Материалы по тегу: risc-v
|
01.08.2023 [10:02], Сергей Карасёв
Esperanto готовит универсальный чип ET-SoC-2 на базе RISC-V для задач НРС и ИИСтартап Esperanto Technologies, по сообщению ресурса HPC Wire, готовит новый чип с архитектурой RISC-V, ориентированный на системы высокопроизводительных вычислений (НРС) и задачи ИИ. Изделие получит обозначение ET-SoC-2. Нынешний чип ET-SoC-1 объединяет 1088 энергоэффективных ядер ET-Minion и четыре высокопроизводительных ядра ET-Maxion. Решение предназначено для инференса рекомендательных систем, в том числе на периферии. Чип ET-SoC-2 будет включать в себя новые высокопроизводительные ядра CPU на базе RISC-V с векторными расширениями. Точные данные о производительности не раскрываются, но говорится, что изделие обеспечит быстродействие с двойной точностью более 10 Тфлопс. Архитектура ET-SoC-2 предполагает совместную работу сотен и тысяч чипов для организации платформ НРС. При этом Esperanto делает упор на энергетической эффективности своих решений. 
Источник изображения: Esperanto Technologies По словам Дейва Дитцеля (Dave Ditzel), генерального директора Esperanto, чипы RISC-V смогут взять на себя функции и CPU, и GPU при обработке ресурсоёмких приложений, в частности, машинного обучения. Процессоры RISC-V отстают по производительности от чипов x86 и Arm, хотя разрыв постепенно сокращается. Дитцель сказал, что стойки с чипами ET-SoC-1 могут обеспечить производительность в петафлопсы. Однако проблема с внедрением RISC-V заключается в слабо развитой экосистеме ПО.
19.05.2023 [10:20], Сергей Карасёв
Meta✴ представила ИИ-процессор MTIA для дата-центров — 128 ядер RISC-V и потребление всего 25 ВтMeta✴ анонсировала свой первый кастомизированный процессор, разработанный специально для ИИ-нагрузок. Изделие получило название MTIA v1, или Meta✴ Training and Inference Accelerator: оно оптимизировано для обработки рекомендательных моделей глубокого обучения. Проект MTIA является частью инициативы Meta✴ по модернизации архитектуры дата-центров в свете стремительного развития ИИ-платформ. Утверждается, что чип MTIA v1 был создан ещё в 2020 году. Это интегральная схема специального назначения (ASIC), состоящая из набора блоков, функционирующих в параллельном режиме. 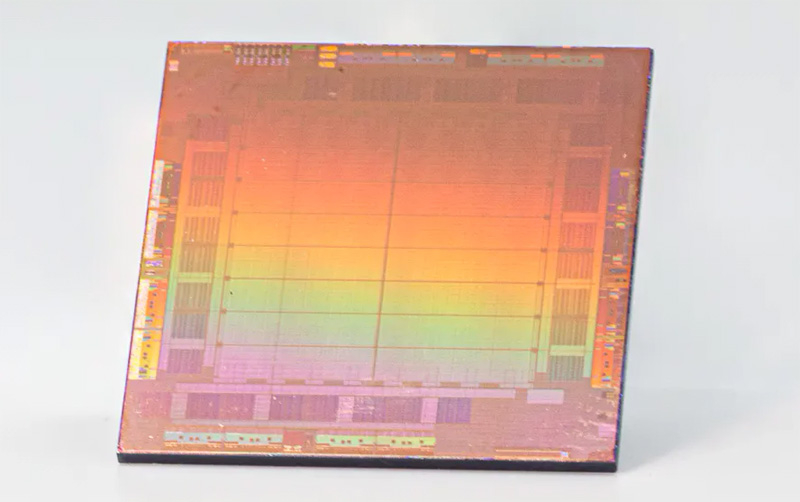
Источник изображений: Meta✴ Известно, что при производстве MTIA v1 используется 7-нм технология. Конструкция включает 128 Мбайт памяти SRAM. Чип может использовать до 64/128 Гбайт памяти LPDDR5. Задействован фреймворк машинного обучения Meta✴ PyTorch с открытым исходным кодом, который может применяться для решения различных задач в области компьютерного зрения, обработки естественного языка и пр. 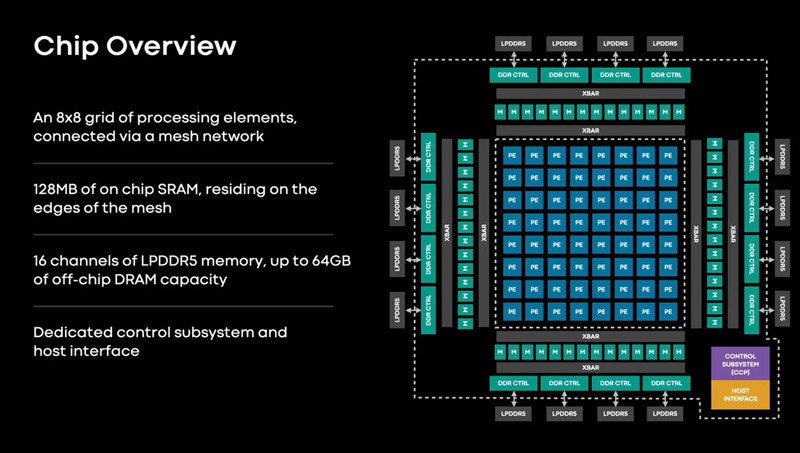 Процессор MTIA v1 имеет размеры 19,34 × 19,1 мм. Он содержит 64 вычислительных элемента в виде матрицы 8 × 8, каждый из которых объединяет два ядра с архитектурой RISC-V. Тактовая частота достигает 800 МГц, заявленный показатель TDP — 25 Вт. Meta✴ признаёт, что у MTIA v1 присутствуют «узкие места» при работе с ИИ-моделями большой сложности: требуется оптимизация подсистем памяти и сетевых соединений. Однако в случае приложений низкой и средней сложности платформа, как утверждается, обеспечивает более высокую эффективность по сравнению с GPU. 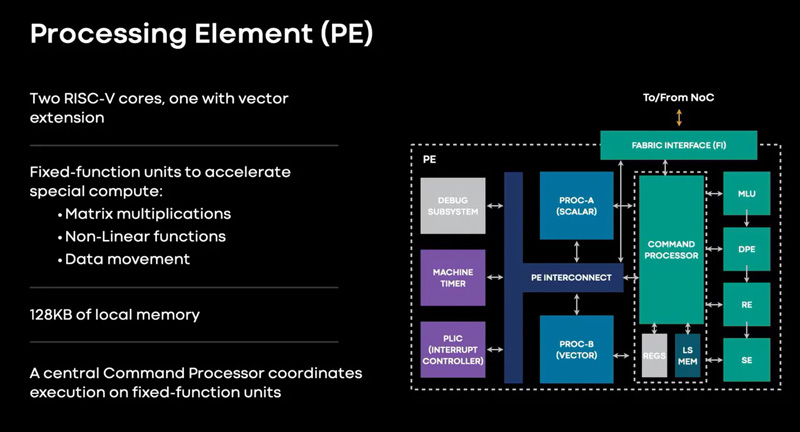 В дальнейшем в семействе MTIA появятся более производительные изделия, но подробности о них не раскрываются. Ранее говорилось, что Meta✴ создаёт некий секретный чип, который подойдёт и для обучения ИИ-моделей, и для инференса: это решение может увидеть свет в 2025 году.
27.01.2023 [23:32], Владимир Мироненко
На фоне колоссальных потерь прибыли Intel отказалась от развития коммутаторов и по-тихому закрыла программу Pathfinder для RISC-VКомпания Intel опубликовала итоги работы в IV квартале 2022 года, окончившемся 31 декабря и принёсшем ей значительные убытки. Выручка компании составила $14,04 млрд, что на 32 % ниже результата за аналогичный период предыдущего года, а также меньше прогноза аналитиков. Intel завершила квартал с чистыми убытками в размере $661 млн (GAAP), в то время как годом ранее её квартальная прибыль составила $4,62 млрд. В IV квартале группа клиентских решений Intel Client Computing Group (CCG) принесла доход в размере $6,63 млрд, что на 36 % ниже результата IV квартала 2021 года. Как сообщает Intel, падение спроса на ПК в основном коснулось потребительского и образовательного рынков, и клиенты решили сократить запасы на складах. По данным Gartner, рынок ПК за отчётный период сократился сильнее, чем в любом другом квартале, с тех пор как компания начала проводить мониторинг отрасли в 1990-х годах. 
Источник изображений: Intel Группа Datacenter and AI Group (DCAI), которая отвечает за решения для ЦОД и платформы ИИ, принесло компании за квартал доход в размере $4,3 млрд, что на 33 % меньше прошлогоднего, но все же больше прогноза аналитиков. Intel объяснила результат давлением со стороны конкурентов и сокращением размера рынка. Как отметил ресурс The Register, несмотря на запуск в начале этого месяца чипов Xeon Sapphire Rapids (это первые новые CPU для ЦОД от Intel почти за два года), они только сейчас начали поступать к клиентам, включая Dell, Google Cloud, HPE, Lenovo, NVIDIA, Supermicro. То есть Intel вряд ли получит достаточно большую выручку от их реализации в этом квартале. Заодно компания решила не строить лабораторию по развитию решений для ЦОД. Всё это сыграет на руку AMD.  Группа Network and Edge Group (NEX), специализирующаяся на сетевых продуктах и периферийных вычислениях, тоже продемонстрировало признаки замедления спроса в IV квартале. Выручка группы снизилась на 1 % в годовом исчислении (до $2,1 млрд), что означает отход от тенденции к росту, о котором она сообщала в предыдущие кварталы. Впрочем, у группы в финансовом году отмечен рост дохода на 11 %. Тем не менее, компания решила фактически избавиться от бизнеса по производству коммутаторов, хотя всего несколько лет назад она инвестировала в это направление и купила Barefoot Networks. Intel сохранит поддержку текущих решений Tofino, но в дальнейшем сосредоточится на развитии IPU. При этом нельзя не отметить, что коммутаторы являлись важной частью будущей экосистемы IPU/DPU.  Положительным моментом для Intel в IV квартале 2022 года является то, что более мелкие подразделения компании показали рост. Выручка подразделения Accelerated Computing Systems and Graphics (AXG), занимающегося разработкой ускорителей, увеличило выручку на 1 % до $247 млн, а также сократило операционные убытки. Подразделение Mobileye, поставщик решений для автономного вождения, которое недавно провело IPO, принесло компании $565 млн, что больше прошлогоднего результата на 59 %. У подразделения Intel Foundry Services выручка в IV квартале выросла на 30 % до $319 млн. При этом компания без объявления закрыла программу Pathfinder for RISC-V. Кроме того, в 2022 году Intel отказалась от развития 3D XPoint/Optane.  Если говорить о результатах за год, то общая выручка Intel снизилась на 20 % (до $63,1 млрд), это привело к падению чистой прибыли на 60 % (до $8 млрд). В частности, выручка группы DCAI упала на 15 % (до $19,2 млрд), группа NEX принесла компании $8,9 млрд, что на 11 % меньше, чем в предыдущем году. Клиентская группа CCG сократила выручку в годовом исчислении на 23 % (до $31,7 млрд). Согласно прогнозу Intel, в I квартале 2023 года выручка будет примерно на 40 % ниже, чем в I квартале 2022 года, в пределах от $10 до $11,5 млрд. Валовая прибыль Intel будет находиться на уровне 39 %.
13.12.2022 [21:52], Алексей Степин
Ventana анонсировала первый по-настоящему серверный RISC-V процессор Veyron V1: 192 ядра с частотой 3,6 ГГцАрхитектура RISC-V достаточно молода и обычно ассоциируется с экономичными чипами на платах, подобных Raspberry Pi. Однако технически она позволяет создавать и мощные процессоры, способные поспорить с лучшими решениями на базе архитектур Arm и x86. На саммите RISC-V компания Ventana Micro Systems анонсировала целое семейство высокопроизводительных процессоров, первенцем в котором стал чип Veyron V1, который, по словам разработчиков, сможет потягаться в однопоточной производительности с самыми современными CPU класса High-End. 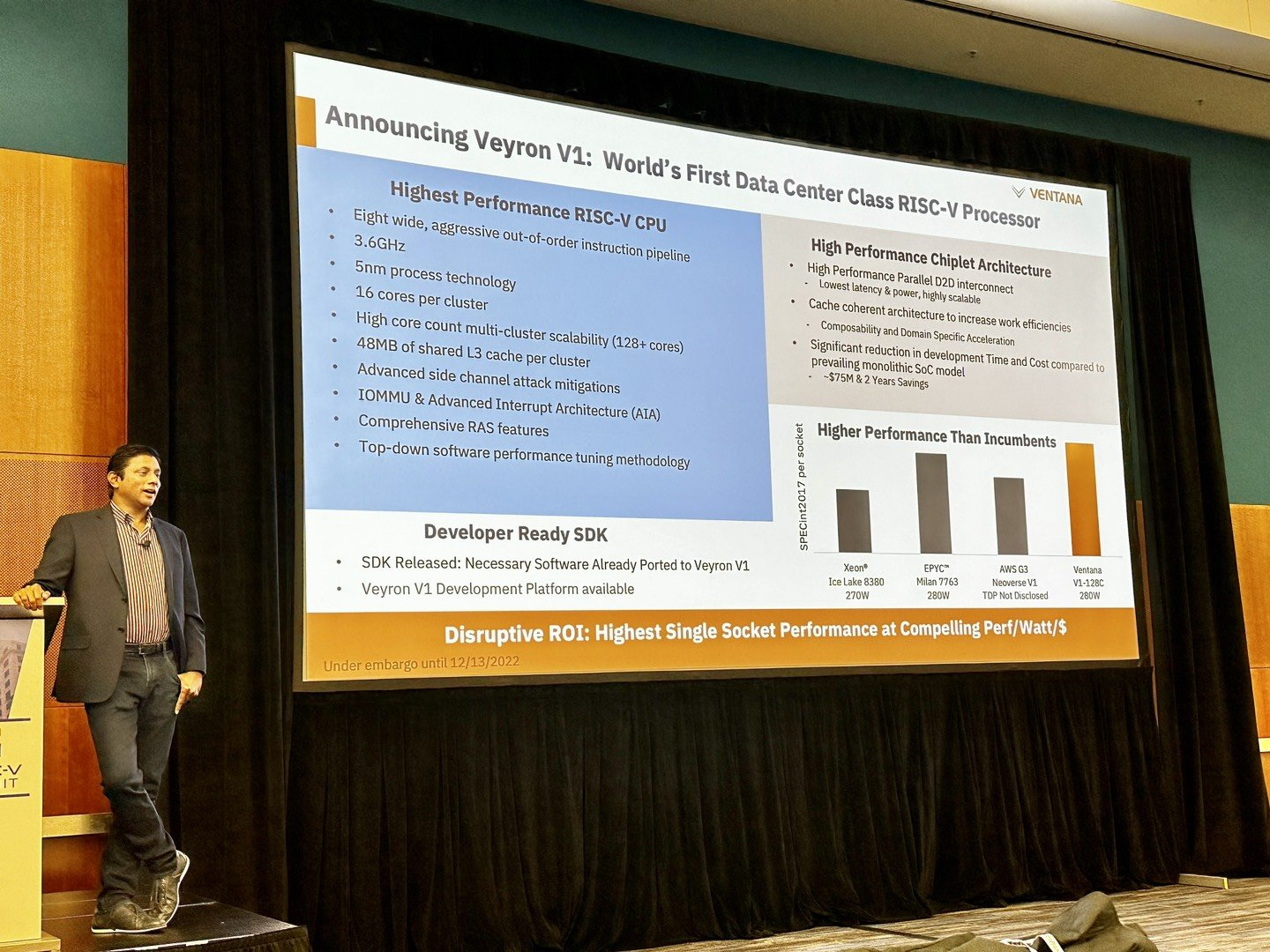
Veyron V1 должен стать самым быстрым процессором с архитектурой RISC-V. Источник: Twitter@risc_v Новинка нацелена на рынок гиперскейлеров, причём благодаря чиплетному дизайну новый процессор изначально разрабатывался как кастомизируемый под задачи заказчика. Veyron V1 будет предлагаться в виде своеобразного набора-конструктора, включающего в себя один или несколько вычислительных чиплетов Veyron, I/O-хаба и интерконнекта, позволяющего связать все компоненты воедино. Это, по словам разработчиков, должно серьёзно ускорить и удешевить процесс внедрения новой процессорной платформы, снизив расходы на разработку чипов на 75 %, а время создания — до не более чем двух лет. 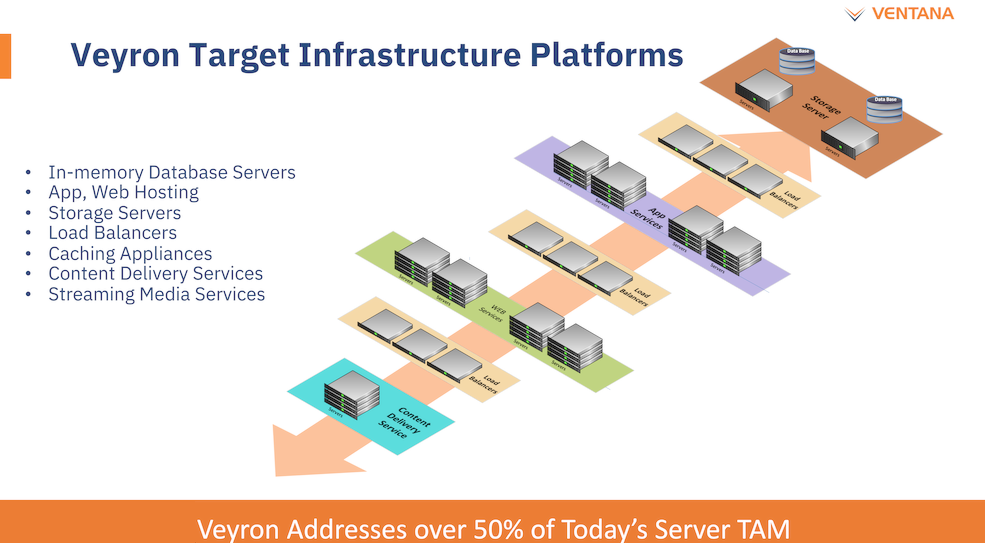
Платформа Veyron V1 универсальна и покрывает широкий спектр задач. Источник здесь и далее: StorageReview Вычислительный чиплет Veyron V1 использует продвинутые 64-битные ядра RISC-V и располагает 2 Мбайт кеша L2, а также многопоточным контроллером памяти. Предусмотрены конфигурации чиплета с 6, 8, 12 или 16 ядрами с частотой в районе 3 ГГц, что сопоставимо с решениями Google и AWS. Использоваться процессор может не только в ЦОД, но и в различных встраиваемых системах, базовых станциях 5G или даже клиентских рабочих станциях. 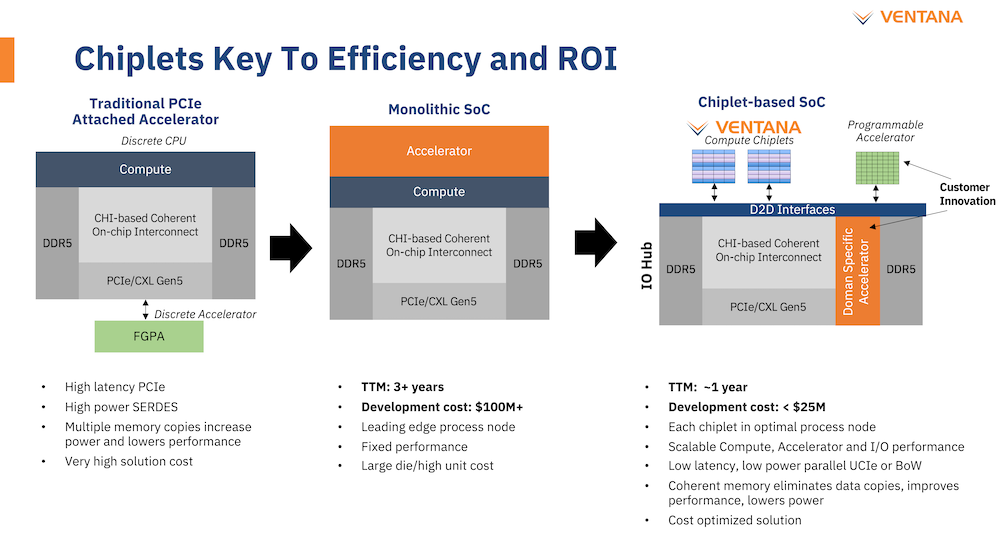
Чиплетная архитектура ускорит цикл разработки и внедрения, а также упростит задачу подключения кастомных ускорителей Архитектурно дизайн Veyron V1 использует агрессивный конвейер шириной восемь инструкций и с внеочередным исполнением. Чип способен работать на частоте до 3,6 ГГц благодаря использованию 5 нм техпроцесса TSMC. I/O-хаб может производиться с использованием более дешёвых 12 или даже 16-нм техпроцессов. Для соединения компонентов процессора разработан специальный низколатентный интерконнект D2D. 
Платформа разработки Veyron V1 и её технические характеристики Каждый чиплет включает в себя до 16 ядер, предусмотрена возможность масштабирования процессора до 192 ядер в 12 чиплетах. Общий объём разделяемого кеша L3 составляет 48 Мбайт. Заявлен высокий уровень защищённости архитектуры от атак по сторонним каналам. Разработчики заявляют о беспрецедентно низком энергопотреблении: 128 ядер V1 уложатся в 280 Вт; AMD EPYC 7763 потребляет столько же при вдвое меньшем числе ядер. 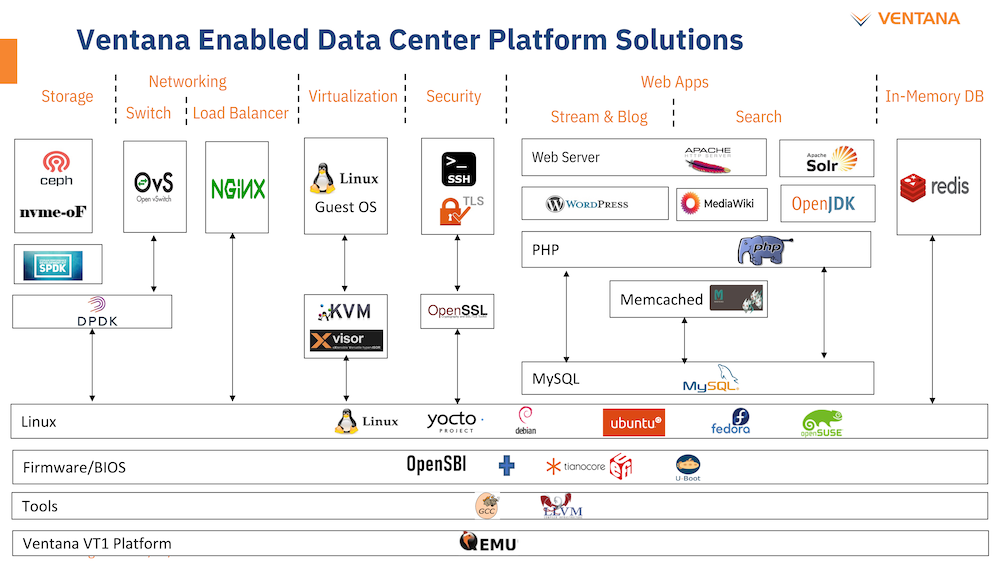
Ventana поддержит новую платформу на всех уровнях разработки системного и прикладного ПО Анонс Ventana нельзя назвать «бумажным» — компания говорит о доступности комплектов разработчика, причём сразу в двух типах шасси: в настольном и в серверном корпусе высотой 2U. Конфигурация включает в себя 16-ядерную версию V1, 128 гбайт памяти DDR5, подключенной с помощью интерфейса CXL (PCIe 5.0) x16, два свободных слота расширения PCIe 5.0 x16, загрузочный накопитель NVMe M.2 и 8 NVMe SFF SSD формата 2,5" для хранения данных. Для удалённого управления предусмотрен 1GbE-порт. 
Большая часть критически важного программного обеспечения уже портирована на архитектуру RISC-V Компания не забыла и о поддержке со стороны программного обеспечения: платформы разработчика Ventana Veyron V1 будут сопровождаться полноценным SDK с основным ПО, уже портированным на новую архитектуру. В список входят компиляторы GCC и LLVM, отладчик OpenOCD/GDB, исходные коды и бинарные файлы загрузчиков U-Boot и Tianocore UEFI EDK2.1. Поддерживается ряд дистрибутивов Linux, а также другое системное и прикладное ПО. Ожидается, что новые системы будут доступны в начале следующего года.
18.10.2022 [19:00], Сергей Карасёв
AMD, Google, Microsoft и NVIDIA представили Caliptra — проект по повышению безопасности каждого чипаВ ходе саммита OCP (Open Compute Project) анонсирована открытая спецификация Caliptra 0.5, призванная повысить безопасность процессоров, ускорителей, накопителей и практически любых систем-на-чипе (SoC). Речь идёт об аппаратной реализации технологии Root of Trust (RoT). Она предназначена для проверки целостности и подлинности прошивок и другого встроенного, а также системного программного обеспечения.  RoT гарантирует, что только доверенное ПО может исполняться на чипе. Отмечается, что традиционно средства RoT отделены от SoC и обычно обеспечиваются материнской платой. Однако новые бизнес-модели, предполагающие периферийные и облачные вычисления, предъявляют повышенные требования к обеспечению безопасности. Спецификация Caliptra 0.5 как раз и решает данную проблему. 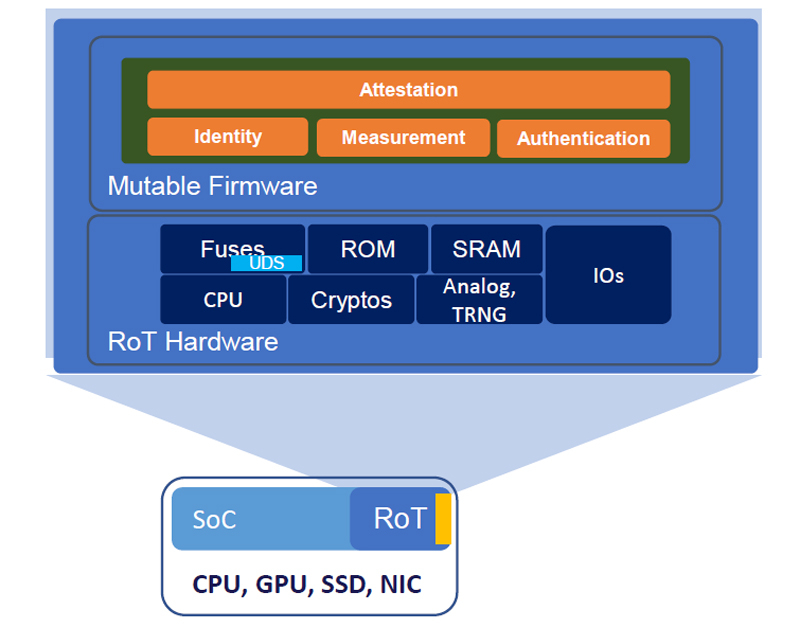
Источник изображений: Caliptra В разработке решения приняли участие AMD, Google, Microsoft и NVIDIA. Спецификация будет поддерживаться различными аппаратными изделиями следующего поколения — CPU, GPU, SSD, NIC и иные ASIC. Отмечается, что Caliptra 0.5 RTL (IP-блоки на базе RISC-V с необходимой обвязкой) распространяется через CHIPS Alliance (Common Hardware for Interfaces, Processors and Systems) — консорциум, который работает над созданием целого спектра открытых решений для SoC и высокоплотных упаковок чипов. 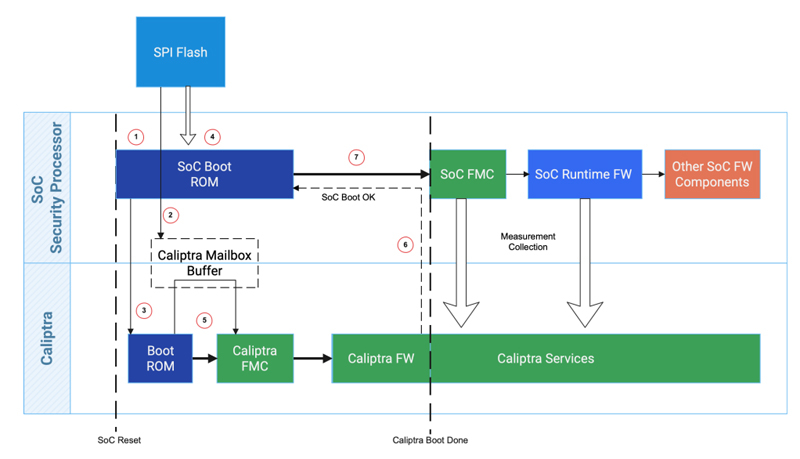 «Существует потребность в улучшенной прозрачности и согласованности низкоуровневой аппаратной безопасности. Мы открываем исходный код Caliptra вместе с нашими партнёрами для удовлетворения этих потребностей», — отмечает Microsoft. Также компания совместно с Google, Infineon и Intel представила Project Kirkland, направленный на создание защищённого канала связи между CPU и TPM с использованием программных средств. 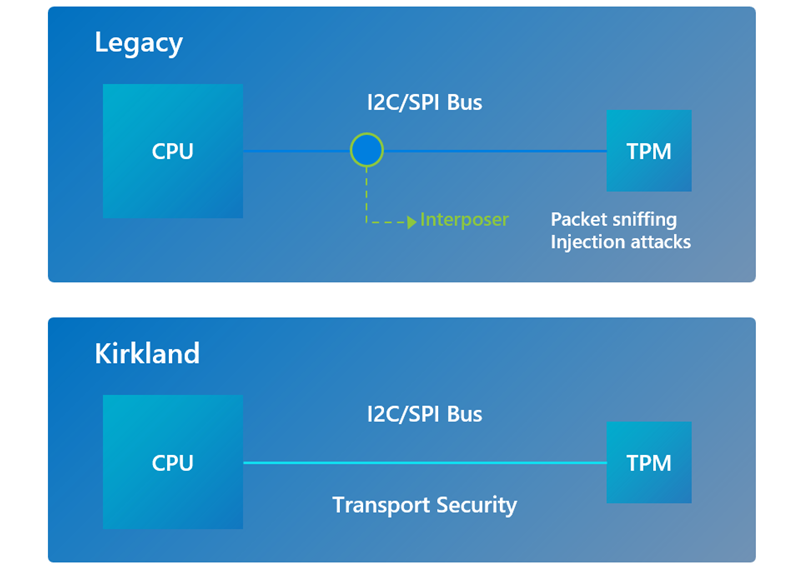
Источник: Microsoft Спецификация Caliptra 0.5 доступна здесь для оценки. На основе отзывов будет выработан окончательный стандарт, отвечающий различным потребностям в зависимости от варианта использования. Кроме того, доступен исходный код, что поможет членам сообщества интегрировать решение в свои микросхемы. Говорится также, что выход спецификации знаменует собой важный шаг вперёд в сторону общеотраслевого сотрудничества в области информационной безопасности.
23.09.2022 [19:58], Алексей Степин
Google заявила, что использует процессоры SiFive Intelligence X280 на RISC-V вместе со своим TPUАрхитектура RISC-V продолжает понемногу набирать популярность и завоевывать внимание ведущих игроков на рынке информационных технологий. На мероприятии AI Hardware Summit в совместном выступлении ведущего архитектора SiFive и архитектора Google TPU было отмечено, что Google уже использует процессоры с ядрами Intelligence X280. Эти ядра — один из вариантов воплощения архитектуры RISC-V, из продвигаемых SiFive. Анонс Intelligence X280 состоялся ещё в апреле 2021 года, когда SiFive выпустила апдейт 21G1, основной упор в котором был сделан на максимизацию характеристик уже существующих ядер RISC-V в области операций с плавающей запятой. 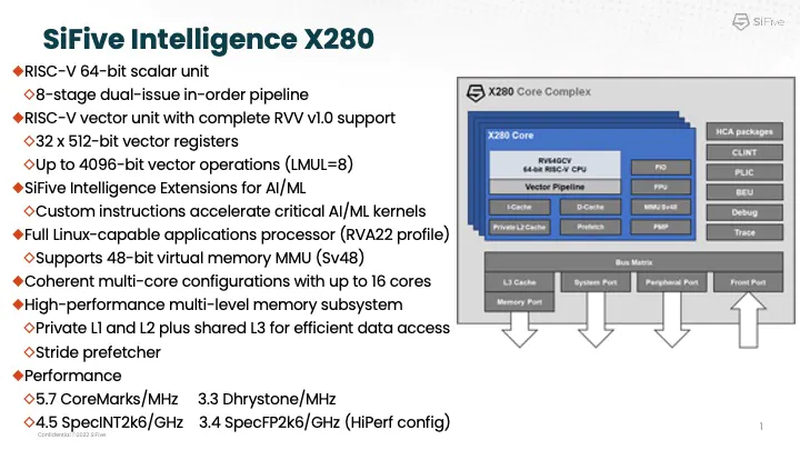
Процессорное ядро Intelligence X280 и его возможности. Источник: SiFive Как следует из названия, данный вариант процессора оптимизирован под задачи машинного интеллекта: ядра RISC-V в нём дополнены векторными конвейерами RISC-V Vector (RVV) с производительностью 4,5 Тфлопс BF16 и 9,2 Топс INT8 на ядро. Одной из самых интересных технологий в Intelligence X280 является интерфейс Vector Coprocessor Interface eXtension (VCIX). 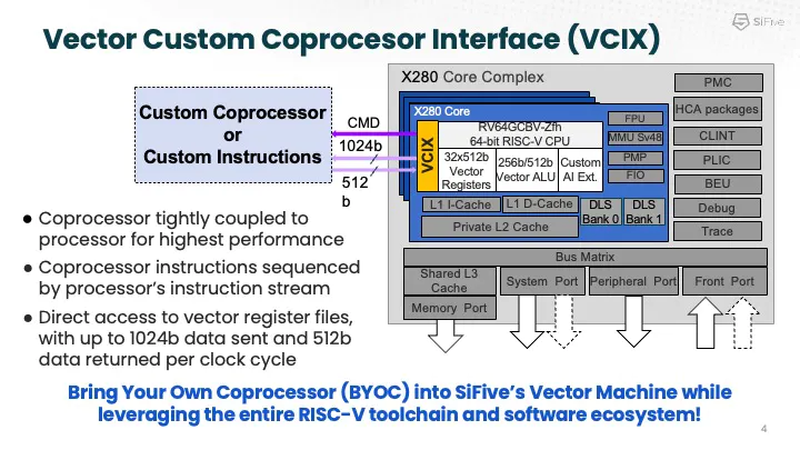
Устройство VCIX. Источник: SiFive Он позволяет подключать внешние ускорители векторных операций напрямую к регистровому файлу X280, минуя основную шину и кеши. Такой подход минимизирует накладные расходы и не требует использования специальных средств при программировании системы, поскольку связка из X280 и подключённого по VCIX ускорителя работает полностью прозрачно в рамках стандартных средств разработки SiFive. 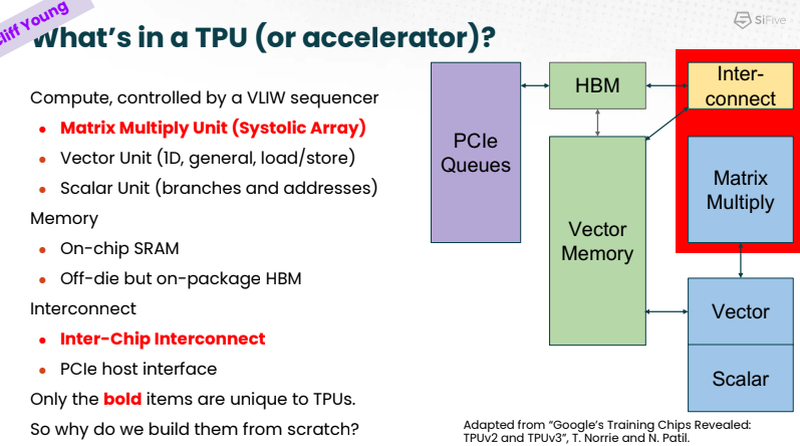
Сильные стороны Google TPU. Источник: SiFive На саммите в Санта-Кларе разработчики SiFive и Google TPU рассказали, что процессоры Intelligence X280 используются в качестве хост-процессоров к ускорителям систолической векторной математики Google MXU; правда, о масштабах внедрения RISC-V в Google сведений приведено не было. 
Разделение труда Intelligence X280 и Google TPU. Источник: SiFive Ранее уже появлялась информация, что Google активно тестирует ASIC сторонних разработчиков в связке со своим TPU, в частности, чипы Broadcom, дабы разгрузить его от второстепенных задач и сделать упор на сильных сторонах — матричной математике и быстром интерконнекте. Похоже, SiFive Intelligence X280 решает задачу интеграции подобного рода задач более изящно: как отметил в выступлении Клифф Янг (Cliff Young), архитектор Google TPU, с помощью VCIX можно построить машину, позволяющую усидеть на двух стульях (build a machine that lets you have your cake and eat it too).
24.08.2022 [22:42], Владимир Мироненко
Untether AI представила ИИ-ускоритель speedAI240 — 1,5 тыс. ядер RISC-V и 238 Мбайт SRAM со скоростью 1 Пбайт/сКомпания Untether AI анонсировала ИИ-архитектуру следующего поколения speedAI (кодовое название «Boqueria»), ориентированную на инференс-нагрузки. При энергоэффективности 30 Тфлопс/Вт и производительности до 2 Пфлопс на чип speedAI устанавливает новый стандарт энергоэффективности и плотности вычислений, говорит компания.  Поскольку at-memory вычисления в ряде задач значительно энергоэффективнее традиционных архитектур, они могут обеспечить более высокую производительность при одинаковых затратах энергии. Первое поколение устройств runAI в 2020 году Untether AI достигла энергоэффективности на уровне 8 Тфлопс/Вт для INT8-вычислений. Новая архитектура speedAI обеспечивает уже 30 Тфлопс/Вт. .jpg)
Изображения: Untether AI (via ServeTheHome) 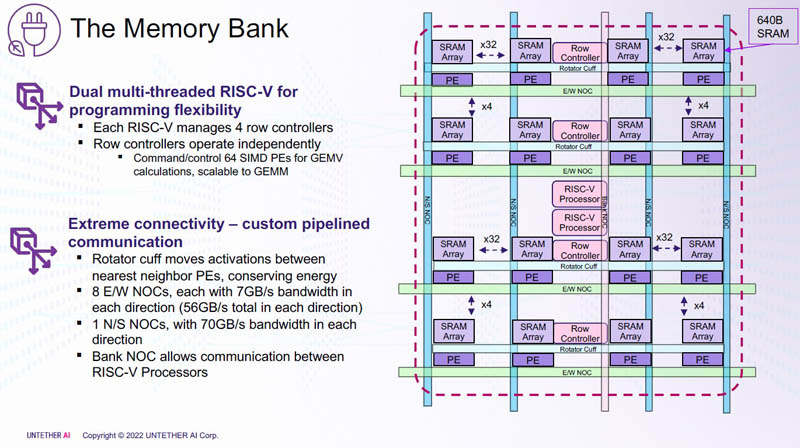 Этого удалось добиться благодаря архитектуре второго поколения, использованию более 1400 оптимизированных 7-нм ядер RISC-V (1,35 ГГц) с кастомными инструкциями, энергоэффективному управлению потоком данных и внедрению поддержки FP8. Вкупе это позволило вчетверо поднять эффективность speedAI по сравнению с runAI. Новинка может быть гибко адаптирована к различным архитектурам нейронных сетей. Концептуально speedAI напоминает ещё один тысячеядерный чип RISC-V — Esperanto ET-SoC-1. 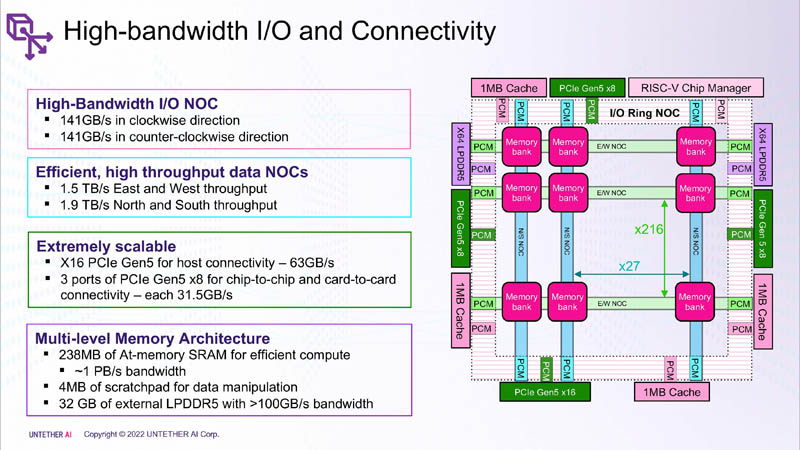 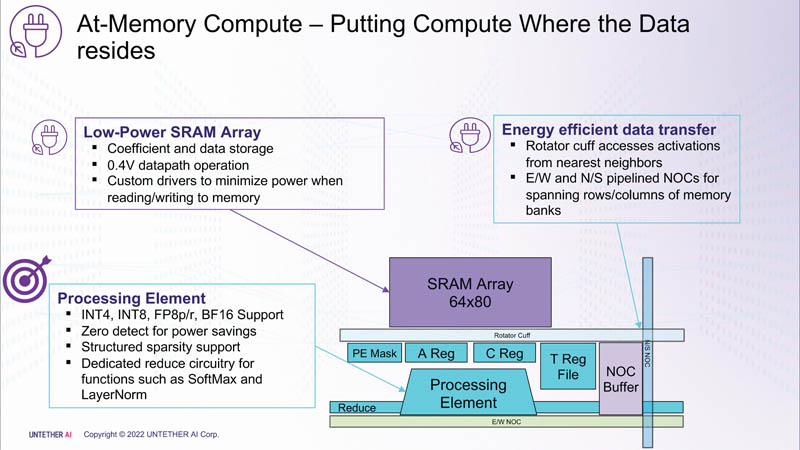 Первый член семейства speedAI — speedAI240 — обеспечивает 2 Пфлопс вычислениях в FP8-вычислениях или 1 Пфлопс для BF16-операций. Благодаря этому обеспечивается самая высокая в отрасли эффективность — например, для модели BERT заявленная производительность составляет 750 запросов в секунду на Вт (qps/w), что, по словам компании, в 15 раз выше, чем у современных GPU. Добиться повышения производительности удалось благодаря тесной интеграции вычислительных элементов и памяти.  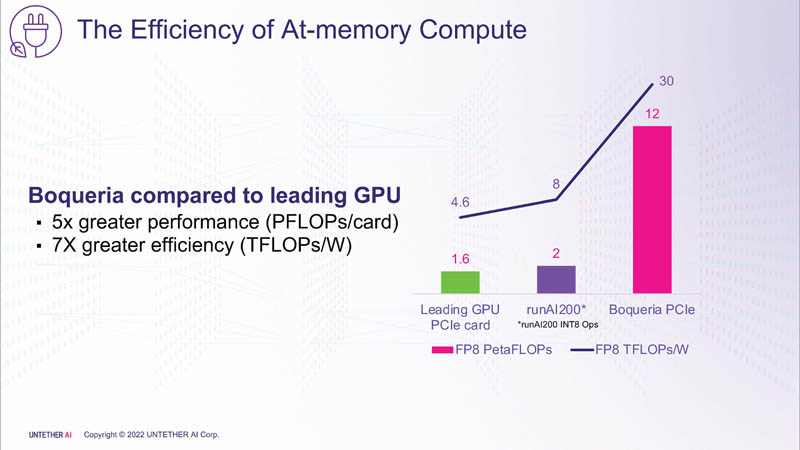 На каждый блок SRAM объёмом 328 Кбайт приходится 512 вычислительных блоков, поддерживающих работу с форматами INT4, INT8, FP8 и BF16. Каждый вычислительный блок имеет два 32-бит (RV32EMC) кастомных ядра RISC-V с поддержкой четырёх потоков и 64 SIMD. Всего есть 729 блоков, так что суммарно чип несёт 238 Мбайт SRAM и 1458 ядер. Блоки провязаны между собой mesh-сетью, к которой также подключены кольцевая IO-шина, несущая четыре 1-Мбайт блока общего кеша, два контроллера LPDRR5 (64 бит) и порты PCIe 5.0: один x16 для подключения к хосту и три x8 для объединения чипов. Суммарная пропускная способность SRAM составляет около 1 Пбайт/с, mesh-сети — от 1,5 до 1,9 Тбайт/с, IO-шины — 141 Гбайт/c в обоих направлениях, а 32 Гбайт DRAM — чуть больше 100 Гбайт/с. PCIe-интерфейсы позволяют объединить до трёх ускорителей, с шестью speedAI240 чипами у каждого. Решения speedAI будут предлагаться как в виде отдельных чипов, так и в составе готовых PCIe-карт и M.2-модулей. Ожидается, что первые поставки избранным клиентам начнутся в первой половине 2023 года.
08.02.2022 [00:30], Владимир Мироненко
Ventana, разработчик серверных процессоров RISC-V, объявил о стратегическом партнёрстве с IntelСтартап Ventana Micro Systems Inc., разработчик высокопроизводительных серверных процессоров на базе архитектуры RISC-V, объявил о стратегическом партнёрстве с Intel — ядра и чиплеты Ventana будут доступны в рамках Intel Foundry Services (IFS) для крупных клиентов ЦОД, операторов сетей 5G, потребителей в областях ИИ и машинного обучения, автомобильной индустрии и т. д. Ventana разрабатывает серверные CPU с расширяемыми возможностями, поставляемые в виде SoC с чиплетной компоновкой или IP-блоков. Процессоры предназначены для обеспечения лучшей в своём классе однопоточной производительности и могут быть оптимизированы для высокопроизводительных и облачных вычислений, ЦОД-нагрузок, 5G и периферийных вычислений, выполнения задач ИИ и машинного обучения, автомобильных и клиентских приложений. 
Источник изображения: ventanamicro.com Модульная и масштабируемая продуктовая стратегия Ventana, основанная на использовании чиплетов, позволяет обеспечить быстрое коммерческое внедрение со значительной экономией времени и стоимости разработки по сравнению с преобладающими на рынке IP-моделями. Собственные ядра CPU компания намерена выпускать на TSMC по 5-нм нормам, но для остальных блоков могут использоваться сторонние производства. В рамках партнёрства с Intel ядра Ventana можно будет интегрировать в SoC конечных заказчиков. Кроме того, Ventana планирует предложить масштабируемую вычислительную платформу, которая позволит гиперскейлерам и крупным OEM-производителям гибко подбирать и настраивать функциональные блоки у заказываемых чипов, значительно сокращая время и стоимость разработки. Боб Бреннан (Bob Brennan), вице-президент Intel Foundry Services по разработке клиентских решений отметил, что у Ventana «самая совершенная и хорошо разработанная платформа» на базе Open Chiplet, которая полностью соответствует видению Intel. По его словам, чиплеты Ventana позволят IFS предоставлять модульные решения, повышающие производительность, снижающие энергопотребление и затраты на разработку, и ускоряющие время выхода продуктов на рынок.
17.12.2021 [01:35], Алексей Степин
Российский серверный процессор Baikal-S2 получит чиплетную компоновку, 128 ядер Armv9 с частотой 3 ГГц, 8 каналов DDR5, 192 линии PCIe 5.0 и CXL 2.0На ежегодной итоговой конференции Байкал Электроникс состоялся анонс 128-ядерных серверных Arm-процессоров второго поколения Baikal-S2, были показаны результаты тестов 48-ядерных Baikal-S, анонсированы первые же российские серверы и СХД на их основе, а также было объявлено о заключении стратегических сделок и планах на будущее. Если говорить о сделках, то можно смело сказать, что рамками только Arm Байкал себя уже не ограничивает: получение доли в CloudBEAR означает и получение основы для разработки собственных чипов с архитектурой RISC-V, и первым же проектом станет создание сертифицированной системы доверенной загрузки для процессоров Baikal-L и Baikal-S2. Но среди равноправных партнёров значатся не только российские разработчики — заключена сделка с Esperanto Technologies. 
Тестовая плата с процессором Baikal-S (Изображения: Байкал Электроникс) Данная сделка позволит получить доступ к весьма серьёзным разработкам: напомним, Esperanto создала ET-SoC-1, мощнейший ИИ-ускоритель с более чем тысячью ядер RISC-V в составе. Связка из четырёх таких чипов развивает более 800 Топс в задачах инференса, потребляя всего 120 Вт. Надо ли говорить, насколько это важно в эпоху нейросетей, машинного обучения и разнообразных сопроцессоров-ускорителей.  Несмотря на то, что Baikal-S «старичком» назвать никак нельзя, компания анонсировала уже второе поколение чипов — Baikal-S2 базируется на новейшей архитектуре Neoverse-N2 (ARMv9). Процессор будет выполнен по 6-нм техпроцессу с использованием чиплетной компоновки и получит 128 ядер с частотой порядка 3 ГГц, 8 каналов DDR5 (возможно, будет и больше), 192 линии PCIe 5.0, поддержку CXL 2.0 и CCIX 2.0. Ожидается, что он станет аналогом AMD EPYC Milan. Разработку планируется закончить к 2025 году.  Что касается текущего поколения Baikal-S, то осенью этого года была получена первая партия чипов, а также было анонсировано несколько решений на его основе. Как теперь отрапортовали разработчики, первые чипы оказались очень удачными во всех отношениях, так что больших препятствий на пути их внедрения быть не должно. На конференции были представлены одно- и двухсокетные серверы и СХД от российских компаний 3Logic, Aquarius, ICL, iRU, Норси-Транс. Впоследствии появятся и четырёхпроцессорные системы. 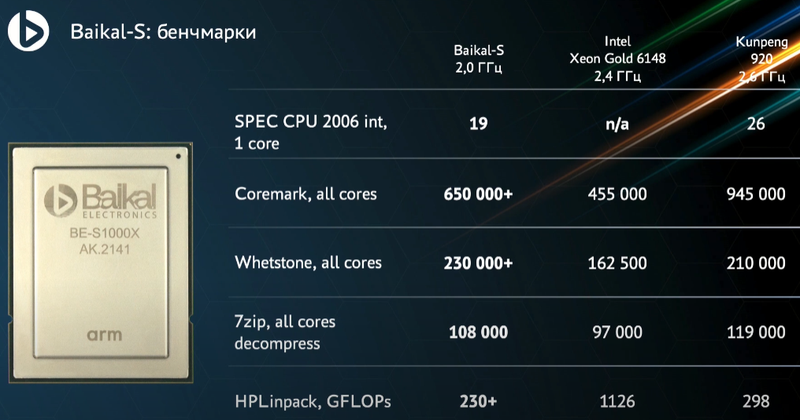 Напомним, что Baikal-S содержит в своём составе 48 ядер Arm Cortex-A75 с частотой до 2,5 ГГц и имеет TDP 120 Вт. Шестиканальный контроллер памяти поддерживает до 768 Гбайт DDR4-3200. Современно выглядит и поддержка PCI Express 4.0 (80 линий), и наличие выделенного управляющего ядра для организации доверенных вычислений, и аппаратная виртуализация.  В синтетических тестах новинка показала результаты, сравнимые с Intel Xeon Gold 6148 или AMD EPYC 7351, а своему китайскому «коллеге» в лице HiSilicon Kunpeng 920 процессор уступил лишь в некоторых тестах. Разработчики уверены, что процессор получился универсальным и его можно использовать практически везде: в серверах любых профилей, СХД, суперкомпьютерах, устройствах сетевой безопасности и даже в базовых станциях 5G. Результаты тестов также доступны и на сайте Geekbench.  Ожидается, что SDK для новой платформы будет доступен уже в конце февраля следующего года. Весной появятся двухпроцессорные платы и первые 20 серверов попадут в центры тестирования, а к середине лета 200 с лишним серверов примут своё участие в пилотных проектах. Старт серийного производства CPU намечен на октябрь-ноябрь 2022 года — речь идёт примерно о 10 тыс. процессоров. В 2023 году этот объём будет утроен и при необходимости увеличен.  Таким образом, Байкал Электроникс доказала, что может создавать достойные серверные решения, не уступающие зарубежным, причём, как на базе x86-64, так и на базе Arm. Уже сейчас процессоры Baikal-S могут стать основой для производительных серверов российской разработки, а сделка с Esperanto сделает российские HPC-системы и комплексы машинного обучения по-настоящему мощными.
16.12.2021 [16:59], Сергей Карасёв
Российская компания Syntacore вошла в состав правления RISC-V InternationalRISC-V International сообщила о том, что российская компания Syntacore, подконтрольная российской же компании YADRO, получила статус премиального участника названной организации. При этом сооснователь и исполнительный директор Syntacore Александр Редькин вошёл состав правления RISC-V International. Syntacore является отечественным разработчиком микропроцессорных ядер и специализированных инструментов на архитектуре RISC-V. Компания входит в число основателей открытого международного консорциума RISC-V. Его цель заключается в разработке и продвижение одноимённой открытой архитектуры. 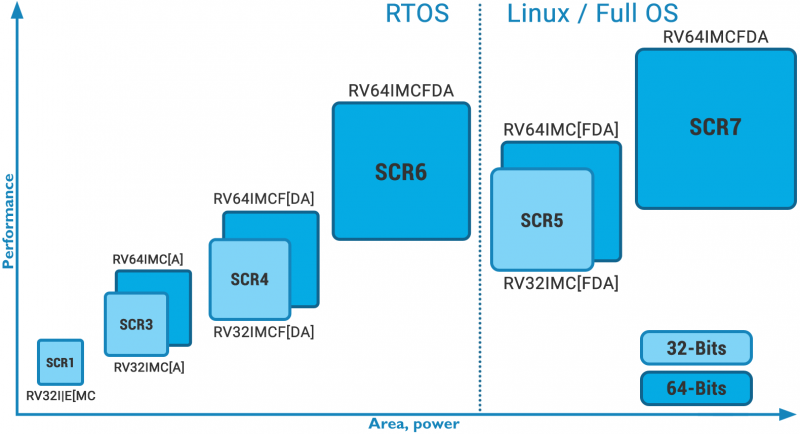
Изображение: Syntacore «Сегодняшний анонс ещё сильнее укрепляет наше лидирующее положение на рынке интеллектуальной собственности RISC-V в новом году и дальше. Вся наша интеллектуальная собственность полностью совместима с последней версией спецификации RISC-V», — отметил господин Редькин. Компания Syntacore является одним из лидеров экосистемы RISC-V и лицензирует микропроцессорные технологии собственной разработки на базе данной архитектуры клиентам в России и за рубежом. Продукты на основе процессорных технологий компании разрабатываются по нормам от 180 до 7 нм. |
|

