Материалы по тегу: ethernet
|
17.07.2024 [11:01], Сергей Карасёв
2.5GbE в формате M.2: Cervoz выпустила крошечный адаптер MEC-LAN-2631iКомпания Cervoz анонсировала изделие MEC-LAN-2631i — миниатюрный сетевой адаптер 2.5GbE, ориентированный на применение в промышленной и коммерческой сферах. Изделие может монтироваться, например, во встраиваемые системы или индустриальные компьютеры. Новинка состоит из модуля формата M.2 2230, использующего интерфейс PCIe 2.1 x1 (до 5,0/2,5 GT/s). Этот модуль при помощи кабеля соединяется с крошечным блоком, оснащённым разъёмом RJ-45. Задействован контроллер Intel I226-IT: поддерживаются режимы 10/100/1000/2500MbE. Применяется универсальный монтажный механизм Cervoz MECFIX, разработанный для плат расширения MEC. Он совместим со стандартными и низкопрофильными планками PCI/PCIe. Кроме того, возможно крепление внутри системы в любом положении и под любым углом. 
Источник изображения: Cervoz Для решения MEC-LAN-2631i заявлена совместимость со стандартами IEEE 802.3, IEEE802.3u, IEEE 802.3ab, IEEE 802.3z и IEEE 802.3bz. Поддерживается функция Wake-on-LAN. Диапазон рабочих температур простирается от -40 до +85 °C. Cervoz предоставляет драйверы для Windows 10 и Windows 11, но, изделие также должно быть совместимо с Linux. Гарантия производителя — три года. Заявленное энергопотребление составляет примерно 1,16 Вт.
02.07.2024 [23:55], Алексей Степин
15 тыс. ускорителей на один ЦОД: Alibaba Cloud рассказала о сетевой фабрике, используемой для обучения ИИAlibaba Cloud раскрыла ряд сведений технического характера, касающихся сетевой инфраструктуры и устройства своих дата-центров, занятых обработкой ИИ-нагрузок, в частности, обслуживанием LLM. Один из ведущих инженеров компании, Эньнань Чжай (Ennan Zhai), опубликовал доклад «Alibaba HPN: A Data Center Network for Large Language Model Training», который будет представлен на конференции SIGCOMM в августе этого года. В качестве основы для сетевой фабрики Alibaba Cloud выбрала Ethernet, а не, например, InfiniBand. Новая платформа используется при обучении масштабных LLM уже в течение восьми месяцев. Выбор обусловлен открытостью и универсальностью стека технологий Ethernet, что позволяет не привязываться к конкретному вендору. Кроме того, меньше шансы пострадать от очередных санкций США. Отмечается, что традиционный облачный трафик состоит из множества относительно небыстрых потоков (к примеру, менее 10 Гбит/с), тогда как трафик при обучении LLM включает относительно немного потоков, имеющих периодический характер со всплесками скорости до очень высоких значений (400 Гбит/с). При такой картине требуются новые подходы к управлению трафиком, поскольку традиционные алгоритмы балансировки склонны к перегрузке отдельных участков сети. 
Источник здесь и далее: Alibaba Cloud Разработанная Alibaba Cloud альтернатива носит название High Performance Network (HPN). Она учитывает многие аспекты работы именно с LLM. Например, при обучении важна синхронизация работы многих ускорителей, что делает сетевую инфраструктуру уязвимой даже к единичным точкам отказа, особенно на уровне внутристоечных коммутаторов. Alibaba Cloud использует для решения этой проблемы парные коммутаторы, но не в стековой конфигурации, рекомендуемой производителями. 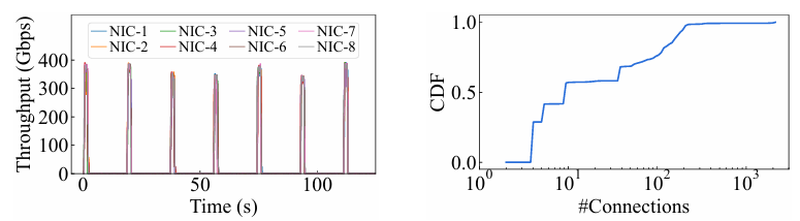
Характер трафика при обучении LLM Каждый хост содержит восемь ИИ-ускорителей и девять сетевых адаптеров. Каждый из NIC имеет по паре портов 200GbE. Девятый адаптер нужен для служебной сети. Между собой внутри хоста ускорители общаются посредством NVLink на скорости 400–900 Гбайт/с, а для общения с внешним миром каждому из них полагается свой 400GbE-канал с поддержкой RDMA. При этом порты сетевых адаптеров подключены к разным коммутаторам из «стоечной пары», что серьёзно уменьшает вероятность отказа. 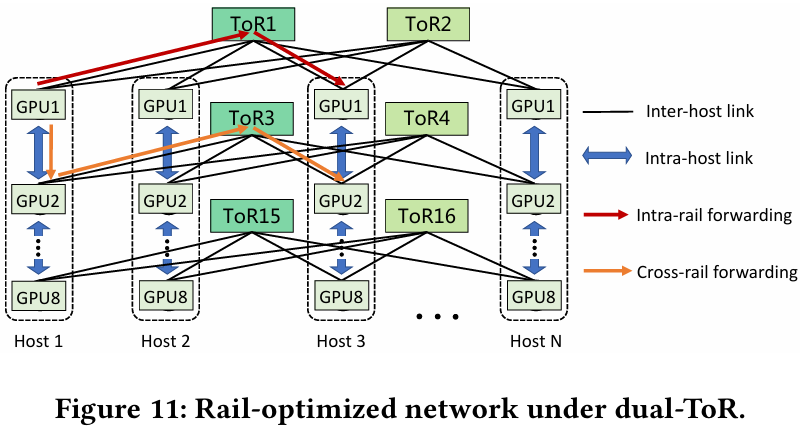 В докладе говорится, что Alibaba Cloud использует современные одночиповые коммутаторы с пропускной способностью 51,2 Тбит/с. Этим условиям отвечают либо устройства на базе Broadcom Tomahawk 5 (март 2023 года), либо Cisco Silicon One G200 (июнь того же года). Судя по использованию выражения «начало 2023 года», речь идёт именно об ASIC Broadcom. 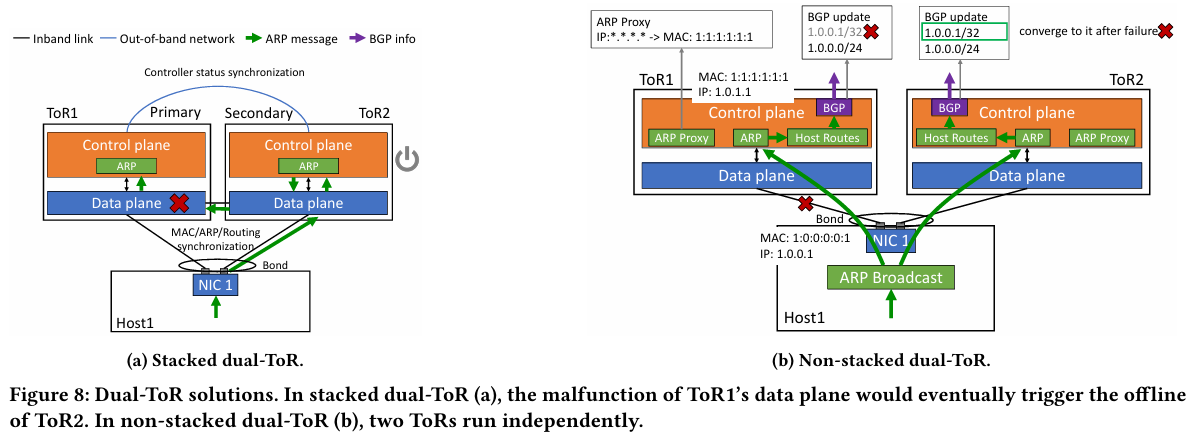 Своё предпочтение именно одночиповых коммутаторов компания объясняет просто: хотя многочиповые решения с большей пропускной способностью существуют, в долгосрочной перспективе они менее надёжны и стабильны в работе. Статистика показывает, что аппаратные проблемы у подобных коммутаторов возникают в 3,77 раза чаще, нежели у одночиповых. 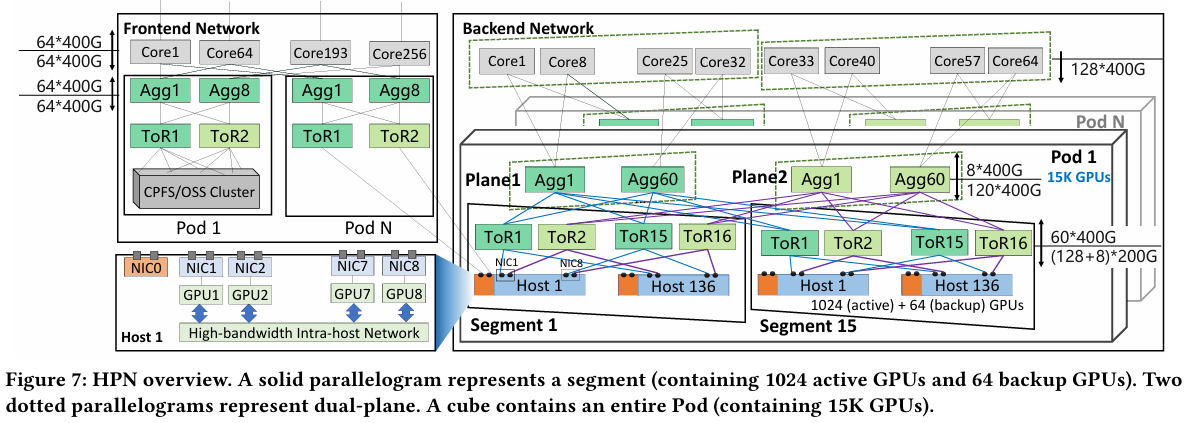 Одночиповые решения класса 51,2 Тбит/с выделяют много тепла, но ни один поставщик оборудования не смог предложить Alibaba Cloud готовые решения, способные удерживать температуру ASIC в пределах 105 °C. Выше этого порога срабатывает автоматическая защита. Поэтому для охлаждения коммутаторов Alibaba Cloud создала собственное решение на базе испарительных камер. 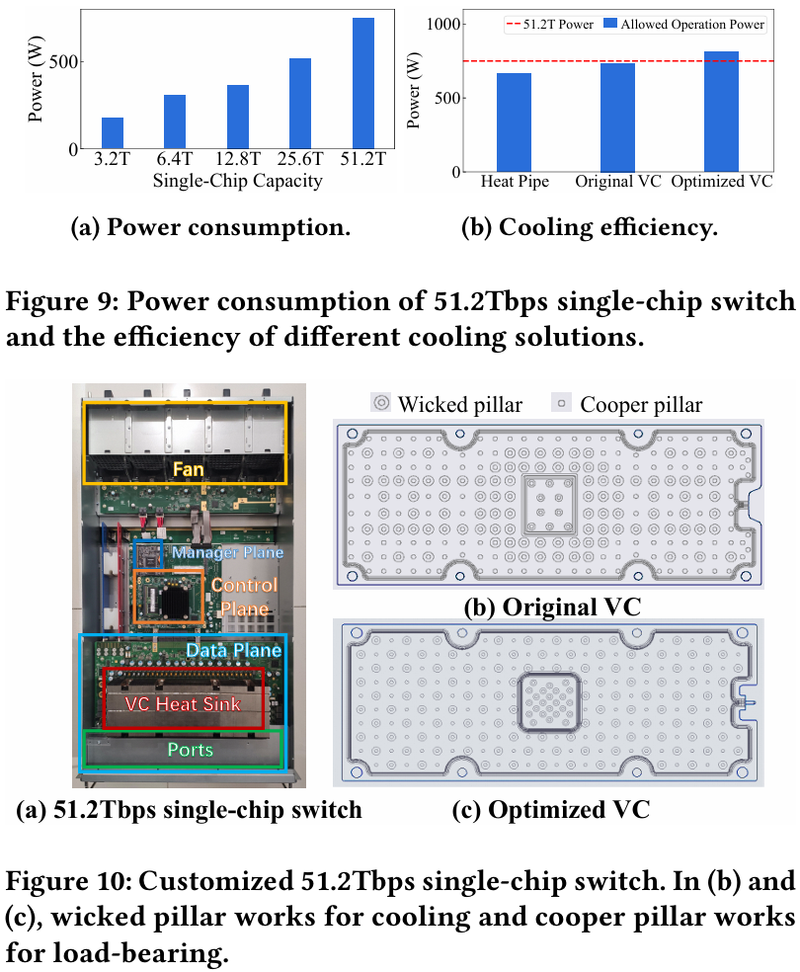 Сетевая фабрика позволяет создавать кластеры, каждый из которых содержит 15360 ускорителей и располагается в отдельном здании ЦОД. Такое высокоплотное размещение позволяет использовать оптические кабели длиной менее 100 м и более дешёвые многомодовые трансиверы, которые дешевле одномодовых примерно на 70 %. Ёмкость такого дата-центра составляет около 18 МВт. 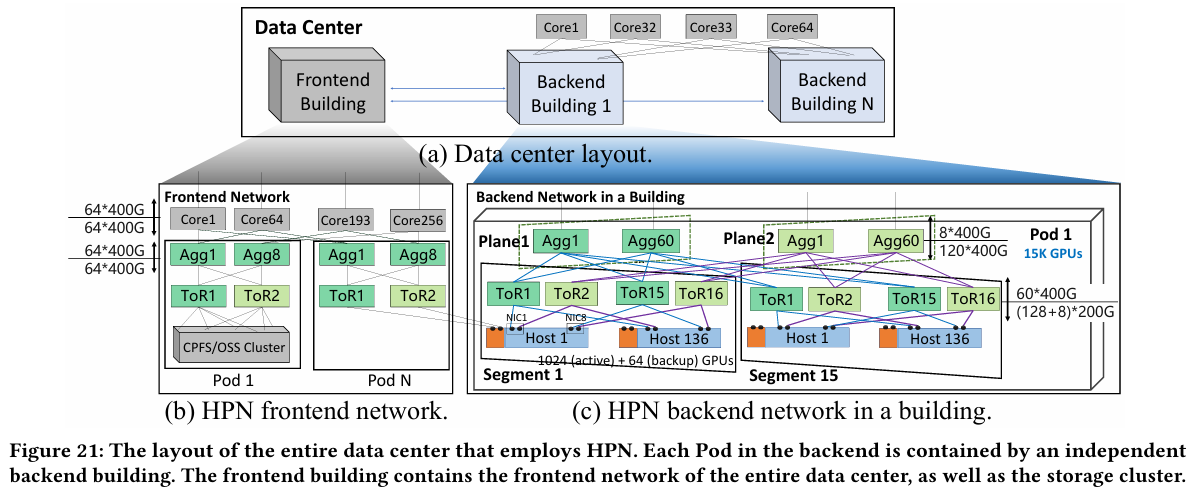 Но есть у HPN и недостаток: использование топологии с двумя внутристоечными коммутаторами и другие особенности архитектуры усложняют кабельную подсистему, поэтому инженеры поначалу столкнулись с ростом ошибок при подключении сетевых интерфейсов. В настоящее время активно используются тесты, позволяющие проверить каждое подключение на соответствие идентификаторов портов и коммутаторов рабочим схемам. Отмечается, что параметры Ethernet-коммутаторов удваиваются каждые два года, поэтому компания уже разрабатывает сетевую архитектуру следующего поколения, рассчитанную на применение будущих ASIC 102,4 Тбит/с. По словам Alibaba Cloud, обучение LLM с сотнями миллиардов параметров потребует огромного распределённого кластера, количество ускорителей в котором исчисляется миллионами. И ему требуется соответствующая сетевая инфраструктура.
02.07.2024 [12:10], Сергей Карасёв
Dell'Oro: продажи кампусных Ethernet-коммутаторов рухнули на 23 %По оценкам Dell'Oro Group, выручка от реализации кампусных Ethernet-коммутаторов в I квартале 2024 года в глобальном масштабе сократилась практически на четверть — на 23 % — по сравнению с аналогичным периодом предыдущего года. В результате объём рынка достиг двухлетнего минимума. Говорится, что снижение спроса зафиксировано во всех регионах, за исключением Центральной и Латинской Америки (CALA). Отмечается сокращение отгрузок портов практически всех типов. Кроме того, в годовом исчислении снизилась средняя стоимость коммутаторов. 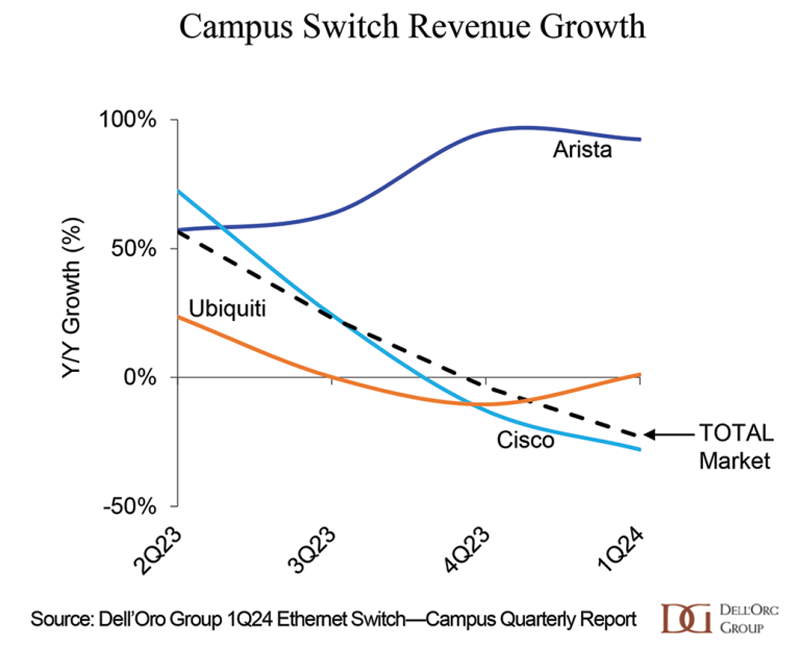
Источник изображения: Dell'Oro Group Среди ведущих игроков названы Arista Networks, Cisco и Ubiquiti. У первой из названных компаний выручка от поставок кампусных Ethernet-коммутаторов в I четверти 2024-го поднялась более чем на 80 % год к году. Третий квартал подряд Arista наращивает рыночную долю. Ubiquiti также смогла незначительно увеличить объём реализации. У Cisco продажи, напротив, резко сократились: падение в годовом исчислении превысило 25 %. Годом ранее Cisco продемонстрировала существенный рост, связанный с удовлетворением отложенного спроса. В исследовании отмечается, что некоторые поставщики кампусных Ethernet-коммутаторов в I квартале 2024 года смогли увеличить среднюю стоимость портов благодаря расширению ассортимента продукции. Прогнозируется, что спрос на устройства с поддержкой 5GbE-портов увеличится на фоне роста востребованности точек доступа стандарта Wi-Fi 7.
22.03.2024 [21:10], Сергей Карасёв
Консорциум Ultra Ethernet пополнился 45 участниками, но NVIDIA среди них так и нетКонсорциум Ultra Ethernet объявил о том, что в его состав вошли 45 новых участников. Таким образом, на сегодняшний день общее количество членов этой организации достигает 55. К участию в Ultra Ethernet приглашаются и другие заинтересованные компании и институты. Напомним, консорциум был создан в июле 2023 года. Его задача заключается в разработке основанной на Ethernet открытой высокопроизводительной архитектуры с полным коммуникационным стеком, отвечающей задачам современных рабочих нагрузок ИИ и НРС. Изначально в состав Ultra Ethernet входили AMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft. Позднее к консорциуму присоединилась компания Cornelis Networks, поставщик HPC-интерконнекта на базе Omni-Path. 
Источник изображения: Ultra Ethernet С ноября 2023-го организация начала принимать новых участников в массовом порядке. С тех пор инициативу поддержали Nokia, Lenovo, Baidu, Dell, Huawei, IBM, Supermicro, Tencent и многие другие компании. Примечательно, что в списке участников так и нет AWS, Google и NVIDIA. Последняя по-прежнему считает InfinBand лучшим интерконнектом для HPC/ИИ-кластеров и является фактически единственным поставщиком данной технологии. Более того, даже Ethernet-решения NVIDIA подвергаются критике со стороны конкурентов. 
Источник изображения: Ultra Ethernet Для тех, кто заинтересован в работах в рамках проекта, Ultra Ethernet предлагает различные варианты участия через восемь технических групп. В их число, в частности, входят физический, транспортный и программный уровни, хранение, управление, отладка и пр. В настоящее время ведётся активная работа над спецификацией Ultra Ethernet версии 1.0: представить её планируется в III квартале текущего года. Ожидается, что совместная работа десятков IT-компаний в перспективе позволит создать революционные коммуникационные платформы.
22.03.2024 [09:09], Алексей Степин
NVIDIA представила 800G-платформы Quantum-X800 и Spectrum-X800 для InfiniBand- и Ethernet-фабрик нового поколенияДополнением к только что представленным ИИ-ускорителям NVIDIA Blackwell станут новые сетевые 800G-платформы Quantum-X800 и Spectrum-X800, а также сетевые адаптеры ConnectX-8. Именно они позволят вывести масштабирование ИИ-кластеров на новый уровень и позволят «прокормить» гигантские массивы ускорителей в дата-центрах гиперскейлеров. Платформа NVIDIA Quantum-X800 ориентирована на наиболее производительные ИИ- и HPC-кластеры. Она использует новое поколение технологии InfiniBand, всё ещё обладающей рядом преимуществ в сравнении с Ethernet, и включает в себя обновлённые SHARP-движки. Технология SHARPv4 реализует «вычисления в сети» (In-Network Computing), что позволяет не только существенно разгрузить вычислительные узлы и серверы, но и обеспечить более высокую пропускную способность интерконнекта вкупе с более серьёзными возможностями его масштабирования. 
NVIDIA Q3400-RA 4U (справа) и SN5600. Источник изображений здесь и далее: NVIDIA Основой платформы Quantum-X800 стал 4U-коммутатор Q3400-RA, впервые в индустрии, как говорит компания, использующий 200G-блоки SerDes для каждой линии InfiniBand. Коммутатор располагает 144 портами 800G в 72 OSFP-модулях и выделенным портом для Unified Fabric Manager. Новинка имеет стандартное 19″ исполнение с воздушным охлаждением, но есть и вариант Q3400-LD с жидкостным охлаждением, предназначенный для 21″ OCP-стоек. В двухуровневом варианте fat tree коммутаторы позволят объединить 10 368 NIC.  Основным адаптером для новой платформы InfiniBand является ConnectX-8 SuperNIC с интерфейсом PCIe 6.0. Он является частью SHARPv4 и предлагается в однопортовом (OSFP224) и двухпортовом (QSFP112) вариантах и в нескольких форм-факторах, включая OCP 3.0. На платах также имеется разъём SocketDirect на 16 линий PCIe. Также компания представила компоненты NVIDIA LinkX: оптические трансиверы 2xDR4/2xFR4 и активные медные кабели (LACC).  Не забыла NVIDIA и про Ethernet: здесь вывести производительность сети на новый уровень должна платформа Spectrum-X800. Её основой служит новейший коммутатор SN5600 — это, по словам NVIDIA, первый в мире Ethernet-коммутатор класса 800GbE, специально разработанный для применения гиперскейлерами в крупных облачных ИИ-комплексах. Применяемая архитектура позволяет гарантировать каждому клиенту оптимальный и постоянный уровень производительности, а потоковая телеметрия позволит находить и ликвидировать возможные «бутылочные горлышки» в сети буквально на лету.  Общая пропускная способность SN5600 составляет 51,2 Тбит/с. Коммутатор располагает 64 портами 800GbE в формате OSFP. В нём используется ASIC пятого поколения на базе архитектуры Spectrum-4. В качестве основного адаптера предлагается SuperNIC на базе DPU BlueField-3 с двумя 400GbE-портами. 
Фото: Twitter/NVIDIANetworkng Spectrum-X800 сопровождает полноценный спектр инфраструктурных компонентов, включая кабели DAC и LACC. С оптическими трансиверами длина соединения 800GbE может достигать двух километров. Начиная со следующего года, решения на базе новых сетевых платформ NVIDIA будут доступны от широкого круга поставщиков оборудования, включая Aivres, DDN, Dell Technologies, Eviden, Hitachi Vantara, HPE, Lenovo, Supermicro и VAST Data.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ.
17.08.2023 [20:16], Алексей Степин
Brocade представила новые FC64-продукты — 512-портовый директор X7 и Ethernet-мост 7850 Extension SwitchПодразделение Brocade Storage Networking компании Broadcom представило новые коммутаторы класса Director, предлагающие до 512 портов FC64. Предельная пропускная способность заявлена на уровне 39,6 Тбайт/с. При этом сохранена совместимость с предыдущими поколениями Fibre Channel. Кроме того, был представлен и новый мост Ethernet ↔ Fibre Channel, который позволяет создавать распределённые SAN. Новые устройства серии Brocade X7 Directors являются наиболее высокоплотными в индустрии — они представлены в вариантах с 256 и 512 портами Fibre Channel седьмого поколения (64 Гбит/с на порт) в исполнениях 8U и 14U соответственно. Первое поколение X7 увидело свет ещё в 2020 году, но тогда оно было ограничено использованием 48-портовых лезвий FC64, что давало максимум 384 порта. Новый вариант использует новые 64-портовые модули с трансиверами SFP-DD, позволившими на треть поднять плотность портов. Устройства работают под управлением Fabric OS 9.0.x. 
Источник изображений здесь и далее: Broadcom Другой интересной новинкой Brocade является коммутатор Brocade 7850 Extension Switch, делающий более простым построение географически распределённой SAN. По сути, это мост с 24 портами FC64/FICON, обеспечивающий проброс FC-трафика, для чего имеется 16 портов 25/10GbE, а также два WAN-порта 100GbE. WAN-трафик шифруется на лету на полной скорости по алгоритму AES с 256-битным ключом. Имеются механизмы защиты от кибер-атак, а также автоматическая проверка целостности ПО и аппаратного обеспечения. 
20.07.2023 [23:30], Игорь Осколков
AMD, Broadcom, Cisco, Intel и другие вендоры создадут интерконнект Ultra Ethernet для HPC и ИИAMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft в рамках Linux Foundation сформировали новый консорциум Ultra Ethernet Consortium, который намерен создать на базе Ethernet новый масштабируемый и эффективный с точки зрения стоимости коммуникационный стек, ориентированный на высокопроизводительные вычисления (HPC) и ИИ. Иными словами, речь идёт о создании спецификаций интерконнекта нового поколения на базе Ethernet для современных кластеров, облаков и иных платформ. UEC сформировал четыре рабочих группы, ответственных за физический, канальный и транспортный уровни, а также за уровень ПО. Целью же является создание современного сетевого стека, который учитывает потребности HPC- и ИИ-нагрузок, включая новые методы борьбы с заторами в сети, высокий уровень утилизации канала (в том числе 800G/1.6T), многопутевую и гарантированную доставку, сквозную телеметрию, консистентность и низкий уровень задержек, автоматизацию, безопасность и защищённость, масштабируемость, стабильность, надёжность, снижение TCO и так далее. 
Источник: Ultra Ethernet Consortium Фактически отдельные вендоры уже наделили рядом перечисленных свойств свои продукты, однако унификация и объединение усилий, как считается, должны пойти на пользу всем. Всем, кроме, по-видимому, NVIDIA, которой в списке основателей UEC нет (как и Marvell, к слову). NVIDIA после поглощения Mellanox фактически стала монополистом на рынке InfiniBand, который она активно продвигает, не забывая, впрочем, и о своём проприетарном интерконнекте NVLink, который в последней своей версии выбрался за пределы узла. Справедливости ради — про Ethernet компании тоже не забывает. В обзоре UEC аккуратно критикуется и InfiniBand, и его адаптация в виде RoCE. Авторы указывают на правильность и успешность идеи RDMA, но жалуются на не слишком высокую практичность и удобство современных реализаций. И именно поэтому они первым делом предлагают внедрить новый транспортный протокол Ultra Ethernet Transport (UET), который и позволит реализовать интерконнект будущего, а заодно ещё раз доказать эффективность и гибкость технологии Ethernet, которой в этом году исполнилось 50 лет. Впрочем, это только один из кирпичиков UEC. Примечательно, что первые продукты на базе новых спецификаций обещали показать уже в 2024 году.
25.06.2023 [16:53], Алексей Степин
Cisco представила ASIC Silicon One G200: 51,2 Тбит/с для ИИКомпания Cisco успешно выпустила новые ASIC для сетевых коммутаторов с производительностью 51,2 Тбит/с. Как заявляют разработчики, коммутаторы на базе чипа серии G200 способны объединить в единый комплекс 32 тыс. ускорителей. Новое решение входит в портфолио Cisco Silicon One и изначально нацелено на рынок гиперскейлеров и создателей ИИ-кластеров. В новом чипе в два раза увеличено количество блоков SerDes с производительностью 112 Гбит/с (с 256 до 512), что и позволило довести общую коммутационную производительность до 51,2 Тбит/с. Доступны конфигурации 64×800GbE, 128×400GbE или 256×200GbE, всё зависит от желаемой плотности размещения и скорости портов. Это, в частности, позволяет избавиться от избыточных уровней в топологии сети. 
Источник изображений: Cisco Cisco отмечает, что новинка вдвое энергоэффективнее и имеет вдвое меньшую задержку в сравнении с G100. Кроме того, чипы предлагают расширенную телеметрию, поддержку языка P4 для обработки трафика на лету, а также возможность использования современных интерфейсов, в том числе интегрированную оптику или медные кабели длиной до 4 м, чего более чем достаточно для организации связи на уровне стойки. 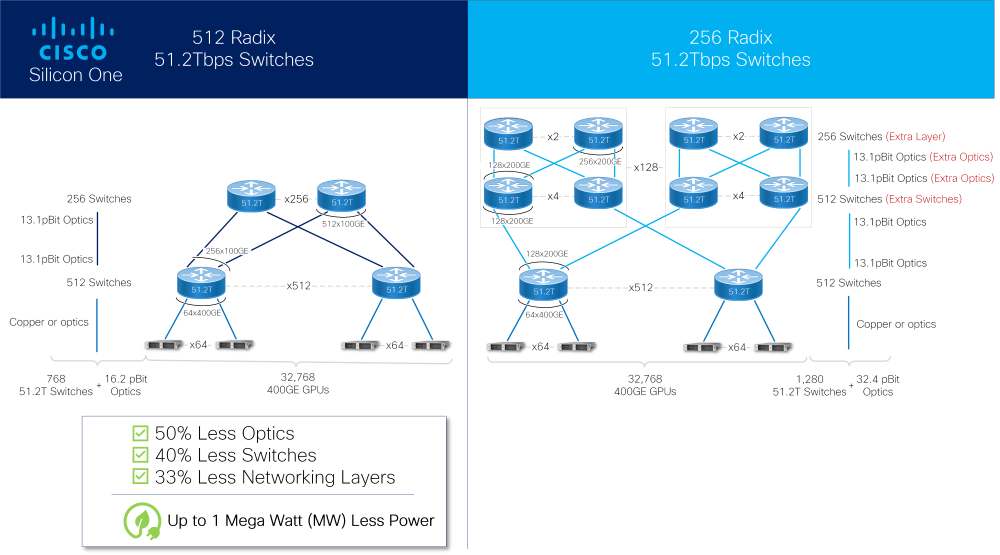 Как и Broadcom Tomahawk-5 или Jericho3-AI, Marvell Teralynx 10 и NVIDIA Spectrum-X, новый чип Cisco содержит возможности, востребованные в среде ИИ-систем, такие как продвинутые средства преодоления заторов в сети (congestion), технологии packet spraying и резервирование линков с возможностью мгновенного восстановления разорванного соединения. Новые чипы серии G200 уже поставляются, но компания пока не назвала даты появления на рынке коммутаторов Cisco на базе нового «кремния».
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 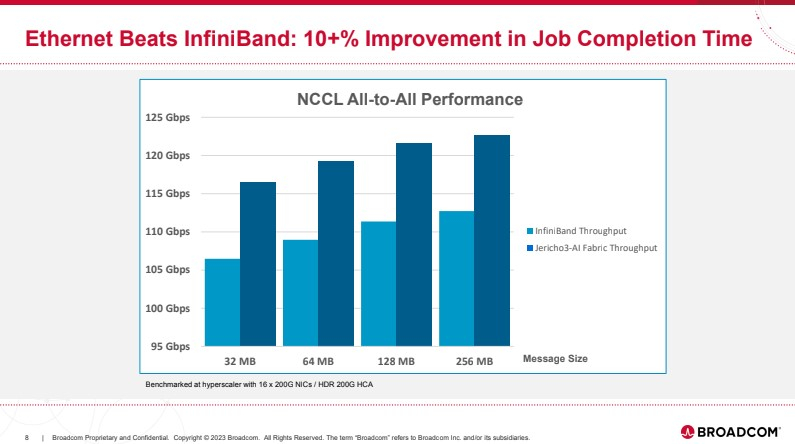 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom. |
|

