Материалы по тегу: ids
|
28.08.2024 [12:32], Сергей Карасёв
Sapphire Rapids Refresh для рабочих станций: Intel Xeon W-2500 и W-3500 получили до 60 ядер и до 112,5 Мбайт кешаКорпорация Intel, по сообщению ресурса VideoCardz, представила процессоры Xeon W-2500 и W-3500 поколения Sapphire Rapids Refresh. Эти чипы предназначены для применения в рабочих станциях и высокопроизводительных настольных компьютерах. Они придут на смену семействам Xeon W-3400 и W-2400. В серию Xeon W-2500 вошли изделия с 26, 22, 18, 14, 12, 10 и 8 ядрами. Во всех случаях поддерживается технология многопоточности. Объём кеша L3 варьируется от 22,5 до 48,75 Мбайт. Версии с 8 и 10 ядрами могут работать с памятью DDR5-4400, все другие модели — с DDR5-4800 (четыре канала). Показатель базовой мощности (Processor Base Power, PBP) варьируется от 175 до 250 Вт. 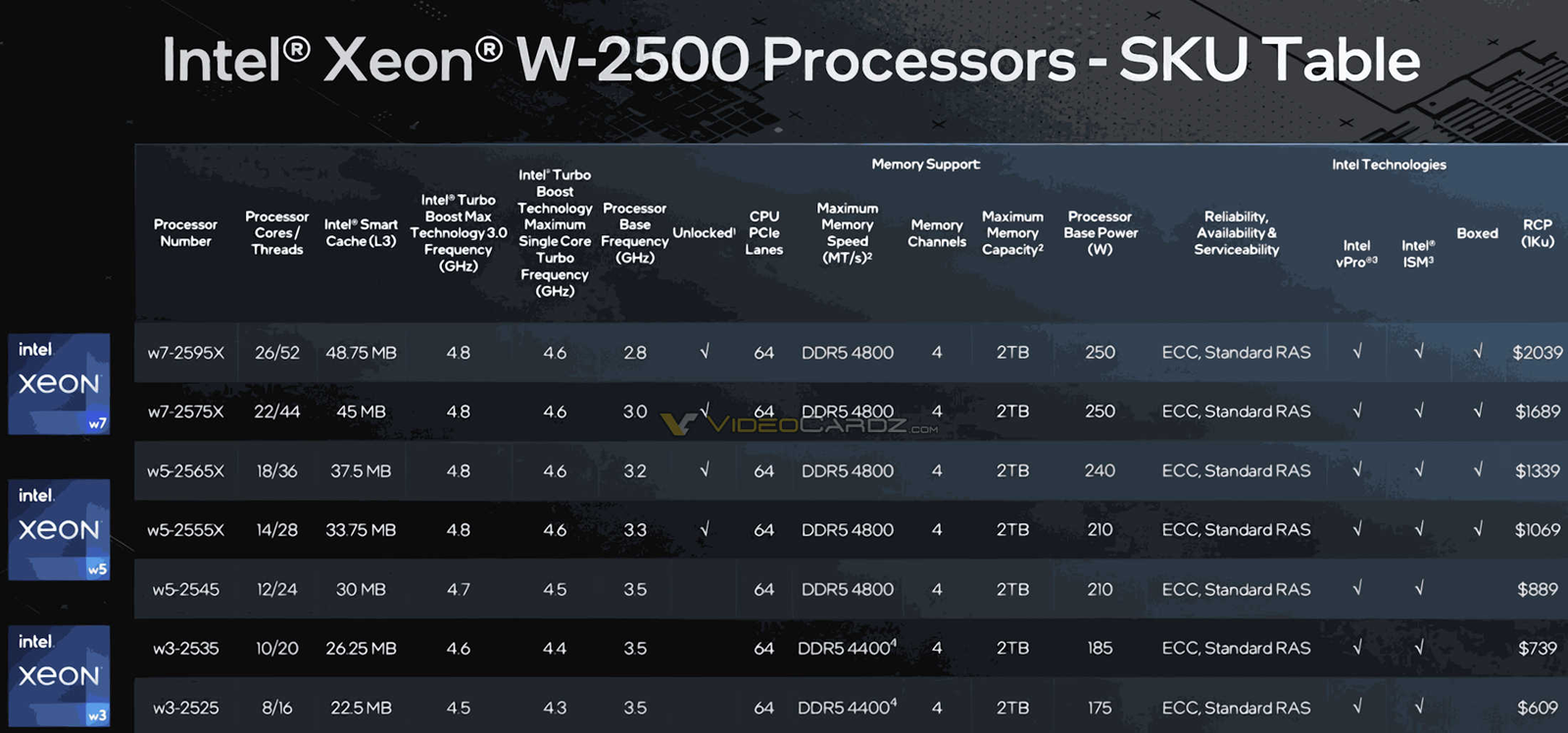
Источник изображений: VideoCardz Семейство Xeon W-2500 возглавляет модель Xeon W7-2595X с 26 ядрами: базовая частота равна 2,8 ГГц, максимальная — 4,8 ГГц. Этот чип, как и другие решения с суффиксом «X», имеет разблокированный множитель, благодаря чему обеспечивается возможность разгона. Все процессоры серии поддерживают 64 линии PCIe 5.0. Цена варьируется от $609 до $2039. 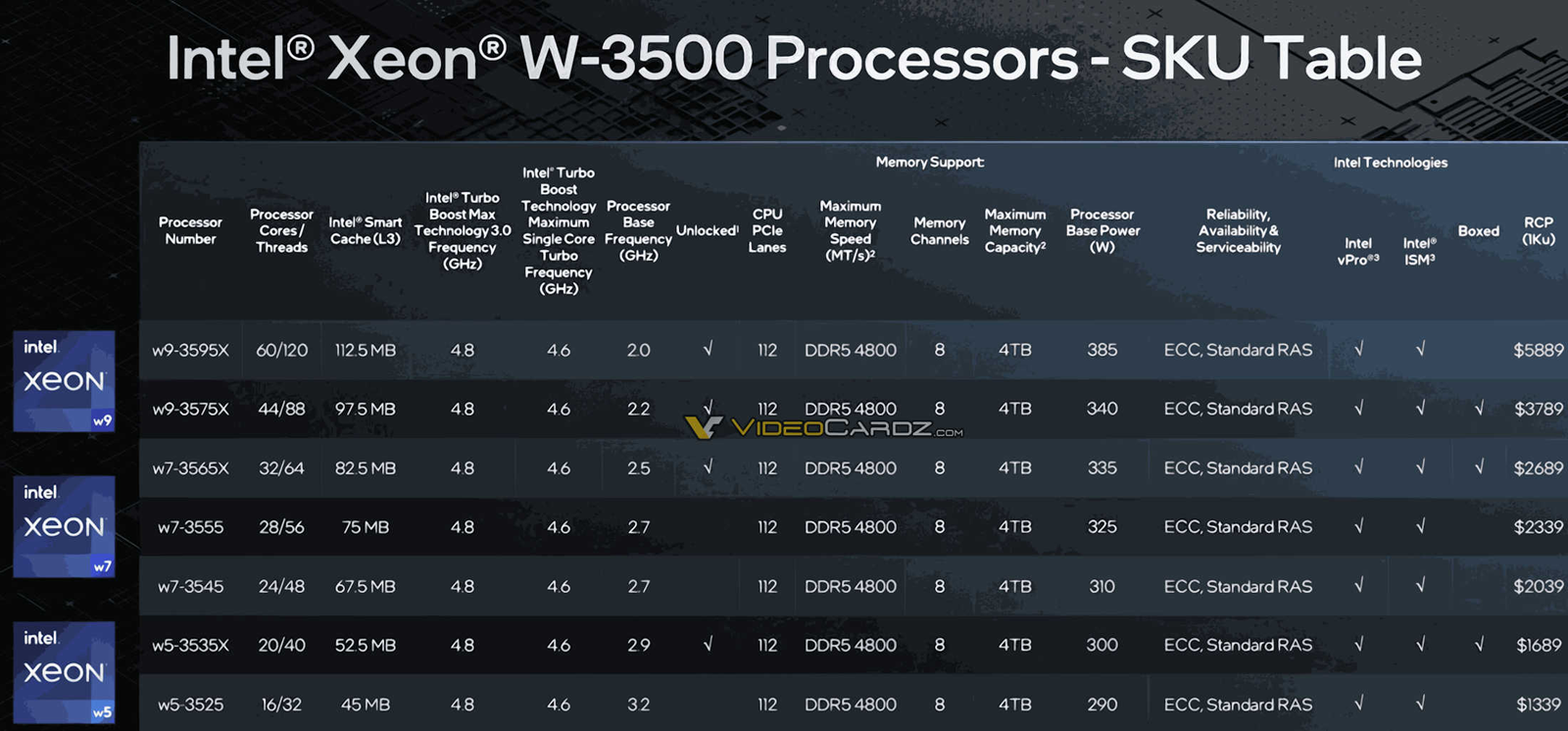 Более мощные изделия Xeon W-3500 насчитывают от 16 до 60 ядер с поддержкой многопоточности. Размер кеша L3 — от 45 до 112,5 Мбайт. Все процессоры могут работать с памятью DDR5-4800 (восемь каналов). Количество линий PCIe 5.0 равно 112. Значение PBP находится в диапазоне от 290 до 385 Вт. На вершине семейства располагается модель Xeon W9-3595X с базовой частотой 2,0 ГГц и максимальной частотой 4,8 ГГц. Цена варьируется от $1339 до $5889. Новые процессоры рассчитаны на работу с материнскими платами на чипсете Intel W790. 
Источник изображения: Intel
27.08.2024 [16:32], Сергей Карасёв
Xeon 6 на границе: Intel Granite Rapids-D получат поддержку PCIe 5.0, 2 × 100GbE, DDR5-5600 и MCR-DIMMКорпорация Intel раскрыла некоторые технические характеристики SoC Xeon 6 поколения Granite Rapids-D, предназначенных для периферийных решений (edge), в том числе на базе платформы Intel Tiber Edge. Изделия, использующие чиплетную компоновку, появятся на рынке в 2025 году. Процессоры базируются на производительных P-ядрах Redwood Cove. Каждое ядро получило по 64 Кбайт L1-кеша для инструкций и данных, а также L2-кеш объёмом 2 Мбайт. Конструкция SoC включает один или два вычислительных тайла, а также тайл ввода-вывода (I/O), отвечающий за реализацию PCIe, CXL и различных вспомогательных ускорителей. Вычислительные блоки производятся по техпроцессу Intel 3, IO-тайл — по техпроцессу Intel 4. Тайлы «сшиты» посредством EMIB. 
Источник изображения: Intel Xeon 6 Granite Rapids-D будут доступны в модификациях с поддержкой четырёх (2DPC) и восьми каналов памяти. Размеры BGA-упаковок — 77,5 × 50 мм и 77,5 × 56,5 мм соответственно. Говорится о поддержке DDR5-5600 м MCR-DIMM, 32 линий PCIe 5.0, 16 линий PCIe 4.0 и 16 линий CXL 2.0. Возможно использование до восьми Ethernet-портов 1/10/25GbE, до четырёх портов 50GbE или двух портов 100GbE. Ethernet-контроллер поддерживает классификацию пакетов и обработку ACL, предлагает различные планировщики и возможность программируемой обработки трафика. Возможности Intel QAT (Quick Assist Technology) тоже значительно расширены. Во-первых, теперь в состав QAT входит медиаускоритель для обработки потокового видео на лету: (де-)кодирования и транскодирования, масштабирования, обрезки кадра и т.д. Говорится как минимум о поддержка 1080p@30 для AVC/HEVC/AV1. Видеопоток при необходимости можно тут же направить к процессорным ядрам с AMX. Во-вторых, появилась возможность в один проход сжать и зашифровать данные с попутной проверкой их целостности. 
Источник изображения: Intel Чипы также получили поддержку Intel DLB (Dynamic Load Balancer), Intel vRAN Boost, Intel Data Streaming Accelerator (DSA), Intel SGX (Software Guard Extensions), Intel TDX (Trust Domain Extensions). Кроме того, были значительно расширены возможности функции Intel RDT (Resource Director Technology), которая теперь позволяет отслеживать и управлять состоянием IO-устройств, включая PCIe, CXL, интегрированных ускорителей и т.д. Встроенные ИИ-возможности обеспечивает более чем 8-кратный прирост быстродействия в Resnet-50 и более чем 6-кратное увеличение производительности в Visual Transformer по сравнению с Xeon D 2899NTN предыдущего поколения (с AVX512 VNNI) благодаря новым инструкциям AMX. Поддерживается работа в режиме FP16. Intel пока не раскрывает максимальное количество вычислительных ядер у Xeon 6 Granite Rapids-D. Но в ходе презентации был упомянут вариант с 42 ядрами, работающий в связке со 128 Гбайт памяти DDR5-5600/4800. Процессоры будут предлагаться в версиях, оптимизированных для вычислительных нагрузок и edge-приложений с ИИ-функциями.
19.08.2024 [10:10], Сергей Карасёв
Gigabyte представила ИИ-серверы с ускорителями NVIDIA H200 и процессорами AMD и IntelКомпания Gigabyte анонсировала HGX-серверы G593-SD1-AAX3 и G593-ZD1-AAX3, предназначенные для задач ИИ и НРС. Устройства, выполненные в форм-факторе 5U, включают до восьми ускорителей NVIDIA H200. При этом используется воздушное охлаждение. 
Источник изображений: Gigabyte Модель G593-SD1-AAX3 рассчитана на два процессора Intel Xeon Emerald Rapids с показателем TDP до 350 Вт, а версия G593-ZD1-AAX3 располагает двумя сокетами для чипов AMD EPYC Genoa с TDP до 300 Вт. Доступны соответственно 32 и 24 слота для модулей оперативной памяти DDR5.  Серверы наделены восемью фронтальными отсеками для SFF-накопителей NVMe/SATA/SAS-4, двумя сетевыми портами 10GbE на основе разъёмов RJ-45 (выведены на лицевую панель) и выделенным портом управления 1GbE (находится сзади). Есть четыре слота FHHL PCIe 5.0 x16 и восемь разъёмов LP PCIe 5.0 x16. Модель на платформе AMD дополнительно располагает двумя коннекторами М.2 для SSD с интерфейсом PCIe 3.0 x4 и x1.  Питание у обоих серверов обеспечивают шесть блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. Габариты новинок составляют 447 × 219,7 × 945 мм. Диапазон рабочих температур — от +10 до +35 °C. Есть два порта USB 3.2 Gen1 и разъём D-Sub. Массовое производство серверов Gigabyte серии G593 запланировано на II половину 2024 года. Эти системы станут временной заменой (G)B200-серверов, выпуск которых задерживается.
05.08.2024 [08:16], Сергей Карасёв
Новые кластеры Supermicro SuperCluster с ускорителями NVIDIA L40S ориентированы на платформу Omniverse
emerald rapids
hardware
intel
l40
nvidia
omniverse
sapphire rapids
supermicro
xeon
ии
кластер
сервер
Компания Supermicro расширила семейство высокопроизводительных вычислительных систем SuperCluster, предназначенных для обработки ресурсоёмких приложений ИИ/HPC. Представленные решения оптимизированы для платформы NVIDIA Omniverse, которая позволяет моделировать крупномасштабные виртуальные миры в промышленности и создавать цифровых двойников. Системы SuperCluster for NVIDIA Omniverse могут строиться на базе серверов SYS-421GE-TNRT или SYS-421GE-TNRT3 с поддержкой соответственно восьми и четырёх ускорителей NVIDIA L40S. Обе модели соответствуют типоразмеру 4U и допускают установку двух процессоров Intel Xeon Emerald Rapids или Sapphire Rapids в исполнении Socket E (LGA-4677) с показателем TDP до 350 Вт (до 385 Вт при использовании СЖО). Каждый из узлов в составе новых систем SuperCluster несёт на борту 1 Тбайт оперативной памяти DDR5-4800, два NVMe SSD вместимостью 3,8 Тбайт каждый и загрузочный SSD NVMe M.2 на 1,9 Тбайт. В оснащение включены четыре карты NVIDIA BlueField-3 (B3140H SuperNIC) или NVIDIA ConnectX-7 (400G NIC), а также одна карта NVIDIA BlueField-3 DPU Dual-Port 200G. Установлены четыре блока питания с сертификатом Titanium мощностью 2700 Вт каждый. В максимальной конфигурации система SuperCluster for NVIDIA Omniverse объединяет пять стоек типоразмера 48U. В общей сложности задействованы 32 узла Supermicro SYS-421GE-TNRT или SYS-421GE-TNRT3, что в сумме даёт 256 или 128 ускорителей NVIDIA L40S. 
Источник изображения: Supermicro Кроме того, в состав такого комплекса входят три узла управления Supermicro SYS-121H-TNR Hyper System, три коммутатора NVIDIA Spectrum SN5600 Ethernet 400G с 64 портами, ещё два коммутатора NVIDIA Spectrum SN5600 Ethernet 400G с 64 портами для хранения/управления, два коммутатора управления NVIDIA Spectrum SN2201 Ethernet 1G с 48 портами. При необходимости конфигурацию SuperCluster for NVIDIA Omniverse можно оптимизировать под задачи заказчика, изменяя масштаб вплоть до одной стойки. В этом случае применяются четыре узла Supermicro SYS-421GE-TNRT или SYS-421GE-TNRT3.
03.08.2024 [12:33], Сергей Карасёв
128 P-ядер, 504 Мбайт кеша и TDP 500 Вт: утекли характеристики Intel Xeon Granite RapidsВ распоряжении сетевых источников, по сообщению ресурса VideoCardz, оказалась информация о характеристиках части процессоров Intel Xeon 6 семейства Granite Rapids, в основу которых лягут производительные ядра P-core. Речь идёт о чипах Xeon 6900P, которые, как ожидается, появятся на рынке в текущем квартале. Формальная презентация Xeon 6 Granite Rapids состоялась в начале июня текущего года — вместе с изделиями Xeon 6 Sierra Forest, построенными на энергоэффективных ядрах E-core. Для платформы Xeon 6 предусмотрено использование разъёмов LGA-4710 и LGA-7529: в первом случае заявлена поддержка чипов с TDP до 350 Вт и 8-канальной памяти, во втором — 500 Вт и 12-канальной памяти. При этом в обоих вариантах возможно построение двухсокетных серверов. 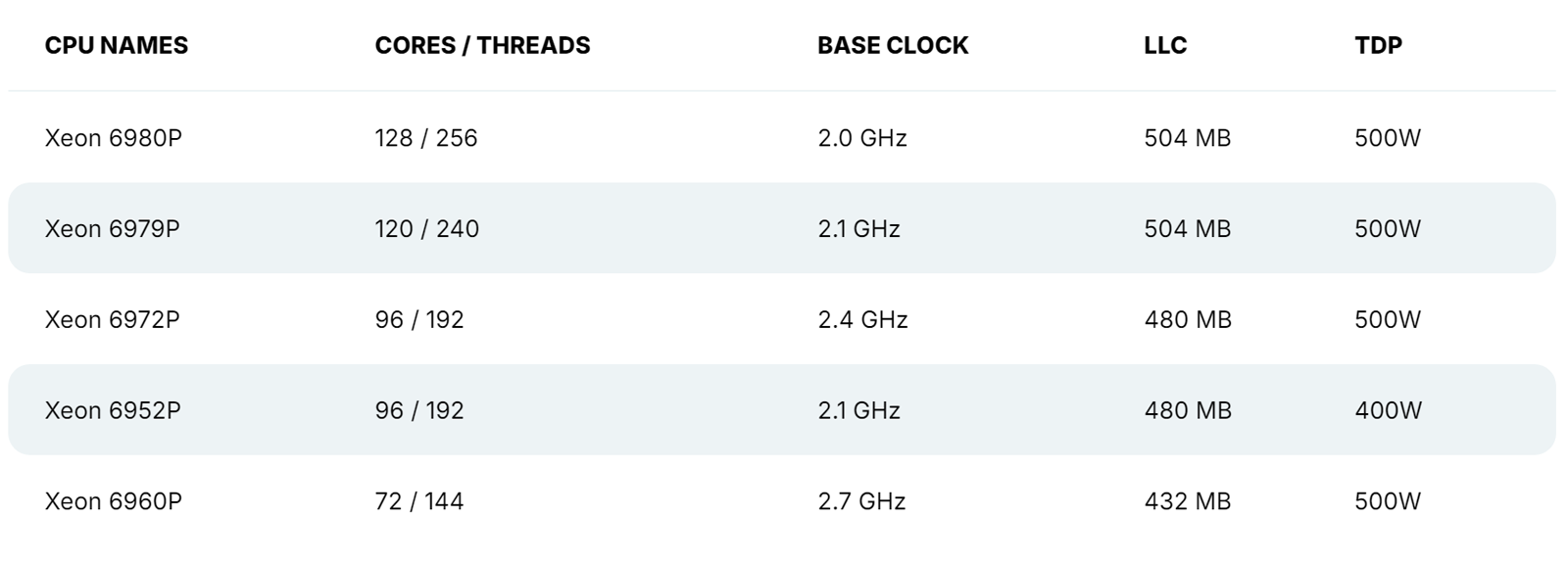
Источник изображения: Wccftech Как стало известно, в семейство Xeon 6 Granite Rapids войдут модели с 32, 44, 56, 72, 96, 120 и 128 ядрами Redwood Cove. Они получат поддержку SMT и до 504 Мбайт L3-кеша. Величина TDP составит до 500 Вт. В частности, говорится о подготовке процессоров Xeon Platinum 6980P, 6979P, 6972P, 6952P и 6960P. Их базовая тактовая частота варьируется от 2,0 до 2,7 ГГц (см. характеристики). Для чипов Xeon 6 Granite Rapids заявлена поддержка памяти DDR5-6400 и MCR-8800, до 96 линий PCIe Gen 5.0/CXL 2.0 и до 6 линий UPI 2.0.
30.06.2024 [14:28], Сергей Карасёв
В Австралии запущен ИИ-суперкомпьютер Virga [Обновлено]Государственное объединение научных и прикладных исследований Австралии (CSIRO) сообщило о вводе в эксплуатацию высокопроизводительного вычислительного комплекса Virga. Система, предназначенная для ИИ-задач, ускорит научные открытия, а также поможет развитию промышленности и экономики страны. Суперкомпьютер располагается в дата-центре Hume компании CDC в Канберре. Его созданием занималась компания Dell: в основу положены серверы PowerEdge XE9640, оснащённые двумя процессорами Intel Xeon Sapphire Rapids 8452Y (36C/72T, 2,0/3,2 ГГц, 300 Вт), до 512 Гбайт RAM и четырьмя 61,44-Тбайт NVMe SSD. Задействованы ИИ-ускорители NVIDIA H100 с 96 Гбайт памяти HBM3 — всего 448 шт. Система занимает 14 стоек, а в качестве интерконнекта используется Infiniband NDR. Dell заключила контракт на создание Virga в 2023 году: сумма изначально составляла $9,65 млн, однако фактическое строительство комплекса обошлось в $10,85 млн. Новый суперкомпьютер придёт на смену НРС-системе CSIRO предыдущего поколения под названием Bracewell, но унаследует от неё BeeGFS-хранилище, также построенное на оборудовании Dell. В нынешнем рейтинге TOP500 машина занимает 72 место с пиковой и практической FP64-производительностью 18,46 Пфлопс и 14,94 Пфлопс соответственно. Комплекс Virga получил своё имя в честь метеорологического эффекта «вирга» — это дождь, который испаряется, не достигая земли: видеть его можно в виде полос, выходящих из-под облаков. Систему Virga планируется использовать для таких задач, как прогнозирование пожаров, разработка вакцин нового поколения, проектирование гибких солнечных панелей, анализ медицинских изображений и пр. 
Источник изображения: CSIRO Пока подробные технические характеристики Virga и показатели быстродействия не раскрываются. Отмечается лишь, что в составе комплекса применена гибридная система прямого жидкостного охлаждения. Говорится также, что CDC оперирует двумя кампусами дата-центров Hume. Площадка Hume Campus One объединяет три ЦОД и имеет мощность 21 МВт, тогда как в состав Hume Campus Two входят два объекта суммарной мощностью 51 МВт.
20.12.2023 [16:13], Сергей Карасёв
Intel Xeon Emerald Rapids на китайский лад: представлены чипы Jintide 5-го поколения с 48 ядрамиКитайская компания Montage Technology, по сообщению ресурса Tom's Hardware, анонсировала процессоры Jintide 5-го поколения для местного рынка. По сути, это новейшие серверные чипы Intel Xeon Emerald Rapids с незначительно изменённой маркировкой и модифицированным набором поддерживаемых технологий. В 2016 году Intel организовала партнёрский проект с китайским университетом Цинхуа и Montage Technology Global Holdings, Ltd. для создания продуктов, ориентированных на рынок серверов и ЦОД в КНР. В рамках сотрудничества поставляются чипы Jintide на базе Xeon разных семейств. В начале 2023 года компании представили серию процессоров Jintide на базе Sapphire Rapids. В серию Jintide 5-го поколения на момент анонса вошли пять моделей: C8558P, C6548Y+, C5520+, C6542Y и C4514Y. Фактически это китайские варианты процессоров Xeon Platinum 8558P, Xeon Gold 6548Y+, Xeon Gold 5520+, Xeon Gold 6542Y и Xeon Silver 4514Y. Число вычислительных ядер составляет от 16 до 48; во всех случаях поддерживается технология многопоточности. Показатель TDP варьируется от 150 до 350 Вт (см. характеристики ниже). 
Источник изображения: Montage Technology Чипы Jintide получили дополнительные средства мониторинга и аппаратного шифрования: это технологии PrC (Pre-check) и DSC (Dynamic Security Check). От оригинальных Xeon Emerald Rapids унаследованы такие возможности, как поддержка восьми каналов памяти DDR5-5600 суммарным объёмом до 4 Тбайт и 80 линий PCIe 5.0. Изделия Jintide могут применяться в двухпроцессорных серверах. 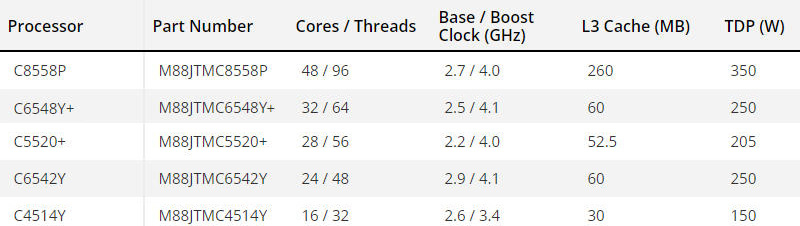
Источник изображения: Tom's Hardware На данный момент семейство Jintide 5-го поколения ограничено перечисленными моделями, и не до конца ясно, собирается ли Montage Technology выпускать другие версии. Напомним, в серии Xeon Emerald Rapids доступны процессоры с количеством ядер до 64.
17.12.2023 [17:04], Сергей Карасёв
В семейство Intel Xeon Scalable 5-го поколения вошли не только чипы Emerald Rapids, но и Sapphire RapidsНа днях корпорация Intel анонсировала процессоры Xeon Scalable 5-го поколения. Как выяснилось, в это семейство вошли не только изделия Emerald Rapids, но и чипы Sapphire Rapids. Напомним, что серия Sapphire Rapids стала основой платформы Xeon Scalable 4-го поколения. Новейшие процессоры Emerald Rapids производятся по технологии Intel 7 (10 нм ESF), насчитывают до 64 вычислительных ядер, поддерживают восемь каналов оперативной памяти DDR5-4400/5200/5600 и до 80 линий PCIe 5.0, а также CXL Type 1/2/3. Показатель TDP достигает 385 Вт. На сайте Intel говорится, что в список изделий Emerald Rapids входят 28 продуктов. Вместе с тем в перечне Xeon 5-го поколения значатся 32 процессора: сюда дополнительно входят изделия Xeon Bronze 3508U, Xeon Silver 4509Y, Xeon Silver 4510 и Xeon Silver 4510T. Все они относятся к поколению Sapphire Rapids. 
Источник изображений: Intel Перечисленные чипы также производятся по технологии Intel 7. Модели Xeon Bronze 3508U и Xeon Silver 4509Y наделены восемью ядрами, при этом второй из этих чипов поддерживает технологию многопоточности. Тактовая частота составляет соответственно 2,1–2,2 ГГц и 2,6–4,1 ГГц. Величина TDP в обоих случаях равна 125 Вт. При этом 3508U, похоже, является вообще единственным CPU в семействе, у которого есть только один FMA-порт. 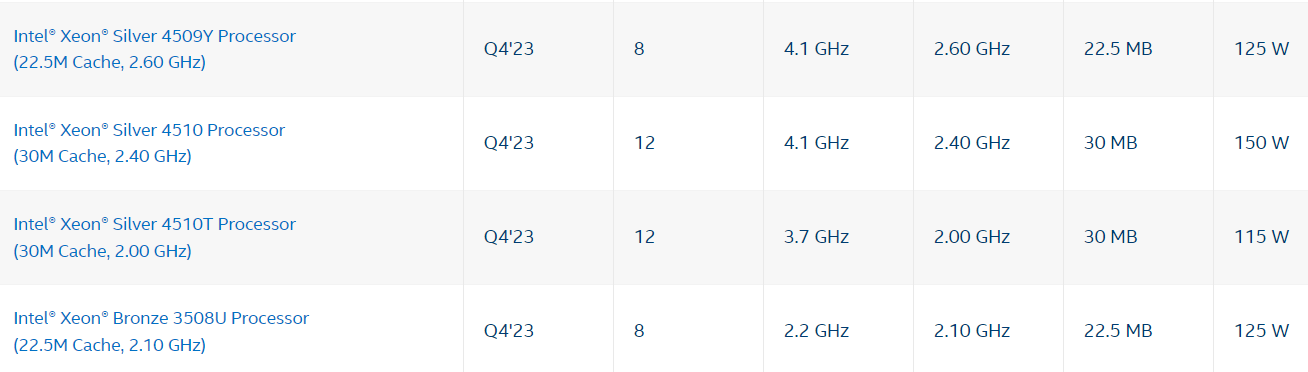 Процессоры Xeon Silver 4510 и Xeon Silver 4510T получили 12 ядер с возможностью обработки 24 потоков инструкций. Частота варьируется в диапазонах 2,4–4,1 ГГц и 2,0–3,7 ГГц. Показатель TDP — 150 и 115 Вт. Первые три из перечисленных чипов ориентированы на серверы и корпоративные системы, а четвёртый может также применяться в индустриальном оборудовании с расширенным диапазоном рабочих температур.  Иными словами, все модели Emerald Rapids относятся к Xeon Scalable 5-го поколения, но не все Xeon Scalable 5-го поколения являются изделиями Emerald Rapids. Это может создать некоторую путаницу среди потребителей.
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
30.03.2023 [19:45], Владимир Мироненко
В 2023 году Intel выпустит Xeon Emerald Rapids и подготовит полтора десятка FPGA, а чипы Sierra Forest и Granite Rapids появятся уже в 2024 годуВ ходе мероприятия для инвесторов Intel подтвердила свои планы по противодействию процессорам AMD EPYC Bergamo, в которых будет использоваться архитектура с высокой плотностью ядер Zen4c, а также всё нарастающему давлению Arm. Intel придерживается планов по созданию собственных архитектур с производительными и энергоэффективными ядрами для чипов Xeon. Intel объявила, что рассчитывает выпустить следующее, пятое по счёту поколение процессоров Xeon Scalable под кодовым названием Emerald Rapids (EMR), преемников Sapphire Rapids (SPR), в IV квартале 2023 года. Компания также продемонстрировала чип Emeralds Rapids, состоящий из двух чиплетов (тайлов в терминологии Intel). Sapphire Rapids, напомним, имеется четыре тайла меньших размеров. Сообщается, что образцы Emerald Rapids уже доступны избранным заказчикам. Не вдаваясь особо в технические подробности, компания рассказала, что Emerald Rapids будет работать в том же диапазоне TDP, что и Sapphire Rapids, что повысит общую производительность платформы в пересчёте на Вт. 
Изображения: Intel Учитывая то, что Emerald Rapids будет использовать ту же платформу LGA 4677, что и Sapphire, заказчики смогут заменить Sapphire на Emerald в существующих решениях. Такой подход позволит легко модернизировать уже внедрённые системы, а в случае производителей оборудования — ускорить вывод Emerald Rapids на рынок. Emerald Rapids будет построен на том же техпроцессе Intel 7. Это означает, что прирост производительности должен быть обеспечен за счёт архитектурных улучшений. Intel сообщила о «повышенной плотности ядер», поэтому можно предположить, что у Emerald Rapids будет больше ядер в сравнении с Sapphire Rapids. 
Emerald Rapids Вслед за Emerald Rapids компания планирует начать в 2024 году поставки чипов следующего поколения Granite Rapids (GNR) на базе производительных P-ядер. Сообщается, что вычислительные тайлы Granite Rapids будут выпускаться с использованием техпроцесса Intel 3. Intel также впервые сообщила, что Granite Rapids будут поддерживать MCR DIMM (DDR5-8800+) и обеспечат ПСП в пределах 1,5 Тбайт/с (12 каналов памяти). Ещё одной особенностью станет полный переход на чиплетную компоновоку с независимым IO-тайлом. Первые образцы Granite Rapids уже тестируются некоторыми заказчиками. 
Emerald Rapids В первой половине 2024 года должен выйти и процессор Sierra Forest (SRF), первый Intel Xeon с энергоэффективными E-ядрами (следующее за Gracemont поколение) общим числом до 144 единиц. Сообщается, что Sierra Forest и Granite Rapids будут использовать одну и ту же платформу Birch Stream. Следует отметить, что чипы Sierra Forest появятся несколько раньше, чем Granite Rapids, и тоже будут использовать техпроцесс Intel 3, а также IO-тайлы. Отмечается, что Sierra Forest даже в текущем виде оказались на удивление стабильно работающими. Более того, их уже тестирует как минимум один заказчик Intel. 
Sierra Forest На смену Sierra Forest придут в 2025 году чипы Clearwater Forest (CWF), которые станут первыми в семействе Intel Xeon, основанными на техпроцессе Intel 18A. По словам Intel, её заказчики не хотят серверные процессоры смешанной архитектуры, то есть требуют чипы либо только с P-ядрами, либо только с E-ядрами. Sierra Forest сейчас является, пожалуй, наиболее важным продуктом для Intel и для демонстрации производственных возможностей, и для сохранения заказчиков среди гиперскейлеров. 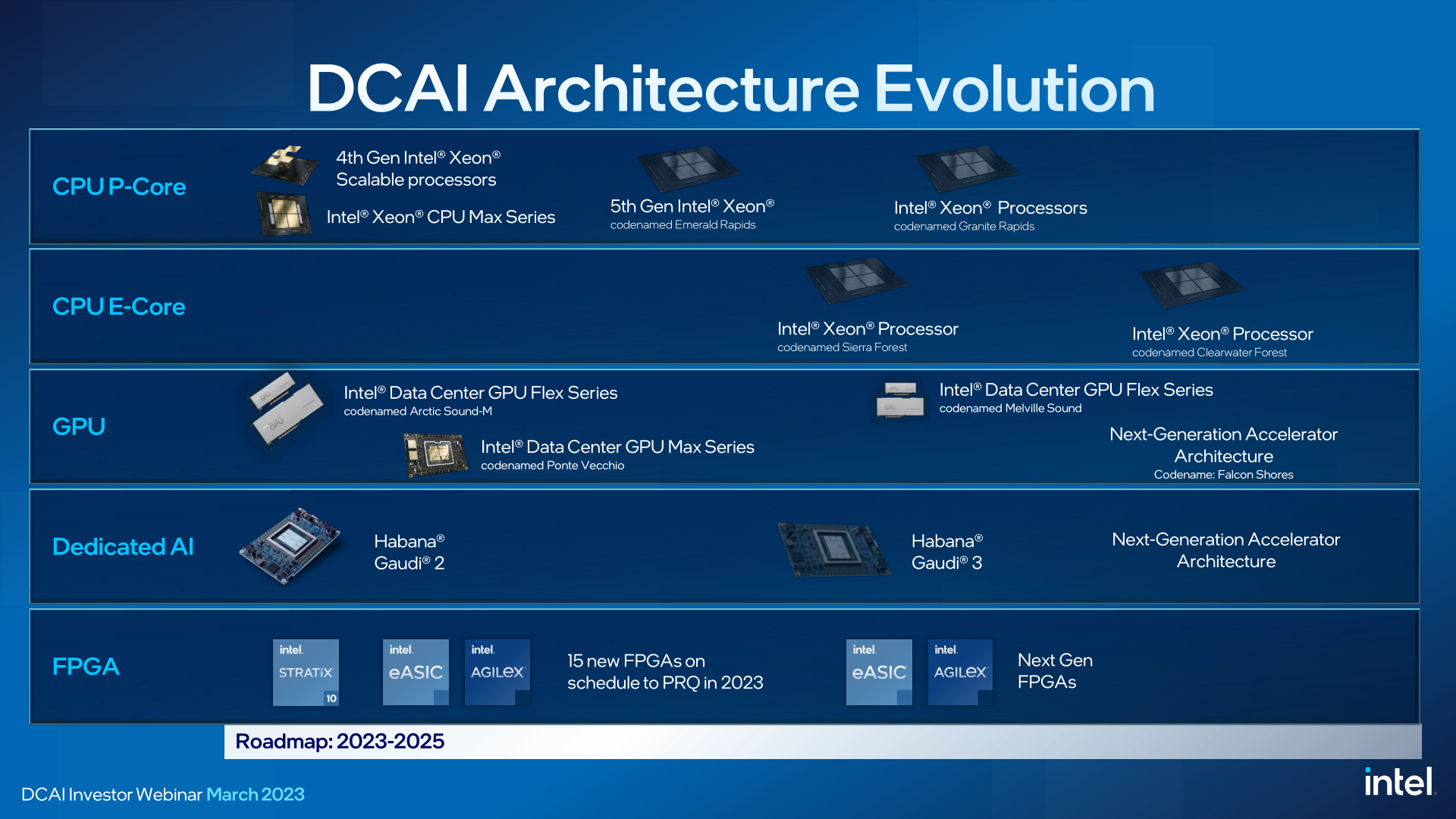 Что касается ускорителей, то компания в этом году планирует подготовить сразу 15 различных FPGA в сериях Agilex и Stratix, а также eASIC. Intel, как уже говорилось ранее, не забрасывает работу над специализированными ускорителями Habana, но грядущие Gaudi3 от нынешних Gaudi2 будут отличаться переходом с 7-нм на 5-нм техпроцесс. Отменённых Rialto Bridge в планах более нет, да и Falcon Shores тоже не упоминаются. При этом Intel считает, что к 2027 году в области ИИ-чипов соотношение между CPU и GPU будет на уровне 60/40. |
|

