Материалы по тегу: ids
|
29.06.2025 [21:11], Сергей Карасёв
Таёжное облако: ИИ-кластер Northern Data Njoerd вошёл в рейтинг TOP500
h100
hardware
hpc
hpe
intel
northern data
nvidia
sapphire rapids
xeon
великобритания
ии
облако
суперкомпьютер
Немецкая компания Northern Data Group, поставщик решений в области ИИ и НРС, объявила о том, что её система Njoerd вошла в июньский рейтинг мощнейших суперкомпьютеров мира TOP500. Этот вычислительный комплекс, расположенный в Великобритании, построен на платформе HPE Cray XD670. Машина Njoerd попала на 26-е место списка TOP500. Она объединяет 244 узла, каждый из которых содержит восемь ускорителей NVIDIA H100. В общей сложности задействованы примерно 28,5 млн ядер CUDA. Кроме того, в составе системы используются процессоры Intel Xeon Platinum 8462Y+ (32C/64C, 2,8–4,1 ГГц, 300 Вт). Применён интерконнект Infiniband NDR400. FP64-производительность Njoerd достигает 78,2 Пфлопс, а теоретическое пиковое быстродействие составляет 106,28 Пфлопс. При рабочих нагрузках ИИ суперкомпьютер демонстрирует производительность 3,86 Эфлопс в режиме FP8 и 1,93 Эфлопс в режиме FP16. Заявленный показатель MFU (Model FLOPs Utilization) при предварительном обучении современных больших языковых моделей (LLM) находится на уровне 50–60 %. Таким образом, как утверждается, система Njoerd на сегодняшний день представляет собой наиболее эффективный кластер H100 подобного размера, оптимизированный для ресурсоёмких рабочих нагрузок ИИ и HPC. Суперкомпьютер входит в состав Taiga Cloud — одной из крупнейших в Европе облачных платформ, ориентированных на задачи генеративного ИИ. Эта вычислительная инфраструктура использует на 100 % безуглеродную энергию. Показатель PUE варьируется от 1,15 до 1,06. Доступ к ресурсам предоставляется посредством API или через портал самообслуживания. Одним из преимуществ Taiga Cloud компания Northern Data Group называет суверенитет данных. 
Источник изображения: Northern Data Group
17.06.2025 [15:31], Сергей Карасёв
Представлен российский OCP-сервер Delta Serval на базе Intel Xeon 6Российский разработчик и производитель IT-оборудования Delta Computers объявил о начале серийного выпуска двухпроцессорных 2OU-серверов Delta Serval. Системы предназначены для НРС-задач, виртуализации, а также использования в составе облачных инфраструктур. В основу Delta Serval положена аппаратная платформа Intel Xeon 6. При этом заказчики могут выбирать между процессорами Xeon Granite Rapids-SP (6500P/6700P) с производительными Р-ядрами и Xeon Sierra Forest с энергоэффективными Е-ядрами (6700E) с TDP 350 Вт. Поддерживается до 8 Тбайт памяти DDR5-6400 в виде 32 модулей. Возможно использование MRDIMM-8000. В зависимости от конфигурации могут быть установлены до восьми U.2 SSD (PCIe 5.0, NVMe) с толщиной 7 мм или до четырёх таких SSD с толщиной 15 мм. Кроме того, есть два коннектора для SSD формата M.2 2280 с интерфейсом PCIe. Доступны один слот OCP 3.0 PCIe 5.0 и четыре слота PCIe 5.0 x16 для карт HHHL. 
Источник изображений: Delta Computers Сервер оснащён портом USB 3.0 Type-A и интерфейсом miniDP, а также сетевым портом управления 1GbE. Задействована система гибридного охлаждения Delta Hybrid Cooling с резервированием вентиляторов по схеме N+1 (с поддержкой горячей замены). По заявлениям Delta Computers, машина может функционировать на максимальной частоте без деградации и перегрева процессоров при температуре в холодном коридоре до +45 °C. Применяется фирменное микропрограммное обеспечение Delta BIOS и Delta BMC.  Среди ключевых преимуществ новинки разработчик выделяет большое количество вычислительных ядер (до 172 P-ядер или до 288 E-ядер), возможность гибкой адаптации под требования заказчика, высокую плотность компоновки и поддержку интеграции с новыми аппаратными и программными платформами.
09.06.2025 [09:19], Сергей Карасёв
«Аквариус» анонсировала отечественные серверы AQserv на базе Intel Xeon 6«Аквариус» сообщила о разработке инженерных образов 2U-серверов AQserv с процессорами Intel Xeon 6. Устройства предназначены для решения задач в таких областях, как ИИ, машинное обучение, большие данные и пр. Полностью технические характеристики серверов пока не раскрываются. Известно, что они имеют двухсокетное исполнение с возможностью выбора чипов Xeon 6500P/6700P (Granite Rapids) с производительными Р-ядрами и Xeon 6700E (Sierra Forest) с энергоэффективными Е-ядрами. Говорится о поддержке 32 DIMM-слотов DDR5-8000/6400/5200, восьми слотов PCIe 5.0 x16, одного слота OCP 3.0 (PCIe 5.0 x16). Дисковая подсистема представлена двумя слотами для SFF-накопителей (SATA/SAS/NVMe) и двумя E1.S-слотами (NVMe) с горячей заменой. Дисковая корзина представлена в двух вариантах: 24 × SFF (SATA/SAS/NVMe) или 12 × LFF (SATA/SAS/NVMe). За управление отвечает BMC ASPEED AST2600 с выделенным 1GbE-портом RJ45, а также фирменной прошивкой «Аквариус Командир». Устройства наделены фирменной системой управления и мониторинга, которую «Аквариус» развивает с 2020 года. Она позволяет выполнять базовые операции по обслуживанию основных компонентов серверов, а также обеспечивает расширенную поддержку служб каталогов (таких как AD, LDAP, ALD Pro) и дополнительные возможности, в том числе в плане автоматизации. Благодаря этому, по заявлениям производителя, ускоряется ввод оборудования в эксплуатацию и снижается совокупная стоимость владения (TCO). 
Источник изображения: «Аквариус» Серверы AQserv на базе Xeon 6 оптимизированы для ресурсоёмких нагрузок, связанных с виртуализацией, облачными платформами, аналитическими приложениями и пр. «Аквариус» отмечает, что по сравнению с машинами предыдущего поколения достигается увеличение производительности в два–три раза, а в некоторых сценариях — в пять и более раз. Такие показатели обеспечиваются благодаря новой архитектуре, большому количеству ядер, поддержке инструкций AMX, использованию оперативной памяти MRDIMM и др. 
Источник изображения: «Аквариус» «Мы начали разработку серверов на базе Xeon 6 заранее, ещё до официального выпуска первых процессоров Xeon 6 компанией Intel, чтобы наши заказчики могли первыми получить доступ к решениям нового поколения. В условиях стремительно растущих требований к IT-инфраструктуре важно опережать запросы рынка, и мы уверены, что наш новый продукт позволит бизнесу решать задачи цифровой трансформации на совершенно новом уровне эффективности», — говорит президент «Аквариус». Впрочем, Selectel анонсировала собственные серверы на базе Xeon 6 ещё в октябре прошлого года.
07.06.2025 [16:35], Сергей Карасёв
HPE представила отказоустойчивые системы Nonstop Compute на базе Intel Xeon Sapphire RapidsКомпания HPE пополнила семейство отказоустойчивых решений Nonstop Compute двумя новинками — системой начального уровня NS5 X5 и флагманской моделью NS9 X5. Архитектура платформ объединяет вычислительные мощности, ресурсы хранения, сетевые функции и сопутствующее ПО. Решение Nonstop Compute NS5 X5 ориентировано на сравнительно небольших корпоративных заказчиков. Система формата 36U/42U может нести на борту до четырёх процессоров Intel Xeon Bronze 3400 поколения Sapphire Rapids. Объём оперативной памяти достигает 128 Гбайт в расчёте на CPU, что в сумме даёт до 512 Гбайт. Возможна установка до 100 SAS SSD вместимостью 1,6 Тбайт каждый. Допускается также подключение внешних массивов хранения HPE XP8. В общей сложности могут использоваться до 20 сетевых портов, в том числе 10GbE. 
Источник изображения: HPE В свою очередь, модель Nonstop Compute NS9 X5 ориентирована на ресурсоёмкие нагрузки, такие как обработка транзакций в реальном времени в больших масштабах и интенсивная работа с данными. Максимальная конфигурация включает 16 процессоров Xeon Gold 6400 семейства Sapphire Rapids с 512 Гбайт памяти в расчёте на CPU, что в сумме обеспечивает до 8 Тбайт ОЗУ. Система может быть оборудована 2700 SAS SSD ёмкостью до 1,6 Тбайт каждый. Предусмотрена возможность использования до 270 сетевых портов на систему, в том числе 25GbE. В целом, решения Nonstop Compute ориентированы на сегмент рынка, где требуется менее высокая стоимость по сравнению с традиционными мейнфреймами, но при этом предъявляются более высокие требования в плане надёжности и масштабируемости, чем к стандартным серверам. IDC относит продукты Nonstop Compute к системам с доступностью класса Availability Level 4 (AL4): это означает, что показатель безотказной работы составляет от 99,999 % до 99,9999 %. Таким образом, системы подходят для применения в том числе в финансовом секторе. HPE утверждает, что шесть из десяти крупнейших мировых банков используют устройства Nonstop Compute.
04.06.2025 [09:44], Сергей Карасёв
YADRO представила All-Flash СХД Tatlin.AFAРоссийская компания YADRO представила высокопроизводительную систему хранения данных Tatlin.AFA, предназначенную для решения задач крупных корпоративных клиентов. Утверждается, что это первое в России решение типа All-NVMe с возможностью установки SSD с интерфейсом PCIe 4.0/5.0 и поддержкой End-to-end NVMe. Устройство выполнено в форм-факторе 2U и оснащено двумя контроллерами в режиме Symmetric Active–Active. Каждый из контроллеров оборудован двумя процессорами Intel Xeon поколения Emerald Rapids. Объём памяти DDR5 ECC составляет 1,5 Тбайт. Предусмотрены дублированные батареи для обеспечения сохранности данных в кеше. СХД располагает 24 отсеками для NVMe SSD стандарта U.2 / U.3 вместимостью до 30 Тбайт каждый, что в сумме даёт до 720 Тбайт «сырой» ёмкости. Кроме того, могут быть подключены два модуля расширения S24N, каждый из которых также содержит два двухпроцессорных контроллера, 24 слота для накопителей и два 200GbE-порта с RocE. Таким образом, общая вместимость в конфигурации с двумя модулями S24N превышает 2 Пбайт. Заявленное быстродействие на операциях ввода/вывода в секунду (IOPS) составляет более 2 млн, а пропускная способность достигает 50 Гбайт/с. Поддерживаются протоколы FC, iSCSI, NVMe/TCP, NVMe/RoCE. Заявлена совместимость с VMWare Sphere 7.x / 8.x, «РЕД ОС Виртуализация», «Альт Сервер Виртуализация», ECP Veil / SE, zVirt 3.x / 4.x, «Горизонт ВС», BASIS (DE), ОС Windows Server 2016/2019/2022, Oracle Linux 7.x/8.x/9.x, Rocky Linux 9.x, SUSE Linux 12/15, Ubuntu Server, IBM AIX 7.2 / 7.3 (VIOS), Astra Linux 1.x, «РЕД ОС» 7.3/7.3.1/8.0, «Альт Сервер». 
Источник изображения: YADRO В зависимости от конфигурации доступны до 16/32 портов 10/25GbE, до 16 портов 100GbE или до 20 портов FC16/32/64. Предусмотрены пять слотов PCIe 5.0 x16 для сетевых адаптеров. Установлены два блока питания мощностью 3200 Вт с резервированием 1+1, поддержкой горячей замены и аккумуляторным модулем. Диапазон рабочих температур простирается от +10 до +30 °C. Упомянута собственная технология T-RAID с поддержкой различных схем защиты, резервирования компонентов и моментальных снимков. Реализованы следующие уровни защиты T-RAID: 8 + 1, 8 + 2, 8 + 3, 8 + 4, 8 + 5, 8 + 6, 8 + 7, 8 + 8, 10 + 1, 10 + 2, 10 + 3, а также 14 + 1 и 14 + 2. Использует программная платформа Tatlin.OS.
31.05.2025 [12:03], Сергей Карасёв
OpenYard представила серверы RS102I и RS202I на базе Intel Xeon Emerald RapidsРоссийский производитель OpenYard анонсировал серверы RS102I и RS202I, выполненные в форм-факторе 1U и 2U соответственно. Новинки простроены на аппаратной платформе Intel с возможностью установки двух процессоров Xeon поколения Emerald Rapids или Sapphire Rapids. Модель RS102I предназначена для таких задач, как виртуализация, облачные приложения и высокопроизводительные вычисления. Доступны 32 слота для модулей оперативной памяти DDR5 суммарным объёмом до 8 Тбайт. Во фронтальной части расположены отсеки для 12 накопителей SFF (интерфейсы PCIe 5.0, SAS или SATA) с функцией горячей замены. При использовании NVMe SSD суммарная вместимость подсистемы хранения данных может достигать 368 Тбайт. Возможна организация массивов RAID 0/1/5/6/10/50/60. Сервер располагает двумя слотами PCIe 5.0 x16 FHHL и двумя разъёмами OCP 3.0 (PCIe 5.0 x16). Могут применяться сетевые карты 10/25GbE или 100/200GbE, а также адаптеры FC 16/32/64Gb. За питание отвечают два блока мощностью 1600 Вт каждый с резервированием. Габариты устройства составляют 438 × 43,5 × 815 мм. 
Источник изображений: OpenYard В свою очередь, модель RS202I ориентирована на транзакционные и аналитические базы данных, задачи ИИ, виртуализацию, облачные приложения и доставку медиаконтента. Система оснащена 32 слотами DDR5 с поддержкой 8 Тбайт памяти. Поддерживается установка до 24 накопителей SFF или до 12 устройств LFF спереди (PCIe 5.0, SAS или SATA) и до четырёх накопителей SFF сзади (SATA/SAS). Реализована горячая замена; допускается создание массивов RAID 0/1/5/6/10/50/60. Максимальная суммарная вместимость при использовании NVMe SSD — 860 Тбайт.  Слоты расширения выполнены по схеме 6 × PCIe 5.0 x16 FHHL, 4 × PCIe 5.0 x8 HHHL и 2 × OCP 3.0 PCIe 5.0 x16 (с поддержкой NCSI). Установлены два блока питания мощностью до 2400 Вт с резервированием. Сервер имеет размеры 438 × 87,5 × 815 мм.
29.05.2025 [11:22], Сергей Карасёв
Дебютировали российские серверы «Аквариус» AQserv RS на базе Intel Xeon Emerald RapidsКомпания «Аквариус» анонсировала серверы серии AQserv RS типоразмера 2U, выполненные на аппаратной платформе Intel. Устройства, как утверждается, подходят для решения широкого спектра задач — от виртуализации и облачных приложений до ИИ и машинного обучения. Новинки внесены в Единый реестр российской радиоэлектронной продукции Минпромторга РФ. В семействе представлены две модели — AQserv T50 D224RS и AQserv T50 D212RS. Обе они допускают установку двух процессоров Xeon поколения Emerald Rapids или Sapphire Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-5600 суммарным объёмом до 8 Тбайт. Присутствуют два сетевых порта 1GbE (Intel i210), два слота расширения PCIe 5.0 и шесть слотов PCIe 4.0, а также разъём OCP 3.0 (PCIe 5.0 x16). В оснащение входит контроллер Aspeed AST 2600. 
Источник изображений: «Аквариус» Ключевое различие серверов заключается в организации подсистемы хранения данных. Вариант AQserv T50 D224RS поддерживает в общей сложности до 30 накопителей: это 24 фронтальных и четыре тыльных SFF (SAS/SATA/NVMe) с возможностью горячей замены, а также два внутренних SSD формата M.2 2280/22110 с интерфейсом SATA или PCIe (NVMe). В свою очередь, версия AQserv T50 D212RS рассчитана на 18 накопителей, включая 12 фронтальных устройств LFF (SAS/SATA/NVMe) с горячей заменой, четыре тыльных устройства SFF (SAS/SATA или NVMe) с горячей заменой и два внутренних SSD стандарта M.2 2280/22110.  Серверы оснащены четырьмя портами USB 2.0 Type-А (по два спереди и сзади), двумя разъёмами D-Sub (по одному спереди и сзади), последовательным портом, гнёздами RJ45 и выделенным сетевым портом управления. Установлены два блока питания мощностью до 2700 Вт с сертификатом 80 PLUS Platinum / Titanium. Применена система воздушного охлаждения с четырьмя вентиляторами диаметром 80 мм с ШИМ-управлением. Диапазон рабочих температур — от 10 до +35 °C. Заявлена совместимость с РЕД ОС 7.3 и выше, Windows Server 2016/2019, Red Hat Enterprise Linux Server 7.x, SUSE Enterprise Linux Server 12.x и Ubuntu 22.04. Как отмечает разработчик, BMC «Аквариус Командир Лайт» обеспечивает удобное удалённое управление и интеграцию с системами централизованного мониторинга, что значительно упрощает администрирование. Упомянута поддержка различных версий BIOS, включая российскую Numa BIOS.
23.05.2025 [15:22], Владимир Мироненко
Специально для ИИ: Intel представила три оптимизированных процессора Intel Xeon Granite Rapids, один из которых используется в NVIDIA DGX B300Intel представила три новых процессора семейства Intel Xeon 6 Granite Rapids-SP/AP — 6962P, 6774P и 6776P, разработанные для управления «самыми передовыми ИИ-системами ускорителей». Новые процессоры с P-ядрами используют технологию Intel Priority Core Turbo (PCT), а также технологию Intel Speed Select Turbo Frequency (Intel SST-TF), которые позволяют настраивать частоты ядер процессора для повышения производительности ускорителя при обработке требовательных рабочих ИИ-нагрузок. Новые процессоры Xeon 6 уже доступны для заказчиков. В частности, Intel Xeon 6776P используется в ИИ-системе NVIDIA DGX B300, где «играет важную роль в управлении, оркестрации и поддержке ИИ-системы». «Новые чипы демонстрируют непревзойдённую производительность Xeon 6, что делает их идеальными процессорам для ИИ-систем с ускорением на GPU следующего поколения», — отметила Карин Айбшиц Сигал (Karin Eibschitz Segal), корпоративный вице-президент и временный генеральный директор Intel Data Center Group. 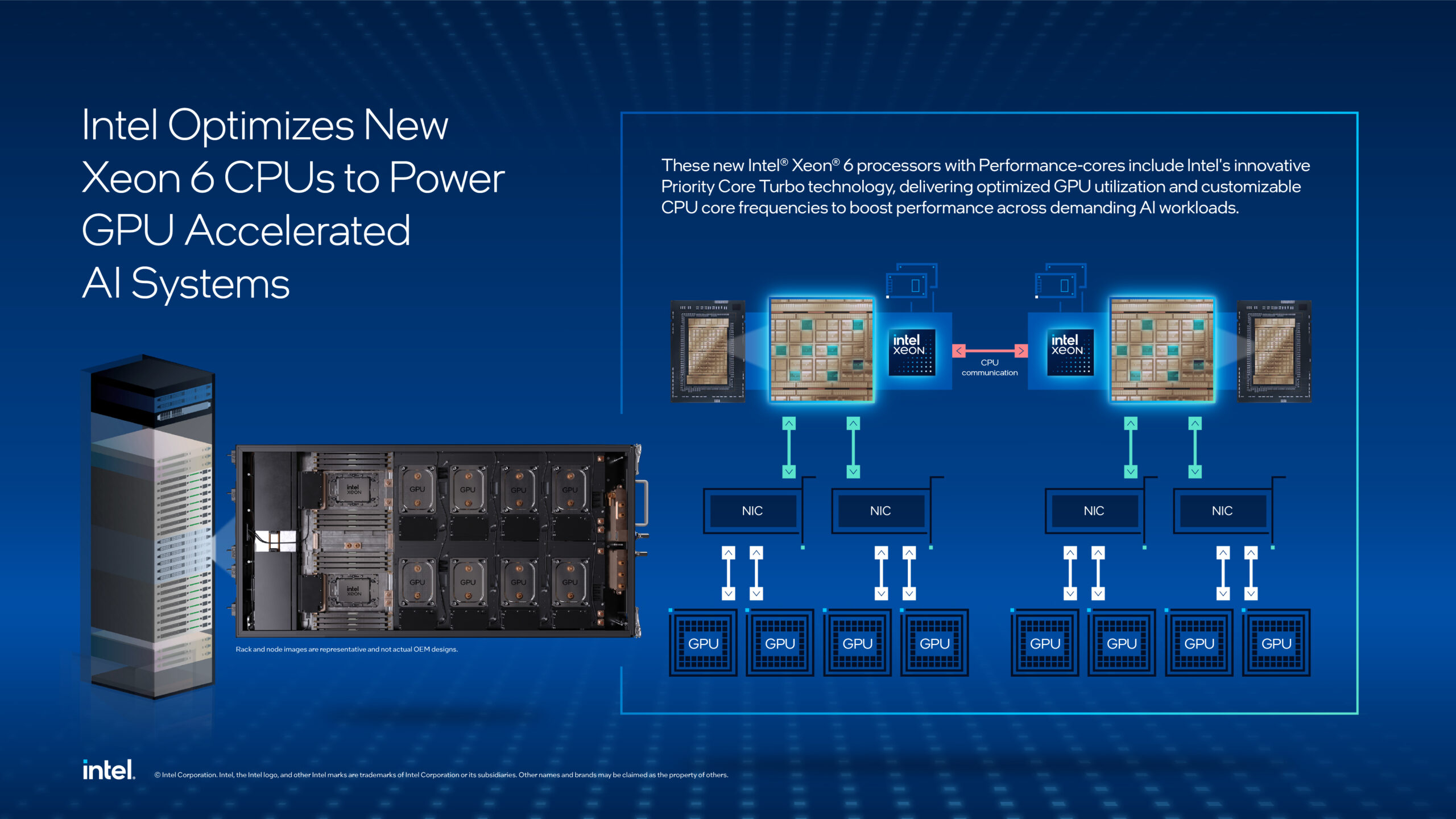
Источник изображения: Intel Как сообщила Intel, внедрение PCT в сочетании с Intel SST-TF обеспечивает значительный скачок производительности ИИ-систем. PCT позволяет динамически формировать пул высокоприоритетных ядер, которые работают на более высоких турбочастотах, в то время как остальные ядра работают на базовой частоте, обеспечивая оптимальное распределение ресурсов процессора. Эта функция имеет решающее значение для рабочих ИИ-нагрузок, требующих последовательной и пакетной обработки, более быстрой отправки данных к ускорителям и повышения общей эффективности системы. Впрочем, в случае 6776P лишь до восьми ядер могут работать на повышенной турбочастоте. 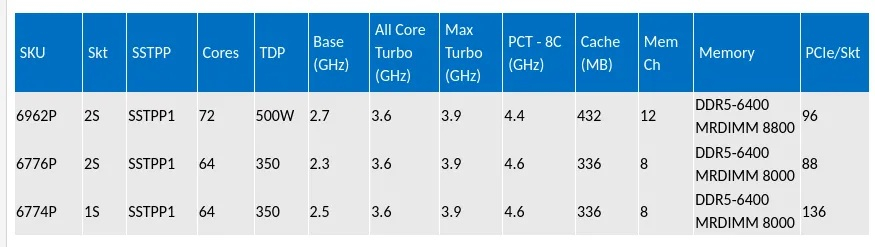
Источник изображения: Phoronix Процессоры Xeon 6 с P-ядрами, по словам Intel обеспечивают ведущие в отрасли характеристики для ИИ-систем, включая:
Новые процессоры отличаются высокой надёжности и удобством обслуживания, что сводит к минимуму перебои в работе. Как сообщается, новинки поддерживают AMX-вычисления с точностью FP16, что обеспечивает эффективную предобработку данных и выполнение критических задач ЦП в рабочих ИИ-нагрузках.
02.05.2025 [13:50], Сергей Карасёв
MiTAC анонсировала OCP-серверы на основе AMD EPYC Turin с воздушным и жидкостным охлаждением, а также edge-сервер на базе Intel Xeon Sapphire RapidsКомпания MiTAC Computing Technology представила OCP-серверы нового поколения C2810Z5 и C2820Z5, предназначенные для приложений ИИ и НРС. Устройства выполнены на аппаратной платформе AMD EPYC 9005 Turin. Решение C2810Z5 типоразмера 2OU имеет двухузловую конструкцию. Каждый узел допускает установку одного процессора и 12 модулей оперативной памяти DDR5-6400. Доступны шесть отсеков для накопителей U.2 и два посадочных места для SSD стандарта E1.S. Предусмотрены слоты PCIe 5.0 x16 для карт FHHL, HHHL и OCP NIC 3.0. Устройство оснащено воздушным охлаждением. Данная модель подходит для развёртывания микросервисов в облачных средах. В свою очередь, вариант C2820Z5 — это четырёхузловая система 2OU с технологией прямого жидкостного охлаждения. Каждый узел поддерживает два процессора EPYC 9005 Turin и 24 модуля памяти DDR5. Сервер подходит для высокопроизводительных вычислений. Кроме того, MiTAC анонсировала семейство серверов Whitestone 2 (WS2): это, как утверждается, компактная, но мощная платформа, специально оптимизированная для сетей Open RAN и периферийных задач. Система выполнена в корпусе небольшой глубины формата 1U. Задействован процессор Intel Xeon поколения Sapphire Rapids. 
Источник изображения: MiTAC Предусмотрены восемь слотов для модулей DDR5. Во фронтальной части находятся четыре порта 25GbE SFP28 и восемь портов 10GbE SFP+. Говорится о поддержке IEEE 1588 v2, Sync-E и GPS для синхронизации. В тыльной части располагаются вентиляторы охлаждения в виде девяти сдвоенных блоков.
22.04.2025 [11:17], Сергей Карасёв
«Сигналтек» представила российский сервер SignalEdge на базе Intel Xeon Emerald RapidsКомпания «Сигналтек» сообщила о начале производства на территории России сервера SignalEdge нового поколения, ориентированного на применение в телеком-сфере и на решение задач на периферии. Устройство может использоваться, в частности, для обеспечения информационной безопасности. Сервер выполнен в форм-факторе 1U. Допускается установка двух процессоров Intel Xeon поколения Emerald Rapids или Sapphire Rapids в исполнении LGA 4677 с показателем TDP до 270 Вт. Поддерживается до 8 Тбайт оперативной памяти DDR5-4800 (32 слота). Возможна установка двух SSD стандарта M.2 SATA/NVMe и ещё двух SSD M.2 NVMe. Предусмотрены сетевой порт управления 1GbE, аналоговый разъём D-Sub и два порта USB 3.0. Во фронтальной части располагаются посадочные места для семи адаптеров: это могут быть по две карты HHHL PCIe 5.0 x16 и FHHL PCIe 5.0 x16, а также три устройства OCP 3.0. Говорится о применении инновационной системы охлаждения. За питание отвечают два блока мощностью 1200 Вт каждый с резервированием 1+1. 
Источник изображения: «Сигналтек» Особенностью новинки «Сигналтек» называет разработку собственного сетевого адаптера формата OCP 3.0 с интерфейсом PCIe 4.0 x8 на базе контроллера Intel X710. Адаптер поддерживает четыре оптических модуля 10Gb SFP+. Для управления питанием и мониторинга температуры задействован российский 32-разрядный микроконтроллер Миландр K1986BE92FI. При изготовлении изделия используется текстолит российского производства. Сборка осуществляется на собственных мощностях компании.  На основе сервера SignalEdge могут создаваться межсетевые экраны следующего поколения (NGFW) и системы глубокого анализа трафика (DPI). В настоящее время идет процесс включения новинки в реестр Минпромторга РФ. |
|

