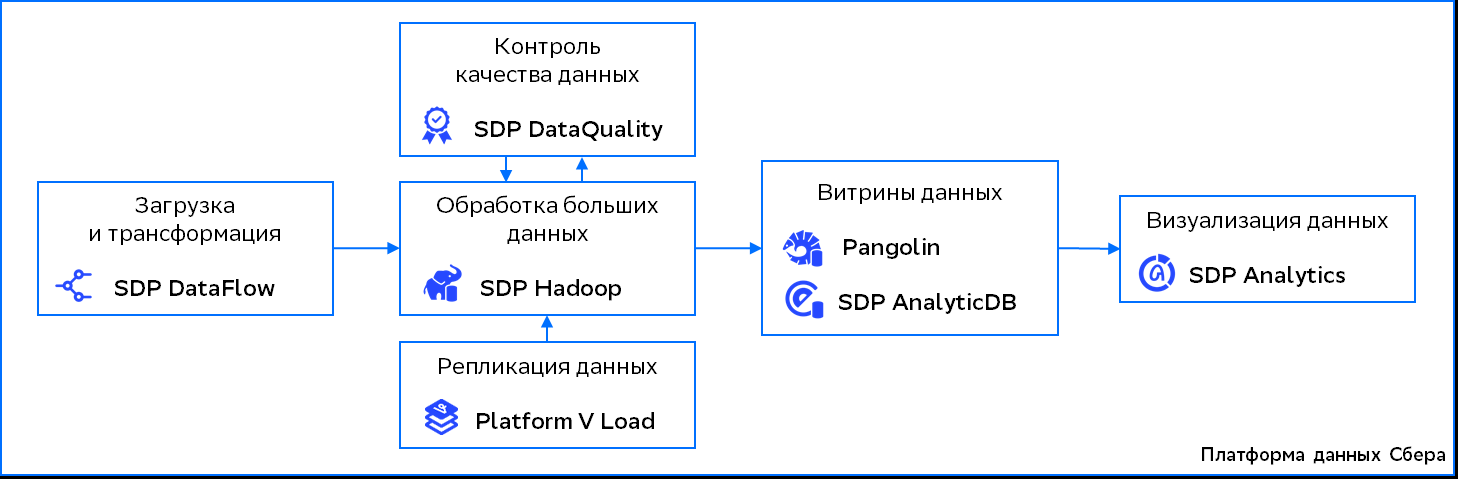
Источник изображения: Сбербанк Компания подчёркивает, что перевод хранилищ на SberData Platform снял для исследователей данных существенные ограничения, обусловленные архитектурными особенностями зарубежного решения. Кроме того, значительно снизилась стоимость хранения информации. В целом, реализация проекта повысила доступность технологий работы с данными для широкого круга пользователей. Платформа SberData Platform включена в Реестр программного обеспечения Минцифры РФ. Сбербанк осуществляет активное импортозамещение в различных сферах. В частности, кредитная организация намерена полностью отказаться от зарубежных СУБД в значимых объектах критической инфраструктуры. Кроме того, ведётся переход с Citrix на отечественную VDI-платформу Termidesk, а на замену SAP ERP создаётся несколько прикладных платформ по управлению финансами, закупками, недвижимостью и кадрами.
16.10.2024 [23:10], Владимир Мироненко
ВТБ первым из российских банков приобрёл гибридные цифровые права (ГЦП), закупив планшеты YADRO KVADRA_TВТБ сообщил о покупке гибридных цифровых прав (ГЦП), обеспеченных поставкой планшетов KVADRA_T компании YADRO («ИКС Холдинг»). В рамках сделки банк приобрёл 40 ГЦП на сумму 1,6 млн рублей. Эмитентом ЦФА, выпуск которых прошёл на платформе «Мастерчейн» на кодовой базе блокчейн-сети Ethereum, выступила компания YADRO. Срок размещения ГЦП составляет 2 месяца. По его истечении банк получит 40 планшетов. Как сообщается в пресс-релизе, ВТБ стал первым российским банком, который использовал данную схему. Заместитель главы правления ВТБ отметил, что крупный российский бизнес заинтересован в импортозамещении своей технологической базы и что банк видит своей стратегической целью поддержку бизнеса, а потому рассматривает различные варианты закупок. Сейчас наблюдается тренд на токенизацию активов реального мира (Real World Assets, RWA) и ГЦП — самый подходящий и выгодный инструмент для закупок, говорит банк. Производители при продаже ГЦП получают гарантированный аванс за товар, а инвесторы — гибкий финансовый актив, гарантирующий поставку товара и при этом защищённый от убытков, пояснил Кулик. 
Источник изображения: ВТБ Глава YADRO отметил, что при использовании технологии распределённого реестра операции прозрачны, контролируемы, устойчивы к несанкционированным изменениям. Как сообщает ВТБ, в 2024 году количество выпусков ЦФА в России превысило 700 шту. на общую сумму 450 млрд руб. При этом объём выпусков ЦФА группы ВТБ занимает около 20 % и составляет 80 млрд рублей.
10.10.2024 [11:18], Сергей Карасёв
Индустриальный мини-компьютер GigaIPC QBiX-ADNAN97-A1 оснащён чипом Intel Alder Lake-NКомпания GigaIPC, подразделение Gigabyte, анонсировала индустриальный компьютер небольшого форм-фактора QBiX-ADNAN97-A1, рассчитанный на решение таких задач, как промышленная автоматизация, edge-вычисления и пр. В основу положена аппаратная платформа Intel Alder Lake-N. Устройство несёт на борту чип Intel Processor N97 (4C/4T; до 3,6 ГГц; 12 Вт). Предусмотрен один слот SO-DIMM для модуля оперативной памяти DDR5-4800 ёмкостью до 16 Гбайт. Применено пассивное охлаждение, а ребристая поверхность корпуса выполняет функции радиатора для отвода тепла. Новинка располагает коннектором M.2 2280 M-Key для SSD с интерфейсом PCIe 3.0 х1 или SATA-3. Кроме того, есть разъём M.2 2230 E-Key для комбинированного адаптера Wi-Fi/Bluetooth. В оснащение входят звуковой кодек Realtek ALC269 и двухпортовый сетевой контроллер 1GbE на основе Realtek RTL8111H. Возможна установка опционального модуля TPM 2.0 (NUVOTON NPCT760AABYX). 
Источник изображения: GigaIPC Мини-компьютер имеет размеры 118 × 109,4 × 44,4 мм. На фронтальную панель выведены два порта USB 3.2 Gen2, последовательный порт (RS-232) и комбинированное аудиогнездо на 3,5 мм. Сзади находятся два разъёма HDMI 2.0 с возможностью вывода изображения с разрешением 4096 × 2160 пикселей и частотой 60 Гц, два порта USB 3.2 Gen2, два гнезда RJ-45 для сетевых кабелей, отверстия для подсоединения антенн Wi-Fi. Питание подаётся через адаптер (19 В / 65 Вт). Диапазон рабочих температур — от 0 до +50 °C. Говорится о совместимости с Windows 10 и Windows 11. Ориентировочная цена GigaIPC QBiX-ADNAN97-A1 составляет $350. |
|

