Материалы по тегу: intel xe
|
02.06.2026 [01:04], Владимир Мироненко
ИИ-ускоритель Intel Crescent Island получит до 480 Гбайт LPDDR5XIntel сообщила новые подробности о своём будущем ИИ-ускорителе для ЦОД с кодовым именем Crescent Island, который был анонсирован в прошлом году. Новый GPU основан на архитектуре Xe3P, представляющей усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake. Ожидается, что Xe3P также будет использоваться в GPU Intel серии Arc-C для клиентских устройств. Компания отметила, что чип разработан специально для рабочих нагрузок агентного ИИ. В то время как традиционные ИИ-ускорители от NVIDIA и AMD полагаются на дорогую память HBM, в новом чипе Intel используется LPDDR5X, и он предназначен для работы в серверах с воздушным охлаждением, а не с жидкостным. Crescent Island будет поддерживать до 480 Гбайт памяти LPDDR5X, хотя базовая эталонная конфигурация рассчитана на 160 Гбайт. Intel заявила, что Crescent Island оптимизирован по производительности на Вт — до TDP 350 Вт в версии с воздушным охлаждением и интерфейсом PCIe. 
Источник изображений: Intel Сообщается, что GPU будет поддерживать широкий спектр форматов данных от FP4 до FP64, а также полностью открытый программный стек oneAPI, что идеально подходит для поставщиков услуг «токены как услуга» и сценариев использования для инференса. Концептуально новинка напоминает Rubin CPX, от которого NVIDIA отказалась.  Intel уже оценивает свой открытый унифицированный программный стек для гетерогенных систем ИИ с помощью существующей линейки Arc Pro B-серии, поэтому будущие версии чипов получат доступ к этим оптимизациям на ранних этапах. Intel планирует начать тестирование GPU Crescent Island для клиентов во II половине 2026 года с общей доступностью в 2027 году.
15.10.2025 [09:13], Сергей Карасёв
Intel представила GPU-ускоритель Crescent Island для ИИ-инференсаКорпорация Intel, как и ожидалось, представила на мероприятии OCP Global Summit в Сан-Хосе (Калифорния, США) графический процессор нового поколения для дата-центров. Изделие с кодовым названием Crescent Island специально оптимизировано для задач ИИ-инференса. В основу GPU положена архитектура Xe3P. Она представляет собой усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake для ноутбуков и компактных настольных ПК. Говорится об улучшенном показателе производительности в расчёте на 1 Вт затрачиваемой энергии. Ускоритель на базе Crescent Island получит 160 Гбайт памяти LPDDR5X. Как отмечает ресурс Tom's Hardware, максимальный объём чипов LPDDR5X составляет 8 Гбайт. При этом используются два 16-бит канала памяти, что в сумме даёт 32 бита. Таким образом, для обеспечения 160 Гбайт памяти требуются 20 чипов LPDDR5X. Это означает, что ускоритель получит либо один массивный GPU с 640-бит интерфейсом памяти для подключения всех 20 чипов LPDDR5X, либо два менее крупных процессора с 320-бит интерфейсом, каждый из которых будет обслуживать 10 чипов LPDDR5X. 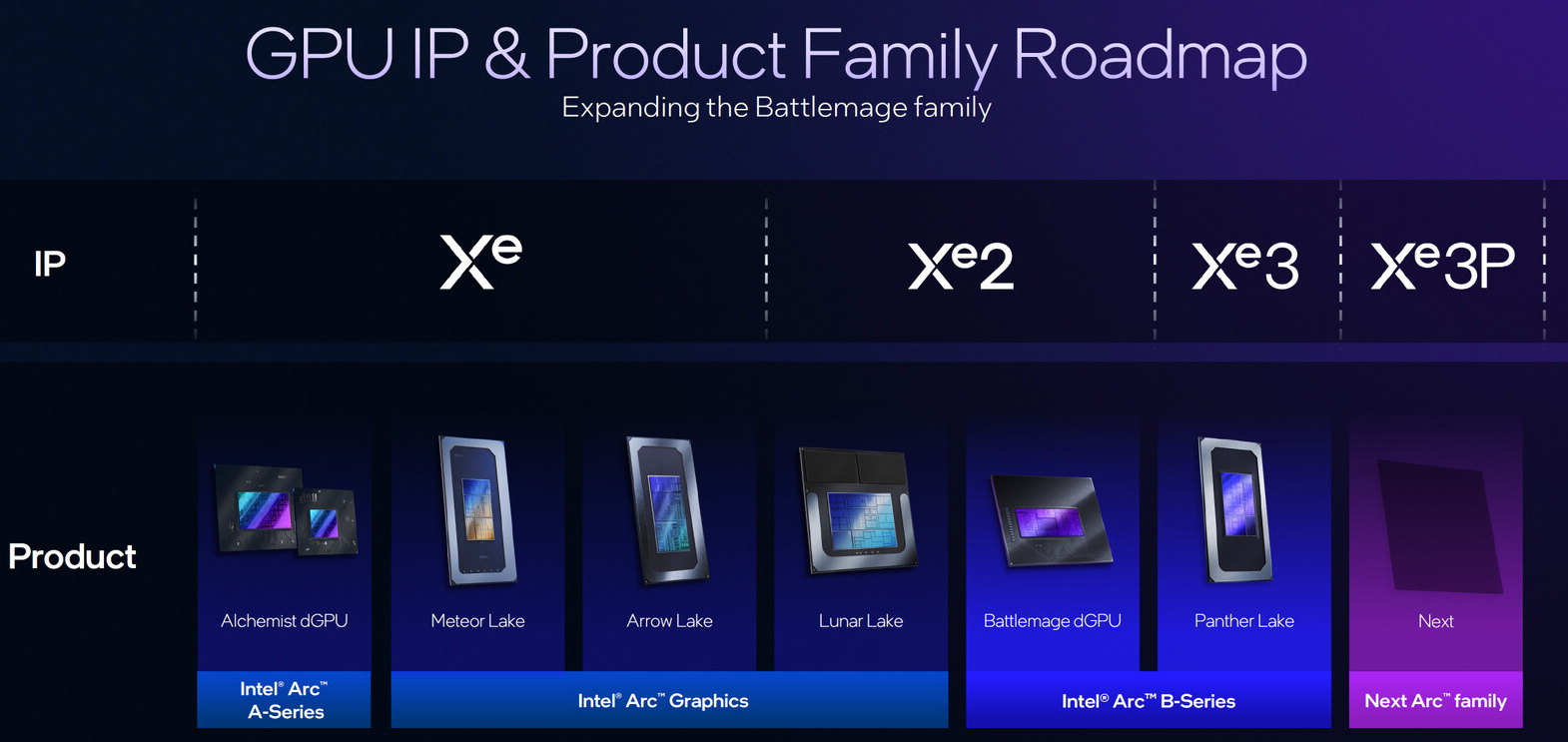
Источник изображения: Intel Прочие технические детали не раскрываются. При этом Intel отмечает, что изделие Crescent Island предназначено для использования в серверах с воздушным охлаждением. GPU поддерживает работу с широким спектром типов данных, благодаря чему может применяться в составе облачных платформ «токен как услуга» (tokens-as-a-service). 
Источник изображения: Intel Пробные поставки новинки планируется начать во II половине 2026 года, тогда как широкая доступность ожидается не ранее 2027-го. Решениям на основе Crescent Island предстоит конкурировать с ИИ-ускорителями AMD и NVIDIA следующего поколения, такими как Rubin CPX.
22.09.2025 [13:02], Сергей Карасёв
ASRock представила видеокарты Intel Arc Pro B60 для рабочих станций с ИИКомпания ASRock анонсировала видеокарты Intel Arc Pro B60 Passive 24GB и Intel Arc Pro B60 Creator 24GB для профессиональных рабочих станций, ориентированных на задачи ИИ, большие языковые модели (LLM), дизайн, 3D-моделирование и пр. Новинки выполнены на архитектуре Intel Xe2-HPG и оснащены 24 Гбайт памяти GDDR6 со 192-битной шиной (19 Гбит/с). Модель Intel Arc Pro B60 Passive 24GB, наделённая пассивным охлаждением, имеет однослотовое исполнение. Карта будет доступна исключительно бизнес-заказчикам. В свою очередь, Intel Arc Pro B60 Creator 24GB получила активный кулер (с бесшумным режимом 0dB Silent Cooling) и двухслотовое исполнение. Обе новинки могут использоваться в конфигурациях с несколькими GPU в Linux-средах, что делает их подходящими для серверных развёртываний в рамках масштабных ИИ-платформ. 
Источник изображений: ASRock Видеокарты располагают 20 ядрами Xe2-HPG и 160 матричными движками (XMX). Частота ядра составляет 2400 МГц. Задействован интерфейс PCIe 5.0. Дополнительное питание подаётся через 8-контактный коннектор. Говорится о поддержке Microsoft DirectX 12 Ultimate. Доступны четыре интерфейса DisplayPort 2.1 — основной с поддержкой UHBR13.5 и три дополнительных с поддержкой UHBR10. Видеокарта Intel Arc Pro B60 Passive 24GB имеет размеры 190 × 112 × 19 мм и весит 566 г. Габариты Intel Arc Pro B60 Creator 24GB составляют 271 × 112 × 39 мм, масса — 1118 г.  Некоторые ретейлеры уже начали приём предварительных заказов на эти решения. Так, на сайте американского магазина Central Computers версия Intel Arc Pro B60 Creator 24GB предлагается по ориентировочной цене $600.
21.11.2024 [00:26], Владимир Мироненко
Intel случайно раскрыла, что готовит ИИ-ускоритель Jaguar Shores вслед за Falcon ShoresIntel сообщила о новом ИИ-ускорителе Jaguar Shores, готовящемся в качестве преемника Falcon Shores, упомянув его в презентации во время технического семинара на конференции SC24. Презентация была посвящена чипам Gaudi, сообщает ресурс HPCwire. По мнению источника, упоминание чипа следующего поколения в презентации могло быть случайным. Ожидается, что Falcon Shores поступит в серийное производство в 2025 году. Также в следующем году в массовую продажу поступит ИИ-ускоритель Gaudi 3, представленный ещё в феврале 2023 года. В остальном Intel предпочитает не раскрывать подробностей о своих планах по выпуску ИИ-чипов. Для сравнения, NVIDIA и AMD уже анонсировали планы по выпуску чипов вплоть до 2026–2027 гг. В августе прошлого года Intel сообщила ресурсу HPCwire о работе над чипом Falcon Shores 2, который планируется к выпуску в 2026 году. «У нас упрощённая дорожная карта, поскольку мы объединяем наши GPU и ускорители в единое предложение», — пояснил тогда генеральный директор Патрик Гелсингер (Pat Gelsinger). С тех пор финансовое положение Intel значительно ухудшилось, однако компания продолжает разработку новых ИИ-ускорителей. Пока неясно, будет ли Jaguar Shores GPU или ASIC, но логика именования чипов Intel позволяет предположить, что речь идёт именно о GPU следующего поколения. 
Источник изображения: Intel На данный момент Intel уступила рынок ИИ-обучения компаниям NVIDIA и AMD, сосредоточив свои усилия на инференсе с использованием ИИ-ускорителей Gaudi. Вероятно, Jaguar Shores также будет ориентирован на задачи инференса, который Гелсингер определил как более крупный и перспективный рынок. Однако чтобы догнать ушедших вперёд конкурентов NVIDIA и AMD, Jaguar Shores должен стать действительно прорывным продуктом, полагает HPCwire. «Наши инвестиции в ИИ будут дополнять и использовать наши решения на базе x86, с акцентом на корпоративный, экономически эффективный вывод данных. Наша дорожная карта для Falcon Shores остаётся неизменной», — заявил представитель Intel ресурсу HPCwire несколько месяцев назад.
17.09.2024 [20:59], Владимир Мироненко
Объявленный Intel план реструктуризации ставит под сомнение будущее ускорителей Falcon ShoresВ начале недели Intel разослала сотрудникам письмо с описанием плана выхода из кризиса, который ставит под сомнение будущее ускорителей Falcon Shores, ранее намеченных к выпуску в 2025 году, пишет ресурс HPCwire. Согласно плану, компания сосредоточится на выпуске продуктов на архитектуре x86, что может отразиться на производстве Falcon Shores, поскольку глава Intel Пэт Гелсингер (Pat Gelsinger) ранее заявил, что не будет конкурировать с NVIDIA и AMD в области обучения ИИ. Следующий этап реструктуризации также включает сокращение расходов ещё на $10 млрд и увольнение 15 тыс. сотрудников, из которых 7,5 тыс. уже выразили согласие сделать это на добровольной основе. «Мы должны сосредоточиться на нашей сильной франшизе x86, поскольку мы реализуем нашу стратегию ИИ, одновременно оптимизируя наш портфель продуктов для обслуживания клиентов и партнёров Intel», — подчеркнул в письме Гелсингер. В прошлом месяце на аналитической конференции Deutsche Bank он заявил, что компания покидает рынок обучения ИИ с тем, чтобы сосредоточиться на инференсе, используя сильную сторону чипов x86. 
Источник изображения: Intel Желание Intel сократить расходы и отказаться от неактуальных продуктов может повлиять на реализацию проекта по выпуску Falcon Shores, ускорителя для ЦОД, выход которого неоднократно откладывался. Он является преемником ускорителя Intel Ponte Vecchio (Data Center GPU Max 1550) на базе архитектуры Xe, массовый выпуск которого был фактически прекращён после ввода в эксплуатацию суперкомпьютера Aurora. Ранее Intel отказалась от ускорителей серии Rialto Bridge, а в Falcon Shores было решено отказаться от гибридного подхода, к которому к этому моменту пришли и AMD, и NVIDIA. Впрочем, от ИИ-ускорителей Gaudi компания не отрекается. Intel не ответила на запрос о комментарии о будущем Falcon Shores. И основные разработчики, занимавшиеся этим проектом — Джейсон Маквей (Jason McVeigh) и Раджа Кодури (Raja Koduri) — либо ушли, либо были назначены на другие должности. Гелсингер признал, что Intel сильно отстаёт от своих конкурентов в области GPU и чипов для обучения ИИ, включая NVIDIA, AWS, Google Cloud и AMD. Впрочем, для AWS Intel будет производить в США кастомные процессоры Xeon 6 и ИИ-ускорители (вероятно, это наследники Trainium/Inferentia). 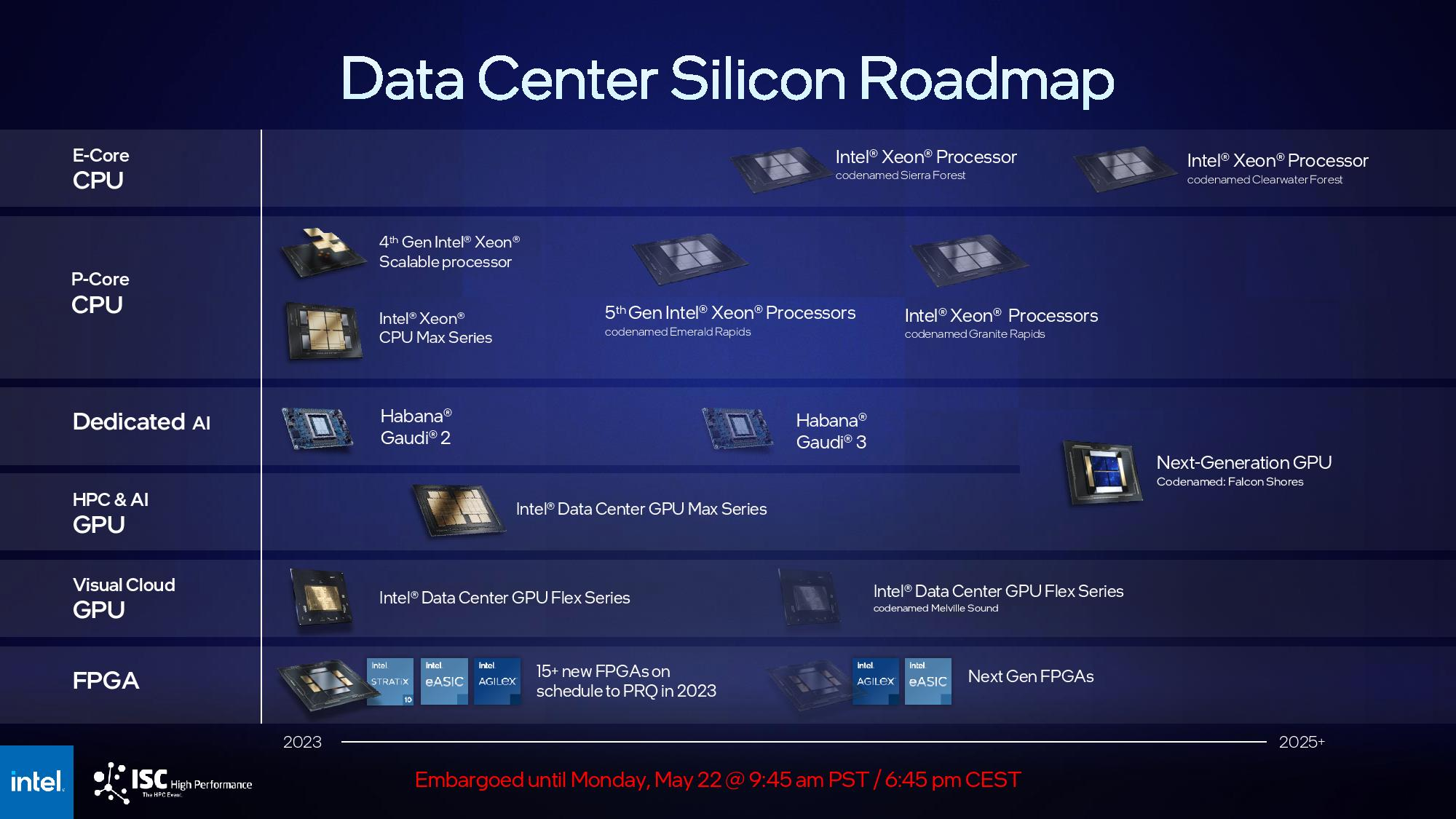
Источник изображения: Intel Также компания отметила отставание на рынке серверов для ЦОД, где сейчас большим спросом пользуются серверы с ИИ-ускорителями. «Где мы ещё не полностью вывели бизнес на хорошие позиции, так это в области CPU для ЦОД», — сообщил в этом месяце финансовый директор Intel Дэйв Цинснер (Dave Zinsner) на конференции Citi Global Technology Conference. Процессоры Xeon Emerald Rapids не оправдали ожиданий компании. Обычный цикл обновления гиперскейлеров в этот раз значительно растянулся, поскольку они активно вкладываются в развитие ИИ-инфраструктуры, попутно увеличивая срок службы традиционных серверов. Следующее поколение Granite Rapids (Xeon 6) должно выйти в начале следующего года. А Diamond Rapids, которые будут выпускаться по техпроцессу Intel 18A (1,8 нм), как ожидается, помогут вывести Intel на лидирующие позиции. Выход на производство по техпроцессу 18A с использованием новой структуры транзисторов RibbonFET и технологии PowerVia является для Intel одной из приоритетных задач. В частности, это техпроцес будет использоваться для выпуска серверных процессоров Clearwater Forest. Пока Intel под натиском AMD активно теряет долю рынка серверных CPU.
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 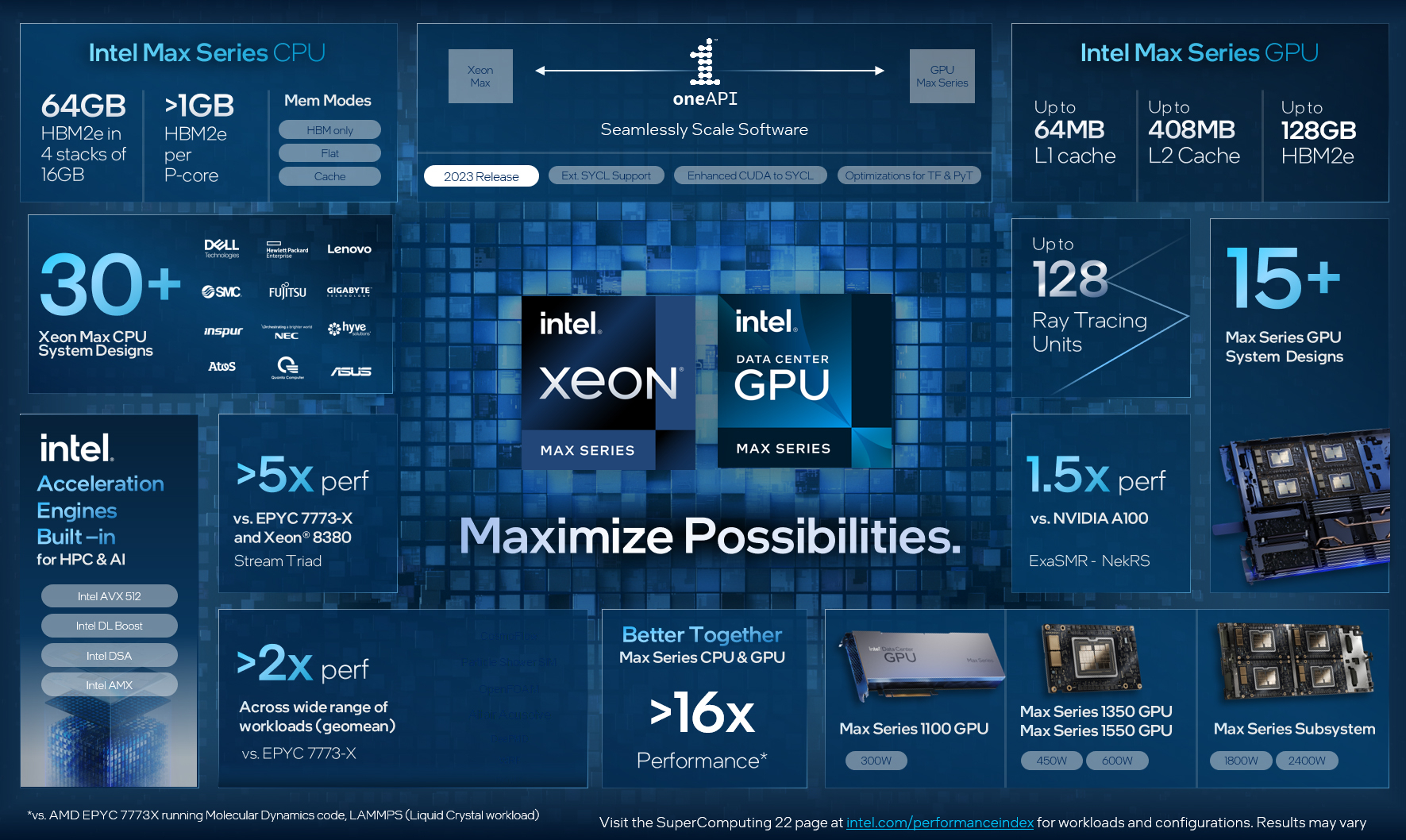
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 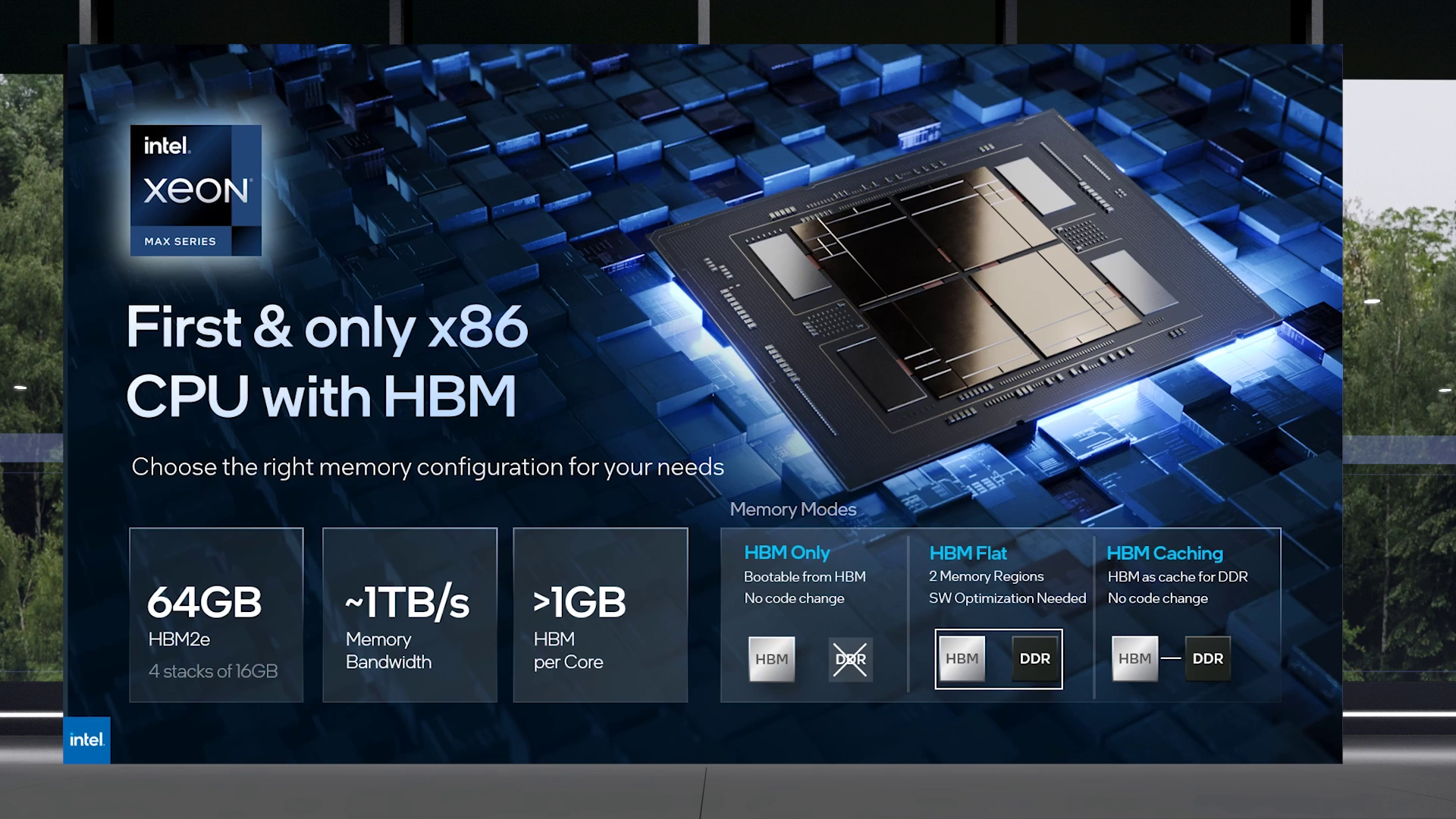 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA.
24.08.2022 [21:16], Алексей Степин
Intel переименовала свои первые серверные ускорители Intel Arctic Sound-M во FlexРанее мы уже рассказывали об ускорителях Intel Arctic Sound-M, о которых впервые стало известно ещё зимой. Это универсальное решение, базирующееся на графической архитектуре Xe-HPG и предназначенное для решения широкого круга задач, от организации виртуальных рабочих мест до применения в системах машинной аналитики. Сегодня Intel официально заявила, что ускорители Arctic Sound-M теперь будут доступны под брендом Flex. В основе по-прежнему лежит микроархитектура DG2 Alchemist, и компания позиционирует Flex как решение, способное ощутимо снизить стоимость владения для серверной инфраструктуры, особенно занятой в задачах транскодирования видеопотоков. 
Источник: Intel Intel заявляет, что Flex 140 в пять раз превосходит NVIDIA A10 в задачах транскодирования видео, вдвое — в сценариях декодирования, и всё это с вдвое меньшим уровнем энергопотребления, а значит, и тепловыделения. Речь идёт о младшем решении в серии с интерфейсом PCIe 4.0 x8, которое имеет два восьмиядерных чипа Xe (1600/1950 МГц) и 12 Гбайт GDDR6-памяти (192 бит, 336 Гбайт/с). Flex 170 оснащён одним чипом, но в 32-ядерном варианте (1950/2050 МГц), и имеет вдвое более высокий теплопакет (150 против 75 Вт), а также 16 Гбайт GDDR6 (256 бит, 576 Гбайт/с) и интерфейс PCIe 4.0 x16. 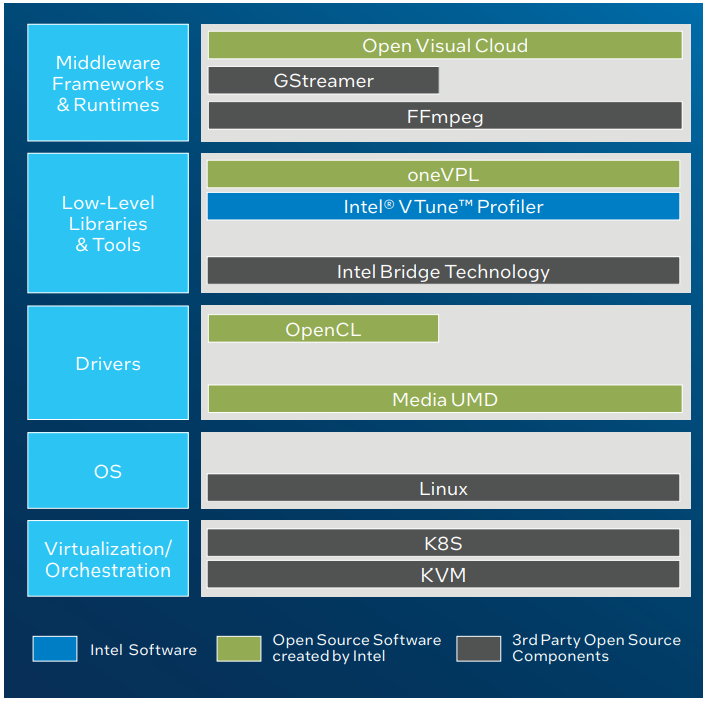
Источник: Intel До 10 ускорителей Flex 140 можно разместить в стандартном 4U-шасси, что позволит одновременно обрабатывать до 360 потоков 1080р60 HEVC. Производительность Flex 140 достаточно высока, чтобы гарантировать задержку не более 1 сек при начале транскодирования видеопотока с параметрами 8K@60 (AV1 или HEVC HDR). Intel активно делает упор на аппаратной поддержке видеостандарта AV1, но ускорители работают и с HEVC, AVC и VP9. 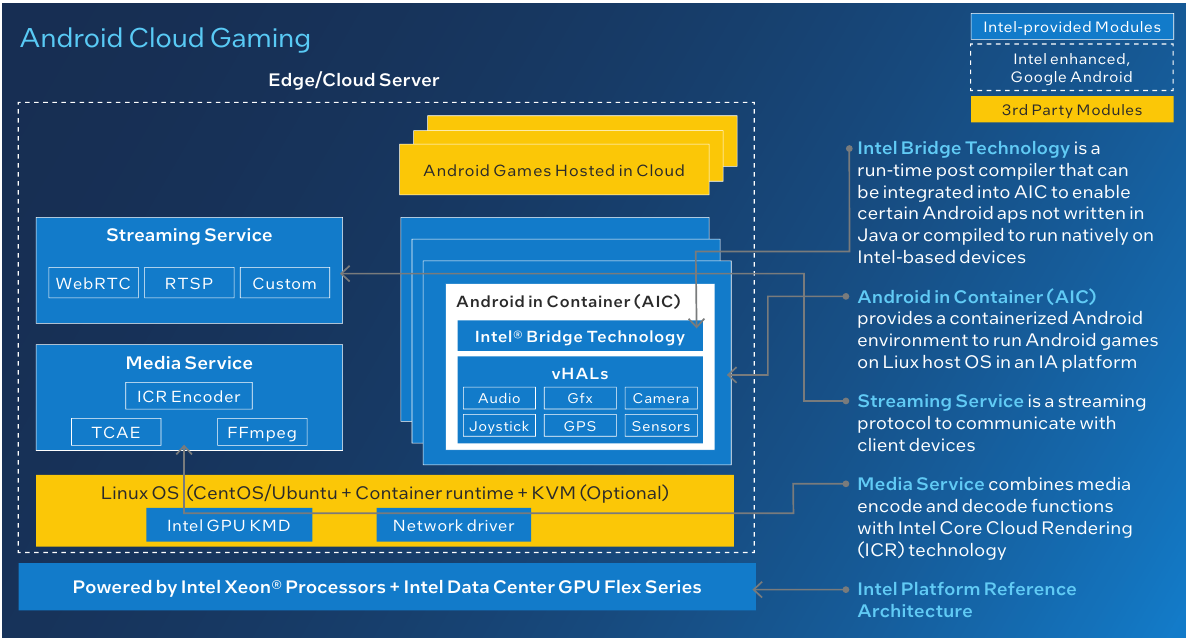
Архитектура облачного Android-гейминга Intel. Источник: Intel Также найдут своё применения ускорители Intel Flex Series и в облачных игровых платформах для Android, где единственная плата Flex 170 сможет обслуживать до 68 сессий в режиме 720p30, а шесть ускорителей Flex 140 будут в состоянии обеспечить до 216 игровых сессий с такими же параметрами. Помимо всего прочего поддерживается и аппаратное ускорение трассировки лучей. Работают новые ускорители под управлением унифицированной платформы oneAPI. 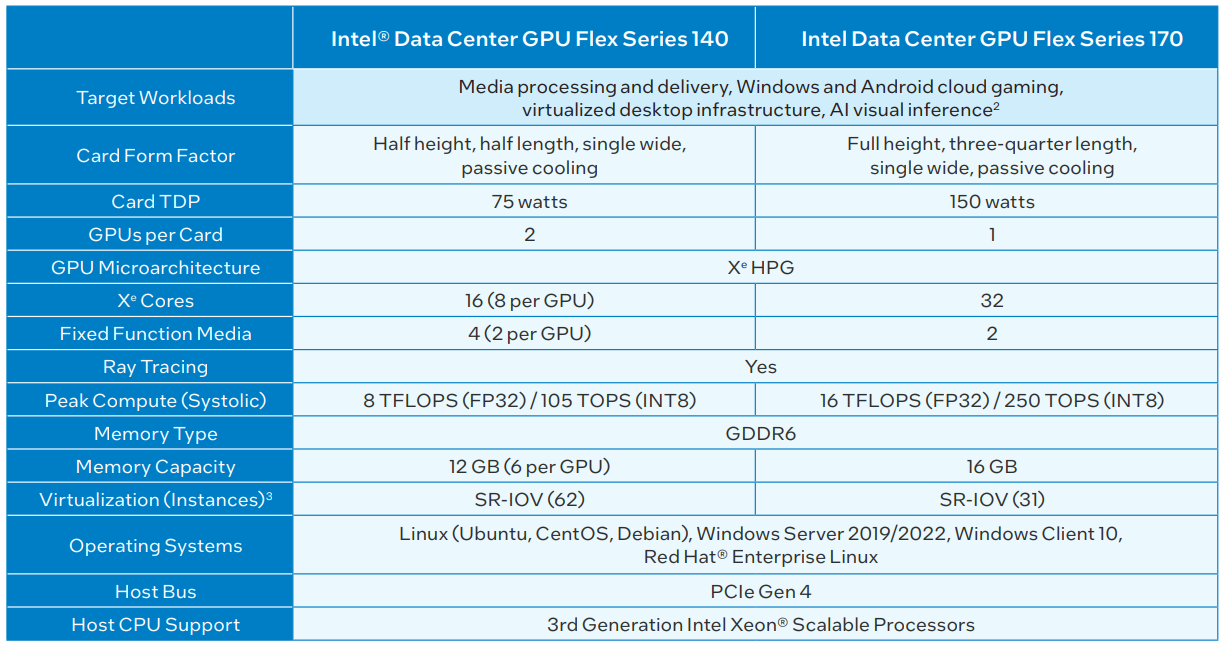 Стоимости новых ускорителей Intel пока не разглашает, но с учётом того, что компания сильно упирает на снижение стоимости владения, цена, судя по всему, будет сравнительно доступной и наверняка более привлекательной, чем у NVIDIA A10. Кроме того, Intel говорит об отсутствии необходимости докупать лицензии, чтобы воспользоваться всеми возможностями ускорителей. Но умалчивает, что производительность старшей модели Flex 170 в INT8-вычислениях совпадает с таковой у A10 (250 Топс), а в FP32-расчётах решение Intel и вовсе проигрывает. К тому же у A10 в полтора раза больше RAM.
19.08.2021 [16:00], Игорь Осколков
Intel анонсировала ускорители Xe HPC Ponte Vecchio: 100+ млрд транзисторов, микс 5/7/10-нм техпроцессов Intel и TSMC и FP32-производительность 45+ ТфлопсКак и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.  Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.  Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.  Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.  Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков. 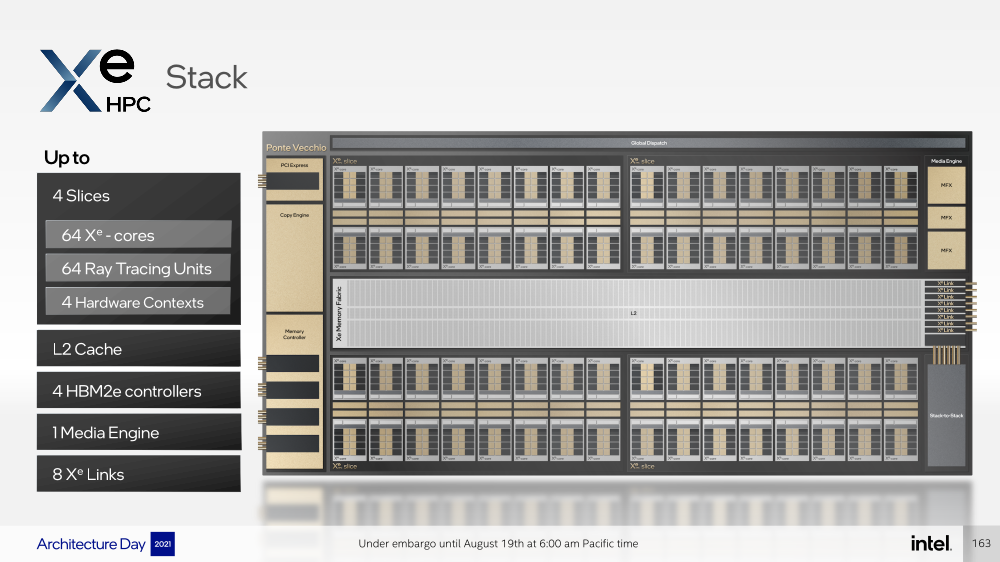 Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом. 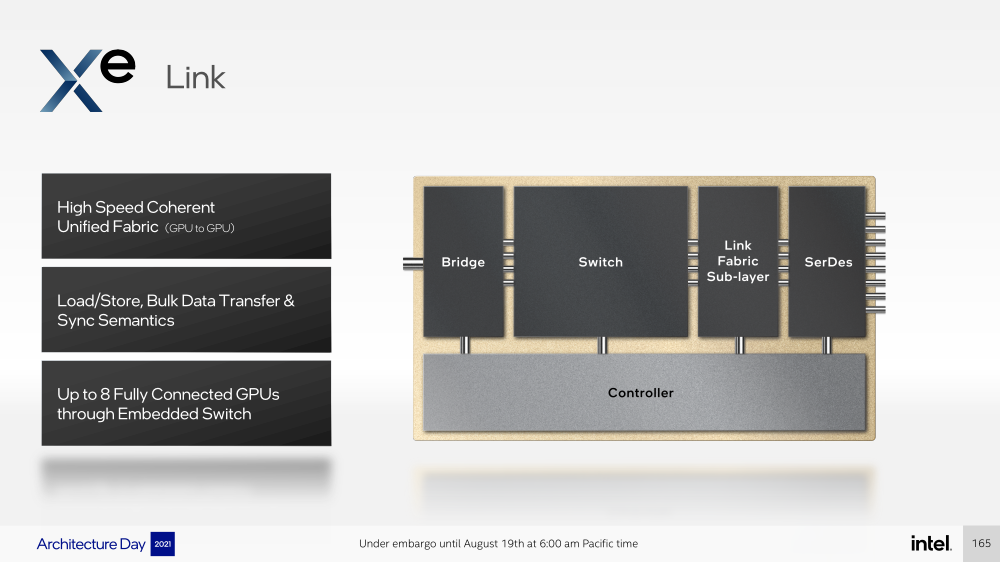  В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс. 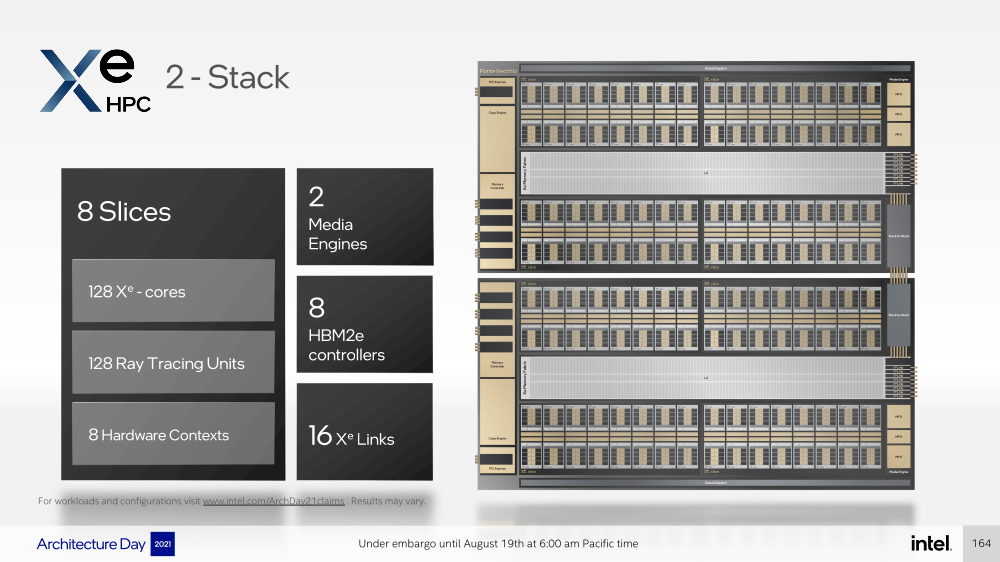 Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.  В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).  Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA. |
|


