Материалы по тегу: b200
|
08.08.2024 [00:48], Сергей Карасёв
NVIDIA задержит выпуск ускорителей GB200, отложит B100/B200, а на замену предложит B200AКомпания NVIDIA, по сообщению ресурса The Information, вынуждена повременить с началом массового выпуска ИИ-ускорителей следующего поколения на архитектуре Blackwell, сохранив высокие темпы производства Hopper. Проблема, как утверждается, связана с технологией упаковки Chip on Wafer on Substrate (CoWoS) от TSMC. Отмечается, что NVIDIA недавно проинформировала Microsoft о задержках, затрагивающих наиболее продвинутые решения семейства Blackwell. Речь, в частности, идёт об изделиях Blackwell B200. Серийное производство этих ускорителей может быть отложено как минимум на три месяца — в лучшем случае до I квартала 2025 года. Это может повлиять на планы Microsoft, Meta✴ и других операторов дата-центров по расширению мощностей для задач ИИ и НРС. По данным исследовательской фирмы SemiAnalysis, задержка связана с физическим дизайном изделий Blackwell. Это первые массовые ускорители, в которых используется технология упаковки TSMC CoWoS-L. Это сложная и высокоточная методика, предусматривающая применение органического интерпозера — лимит возможностей технологии предыдущего поколения CoWoS-S был достигнут в AMD Instinct MI300X. Кремниевый интерпорзер, подходящий для B200, оказался бы слишком хрупок. Однако органический интерпозер имеет не лучшие электрические характеристики, поэтому для связи используются кремниевые мостики. В используемых материалах как раз и кроется основная проблема — из-за разности коэффициента теплового расширения различных компонентов появляются изгибы, которые разрушают контакты и сами чиплеты. При этом точность и аккуратность соединений крайне важна для работы внутреннего интерконнекта NV-HBI, который объединяет два вычислительных тайла на скорости 10 Тбайт/с. Поэтому сейчас NVIDIA с TSMC заняты переработкой мостиков и, по слухам, нескольких слоёв металлизации самих тайлов.  Вместе с тем у TSMC наблюдается нехватка мощностей по упаковке CoWoS. Компания в течение последних двух лет наращивала мощности CoWoS-S, в основном для удовлетворения потребностей NVIDIA, но теперь последняя переводит свои продукты на CoWoS-L. Поэтому TSMC строит фабрику AP6 под новую технологию упаковки, а также переведёт уже имеющиеся мощности AP3 на CoWoS-L. При этом конкуренты TSMC не могут и вряд ли смогут в ближайшее время предоставить хоть какую-то альтернативную технологию упаковки, которая подойдёт NVIDIA. Таким образом, как сообщается, NVIDIA предстоит определиться с тем, как использовать доступные производственные мощности TSMC. По мнению SemiAnalysis, компания почти полностью сосредоточена на стоечных суперускорителях GB200 NVL36/72, которые достанутся гиперскейлерам и небольшому числу других игроков, тогда как HGX-решения B100 и B200 «сейчас фактически отменяются», хотя малые партии последних всё же должны попасть на рынок. Однако у NVIDIA есть и запасной план. План заключается в выпуске упрощённых монолитных чипов B200A на базе одного кристалла B102, который также станет основой для ускорителя B20, ориентированного на Китай. B200A получит всего четыре стека HBM3e (144 Гбайт, 4 Тбайт/с), а его TDP составит 700 или 1000 Вт. Важным преимуществом в данном случае является возможность использования упаковки CoWoS-S. Чипы B200A как раз и попадут в массовые HGX-системы вместо изначально планировавшихся B100/B200.  На смену B200A придут B200A Ultra, у которых производительность повысится, но вот апгрейда памяти не будет. Они тоже попадут в HGX-платформы, но главное не это. На их основе NVIDIA предложит компромиссные суперускорители MGX GB200A Ultra NVL36. Они получат восемь 2U-узлов, в каждом из которых будет по одному процессору Grace и четыре 700-Вт B200A Ultra. Ускорители по-прежнему будут полноценно объединены шиной NVLink5 (одночиповые 1U-коммутаторы), но вот внутри узла всё общение с CPU будет завязано на PCIe-коммутаторы в двух адаптерах ConnectX-8. Главным преимуществом GX GB200A Ultra NVL36 станет воздушное охлаждение из-за относительно невысокой мощности — всего 40 кВт на стойку. Это немало, но всё равно позволит разместить новинки во многих ЦОД без их кардинального переоборудования пусть и ценой потери плотности размещения (например, пропуская ряды). По мнению SemiAnalysis, эти суперускорители в случае нехватки «полноценных» GB200 NVL72/36 будут покупать и гиперскейлеры.
22.07.2024 [15:57], Руслан Авдеев
Поставки суперускорителей с чипами NVIDIA GB200 могут задержаться из-за протечек СЖОNVIDIA уже готовилась начать продажи систем на базе новейших ИИ-суперускорителей GB200, однако столкнулась с непредвиденной проблемой — TweakTown сообщает, что в системах жидкостного охлаждения этих серверов начали появляться протечки. Судя по всему, серверы на основе GB200 использовали дефектные компоненты систем СЖО охлаждения, поставляемые сторонними производителями: разветвители, быстросъёмные соединители и шланги. Некорректная работа любого из этих компонентов может привести к утечке охлаждающей жидкости. В случае с моделью GB200 NVL72 стоимостью в $3 млн это может перерасти в большую проблему. К счастью, нарушения в работе новых систем NVIDIA GB200 NVL36 и NVL72 обнаружили до начала массового производства в преддверии запуска поставок ключевым покупателям ИИ-решений. Предполагается, что на сроках поставок проблема не скажется, поскольку её успеют устранить. Впрочем, по данным источников, теперь крупные провайдеры облачных сервисов «нервничают». 
Источник изображения: NVIDIA NVIDIA предлагают свою продукцию всё больше тайваньских производителей, способных заменить бракованные компоненты для серверных систем с GB200. Однако сертификация компонентов — процесс довольно сложный, поскольку многие тайваньские компании не специализировались на их выпуске ещё в недавнем прошлом. Тем не менее, когда NVIDIA объявила, что ускорители следующего поколения получат жидкостное охлаждение, многие производители решили попробовать себя в этой сфере. Тайваньские Shuanghong и Qihong уже имеют хороший опыт в выпуске водоблоков, а теперь расширили спектр разрабатываемых товаров, предлагая разветвители, быстросъемные соединители и шланги. Именно эти компании по некоторым данным сейчас предоставляют необходимые комплектующие для замены бракованных в новых суперускорителях NVIDIA GB200 NVL36 и NVL72. Лидером на рынке серверных СЖО остаётся CoolIT, но её услугами NVIDIA, видимо, решила не пользоваться.
22.07.2024 [12:51], Руслан Авдеев
NVIDIA готовит урезанную версию флагманского ИИ-чипа Blackwell для КитаяNVIDIA работает над новым вариантом представленного весной флагманского ИИ-ускорителя серии Blackwell — теперь для китайского рынка, находящегося под давлением американских санкций. По данным Reuters, вендор работает над тем, чтобы привести оборудование в соответствие с техническими требованиями властей США к поставляемым в Китай полупроводникам. Серию Blackwell компания представила в марте 2024 года. Массовое производство планируется позже в текущем году. Выпускаемый в рамках нового семейства ускоритель B200 до 30 раз производительнее своего предшественника при выполнении некоторых задач. Над выпуском и поставками упрощённого для Китая чипа B20 вендор будет работать совместно с одним из своих крупнейших дистрибьюторов в Китае — компанией Inspur. Источники Reuters пожелали остаться неизвестными, в самой NVIDIA новость пока не комментируют, предпочитают молчать и в Inspur. 
Источник изображения: NVIDIA Вашингтон в очередной раз ужесточил контроль над поставками передовых чипов в Китай в 2023 году, пытаясь предотвратить развитие в Поднебесной собственных суперкомпьютеров. С тех пор NVIDIA разработала три чипа, специально оптимизированных для китайского рынка. Примечательно, что американские санкции помогли компаниям вроде китайского техногиганта Huawei и стартапам вроде Enflame добиться некоторых успехов на китайском рынке ИИ-ускорителей. Появление версии чипа серии Blackwell для Китая, вероятно, поможет NVIDIA избавиться от конкуренции на одном из ключевых рынков. Из-за санкций США за год, закончившийся в январе, выручка NVIDIA в Китае составила 17 % от общемировой, для сравнения, двумя годами ранее на страну приходилось 26 % всех продаж компании. Изначально предназначенный для Китая чип H20, продажи которого начались в этом году, раскупался довольно слабо, поэтому вендору пришлось снизить цену, чтобы сделать его дешевле конкурирующего решения Huawei. Теперь, по данным источников, продажи растут быстрыми темпами. По оценкам экспертов SemiAnalysis, в этом году NVIDIA намерена продать в Китае более 1 млн чипов H20 на сумму свыше $12 млрд. При этом высока вероятность, что американские власти и дальше продолжат ужесточать экспортный контроль, ограничивая поставки передовых ускорителей в КНР. Более того, США хотят, чтобы Нидерланды и Япония всё активнее включались в санкционный процесс, ограничивая с Китаем сотрудничество в области оборудования для производства полупроводников. Также, как сообщают источники, имеются предварительные планы ограничить доступ к наиболее передовым ИИ-моделям. Акции полупроводниковых компаний упали на прошлой неделе на фоне новостей о том, что США оценивают целесообразность введения правила, позволяющего просто запрещать продажи продуктов, выпущенных с помощью американских технологий. UPD: Inspur отрицает совместную работу с NVIDIA над ускорителями B20.
17.07.2024 [23:33], Игорь Осколков
Суперускоритель по суперцене — NVIDIA GB200 NVL72, вероятно, будет стоить $3 млнКомпания NVIDIA значительно увеличила заказ на ускорители Blackwell у TSMC, сообщает TrendForce со ссылкой на United Daily News (UDN). По данным источника, NVIDIA намерена получить уже не 40 тыс., а 60 тыс. суперускорителей нового поколения, причём 50 тыс. из них придётся на стоечные системы GB200 NVL36. При этом Blackwell всё равно будут в дефиците, как и обещал ещё зимой глава NVIDIA Дженсен Хуанг (Jensen Huang). B200 включает два тайла, объединённых 2,5D-упаковкой CoWoS-L и соединённых интерконнектом NV-HBI. Чип имеет 208 млрд транзисторов, изготовленных по кастомному техпроцессу TSMC 4NP. GB200 объединяет два ускорителя B200 и один 72-ядерный Arm-процессор Grace. А суперускоритель GB200 NVL72, в свою очередь, объединяет в рамках одной стойки Oberon сразу 18 1U-узлов с парой GB200 в каждом (плата Bianca, 72 × B200 и 36 × Grace), провязанных шиной NVLink 5. Вся эта система потребляет порядка 120 кВт, оснащена СЖО и единой DC-шиной питания. Однако у GB200 NVL72 довольно специфические требования к окружению, поэтому NVIDIA предлагает суперускоритель попроще — GB200 NVL36, который как раз и должен стать наиболее массовым в данной серии. Эта платформа точно так же занимает целую стойку, но использует 2U-узлы с теми же платами Bianca (суммарно 36 × B200 и 18 × Grace), потребляя всего 66 кВт. При этом всё равно подразумевается использование двух стоек GB200 NVL36, объединённых интерконнектом, так что GB200 NVL72 всё равно получается более энергоэффективным решением. 
NVIDIA GB200 Как отмечает SemiAnalysis, GB200 NVL36 также будет доступен в варианте с платами Ariel, имеющими по одному чипу B200 и Grace. Наконец, во II квартале 2025 года появятся системы B200 NVL72 и B200 NVL36 с x86-процессорами (Miranda). Кроме того, NVIDIA представила и отдельные MGX-узлы GB200 NVL2 с парой GB200. В общем, ускорителей B200 компании понадобится много, чтобы наверняка удержать лидерство на рынке. 
Источник изображения: NVIDIA По словам UDN, GB200 NVL36 будет стоить порядка $1,8 млн, а GB200 NVL72 обойдётся уже в $3 млн. Одиночный GB200 будет стоить $60–$70 тыс., а самый простой ускоритель B100 оценён в $30–$35 тыс. Нужно подчеркнуть, что это оценки сторонних аналитиков. Сама компания официально не раскрывает стоимость своих продуктов. Это устоявшаяся практика на данном рынке, против которой пошла только Intel, публично назвавшая стоимость ИИ-ускорителей Gaudi. Впрочем, ранее глава NVIDIA намекнул, что B200 будет стоить приблизительно $30–$40 тыс.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 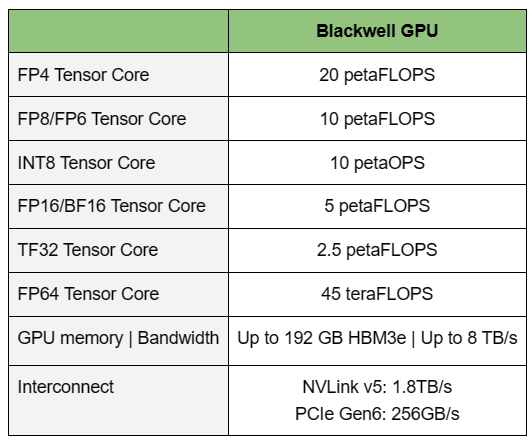 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений.  Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 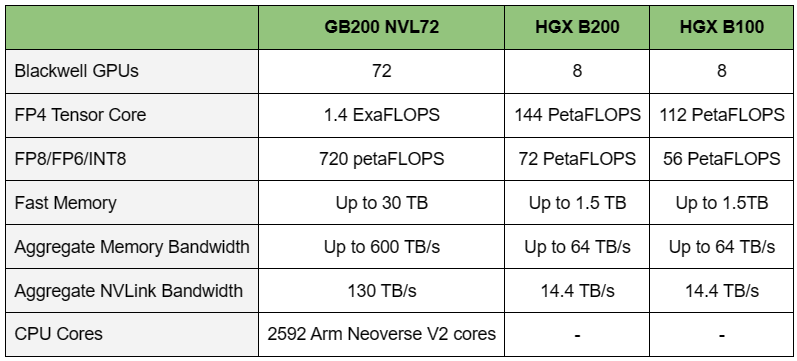 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку (Oberon), оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle. |
|

