Материалы по тегу: pci express
|
05.08.2025 [18:00], Сергей Карасёв
Спецификации PCIe 8.0 будут утверждены к 2028 году: до 1 Тбайт/с в двустороннем режиме x16Организация PCI Special Interest Group (PCI-SIG) объявила о том, что спецификация PCI Express (PCIe) 8.0 будет готова к 2028 году. Интерфейс нового поколения обеспечит удвоение пропускной способности по сравнению с предыдущей версией стандарта, а также привнесёт ряд других изменений. Напомним, финальная спецификация PCIe 7.0 была опубликована в июне нынешнего года. «Сырая» скорость достигает 128 ГТ/с на линию, а пропускная способность в двустороннем режиме в конфигурации x16 составляет 512 Гбайт/с. Реализованы кодирование PAM4, поддержка Flit-режима и обратная совместимость с предыдущими версиями PCIe. В случае PCIe 8.0 «сырая» скорость увеличится до 256 ГТ/с на линию, тогда как пропускная способность в двустороннем режиме x16 поднимется до 1 Тбайт/с. Как и прежде, планируется обеспечение обратной совместимости с более ранними поколениями PCIe. Для повышения скорости передачи данных подвергнется доработкам протокол. Кроме того, будет уделяться внимание дальнейшему улучшению энергетической эффективности, обеспечению целевых показателей надёжности и задержки. Упомянуто кодирование PAM4. 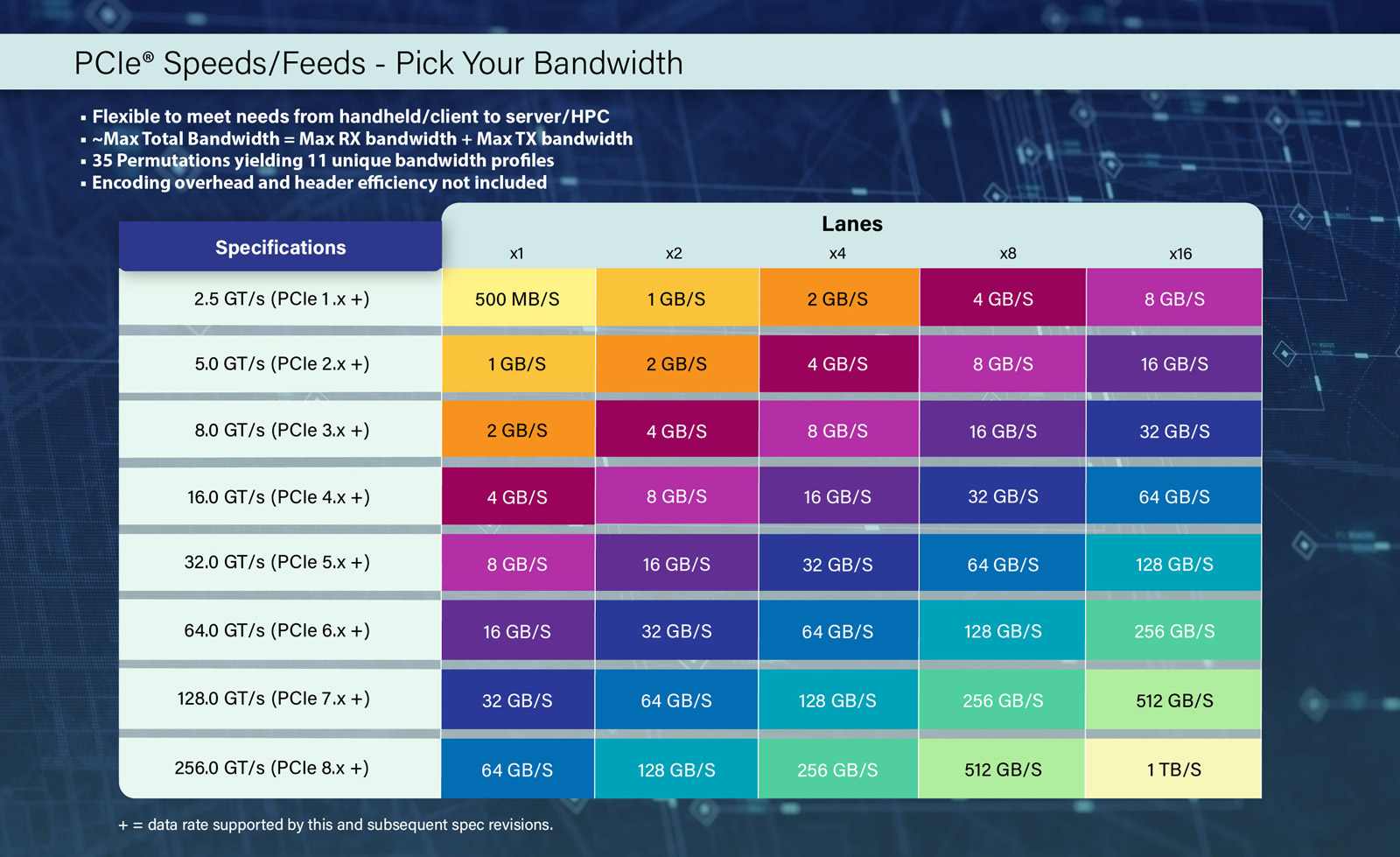
Источник изображений: PCI-SIG Одновременно продолжится работа над совершенствованием кабелей CopprLink для PCIe. Весной 2024 года PCI-SIG обнародовала спецификации электрических кабелей и разъёмов CopprLink для внешних и внутренних подключений PCIe 5.0 и PCIe 6.0: скорость достигает 32 и 64 ГТ/с соответственно. Максимальная длина соединения в пределах одной системы составляет 1 м, между стойками — 2 м. Но, как отмечается, для высокопроизводительных систем требуются соединения большей протяжённости. 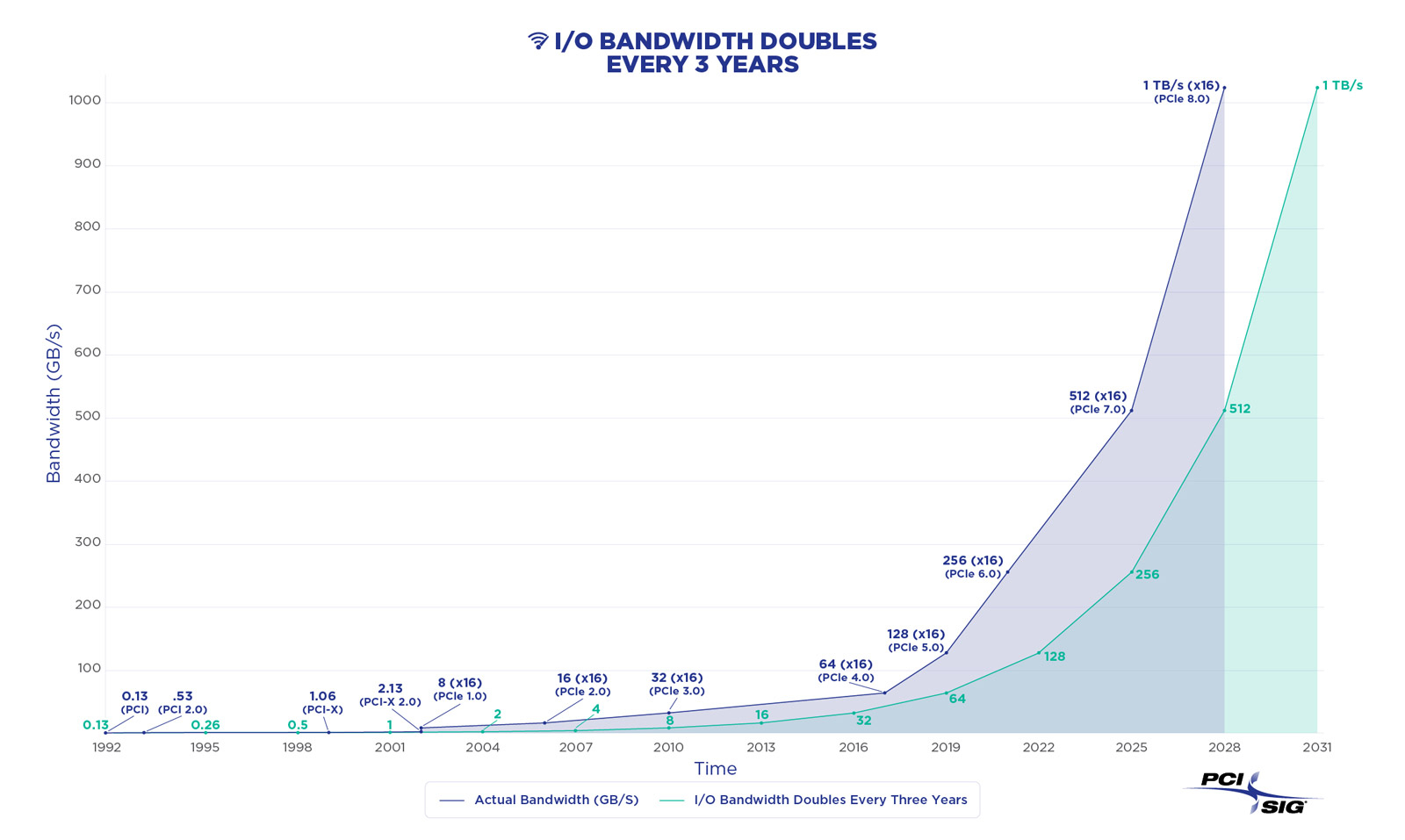 В целом, спецификация PCIe 8.0 нацелена на создание высокоскоростного интерфейса для таких сфер применения, как ИИ и машинное обучение, периферийные и квантовые вычисления, а также приложения с интенсивным использованием данных, включая дата-центры гиперскейлеров, НРС-задачи, автомобильные и аэрокосмические платформы и пр.
11.06.2025 [23:59], Игорь Осколков
Представлена финальная спецификация PCI Express 7.0Консорциум PCI-SIG официально объявил о релизе спецификаций PCI Express 7.0 версии 1.0. Базовые характеристики интерфейса изменений не претерпели: «сырая» скорость 128 ГТ/с на линию, которая конвертируется в 512 Гбайт/с в двустороннем режиме в конфигурации x16; кодирование PAM4; поддержка Flit-режима; универсальность и обратная совместимость с предыдущими версиями PCIe; повышенная энергоэффективность; расширенная коррекция ошибок и т.д. Новый стандарт ориентирован на решения с интенсивным обменом данными, которым требуются низкая задержка, высокая скорость и повышенная надёжность: ИИ-платформы, 800G-сети, облака гиперскейлеров, квантовые системы и т.п. Впрочем, как и стандарты прошлого поколения, PCIe 7.0 сохранит гибкость, предоставляя 11 различных профилей, которые охватывают весь спектр возможных применений интерфейса, от мобильных платформ до HPC-систем. Консорциум придерживается выбранного темпа выпуска спецификаций — каждые три года появляется новый стандарт, который, по мнению PCI-SIG, всегда чуть опережает текущие потребности индустрии. Здесь есть два важных момента. Во-первых, PCI-SIG не пытается добиться максимально возможной скорости (за NVLink уже не угнаться), а старается дать максимум скорости по приемлемой цене. Во-вторых, уже сейчас разработчики IP говорят о возможных проблемах насыщения данными даже одной линии PCIe 7.0 в некоторых приложениях и сложностях физической и логической реализации нового интерфейса. 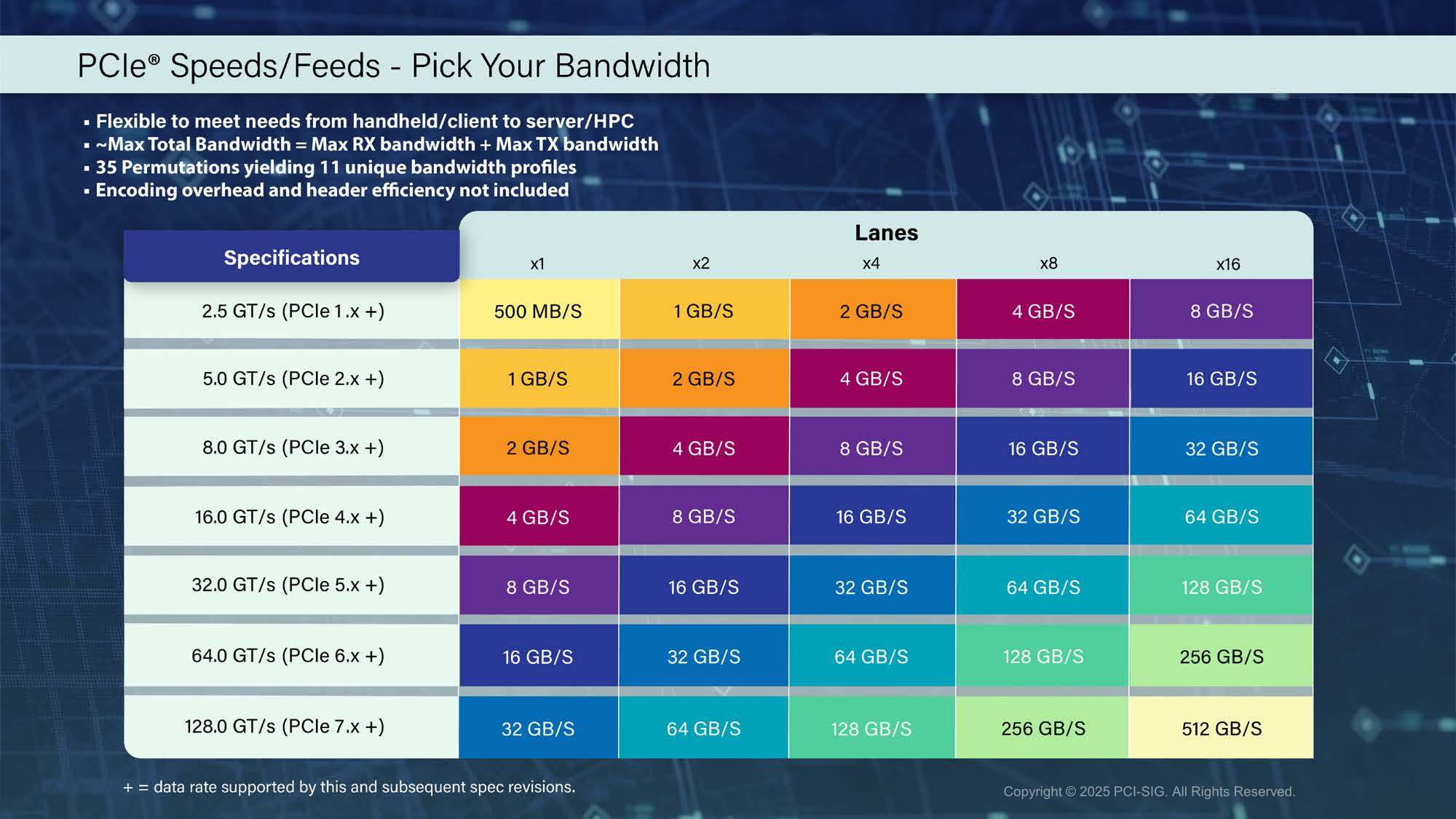
Источник изображений: PCI-SIG  Впрочем, до появления первых реальных продуктов с поддержкой PCIe 7.0 ещё долго. На 2027 год запланирован старт предварительного «тестирования на соответствие» (FYI, First Year Inventory Compliance Program), так что внедрение нового стандарта начнётся не раньше 2028 года. Внедрение PCIe 6.0, представленного ещё в январе 2022 года, тоже только-только начинается и займёт ещё год-два.   Анонсированная почти два года назад оптическая версия PCIe продолжает разрабатываться. В PCIe 7.0 и PCIe 6.4 впервые были добавлены спецификации ретаймеров, которые позволят передавать сигнал PCIe по оптоволокну. Это позволит сделать интерконнект на базе PCIe значительно компактнее, чем при использовании традиционных медных соединений, а также позволит эффективно вывести PCIe за пределы узла. Впрочем, пока что речь идёт скорее о масштабах стойки или нескольких, а не целого ЦОД.
24.12.2024 [15:41], Сергей Карасёв
Sipeed выпустила NanoKVM-PCIe — плату расширения IP-KVM с OLED-дисплеем и Wi-Fi 6Компания Sipeed анонсировала решение NanoKVM-PCIe — плату расширения с интерфейсом PCIe для организации удалённого управления IP-KVM (Keyboard, Video, Mouse). Изделие может применяться в настольных рабочих станциях, а также в стоечных серверах. Новинка представляет собой альтернативу крошечному модулю NanoKVM, вышедшему летом нынешнего года. В основу NanoKVM-PCIe положен чип Sophgo SG2002, который объединяет два ядра C906 с архитектурой RISC-V (1000 и 700 МГц), одно ядро Arm Cortex-A53, а также контроллер 8051 с частотой от 25–300 МГц. Есть нейропроцессорный блок с производительностью до 1 TOPS (INT8) и 256 Мбайт памяти DDR3. 
Источник изображения: Sipeed Карта располагает слотом microSD, интерфейсом HDMI с поддержкой видео 1080p60, сетевым портом 10/100MbE RJ45 с опциональной поддержкой PoE, а также двумя разъёмами USB Type-C. Дополнительно в оснащение может быть включён адаптер Wi-Fi 6 с коннектором для антенны. Особенность NanoKVM-PCIe заключается в наличии небольшого информационного OLED-дисплея с диагональю 0,49″ и разрешением 64 × 32 точки: этот экран расположен на монтажной планке. Плата имеет низкопрофильное исполнение с габаритами 66 × 57 × 18 мм. Питание (0,2 A / 5 В) может подаваться через слот PCIe, порт USB Type-C или посредством PoE. Применяется прошивка с поддержкой управления UEFI/BIOS, эмулированными USB-мышью/клавиатурой и USB-накопителем, IPMI, WoL, Tailscale, WebSSH и пр. компания Sipeed принимает предварительные заказы на новинку по цене от $42 до $58 в зависимости от выбранных опций.
06.12.2024 [12:00], Руслан Авдеев
Новая веха: консорциум PCI-SIG теперь включает 1000 компаний со всего мираКонсорциум PCI-SIG — организация, ответственная за разработку и распространение стандарта PCI Express (PCIe), объявила о достижении важной вехи — теперь в её составе насчитывается тысяча компаний. Как сообщает пресс-служба организации, технология PCIe, представленная ещё в 2003 году, в последнее время стала ключевым IO-стандартом, а в 2022 году PCI-SIG отметила 30-летие своей инновационной деятельности. В следующем году планируется представить новейший стандарт PCIe 7.0. По словам главы PCI-SIG Эла Янеса (Al Yanes), в последние 32 года именно многообразие участников консорциума позволило создать надёжный, универсально совместимый (в том числе обратно совместимый) интерфейс. Ожидается, что его внедрение продолжится и в новых сферах ИИ и машинного обучения (ML), а также HPC-вычислений в целом. 
Источник изображения: DESIGNECOLOGIST/unsplash.com PCI-SIG уже разработала разнообразные технологии и спецификации PCI, а также шесть поколений интерфейса PCIe. В числе наиболее актуальных инноваций — представленные в 2024 году спецификации кабелей CopprLink для внутренних и внешних соединений, а также создание рабочих групп, изучающих оптические соединения. Участники PCI-SIG получают:
Участие в PCI-SIG свободно, о преимуществах и условиях вступления можно узнать на сайте компании или в её социальных сетях. Ещё в июне 2024 года сообщалось, что разработка и внедрение новых стандартов PCI Express не ускорятся, но PCI-SIG не видит в этом проблемы.
03.07.2024 [23:49], Сергей Карасёв
Panmnesia расширит память GPU с помощью DRAM или даже SSDЮжнокорейский стартап Panmnesia сообщил о разработке специализированного CXL-решения, которое позволяет расширять встроенную память ускорителей на базе GPU путём подключения внешних блоков DRAM или даже SSD. Отмечается, что современным приложениям ИИ и НРС требуется значительный объём быстрой памяти, но возможности ускорителей в этом плане ограничены. Сложность расширения памяти актуальных ускорителей заключается в том, что в таких изделиях отсутствуют логическая структура CXL и компоненты, поддерживающие DRAM и/или SSD. Кроме того, подсистемы кеша и памяти GPU не распознают никаких расширений. В лучшем случае предлагается механизм унифицированной виртуальной памяти (UVM) для совместного доступа к содержимому памяти и CPU, и GPU. Однако этот механизм довольно медленный. 
Источник изображений: Panmnesia Panmnesia обошла существующие ограничения путём создания собственного root-комплекса, совместимого со стандартом CXL 3.1 и предоставляющего несколько root-портов. Он и обеспечивает поддержку внешней памяти через PCIe. При этом задействован особый декодер HDM (Host-managed Device Memory), отвечающий за работу с адресными пространствами. Это сложное решение в каком-то смысле «обманывает» подсистему памяти ускорителя, заставляя ее рассматривать внешнюю PCIe-память как доступную напрямую. 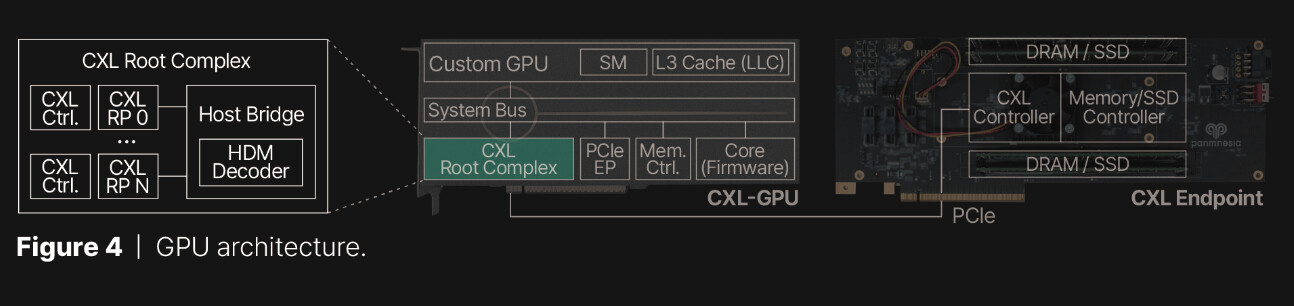 Прототип, основанный на кастомизированном GPU, в ходе тестов продемонстрировало задержки менее 100 нс при передаче данных в обоих направлениях. При этом решение Panmnesia предоставляет более гранулярный доступ к памяти в сравнении с UVM. Быстродействие CXL-системы Panmnesia оказалось в 3,22 раза выше в пересчёте на IPC по сравнению с UVM.
18.06.2024 [22:45], Алексей Степин
Обещанного три года ждут: разработка и внедрение новых стандартов PCI Express не ускорятся, но PCI-SIG не видит в этом проблемыНа недавно прошедшей конференции PCI-SIG Developers Conference 2024 вице-президент группы, Ричард Соломон (Richard Solomon) рассказал о разработке новых версий стандарта PCI Express. Создание новых стандартов вышло на устоявшийся трехлётний цикл, но в данном случае имплементация и выход на массовый рынок не равны собственно разработке очередной версии PCIe. Приблизительно за три года PCI-SIG успевает разработать, внести корректировки, согласовать все нюансы со всеми участниками консорциума и опубликовать спецификации нового стандарта. Но после этого необходимо получить первые образцы «кремния» с его поддержкой и провести все необходимые квалификационные процедуры. Одна только фаза «тестирования на соответствие» (FYI, First Year Inventory Compliance Program) занимает полгода. 
Источник здесь и далее: PCI-SIG Главной причиной достаточно длительного цикла, отметил вице-президент PCI-SIG, является время от окончания работы над спецификациями до получения готовых ASIC, без которых невозможно начать полномасштабное тестирование. Таким образом, формально появившийся в начале 2022 года стандарт PCIe 6.0 лишь в июне 2024 года добрался до фазы FYI. При этом первый дизайн (только на бумаге, конечно) IP-блоков для PCIe 6.0 появился ещё даже до финализации стандарта.  Более того, спецификации PCIe 6.0 в скором времени снова будут обновлены для поддержки нового стандарта оптических соединений, которые, впрочем, не заменят, а дополнят традиционные медные соединения. Финализация правок ожидается в декабре текущего года. Кроме того, появится поддержка и новых кабелей CopprLink. Так что на выход PCIe 6.0 на рынок стоит рассчитывать где-то в начале 2025 года.  Конечно, хотелось бы привести цикл разработки PCI Express в соответствии с циклами других производителей, включая разработчиков Ethernet, Infiniband и CXL, но состав PCI-SIG, насчитывающий уже почти тысячу компаний-участников, продолжает расти, что, конечно, не способствует быстрому согласованию спецификаций и получению всех нужных образцов технологии. Более того, все устройства любого стандарта PCIe обязаны быть совместимы со старыми версиями, вплоть до 1.0.  И весь этот процесс необходимо поддерживать и далее: на середину или конец 2025 года запланирован выпуск финальных спецификаций PCI Express 7.0. Так что FIY-фазы стоит ожидать не ранее 2028 года. При этом проверка устройств нового стандарта на взаимную совместимость, в том числе чисто электрическую, становится всё сложнее с учётом заявленных частот и скоростей и оттого всё более необходимой.  Но даже с трёхлетним циклом разработки, говорит PCI-SIG, пока удаётся опережать требования индустрии. Пропускная способность I/O-систем тоже удваивается примерно каждые три года, но к этому моменту у разработчиков PCIe уже готов и протестирован новый стандарт, покрывающий все разумные потребности и массово реализуемый за разумные деньги.  И сравнивать PCIe, например, с NVLink с этой точки зрения может быть не совсем корректно, поскольку целью PCI-SIG не является достижение предельно высокой производительности любой ценой. Вместо этого группа обеспечивает развитие разумной, совместимой экосистемы решений с наилучшим соотношением цены и возможностей. Это не означает, что в абсолютных значениях решения на базе новых стандартов будут дешевле, но, как отметил вице-президент, экосистема PCIe позволяет разработчикам выбрать приемлемое для каждого случая сочетание характеристик. В настоящее время спецификация PCIe 7.0 версии 0.5 стала доступна участникам PCI-SIG. Новый стандарт доводит скорость передачи данных до 128 ГТ/с на линию при повышении энергоэффективности. Напомним, начиная с PCIe 6.0 доступен режим кодирования Flit, позволяющий избежать накладных расходов при передаче данных, и сделан переход к модуляции PAM4. Оптический вариант PCIe 7.0 тоже появится, но всё ещё будет опциональным. По словам Соломона, разговоры о вынужденном переходе на «оптику» ведутся более десяти лет, но по факту возможностей «меди» всё ещё хватает и будет хватать.
10.05.2024 [11:32], Сергей Карасёв
Суперкомпьютер в стойке GigaIO SuperNODE обзавёлся поддержкой AMD Instinct MI300XКомпания GigaIO анонсировала новую модификацию системы SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Суперкомпьютер в стойке теперь может комплектоваться ускорителями AMD Instinct MI300X, благодаря чему значительно повышается производительность при работе с большими языковыми моделями (LLM). Решение SuperNODE, напомним, использует фирменную архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE даёт возможность более эффективно использовать ресурсы. Изначально для SuperNODE предлагались конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100. Новая версия допускает использование 32 изделий Instinct MI300X. Утверждается, что архитектура FabreX в сочетании с технологией интерконнекта AMD Infinity Fabric наделяет систему SuperNODE «лучшими в отрасли» возможностями в плане задержек при передаче данных, пропускной способности и управления перегрузками. Это позволяет эффективно справляться с обучением LLM с большим количеством параметров. 
Источник изображения: GigaIO Отмечается, что SuperNODE значительно упрощает процесс развёртывания и управления инфраструктурой ИИ. Традиционные конфигурации обычно включают в себя сложную сеть и необходимость синхронизации нескольких серверов, что создаёт определённые технических сложности и приводит к дополнительным временным затратам. Конструкция SuperNODE с 32 мощными ускорителями в рамках одной системы позволяет решить указанные проблемы.
04.04.2024 [22:34], Александр Бенедичук
Полстандарта: опубликована спецификация PCIe 7.0 версии 0.5Организация PCI-SIG опубликовала первую полную предварительную версию спецификаций грядущего стандарта PCI Express 7.0. Таким образом, будущий интерфейс, который удвоит пропускную способность по сравнению с PCIe 6.0, стал на шаг ближе к воплощению в реальных продуктах. В блоге президента PCI-SIG Эла Янеса ( Al Yanes) говорится: «Продолжается работа над спецификацией PCI Express (PCIe) 7.0, которую PCI-SIG анонсировала на конференции разработчиков в США в июне 2022 года. Благодаря напряженной работе наших технических групп, мы рады сообщить, что версия 0.5 теперь доступна для ознакомления. Это официальный первый вариант спецификации, учитывающий все отзывы, которые мы получили от пользователей после выхода версии 0.3 в июне 2023 года». 
Источник изображения: PCI-SIG Янес говорит, что PCIe 7.0 ориентирован на 800GbE-решения, систем ИИ и машинного обучения, дата-центры гиперскейлеров и облака, HPC и квантовые вычисления. Отличительными чертами нового стандарта станут:
Публикация финальной версии спецификации запланирована на 2025 год. Ожидается, что программа для проверки соответствия стандарту PCIe 7.0 будет доступна в 2027 году, а продукты будут выпущены после этого.
17.11.2023 [21:46], Алексей Степин
PCI-SIG выпустила предварительные спецификации PCIe 7.0 и анонсировала кабели CopprLinkОрганизация PCI Special Interest Group (PCI-SIG) рассказала о последних планах по развитию интерфейса PCI Express. В числе прочего были опубликованы сведения о новом стандарте кабелей и разъёмов CopprLink для подключений PCIe 5.0/6.0. Основанная в 1992 году организация PCI-SIG опубликовала первые спецификации PCI Express в 2003 году, а сегодня без этого интерфейса невозможно представить себе ни одну мало-мальски мощную вычислительную систему. В PCI-SIG на данный момент входит свыше 950 участников. Планы по развитию PCI Express, простирающиеся до 2028 года, показывают, что разработка новых, более производительных версий шины идёт темпами, позволяющими удовлетворить требования к скорости IO-подсистем, удваивающиеся примерно каждые 3 года. В версии PCIe 7.0 планируется довести этот показатель для x16-подключений до 512 Гбайт/с. Предварительная версия стандарта (релиз 0.3) была сформирована совсем недавно. 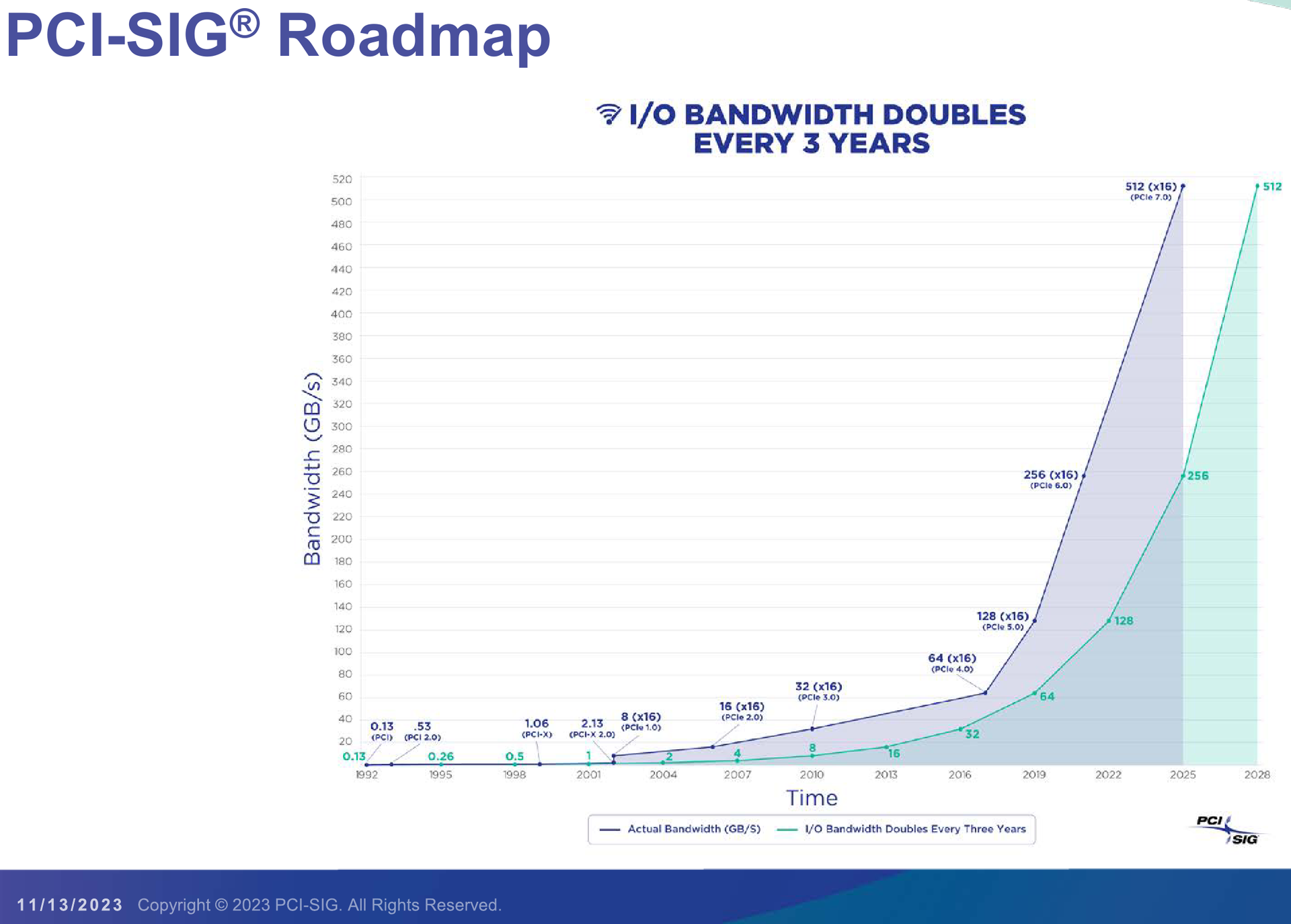
Источник изображений здесь и далее: PCI-SIG На данный момент релиз спецификаций PCI Express 7.0 ожидается в 2025 году, а массовое появление новых продуктов на их основе запланировано на 2028 год. Впрочем, первые продукты наверняка появятся чуть раньше. Во II квартале 2024 года ожидается появление первых решений с PCIe 6.0, а массовый характер программа тестирования таких устройств на соответствие стандарту примет лишь в 2025.  В августе этого года была сформирована новая рабочая группа PCI-SIG Optical Workgroup, ответственная за разработку оптического интерконнекта на базе PCI Express и взаимодействие с производителями в этой области. Задача заключается в адаптации стека технологий PCIe к оптической среде передачи данных с минимальными изменениями. Новые кабели позволят организовать соединения между стойками в пределах ЦОД в случаях, когда требуется минимальная латентность.  Однако полная замена медных кабелей не планируется — оптика дополнит медь там, где нужна большая длина соединения. Поэтому PCI-SIG ведёт разработку нового стандарта электрических кабелей под общим названием CopprLink, который должен будет заменить существующие кабели OCuLink. Возможностей последних для организации внутрисистемного интерконнекта в современных условиях уже не всегда достаточно.  Новые серверы и СХД требуют более высокой пропускной способности и гибкости топологии, что учитывается при разработке CopprLink. Эти кабели позволят как обеспечивать высокоскоростные подключения в пределах самих систем, так и соединять между собой шасси в пределах стойки. Разрабатываются и варианты для межстоечного соединения.  Вопреки непроверенным слухам, CopprLink не поддерживает передачу сколько-нибудь мощного питания и не является заменой стандарту 12VHPWR. В настоящее время спецификации CopprLink, обеспечивающего работу на скоростях PCIe 5.0/6.0, уже достигли версии 0.9. Полноценный анонс технологии должен состояться в начале 2024 года. 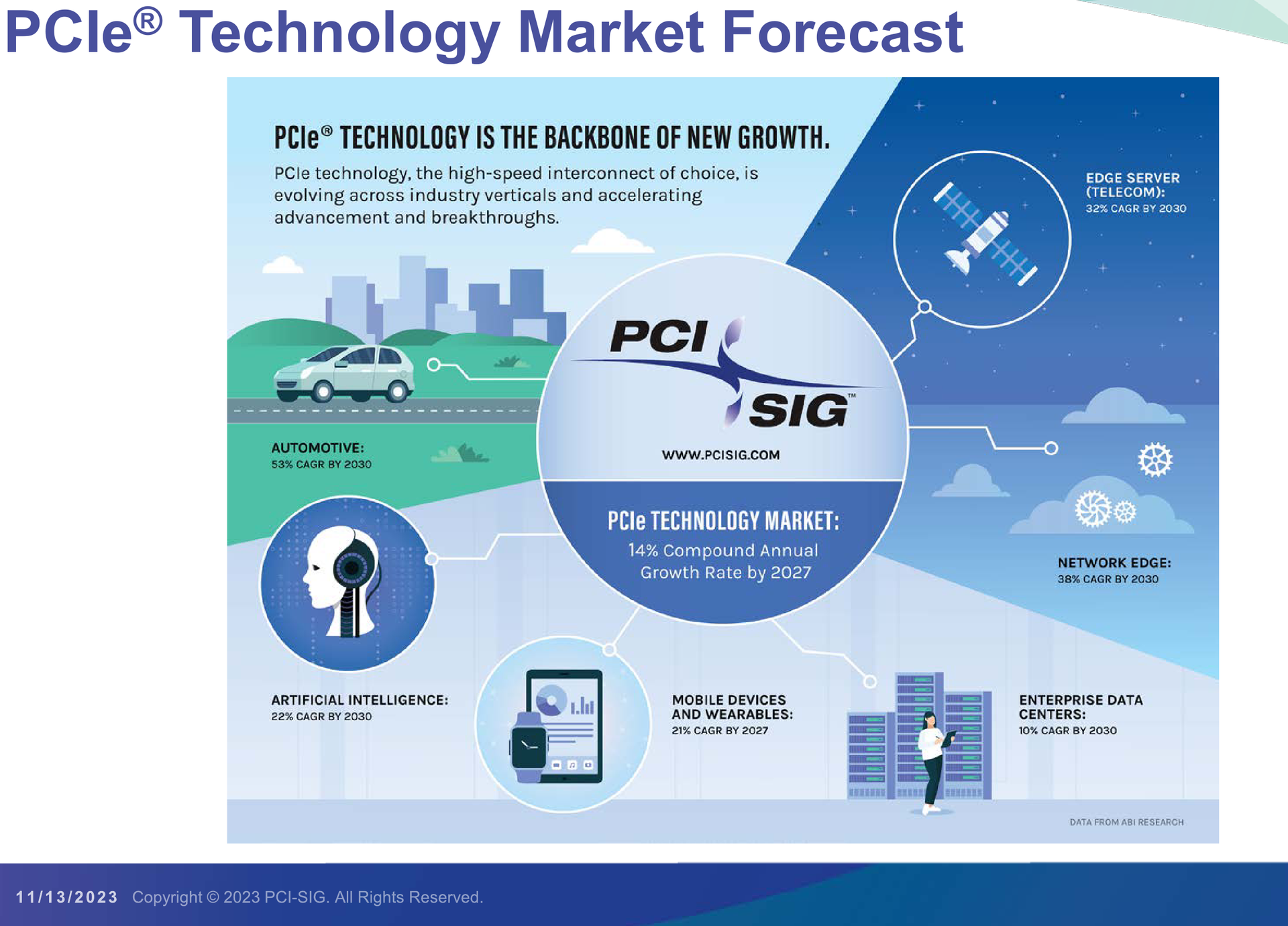 Технология PCI Express востребована во многих сегментах, от традиционных серверов и ПК до крупных ЦОД, телеком-платформ, ИИ-кластеров, умного транспорта и даже в мобильных и носимых устройствах. Ожидается, что в период до 2027 показатель CAGR для рынка PCIe-решений составит 14 %, а к концу периода он достинет объёма $10 млрд. Быстрее всего развитие будет идти в секторе автомобильных решений (CAGR 53 % до 2030 года), периферийных сетевых (38 %) и телекоммуникационных (32 %) платформ.
11.11.2023 [23:59], Алексей Степин
СуперДупер: GigaIO SuperDuperNODE позволяет объединить посредством PCIe сразу 64 ускорителяКомпания GigaIO, чьей главной разработкой является система распределённого интерконнекта на базе PCI Express под названием FabreX, поставила новый рекорд — в новой платформе разработчикам удалось удвоить количество одновременно подключаемых PCIe-устройств, увеличив его с 32 до 64. О разработках GigaIO мы рассказывали читателям неоднократно. Во многом они действительно уникальны, поскольку созданная компанией композитная инфраструктура позволяет подключать к одному или нескольким серверам существенно больше различных ускорителей, нежели это возможно в классическом варианте, но при этом сохраняет высокий уровень утилизации этих ускорителей. 
GigaIO SuperNODE. Источник изображений здесь и далее: GigaIO В начале года компания уже демонстрировала систему с 16 ускорителями NVIDIA A100, а летом GigaIO представила мини-кластер SuperNODE. В различных конфигурациях система могла содержать 32 ускорителя AMD Instinct MI210 или 24 ускорителя NVIDIA A100, дополненных СХД ёмкостью 1 Пбайт. При этом система в силу особенностей FabreX не требовала какой-либо специфической настройки перед работой. 
FabreX позволяет физически объединить все типы ресурсов на базе существующего стека технологий PCI Express На этой неделе GigaIO анонсировала новый вариант своей HPC-системы, получившей незамысловатое название SuperDuperNODE. В ней она смогла удвоить количество ускорителей с 32 до 64. Как и прежде, система предназначена, в первую очередь, для использования в сценариях генеративного ИИ, но также интересна она и с точки зрения ряда HPC-задач, в частности, вычислительной гидродинамики (CFD). Система SuperNODE смогла завершить самую сложную в мире CFD-симуляцию всего за 33 часа. В ней имитировался полёт 62-метрового авиалайнера Конкорд. Хотя протяжённость модели составляет всего 1 сек, она очень сложна, поскольку требуется обсчёт поведения 40 млрд ячеек объёмом 12,4 мм3 на протяжении 67268 временных отрезков. 29 часов у системы ушло на обсчёт полёта, и ещё 4 часа было затрачено на рендеринг 3000 4К-изображений. С учётом отличной масштабируемости при использовании SuperDuperNODE время расчёта удалось сократить практически вдвое. Как уже упоминалось, FabreX позволяет малой кровью наращивать число ускорителей и иных мощных PCIe-устройств на процессорный узел при практически идеальном масштабировании. Обновлённая платформа не подвела и в этот раз: в тесте HPL-MxP пиковый показатель утилизации составил 99,7 % от теоретического максимума, а в тестах HPL и HPCG — 95,2 % и 88 % соответственно. Компания-разработчик сообщает о том, что программное обеспечение FabreX обрело завершённый вид и без каких-либо проблем обеспечивает переключение режимов SuperNODE между Beast (система видна как один большой узел), Swarm (множество узлов для множества нагрузок) и Freestyle Mode (каждой нагрузке выделен свой узел с заданным количеством ускорителей). Начало поставок SuperDuperNODE запланировано на конец года. Партнёрами, как и в случае с SuperNODE, выступят Dell и Supermicro. |
|

