Материалы по тегу: c
|
13.10.2020 [23:41], Владимир Мироненко
Amazon купила у радиолюбителей 4 млн IPv4-адресов за $108 млнПрезидент неправительственной организации радиолюбителей Amateur Radio Digital Communications (ARDC) из Калифорнии (США) Фил Карн (Phil Karn, KA9Q), подтвердил, что ARDC получила $108 млн от Amazon за 4 млн адресов IPv4.  С момента выделения любительскому радио в середине 1980-х годов сети 44 (44.0.0.0/8), также известной как AMPRNet, она использовалась радиолюбителями для проведения научных исследований и экспериментов с цифровыми коммуникациями по радио с целью продвижения современного уровня любительских радиосетей и обучения радиолюбителей этим методам. Этот процесс координирует некоммерческая организация ARDC. Блок (44.192.0.0/10) примерно из четырех млн IP-адресов AMPRNet из 16 млн доступных был продан Amazon организацией ARDC в середине 2019 года, но лишь сейчас была объявлена стоимость сделки. Amazon заплатила ARDC примерно $27 за каждый IPv4-адрес. «Соглашение о неразглашении информации с Amazon, которое касалось продажи наших избыточных IP-адресов, требовало от нас не сообщать точные суммы в долларах до тех пор, пока мы не обязаны по закону раскрывать их в наших ежегодных налоговых декларациях, аудиторских и финансовых отчетах. Они только что были обнародованы и доступны в Интернете на веб-сайте генерального прокурора Калифорнии (поскольку ARDC зарегистрирована в Калифорнии). Вы также можете получить некоторую справочную информацию в нашей статье в Википедии», — сообщил Фил Карн в посте на сайте AMSAT Bulletin Board (AMSAT-BB). Он пообещал, что организация будет ежегодно выделять из полученной суммы порядка $5 млн на интернет- и радиолюбительские цифровые коммуникационные проекты. «На сегодняшний день мы выделили около $2,5 млн в виде грантов, так что мы только начинаем», — добавил глава ARDC.
27.08.2020 [19:13], Алексей Степин
TSMC и Graphcore создают ИИ-платформу на базе технологии 3 нмНесмотря на все проблемы в полупроводниковой индустрии, технологии продолжают развиваться. Технологические нормы 7 нм уже давно не являются чудом, вовсю осваиваются и более тонкие нормы, например, 5 нм. А ведущий контрактный производитель, TSMC, штурмует следующую вершину — 3-нм техпроцесс. Одним из первых продуктов на базе этой технологии станет ИИ-платформа Graphcore с четырьмя IPU нового поколения. Британская компания Graphcore разрабатывает специфические ускорители уже не первый год. В прошлом году она представила процессор IPU (Intelligence Processing Unit), интересный тем, что состоит не из ядер, а из так называемых тайлов, каждый из которых содержит вычислительное ядро и некоторое количество интегрированной памяти. В совокупности 1216 таких тайлов дают 300 Мбайт сверхбыстрой памяти с ПСП до 45 Тбайт/с, а между собой процессоры IPU общаются посредством IPU-Link на скорости 320 Гбайт/с. 
Colossально: ИИ-сервер Graphcore с четырьмя IPU на борту Компания позаботилась о программном сопровождении своего детища, снабдив его стеком Poplar, в котором предусмотрена интеграция с TensorFlow и Open Neural Network Exchange. Разработкой Graphcore заинтересовалась Microsoft, применившая IPU в сервисах Azure, причём совместное тестирование показало самые положительные результаты. Следующее поколение IPU, Colossus MK2, представленное летом этого года, оказалось сложнее NVIDIA A100 и получило уже 900 Мбайт сверхбыстрой памяти.  Машинное обучение, в основе которого лежит тренировка и использование нейронных сетей, само по себе требует процессоров с весьма высокой степенью параллелизма, а она, в свою очередь, автоматически означает огромное количество транзисторов — 59,4 млрд в случае Colossus MK2. Поэтому освоение новых, более тонких и экономичных техпроцессов является для этого класса микрочипов ключевой задачей, и Graphcore это понимает, заявляя о своём сотрудничестве с TSMC. 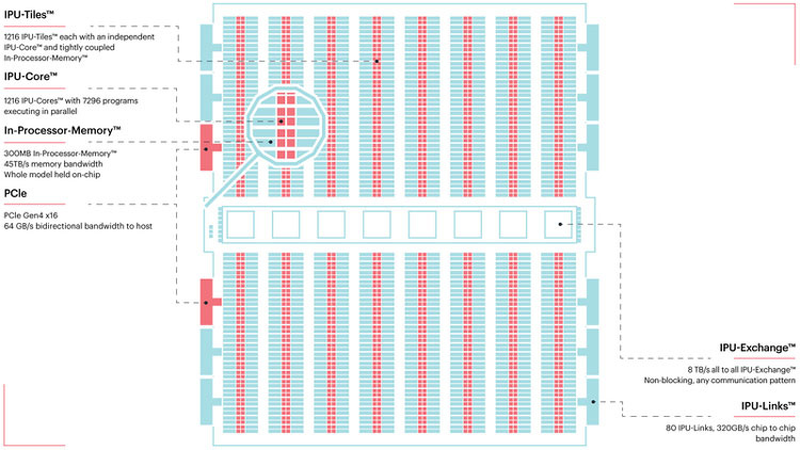
Тайловая архитектура Graphcore Colossus MK2 В настоящее время TSMC готовит к началу «рискового» производства новый техпроцесс с нормами 3 нм, причём скорость внедрения такова, что первые продукты на его основе должны увидеть свет уже в 2021 году, а массовое производство будет развёрнуто во второй половине 2022 года. И одним из первых продуктов на базе 3-нм технологических норм станет новый вариант IPU за авторством Graphcore, известный сейчас как N3. Судя по всему, использовать 5 нм британский разработчик не собирается. 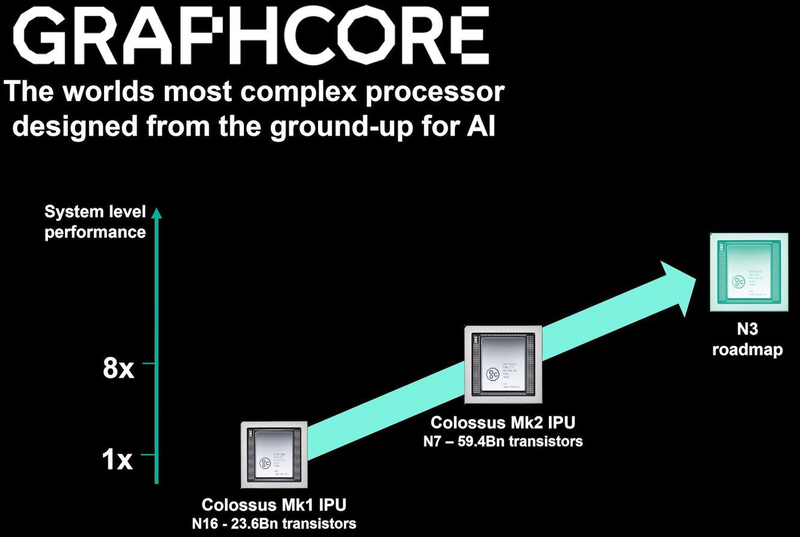
В планах компании явно указано использование 3-нм техпроцесса В настоящее время чипы Colossus MK2 производятся с использованием техпроцесса 7 нм (TSMC N7). Они включают в себя 1472 тайла и способны одновременно выполнять 8832 потока. В режиме тренировки нейросетей с использованием вычислений FP16 это даёт 250 Тфлопс, но существует удобное решение мощностью 1 Пфлопс — это специальный 1U-сервер Graphcore, в нём четыре IPU дополнены 450 Гбайт внешней памяти. Доступны также платы расширения PCI Express c чипами IPU на борту. Дела у Graphcore идут неплохо, её технология оказалась востребованной и среди инвесторов числятся Microsoft, BMW, DeepMind и ряд других компаний, разрабатывающих и внедряющих комплексы машинного обучения. Разработка 3-нм чипа ещё более упрочнит позиции этого разработчика. Более тонкие техпроцессы существенно увеличивают стоимость разработки, но финансовые резервы у Graphcore пока есть; при этом не и исключён вариант более тесного сотрудничества, при котором часть стоимости разработки возьмёт на себя TSMC.
24.07.2020 [00:50], Игорь Осколков
Phytium Tengyun S2500: 64-ядерный ARM-чип для восьмипроцессорных системКак сообщает cnTechPost, Phytium, китайский разработчик процессоров, анонсировал новый 64-ядерный чип Tengyun S2500, ориентированный на высокопроизводительные вычисления (HPC). Компания и прежде была известна разработками в этой области — её процессоры легли в основу суперкомпьютеров Tiahne, занимавших первые строчки рейтинга TOP500. 
Изображения: cnTechPost В отличие от своего предшественника FT-2000+/64, тоже 64-ядерного, ядра новинки в дополнение к L2-кешу объёмом 512 Кбайт получили общий L3-кеш на 64 Мбайт. Кроме того, чип поддерживает восемь каналов памяти DDR4-3200. Отличительной чертой Tengyun S2500 является возможность объединения — судя по всему, бесшовного — от двух до восьми процессоров в рамках одной системы. Для связи между CPU используется несколько линий собственной шины со скоростью 800 Гбит/с.  В основе CPU лежат ядра FTC663, работающие на частоте 2 – 2,2 ГГц. Они же используются в представленном в прошлом году младшем чипе Phytium FT2000/4. Ядра серии FTC600 базируются на модифицированной архитектуре ARMv8 и включают переделанные блоки для целочисленных вычислений и вычислений с плавающей запятой, ASIMD-инструкции, новый динамический предсказатель переходов, поддержку виртуализации, а также традиционные для китайских CPU блоки шифрования и безопасности, соответствующие локальным стандартам.  Энергопотребление новинок достигает 150 Вт. Изготавливаться они будут на TSCM по техпроцессу 16-нм FinFET. Начало массового производства запланировано на четвёртый квартал этого года. Тогда же появятся и 14-нм десктопные чипы Phytium Tengrui D2000, которым через года не смену придут Tengrui D3000. Выход 7-нм серверных процессоров Phytium Tengyun S5000 запланирован на третий квартал 2021 года, а 5-нм чипы Tengyun S6000 появятся уже в 2022-ом.
27.06.2020 [18:54], Алексей Степин
ISC 2020: NEC анонсировала новые векторные ускорители SX-AuroraВ японском сегменте рынка супервычислений продолжает доминировать свой, уникальный подход к построению систем класса HPC. Fujitsu сделала ставку на гомогенную архитектуру A64FX с памятью HBM2 и заняла первое место в Top500, но и другая японская компания, NEC, не отказалась от своего видения суперкомпьютерной архитектуры. На предыдущей конференции SC19 NEC пополнила свой арсенал новыми ускорителями SX-Aurora 10E, которые получили более быстрые сборки HBM2. О новых ускорителях «Type 20» речь заходила ещё до начала эпидемии COVID-19; к сожалению, она внесла свои коррективы и анонс новинок состоялся лишь сейчас, летом 2020 года.  Изначально процессор SX-Aurora, используемый во всей серии ускорителей «Type 10» имеет 8 векторных блоков, каждый из которых дополнен 2 Мбайт кеша и 6 сборок памяти HBM2 общим объёмом 24 или 48 Гбайт. Из-за сравнительно грубого 16-нм техпроцесса уровень тепловыделения достаточно высок и составляет примерно 225 Ватт. В отличие от Fujitsu A64FX, NEC SX-Aurora требует для своей работы управляющего хост-процессора, и обычно компания комбинирует его с Intel Xeon, но существуют варианты и с AMD EPYC второго поколения. 
ISC 2018: HPC-модуль с восемью векторными ускорителями NEC SX-Aurora Type 10 Это роднит SX-Aurora с более широко распространёнными ускорителями на базе графических процессоров, однако позиционирование у них всё-таки выглядит иначе. ГП-ускорители, по мнению NEC, гораздо сложнее в программировании, хотя и обеспечивают высокую производительность. 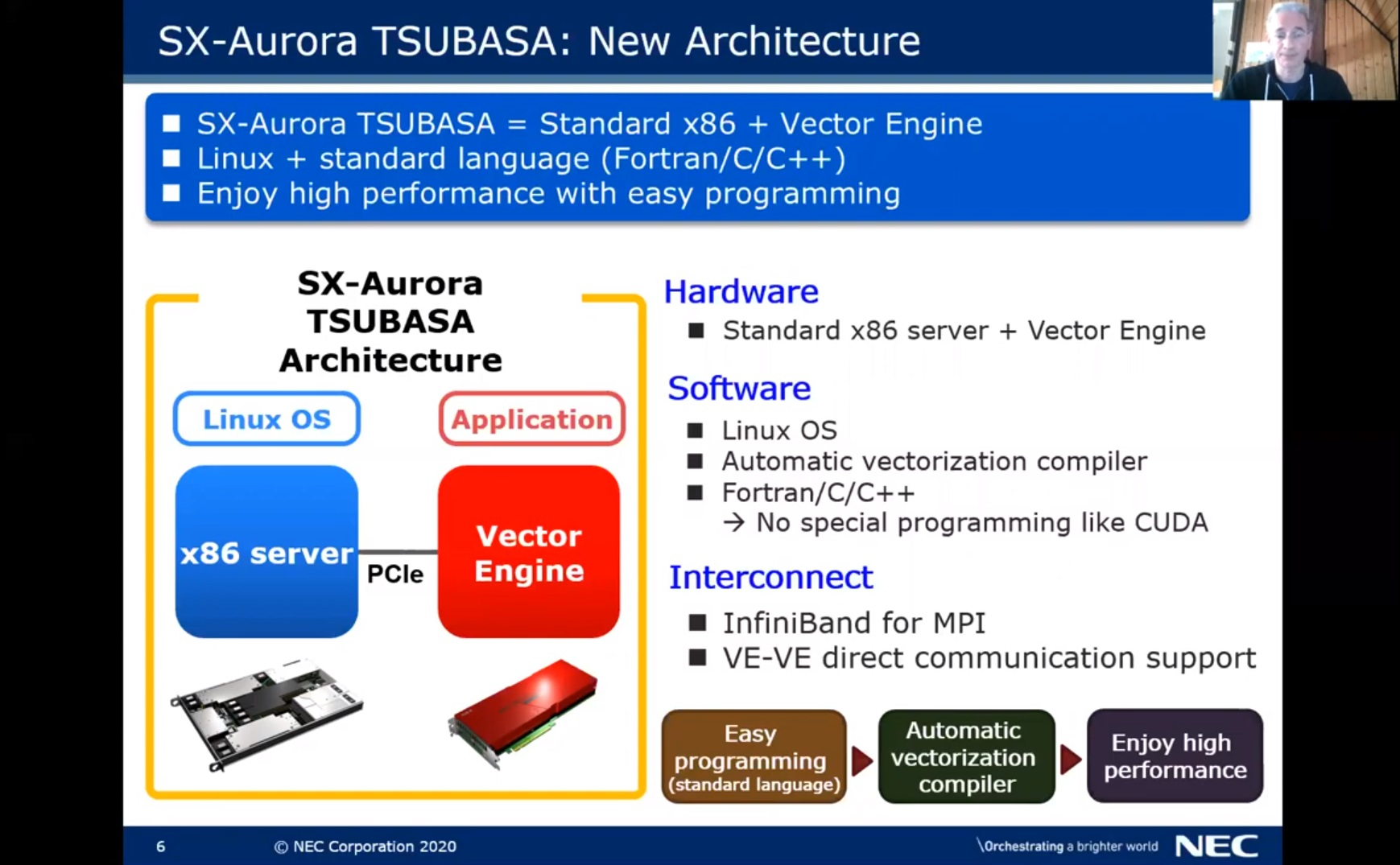 Свою же разработку компания относит к решениям с похожим уровнем производительности, но гораздо более простым в программировании. Упор также делается на высокую пропускную способность памяти, составляющую у новинок «Type 20» 1,5 Тбайт/с.  Новая версия NEC Vector Engine, VE20, структурно, скорее всего, не изменилась. Вместо восьми ядер новый процессор получил 10, и, как уже было сказано, новые сборки HBM2, в результате чего ПСП удалось поднять с 1,35 до 1,5 Тбайт/с, а вычислительную мощность с 2,45 до 3,07 Тфлопс. 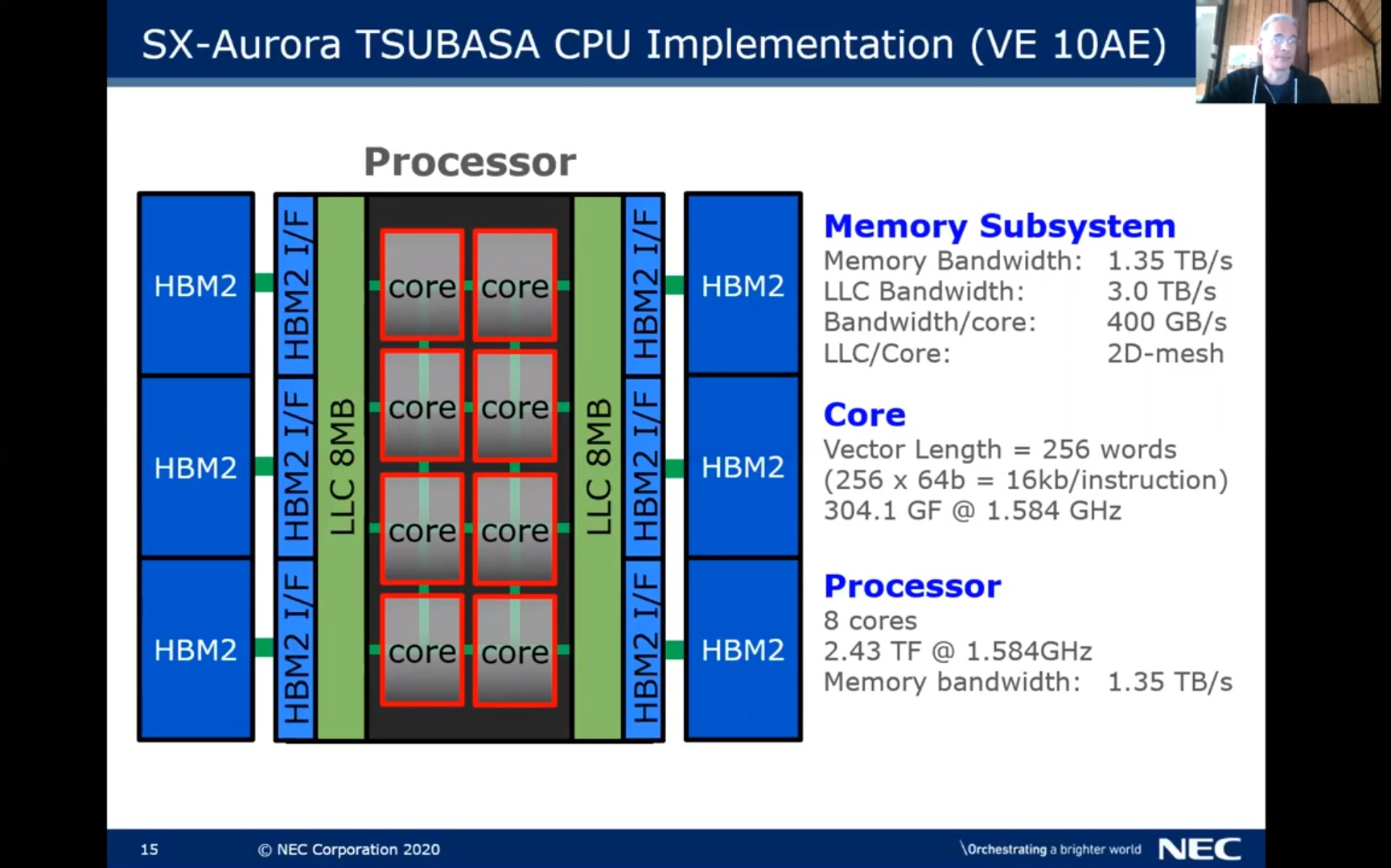 В серии пока представлено два новых ускорителя, Type 20A и 20B, последний аналогичен по конфигурации решениям Type 10 и использует усечённый вариант процессора с 8 ядрами. Говорится о неких архитектурных улучшениях, но деталей компания пока не раскрывает. Оба варианта процессора VE20 работают на частоте 1,6 ГГц, а прирост производительности в сравнении с VE10 достигается в основном за счёт повышения ПСП.  Похоже, VE20 лишь промежуточная ступень. В 2022 году планируется выпуск процессора VE30, который получит подсистему памяти с пропускной способностью свыше 2 Тбайт/с, в 2023 должен появиться его наследник VE40, но настоящий прорыв, судя по всему, откладывается до 2024 года, когда NEC планирует представить VE50, об архитектуре и возможностях которого пока ничего неизвестно. 
25.06.2020 [21:10], Алексей Степин
ISC 2020: Tachyum анонсировала 128-ядерные ИИ-процессоры Prodigy и будущий суперкомпьютер на их основеМашинное обучение в последние годы развивается и внедряется очень активно. Разработчики аппаратного обеспечения внедряют в свои новейшие решения поддержку оптимальных для ИИ-систем форматов вычислений, под этот круг задач создаются специализированные ускорители и сопроцессоры. 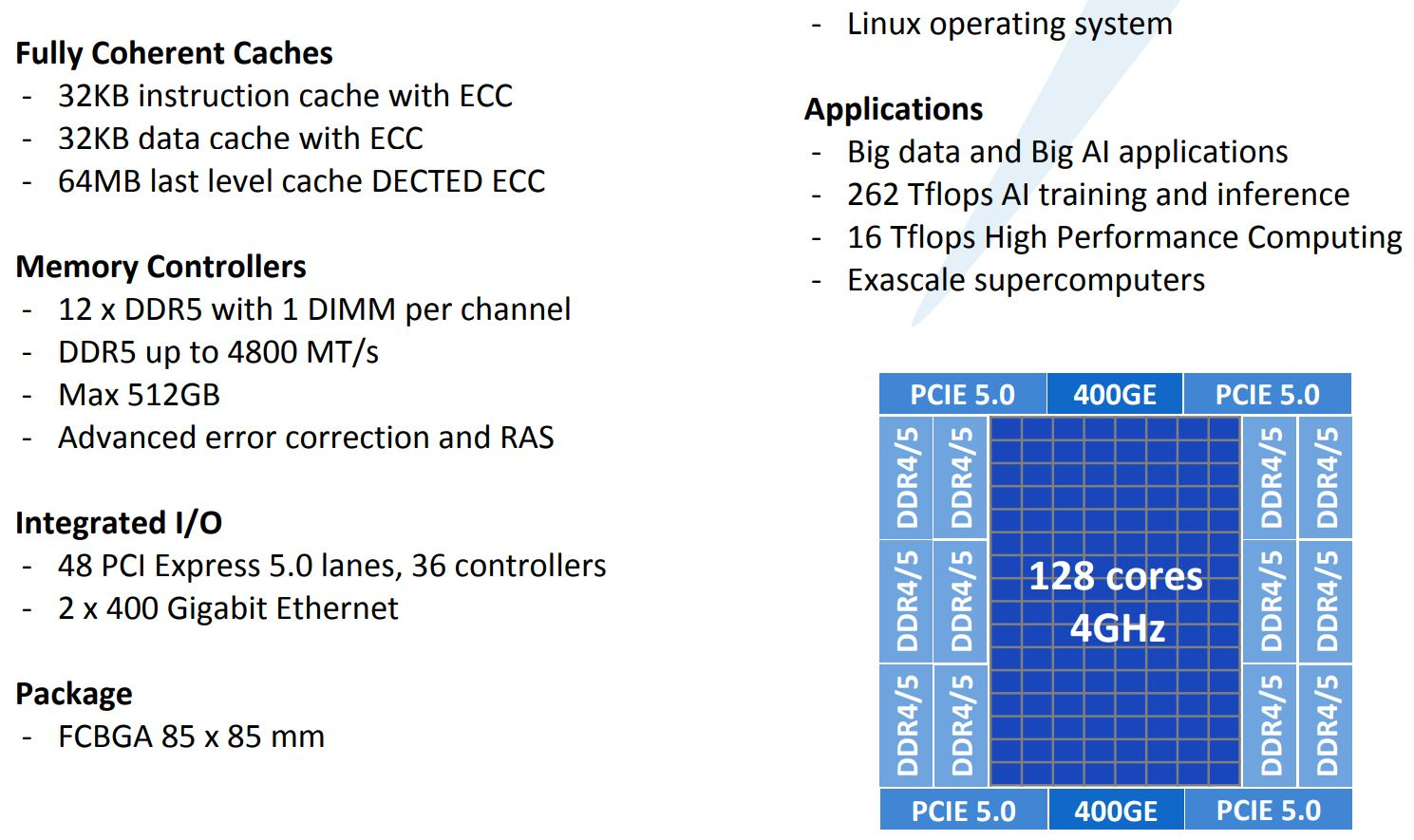 Словацкая компания Tachyum достаточно молода, но уже пообещала выпустить процессор, который «отправит Xeon на свалку истории». О том, что эти чипы станут основой для суперкомпьютеров нового поколения, мы уже рассказывали читателям, а на конференции ISC High Performance 2020 Tachyum анонсировала и сами процессоры Prodigy, и ИИ-комплекс на их основе.  Запуск готовых сценариев машинного интеллекта достаточно несложная задача, с ней справляются даже компактные специализированные чипы. Но обучение таких систем требует куда более внушительных ресурсов. Такие ресурсы Tachyum может предоставить: на базе разработанных ею процессоров Prodigy она создала дизайн суперкомпьютера с мощностью 125 Пфлопс на стойку и 4 экзафлопса на полный комплекс, состоящий из 32 стоек высотой 52U.  Основой для новой машины является сервер-модуль собственной разработки Tachyum, системная плата которого оснащается четырьмя чипами Prodigy. Каждый процессор, по словам разработчиков, развивает до 625 Тфлопс, что дает 2,5 Пфлопс на сервер. Компания обещает для новых систем трёхкратный выигрыш по параметру «цена/производительность» и четырёхкратный — по стоимости владения. При этом энергопотребление должно быть на порядок меньше, нежели у традиционных систем такого класса. 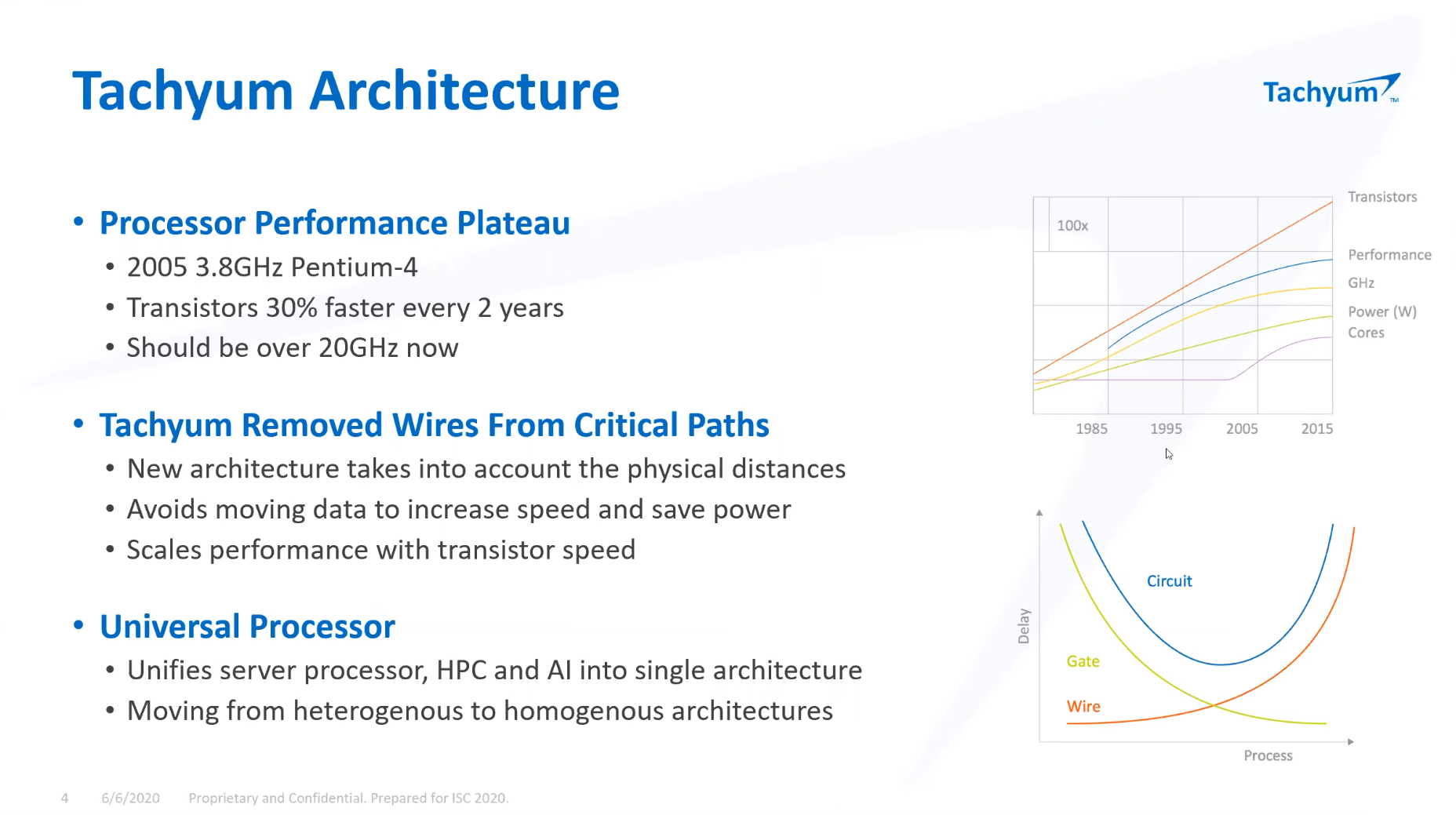 Архитектура Prodigy представляет существенный интерес: это не узкоспециализированный чип, вроде разработок NVIDIA, а универсальный процессор, сочетающий в себе черты ЦП, ГП и ускорителя ИИ-операций. Структура кристалла построена вокруг концепции «минимального перемещения данных». При разработке Tachyum компания принимала во внимание задержки, вносимые расстоянием между компонентами процессора, и минимизировала их. 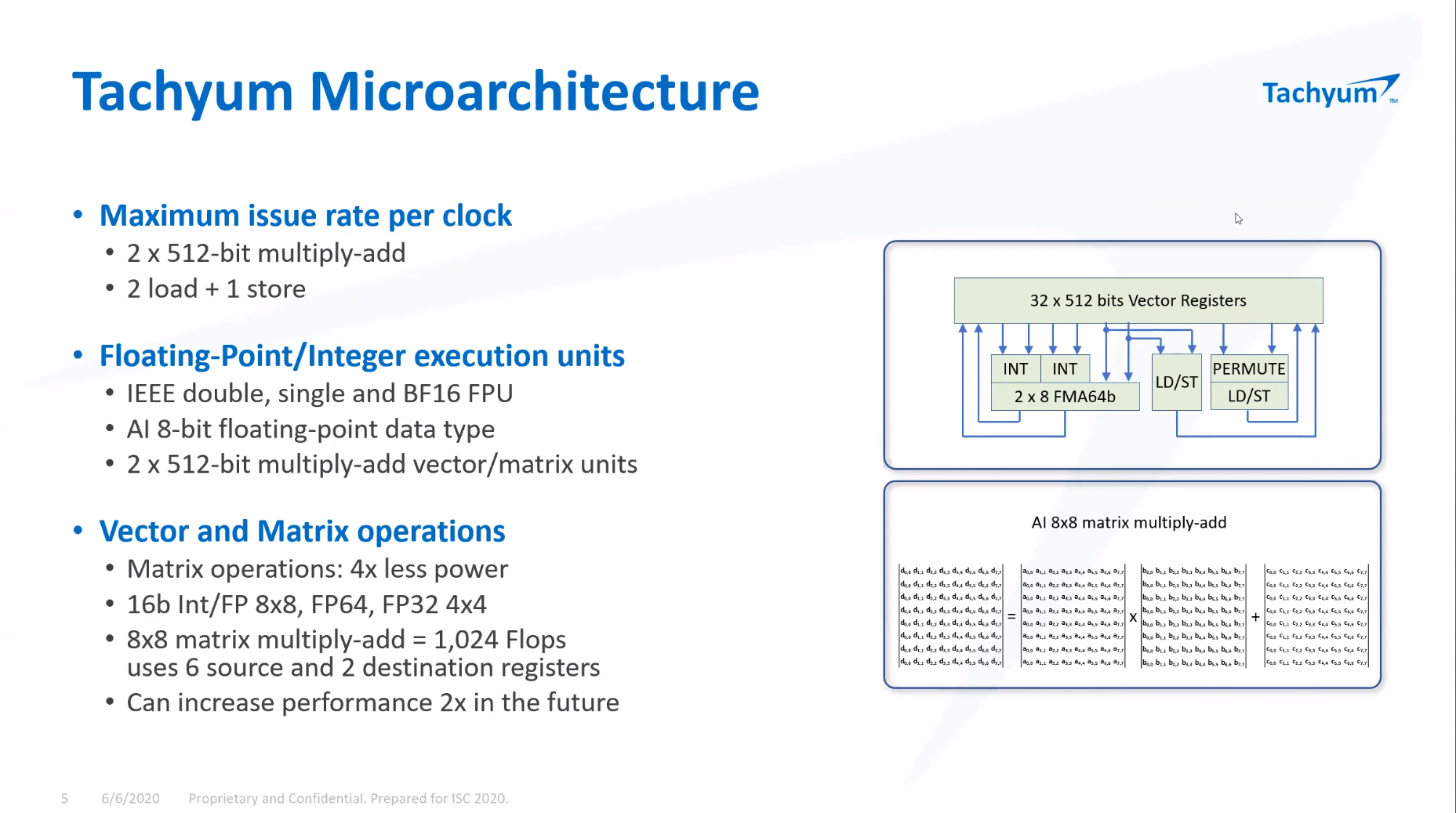 Процессор Prodigy может выполнять за такт две 512-битные операции типа multiply-add, 2 операции load и одну операцию store. Соответственно то, что каждое ядро Prodigy имеет восемь 64-бит векторных блока, похожих на те, что реализованы в расширениях Intel AVX-512 IFMA (Integer Fused Multiply Add, появилось в Cannon Lake). Блок вычислений с плавающей точкой поддерживает двойную, одинарную и половинную точность по стандартам IEEE. Для ИИ-задач имеется также поддержка 8-битных типов данных с плавающей запятой. 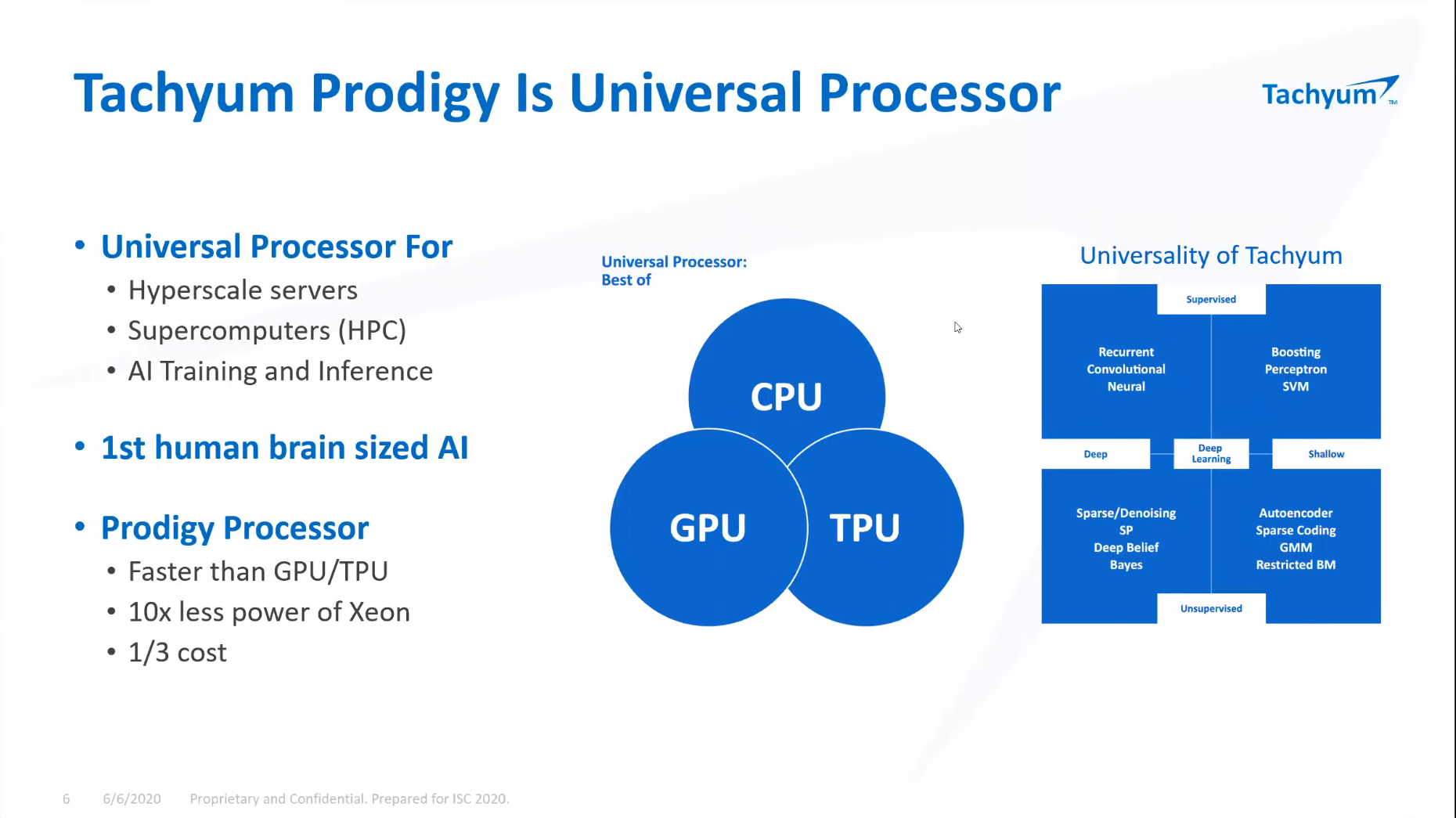 Векторные и матричные операции — сильная сторона Prodigy. На перемножении-сложении матриц размерностью 8 × 8 ядро развивает 1024 Флопс, используя 6 входных и 2 целевых регистра (в сумме есть тридцать два 512-бит регистра). Это не предел, разработчик говорит о возможности увеличения скорости выполнения этой операции вдвое. Tachyum обещает, что система на базе Prodigy станет первым в мире ИИ-кластером, способным запустить машинный интеллект, соответствующий человеческому мозгу.  С учётом заявлений о 10-кратной экономии электроэнергии и 1/3 стоимости от стоимости Xeon, это заявление звучит очень сильно. Но Prodigу — не бумажный продукт-однодневка. Tachyum разработала не только сам процессор, но и всю необходимую ему сопутствующую инфраструктуру, включая и компилятор, в котором реализованы оптимизации в рамках «минимального перемещения данных». Новинка разрабона с использованием 7-нм техпроцесса, максимальное количество ядер с вышеописанной архитектурой — 64. Помимо самих ядер, кристалл T864 содержит восьмиканальный контроллер DDR5, контроллер PCI Express 5.0 на 64 (а не 72, как ожидалось ранее) линии и два сетевых интерфейса 400GbE. При тактовой частоте 4 ГГц Prodigy развивает 8 Тфлопс на стандартных вычислениях FP32, 1 Пфлоп на задачах обучения ИИ и 4 Петаопа в инференс-задачах. Самая старшая версия, Tachyum Prodigy T16128, предлагает уже 128 ядер с частотой до 4 ГГц, 12 каналов памяти DDR5-4800 (но только 1DPC и до 512 Гбайт суммарно), 48 линий PCI Express 5.0 и два контроллера 400GbE. Производительность в HPC-задачах составит 16 Тфлопс, а в ИИ — 262 Тфлопс на обучении и тренировке.  Системные платы для Prodigy представлены, как минимум, в двух вариантах: полноразмерные четырёхпроцессорные для сегмента HPC и компактные однопроцессорные для модульных систем высокой плотности. Полноразмерный вариант имеет 64 слота DIMM и поддерживает модули DDR5 объёмом до 512 Гбайт, что даёт 32 Тбайт памяти на вычислительный узел. Сам узел полностью совместим со стандартами 19″ и Open Compute V3, он может иметь высоту 1U или 2U и поддерживает питание напряжением 48 Вольт. Плата имеет собственный BIOS UEFI, но для удалённого управления в ней реализован открытый стандарт OpenBMC.  Tachyum исповедует концепцию универсальности, но всё-таки узлы для HPC-систем на базе Prodigy могут быть нескольких типов — универсальные вычислительные, узлы хранения данных, а также узлы управления. В качестве «дисковой подсистемы» разработчики выбрали SSD-накопители в формате NF1, подобные представленному ещё в 2018 году накопителю Samsung. Таких накопителей в корпусе системы может быть от одного до 36; поскольку NF1 существенно крупнее M.2, поддерживаются модели объёмом до 32 Тбайт, что даёт почти 1,2 Пбайт на узел. Стойка с модулями Prodigy будет вмещать до 50 модулей высотой 1U или до 25 высотой 2U. Согласно идее о минимизации дистанций при перемещении данных, сетевой коммутатор на 128 или 256 портов 100GbE устанавливается в середине стойки.  Такая конфигурация работает в системе с числом стоек до 16, более масштабные комплексы предполагается соединять между собой посредством коммутатора высотой 2U c 64 портами QSFP-DD, причём поддержка скорости 800 Гбит/с появится уже в 2022 году. 512 стоек могут объединяться посредством высокопроизводительного коммутатора CLOS, он имеет высоту 21U и также получит поддержку 800 Гбит/с в дальнейшем. Компания активно поддерживает открытые стандарты: применён загрузчик Core-Boot, разработаны драйверы устройств для Linux, компиляторы и отладчики GCC, поддерживаются открытые приложения, такие, как LAMP, Hadoop, Sparc, различные базы данных. В первом квартале 2021 года ожидается поддержка Java, Python, TensorFlow, PyTorch, LLVM и даже операционной системы FreeBSD.  Любопытно, что существующее программное обеспечение на системах Tachyum Prodigy может быть запущено сразу в виде бинарных файлов x86, ARMv8 или RISC-V — разумеется, с пенальти. Производительность ожидается в пределах 60 ‒ 75% от «родной архитектуры», для достижения 100% эффективности всё же потребуется рекомпиляция. Но в рамках контрактной поддержки компания обещает помощь в этом деле для своих партнёров. Разумеется, пока речи о полномасштабном производстве новых систем не идёт. Эталонные платформы Tachyum обещает во второй половине следующего года. Как обычно, сначала инженерные образцы получают OEM/ODM-партнёры компании и системные интеграторы, а массовые поставки должны начаться в 4 квартале 2021 года. Однако ПЛИС-эмуляторы Prodigy появятся уже в октябре этого года, инструментарий разработки ПО — и вовсе в августе.  Планы у Tachyum поистине наполеоновские, но её разработки интересны и содержат целый ряд любопытных идей. В чём-то новые процессоры можно сравнить с Fujitsu A64FX, которые также позволяют создавать гомогенные и универсальные вычислительные комплексы. Насколько удачной окажется новая платформа, говорить пока рано.
22.06.2020 [18:20], Игорь Осколков
ARM-суперкомпьютер Fugaku поднялся на вершину рейтингов TOP500, HPCG и HPL-AIКонечно же, речь идёт о японском суперкомпьютере Fugaku на базе ARM-процессоров A64FX, который досрочно начал трудиться весной этого года. Эта машина стала самым мощным суперкомпьютером в мире сразу в трёх рейтингах: классическом TOP500, современном HPCG и специализированном HPL-AI.  Суперкомпьютер состоит из 158976 узлов, которые имеют почти 7,3 млн процессорных ядер, обеспечивающих реальную производительность на уровне 415,5 Пфлопс, то есть Fugaku почти в два с половиной раза быстрее лидера предыдущего рейтинга, машины Summit. Правда, оказалось, что с точки зрения энергоэффективности новая ARM-система мало чем отличается от связки обычного процессора и GPU, которой пользуется большая часть суперкомпьютеров. Так что на первое место в Green500 она не попала. 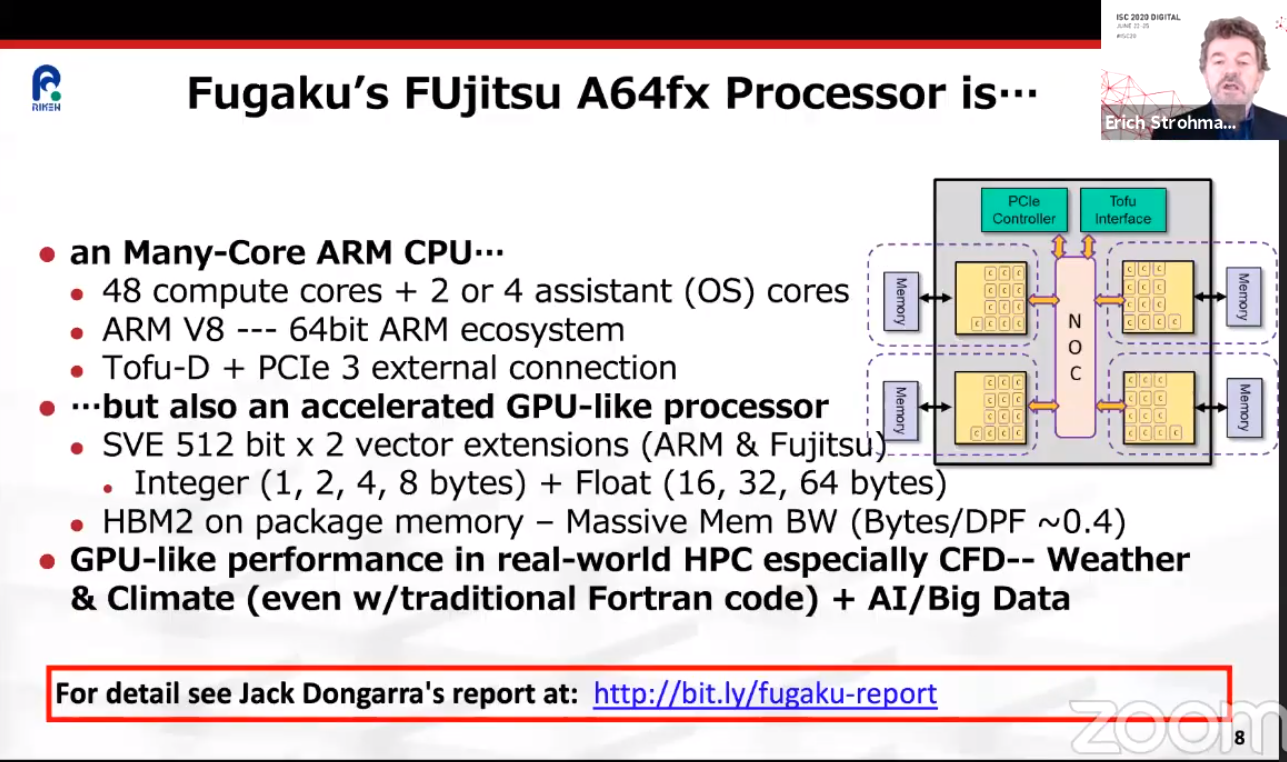  Однако на стороне Fugaku универсальность — понижение точности вычислений вдвое приводит к удвоение производительности. Так что машина имеет впечатляющую теоретическую пиковую скорость вычислений 4,3 Эопс на INT8 и не менее впечатляющие 537 Пфлопс на FP64. Это помогло занять её первое место в бенчмарке HPL-AI, которые использует вычисления разной точности. А общая архитектура процессора, включающего набортную память HBM2, и системы, использующей интерконнект Tofu, способствовали лидерству в бенчмарке HPCG, который оценивает эффективность машины в целом. 
09.06.2020 [19:49], Юрий Поздеев
Суперкомпьютер Neocortex: 800 тыс. ядер Cerebras для ИИПиттсбургский суперкомпьютерный центр (PSC) получит $5 млн от Национального научного фонда на создание суперкомпьютера нового типа Neocortex, который объединяет ИИ-серверы Cerebras CS-1 и HPE SuperDome Flex в единую систему с общей памятью. Планируется, что решение будет введено в эксплуатацию до конца 2020 года.  Каждый сервер Cerebras CS-1 имеет процессор Cerebras Wafer Scale Engine (WSE), который содержит 400 000 ядер, оптимизированных для работы с ИИ (46 225 мм2, 1,2 трлн транзисторов). В паре с ними работает HPE SuperDome Flex, который используется для предварительной обработки информации и постобработки после Cerebras. SuperDome Flex представлен в максимальной комплектации, то есть с 32 процессорами Intel Xeon, 24 Тбайт оперативной памяти, 205 Тбайт флеш-памяти и 24 интерфейсными картами.  Каждый сервер Cerebras CS-1 подключается к SuperDome Flex через 12 каналов со скоростью 100 Гбит/с каждый. Процессор WSE способен обрабатывать 9 Пбайт данных в секунду, что, по подсчетам Nystrom, эквивалентно примерно миллиону фильмов в HD-качестве. Характеристики решения действительно впечатляют! 
Neocortex назван в честь области мозга, отвечающей за функции высокого порядка, включая когнитивные способности, сновидения и формирование речи Архитектура решения строилась таким образом, чтобы не пришлось разбивать вычислительные блоки на множество узлов — это позволило снизить задержки в обработке информации и ускорить обучение моделей ИИ. Cerebras CS-1 разрабатывался специально для ИИ, поэтому он имеет преимущества перед серверами с графическими ускорителями, которые хорошо справляются с матричными операциями, но имеют многие конструктивные ограничения.  По заявлениям Neocortex, сервер CS-1 будет на несколько порядков мощнее системы PSC Bridges-AI. Один сервер Neocortex CS-1 будет эквивалентен примерно 800-1500 серверов с традиционной архитектурой с использованием графических ускорителей. Задачи, в которых Neocortex покажет себя максимально эффективно относятся к классу нейронных сетей DCIGN (deep convolutional inverse graphics networks) и RNN (recurrent neural networks). Если говорить простыми словами, то это более точное прогнозирование погоды, анализ геномов, поиск новых материалов и разработка новых лекарств.  PSC, помимо Neocortex, запускает еще и новое поколение системы Bridges-2, которое будет развернуто осенью 2020 года. Таким образом, до конца этого года будут введены в эксплуатацию два мощных суперкомпьютера для ИИ. Neocortex и Bridges-2 будут поддерживать самые популярные фреймворки машинного обучения, что позволит создать гибкую и мощную экосистему для ИИ, анализа данных, моделирования и симуляции. До 90% машинного времени Neocortex будет выделяться через XSEDE (Extreme Science and Engineering Discovery Environment), финансируемую NSF организацию, которая координирует совместное использование передовых цифровых услуг, включая суперкомпьютеры и ресурсы для визуализации и анализа данных, с исследователями на национальном уровне.
02.12.2019 [14:58], Алексей Степин
NEC обновила серию ускорителей SX-Aurora и опубликовала планы относительно HPCКомпания NEC не спешит отказываться от своего уникального пути на рынке супервычислений и продолжает развивать серию векторных процессоров SX-Aurora. На конференции SC19 компания представила ряд новых решений, сочетающих в себе SX-Aurora и новейшие процессоры AMD «Rome» Intel Xeon 9200. 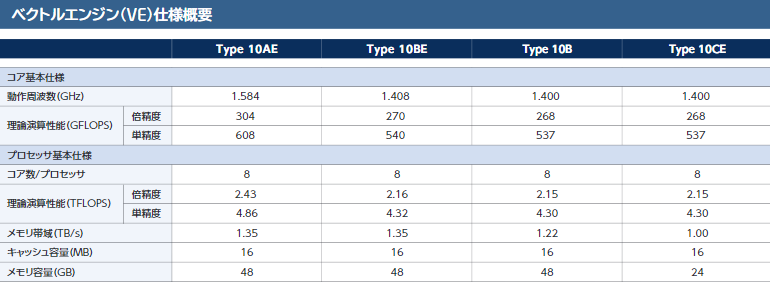
Типы ускорителей SX-Aurora Как и два года назад, основой платформы NEC является плата расширения «Type 10»; впрочем, в настоящее время производитель заменяет его на усовершенствованный «Type 10E» с более быстрыми сборками HBM2 на борту. За счёт этого ПСП удалось поднять на 10%, и даже в самом доступном варианте «Type 10CE» данный параметр теперь составляет 1 Тбайт/с против ранних 750 Гбайт/с. 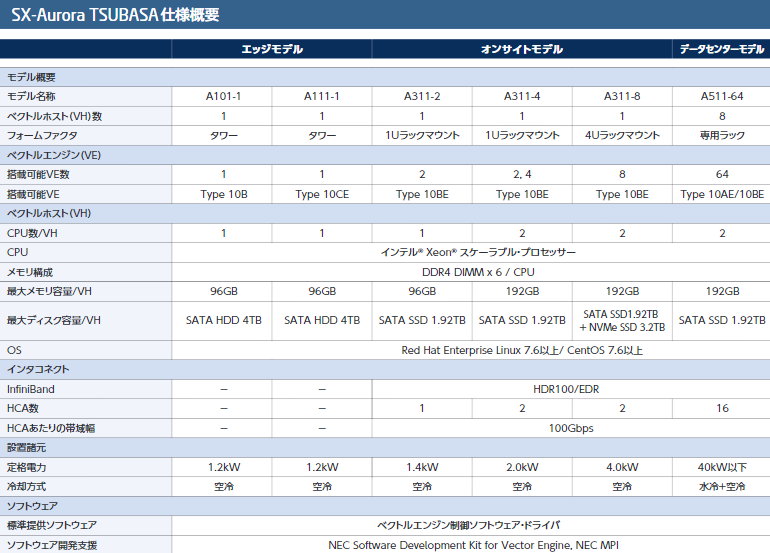
Системы NEC на базе SX-Aurora Массовый выпуск плат NEC «Type 10E» намечен на январь 2020 года. Всего в семействе будет четыре модели, отличающиеся тактовыми частотами, объёмом HBM2 и системой охлаждения. Последняя будет представлена в воздушном активном и пассивном вариантах, также будет выпускаться и вариант с жидкостным охлаждением. 
Сервер NEC A412-8 сочетает в себе SX-Aurora и AMD Rome Компания не собирается останавливаться на достигнутом и чип текущего поколения VE10 будет заменён на VE20 уже в середине или конце 2020 года. Он получит ещё более быструю память, больше векторных ядер (возможно 10 против 8 сегодняшних) и неизвестные пока новые функции. Следующее за ним поколение, VE30, должно появиться в 2022 году. Об этом поколении данных пока нет — известно лишь, что эти процессоры будут иметь новую архитектуру. 
30.09.2019 [11:00], Андрей Созинов
Конец эпохи? Oracle сворачивает SPARC-бизнес и инвестирует в ARMКомпания Oracle объявила, что инвестировала $40 млн в компанию Ampere Computing, которая занимается разработкой 64-разрядных ARM-процессоров серверного класса. Похоже, компания потеряла интерес к SPARC, доставшейся ей при покупке Sun, так что эпоха этой архитектуры подходит к концу.  Инвестиции были произведены ещё в апреле текущего года. За сумму в примерно 40 млн долларов было приобретено около 20 % акций Ampere Computing, за счёт чего Oracle получила одно из кресел в совете директоров. Кроме того, самой Ampere управляет Рене Джеймс (Renée James), которая также занимает место в совете директоров Oracle. Помимо инвестиций Oracle заплатила Ampere около $419 000 за разработку и тестирование оборудования в 2019 финансовом году. Интересно, что сама компания об инвестициях Oracle не сообщала, отметив лишь финансирование со стороны ARM Holdings и Carlyle Group. Ampere специализируется на разработке процессоров для облачных систем и серверов, которые сочетают высокую производительность и энергоэффективность.  В то же время Oracle всё меньше внимания уделяет собственной архитектуре SPARC и разработке процессоров на её основе. Заявлений об отказе от этой архитектуры пока что не последовало. Однако в отчёте за 2019 финансовый год Сафра Кац (Safra Catz), один из генеральных директоров Oracle, заявила: «Наши высокодоходные облачные решения Fusion и NetSuite быстро растут, и мы сокращаем свой низкорентабельный бизнес устаревшего [legacy] аппаратного обеспечения». 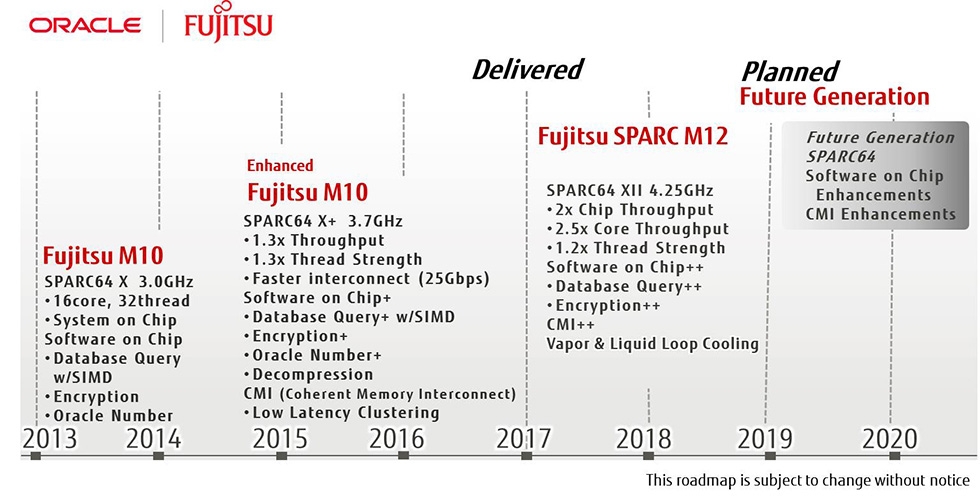 В последний раз обе компании обновляли свои SPARC-процессоры в 2017 году. После выхода M8 Oracle фактически разогнала отдел, занимавшийся разработкой CPU. Fujitsu же после выпуска SPARC64 XII говорила о намерениях выпустить следующее поколение SPARC64 в 2020 году. Формально Fujitsu остаётся последним разработчиком высокопроизводительных SPARC-процессоров серверного уровня, но у компании наверняка немало ресурсов уходит на суперкомпьютер Post-K и ARM-процессор A64FX. И несмотря на то, что лицензиями на SPARC обладает довольно много компаний, среди которых есть и отечественные разработчики, вряд ли хоть кто-то из них будет вкладываться в серьёзное развитие архитектуры.  Наконец, хотелось бы отметить, что и операционная система Solaris 11, возможно, станет последней ОС от Oracle для платформы SPARC. Первый релиз вышел 8 лет назад, и хотя Oracle постепенно вносит в неё некоторые улучшения, признаки разработки Solaris 12 отсутствуют. А на днях компания заявила, что обеспечит стандартную поддержку системы Solaris 11 до 2031 года и расширенную поддержку до 2034 года. Таким образом, Oracle исполнит свои долгосрочные обязательства по обновлению Solaris. Однако будет крайне удивительно, если мы когда-либо увидим Solaris 12.
22.09.2019 [21:27], Андрей Созинов
3 ядра, 2 гига: Aspeed выпустила BMC AST2600Компания Aspeed официально представила новый BMC под названием AST2600, который придёт на смену актуальному контроллеру AST2500. Новинка найдёт применение в серверах следующего поколения, которые появятся в 2020 году.  Предварительные данные о харакеристиках новинки, про которые мы уже писали, подтвердились. В основе 28-нм SoC Aspeed AST2600 лежат три ядра с архитектурой ARM: два основных Cortex A7 и одно вспомогательное Cortex M3. Контроллер позволяет использовать до 2 Гбайт RAM DDR4. 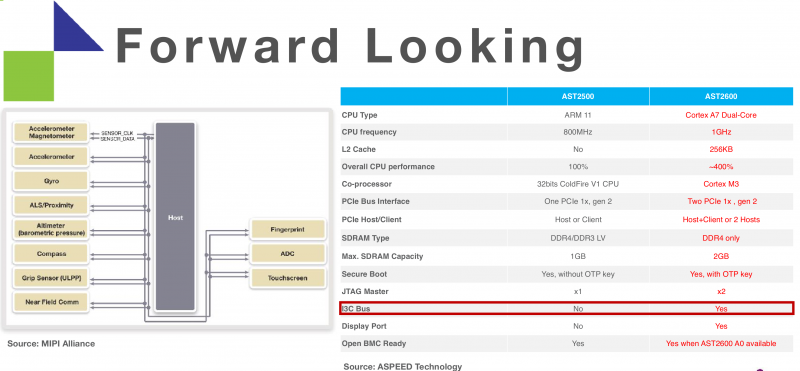 BMC поддерживает технологии TrustZone и Secure Boot, которые призваны повысить безопасность. Также он обладает поддержкой до четырёх гигабитных сетевых интерфейсов. Обычно, правда, используется не более одного интерфейса, который нужен для подключения к BMC. Однако дополнительные сетевые порты можно использовать, например, для мониторинга и других задач. 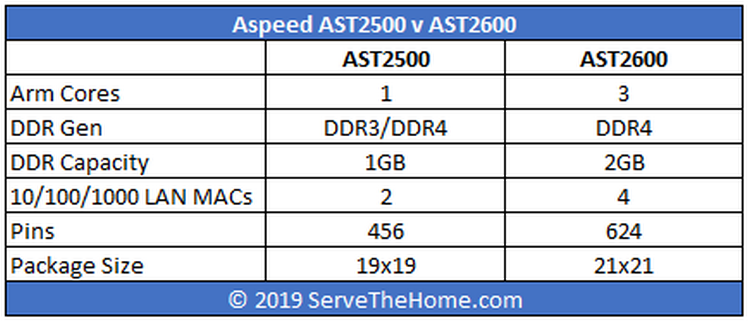 Дополнительные возможности отразились на числе контактов — их теперь 624, что на 37 % больше по сравнению с предшественником — и, что важнее, на площади чипа, которая увеличилась до 441 мм 2. Соответственно, на материнской плате придётся отводить под BMC больше места. |
|

