Материалы по тегу: b200
|
13.03.2026 [14:12], Руслан Авдеев
Китайская ByteDance обойдёт санкции США и получит доступ к чипам NVIDIA B200 на $2,5 млрдМатеринская компания TikTok — китайская ByteDance — получила доступ к современным американским ускорителям NVIDIA. Она обошла введённые властями США ограничения на доступ к технологиям, заключив соглашение с Aolani Cloud из Юго-Восточной Азии, сообщает The Wall Street Journal. В Малайзии для ByteDance будет развёрнуто около 36 тыс. ИИ-ускорителей NVIDIA B200. Источники сообщают, что Aolani закупает серверы у компании Aivres, занимающейся их сборкой. Последняя, по словам HPE, фактически принадлежит Inspur и уже давно поставляет подсанкционное оборудование в КНР и другие страны. Стоимость оборудования, вероятно, составит более $2,5 млрд. При этом Aolani сообщает, что пока располагает оборудованием на сумму $100 млн. Источники сообщают, что ByteDance намерена организовать исследования в сфере ИИ за пределами КНР и удовлетворить спрос клиентов со всего мира на решения на основе искусственного интеллекта. Уже сегодня она предлагает обычным пользователям разнообразные ИИ-приложения, бросая вызов Google, OpenAI и другим американским компаниям; четверть выручки уже поступает из-за пределов Китая. Так, она разработала более десятка приложений с ИИ-функциями, включая китайские и глобальные версии. 
Источник изображения: Esmonde Yong/unspalsh.com Согласно январскому рейтингу Andreessen Horowitz, компания курирует 5 из 50 наиболее популярных в мире пользовательских ИИ-приложений по количеству ежемесячных активных пользователей. В ByteDance работают команды исследователей в филиалах в Сингапуре и даже США. Напряжённость в отношениях между США и Китаем мешает бизнесу ByteDance: в январе компании пришлось передать американское подразделение TikTok под контроль «дружественно настроенным» к США инвесторам. Более трёх лет китайские технобизнесы имеют дело с американским экспортным контролем, не позволяющим напрямую продавать Китаю передовые ИИ-чипы вроде моделей серии Blackwell. Для развития технологий китайские компании вынуждены тратить всё больше средств на доступ к вычислительным мощностям за рубежом, благодаря чему возникла целая индустрия посредников, строящих ЦОД на продуктах NVIDIA для сдачи в аренду китайским клиентам. По имеющимся данным, в конце 2023 года инвесторы создали компанию Aolani с материнским холдингом на Каймановых островах. В числе инвесторов — сингапурская K3 Ventures. Aolani является приоритетным облачным партнёром NVIDIA, имеющим доступ к её новейшим чипам. С февраля 2025 года Aolani сдаёт ByteDance в аренду ИИ-серверы в Малайзии на основе ускорителей NVIDIA H100. За ускорители Blackwell компания ByteDance уже внесла предварительные платежи. Они будут развёрнуты в Малайзии. Помимо Малайзии, компания намерена создать мощности в Южной Корее, Австралии и Европе. 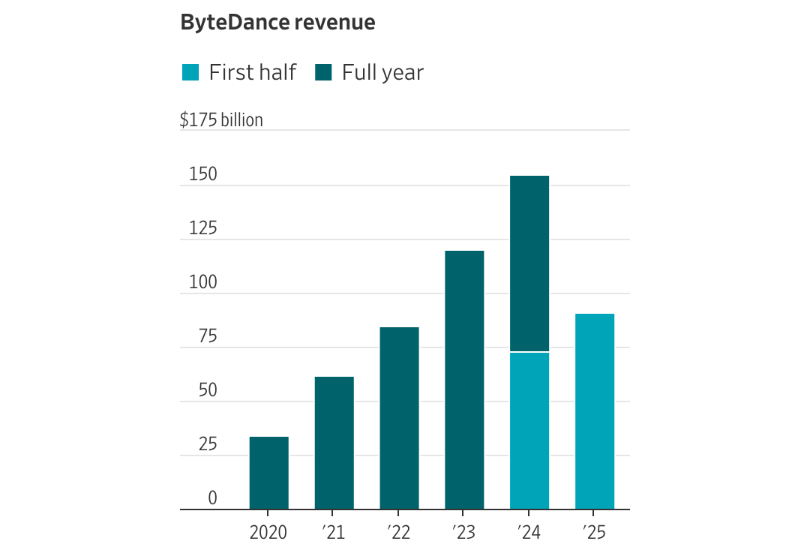
Источник изображения: Bloomberg Подчёркивается, что бизнес сотрудничает с американской юридической компанией, чтобы соответствовать американским требованиям. По мнению юристов, изменения правовых норм будут носить «перспективный, а не ретроспективный характер». Отмечается, что Aolani соблюдает все правила экспортного контроля, а ускорители не передаются клиентам и те не имеют на них никаких прав. В NVIDIA также придерживаются позиции, что американские правила экспорта позволяют создавать облачные сервисы вне стран, подпадающих под ограничения, вроде Китая, а сам вендор проверял всех облачных партнёров, прежде чем продавать чипы прямо или косвенно. По информации The Wall Street Journal, ByteDance вела переговоры об использовании ИИ-серверов с более чем 7 тыс. B200 в ЦОД в Индонезии, а Reuters сообщает, что компания также вела переговоры с США о разрешении покупки ускорителей NVIDIA H200, но её не удовлетворили условия их использования. Ещё в 2024 году сообщалось, что китайские компании нашли лазейку в законах США для доступа к передовым ИИ-ускорителям и моделям в облаках AWS и Azure, причём на территории самих Соединённых Штатов. Также в конце 2025 года появилась информация, что китайская INF Tech обошла санкции США на доступ к ускорителям NVIDIA Blackwell через индонезийское облако.
06.03.2026 [17:01], Руслан Авдеев
Инференс-нагрузки Perplexity прописались в облаке CoreWeaveКомпания CoreWeave объявила о заключении долгосрочного соглашения с Perplexity. Стратегическое партнёрство призвано обеспечить выполнение рабочих ИИ-нагрузок последней, также предусмотрено пилотное внедрение в обеих организациях новых сервисов. Утверждается, что CoreWeave позволяет клиентам переходить от разработки непосредственно к внедрению без перепроектирования систем и инструментов. Соглашение предусматривает, что платформа CoreWeave будет использоваться Perplexity для инференса нового поколения. Выделенные кластеры на основе суперускорителей NVIDIA GB200 NVL72 гарантируют соответствие инфраструктуры облачного провайдера изменению задач Perplexity и высоким требованиям экосистемы на основе Sonar и Search API. В своё время Perplexity начинала с выполнения задач инференса с помощью CoreWeave Kubernetes Service и применения платформы W&B Models для (до-)обучения моделей и управления ими на всех этапах, от экспериментального до ввода в эксплуатацию. Дополнительно CoreWeave повсеместно внедрит в своей организации инструменты Perplexity Enterprise Max, что позволит её специалистам искать информацию в интернете и внутренней базе данных, проводить углублённые исследования, анализировать данные и визуализировать их. Партнёрство является свидетельством «мультиоблачной» стратегии Perplexity. Чуть более месяца назад Microsoft заключила крупную облачную сделку с Perplexity, но ключевым провайдером ИИ-поисковика останется AWS. 
Источник изображения: CoreWeave/Perplexity Это лишь последняя из удачных сделок CoreWeave, сдающей в аренду мощности даже таким компаниям, как Microsoft, Meta✴ и OpenAI. В 2025 году компания получила средства от NVIDIA, которая арендовала свои же ускорители у CoreWeave. В сентябре 2025 года компания обязалась выкупить у неооблачного оператора все нераспроданные мощности. CoreWeave на волне роста спроса на облачные услуги удвоит в 2026 году капитальные затраты, хотя некоторые инвесторы сомневаются в целесообразности таких мер.
18.02.2026 [18:50], Владимир Мироненко
Власти Индии закупят ещё 20 тыс. ускорителей NVIDIA для ускорения развития ИИ в странеНа проходящем в Нью-Дели саммите India AI Impact Summit министр электроники и информационных технологий Индии Ашвини Вайшнау (Ashwini Vaishnaw) заявил, что Индия расширит свои вычислительные мощности для ИИ-нагрузок свыше имеющихся 38 тыс. ускорители, добавив еще 20 тыс. еди. в ближайшее время в рамках программы «Миссия ИИ 2.0». Вайшнау сообщил ресурсу EE Times, что заказы на новые GPU будут размещены в течение недели, и ожидается, что они будут развёрнуты в течение следующих шести месяцев. Расширение вычислительных мощностей происходит в ходе реализации рамочного соглашения между Индией и США на 2026 год, в соответствии с которым две страны договорились значительно увеличить торговлю технологическими продуктами, включая ускорители и другие компоненты для ЦОД. Соглашение предусматривает намерение Индии закупить в течение пяти лет американские энергоносители, самолёты, технологические товары и критически важные материалы на сумму $500 млрд, расширяя при этом совместное технологическое сотрудничество. Заявление Вайшнау говорит о дальнейшем развитии программы IndiaAI Mission, утверждённой в марте 2024 года с бюджетом около $1,14 млрд на пять лет. Первоначально программой планировалось развёртывание 10 тыс. GPU, но их количество уже достигло 38 тыс. Ускорители предоставляются местным компаниям по субсидированной ставке ₹65/час (около $0,72/час). 
Источник изображения: NVIDIA С момента запуска в рамках программы IndiaAI Mission разрабатывались семь основных направлений, включая субсидированные вычислительные ресурсы, разработку базовых моделей, финансирование стартапов и безопасное управление ИИ. Двенадцать стартапов уже были отобраны для разработки отечественных многомодальных базовых моделей с использованием специфических для Индии наборов данных. NVIDIA сообщила о поддержке приоритетов IndiaAI Mission, включая, расширение вычислительных мощностей благодаря поставке ускорителей NVIDIA, разработку передовых ИИ-моделей и исследования и инновации в области ИИ. В рамках программы IndiaAI Mission компания сотрудничает с поставщиками облачных услуг Yotta, L&T и E2E Networks для создания передовых ИИ-фабрик. Yotta — поставщик облачных услуг, создающий крупномасштабную суверенную ИИ-инфраструктуру для Индии под брендом Shakti Cloud, работающую на базе более чем 20 тыс. ускорителей NVIDIA Blackwell Ultra. Его кампусы в Нави Мумбаи (Navi Mumbai) и Большой Нойде (Greater Noida) предоставляют индийским предприятиям и госсектору услуги облачных ИИ-сервисов с высокой пропускной способностью и большим количеством GPU с оплатой по мере использования. 
Источник изображения: NVIDIA В свою очередь, компания E2E Networks создаёт кластер ускорителей NVIDIA Blackwell на своей платформе TIR, размещённый в ЦОД L&T Vyoma в Ченнаи (Chennai). Облачная платформа TIR будет включать системы NVIDIA HGX B200 и корпоративное ПО NVIDIA, а также открытые модели NVIDIA Nemotron для ускорения развития ИИ в таких областях, как агентный ИИ, здравоохранение, финансы, производство и сельское хозяйство. Третий индийский партнёр NVIDIA на ИИ-рынке — компания Netweb Technologies, которая запускает суперкомпьютерные системы Tyrone Camarero AI, построенные на узлах NVIDIA GB200 NVL4, произведённых в рамках государственной программы «Сделано в Индии». Сообщается, что облачная ИИ-инфраструктура в Индии будет размещать рабочие нагрузки, а также обеспечивать интеллектуальные возможности для обучения моделей, тонкой настройки и масштабного инференса. Мощности в этих ЦОД будут зарезервированы для разработчиков моделей, стартапов, исследователей и предприятий для создания, тонкой настройки и развёртывания ИИ в Индии. Ранее глава OpenAI Сэм Альтман (Sam Altman) заявил, что Индия способна стать одним из мировых ИИ-лидеров, особенно в создании малых рассуждающих моделей (SLM).
27.01.2026 [12:53], Сергей Карасёв
Giga Computing представила ИИ-сервер на базе NVIDIA GB200 NVL4 с СЖОКомпания Giga Computing, подразделение Gigabyte Group, пополнила ассортимент серверов моделью XN24-VC0-LA61, ориентированной на ИИ-задачи и другие ресурсоёмкие нагрузки. Устройство выполнено в форм-факторе 2U на аппаратной платформе NVIDIA GB200 NVL4. В общей сложности задействованы четыре GPU поколения Blackwell со 186 Гбайт памяти HBM3E каждый (пропускная способность до 8 Тбайт/с) и два CPU Grace с 480 Гбайт памяти LPDDR5X (пропускная способность до 512 Гбайт/с). Применяется GPU — GPU интерконнект NVIDIA NVLink и CPU — GPU интерконнект NVIDIA NVLink-C2C. Реализована система прямого жидкостного охлаждения. Доступны четыре сетевых порта OSFP InfiniBand XDR на 800 Гбит/с или два порта Ethernet на 400 Гбит/с на базе NVIDIA ConnectX-8 SuperNIC. Кроме того, имеется порт 1GbE на основе Intel I210-AT и выделенный сетевой порт управления 1GbE. В оснащение входит контроллер ASPEED AST2600. Во фронтальной части расположены восемь посадочных мест для SFF-накопителей с интерфейсом PCIe 5.0 (NVMe) с жидкостным охлаждением. Опционально может быть установлен DPU NVIDIA BlueField-3. 
Источник изображений: Giga Computing Есть внутренний разъём для SSD типоразмера M.2 2242/2260/2280/22110 с интерфейсом PCIe 5.0 x4, слот PCIe 5.0 х16 для карты FHHL с СЖО и ещё один разъём PCIe 5.0 х16 FHHL. Предусмотерны коннекторы USB 3.2 Gen1 Type-A, Micro-USB, Mini-DP и RJ45.  Сервер имеет габариты 438 × 87 × 900 мм и массу 42,8 кг. За питание отвечают четыре блока мощностью 3200 Вт с сертификатом 80 PLUS Titanium. Диапазон рабочих температур простирается от +10 до +35 °C.
22.12.2025 [14:36], Руслан Авдеев
Японское неооблако Datasection предоставит китайской Tencent десятки тысяч подсанкционных чипов NVIDIA B200/B300Хотя некоторые международные игроки стремятся ограничить доступ Китая к передовым американским чипам, в дата-центре близ Осаки (Япония) современные ИИ-ускорители используются единственным клиентом — китайской Tencent, сообщает The Financial Times. Чипы NVIDIA B200 принадлежат японской Datasection, недавно переключившейся с маркетинговых решений на управление ИИ ЦОД. С тех пор компания заключила соглашение с клиентом на сумму $1 млрд, а тот получил доступ к значительной части из 15 тыс. ИИ-ускорителей NVIDIA Blackwell. По словам источников издания, этим клиентом и является Tencent. Сделка позволяет китайскому техногиганту использовать довольно сложную, но вполне легальную стратегию для доступа к передовым ИИ-чипам на фоне санкций США. В результате сделки Datasection превратилась в одну из крупнейших «неооблачных» компаний в Азии. По словам представителя компании, менее полугода назад для обеспечения работы ИИ-моделей было достаточно 5 тыс. чипов B200, а теперь требуется минимум 10 тыс. Правила, которые вводили при прошлом президенте США, должны были закрыть юридическую лазейку, позволяющую китайским компаниями получать доступ к передовым ИИ-ускорителями в ЦОД и облаках за пределами КНР, но в мае новый президент отменил их. Теперь же одобрена поставка в Китай чипов NVIDIA H200, поэтому компании вроде Tencent, возможно, снова смогут строить собственные ИИ ЦОД на более современных ускорителях. Однако по словам Bernstein Research, использование зарубежных облаков вместо покупки чипов может оказаться для китайских технологических групп даже более привлекательным вариантом. 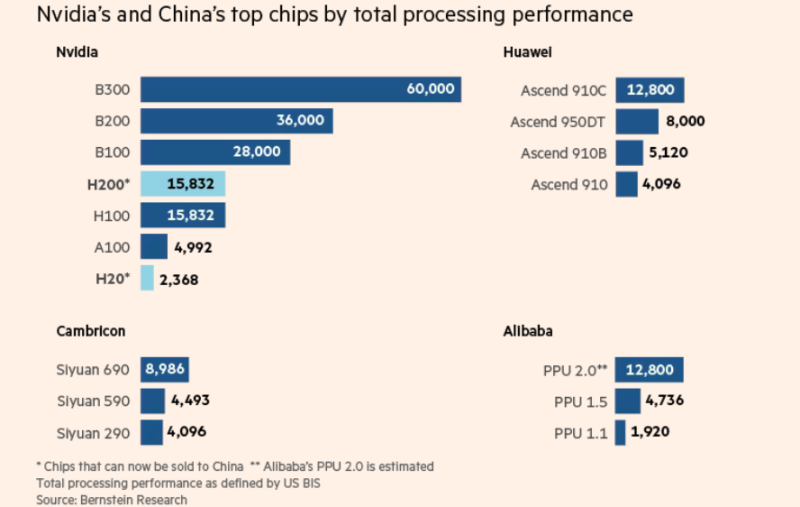
Источник изображения: The Financial Times Datasection намерена создать ИИ ЦОД с более 100 тыс. ускорителей NVIDIA. По некоторым данным, первые 15 тыс. чипов в основном зарезервированы для Tencent на три года. Впрочем, в самой Datasection вероятную сделку не комментируют, упоминая лишь о «крупном клиенте». По данным The Financial Times, в июле Datasection заключила контракт с «одним из крупнейших в мире поставщиков облачных услугу» на $406 млн, согласившись заплатить $272 млн за 5 тыс. B200 для объекта в Осаке, а уже в августе оборудование прибыло в Японию. Вскоре партнёры заключили ещё одну сделку, на этот раз на $800 млн с расчётом на второй ИИ ЦОД в Сиднее, где будут развёрнуты десятки тысяч B300. В декабре Datasection объявила, что первые 10 тыс. ускорителей B300 для сиднейского дата-центра обойдутся в $521 млн. В компании утверждают, что речь идёт о первом в мире ИИ-кластере гиперскейл-уровня на базе B300. По данным источников, мощности австралийского ЦОД тоже будут использоваться преимущественно Tencent. Контракт с «крупным клиентом» заключён на пять лет, с возможным продлением на два года. По сведениям источников, посредником (для защиты данных) выступает токийская NowNaw. Datasection может расторгнуть соглашения, если США вновь изменят правила работы с КНР. 
Источник изображения: Datasection Все участники сделки уверяют, что соблюдают все применимые законы, в том числе относительно использования зарубежных облачных сервисов. По словам Datasection, Министерство торговли Соединённых Штатов и NVIDIA одобрили использование ей ИИ-ускорителей. Кроме того, принимаются меры, чтобы компания не попадала под действие некоторых японских законов, в том числе о валютном контроле. В будущем Datasection рассчитывает выйти на рынок высокодоходных облачных сервисов, в частности, она нацелена на экспансию в Европу. В прошлом году она привлекла в совет директоров испанского и американского политиков. В Datasection уверены, что даже если ограничения США на экспорт ослабят, дав китайскому бизнесу доступ к самым передовым чипам NVIDIA, ей это не помешает. Как считают представители неооблачной компании, спрос на вычислительные мощности так высок, что новых клиентов найти будет несложно. В худшем случае деятельность придётся остановить «скажем, на неделю». В 2025 году акции Datasection выросли почти на 185 %, хотя и успели упасть с лета на фоне опасений по поводу избыточных инвестиций в ИИ и торговых атак на ценные бумаги со стороны участников фондового рынка.
05.12.2025 [17:29], Руслан Авдеев
Малайзия стала на шаг ближе к ИИ-суверенитету — запущен 600-МВт дата-центр с суперускорителями NVIDIAМалайзия сделала очередной важный шаг на пути достижения суверенитета в области технологий искусственного интеллекта. В Кулае (Kulai, штат Джохор) введена в эксплуатацию первая очередь дата-центра на основе технологий NVIDIA мощностью 600 МВт, сообщает Converge! Digest. Это позволит существенно снизить зависимость от иностранной ИИ-инфраструктуры. Построенный совместно с NVIDIA и YTL Power International (YTLP) центр находится на территории принадлежащего последней технопарка Green Data Center Park. Объект оснастили ИИ-системами NVIDIA GB200 NVL72 для обучения крупных ИИ-моделей и корпоративного инференса. Запуск последовал за дебютом малайзийской ИИ-модели ILMU — первого национального варианта LLM, разработанного в самой стране. Это свидетельствует о желании малайзийского правительства развивать собственные ИИ-компетенции, а не полагаться исключительно на сторонних поставщиков облачных услуг. При этом под давлением США выбор был сделан в пользу американских, а не китайских технологий. 
Источник изображения: Ven Jiun (Greg) Chee/unsplash.com Дата-центр укрепляет долгосрочные амбиции страны по превращению в ведущий ИИ-хаб АСЕАН к 2030 году. Власти подчёркивали стратегическую важность суверенных вычислений в ходе недавних переговоров с главой NVIDIA Дженсеном Хуангом (Jensen Huang). В бюджете на 2026 год выделено RM5,9 млрд (более $1,4 млрд) на расширение ИИ-инфраструктуры, масштабирование внедрения ИИ в промышленности и повышение цифровой конкурентоспособности в производстве, телеком-секторе и сфере услуг. Развитие инфраструктуры соответствует общей динамике развития региона, в т.ч. речь про крупные инвестиции в Джохоре и его окрестностях. В настоящее время регион является одним из самых быстрорастущих хабов ЦОД в Юго-Восточной Азии. Всё новые и новые проекты ЦОД указывают на устойчивый спрос на мощности, близость к IT-экосистеме Сингапура и выгодные условия в области энергетики. Конкуренцию Малайзии пытается составить Индонезия. 
Источник изображения: DayOne Малайзия определяет создание суверенных вычислительных мощностей и государственно-частное партнёрство как основные принципы стратегии развития цифровой индустрии. Как считают в Converge! Digest, действия Малайзии отражает аналогичные инвестиции в ИИ-вычисления, основанные на принципах суверенитета, осуществляющиеся в Сингапуре, Индонезии, Южной Корее, Японии и на Ближнем Востоке. Повсеместно страны создают специальные кластеры ускорителей для поддержки ИИ-индустрии. Укрепление партнёрства NVIDIA с поддерживаемыми государствами игроками в области ИИ от Сингапура до Саудовской Аравии отражает и растущий спрос на локализованные мощности и специализированные стоечные архитектуры. По мере развития ИИ-проектов в Джохоре Малайзия становится крупным ИИ-хабом с конкурентоспособными ценами в региональной гонке за развитие инфраструктуры. В августе сообщалось, что во II квартале 2025 года штат Джохор (Малайзия) одобрил 42 проекта строительства ЦОД.
18.11.2025 [10:54], Сергей Карасёв
Начался монтаж крупнейшего в США академического суперкомпьютера Horizon с ИИ-быстродействием до 80 ЭфлопсНациональный научный фонд США (NSF) объявил о начале монтажа вычислительно комплекса Horizon — крупнейшего в стране академического суперкомпьютера. Система расположится в Техасском центре передовых вычислений (TACC) при Техасском университете в Остине (UT Austin). Проект реализуется в сотрудничестве с Dell, NVIDIA, VAST Data, Spectra Logic, Versity и Sabey Data Centers. Суперкомпьютер будет развёрнут в новом дата-центре мощностью 15–20 МВт с передовым жидкостным охлаждением в Раунд-Роке (штат Техас). В основу системы лягут серверы Dell PowerEdge. Говорится об использовании процессоров NVIDIA Vera и суперчипов NVIDIA Grace Blackwell. В общей сложности будут задействованы около 1 млн CPU-ядер и примерно 4 тыс. GPU. Архитектура предусматривает использование интерконнекта NVIDIA Quantum-2 InfiniBand. Вместимость локального хранилища данных, выполненного исключительно на основе SSD, составит 400 Пбайт. Оно обеспечит пропускную способность при чтении/записи более 10 Тбайт/с. 
Источник изображения: TACC Заявленная производительность Horizon — 300 Пфлопс: это примерно в 10 раз больше по сравнению с системой Frontera, которая в настоящее время является самым мощным академическим суперкомпьютером в США. При выполнении ИИ-задач новый вычислительный комплекс обеспечит быстродействие до 20 Эфлопс на операциях BF16/FP16 и до 80 Эфлопс в режиме FP4 — более чем 100-кратный прирост по сравнению с нынешними машинами, которые эксплуатируются в американских академических кругах. При этом говорится о повышении энергетической эффективности до шести раз. Запуск Horizon запланирован на весну 2026 года. Суперкомпьютер будет использоваться для решения сложных и ресурсоёмких задач в таких областях, как биомедицина, физика, энергетика, экология и пр. В частности, система будет применяться для моделирования климата.
14.11.2025 [09:38], Сергей Карасёв
«За пределы экзафлопсного уровня»: Eviden представила суперкомпьютерную платформу BullSequana XH3500Компания Eviden, входящая в Atos Group, анонсировала конвергентную суперкомпьютерную платформу BullSequana XH3500 для ресурсоёмких нагрузок ИИ и HPC. Новинка сочетает передовые аппаратные решения с комплексной экосистемой ПО, обеспечивая возможность масштабирования «за пределы экзафлопсного уровня». BullSequana XH3500 использует открытую модульную конструкцию. Такой подход позволяет свободно комбинировать блоки CPU, GPU и сетевые компоненты от различных производителей, адаптируя конфигурации под определённые потребности. При этом устраняется зависимость от какого-либо конкретного поставщика оборудования, что обеспечивает полную технологическую свободу. По заявлениям Eviden, платформа BullSequana XH3500 по сравнению с системой предыдущего поколения позволяет добиться повышения электрической мощности более чем на 80 % в расчёте на 1 м2 и увеличения эффективности охлаждения на 30 % в расчёт на 1 кВт. Это даёт возможность удовлетворить растущие потребности в вычислительных ресурсах без необходимости расширения площадей в дата-центрах. Габариты стойки BullSequana XH3500 без модуля ультраконденсатора составляют 2270 × 900 × 1457 мм. Мощность AC достигает 284 кВт (с одной помпой). Задействовано на 100 % безвентиляторное прямое жидкостное охлаждение (DLC) пятого поколения с возможностью использования горячей воды с температурой до 40 °C. Подсистемы питания и охлаждения выполнены по схеме с резервированием N+1. Доступны 38 универсальных слотов 1U. 
Источник изображения: Eviden Для платформы BullSequana XH3500 разработаны узлы BullSequana XH3515B и BullSequana AI1242. Первый соответствует типоразмеру 1U: это одноузловое изделие оборудовано двумя чипами NVIDIA Grace CPU и четырьмя ускорителями NVIDIA Blackwell B200. Возможна установка до девяти NVMe SSD в форм-факторе E1.S. Говорится о поддержке четырёх сетевых устройств Eviden BXI V3 или InfiniBand NDR/XDR. В свою очередь, сервер BullSequana AI1242 имеет исполнение 2U. Данное решение несёт на борту два процессора AMD EPYC Turin и GPU-ускоритель AMD Instinct MI355X. Реализована поддержка восьми устройств Eviden BXI V3 или InfiniBand NDR/XDR, а также четырёх накопителей E1.S NVMe SSD.
05.11.2025 [10:16], Владимир Мироненко
NVIDIA и Deutsche Telekom строят в Германии ИИ-фабрику стоимостью €1 млрд
b200
deutsche telekom
dgx
hardware
nvidia
omniverse
германия
ии
конфиденциальность
промышленность
цод
NVIDIA и Deutsche Telekom представили первое в мире промышленное ИИ-облако (Industrial AI Cloud) — суверенную корпоративную платформу, запуск которой запланирован на начало 2026 года в рамках совместного проекта стоимостью €1 млрд. Платформа использует передовое оборудование NVIDIA, включая системы DGX B200 и серверы RTX PRO, а также ПО, в том числе NVIDIA AI Enterprise, CUDA-X и Omniverse, полностью интегрированное в облачную и сетевую экосистему Deutsche Telekom. Deutsche Telekom сообщила, что NVIDIA поставит более тысячи систем NVIDIA DGX B200 и серверов NVIDIA RTX PRO с 10 тыс. ускорителей NVIDIA Blackwell. Оборудование уже устанавливается в модернизированном дата-центре в Мюнхене. Объект начнёт работу в I квартале 2026 года, ИИ-производительность его систем составит 500 Пфлопс (точность вычислений не указана). Сообщается, что благодаря запуску этой ИИ-фабрики вычислительная мощность ИИ-решений в Германии увеличится сразу на 50 %. Управление объектом площадью в несколько тысяч квадратных метров будет осуществлять Deutsche Telecom, а компания SAP, занимающаяся разработкой корпоративного программного обеспечения, предоставит свою платформу SAP Business Technology Platform и соответствующие приложения. Европейская компания Polarise, занимающаяся разработкой ЦОД, также будет участвовать в проекте, пишет DataCenter Dynamics. «Благодаря этим вычислительным мощностям Германия станет ведущей в Европе суверенной точкой ИИ-доступа, созданной в рамках исключительно частной инициативы», — отметила Deutsche Telekom. 
Источник изображения: NVIDIA Сообщается, что Industrial AI Cloud — один из первых флагманских проектов инициативы Made for Germany («Сделано для Германии»), в которой участвуют более 100 компаний. Цель инициативы — укрепить позиции Германии как бизнес-площадки и ускорить цифровизацию экономики и управления страны. Компании смогут резервировать вычислительные мощности для разработки промышленных приложений ИИ. Облако также будет обслуживать государственные службы и оборонный сектор, пишет Reuters. Deutsche Telekom сообщила, что среди первых партнёров проекта — Agile Robots, чьи роботы, по слухам, будут использоваться для установки серверных стоек на объекте. Благодаря использованию NVIDIA Omniverse она расширит свои возможности по обучению, тестированию и валидации базовых моделей робототехники для целых парков роботов. Также в числе первых партнёров компания Perplexity, которая будет использовать новый ИИ ЦОД для предоставления услуг ИИ-инференса немецким пользователям и компаниям. Siemens сообщила, что будет использовать облачную платформу для ускорения внедрения промышленного ИИ, в том числе для собственных сервисов и для предложения решений на базе ИИ клиентам и партнёрам. По данным Siemens, такие автопроизводители, как Mercedes-Benz и BMW, будут использовать Industrial AI Cloud для проведения сложных симуляций с использованием цифровых двойников на базе ИИ, что значительно ускорит разработку автомобилей.
04.11.2025 [01:00], Владимир Мироненко
OpenAI потратит $38 млрд на аренду ускорителей NVIDIA у AWS, а AWS за $5,5 млрд арендует мощности у Cipher MiningAWS и OpenAI объявили о многолетнем стратегическом партнёрстве, в рамках которого AWS предоставит OpenAI ИИ-инфраструктуру. В рамках соглашения стоимостью $38 млрд OpenAI на семь лет получает доступ к вычислительным ресурсам AWS, включающим сотни тысяч ускорителей NVIDIA GB200/GB300 NVL72 в составе EC2 UltraServer, с возможностью расширения до десятков миллионов чипов для быстрого масштабирования агентных рабочих нагрузок. Согласно пресс-релизу, OpenAI сразу же начнёт использовать вычислительные ресурсы AWS. На первом этапе сделки будут использоваться существующие дата-центры AWS, а Amazon в конечном итоге развернёт дополнительную инфраструктуру для OpenAI. Развёртывание вычислительных мощностей планируется завершить до конца 2026 года. В 2027 году и далее возможно их расширение. В интервью ресурсу CNBC Дэйв Браун (Dave Brown), вице-президент по вычислительным сервисам и сервисам машинного обучения AWS, отметил, что OpenAI достанутся отдельные мощности, часть из которых уже доступна и используется. «Масштабирование передовых ИИ-технологий требует мощных и надёжных вычислений, — заявил генеральный директор OpenAI Сэм Альтман (Sam Altman). — Наше партнёрство с AWS укрепляет обширную вычислительную экосистему, которая станет движущей силой новой эры и сделает передовой ИИ доступным каждому». Примечательно, что для OpenAI будут развёрнуты узлы с преимущественно NVIDIA Connect-X, а не EFA, ради которых AWS переработала стойки GB300 NVL72, передаёт SemiAnalysis. Также OpenAI не будет использовать фирменные инструменты вроде SageMaker HyperPod, а задействует собственные решения для управления инфраструктурой. Т.е. речь идёт скорее о сдаче в аренду серверов, а не облачных сервисах. По-видимому, Project Ceiba также не относится к сделке. 
Источник изображения: Amazon Вместе с тем OpenAI продолжит активно сотрудничать с Microsoft, обязавшись приобрести сервисы Azure на $250 млрд. Сделка была заключена после завершения реструктуризации OpenAI, в связи с чем ей уже нет необходимости получать одобрение Microsoft на покупку вычислительных сервисов у других компаний. В 2019–2023 гг. OpenAI использовала только вычислительные мощности Microsoft, являвшейся её основным инвестором. За последние 18 месяцев, несмотря на жалобы OpenAI на то, что ей не удалось получить от Microsoft всю необходимую вычислительную мощность, технологический гигант позволил стартапу заключить отдельные соглашения с двумя другими облачными провайдерами, пишет The New York Times. В последнее время OpenAI активно заключает сделки, в том числе, с такими компаниями, как AMD, CoreWeave, NVIDIA, Broadcom, Oracle и Google. Общая сумма сделок составила около $1,4 трлн, что побудило некоторых экспертов заявить о грядущем пузыре в сфере ИИ. Они также высказывают сомнения в наличии у США необходимых ресурсов и возможностей для воплощения этих амбициозных обещаний в реальность. Попутно стало известно о заключении AWS договора с оператором майнинговых дата-центров Cipher Mining на сумму около $5,5 млрд, согласно которому ей будут предоставлены в аренду на 15 лет площади и электропитание в ЦОД последней. Как сообщает Data Center Dynamics, согласно условиям договора, Cipher Mining предоставит AWS в 2026 году 300 МВт с поддержкой воздушного и жидкостного охлаждения стоек. Ранее Cipher Mining заключила сделку с Google и Fluidstack. |
|

