Материалы по тегу: периферийные вычисления
|
22.07.2026 [16:56], Сергей Карасёв
NVIDIA повысила цены на модули Jetson: некоторые подорожали вдвоеКомпания NVIDIA, по сообщению ресурса CNX Software, повысила цены на вычислительные модули Jetson и комплекты для разработчиков на их основе. Стоимость некоторых изделий увеличилась сразу в два раза. Официально о причинах столь резкого скачка ничего не сообщается. Но можно предположить, что это связано с дефицитом чипов оперативной и флеш-памяти. Ранее из-за недостатка компонентов NVIDIA была вынуждена свернуть продажи изделий Jetson с памятью LPDDR4, которые были выпущены до 2021 года включительно. Значительнее всего подорожал модуль Jetson Nano: при заказах партиями от 1 тыс. штук его цена подскочила на 101 % — с $99 до $199. Вдвое подорожали и модули Jetson AGX Orin, оснащённые 32 Гбайт RAM: теперь они предлагаются за $1799 вместо прежних $899. В наименьшей степени рост цен затронул изделия Jetson Orin Nano с 8 Гбайт памяти и Jetson TX2i — плюс 33 %. 
Источник изображения: NVIDIA В целом обновлённый прайс-лист выглядит следующим образом:
16.07.2026 [15:50], Сергей Карасёв
NVIDIA представила модули Jetson T2000 и T3000 с GPU Blackwell для ИИ-задач на периферииКомпания NVIDIA объявила о расширении семейства вычислительных модулей Jetson Thor: дебютировали изделия T2000 и T3000, предназначенные для создания робототехнических систем и запуска ИИ-приложений на периферии сети. Обе новинки построены на архитектуре Blackwell. Младшее из двух решений, Jetson T2000, содержит шесть 64-бит вычислительных ядер Arm Neoverse-V3AE. Кроме того, задействован 1024-ядерный графический блок NVIDIA Blackwell. ИИ-производительность достигает 400 Тфлопс (FP4 Sparse). Объём памяти LPDDR5X составляет 16 Гбайт, её пропускная способность — до 137 Гбайт/с. Реализованы два сетевых интерфейса 10GbE. Энергопотребление не уточняется. В свою очередь, модуль Jetson T3000 объединяет восемь ядер Arm Neoverse-V3AE с 1 Мбайт кеша L2 каждое и 1536-ядерный GPU на базе NVIDIA Blackwell. Быстродействие на операциях ИИ составляет до 865 Тфлопс (FP4—Sparse). Это изделие располагает 32 Гбайт памяти LPDDR5X с пропускной способностью 273 Гбайт/с. Говорится о поддержке 25GbE-подключения. Энергопотребление, согласно предварительным данным, находится в диапазоне от 20 до 65 Вт. Размеры обеих новинок — примерно 50 × 87 мм. Прочие технические характеристики пока не раскрываются. 
Источник изображения: NVIDIA NVIDIA намерена начать поставки Jetson T2000 и Jetson T3000 в I квартале следующего года. Разработчики уже могут приступить к созданию продуктов на новых модулях, используя комплект Jetson AGX Thor Developer Kit. Отмечается, что в число партнёров NVIDIA по экосистеме Jetson входят такие компании, как ADLINK, Advantech, AAEON, Aetina, Auvidea, AVerMedia, Connect Tech, ForeCR, JWIPC, NEXCOM Robotic Solutions, Realtimes, Seeed Studio, Twowin, TZTEK и YUAN. Некоторые из них уже объявили о намерении выпустить решения на новых аппаратных платформах.
15.07.2026 [10:51], Сергей Карасёв
IBM представила компактный сервер Power S1112 для периферийных развёртыванийIBM анонсировала компактный сервер Power S1112, ориентированный на периферийные развёртывания и локальное использование на площадках небольших заказчиков. Устройство будет предлагаться в двух вариантах исполнения — стоечном форм-факторе 2U и башенном. Новинка имеет односокетную конфигурацию на базе POWER11. Стоечный вариант может оснащаться процессором, насчитывающим до десяти ядер (3,05–4,0 ГГц), тогда как башенная модификация довольствуется четырёъядерным чипом (3,6–4,0 ГГц). Доступны четыре слота для модулей оперативной памяти DDR5-4800 суммарным объёмом до 512 Гбайт. Сервер получил по два слота PCIe 4.0 x16 и PCIe 4.0 x8 для карт расширения HHHL. Имеются четыре посадочных места для NVMe-накопителей стандарта U.2. Реализованы сетевой порт 1GbE RJ45, разъём USB 3.0 на передней панели и внутренний порт USB 3.0. Питание обеспечивают два блока мощностью 800 Вт с резервированием и сертификатом 80 PLUS Titanium. Допустимый диапазон рабочих температур — от +5 до +40 °C, рекомендованный — от +18 до +27 °C. Габариты стоечной версии составляют 223,5 × 660,4 × 88,9 мм, масса — 20,4 кг. Башенный вариант имеет размеры 210,8 × 784,8 × 411,5 мм и весит 24,5 кг. 
Источник изображения: poweribmi.fr На сервере могут использоваться ОС IBM i, AIX и Linux, в том числе с применением виртуализации IBM PowerVM. Упомянуто квантово-безопасное шифрование, обеспечивающее целостность системы и безопасность критически важных функций. Комплекс средств Power RAS (Reliability, Availability, and Serviceability) помогает минимизировать простои, повысить доступность и удобство обслуживания оборудования.
14.07.2026 [10:01], Сергей Карасёв
ИИ на батарейках: Ambient Scientific представила экономичный микроконтроллер GPX10 Pro для работы на периферииКомпания Ambient Scientific анонсировала микроконтроллер GPX10 Pro для встраиваемых ИИ-приложений, работающих в режиме Always-On на периферийных устройствах. Новинка характеризуется небольшим энергопотреблением (менее 100 мкВт), благодаря чему может получать питание от небольшой батарейки. Изделие оснащено ядром Arm Cortex-M4F, функционирующим на частоте от 100 кГц до 100 МГц. Есть 2048 Кбайт системной памяти SRAM и дополнительно 64 Кбайт памяти SRAM, которая используется Always-On-секцией. Для хранения данных может быть подключён внешний флеш-модуль SPI или QSPI. В составе микроконтроллера задействованы десять программируемых ядер MX8 для выполнения задач глубокого обучения со сверхнизким энергопотреблением. Применён фирменный ИИ-движок DigAn, который позволяет ядрам переключаться между режимами Master (ведущий) и Slave (ведомый). Максимальная производительность составляет 512 GOPS при частоте 100 МГц с КПД более 7 TOPS/Вт. Возможно выполнение до 2560 операций MAC (умножение с накоплением) за такт, или 256 операций за такт в пересчёте на ядро. Говорится о поддержке стандартных нейронных сетей (CNN, RNN, LSTM, FCN). 
Источник изображения: Ambient Scientific Реализованы следующие интерфейсы: 16 × GPIO, 1 × I2C Slave, 1 × I2C Master, 2 × SPI, 2 × UAR, DVP (камера и пр.). Могут быть одновременно подключены до десяти цифровых и аналоговых датчиков, до четырёх аналоговых и двух цифровых микрофонов. Поддерживается асимметричное шифрование по алгоритму AES-128. Разработчикам будет доступен специализированный SDK-комплект, совместимый с фреймворками для ИИ и машинного обучения Keras, Tensorflow и ONNX, средствами компиляции ONNX Runtime, MX8 Runtime, ONNX-MLIR и пр. Будет также предлагаться набор GPX10 Pro Development Kit с аналоговым и цифровым микрофонами, акселерометром, датчиком газа, встроенным разъёмом для камеры, модулем Bluetooth и другими компонентами. Заявлена поддержка операционных систем Windows и RTOS.
08.07.2026 [12:39], Сергей Карасёв
Biostar представила компьютер EdgeComp MS-NAT4000 для периферийного ИИ на базе NVIDIA Jetson Thor T4000Компания Biostar анонсировала индустриальный компьютер небольшого форм-фактора EdgeComp MS-NAT4000, предназначенный для решения ИИ-задач на периферии сети. Устройство может применяться, например, для организации интеллектуального видеонаблюдения, обработки данных от датчиков в реальном времени, автоматизации операций и пр. В основу новинки положена аппаратная платформа NVIDIA Jetson Thor T4000. Это решение объединяет CPU с 12 ядрами Arm Neoverse-V3AE (до 2,6 ГГц) и 1536-ядерный GPU на архитектуре Blackwell (до 1,57 ГГц). Заявленная ИИ-производительность достигает 1200 Тфлопс (FP4—Sparse). В оснащение входят 64 Гбайт памяти LPDDR5X. 
Источник изображений: Biostar Накопители могут быть подключены к двум портам SATA-3 и разъёму M.2 Key M 2260/2280 (PCIe 5.0 x4). Кроме того, есть коннектор M.2 Key B 3042/3052 (USB 3.2) для сотового модема 4G/5G и слот M.2 Key E 2230 (PCIe 5.0 x1 + USB 2.0) для комбинированного адаптера Wi-Fi/Bluetooth. Реализованы два сетевых порта 5GbE (RJ45) и один порт QSFP28 (4 × 25GbE).  Для подключения мониторов служат интерфейсы HDMI (3840 × 2160; 60 Гц) и DP 1.4a. Предусмотрены четыре порта USB 3.1 Type-A и порт USB Type-C, два последовательных порта, а также 3,5-мм аудиогнёзда. Питание подаётся через сетевой адаптер мощностью 240 Вт (24 В / 10 A). Габариты составляют 192 × 154 × 80 мм, масса — 1,79 кг. Диапазон рабочих температур простирается от 0 до +50 °C. Говорится о поддержке программного пакета JetPack 7.1 (Linux Kernel 6.8 и Ubuntu 24.04). Кроме того, упомянут модуль TPM 2.0 для обеспечения безопасности.
21.05.2026 [14:55], Руслан Авдеев
Armada привлекла $230 млн на расширение производства модульных ИИ ЦОДArmada Inc., поставляющая контейнерные дата-центры и ПО для спутниковых интернет-технологий, привлекла $230 млн инвестиций, повысив оценку капитализации до $2 млрд, сообщает Silicon Angle. Ведущими инвесторами выступили BlackRock, Overmatch и 8090 Industries. Также в раунде приняли участие другие компании, в т.ч. крупный поставщик промышленного оборудования Johnson Controls, заключивший с Armada сделку о промышленном партнёрстве. Armada предлагает серию портативных ЦОД Galleon. Самый компактный вариант Beacon размером всего с чемодан, самый большой обеспечивает вычислительную мощность в несколько мегаватт. ЦОД поставляются в защищённых контейнерах, способных выдержать высокие температуры, удары и прочие внешние воздействия. Встроенные в корпус датчики позволяют своевременно выявлять попытки взлома. Прочность таких ЦОД позволяет работать даже в нетипичных условиях. По словам Armada, дата-центры можно вводить в эксплуатацию за несколько дней, поскольку им не нужна специальная энергетическая инфраструктура. Johnson Controls тоже выпускает модульные ЦОД и имеет подразделение Silent-Aire для производства систем воздушного охлаждения серверных. Недавно компания также приобрела купила разработчика СЖО Alloy Enterprises. Johnson Controls поможет Armada построить производство площадью 37 тыс. м2 для выпуска модульных дата-центров. Уже летом компании рассчитывают начать производство, первоначально приоритете будет отдаваться самому крупному варианту ЦОД Armada — Leviathan. 
Источник изображения: Armada Компания также предлагает маркетплейс, позволяя предустановить сторонние ИИ-системы на оборудование Galleon, а платформа Bridge позволяет монетизировать ИИ-инфраструктуру, сдавая вычислительные мощности в аренду. Сервис Atlas позволяет клиентам приобретать спутниковые терминалы Starlink за «кредиты» Microsoft Azure, управлять ими и отслеживать использование интернета. Наконец, ПО Drones добавляет функциональность, позволяющую управлять БПЛА. Armada заявляет, что ПО позволяет собирать телеметрию состояния компонентов беспилотников и отслеживать их полёт, а встроенный ИИ-ассистент ускоряет выполнение некоторых задач, вроде составления графиков техобслуживания.
15.05.2026 [10:57], Сергей Карасёв
Мини-ПК DX-AIPlayer получил ИИ-ускоритель DX-M1 с производительностью 25 ТопсЮжнокорейский стартап Deepx, по сообщению ресурса CNX Software, выпустил компьютер DX-AIPlayer небольшого форм-фактора, предназначенный для решения ИИ-задач на периферии. В устройстве соседствуют процессор Intel поколения Alder Lake-N и фирменный ускоритель DX-M1. Новинка заключена в корпус с габаритами 95 × 95 × 55 мм, а масса составляет около 450 г. Установлен чип Intel Processor N97 с четырьмя ядрами (без многопоточности), работающими на частоте до 3,6 ГГц (TDP — 12 Вт). Объём оперативной памяти LPDDR5 составляет 8 Гбайт с возможностью расширения до 16 Гбайт. Вместимость флеш-накопителя eMMC — 64 или 128 Гбайт. Упомянутый ускоритель Deepx DX-M1 выполнен в виде модуля M.2 2280 M-Key с интерфейсом PCIe 3.0 x4. Он располагает 4 Гбайт памяти LPDDR5 и чипом QSPI NAND на 1 Гбит, а TDP составляет 5 Вт. Заявленная ИИ-производительность достигает 25 TOPS в режиме INT8. 
Источник изображения: Deepx В оснащение мини-компьютера входит двухпортовый 1GbE-контроллер; опционально может быть добавлен комбинированный адаптер Wi-Fi/Bluetooth (M.2 2230 E-key). Есть интерфейсы HDMI 2.0b и DisplayPort 1.2 для вывода изображения, три порта USB 3.1 Type-A, два гнезда RJ45 для сетевых кабелей, два последовательных порта (RS-232/422/485), а также 3,5-мм аудиогнёзда. Питание (12 В) подаётся через DC-разъём. Возможен монтаж на стену или монитор посредством крепления VESA. Диапазон рабочих температур — от 0 до +60 °C. Говорится о поддержке ОС Windows 10/11, Ubuntu (20.04/22.04/24.04 LTS) и Yocto Project (v5.1), а также популярных фреймворков, включая PyTorch, TensorFlow, ONNX, Keras и Ultralytics YOLO. Цена составляет $995 за версию с 8 Гбайт ОЗУ.
14.05.2026 [10:56], Сергей Карасёв
SiFive представила RISC-V-ядра Performance P570 Gen 3 для IoT-приложенийКомпания SiFive анонсировала производительные процессорные ядра Performance P570 третьего поколения (Gen 3) с архитектурой RISC-V. Они ориентированы на требовательные периферийные ИИ-приложения, потребительские и коммерческие решения интернета вещей (IoT) и пр. Новые ядра используют 64-бит архитектуру RISC-V с поддержкой внеочередного исполнения инструкций. Допускаются конфигурации, насчитывающие до четырёх ядер в кластере. При этом возможно использование до четырёх кластеров, что в сумме даёт до 16 вычислительных ядер. Используется общий кеш L3 на уровне кластера и опциональный общий кеш L2. Для Performance P570 Gen 3 заявлена поддержка широкого спектра типов данных: INT8, INT16, INT32, INT64, FP16, FP32, FP64 и BFloat16. Заявлена полная совместимость с профилем RVA23, который стандартизирует набор инструкций ISA. Реализованы такие функции, как векторные операции, инструкции с плавающей запятой и атомарные инструкции, которые востребованы в сферах НРС и ИИ. Добавлены расширения для повышения производительности и улучшения безопасности, включая Smepmp, Zvkng, Zvksg, Zicfilp, Zicfiss, Zfbfmin, Zvfbfmin, Zvfbfwma и Zvdot4a8i. Упомянута возможность работы с современными ОС, включая Android, Ubuntu 26.04 LTS и платформы Red Hat. 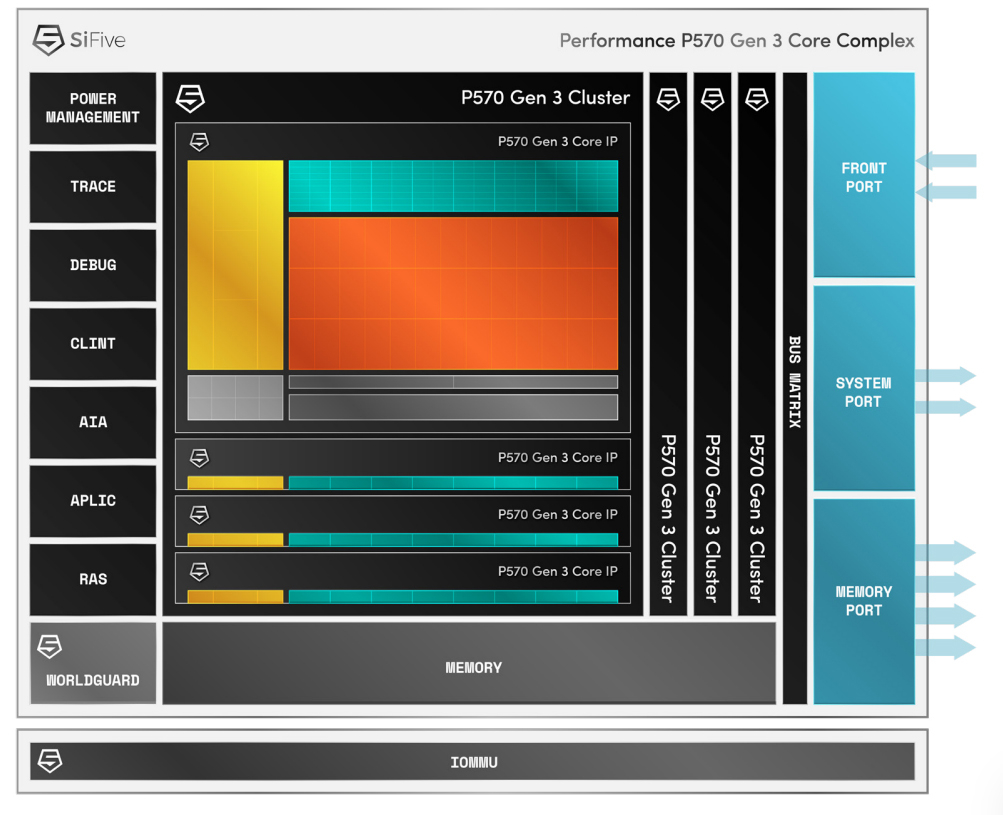
Источник изображения: SiFive В тесте Geekbench 6 ядра Performance P570 Gen 3 демонстрируют примерно вдвое более высокую производительность в расчёте на 1 ГГц по сравнению с изделиями P550. При выполнении определённых ИИ-задач, таких как распознавание объектов, достигается 21-кратный прирост быстродействия благодаря 128-битному векторному конвейеру VLEN. Если сравнивать с ядрами P470 Gen2, то у P570 выигрыш в производительности составляет 30 % и 350 %. В традиционных CPU-нагрузках, по данным SpecInt 2006/2017, ядра P570 показывают прирост быстродействия на 7–13 % по сравнению с P550 при сопоставимых значениях с P470. Кроме того, обеспечивается повышение энергетической эффективности. У ядер Performance P570 Gen 3 динамическое энергопотребление (мВт/ГГц) снижено на 13 % и 5 % по сравнению с P550 и P470 соответственно, а потери мощности (мВт) уменьшены на 51 % и 5 %.
12.05.2026 [16:33], Руслан Авдеев
Космический DevSecOps: Red Hat и Voyager Technologies успешно протестировали микро-ЦОД на борту МКС
linux
red hat
red hat enterprise linux
software
гибридное облако
ии
контейнеризация
космос
микро-цод
мкс
периферийные вычисления
Red Hat и Voyager Technologies объявили об успешном развёртывании в космическом микро-ЦОД LEOcloud Space Edge IaaS на борту МКС программных платформы RHEL Linux 10.1 и образа Red Hat Universal Base Image (UBI). Проект предназначен для развития орбитальных ЦОД и периферийных вычислений в космосе. Предлагаемое решение позволяет запускать контейнеризированные и связанные с ИИ нагрузки на орбите, ближе к источнику получаемых в космосе данных. Использование версии Red Hat Enterprise Linux на аппаратной площадке Space Edge Micro Datacenter позволяет снизить задержки и операционные издержки, в то же время обеспечивая более проактивную защиту периферийных сред, говорит компания. По словам Red Hat, космос стал «новым фронтиром» для гибридных облаков, на котором успех зависит от наличия надёжной, доверенной облачной инфраструктуры, где бы ни генерировались данные. Появление орбитальных ЦОД (ODC) требует открытых инноваций и чрезвычайно высокой отказоустойчивости. Взаимодействие компаний направлено на решение уникальных для космических сред проблем: оптимизацию работы систем при дефиците электроэнергии и аппаратных ресурсов, обработку данных при задержках и перебоях связи, предоставление Linux корпоративного уровня. Интеграция соответствующих задач с наземными DevSecOps-практиками даст возможность Red Hat и Voyager помочь различным организациям расширять свои гибридные облака с повышением стабильности и операционной надёжности. 
Источник изображения: NASA/unsplash.com Сегодня компании закладывают основу для новой эры вычислений в космосе, где облачные возможности будут распространяться от земной поверхности к низким околоземным орбитам, на Луну и т.д. Соответствующий подход позволит переносить DevSecOps-практики, стратегии контейнеризации и проактивные механизмы безопасности в передовые операционные среды. Компании выделили несколько ключевых технологических особенностей платформы:
Voyager расширяет DevSecOps-практики в космос благодаря использованию «движка» для запуска контейнеров Podman и Ansible Automation Platform для автоматизации задач, с контейнеризированными приложениями, работающими от земли до орбиты и инструментами, оптимизированными с помощью ИИ. В сентябре 2025 года сообщалось, что прототип орбитального ЦОД Axiom Space и Red Hat для экспериментов с периферийными вычислениями прибыл на МКС, а в октябре того же года основатель Amazon Джефф Безос (Jeff Bezos) пророчил эпоху космических ЦОД гигаваттного масштаба. Этой весной SpaceX подала заявку на вывод в космос миллиона спутников-ЦОД, а у Amazon, раскритиковавшей инициативу. Похоже, имеются собственные планы на этот счёт.
01.05.2026 [14:07], Сергей Карасёв
HPE представила серверы ProLiant Compute EL220/EL240 Gen12 для ИИ-задач на периферии
amd
epyc
gpu
granite rapids
hardware
hpe
intel
sierra forest
sorano
xeon
периферийные вычисления
сервер
HPE анонсировала серверы ProLiant Compute EL220 и EL240 Gen12 для приложений ИИ и критически важных рабочих нагрузок на периферии. Устройства выполнены на основе шасси ProLiant Compute EL2000, которое спроектировано специально для эксплуатации в суровых условиях. Системы на базе EL2000 могут использоваться при температурах от -40 до +55 °C и влажности до 95 %. Говорится об устойчивости к воздействию сильных вибраций, которые могут наблюдаться, например, на борту самолётов или наземной техники. 
Источник изображений: HPE Шасси допускает установку двух серверов ProLiant Compute EL220 Gen12 типоразмера 1U или одного сервера ProLiant Compute EL240 Gen12 в форм-факторе 2U. Эти устройства выполнены на процессорах Intel Xeon 6700 (Sierra Forest-SP/Granite Rapids-SP), которые могут насчитывать до 144 вычислительных ядер. Объём оперативной памяти DDR5 достигает 2 Тбайт. Возможен монтаж двух SSD формата М.2 (NVMe) и четырёх накопителей EDSFF. Модификация ProLiant Compute EL240 Gen12 также может быть укомплектована двумя GPU-ускорителями одинарной ширины или одной картой двойной ширины. Упомянуты средства управления iLO 7. В продажу новинки поступят позднее в текущем году.  Кроме того, HPE представила обновлённую версию компактного edge-сервера ProLiant DL145 Gen11 на аппаратной платформе AMD. Это устройство переведено на процессоры EPYC 8005 Sorano, насчитывающие до 84 ядер. Поддерживается до 768 Гбайт DDR5. Система может быть оборудована двумя SFF-накопителями или шестью EDSFF-изделиями. Могут быть задействованы до трёх GPU одинарной ширины или один ускоритель двойной ширины. Сервер уже доступен для заказа. |
|

