Материалы по тегу: hardware
|
18.11.2025 [10:54], Сергей Карасёв
Начался монтаж крупнейшего в США академического суперкомпьютера Horizon с ИИ-быстродействием до 80 ЭфлопсНациональный научный фонд США (NSF) объявил о начале монтажа вычислительно комплекса Horizon — крупнейшего в стране академического суперкомпьютера. Система расположится в Техасском центре передовых вычислений (TACC) при Техасском университете в Остине (UT Austin). Проект реализуется в сотрудничестве с Dell, NVIDIA, VAST Data, Spectra Logic, Versity и Sabey Data Centers. Суперкомпьютер будет развёрнут в новом дата-центре мощностью 15–20 МВт с передовым жидкостным охлаждением в Раунд-Роке (штат Техас). В основу системы лягут серверы Dell PowerEdge. Говорится об использовании процессоров NVIDIA Vera и суперчипов NVIDIA Grace Blackwell. В общей сложности будут задействованы около 1 млн CPU-ядер и примерно 4 тыс. GPU. Архитектура предусматривает использование интерконнекта NVIDIA Quantum-2 InfiniBand. Вместимость локального хранилища данных, выполненного исключительно на основе SSD, составит 400 Пбайт. Оно обеспечит пропускную способность при чтении/записи более 10 Тбайт/с. 
Источник изображения: TACC Заявленная производительность Horizon — 300 Пфлопс: это примерно в 10 раз больше по сравнению с системой Frontera, которая в настоящее время является самым мощным академическим суперкомпьютером в США. При выполнении ИИ-задач новый вычислительный комплекс обеспечит быстродействие до 20 Эфлопс на операциях BF16/FP16 и до 80 Эфлопс в режиме FP4 — более чем 100-кратный прирост по сравнению с нынешними машинами, которые эксплуатируются в американских академических кругах. При этом говорится о повышении энергетической эффективности до шести раз. Запуск Horizon запланирован на весну 2026 года. Суперкомпьютер будет использоваться для решения сложных и ресурсоёмких задач в таких областях, как биомедицина, физика, энергетика, экология и пр. В частности, система будет применяться для моделирования климата.
18.11.2025 [01:10], Игорь Осколков
Европа присоединилась к экзафлопсному клубу с суперкомпьютером JUPITERЕвропейский суперкомпьютер JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) в Юлихском исследовательском центре (FZJ) в Германии официально преодолел важную отметку — FP64-производительность его GPU-модуля Booster достигла ровно 1 Эфлопс при пиковой теоретической 1,227 Эфлопс. Таким образом в нынешнем рейтинге TOP500 он занял четвёртое место, совсем чуть-чуть не дотянув до суперкомпьютера Aurora с его 1,012 Эфлопс. Впервые машина попала в июньский рейтинг TOP500 с показателем 793 Пфлопс, но тогда она не была полностью готова. Официальный запуск состоялся лишь в сентябре. Впрочем, за прошедшие с момента выхода прошлого рейтинга его лидер El Capitan тоже нарастил мощность, с 1,742 Эфлопс до 1,809 Эфлопс. Frontier же остался на втором месте с показателем 1,353 Эфлопс, хотя изначально он «дотягивался» только до 1,102 Эфлопс. Таким образом, JUPITER формально стал первой публичной экзафлопсной системой за пределами США, если не брать в расчёт китайские системы, о которых КНР предпочитает не распространяться. Мощные суперкомпьютеры, не участвующие в TOP500, бывали и раньше, но вот есть ли среди них машина такого класса, остаётся только гадать. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau Так что если через полгода не будет развёрнут ещё какой-нибудь крупный суперкомпьютер, что вполне реально с нынешними возможностями (нео-)облаков, то JUPITER наверняка поднимется в рейтинге на строчку выше. Сейчас Booster включает порядка 6 тыс. узлов BullSequana XH3000 с 24 тыс. ускорителей GH200 в Quad-исполнении, объединённых 200G-интерконнектом InfiniBand NDR. Ещё приблизительно 5 Флопс в FP64 JUPITER получит от CPU-модуля cCuster из 1300 узлов с 2600 Arm-процессорам SiPearl Rhea1 с 80 ядрами и 64 Гбайт HBM2e. Узлы и интерконнект будут использоваться те же, что в Booster. Однако выпуск этих процессоров только-только начался, так что апгрейд будет завершён только в следующем году. TOP500 в целом в этот раз новизной технологий не блещет, отражая скорее типичный цикл обновления систем. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau Всего в ноябрьском рейтинге появилось 45 новых машин. Самая крупная из них — 135,4-Пфлопс CHIE-4, построенная для SoftBank на базе NVIDIA DGX B200 с InfiniBand NDR400 — занимает аж 17 позицию. Она же единственная пополнила первую десятку рейтинга HPCG с результатом 3760,55 Тфлопс, где заняла шестую позицию. Из необычных новинок можно выделить суперкомпьютер MAXIMUS-384 на 20 месте (114,5 Пфлопс), который объединил Intel Xeon Emerald Rapids и AMD Instinct MI300X. Впрочем, вторая во всём списке и уже не такая новая система с MI300X — IronMan — объединяет их с Sapphire Rapids. 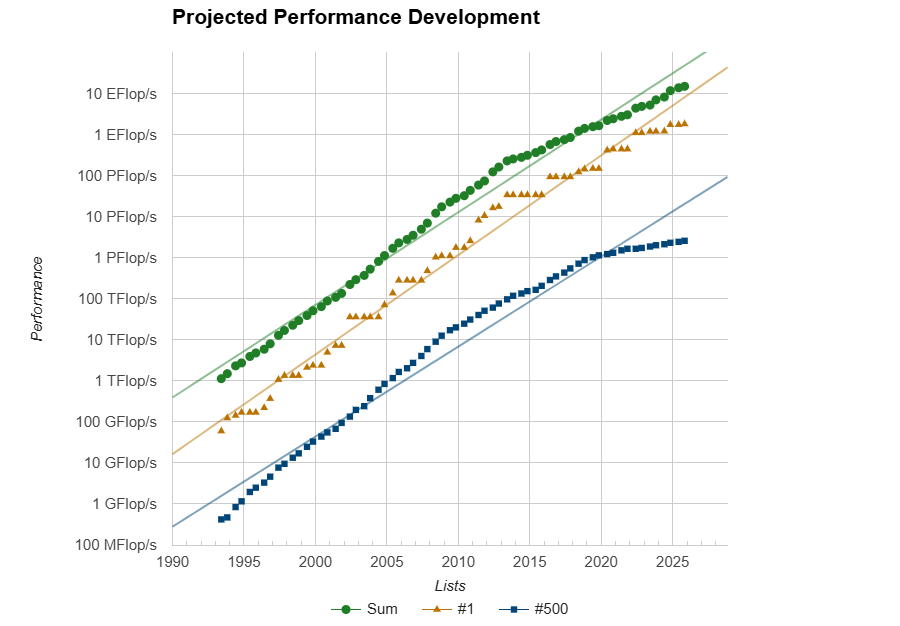
Источник изображения: TOP500 От России в TOP500 попали пять суперкомпьютеров (три от Яндекса и два от Сбера), которые если и обновляли с момента последнего официальной заявки на вхождение в рейтинг, то вряд ли бы стали громко и публично об этом рассказывать. Зато у соседнего Казахстана есть сразу две машины. На 86 позиции с производительностью 20,48 Пфлпос находится Alem.Cloud, на 103 — AI-Farabium с 17,93 Пфлопс. Обе системы используют сочетание Xeon Emerald Rapids, NVIDIA H200 (SXM) и 400G-интерконнект, но первая получила Ethernet, а вторая — InfiniBand NDR. В Green500 существенных изменений тоже не наблюдается. Ровно половину первой десятки занимают машины с NVIDIA GH200. В общей массе чипы NVIDIA тоже доминируют. При этом первая система без ускорителя занимает аж 105 строчку, и до 113 позиции это сплошь Fujitsu A64FX, лежащие в основе Fugaku. Всего TOP500 уже более половины машин оснащены ускорителями. Но от ожидаемого ранее уровня роста производительности весь рейтинг отстаёт на протяжении уже пяти лет. С другой стороны, и фокус сейчас сместился на ИИ, а новым кластерам некогда участвовать в ненужных для них рейтингах.
17.11.2025 [15:46], Руслан Авдеев
Перегрузка энергосетей угрожает лидерству Нидерландов в сфере ЦОД — доступный водород продолжают игнорировать
hardware
водород
дефицит
нидерланды
прогноз
топливные элементы
цод
экология
электропитание
энергетика
В недавнем отчёте ING, одного из крупнейших банков Нидерландов, рисуется всё более мрачная картина местного рынка дата-центров. Амстердам, традиционно входящий в пятёрку крупнейших европейских рынков ЦОД наряду с Франкфуртом, Лондоном, Парижем и Дублином (FLAPD), столкнулся с серьёзными ограничениями роста, сообщает Computer Weekly. В мировом масштабе Амстердам и Франкфурт уже выбыли из первой двадцатки локаций гиперскейлеров. Недавно городской совет объявил, что заявки на создание новых ЦОД начнут рассматриваться только с 2035 года из-за перегрузки энергосети. IMG, ссылаясь на данные Gartner, сообщает о строительстве в настоящее время новых ЦОД приблизительно на 200 МВт, но вот добавить ещё 200 МВт будет невероятно трудно. Подчёркивается, что речь идёт не просто о судьбе проектов в самом Амстердаме — если в Нидерландах не будет возможностей для дальнейшего роста, страна потеряет знания и опыт, а с ними и экономический рост в будущем. Сегодня сектор обеспечивает 150–250 тыс. рабочих мест в сфере цифровой инфраструктуры и вносит порядка €26 млрд в годовой оборот страны. Строительству новых ЦОД мешают перегрузка сетей из-за не слишком удачного планирования развития возобновляемой энергетики, нехватка свободных участков и рост обеспокоенности общественности вопросами нехватки энергии. Сейчас на ЦОД в Нидерландах приходится 3,3 % от общего энергопотребления в стране, но с развитием генеративного ИИ показатель может существенно вырасти. В ING допускают, что IT-нагрузки из Нидерландов в итоге переедут за границу, в частности, в Скандинавию, где энергии для охлаждения требуется намного меньше. Вместе с этим сократится и рынок инженеров и прочих специалистов. 
Источник изображения: Thomas Bormans/unsplash.com Тем временем в мире активно развивают технологии водородных топливных элементов для дата-центров, особенно в этом преуспела Microsoft, а также некоторые другие компании. В 2023 году последняя вместе с Plug Power протестировала водородную энергосистему на 3 МВт. Отмечалось, что проект очень интересен — такую мощность до этого обеспечивали резервные дизель-генераторы. Plug Power уже заключила соглашения с «тремя крупными операторами ЦОД». В 2025 году Microsoft и Equinix запустили пилотные проекты по использованию «зелёного» водорода для питания ЦОД. В США успешным пилотным проектом использования водорода стал проект ECL и Lambda. На этом фоне в Нидерландах сложилась парадоксальная ситуация. Согласно докладу Международного энергетического агентства (IEA) Northwest European Hydrogen Monitor 2024, страна является одним из европейских лидеров в развитии водородной инфраструктуры, причём в проектах участвует и государство, вложившей немало средств в производство и транспортировку водорода по сети трубопроводов. Однако технология находит минимальное применение в секторе ЦОД, за рамки пилотного вышел лишь один проект. 
Источник изображения: Bart Ros/unsplash.com В 2022 году NorthC Datacenters установила на объекте в Гронингене (Groningen) резервную систему питания на водороде мощностью 500 кВт, ежегодно он сокращает выбросы CO2 приблизительно на 78 т. Ни один ЦОД в Нидерландах не последовал этому примеру. В Ассоциации дата-центров Нидерландов убеждены, что в первую очередь «водородным» электричеством необходимо обеспечить тяжёлую промышленность, на которую приходится больше всего выбросов CO2 в Нидерландах. Нежелание многих структур использовать водородные системы как альтернативу обычному топливу легко объяснить, поскольку традиционная инфраструктура и дешевле, и доступнее. Производство «зелёного» водорода требует больших затрат возобновляемой энергии. Кроме того, водородные топливные элементы дороже традиционных «дизелей», но с ростом цен на ископаемое топливо и дальнейшим развитием водородного сектора в регионах вроде Гронингена ожидается падение цен. Вместе с тем водородные топливные элементы работают 20 и более лет, значительно дольше, чем дизельные генераторы. 
Источник изображения: Jon Moore/unsplash.com В феврале 2025 года нидерландский оператор газовой сети Gasunie объявил, что расходы на проект национального водородного трубопровода выросли на 150 % с €1,5 млрд до €3,8 млрд. В IEA подчёркивают, что пока менее 4 % заявленных проектов производства «зелёного» водорода в Северо-Западной Европе достигли стадии «финального инвестиционного решения». Тем не менее, Нидерланды, Германия, Дания и Великобритания к 2030 году будут производить ¾ «зелёного» водорода в регионе. ING предлагает стратегические решения для развития дата-центров, в т.ч. размещение ЦОД неподалёку от морских ветряных электростанций, использование тепла ЦОД в системах центрального отопления и др. «Зелёный» водород можно производить в случае, если поставки возобновляемой энергии превышают спрос, и хранить его для дальнейшего применения, решая проблемы нестабильности возобновляемой энергетики. Отмечается, что власти Нидерландов намерены к 2032 году добиться получения 21 ГВт от морской ветряной энергетики. Впрочем, пока конвергенция стратегических секторов — ЦОД и водородной энергетики — в Нидерландах остаётся в значительной степени теоретической. ING призывают усилить координацию действий на национальном и европейском уровнях. Вопрос о готовности страны инвестировать в водородную инфраструктуру для ЦОД остаётся открытым, но, похоже, окно возможностей уменьшается, поскольку мощности ЦОД и водородную энергетику развивают и другие европейские рынки.
17.11.2025 [13:08], Сергей Карасёв
Veir испытала сверхпроводящие кабели для ЦОД — до 3 МВт на впятеро большее расстояние, чем у обычныхАмериканская компания Veir объявила об успешном испытании своей технологии STAR (Superconducting Technology for AI Racks), которая предполагает использование сверхпроводящих силовых кабелей для питания оборудования в ИИ ЦОД. Разработанное решение предусматривает замену традиционных кабелей на трубки аналогичного размера, в которых находятся сверхпроводящие ленты в жидком азоте с температурой −196 °C. Утверждается, что благодаря такому подходу передаваемая мощность может быть повышена на порядок при том же напряжении. В январе нынешнего года Veir получила $75 млн на развитие технологии: средства предоставили Munich Re Ventures, Microsoft Climate Innovation Fund, Tyche Partners, Piva Capital, National Grid Partners, Dara Holdings и SiteGround. Тестирование системы STAR осуществлялось в моделируемой и масштабируемой среде ЦОД недалеко от штаб-квартиры Veir в Уоберне (Woburn) в Массачусетсе (США). Утверждается, что технология позволяет передавать до 3 МВт энергии по одному низковольтному кабелю. При этом протяжённость таких линий может в пять раз превосходить длину традиционных кабельных подключений. Система рассчитана на работу при напряжении до 800 В. 
Источник изображения: Veir По оценкам Международного энергетического агентства (IEA), в течение следующих пяти лет потребление электроэнергии в дата-центрах по всему миру вырастет более чем в два раза, достигнув 945 ТВт·ч к концу десятилетия. При этом мощность серверных стоек для ИИ, как ожидается, будет составлять до 500 кВт. Традиционная электротехническая инфраструктура, как заявляет Veir, не способна удовлетворить такие потребности, в связи с чем понадобится внедрение принципиально новых решений. Система STAR позволяет повысить гибкость развёртывания ЦОД благодаря высокой плотности мощности в расчёте на один кабель и увеличению охвата, говорит компания. При этом сокращается площадь, занимаемая компонентами подсистем питания, а также уменьшаются сроки ввода объектов в эксплуатацию. Начать коммерциализацию технологии компания Veir намерена в следующем году.
17.11.2025 [12:18], Сергей Карасёв
Silicon Motion представила контроллер SM8388 для QLC SSD с интерфейсом PCIe 5.0Компания Silicon Motion Technology анонсировала контроллер SM8388, предназначенный для построений корпоративных SSD большой ёмкости на основе флеш-чипов памяти QLC. Утверждается, что новинка позволяет создавать сравнительно недорогие твердотельные накопители Nearline-класса. Изделие полностью соответствует спецификации NVMe 2.6; поддерживается интерфейс PCIe 5.0. Контроллер имеет восьмиканальную архитектуру со скоростью передачи данных до 3200 MT/s. Заявленная скорость последовательного чтения информации достигает 14,4 Гбайт/с. Производительность IOPS при произвольном чтении — до 3,5 млн. SSD на базе SM8388 могут иметь вместимость до 128 Тбайт. Контроллер подходит для применения в накопителях различных форм-факторов, включая EDSFF (E1.S/E3.S) и U.2/U.3. Говорится о развитых средствах обеспечения безопасности, включая поддержку TCG Opal, шифрования AES-256, безопасной загрузки и аппаратной технологии Root of Trust (RoT). Заявленное типовое энергопотребление находится в пределах 5 Вт. 
Источник изображения: Silicon Motion Отмечается, что SM8388 является дальнейшим расширением платформы разработки SSD под названием MonTitan, которая дебютировала вместе с высокопроизводительным 16-канальным контроллером SM8366 для накопителей с поддержкой PCIe 5.0 x4, NVMe 2.0a и OCP 2.0. Это решение применяется в составе SSD различных производителей, включая Unigen и Innodisk. Новый контроллер — Silicon Motion SM8388 — ориентирован на устройства хранения данных для облачных платформ и кластеров ИИ. О намерении использовать такие SSD в своих серверных системах уже сообщила AIC.
17.11.2025 [10:14], Руслан Авдеев
Vertiv представила иммерсионные СЖО CoolCenter Immersion на 25–240 кВтVertiv объявила о выпуске системы погружного охлаждения CoolCenter Immersion. Иммерсионная СЖО обеспечивает поддерживает отвод от 25 кВт до 240 кВт на модуль ёмкостью 24U до 52U, обеспечивая при этом PUE на уровне 1,08. По словам компания, иммерсионное охлаждение играет всё более важную роль из-за повсеместного внедрения HPC- и ИИ-платформ. В Vertiv CoolCenter Immersion применяется многолетний опыт, полученный Vertiv в сфере СЖО для создания спроектированных «под ключ» систем, безопасно и эффективно справляющихся с высокоплотными системами. Операторы ЦОД смогут практично масштабировать ИИ-инфраструктуру без ущерба надёжности и удобству обслуживания. 
Источник изображения: Vertiv Каждая система включает внутренний или внешний резервуар для теплоносителя, блок распределения жидкости (CDU), датчики температуры, а также насосы с регулируемой скоростью работы и трубки. Модуль включает два источника питания и резервные насосы, а также встроенные датчики мониторинга состояния и 9″ сенсорный дисплей. Предусмотрена возможность подключения к системе управления зданием (BMS). Тепло отводится через пластинчатый теплообменник во внешний водяной контур. Vertiv уже заключила контракт с Digital Realty в Италии на поставку электроэнергии и систем охлаждения для римского объекта Digital ROM1 мощностью 3 МВт. Запуск ЦОД запланирован на 2027 год. На объекте будет использоваться фрикулинг и система охлаждения, готовая к ИИ-нагрузкам, передаёт DataCenter Dynamics. Сделка стала ещё одной в череде европейских проектов Digital Realty в Париже, Мадриде, Амстердаме и др. 
Источник изображения: Vertiv В Digital Realty подчеркнули, что Рим становится важнейшим шлюзом для цифровой инфраструктуры между Европой и Средиземноморским регионом. Передовые технологии для ROM1 помогут стать дата-центру стратегическим ИИ-хабом, задающим новые стандарты энергоэффективности и производительности в сфере HPC. Также Vertiv работает с Nextra в Африке и намерена сотрудничать с Ezditek для создания ЦОД в Саудовской Аравии. Ранее сообщалось, что нежелание NVIDIA сертифицировать иммерсионные СЖО во многом тормозит их развитие. Прямое жидкостное охлаждение (DLC) менее эффективно, чем иммерсионные системы, но NVIDIA всё ещё считает, что пока достаточно этого. Впрочем, эксперты прогнозируют, что настоящий расцвет технологии придётся на 2027–2028 гг. Ожидается, что она будут активно распространяться после выхода ускорителей NVIDIA Rubin Ultra.
17.11.2025 [10:02], Сергей Карасёв
ИИ-производительность японского суперкомпьютера FugakuNEXT превысит 600 ЭфлопсКомпания Fujitsu поделилась информацией о суперкомпьютере следующего поколения FugakuNEXT (Fugaku Next), который создаётся совместно с японским Институтом физико-химических исследований (RIKEN). Проект реализуется при поддержке Министерства образования, культуры, спорта, науки и технологий Японии (MEXT). FugakuNEXT придёт на смену вычислительному комплексу Fugaku, который в 2020 году стал самым высокопроизводительным суперкомпьютером в мире. В рейтинге ТОР500 от июня 2025 года эта НРС-система занимает седьмое место с FP64-быстродействием приблизительно 442 Пфлопс (теоретическая пиковая производительность достигает 537,21 Пфлопс). Разработку архитектуры FugakuNEXT планируется полностью завершить к середине 2028 года, после чего начнутся производство и монтаж суперкомпьютера. В эксплуатацию система будет введена не ранее середины 2030 года. Известно, что в основу FugakuNEXT лягут Arm-процессоры Fujitsu MONAKA-X, при производстве которых предполагается использовать 1,4-нм технологию. Чипы получат до 144 вычислительных ядер. Кроме того, в состав машины войдут ИИ-ускорители NVIDIA, для связи которых с CPU планируется задействовать шину NVLink Fusion. Платформа также получит новые интерконнекты для горизонтального и вертикального масштабирования. 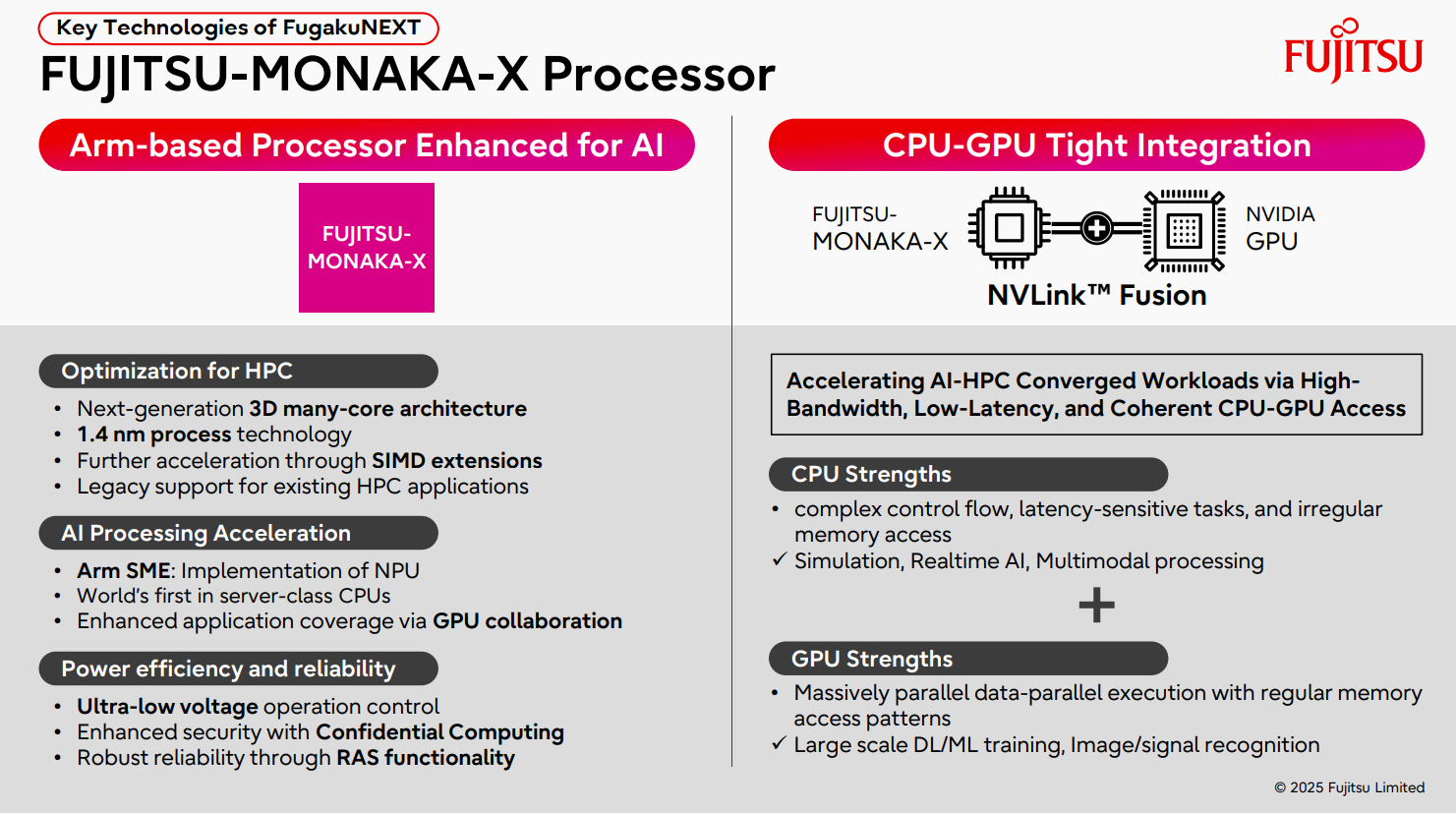
Источник изображений: Fujitsu В материалах Fujitsu говорится, что FugakuNEXT получит в общей сложности свыше 3400 узлов CPU и GPU. Их объём памяти превысит 10 ПиБ (Пебибайт). Агрегированная пропускная способность памяти в случае CPU-блоков составит более 7 Пбайт/с, GPU-модулей — свыше 800 Пбайт/с против 163 Пбайт/с у нынешней системы Fugaku.  Кроме того, раскрываются ожидаемые показатели ИИ-быстродействия FugakuNEXT. У CPU-секции производительность превысит 48 Пфлопс в режиме FP64, 1,5 Эфлопс на операциях FP16/BF16 и 3 Эфлопс в режиме FP8. В случае GPU-раздела быстродействие FP64, FP16/BF16, FP8 и FP8 Sparse составит более 2,6 Эфлопс, 150 Эфлопс, 300 Эфлопс и 600 Эфлопс соответственно.
17.11.2025 [07:45], Владимир Мироненко
NEC и OpenСhip вместе разработают векторные ускорители на базе RISC-V и суперкомпьютеры Aurora следующего поколенияБазирующийся в Барселоне разработчик чипов OpenChip, который некоторые эксперты называют каталонской NVIDIA, и компания NEC объявили о следующем этапе сотрудничества, направленного на совместную разработку векторного процессора (VPU) нового поколения. Ранее компании выполнили технико-экономическое обоснование разработки следующего поколения векторных суперкомпьютеров Aurora с использованием аппаратного и программного стека OpenChip на базе RISC-V. Как сообщается в пресс-релизе, на начальном этапе основное внимание уделялось оценке совместимости архитектуры Aurora от NEC с ускорителями OpenChip, определению логической структуры и начальной разработке программных компонентов. В результате исследования компании пришли к выводу о технической осуществимость проекта, так что теперь компании займутся совместной разработкой следующего поколения высокопроизводительных ускорителей, а также оптимизированного программного стека. Обе компании планируют запуск пилотных развёртываний у отдельных клиентов. По словам старшего вице-президента NEC Сухуна Юна (Suhun Yun), сотрудничество NEC с OpenChip является поворотным моментом в стратегическом развитии NEC в направлении вычислительных архитектур следующего поколения. В свою очередь, OpenChip отметила, что сотрудничество направлено на достижение ряда ключевых преимуществ, в числе которых повышенная производительность критически важных рабочих нагрузок, обеспечение нового уровня вычислительной мощности для HPC, ИИ и ML, а также для таких научных приложений, как геномика и моделирование климата. 
Источник изображения: NEC В 2021 году NEC анонсировала векторные ускорителя SX-Aurora TSUBASA Vector Engine 2.0 (VE20), а в 2022 — доработанные VE30. Однако в 2023 году NEC фактически прекратила разработку новых решений в серии SX-Aurora в связи с появлением ускорителей AMD и NVIDIA, значительно превосходящих её наработки, так что обещанные VE40 и VE50 так и не появились на свет. При этом у NEC и ранее были длительные перерывы в разработке векторных ускорителей, а её суперкомпьютеры на их основе по-прежнему пользуются спросом в некоторых областях, в частности, в метеорологии и климатологии. OpenChip разрабатывает SoC, использующую несколько UCIe-чиплетов, референсные проекты для аппаратных платформ, базовые комплекты разработчиков ПО и прикладные сервисы. Как сообщает ресурс HPCwire, среди других европейских стартапов, разрабатывающих решения на базе RISV-V есть:
За последние годы было поставлено более 10 млрд ядер с архитектурой RISC-V благодаря широкому внедрению архитектуры в микроконтроллерах и встраиваемых устройствах. За последнее время RISC-V стала потенциальной альтернативой проприетарным архитектурам, включая Arm и x86, в разработке ускорителей и HPC-платформ.
16.11.2025 [23:30], Игорь Осколков
Intel отказалась от массовых Xeon Diamond Rapids с восемью каналами памяти — останутся только 16-канальные процессорыIntel, по сообщению ServeTheHome, решила отказаться в следующем поколении серверных процессоров Xeon Diamond Rapids на платформе Oak Stream от чипов с поддержкой восьми каналов памяти, оставив только модели с 16 каналами DRAM и поддержкой MRDIMM. Иными словами, в новом поколении компания, по-видимому, будет ориентироваться на топовый сегмент, оставив недорогие массовые платформы за бортом. Компания дала официальный комментарий ServeTheHome: «Мы исключили 8-канальные Diamond Rapids из наших планов. Мы упрощаем платформу Diamond Rapids, уделяя особое внимание 16-канальным процессорам и расширяя её преимущества для всех остальных, чтобы удовлетворить потребности различных клиентов». Грядущие AMD EPYC Venice также получат 16-канальный контроллер памяти. 
Источник изображения: Intel Пока что и у AMD, и у Intel максимальное количество поддерживаемых каналов памяти составляет 12. Однако в случае Intel реально доступными являются только Xeon Granite Rapids-AP (6900P), тогда как Sierra Forest-AP (6900E) так и остались нишевым продуктом. Грядущие Xeon 6+ Clearwater Forest также останутся при 12 каналах. При этом у EPYC поколения Turin (9005) во всех вариантах доступны 12 каналов.  Наиболее массовые Granite Rapids-SP (6500P/6700P) и Sierra Forest-SP (6700E) на платформе Birch Stream ограничены восемью каналами памяти, но… это может быть не так уж и плохо. Платформы для них дешевле, чем для AP-версий, а относительно небольшое количество каналов памяти даёт определённую гибкость в выборе компонентов. Речь в том числе про физические характеристики серверных платформ — платы с 32 или 48 слотами DIMM вынужденно переходят к «двухярусной» компоновке, когда один процессор сдвинут вглубь шасси из-за невозможности комфортно разместить все слоты и оба сокета в один ряд в рамках стандартного 19” корпуса. 
В многоузловых системах компоновка ещё более экзотическая При этом типовые восьмиканальные решения позволяют легко набрать нужный объём RAM в 2DPC-режиме более дешёвыми модулями памяти (пусть и с потерей производительности), чем в случае 12-канальных платформ с 1DPC. Поэтому 2S-системы с восьмиканальными CPU всё ещё остаются крайне популярными. Однако Intel в Diamond Rapids решила отказаться от массовых платформ.
16.11.2025 [17:38], Руслан Авдеев
Ни доходов, ни рабочих мест: льготы для дата-центров не приносят ничего хорошего большинству штатов США, но отказаться от них трудноАмериканская индустрия ЦОД получает немалые субсидии на уровне штатов, но процедура не всегда прозрачна, а некоторые штаты даже теряют деньги на этом, сообщает некоммерческая организация Good Jobs First. По данным НКО, налоговые льготы для развития ЦОД и облачных вычислений предоставляют 36 штатов, но лишь 11 из них раскрывают, какие именно компании их получают. В остальном всё крайне непрозрачно: лишь в немногих штатах говорят, о каких объёмах льгот идёт речь, и раскрывают информацию о том, выполняют ли компании обещания о капиталовложениях и создают ли рабочие места. В документе «Облачные данные, дорогостоящие сделки: как неохотно штаты раскрывают субсидии центрам обработки данных» (Cloudy Data, Costly Deals: How Poorly States Disclose Data Center Subsidies) приводятся некоторые детали, передаёт The Register. 
Источник изображения: zanck FL/unsplash.com В частности, из 11 штатов, раскрывающих информацию об освобождении от налогов с продаж и использования, ни один не разглашает конечных бенефициаров таких послаблений. Тем временем Amazon, Google, Microsoft, Meta✴ и Apple регулярно «прячутся» за дочерними компаниями. Только 5 из 11 штатов раскрывают вероятные или фактические объёмы субсидий, причём с запозданием. Лишь четыре штата — Иллинойс, Индиана, Невада и Огайо — рассказывают о том, сколько рабочих мест обещают создать операторы ЦОД. Ни один из штатов не отчитывается о фактически созданных рабочих местах, хотя налоговые льготы часто связывают именно с появлением новых вакансий. Наконец, только Невада сообщает, какие зарплаты платят сотрудникам в субсидируемых проектах. По словам НКО, во многих штатах речь идёт о двойных стандартах. Большинство проектов, получающих субсидии, освещаются довольно хорошо, но только не дата-центры. В апреле 2024 года Good Jobs First сообщала, что только освобождение дата-центров от налога с продаж и использования ежегодно обходится бюджетам штатов в миллиарды долларов недополученных доходов. В 2025 финансовом году Техас потерял $1 млрд из-за ЦОД, но штат публикует только названия субсидируемых компаний без каких-либо деталей. Вирджиния, крупнейший в стране рынок ЦОД, тоже теряет почти $1 млрд, но какие компании получают льготы и в каком объёме, не раскрывает. Более того, в нескольких штатах чистые убытки составляют от ¢52 до ¢70 с каждого $1 налоговых субсидий. 
Источник изображения: Good Jobs First ЦОД, как считается, возглавляют список наиболее неэффективно субсидируемых отраслей в 2025 году. В исследовании рекомендуется резко сократить объёмы расходов штатов на дата-центры, отменив или пересмотрев налоговые льготы. В Джорджии и Огайо уже проголосовали за приостановку или отмену этих льгот, но вето на оба законопроекта наложили губернаторы. В любом случае, как считают в Good Jobs First, штаты должны обеспечить полную прозрачность данных о том, какие компании получают льготы, в каких объёмах и что получают взамен. При этом в исследовании даже не касались других послаблений вроде льгот по налогу на имущество и корпоративную прибыль или же скидки на оплату электроэнергии и воды — эти данные также крайне редко раскрываются. Стоит отметить, что JPMorgan недавно спрогнозировал гигантские расходы на дата-центры в ближайшие пять лет и «астрономический» спрос на соответствующую инфраструктуру, поэтому руководство штатов, возможно, просто не может отказаться от участия в «гонке ЦОД». |
|

