Материалы по тегу: ии
|
07.10.2025 [11:18], Сергей Карасёв
В облаке Astra Cloud появился квантовый генератор случайных чисел
astra linux
hardware
гсч
информационная безопасность
квантовые технологии
облако
россия
сделано в россии
«Группа Астра» и научно-образовательная компания QRate сообщили о создании программно-аппаратного комплекса (ПАК) Astra Cloud с квантовым генератором случайных чисел (КГСЧ) QRate Chaos. Пользователи могут получить доступ к истинно случайным числам как сервису на облачной платформе: утверждается, что это первое решение такого класса на российском рынке. Как отмечается, случайные числа широко используются в различных сферах, включая криптографические системы, цифровые платежи, интернет-банкинг, научные приложения и пр. Обычно для генерации случайных чисел применяются специальные компьютерные алгоритмы. Однако они в силу своих особенностей, как говорит QRate, позволяют получать не истинно случайные, а псевдослучайные числовые последовательности. КГСЧ позволяет устранить данный недостаток. Для формирования непредсказуемых последовательностей система QRate Chaos использует фундаментальную неопределённость квантовых процессов. Принцип работы КГСЧ основан на оцифровке шумов из квантового источника энтропии. В качестве последнего служат флуктуации фазы электромагнитного поля в резонаторе полупроводникового лазера, как следствие эффекта усиления спонтанного излучения. 
Источник изображения: «Группа Астра» QRate Chaos доступен в составе ПАК Astra Cloud через веб-интерфейс и CLI-приложение, которое развёртывается в учётной области пользователя (тенанте). Причём один генератор может безопасно обслуживать сразу нескольких таких областей и даже кластеров. Обмен данными с КГСЧ осуществляется по защищённым каналам. Случайные последовательности чисел генерируются в нужном объёме и предоставляются в удобном формате. «Группа Астра» отмечает, что новый сервис может применяться для генерации криптографических ключей, одноразовых паролей и токенов, уникальных идентификаторов и пр. Ещё одним сценарием использования названа защита сетевой инфраструктуры, включая оптимизацию маршрутизации и распределение нагрузки между узлами и сервисами, непредсказуемые фильтры для предотвращения DDoS-атак и пр. Решение также может пригодиться в области генеративного ИИ. «Интеграция квантовых технологий, таких как генератор случайных чисел, в платформу Astra Cloud открывает новые горизонты для построения защищённых облачных сервисов. Уверены, что подобные разработки станут фундаментом цифрового суверенитета и стабильного развития всей ИТ-отрасли страны», — говорит Константин Анисимов, заместитель генерального директора Astra Cloud.
07.10.2025 [09:13], Сергей Карасёв
«Росатом» создал российский интерконнет «Альфа»: до 80 Гбит/с на порт и до 4096 узловНаучно-производственное объединение «Критические информационные системы» (НПО КИС), входящее в «Росатом», представило коммуникационную сеть Альфа, предназначенную для передачи данных между узлами вычислительных систем с высокой скоростью и малой задержкой. В качестве сфер применения сети «Альфа» названы СХД, СУБД, суперкомпьютеры и кластеры (в том числе на основе GPU), бортовые вычислительные комплексы и пр. Архитектура «Альфы» предполагает использование чипа на базе ПЛИС и хост-интерфейса PCIe 3.0 x16. Топология — 5D-тор, Fat Tree, Dragonfly+. Реализована поддержка медных и оптических кабелей, прямого доступа в память удалённого узла (RDMA), атомарных операций и вызовов удалённых прерываний, а также счётчиков производительности и исключительных ситуаций. Передача данных происходит без участия ядра ОС (в пространстве пользователя). 
Источник изображения: «Росатом» Заявленная пропускная способность достигает 80 Гбит/с на порт, пропускная способность MPI (Message Passing Interface) — 72,5 Гбит/с. Задержка между соседними узлами составляет 1,7 мкс, задержка узла — 0,5 мкс. Темп выдачи сообщений — 50 МТ/с. Возможно масштабирование до 4096 узлов. 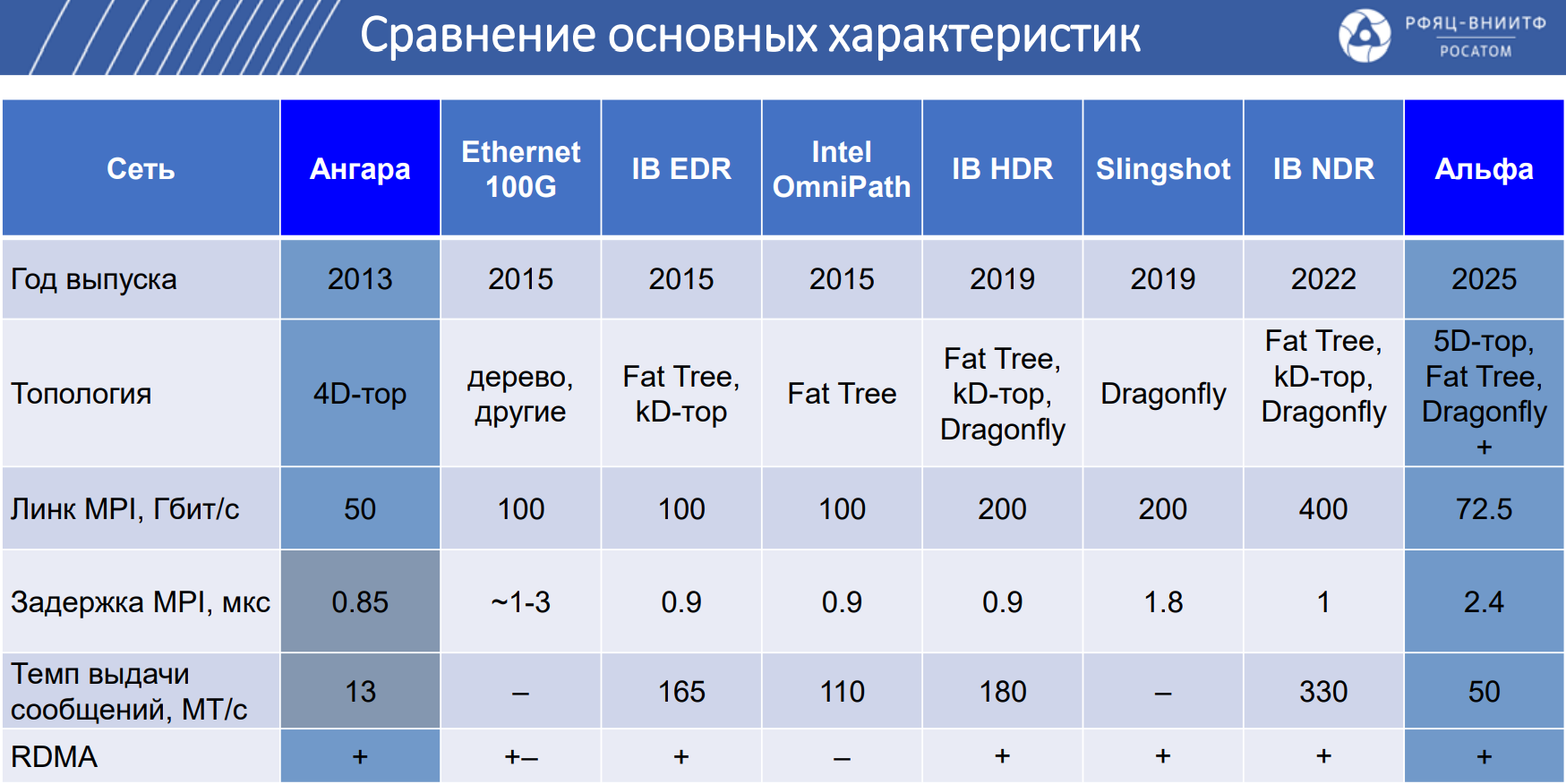
Источник изображения: «Росатом» Для сети «Альфа» разработаны адаптер и коммутатор. Первый выполнен в виде HHHL-карты с интерфейсом PCIe 3.0 x16. Предусмотрены два порта QSFP-DD. Применяется пассивная система охлаждения, потребляемая мощность — до 29,5 Вт. Изделие имеет размеры 142,25 × 68,9 × 17,25 мм. Возможно объединение в кольцо до восьми адаптеров без использования коммутатора. 
Источник изображения: НПО КИС В свою очередь, коммутатор располагает 32 портами QSFP-DD: устройство представляет собой четыре модуля коммутации, соединённых в кольцо. Решение выполнено в форм-факторе 1U с габаритами 650 × 43,6 × 440 мм. Используется активное воздушное охлаждение, а энергопотребление не превышает 300 Вт. Коммутатор получил блок питания с резервированием.
06.10.2025 [17:20], Руслан Авдеев
Caterpillar стала неожиданным бенефециаром ИИ-бумаНередко в ходе «золотой лихорадки» основные капиталы зарабатывали не золотоискатели, а бизнесы, поставлявшие им оборудование. То же случилось во время ИИ-бума: одним из бенефициаров стала компания Caterpillar (CAT), выпускающая традиционное промышленное оборудование, в том числе — турбины для генерации электричества, сообщает Bloomberg. Хотя американская компания хорошо известна своими экскаваторами и бульдозерами, закрыть сентябрь с рекордными показателями ей помогли именно турбины из-за ненасытного спроса ИИ на электроэнергию. Изначально развитие ИИ спровоцировало стремительный рост акций производителей полупроводников и разработчиков ПО, но по мере роста спроса на электроэнергию для ЦОД начался бум акций коммунальных компаний и предприятий, строящих дата-центры. Наконец, инвесторы стали искать и другие сферы применения средств, хлынувших сотнями миллиардов долларов в экономику, связанную со сферой ИИ. В сентябре 2025 года акции Caterpillar выросли в цене на 14 % — это лучший показатель с 2023 года. В результате в годовом исчислении рост акций составил 32 %, что значительно выше роста индекса Nasdaq 100, а также роста на 19 % в группе из семи крупнейших высокотехнологичных компаний США. В прошлую среду акции выросли ещё на 0,8 % — инвесторов не испугали даже новости о продаже акций на €387 млн ($455 млн) пенсионным фондом ABP из Нидерландов. 
Источник изображения: Caterpillar Рост не в полной мере связан с деятельностью Caterpillar по выпуску турбин. Хотя акции резко упали после объявления в августе о миллиардных расходах в связи с новыми тарифами США, ряд факторов, смягчивших финансовые показатели, от снижения налогов до снижения ставки ФРС, позволили удержаться на плаву. Сентябрьский «триумф» CAT во многом обусловлен объявлением Oracle, представившей неожиданно оптимистичный прогноз для своего бизнеса, связанного с облачными вычислениями — он потребует очень много электроэнергии и вычислительных мощностей. Инвесторы ставят на то, что для удовлетворения спроса в электричестве потребуются турбины Caterpillar. В частности, первый ЦОД OpenAI Stargate, в развитии которого принимает участие Oracle, получит 29 газовых турбин. xAI также использует турбины Caterpillar для питания Colossus 2. По мнению экспертов Oppenheimer, рынок осознаёт важность ЦОД на фоне снижения процентных ставок, что, как ожидается, станет катализатором строительства жилой и коммерческой недвижимости. Впрочем, Caterpillar заработает не только на турбинах, но и, например, на оборудовании для добычи меди, которая тоже очень востребована при строительстве ЦОД. Также тяжёлое оборудование компании потребуется и для непосредственного строительства дата-центров. Вместе с тем производители газовых турбин пока опасаются расширять производство. Не так давно Bank of America повысил целевую цену акций компании Caterpillar с $495 до $517, сославшись на использование продуктов Caterpillar в секторе ЦОД. Caterpillar не публикует финансовые результаты подразделения Solar Turbines, отвечающего за решения для генерации энергии, что несколько затрудняет оценки бизнеса инвесторами. В Bank of America считают это подразделение «самым прибыльным продуктом CAT с устойчивыми перспективами роста». 
Источник изображения: Caterpillar Эксперты подчёркивают, что CAT известна прежде всего строительным и горнодобывающим оборудованием, но движущей силой очередного цикла модернизации, вероятно, станет энергетика — в которой инвесторы разбираются меньше всего. Пока Уолл-Стрит следит за тем, не снизится ли рентабельность компании из-за роста издержек. На клиентов CAT может оказать давление и инфляция в других сегментах рынка. Сейчас акции компании торгуются выше средней целевой цены Уолл-Стрит, поэтому их дальнейший рост, вероятно, будет затруднительным. При этом «мультипликатор» P/E (цена/прибыль) на ближайшие 12 месяцев составляет 23, что является максимальным значением с 2021 года. В то же время, по мнению экспертов, оценка даже занижена по сравнению с другими компаниями, выигравшими от спроса на ИИ-технологии, поэтому не исключено, что у ценных бумаг сохранился потенциал роста. Среди компаний, выпускающих энергетическое оборудование, акции Vertiv Holdings и GE Vernova торгуются с мультипликаторами 36 и 53 P/E соответственно благодаря росту их акций на 40 % и 100 % в текущем году. В то же время акции Caterpillar торгуются с дисконтом по сравнению с крупнейшими ИИ-игроками вроде Microsoft и NVIDIA. Прошедшие в минувшую среду торги акциями техасской Fermi Inc. показали, что интерес инвесторов к вложениям в ИИ ещё не угас. Акции компании, рассчитывающей на строительство огромного кампуса для ЦОД и энергомощностей, в ходе первой торговой сессии после выхода на биржу взлетели на 55 %. По словам экспертов, пока рынком в сфере ИИ и ЦОД движет «иррациональное начало» и акции той же Caterpillar могут оказаться в «петле положительной обратной связи».
06.10.2025 [16:45], Владимир Мироненко
AMD поставит OpenAI ИИ-ускорители на 6 ГВт, а OpenAI получит долю в AMDAMD и OpenAI объявили о заключении многолетнего соглашения о стратегическом партнёрстве, в рамках которого будет построена ИИ-инфраструктура на базе сотен тысяч ИИ-ускорителей AMD нескольких поколений общей мощностью 6 ГВт общей стоимостью, по предварительным оценкам, $60–$80 млрд. После объявления о сделке акции AMD выросли на 28 % до $211,18 в начале торгов, что само по себе тянет на рекорд, пишет Bloomberg. В рамках соглашения AMD предоставила OpenAI возможность покупки до 160 млн обыкновенных акций, которые будут переданы по мере достижения контрольных целей. Первый транш будет предоставлен после развёртывания инфраструктуры на 1 ГВт, которое начнется во II половине следующего года. ИИ-системы будут основаны на чипах AMD Instinct MI450. Последующие транши будут выделяться по мере развёртывания оборудования в ЦОД до итогового показателя мощности в 6 ГВт. Выпуск акций также привязан к достижению AMD целей по цене акций и достижению OpenAI технических и коммерческих целей. Исходя из текущего количества выпущенных акций AMD к завершению сделки у OpenAI будет 10 % её акций. 
Источник изображения: AMD «Мы рассматриваем эту сделку как безусловно преобразующую не только для AMD, но и для динамики всей отрасли», — заявил исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) агентству Reuters в воскресенье. В AMD также сообщили, что партнёрство с OpenAI принесет компании десятки миллиардов долларов дохода, значительно увеличит прибыль AMD на акцию и ускорит развитие инфраструктуры ИИ OpenAI. Для AMD эта сделка станет отправной точкой для более широкого внедрения её технологий, что может увеличить доход компании в этой области до более чем $100 млрд, заявили руководители компании, не уточняя конкретных сроков, пишет Bloomberg. Для OpenAI сотрудничество с AMD обеспечит более надёжную альтернативу решениям NVIDIA, на которые OpenAI и операторы ЦОД тратят значительную часть своих бюджетов. В прошлом месяце стало известно о соглашении OpenAI с NVIDIA, в рамках которого производитель чипов инвестирует в стартап до $100 млрд, включая поставку ускорителей общей мощностью не менее 10 ГВт. Ускорители AMD будут использоваться преимущественно для инференса, а NVIDIA — для обучения. Попутно OpenAI при поддержке Broadcom разрабатывает собственные ИИ-ускорители, которые должны появиться в 2026 году.
06.10.2025 [14:41], Руслан Авдеев
Разработчик царь-ускорителей Cerebras Systems отозвал заявку на IPOCerebras Systems решила отозвать заявку о выходе на публичные торги — информация об IPO компании впервые появилась около года назад. Оператор ЦОД и разработчик ИИ-чипов сообщил, что документы об IPO ещё не были одобрены регуляторами, сообщает Bloomberg. Всего несколько дней назад компания закрыла раунд финансирования G на $1,1 млрд, что подняло её стоимость до $8,1 млрд. На тот момент руководство заявляло, что привлечённые средства никак не скажутся на планах выхода на публичные торги. Сообщалось, что они будет потрачены на расширение технологического портфолио, включая разработку ИИ-ускорителей, упаковку, создание ИИ-суперкомпьютеров и др. Раунд финансирования Cerebras стал последним в череде инвестиций в технологическую индустрию, которая тратит миллиарды на новую ИИ-инфраструктуру, призванную преобразить мировую экономику. В последние недели на рынке IPO в США наблюдается оживление. В частности, успешно дебютировали технологические компании Netskope и Figure Technology Solutions, акции которых выросли более чем на 20 % от цены размещения. 
Источник изображения: Cerebras Cerebras подала заявку о выходе на IPO в сентябре 2024 года, но выход на биржу так и не состоялся. Это связывается с позицией американских регуляторов, занявшихся расследованием инвестиций G42 из Абу-Даби на $335 млн. 87 % выручки Cerebras за первые шесть месяцев 2024 года поступили от G42, а строящиеся в США дата-центры предназначены для использования именно компанией из ОАЭ, имеющей связи с Китаем. Впрочем, в марте Cerebras объявила, что разрешила все спорные вопросы с регулятором CFIUS. Последний раунд финансирования возглавили Fidelity Management & Research и Atreides Management. В числе инвесторов — Tiger Global, Valor Equity Partners и венчурный капиталист 1789 Capital, также приняли участие и прежние инвесторы, включая Altimeter Capital Management and Benchmark. На днях Cerebras запустила новый ЦОД в Оклахома-Сити (Oklahoma City, Оклахома) при сотрудничестве со Scale Datacenters. Также компания имеет действующие кластеры для инференса в Санта-Кларе (Santa Clara) и Стоктоне (Stockton) в Калифорнии (последний в плавучем ЦОД Nautilus), а также в Далласе (Dallas, Техса). Также компания создаёт кластеры в Миннеаполисе (Миннесота), Монреале (Канада) на объекте Bit Digital, а также в некоторых локациях на Среднем Западе США и в Европе. Компания внедрила оборудование в Эдинбургском университете (University of Edinburgh), Сандийскийх национальных лабораториях (Sandia National Labs), в лабораториях Лос-Аламоса (Los Alamos Labs), на мощностях G42/Core42 и др.
06.10.2025 [14:00], Сергей Карасёв
HP представила компактный «ИИ-суперкомпьютер» ZGX Nano G1n AI Station на основе NVIDIA GB10Компания HP анонсировала рабочую станцию ZGX Nano G1n AI Station небольшого форм-фактора, предназначенную для работы с ИИ, включая «тонкую» настройку языковых моделей, инференс и агентные приложения. Основой новинки служит суперчип NVIDIA GB10 Grace Blackwell. В целом решение практически не отличается от систем на базе GB10 других вендоров. Устройство заключено в корпус с габаритами 150 × 150 × 51 мм, а масса составляет 1,25 кг. В состав чипа GB10 входят 20-ядерный процессор Grace (10 × Arm Cortex-X925 и 10 × Arm Cortex-A725) и ускоритель Blackwell. Имеется 128 Гбайт унифицированной системной памяти LPDDR5x, пропускная способность которой достигает 273 Гбайт/с. Компьютер может быть оборудован SSD типоразмера M.2 вместимостью 1 или 4 Тбайт (NVMe OPAL). В оснащение входят сетевой контроллер 10GbE (Realtek RTL8127), адаптер NVIDIA ConnectX-7 200GbE, беспроводной модуль MediaTek MT7925 с поддержкой Wi-Fi 7 (2×2) / Bluetooth 5.4. В тыльной части корпуса располагаются разъём USB Type-C для подачи питания, три порта USB Type-C (20 Гбит/с), гнездо RJ45 (10GbE), два порта QSFP и интерфейс HDMI 2.1a. 
Источник изображения: HP На устройстве применяется программная платформа NVIDIA DGX OS на базе Ubuntu, оптимизированная специально для задач ИИ. Заявленная производительность достигает 1000 TOPS на операциях FP4. Возможна работа с ИИ-моделями, насчитывающими до 200 млрд параметров. Кроме того, два экземпляра ZGX Nano G1n AI Station могут быть объединены в одну систему, что позволит использовать ИИ-модели, оперирующие 405 млрд параметров. Продажи компактного ИИ-суперкомпьютера начнутся текущей осенью.
06.10.2025 [10:00], Сергей Карасёв
Orion soft представил рынку собственный VDIРазработчик инфраструктурного ПО для Enterprise-бизнеса Orion soft расширил портфель решений — представил новую функциональность виртуализации рабочих столов и приложений (VDI) в рамках интеграции продуктов zVirt и Termit. Благодаря ей заказчики могут прямо в пользовательском интерфейсе Termit настроить автоматическое создание групп виртуальных рабочих мест из шаблона. Функциональность VDI стала ключевым обновлением нового релиза платформы виртуализации рабочих столов и приложений Termit 2.4. Теперь сотрудники могут подключаться к виртуальным рабочим столам с привычными настройками и приложениями, которые безопасно работают в дата-центре и доступны с любого устройства. VDI предоставляет полноценную рабочую среду с большей изоляцией и персонализацией. «Это стало возможно благодаря глубокой интеграции с системой виртуализации zVirt. В интерфейсе Termit можно настроить сопряжение с zVirt, там же создать группу виртуальных рабочих мест, и в неё автоматически будут добавляться виртуальные машины, создаваемые в zVirt по заданному шаблону — "золотому образу" . Они также автоматически будут вводиться в домен. На стороне виртуализации нужно только настроить "золотой образ", все остальные операции можно совершать в интерфейсе Termit», — рассказывает Константин Прокопьев, лидер продукта Termit Orion soft. Источник изображения: Orion soft VDI в продуктах Orion soft обеспечивает возможность создания как сессионных, так и персонализированных виртуальных машин, а также поддерживает кроссплатформенность, многофакторную аутентификацию и SSO, протоколы X2Go, RDP и Loudplay, перенаправление устройств, различные ОС: Windows, Astra Linux, РЕД ОС, ОС Альт. Функциональность представлена как отдельно в рамках продукта Termit, так и в новом модуле платформы виртуализации zVirt Apps and Desktops. Среди других обновлений релиза Termit 2.4 — улучшение пользовательского опыта и усиление безопасности. В частности, появилась возможность настройки перемещаемых профилей для Linux. Теперь, когда пользователь отключается от рабочего стола, все его актуальные настройки и изменения остаются в удалённом хранилище и при следующем подключении перемещаются за пользователем на новый сервер или виртуальную машину. Это позволяет сохранять единое рабочее окружение для сотрудников и снижает количество обращений в техподдержку. Также в Termit 2.4 реализована функциональность липких сессий. Благодаря ей каждое новое приложение, которое запускает пользователь, не стартует на новом сервере, а «прилипает» к первой запущенной сессии. Это позволяет избежать неэффективного использования ИТ-ресурсов и снижает нагрузку на инфраструктуру, а пользователи больше не сталкиваются с тем, что приложения «зависают» при старте. В Termit 2.4 реализован также веб-клиент и работа из браузера. Эта функциональность позволяет продукту закрыть несколько новых крупных сценариев использования, в том числе обеспечивает возможность работы сотрудников, не имеющих стационарных рабочих мест, с мобильных устройств на базе Android, iOS, «Аврора». В части безопасности пользователям стали доступны аутентификация по смарт-картам и перенаправление смарт-карт, а также централизованные политики перенаправления устройств и буфера обмена. Теперь системные администраторы смогут из единой консоли управлять тем, что сотрудники передают с виртуального рабочего стола, — например, запретить буфер обмена, микрофон, локальные диски, принтеры, смарт-карты. Разрешения и запреты можно устанавливать как всем пользователям, так и отдельному LDAP-каталогу, группе или конкретным сотрудникам. Так компании могут полностью контролировать, какая информация покидает корпоративную сеть, и снизить риски утечки чувствительных данных. Также команда Termit поделилась подробностями о разработке собственного протокола доставки удалённого рабочего стола и терминального доступа. Он будет реализован внутренними силами и без использования Open Source. «Мы изучили существующие на рынке разработки и патенты, наняли сильных специалистов и в этом году начали разработку собственного протокола. Мы пишем его сами, не используем ни X2Go, ни SPICE, ни FreeRDP. Это в первую очередь UDP, но одновременно будет реализована и поддержка TCP. В протоколе "из коробки" будет поддержка виртуальных каналов и мультисессионности», — рассказывает Константин Прокопьев, лидер продукта Termit Orion soft.
06.10.2025 [08:32], Сергей Карасёв
OpenAI оснастит дата-центры энергетическим оборудованием HitachiКомпании OpenAI и Hitachi, по сообщению Nikkei, подписали меморандум о взаимопонимании с целью развития ИИ-инфраструктуры и создания энергетически эффективных дата-центров в глобальном масштабе. Основными целями партнёрства заявлены ускорение разработки генеративного ИИ и снижение затрат на эксплуатацию ЦОД. В рамках сотрудничества Hitachi будет поставлять передовое оборудование для передачи и распределения электроэнергии в дата-центры OpenAI по всему миру. Ожидается, что эти системы помогут снизить потребление электричества и тем самым сократить расходы на поддержание работы ИИ ЦОД. В свою очередь, OpenAI, по условиям соглашения, предоставит Hitachi свои большие языковые модели (LLM). Они могут быть интегрированы в цифровую платформу Hitachi Lumada, которая представляет собой комплексное решение для индустриального интернета вещей (IIoT). 
Источник изображения: Hitachi Говорится также, что Hitachi внесёт вклад в проект Stargate — это совместное предприятие OpenAI, SoftBank и Oracle по развитию ИИ-инфраструктуры в США. Предполагается, что суммарные затраты на реализацию Stargate достигнут $500 млрд. Планируется, что OpenAI начнёт закупать IT-оборудование Hitachi, включая СХД. В состав Hitachi, напомним, входит дочерняя структура Hitachi Vantara, которая специализируется на продуктах для управления данными, включая оборудование, ПО и услуги для облачных платформ и дата-центров. Нужно отметить, что недавно в США были введены в эксплуатацию первые ИИ ЦОД флагманского кампуса OpenAI Stargate. Кроме того, OpenAI объявила о намерении построить пять дополнительных дата-центров по всей территории США. Новые объекты расположатся, в частности, в округах Шакелфорд (Shackelford) в штате Техас и Донья-Ана (Doña Ana) в штате Нью-Мексико.
06.10.2025 [00:17], Руслан Авдеев
Meta✴ построит ещё один «палаточный» ИИ ЦОДНеобходимость быстрой реализации кампуса ИИ ЦОД Prometheus в Огайо сподвигла Meta✴ на использование «палаток» — быстровозводимых тентов с алюминиевым каркасом, покрытым водонепроницаемой тканью, устойчивой к повреждениям. На днях компания получила разрешение от властей Теннеси на создание аналогичного «палаточного городка» в Галлатине (Gallatin), Datacenter Dynamics. Как и Prometheus, он расположится на территории уже действующего кампуса ЦОД с более традиционными капитальными постройками. Площадь нового объекта должна составить 12 542 м2. В июле появилась информация, что компания начала размещать кластеры ИИ-ускорителей стоимостью в несколько миллиардов долларов в тентах, лишённых даже резервного питания и готовых к отлючению из-за сбоев питания и охлаждения. На тот момент считалось, что тенты будут использоваться временно, пока не построят постоянные корпуса ЦОД. Впрочем, глава Meta✴ Марк Цукерберг (Mark Zuckerberg) заявил, что в компании есть сильная команда, занимающаяся разработкой ЦОД, и он хотел бы, чтобы они не просто строили большие бетонные здания по четыре года каждое. Из-за этого и родилась идея с тентами. 
Источник изображения: Meta✴ Кампус в Галлатине официально открылся в ноябре 2024 года. Изначально планировалось построить на территории дата-центр площадью 91 300 м2 и сопутствующую инфраструктуру на участке площадью 325 га. Впоследствии проект получил ещё 58 250 м2 площадей ЦОД и 4180 м2 офисных помещений. А уже в этом году компания приступила к строительству ещё одного здания, что увеличит общую полезную площадь кампуса до 176 516 м2. Дополнительно Meta✴ стремится наращивать возможности в сфере ИИ с помощью аренды ускорителей у других компаний. На днях она подписала облачное соглашение на $14,2 млрд с CoreWeave, которая предоставит IT-гиганту доступ к собственным ИИ-чипам. В августе 2025 года она заключила договор с Google Cloud на сумму $10 млрд сроком на шесть лет. Сейчас компания ведёт переговоры и с Oracle — об облачном соглашении на $20 млрд.
04.10.2025 [12:56], Сергей Карасёв
Fujitsu и NVIDIA создадут вычислительную ИИ-инфраструктуру нового поколенияЯпонская корпорация Fujitsu объявила о расширении стратегического сотрудничества с NVIDIA с целью создания полнофункциональной инфраструктуры ИИ следующего поколения, в состав которой войдут ИИ-агенты. Предполагается, что инициатива поможет ускорить развитие таких отраслей, как здравоохранение, производство, робототехника и др. Партнёры намерены работать по ряду направлений. В частности, Fujitsu и NVIDIA займутся созданием передовой вычислительной инфраструктуры для задач ИИ. Речь идёт об объединении серверных процессоров Fujitsu Monaka на архитектуре Arm с высокопроизводительными GPU разработки NVIDIA. Для этого будет задействована технология NVLink Fusion, позволяющая применять скоростные интерконнекты NVLink со сторонними чипами. Конечной целью является предоставление комплексной экосистемы HPC-ИИ с интегрированным софтом Fujitsu для Arm-процессоров и NVIDIA CUDA. Кроме того, сотрудничество предусматривает создание «саморазвивающейся» платформы ИИ-агентов. Она, как ожидается, обеспечит высокую производительность и безопасность. Планируется внедрение механизма, который позволит агентам и моделям ИИ развиваться автономно с возможностью оптимизации под запросы конкретных отраслей. В конечном итоге, такие агенты будут предоставляться заказчикам в виде микросервисов NVIDIA NIM. 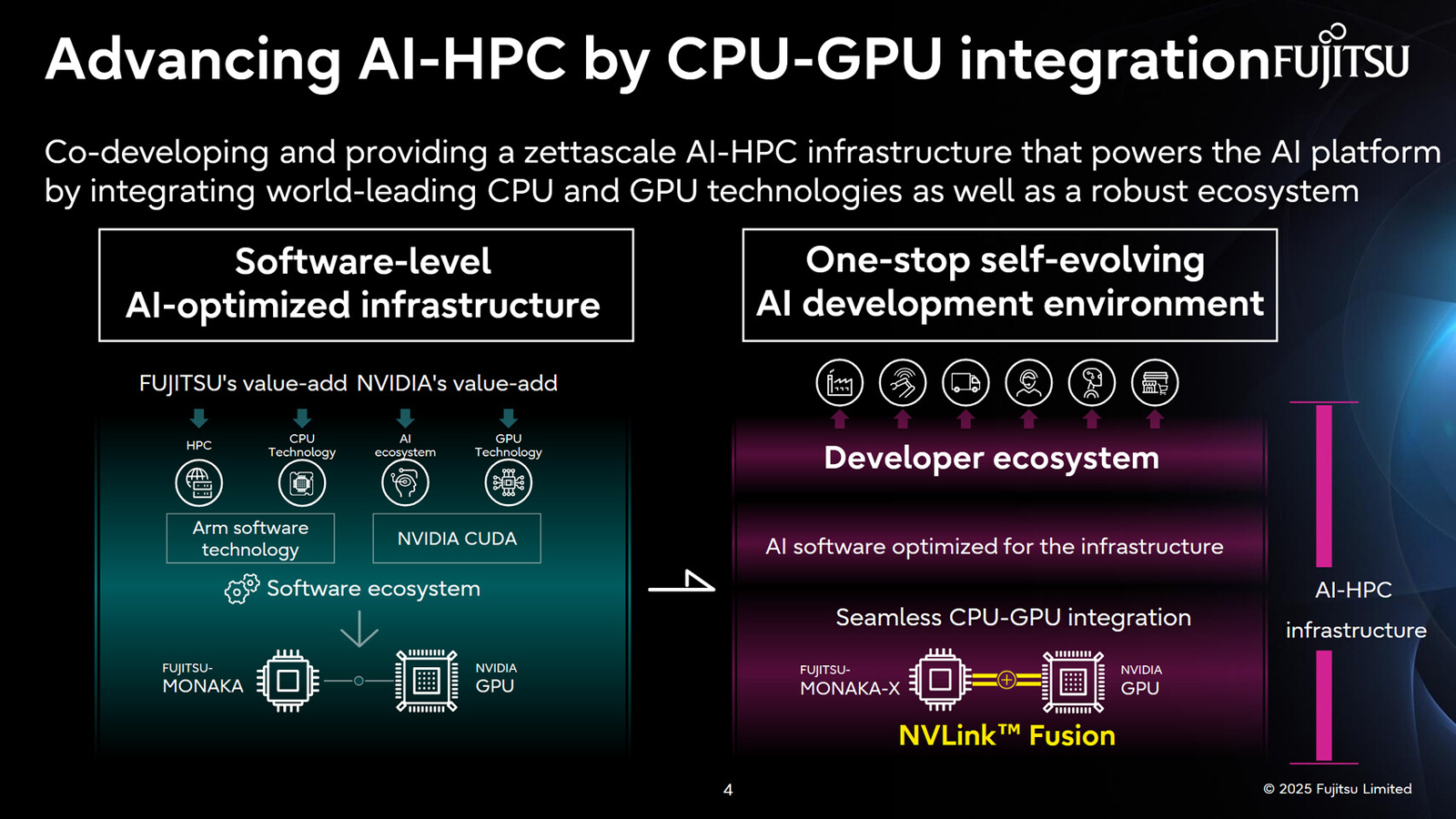
Источник изображений: Fujitsu Ещё одним направлением сотрудничества названо формирование партнёрской экосистемы для расширения использования агентов и моделей ИИ. Планируется также разработка передовых квантовых технологий, включая гибридные квантово-классические вычислительные системы на основе чипов Monaka и НРС-решений NVIDIA.  В целом, как отмечается, к 2030 году спрос на вычислительные мощности для ИИ в Японии вырастет в 320 раз по сравнению с 2020-м. На этом фоне местные компании, включая Fujitsu, SoftBank и KDDI, активно реализуют различные проекты, направленные на развитие рынка ИИ. |
|

