Материалы по тегу: компьютер
|
16.04.2025 [14:20], Сергей Карасёв
Уникальный суперкомпьютер Anton 3 для задач молекулярной динамики введён в эксплуатациюПиттсбургский суперкомпьютерный центр (PSC) ввёл в эксплуатацию вычислительный комплекс Anton 3 — специализированный суперкомпьютер следующего поколения, предназначенный для биомолекулярного моделирования. Система позволяет ускорить исследование ферментов, создание новых лекарственных препаратов, ремоделирование мембран и пр. Проект Anton реализуется частной компанией D. E. Shaw Research. Данная серия суперкомпьютеров названа в честь Антони ван Левенгука (Antoni van Leeuwenhoek) — нидерландского натуралиста, конструктора микроскопов и пионера микробиологии. Системы Anton разрабатываются специально для ускорения процесса моделирования молекулярной динамики. 
Источник изображений: D. E. Shaw Research С помощью этих суперкомпьютеров исследователи могут получить ценную информацию о движениях и взаимодействиях белков и других биологически важных молекул. Многие из решаемых на базе Anton задач не могут быть выполнены за разумное время с помощью любого другого современного суперкомпьютера общего назначения или программного обеспечения для молекулярной динамики, доступного академическому сообществу.  Комплекс Anton 3 имеет 64-узловую конфигурацию. Задействованы 512 кастомных ASIC, а энергопотребление суперкомпьютера находится на уровне 400 кВт. Anton 3 обеспечивает быстродействие до 980 тыс. шагов моделирования в секунду (timesteps per second, TPS). По производительности на задачах молекулярной динамики система, как утверждается, на два порядка превосходит существующие универсальные суперкомпьютеры. Впрочем, по словам Cerebras, её царь-ускорители справляются и с этой задачей. 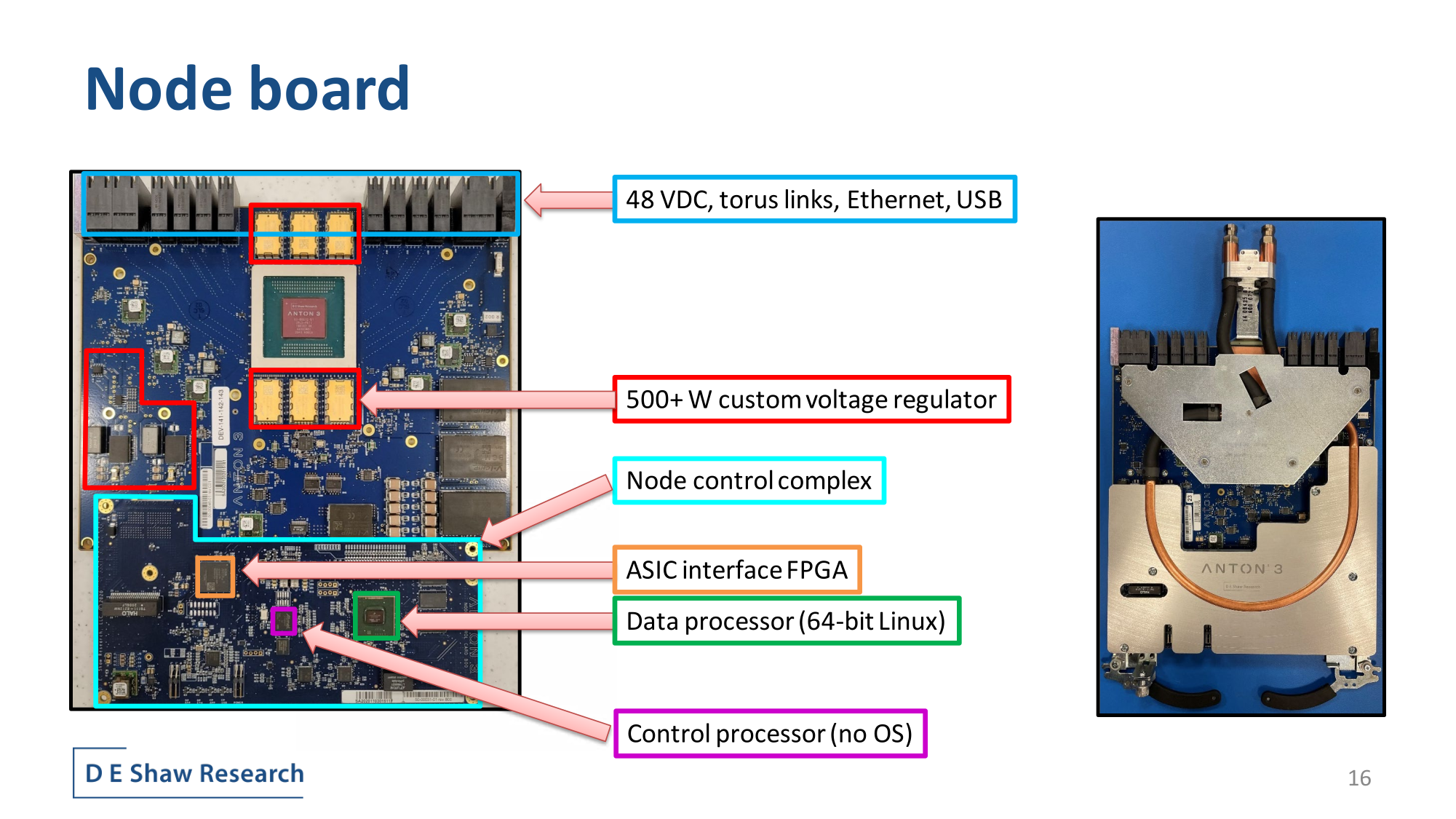 «Благодаря новейшей системе Anton мы сможем предоставить исследователям уникальный ресурс, способный за считанные дни выдавать результаты, на которые при использовании любого другого суперкомпьютера ушли бы годы», — отмечает доктор Филип Блад (Philip Blood), научный директор PSC. Разработкой систем для ускорения расчётов молекулярной динамики также занимается RIKEN в рамках проекта MDGRAPE.
08.04.2025 [13:29], Сергей Карасёв
Eviden создаст для Сербии суперкомпьютер стоимостью €36 млнВласти Сербии, по сообщению ресурса Datacenter Dynamics, заключили контракт с Eviden (подразделение Atos Group) на создание нового суперкомпьютера. Речь идёт о приобретении системы BullSequana последнего поколения, которая будет поставлена к концу текущего года. Технические подробности проекта пока не раскрываются. Отмечается лишь, что контракт с Eviden является частью более широкого соглашения стоимостью €50 млн, подписанного между правительствами Сербии и Франции. Из этой суммы €36 млн пойдёт непосредственно на создание суперкомпьютера. Оставшаяся часть средств будет потрачена на ИИ-инициативы в таких сферах, как здравоохранение, энергетика, транспорт и государственное управление. На сегодняшний день, как отмечается, Сербия эксплуатирует как минимум один неназванный НРС-комплекс, созданный NVIDIA и размещённый в государственном дата-центре в Крагуеваце (столица административного региона Шумадия). Система, запущенная в декабре 2021 года, обошлась в €30 млн. В перспективе в модернизацию этого суперкомпьютера планируется инвестировать €40 млн, что позволит поднять его производительность в семь раз. 
Источник изображения: Правительство Сербии Глава сербского управления по IT и электронному правительству Михайло Йованович (Mihailo Jovanovic) заявил, что новый суперкомпьютер, поставкой которого займётся Eviden, будет насчитывать «в 20 раз больше чипов, чем [нынешняя] система NVIDIA», и получит почти в 30 раз больше памяти. Какие именно чипы имеются в виду, Йованович уточнять не стал. Работа над государственным ЦОД в Крагуеваце стоимостью €30 млн началась в 2019 году, а открытие состоялось в 2020-м. Дата-центр состоит из двух объектов общей площадью около 14 тыс. м2 — это примерно в пять раз больше по сравнению с прежней ЦОД-площадкой в Белграде. Комплекс в Крагуеваце соответствует стандарту Tier IV: он предоставляет услуги хостинга для предприятий и правительственных структур.
06.04.2025 [14:05], Сергей Карасёв
Начато создание европейского суперкомпьютера Daedalus с производительностью 89 ПфлопсЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) сообщило о подписании соглашения с компанией НРЕ на создание суперкомпьютера Daedalus, который расположится в Греции и будет интегрирован с ИИ-фабрикой Pharos. Контракт с НРЕ заключён при участии Национальной инфраструктуры исследований и технологий GRNET S.A. в Афинах. Общая стоимость создания Daedalus оценивается в €36 млн. Из этой суммы 35 % предоставит EuroHPC JU, а остальные 65 % будут привлечены в рамках Национального плана восстановления и обеспечения устойчивости «Греция 2.0». В проекте также участвуют Кипр, Черногория и Северная Македония, вошедшие в специально сформированный консорциум Daedalus. Производительность нового суперкомпьютера составит более 89 Пфлопс (FP64). С таким показателем быстродействия в ноябрьском рейтинге мощнейших суперкомпьютеров мира TOP500 комплекс Daedalus мог бы занять 17-е или 18-е место. Для НРС-платформы предусмотрено применение возобновляемых источников энергии и передовых систем охлаждения, которые значительно повысят энергетическую эффективность. 
Источник изображения: EuroHPC JU Суперкомпьютер Daedalus станет доступен в начале 2026 года широкому кругу пользователей по всей Европе, включая научное сообщество, промышленную сферу и государственный сектор. Машина расположится в новом дата-центре в здании бывшей электростанции Технологического культурного парка Лаврион Национального технического университета Афин (NTUA). Доступ к вычислительным ресурсам комплекса будет совместно управляться EuroHPC JU и консорциумом Daedalus пропорционально их инвестициям. Ожидается, что Daedalus ускорит научные достижения Европы в различных областях, включая ИИ, медицину, метеорологию, анализ больших данных и разработку интеллектуальных транспортных систем. В декабре 2024 года консорциум EuroHPC выбрал площадки для первых европейских ИИ-фабрик (AI Factory): они разместятся в Финляндии, Германии, Греции, Италии, Люксембурге, Испании и Швеции. Аналогичные комплексы также появятся в Австрии, Болгарии, Франции, Германии, Польше и Словении.
05.04.2025 [10:36], Сергей Карасёв
Европейский суперкомпьютер Discoverer получил обновление в виде NVIDIA DGX H200Европейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о модернизации суперкомпьютера Discoverer, установленного в Софийском технологическом парке в Болгарии. Обновленная НРС-система получила название Discoverer+. Комплекс Discoverer, построенный на платформе BullSequana XH2000, был введён в эксплуатацию в 2021 году. Изначальная конфигурация включала 1128 вычислительных узлов, каждый из которых содержит два 64-ядерных процессора AMD EPYC 7H12 поколения Rome. Производительность (FP64) достигала 4,52 Пфлопс с пиковым значением в 5,94 Пфлопс. С такими показателями система находится на 221-й позиции в ноябрьском рейтинге мощнейших суперкомпьютеров мира TOP500. В рамках модернизации добавлен GPU-раздел на основе четырёх модулей NVIDIA DGX H200. Каждый из них содержит восемь ускорителей H200 и два процессора Intel Xeon Platinum 8480C поколения Sapphire Rapids с 56 ядрами (до 3,8 ГГц). Модули обладают быстродействием до 32 Пфлопс каждый в режиме FP8. Кроме того, обновлённый комплекс получил Lustre-хранилище вместимостью 5,1 Пбайт, систему хранения Weka ёмкостью 273 Тбайт и дополнительную ИБП-систему. 
Источник изображения: EuroHPC JU Как отмечается, Discoverer стал первым суперкомпьютером EuroHPC, прошедшим серьёзную модернизацию с момента своего первоначального запуска. После наращивания мощностей комплекс планируется использовать для крупномасштабных проектов в области ИИ, таких как обучение нейронных сетей, создание цифровых двойников сложных объектов и пр. В декабре 2024 года консорциум EuroHPC выбрал площадки для первых европейских ИИ-фабрик (AI Factory): они расположатся в Финляндии, Германии, Греции, Италии, Люксембурге, Испании и Швеции. Кроме того, такие объекты планируется создать в Австрии, Болгарии, Франции, Германии, Польше и Словении. Эти площадки станут частью высококонкурентной и инновационной экосистемы ИИ в Европе.
23.03.2025 [14:14], Сергей Карасёв
Equal1 представила первый в мире стоечный квантовый сервер на базе кремния, который можно развернуть в любом ЦОДИрландский стартап Equal1, специализирующийся на квантовых вычислениях, анонсировал систему Bell-1 — это, по словам компании, первый в мире компактный квантовый сервер, построенный на кремниевом чипе. Устройство может быть легко интегрировано в существующие среды НРС для формирования платформ квантово-классических вычислений. Equal1 отмечает, что современным квантовым компьютерам необходима специализированная инфраструктура, включающая отдельные помещения и сложные системы охлаждения. Но Bell-1 может быть развёрнут в виде стойки в существующем дата-центре. Основой Bell-1 служит чип UnityQ с шестью кубитами — это так называемая квантовая система на кристалле (QSoC). Она объединяет все компоненты квантовых вычислений — средства измерения, управления, считывания и коррекции ошибок — в одном кремниевом процессоре, что, как утверждается, обеспечивает высокую точность и беспрецедентную мощность. Гибридная архитектура включает ядра Arm, ускорители ИИ и нейронные блоки. Говорится о возможности масштабирования до миллионов кубитов. Реализованный подход устраняет сложную оркестрацию между отдельными классическими и квантовыми вычислительными узлами. 
Источник изображения: Equal1 Стоечная система Bell-1 работает от стандартной однофазной сети напряжением 110/220 В, а энергопотребление составляет 1600 Вт, что сопоставимо с высокопроизводительным сервером на базе GPU. Рабочая температура равна 0,3 К (-272,85 °C): для её поддержания применяется полностью автономная система, включающая интегрированный компрессор, криоохладитель и вакуумный насос. При этом температура окружающей среды может находиться в диапазоне от -15 до +45 °C. Габариты квантового сервера составляют 600 × 1000 × 1600 мм, масса — приблизительно 200 кг. Equal1 утверждает, что Bell-1 знаменует собой начало эпохи реальных квантовых вычислений — Quantum Computing 2.0: это означает переход от экспериментальных машин к практическим квантовым решениям. До сих пор квантовые вычисления ограничивались преимущественно научно-исследовательскими институтами. Компания Equal1, по её словам, меняет ситуацию, предлагая «первую коммерчески жизнеспособную квантовую систему», созданную для работы в существующих дата-центрах ИИ и HPC. Предприятия смогут использовать квантовые вычисления без изменения существующей инфраструктуры ЦОД. При этом устраняются барьеры высокой сложности и стоимости.
23.03.2025 [14:08], Сергей Карасёв
Итальянский суперкомпьютер Leonardo будет интегрирован с квантовым компьютером IQM Radiance на 54 кубитаИтальянский суперкомпьютерный центр Cineca объявил о заключении соглашения с компанией IQM Quantum Computers на поставку самого мощного в стране квантового вычислительного комплекса. Речь идёт о системе IQM Radiance в конфигурации с 54 кубитами. Cineca является одним из крупнейших вычислительных центров Италии. Некоммерческий консорциум состоит из 69 итальянских университетов и 21 национальной исследовательской организации. Своей задачей консорциум ставит поддержку итальянского научного сообщества путём предоставления суперкомпьютеров и инструментов визуализации. Монтаж IQM Radiance планируется осуществить в IV квартале нынешнего года. Это будет первый локальный квантовый компьютер на площадке Cineca в Болонье. Суперкомпьютерный центр намерен использовать новую систему для оптимизации квантовых приложений, квантовой криптографии, квантовой связи и квантовых алгоритмов ИИ. 
Источник изображения: IQM Quantum Computers Комплекс IQM Radiance 54 будет интегрирован с вычислительной системой Leonardo, которая является одним из самых быстрых суперкомпьютеров в мире. В ноябрьском рейтинге TOP500 эта машина занимает девятое место с теоретической пиковой производительностью 306,31 Пфлопс. В основу суперкомпьютера положены платформы Atos BullSequana X2610 и X2135. Система построена в рамках сотрудничества EuroHPC, которое сейчас занято развёртыванием сети европейских квантовых компьютеров и ИИ-фабрик. Компания IQM Quantum Computers основана в Хельсинки (Финляндия) в 2018 году. Она поставляет полнофункциональные квантовые компьютеры и специализированные решения для HPC, научно-исследовательских институтов, университетов и предприятий. Ранее IQM заявляла, что к выпуску готовится версия Radiance со 150 кубитами, которую планировалось представить в I квартале 2025 года.
18.03.2025 [10:05], Сергей Карасёв
ExxonMobil развернёт суперкомпьютер Discovery 6 с суперчипами NVIDIA GH200Американская ExxonMobil, одна из крупнейших в мире нефтяных компаний, представила проект высокопроизводительного вычислительного комплекса Discovery 6. Этот суперкомпьютер планируется использовать для поддержания работы передовых систем 4D-сейсморазведки. Комплекс создаётся в партнёрстве с НРЕ и NVIDIA. В основу системы ляжет платформа HPE Cray Supercomputing EX4000. Будут задействованы 4032 суперчипа NVIDIA GH200 Grace Hopper. В состав Grace Hopper входят 72-ядерный Arm-процессор NVIDIA Grace, до 480 Гбайт LPDDR5x и ускоритель NVIDIA H100 с 96 или 144 Гбайт HBM3(e). Говорится об использовании интерконнекта HPE Slingshot. Отмечается, что по производительности новый суперкомпьютер примерно в четыре раза превзойдёт предшественника — систему Discovery 5, введённую в эксплуатацию в ноябре 2022 года. Этот комплекс использует платформу HPE Cray EX235n с 32-ядерными процессорами AMD EPYC 7543 и ускорителями NVIDIA A100 SXM4. В ноябрьском рейтинге TOP500 машина Discovery 5 занимала 46-ю позицию с пиковой производительностью 30,99 Пфлопс. Таким образом, быстродействие Discovery 6, как ожидается, будет находиться на уровне 120 Пфлопс. 
Источник изображения: ExxonMobil Для создаваемого суперкомпьютера предусмотрено использование высокоэффективной системы прямого жидкостного охлаждения (DLC). Благодаря запуску Discovery 6 ExxonMobil рассчитывает сократить время обработки сложных сейсмических данных с месяцев до недель. Это поможет повысить эффективность разведки месторождений нефти и газа, что приведёт к увеличению добычи ресурсов с меньшими капиталовложениями. Завершить монтаж Discovery 6 планируется в I половине текущего года.
17.03.2025 [10:25], Сергей Карасёв
Квантовые компьютеры Pasqal стали доступны в облаке Microsoft AzureКомпания Pasqal объявила о том, что её квантовый компьютер на нейтральных атомах стал доступен через облачную инфраструктуру Microsoft Azure Quantum. Таким образом, исследовательские организации и заинтересованные предприятия смогут экспериментировать с квантовыми вычислениями без больших первоначальных инвестиций. Квантовая платформа Pasqal использует нейтральные атомы для формирования кубитов. Такие атомы не имеют электрического заряда, благодаря чему слабо взаимодействуют с внешними электромагнитными полями, что позволяет улучшить стабильность. 
Источник изображения: Pasqal Каждый кубит в системе Pasqal реализован с помощью одного нейтрального атома, чьи электронные энергетические уровни соответствуют логическим «0» и «1». Атомы захватываются и манипулируются с помощью лазера, благодаря чему могут выполняться высокоточные квантовые операции. Квантовый компьютер Pasqal может функционировать при комнатной температуре, что выгодно отличает его от других машин, для работы которых требуется экстремальное охлаждение. О том, какое количество кубитов используется в системе Pasqal в Microsoft Azure Quantum, ничего не сообщается. При этом отмечается, что решение на базе нейтральных атомов обладает хорошей масштабируемостью и высокой энергоэффективностью. Компания Pasqal основана в 2019 году на базе Института оптики во Франции (Institut d’Optique). В число её соучредителей входит профессор Ален Аспе (Alain Aspect) — французский физик, специалист по квантовой оптике и квантовой запутанности. Он является лауреатом Нобелевской премии по физике 2022 года за эксперименты с запутанными фотонами. На сегодняшний день Pasqal привлекла более €140 млн финансирования.
13.03.2025 [15:55], Руслан Авдеев
ESA запустила суперкомпьютер Space HPC для европейских космических исследованийЕвропейское космическое агентство (ESA) запустило суперкомпьютерную платформу ESA Space HPC, специально разработанную для развития космических исследований и технологий в Евросоюзе. Открытие нового объекта состоялось на территории принадлежащего ESA центра ESRIN в Италии, сообщает HPC Wire. ESA Space HPC обеспечит поддержку исследований и развития технологий в рамках всех программ ESA, обеспечивая учёным и малому и среднему бизнесу из стран Евросоюза доступ к вычислительным мощностям. Инициатива призвана развить использование высокопроизводительных вычислений (HPC) в аэрокосмическом секторе ЕС, она станет основой для более масштабных инициатив в будущем. Как сообщается на сайте проекта, Space HPC построен при участии HPE. Суперкомпьютер включает порядка 34 тыс. ядер процессоров Intel и AMD последних поколений, 156 Тбайт RAM, 108 ускорителей NVIDIA H100, All-Flash подсистему хранения ёмкостью 3,6 Пбайт и пропускной способностью 500 Гбайт/с, а также 400G-интерконнект InfiniBand. Общая пиковая производительность кластера составляет 5 Пфлопс (FP64). Space HPC использует прямое жидкостное охлаждение, а PUE системы не превышает 1,09. Избыточное тепло отправляется на нужды отопления кампуса. Локальная солнечная электростанция обеспечивает более половины энергетических нужд кластера. Представители итальянских властей заявили, что технологические инновации в космическом секторе являются приоритетом для обеспечения безопасности и «стратегической автономии», а также будут способствовать конкурентоспособности европейской промышленности. Также отмечено, что местный аэрокосмический хаб Lazio стал домом для 250 компаний и играет ключевую роль в развитии авионики, электроники, радаров, спутниковых технологий и материаловедения. В руководстве ESA отметили потенциал Space HPC для инноваций в космической индустрии Евросоюза. Новый объект обеспечит агентству гибкую суперкомпьютерную инфраструктуру для исследований и разработок, тестирования и бенчмаркинга, поддержки программ ESA и промышленных предприятий. Доступ к вычислениям будет иметь и малый и средний бизнес, стартапы и т.п. 
Источник изображения: ESA Также отмечается, что дебют Space HPC наглядно продемонстрировал, ESA не только берёт ресурсы у государств-участников, но и много может дать им взамен. Утверждается, что одной из ключевых сфер деятельности, где требуются HPC-платформы, для ESA является наблюдение за Землёй. Новые мощности обеспечат управление наблюдениями, разработку новых приложений и сервисов. Space HPC будет поддерживать сложные нагрузки, включая моделирование, инженерные симуляции, обучение ИИ-моделей, аналитику данных и визуализацию, а также прочие эксперименты, которые помогут снизить риски будущих космических проектов. Это позволит ESA повысить финансовую эффективность проектов и обеспечит возможность обмена данными между разными программами агентства. В конце 2024 года сообщалось, что в 2025 году в Евросоюзе появится сразу семь ИИ-фабрик EuroHPC, а в середине минувшего февраля появилась информация, что Евросоюз направит €200 млрд на развитие ИИ, чтобы не отстать от США и Китая в этой сфере. В прошлом году было отмечено, что реализация миссий NASA задерживается из-за устаревших и перегруженных суперкомпьютеров.
13.03.2025 [08:50], Руслан Авдеев
Cerebras развернёт царь-ускорители WSE-3 ещё в шести ЦОД во Франции, США и КанадеКомпания Cerebras начала установку более тысячи ИИ-систем CS-3 на базе гигантских ускорителей WSE-3 по всей Северной Америке и во Франции. Компания стремится зарекомендовать себя как поставщика одной из крупнейших и быстрейших облачных инференс-платформ, сообщает The Register. Кроме того, компания объявила о расширении сотрудничества с Hugging Face. К концу 2025 года развернёт свои ускорители в дата-центрах в Техасе, Миннесоте, Оклахоме и Джорджии, а также в Канаде и во Франции. Cerebras будет целиком владеть площадками в Оклахома-Сити (Оклахома) и Монреале (Канада), а оставшиеся объекты будут эксплуатироваться в рамках соглашения с G42 из ОАЭ. Крупнейший в США новый кластер CS-3 разместится в Миннеаполисе (Миннесота), его оснастят 512 CS-3 с общим быстродействием 64 Эфлопс (FP16). Он заработает уже во II квартале 2025 года. Cerebras давно сотрудничает с фондом G42, который активно спонсирует ИИ-стартап и является его якорным заказчиком — на G42 пришлось 83 % от всей выручки Cerebras за 2023 календарный год. Однако именно это сотрудничество привело к тому, что Cerebras вынужденно отложила IPO — власти США опасаются, что Китай получит доступ к ИИ-суперчипам Cerebras при посредничестве ОАЭ. По слухам, G42 заключила сделку с США, отказавшись от работы с Китаем в обмен на инвестиции. 
Источник изображения: SNL В ближайшее время Cerebras также намерена расширить API-доступ к своим ускорителям для разработчиков, договорившись с репозиторием моделей Hugging Face. Также Cerebras выиграла контракты с Mistral AI и Perplexity. Недавно объявлено о намерении аналитической платформы AlphaSense заменить трёх поставщиков моделей с закрытым кодом на модель open source, работающую на CS-3. Летом прошлого года было объявлено о партнёрстве с Dell. |
|

