Материалы по тегу: оркестрация
|
20.05.2026 [09:09], Владимир Мироненко
От теории к практике ИИ: Dell анонсировала масштабное обновление платформы AI Factory with NVIDIA
dell
nvidia
software
ии
конфиденциальность
оркестрация
охлаждение
рабочая станция
сервер
схд
частное облако
Компания Dell Technologies объявила о масштабном обновлении платформы AI Factory with NVIDIA, призванном помочь предприятиям перейти от планирования к практическому применению ИИ. Платформа отличается модульной архитектурой данных для ИИ, где их преобразование, обработка и хранение работают вместе как специально разработанный стек. Компания отметила, что AI Factory используют более 5 тыс. клиентов по всему миру, и обновлённая версия платформы обеспечит более интегрированный подход к управлению данными и инфраструктурой, что позволит сократить время, необходимое для развёртывания решений ИИ. Одним из ключевых анонсов мероприятия стала презентация Dell Deskside Agentic AI. Это новое предложение, которое объединяет рабочие станции Dell, эталонный программный стек NemoClaw от NVIDIA и среду выполнения OpenShell, позволяя предприятиям создавать, запускать и управлять автономными агентами на системах, хранящих данные локально или на периферии сети, а не полагаться исключительно на облачную инфраструктуру. Dell позиционирует это предложение как решение для контроля затрат, снижения задержки и суверенитета данных, особенно для разработки ПО, исследований и регулируемых сред. Локальный подход разработан для таких секторов, как разработка ПО, академические исследования и регулируемые отрасли, позволяя этим группам хранить данные внутри компании и преобразовывать переменные расходы на облачные сервисы в предсказуемые инвестиции в инфраструктуру. Dell заявила, что этот подход позволит достичь паритета затрат с публичными облаками в течение трёх месяцев. 
Источник изображений: Dell Dell также интегрирует NVIDIA OpenShell во все продукты портфеля Dell AI Factory, чтобы обеспечить «безопасную песочницу для запуска, создания, тестирования и тонкой настройки агентов» локально. Это обеспечивает Dell единый уровень среды выполнения и политик, охватывающий все уровни — от настольных рабочих станций до серверов Dell PowerEdge XE, с поддержкой Ubuntu и Red Hat AI. Dell также продвигает эталонную архитектуру Dell-NVIDIA AI-Q 2.0, работающую на базе Dell AI Data Platform with NVIDIA, как готовую к продуктовому развёртыванию основу для многоагентных рабочих процессов в таких секторах, как финансовые услуги, производство и госсектор, где требуется более жёсткий контроль над данными и операциями. Dell объявила о ряде улучшений платформы Dell AI Data Platform. В ней были расширены возможности механизма оркестрации данных Dell AI Data Platform путём глубокой интеграции MetadataIQ со всем портфелем хранилищ Dell, начиная с PowerScale — файлового механизма в рамках Dell AI Data Platform with NVIDIA — и расширяя его на другие платформы в будущем. 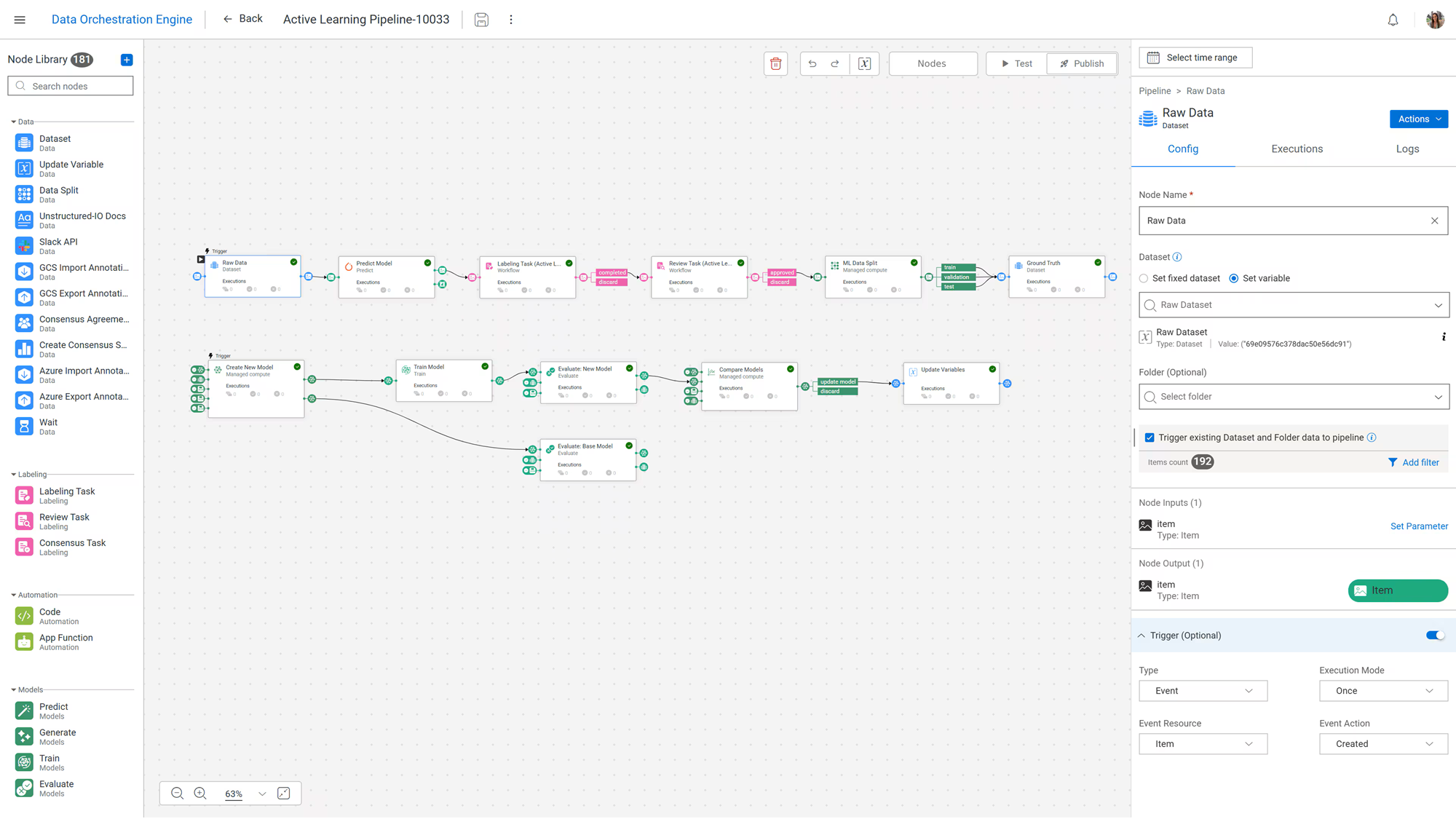 Уровень оркестрации теперь поддерживает индексирование миллиардов неструктурированных файлов и их привязку к управляемым конвейерам обработки данных. Благодаря партнёрству со Starburst и NVIDIA платформа предлагает аналитику SQL с ускорением на GPU через улучшенный Dell Data Analytics Engine, до шести раз быстрее на оборудовании NVIDIA Blackwell и с будущей поддержкой NVIDIA Vera. Это позволяет ускорить получение данных как для традиционной аналитики, так и для ресурсоёмких приложений ИИ с использованием агентов. Возможности хранения данных были расширены с помощью новой системы ObjectScale X7700, которая обеспечивает на 45 % большую ёмкость, чем предыдущее поколение, с гибким масштабированием вычислительных ресурсов и хранилища. В будущем появится поддержка флеш-накопителей объёмом 245 Тбайт, что более чем втрое увеличит плотность хранения. Благодаря интеграции с NVIDIA Omniverse корпоративные хранилища данных могут быть напрямую связаны с цифровыми двойниками и физическими рабочими процессами ИИ.  По мере роста объёма данных для ИИ, объектное хранилище становится логичным местом для обучающих данных, контрольных точек и долгосрочных баз знаний. Dell ObjectScale — объектный движок в рамках Dell AI Data Platform с NVIDIA — создан для выполнения этой роли, обладая высокопроизводительной архитектурой облачного масштаба и, по словам компании, лучшей в отрасли киберустойчивостью. Dell ObjectScale на серверах PowerEdge R7725xd также получил сертификацию NVIDIA Foundation, что означает его пригодность для высокоскоростного доступа к данным в средах с большим количеством GPU. Dell также расширила перечень инфраструктурных решений, запустив PowerRack, готовую систему стоечного масштаба, которая объединяет вычислительные ресурсы, сети, хранилище данных, охлаждение и управление в предварительно спроектированные блоки для развёртывания систем ИИ и HPC. Сообщается, что система может быть полностью настроена и введена в эксплуатацию в течение 6,5 ч. после доставки.  Как отметил ресурс Techzine, это не новая концепция, поскольку Dell поставляла комплексные решения и раньше, но компания расширяет возможности PowerRack по трём направлениям. Сетевой вариант обеспечивает коммутационную способность 800 Тбит/с благодаря восьми новым коммутаторам PowerSwitch SN6600 на стойку. Это в первую очередь предназначено для так называемого трафика east-west, поддерживающего рабочие нагрузки ИИ-инференса. Dell также интегрирует PowerFlex (решение «4-в-1») в свою архитектуру хранения данных Exascale, обеспечивая поддержку блочного, файлового и объектного хранения в стоечном исполнении через PowerFlex, PowerScale, Lightning File System и ObjectScale для нагрузок ИИ, HPC и ресурсоёмких корпоративных рабочих нагрузок. Dell также представила Pro Precision 7 R1 — стоечную рабочую станцию высотой 1U с ускорителями NVIDIA RTX PRO Blackwell Max-Q Workstation Edition и объёмом хранилища до 64 Тбайт. Обновлённые версии Dell Integrated Rack Controller и OpenManage Enterprise расширяют возможности на уровне стойки. В то же время новый PowerCool CDU C7000 разработан для отвода тепла от платформ NVIDIA следующего поколения в компактном стоечном форм-факторе. Это первый CDU для установки в стойку, отвечающий потребностям в охлаждении платформы NVIDIA Vera Rubin NVL72 в компактном форм-факторе 4U (19″) и расширяющий возможности охлаждения Dell и поддержку использования горячей воды с температурой до +40 °C.  Сообщается, что Dell PowerRack для вычислительных систем уже доступна, PowerRack для сетей будет доступна в сентябре 2026 года, а для хранилищ — во II половине 2026 года. Также уже доступны решение Dell Deskside Agentic AI, поддержка NVIDIA OpenShell, NVIDIA AI-Q 2.0 для Dell AI Factory и эталонная архитектура Dell-NVIDIA AI-Q 2.0. В свою очередь, Dell Pro Precision 7 R1 будет доступна в июле 2026 года, Data Orchestration Engine с MetadataIQ — во II квартале 2026 года, CDU — в III квартале 2026 года, а Data Analytics Engine with Starburst — в I квартале 2027 года.
18.05.2026 [20:00], Руслан Авдеев
NVIDIA представила платформу Fleet Intelligence для мониторинга парка ИИ-ускорителей
dcim
nvidia
software
ии
информационная безопасность
кластер
конфиденциальность
мониторинг
облако
оркестрация
телеметрия
цод
NVIDIA представила управляемую платформу Fleet Intelligence, предназначенную для мониторинга состояния крупных кластеров ускорителей, используемых в ИИ-инфраструктуре. Сервис уже доступен бесплатно для клиентов, использующих продукты NVIDIA на основе ускорителей семейств Hopper, Blackwell и Vera Rubin. NVIDIA позиционирует платформу как независимый слой телеметрии и мониторинга, позволяющий отслеживать работу с гетерогенными инфраструктурными средами, независимо от стека оркестрации или планировщика задач. Платформа применяет «лёгкий», интегрируемый в хост-систему агент, который передаёт телеметрию с ИИ-ускорителей в облачную службу Fleet Intelligence, работающую в экосистеме платформы NGC (NVIDIA GPU Cloud). Агент применяет несколько технологий NVIDIA, включая службу мониторинга ускорителей — GPUd, инструмент управления и диагностики чипов DCGM (NVIDIA Data Center GPU Manager) и средства проверки целостности оборудования и ПО NVIDIA Attestation SDK. Компания также выложила код агента Fleet Intelligence на GitHub, что позволит операторам ИИ-инфраструктуры самостоятельно оценить механизмы телеметрии. Fleet Intelligence ведёт сбор данных о степени загруженности ускорителей, пропускной способности памяти, энергопотреблении системы, состоянии интерконнектов NVLink, температуре системы, ошибках ECC, а также показателях состояния аппаратной составляющей. Это помогает операторам ЦОД организовать раннее выявление недоиспользованных ресурсов и ошибок и снизить простои крупных ИИ-кластеров. 
Источник изображений: NVIDIA Одними из основных свойств платформы стали возможности проверки целостности и аттестации на основе технологий защищённых вычислений NVIDIA Confidential Computing. Fleet Intelligence проводит криптографическую валидацию прошивок ИИ-ускорителей и целостность среды выполнения с помощью корневых сертификатов доверия NVIDIA, а также сервиса удалённой проверки оборудования NRAS (NVIDIA Remote Attestation Service). Платформа может подтвердить, что ускорители используют утверждённую прошивку и использует манифесты целостности Reference Integrity Manifests, привязанные к определённым версиям vBIOS. 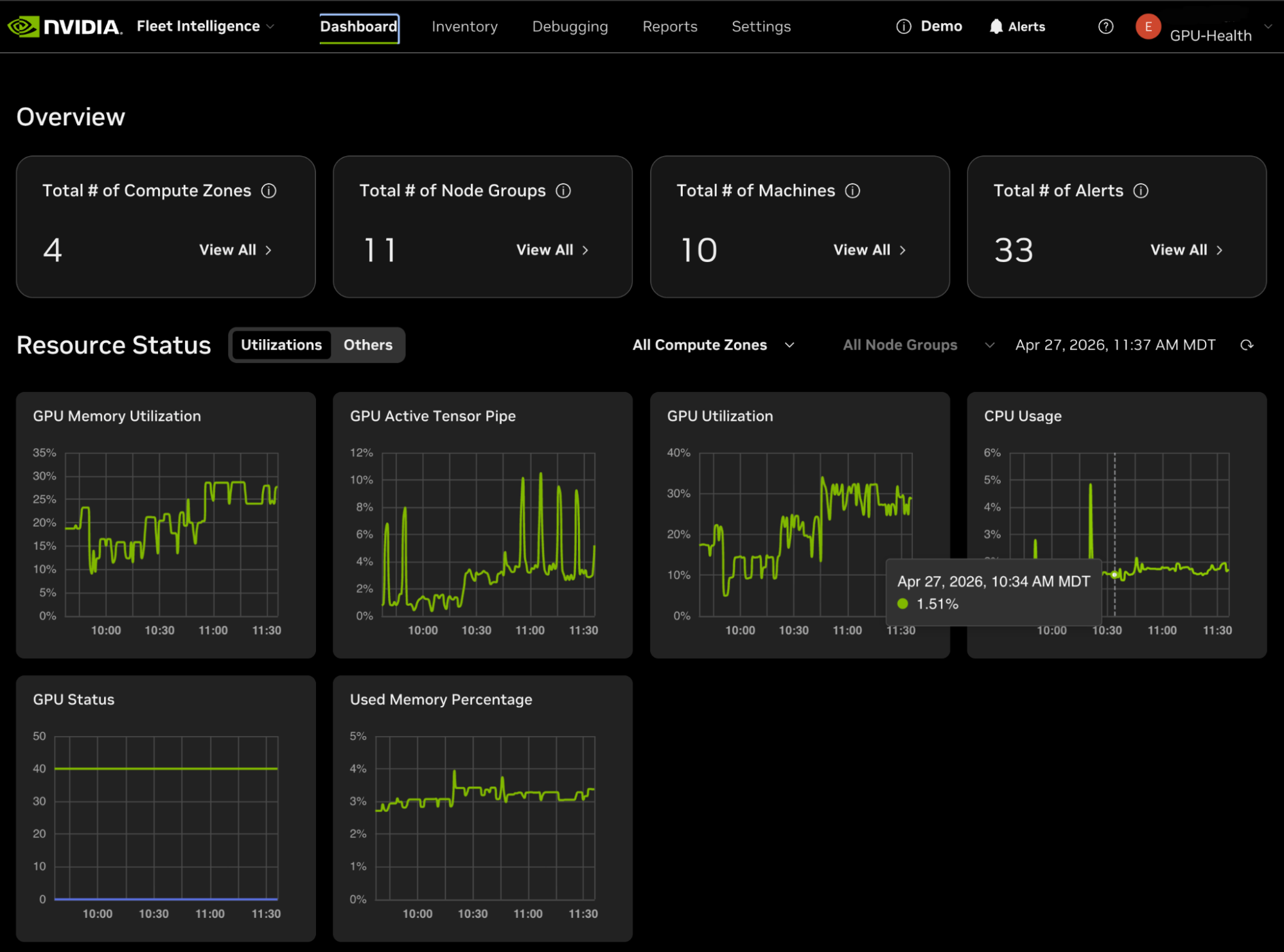 По словам NVIDIA, при разработке Fleet Intelligence применяли опыт эксплуатации облачных платформ NVIDIA DGX Cloud, использовавших сотни тысяч ИИ-ускорителей. В числе корпоративных пользователей, получивших ранний доступ к платформе — Lambda и Iren, обе предоставляли обратную связь в ходе работ. Премьера Fleet Intelligence свидетельствует, что амбиции NVIDIA простираются далеко за пределы простой разработки ИИ-ускорителей, компания развивает ПО и инструменты управления для ИИ-фабрик. Это дополнение уже имеющегося стека компании, включающего системы DGX, интерконнекты NVLink, сетевые продукты Spectrum-X, платформу оркестрации Mission Control и решения для защищённых вычислений. 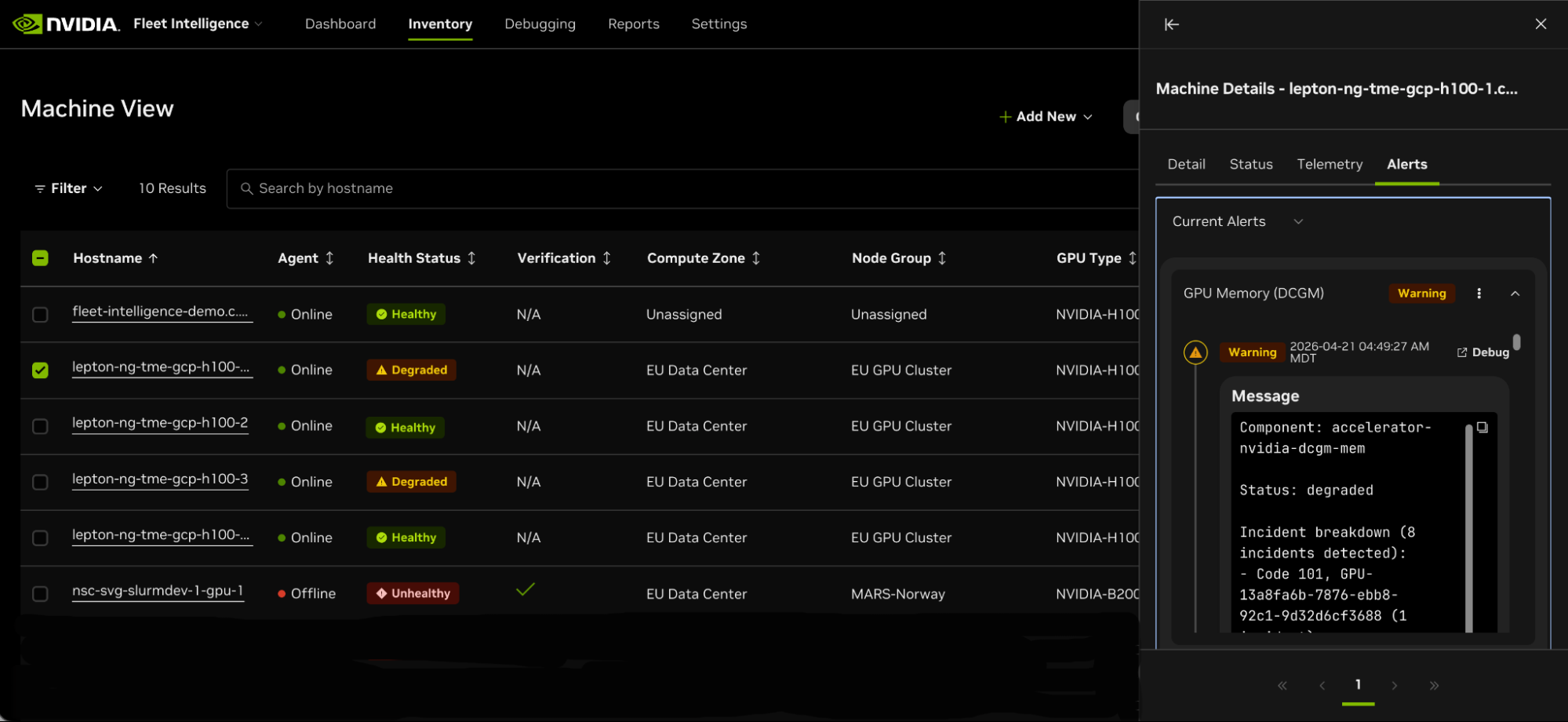 Добавление масштабной телеметрии и предиктивной аналитики отражает растущий спрос гиперскейлеров и корпоративных клиентов на максимальное использование ресурсов ускорителей. Кроме того, премьера платформы является отражением роста конкуренции на рынке систем мониторинга и эксплуатации ИИ-инфраструктуры. Облачные операторы и другие компании, включая AMD, Intel и т.п., строят собственные платформы для телеметрии, диагностики и управления крупными ИИ-кластерами. Возможность NVIDIA интегрировать аппаратную телеметрию, проверку надёжности прошивок и операционную аналитику напрямую в инфраструктурный стек усиливает позиции компании в роли вертикально интегрированного поставщика ИИ-инфраструктуры.
14.05.2026 [09:00], Сергей Карасёв
Basis Dynamix Cloud Control 5.5: новые безопасные инструменты для организации облачной инфраструктуры и хранения данныхКомпания «Базис», лидер российского рынка ПО управления динамической инфраструктурой, представила релиз 5.5 платформы для управления частными, публичными и гибридными облаками Basis Dynamix Cloud Control. В новой версии реализована интеграция со средством защиты виртуализации Basis Virtual Security, представлена гибкая ролевая модель, расширены возможности управления виртуальными центрами обработки данных и сетевой функциональностью. Basis Dynamix Cloud Control — облачное решение, позволяющее заказчику управлять различными платформами виртуализации — в том числе расположенными в разных ЦОДах — через единый графический интерфейс. Продукт обеспечивает создание и администрирование виртуальных центров обработки данных (ВЦОД), развёртывание платформенных сервисов, предбиллинг и разграничение доступа. Поддерживаются сегменты на базе Basis Dynamix Enterprise, Basis Dynamix Standard, VMware vSphere. Новые инструменты для управления виртуальным ЦОДВ обновлённом Basis Dynamix Cloud Control были существенно расширены возможности управления жизненным циклом виртуального ЦОД. В частности, для упрощения администрирования решение может при удалении одного дата-центра автоматически удалять и все связанные с ним компоненты — серверы, сети, порты, роутеры и диски. Для защиты от случайного удаления реализован механизм специального тега, при наличии которого операция блокируется. В релизе 5.5 жизненный цикл дополняется возможностью переносить виртуальный центр обработки данных между проектами, доступными администратору заказчика, в том числе между проектами разных клиентов. Новая возможность упрощает реорганизацию облачной инфраструктуры и администрирование мультитенантных сред. Также было снято ограничение на развёртывание платформенных сервисов (PaaS) — теперь можно запускать параллельно несколько таких сервисов в рамках одного ВЦОД. Это сокращает время подготовки комплексных виртуальных окружений, включающих несколько сервисов. Централизованное управление правами и доступомВ новом Basis Dynamix Cloud Control 5.5 была реализована интеграция с решением защиты Basis Virtual Security. Basis Virtual Security используется в качестве единого провайдера идентификации, оно обеспечивает поддержку технологии единого входа (Single Sign-On, SSO) и даёт администраторам возможность управлять учётными записями и правами доступа пользователей «из одного окна». Централизованное управление снижает нагрузку на администраторов, а пользователей платформы избавляет от необходимости вводить учётные данные при переходе между компонентами экосистемы «Базиса». 
Источник изображений: «Базис» Дополнительное удобство обеспечивает гибкая ролевая модель, с помощью которой администратор может тонко настраивать права доступа пользователей — собирать собственные роли из атомарных разрешений и назначать их в нужном объёме конкретным пользователям. Усовершенствованные политики хранения данных и поддержка внутренних сетейВ новой версии Basis Dynamix Cloud Control реализована поддержка политик хранения данных, используемых в Basis Dynamix Enterprise. Политики позволяют распределять нагрузку между пулами СХД в зависимости от их загруженности, что обеспечивает более равномерное использование ресурсов хранения и упрощает эксплуатацию крупных инсталляций с несколькими пулами. При создании сервера из пользовательского образа в сегментах Basis Dynamix Enterprise теперь можно выбрать профиль хранения индивидуально для каждого диска — как системного, так и дополнительных. Это даёт возможность распределять диски одного сервера по разным типам хранилищ в зависимости от требований к производительности и стоимости. В сегменте Basis Dynamix Enterprise также появилась возможность создавать образы дополнительных дисков: при создании образа сервера сохраняются данные не только на системном, но и на подключенных дисках. 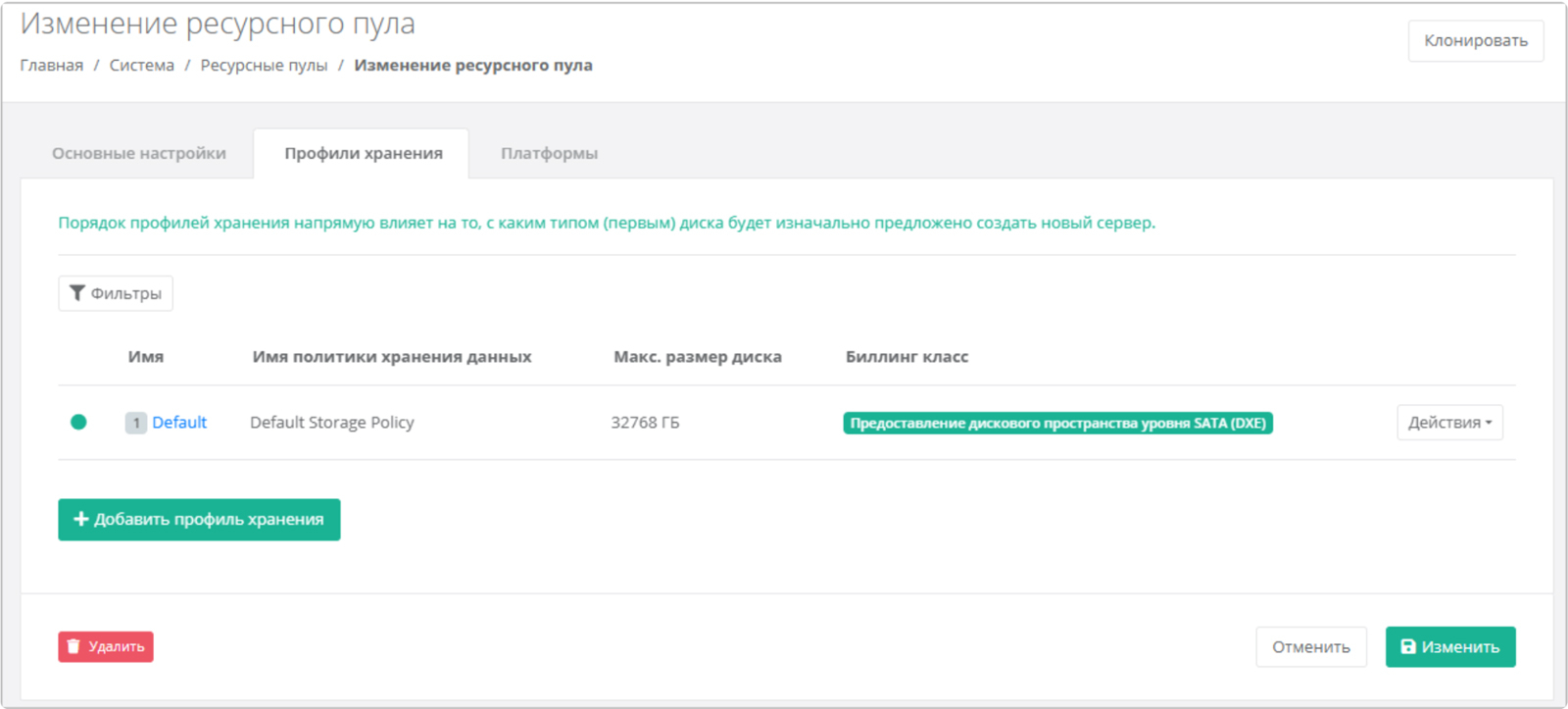 Для ресурсных пулов Basis Dynamix Standard было реализовано полноценное управление сетями и роутерами — аналогично другим сегментам оркестратора. В разделе управления сетевыми подключениями добавлены фильтры по восьми параметрам: типу устройства, серверу, роутеру, балансировщику, кластеру Kubernetes, IP-адресу, признаку служебного подключения и тегам. Это упрощает администрирование комплексной инфраструктуры, состоящей из большого количества физических и виртуальных компонентов. «Экосистемный подход остаётся приоритетом нашей разработки, поэтому в новом релизе Basis Dynamix Cloud Control мы сделали акцент на расширении совместимости с другими решениями нашей экосистемы. Кроме того, значительное внимание было уделено инструментам администрирования прав пользователей и удобству управления виртуальным ЦОД, что будет особенно полезно крупным заказчикам со сложной инфраструктурой», — отметил Дмитрий Сорокин, технический директор компании «Базис».
16.12.2025 [01:05], Владимир Мироненко
NVIDIA купила разработчика Slurm, пообещав не забрасывать open source решениеNVIDIA объявила о приобретении SchedMD — ведущего разработчика открытой системы оркестрации Slurm для высокопроизводительных вычислений (HPC) и ИИ. Финансовые условия сделки не разглашаются. Созданная SchedMD система Slurm обеспечивает планирование и управление большими вычислительными задачами в ЦОД, позволяя уменьшить количество ошибок, ускорить вывод продукции на рынок и снизить затраты. Как сообщает NVIDIA, сделка поможет укрепить экосистему ПО с открытым исходным кодом и стимулировать инновации в области ИИ для исследователей, разработчиков и предприятий. Компания отметила, что рабочие нагрузки HPC и ИИ включают сложные вычисления с выполнением параллельных задач на кластерах, для чего требуется организация очередей, планирование и распределение вычислительных ресурсов. По мере увеличения размеров и мощности кластеров HPC и ИИ задача эффективного использования ресурсов становится критически важной. 
Источник изображения: SchedMD SchedMD была основана в 2010 году разработчиками ПО Slurm Моррисом «Мо» Джеттом (Morris «Moe» Jette) и Дэнни Оублом (Danny Auble) в Ливерморе (Livermore, штат Калифорния). В настоящее время персонал компании насчитывает 40 человек. Сейчас Slurm — ведущий менеджер рабочих нагрузок и планировщик заданий по масштабируемости, пропускной способности и управлению сложными политиками, который используется более чем в половине из десяти и ста лучших систем в списке TOP500 суперкомпьютеров. NVIDIA сообщила, что сотрудничает с SchedMD более десяти лет и продолжит инвестировать в разработку Slurm, чтобы сохранить его поизиции как ведущего планировщика с открытым исходным кодом для HPC и ИИ. NVIDIA обеспечит доступ SchedMD к новым системам, чтобы клиенты могли запускать гетерогенные кластеры с использованием последних инноваций Slurm. Также NVIDIA пообещала и далее поддерживать open source ПО, вкладываться в разработку Slurm и обучение. NVIDIA делает ставку на технологии с открытым исходным кодом и наращивает инвестиции в ИИ-экосистему, чтобы противостоять растущей конкуренции, отметил ресурс Reuters. В конце прошлого года NVIDIA завершила приобретение стартапа Run:ai, разрабатывающего ПО для управления рабочими нагрузками ИИ и оркестрации на базе Kubernetes. А в 2022 году она купила фирму Bright Computing, ещё одного известного разработчика инструментов оркестрации и управления кластерами.
17.11.2025 [16:09], Руслан Авдеев
Программный «ускоритель» Huawei обещает практически удвоить производительность дефицитных ИИ-чиповКитайский техногигант Huawei Technologies инфраструктурное ПО для повышения эффективности использования ИИ-ускорителей, сообщает гонконгская SCMP со ссылкой на государственные СМИ КНР. По имеющимся данным, технология позволит поднять эффективность использования ИИ-чипов, включая GPU и NPU, до 70 % по сравнению с нынешними 30–40 %. Это будет ещё одним крупным достижением в области «компенсации отставания в аппаратном обеспечении за счет совершенствования программного». Новая технология, премьера которой должна состояться на одной из посвящённых ИИ-тематике конференций, позволит «унифицированно управлять» не только ускорителями самой Huawei, но и NVIDIA, а также моделями прочих разработчиков. В самой Huawei от комментариев пока воздержались. Это особенно актуально в свете недоступности актуальных ускорителей NVIDIA, из-за чего китайские компании скупают чипы прошлых поколений. Важность оптимизации использования имеющихся ресурсов наглядна показала «революция DeepSeek». 
Источник изображения: Yiran Ding/unsplash.com Если информация подтвердится, технология может значительно улучшить продажи ИИ-чипов семейства Huawei Ascend в Китае (возможно, и за его пределами). Это может снизить зависимость КНР от чипов NVIDIA и других американских разработчиков. Утверждается, что новая технология Huawei будет аналогична продукту, разрабатывавшемуся израильским стартапом Run:ai и купленному NVIDIA в 2024 году за $700 млн. Его ПО позволяет организовать оркестрацию крупномасштабных ИИ-нагрузок между массивами ИИ-ускорителей. При этом и сама NVIDIA постоянно оптимизирует собственное ПО, повышая производительность исполнения рабочих нагрузок ИИ. Новость может стать хорошим дополнением к сентябрьскому анонсу. Тогда компания поделилась планами выпуска ИИ-ускорителей Ascend следующего поколения. Готовящиеся изделия призваны составить конкуренцию передовым чипов NVIDIA и подготовке мощных ИИ-систем SuperPOD, объединяющих 8192 и 15 488 ускорителей Ascend. На основе таких платформ будут формироваться суперкластеры, насчитывающие до 500 тыс. и более экземпляров Ascend.
08.10.2025 [08:53], Владимир Мироненко
HPE отдала Nokia «ненужные» технологии Juniper Networks для мобильных сетей, часть сотрудников и одного вице-президентаNokia объявила о сделке с HPE, в рамках которой она лицензировала технологии для развития своих решений для мобильных сетей и сетевой автоматизации на базе ИИ. Nokia получит доступ к технологиям, касающимся интеллектуальных контроллеров (RIC) сетей радиодоступа (RAN) и платформы по управлению и оркестрации сервисов (SMO) компании Juniper Networks, приобретённой HPE за $14 млрд. 1 октября 2025 года большая часть соответствующей команды разработчиков перешла в Nokia Mobile Networks, а вместе с ней и Константин Полихронопулос (Constantine Polychronopoulos), вице-президент группы Juniper Networks, о чём пишет Data Center Dynamics. Лицензированные технологии будут интегрированы с решениями платформы Nokia MantaRay для управления сервисами и оркестрации (SMO) и автоматизации сетей. MantaRay SMO — комплексное решение Nokia для автоматизации на базе ИИ без участия оператора, способное достичь 4-го уровня автономных сетей TM Forum. Решение также полностью совместимо с Open RAN и поддерживает открытый интерфейс R1 для rApps. 
Источник изображения: Nokia Как сообщает tele.net.in, за последние пять лет Juniper создала «лучшую в своем классе» платформу RIC, а также решение SMO, обеспечивающее сквозную динамическую «нарезку» сети (end-to-end dynamic network slicing) по требованию. По всей видимости, HPE решила, что бизнес SMO/RIC для неё не является целевым, подобно Broadcom, отказавшейся от разработки RIC в VMware, пишет ресурс The Mobile Network. RIC функционирует в процессе развёртывания Open RAN, выступая своего рода связующим звеном. Это позволяет операторам развёртывать xApps- и rApps-приложения для контроля и проектирования функций RAN, обеспечивая административный суверенитет RAN над функциями, которые обычно реализуются как проприетарные на базовых станциях. RIC также позволяет телекоммуникационным компаниям комбинировать сторонние сетевые приложения, такие как отключение базовых станций или перенаправление трафика из перегруженных сот, с радиоустройствами Ericsson или Nokia, предоставляя оператору больше контроля над своими средами Open RAN. Томми Уитто (Tommi Uitto), президент подразделения мобильных сетей Nokia, отметил, что сделка с HPE расширит возможности Nokia по предложению клиентам «автоматизации, оркестрации и открытых экосистем на базе ИИ, что позволит им эффективнее управлять сетями разных производителей и подготовиться к переходу с 5G на 6G».
20.06.2025 [00:00], Владимир Мироненко
Управлять данными, а не хранилищами: Pure Storage представила унифицированную облачную платформу Enterprise Data CloudPure Storage представила платформу Enterprise Data Cloud (EDC), которая предлагает простой, гибкий и унифицированный способ управления данными и хранилищами, позволяя организациям сосредоточиться на бизнес-задачах, а не на инфраструктуре. EDC позволяет управлять блочными, файловыми и объектными нагрузками в локальных, облачных и гибридных средах. Компания отметила, что использование традиционных моделей хранения влечёт за собой фрагментацию, разрозненность и неконтролируемое разрастание данных. Enterprise Data Cloud (EDC) предназначена для решения этих проблем, предоставляя виртуализированное облако данных с единым контролем, охватывающим различные среды. Такой подход обеспечивает интеллектуальное, автономное управление данными и управление во всём массиве данных, позволяя компаниям снизить риски, затраты и эксплуатационную неэффективность. 
Источник изображений: Pure Storage «Пришло время прекратить управлять хранилищем и начать управлять данными. Поскольку ИИ увеличивает потенциальную ценность корпоративных данных, а киберугрозы ставят их под угрозу, архитектуры хранения данных и инструменты для управления данными не поспевают за развитием», — сообщил в пресс-релизе председатель и генеральный директор Pure Storage Чарльз Джанкарло (Charles Giancarlo). Как отметил ресурс Computer Weekly, EDC представляет собой объединение существующих архитектурных элементов и систем Pure Storage: Purity OS, которая является общей для всех массивов компании; Fusion, которая позволяет обнаруживать и управлять ресурсами хранения; Pure1, которая позволяет управлять парком оборудования с точки зрения производительности и детального управления ресурсами; подписка Evergreen.  В основе платформы лежит решение Pure Fusion, объединяющее хранилища как пул адаптируемых ресурсов и рассматривающее все массивы как конечные точки в единой сети данных. Это позволяет администраторам управлять парком СХД через единый интерфейс и развёртывать рабочие нагрузки с использованием интеллектуальных шаблонов, которые автоматизируют такие параметры, как качество обслуживания, уровни защиты и требования к производительности. Слой Fusion изначально встроен в массивы Pure. Администраторы получили большую гибкость в реагировании на конкретные потребности каждой рабочей нагрузки и больше не должны предварительно планировать и настраивать развёртывания, что снижает риск несоответствия и повышает отказоустойчивость, гарантируя, что ресурсы для рабочих нагрузок будут подготовлены правильно с самого начала. 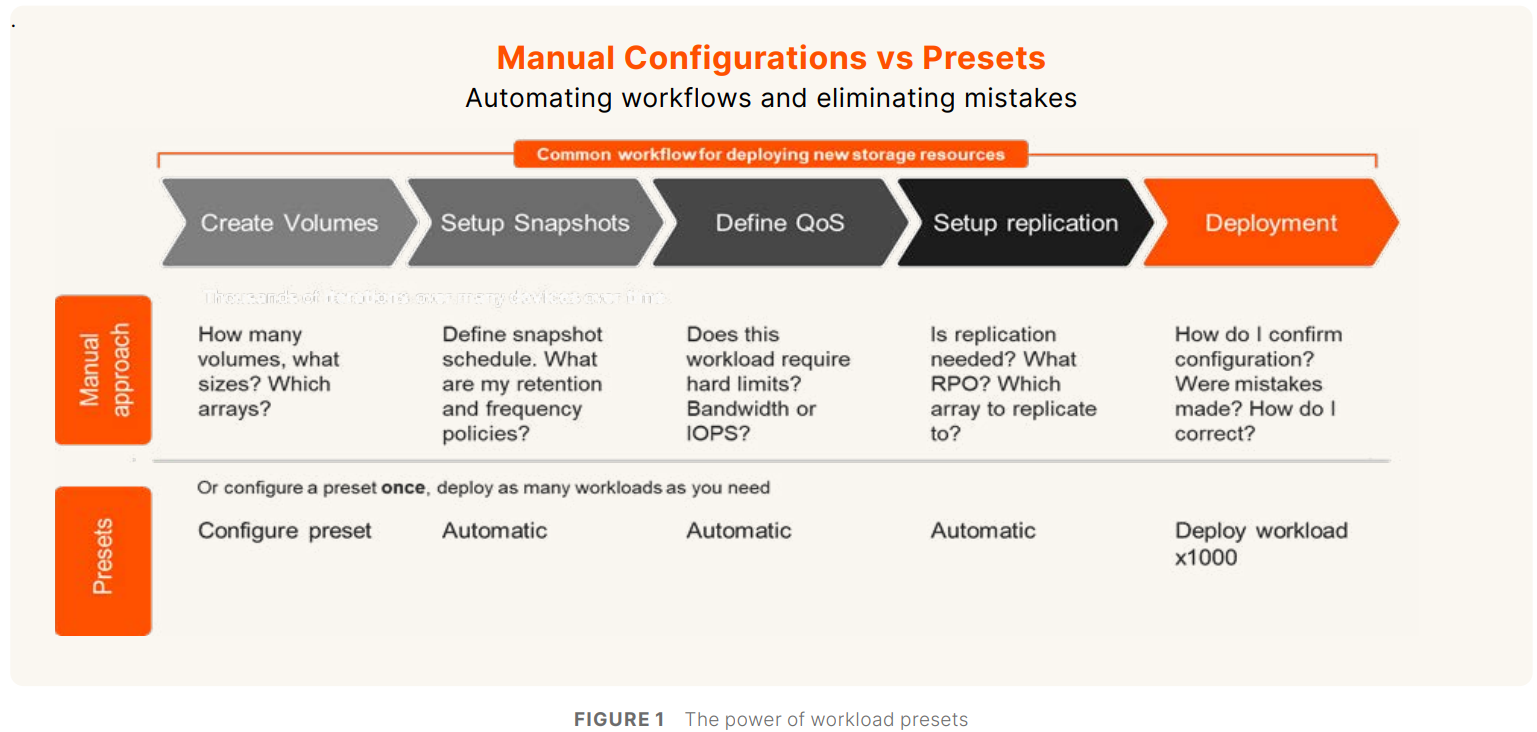 Чтобы устранить проблемы, возникающие из-за ручных операций по подготовке, миграции и многого другого, автоматизация охватывает весь стек платформы с возможностями оркестрации на основе политик и самообслуживания. Встроенное соответствие требованиям и улучшенная киберустойчивость ещё больше минимизируют риск путём использования политик безопасности и управления. Эти новые возможности полностью переопределяют интеллектуальное управление хранением, считает компания. EDC поддерживает готовые сценарии для формирования рабочих процессов, которые интегрируют хранилище с вычислениями, сетями и приложениями, чтобы обеспечить сложные развёртывания, такие как репликация базы данных в нескольких ЦОД и в публичном облаке в рамках одной задачи. 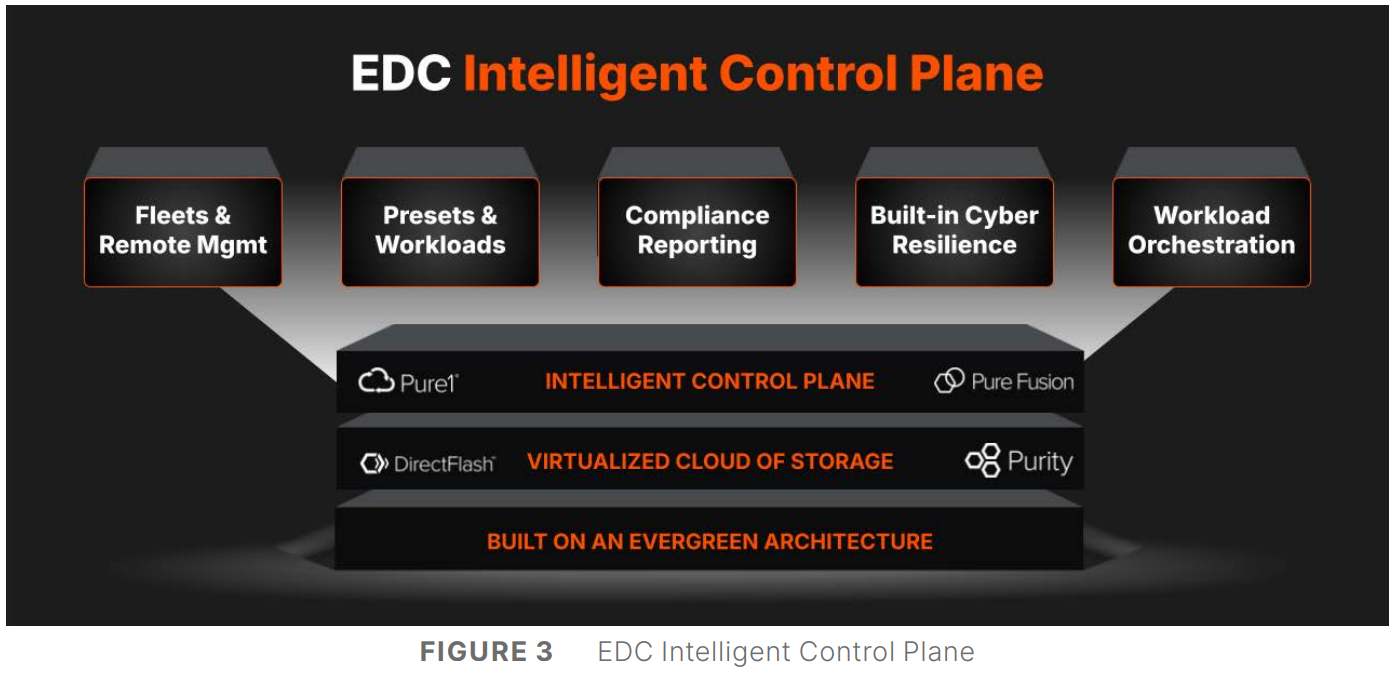 Чад Кенни (Chadd Kenney), вице-президент Pure Storage по технологиям, рассказал, что автоматизированные функции решают некоторые из рутинных задач развёртывания. «Если у кого-то есть приложение, которому требуется Oracle, администратор должен изучить парк массивов хранения, выяснить, какой из них способен принять новую рабочую нагрузку, а затем настроить его, убедившись в работоспособности репликации, наличии снапшотов и корректности политики качества обслуживания, — говорит Кенни. — Шаблоны позволяют вам задавать все конфигурации разом». Платформа предоставляет организованные шаблоны для рабочих процессов, созданные на основе тысяч существующих коннекторов для сторонних приложений и продуктов, в том числе от Cisco, Microsoft, VMware, ServiceNow и Slack. Шаблоны охватывают конфигурации хранилищ, вычислительных ресурсов, сетей, баз данных и приложений. Можно использовать готовые шаблоны от самой Pure и партнёров или создавать свои. 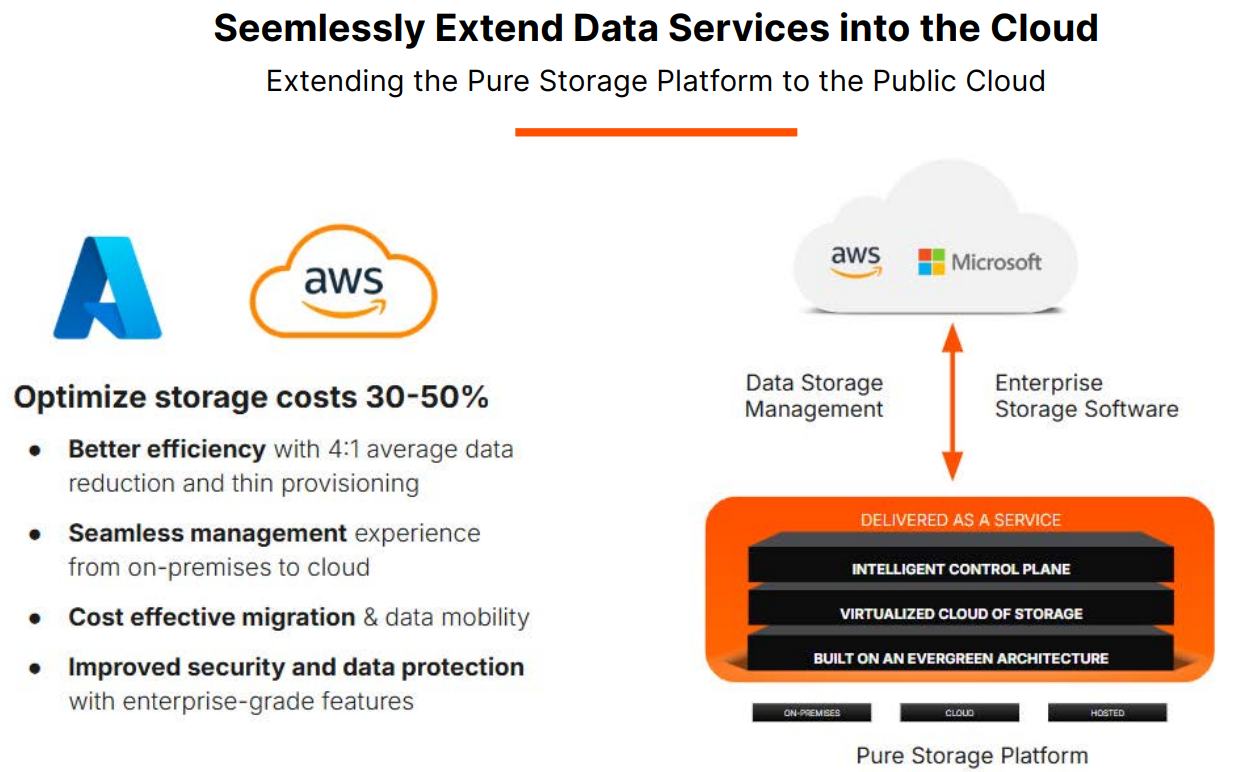 Платформа включает в себя центр оркестрации с шаблонами автоматизации для таких функций, как DRaaS и предоставление данных, и имеет интеграцию с Rubrik Security Cloud и Crowdstrike Logscale. Например, Pure Fusion по сигналу от Rubrik автоматически маркирует снимки, отправляет их на сканирование и быстро выявляет среди них наиболее подходящие для восстановления. В случае с CrowdStrike компания предлагает первое в своём роде проверенное, локальное, устойчивое, безопасное и высокопроизводительное хранилище для Falcon LogScale. Кроме того, платформа предлагает расширенные возможности восстановления сред VMware. Наконец, интеллектуальный помощник компании AI Copilot, отслеживает в реальном времени телеметрию всего EDC, что позволяет ему мгновенно реагировать на запросы по производительности на уровне парка, предоставлять сценарии конфигурации и поддерживать быструю корректировку политики без вмешательства человека, заявила Pure Storage. «В течение 10 секунд он обработает все данные 100 различных систем, даст вам ответ и предоставит сценарий для развёртывания нагрузки», — рассказал Кенни.
01.05.2025 [19:15], Андрей Крупин
Новое поколение платформы Beeline Cloud 2.0 дополнилось функцией интеллектуальной оркестрации гибридного облакаКомпания «Вымпелком», предоставляющая услуги под брендом «Билайн», анонсировала релиз нового поколения облачной платформы Beeline Cloud 2.0 для корпоративного сегмента. Ключевой особенностью Beeline Cloud 2.0 является интеллектуальный оркестратор Vega собственной разработки, обеспечивающий управление гибридной IT-инфраструктурой и объединяющий различные среды виртуализации (OpenStack, VMware и другие) в единый управляемый комплекс. По заверениям команды «Вымпелкома», нововведение позволяет максимально эффективно использовать вычислительные ресурсы дата-центра, одновременно предоставляя облачные сервисы в формате, доступном не только IT-инженерам, но и продуктовым командам, архитекторам и разработчикам ПО с поддержкой методологии CI/CD (Continuous Integration/Continuous Delivery). Будучи комплексным решением, Beeline Cloud 2.0 предоставляет множество функциональных возможностей. В их числе: единое управление мультивиртуализацией через Vega-оркестратор; доступ к IaaS и PaaS (виртуальные машины, базы данных, Kubernetes, DevOps-инструменты и др.); оптимизация инфраструктурных ресурсов и снижение затрат; быстрый запуск и масштабирование продуктов через инструменты самообслуживания; готовность к внедрению генеративных ИИ-систем и современных подходов к разработке; кибербезопасность корпоративного уровня с соблюдением российских стандартов. 
Источник изображения: cloud.beeline.ru «Изначально Vega создавался внутри «Вымпелкома» как оркестратор для трансформации корпоративного IT-ландшафта в соответствии с концепцией «всё как код» — архитектурного подхода, при котором инфраструктура, конфигурации и приложения описываются и управляются через код. Такой подход стал основой подготовки к масштабному внедрению GenAI, поскольку генеративные модели требуют предсказуемой автоматизированной и масштабируемой среды», — поясняют в компании. На текущий момент Beeline Cloud 2.0 находится в стадии закрытого тестирования и проходит финальную настройку. В ближайшем будущем «Вымпелком» планирует запустить платформу в коммерческую эксплуатацию и предоставить клиентам доступ к полноценному облачному стеку, построенному по самым современным принципам.
23.04.2025 [16:15], Руслан Авдеев
GPU под роспись: Amazon резко ужесточила использование дефицитных ИИ-ускорителей внутри компании в рамках Project GreenlandВ прошлом году ретейл-бизнес Amazon столкнулся с острой нехваткой ИИ-ускорителей для внутреннего пользования. Это привело к задержкам при реализации ключевых проектов. На фоне глобального бума ИИ-технологий и дефицита чипов NVIDIA компания вынужденно пересмотрела принципы доступа к ускорителям для собственных нужд, сообщает Business Insider. В июле 2024 года началась реализация т. н. Project Greenland. Фактически речь идёт о платформе для централизованного распределения ресурсов ускорителей. Платформа позволяет отслеживать их использование, перераспределяет мощности в случае простоя и даёт возможность оперативно реагировать на изменения спроса. Теперь все заявки на доступ к ускорителям подаются только через Greenland, а приоритет получают проекты с высоким уровнем возврата инвестиций (ROI), чётким графиком и заметным влиянием на снижение затрат или рост выручки. У проектов с низкой эффективностью доступ к вычислительным мощностям могут вообще отозвать в пользу более перспективных инициатив. Amazon выделила восемь принципов распределения ускорителей среди сотрудников компании:

Источник изображения: Centre for Ageing Better/unsplash.com Amazon уже активно использует искусственный интеллект в различных проектах. В числе ключевых инициатив:
По оценкам Amazon, ИИ-проекты розничного подразделения в 2024 году принесли $2,5 млрд операционной прибыли, попутно сэкономив $670 млн. В 2025 году ретейл-подразделение Amazon намерено вложить $1 млрд в ИИ-проекты розничного сегмента и увеличить расходы на облако AWS до $5,7 млрд (с $4,5 млрд в 2024 году). Если во II полугодии 2024 года розница Amazon нуждалась в более 1 тыс. дополнительных инстансов P5 с NVIDIA H100, то в 2025 году ситуация, как свидетельствуют внутренние прогнозы, должна стабилизироваться. А к концу года внутренние запросы полностью удовлетворят с помощью чипов собственной разработки Amazon Tranium, «но не раньше». Тем не менее, в Amazon не теряют бдительности, постоянно задаваясь вопросом: «Как получить больше ускорителей?».
04.04.2025 [12:37], Руслан Авдеев
«Агрегатор ускорителей» Parasail анонсировал ИИ-гипероблакоСтартап Parasail привлёк $10 млн стартового капитала и выступил с необычным для рынка ИИ предложением. Компания стала своеобразным «агрегатором ускорителей», создав для инференса сеть, позволяющую свести вместе владельцев вычислительных мощностей и их клиентов с максимальной простотой, сообщает The Next Platform. Раунд финансирования возглавили Basis Set Ventures, Threshold Ventures, Buckley Ventures и Black Opal Ventures. Компанию основали Майк Генри (Mike Henry), ранее основавший производителя ИИ-решений Mythic и работавший одним из топ-менеджеров в Groq, и Тим Харрис (Tim Harris), генеральный директор Swift Navigation. Прежний опыт Майка Генри на рынке IT позволил заметить, что в последнее время ландшафт облачных сервисов стремительно меняется — если ранее на нём безраздельно доминировали гиперскейлеры вроде AWS, Microsoft Azure и Google Cloud, то с приходом ИИ они, казалось бы, сохраняют ведущие позиции, но на сцену выходят и новые облачные игроки, чья инфраструктура изначально рассчитана на ИИ-задачи, от обучения до инференса. В конце 2023 года бизнесмены основали компанию Parasail, которая совсем недавно заявила о себе, заодно собрав $10 млн финансирования. Фактически бизнес рассчитан на клиентов, которые заинтересованы в простом доступе к ИИ-технологиям — он будет связывать тех, кто располагает ими, и тех, кто в них нуждается. 
Источник изображения: Campaign Creators/unsplash.com Parasail намеревается использовать рост облачных ИИ-провайдеров вроде CoreWeave (недавно вышедшей на IPO) и Lambda Labs. Для этого создана сеть AI Deployment Network, объединяющая их вычислительные ресурсы в единую инфраструктуру, которая масштабнее, чем Oracle Cloud Infrastructure (OCI). Компания применяет собственный «движок» для оркестрации процессов в этом гипероблаке. Ключевым преимуществом является низкая стоимость услуг — утверждается, что компании, желающие отказаться от сервисов вроде OpenAI и Anthropic, могут рассчитывать на экономию в 15–30 раз, а в сравнении с клиентами провайдеров open source моделей — в 2–5 раз. На настройку уходит несколько часов, а инференс после этого можно начать за считанные минуты. Сегодня Parasail предлагает в облаке ресурсы NVIDIA H200, H100 и A100, а также видеокарт NVIDIA GeForce RTX 4090. Цены составляют от $0,65 до $3,25 за час использования. Parasail столкнулась с проблемой несовместимости инфраструктур: разные облачные платформы используют уникальные подходы к вычислениям, хранению данных, сетевому взаимодействию, а также имеют различия в настройке, биллинге и автоматизации. Хотя Kubernetes и контейнеризация могли бы частично решить эти проблемы, их реализация у разных провайдеров сильно отличается, а Kubernetes изначально не предназначается для работы с несколькими кластерами, регионами или провайдерами одновременно. Чтобы обойти ограничения, Parasail разработала собственную систему, которая объединяет ускорители из разных облаков в единую глобальную сеть. Их решение позволяет централизованно управлять распределёнными узлами, игнорируя различия в инфраструктуре провайдеров. Если один облачный провайдер выйдет из строя, система автоматически заменяет его ресурсы другими, минимизируя простои. Дополняя эту систему автоматизированным динамическим выделением ускорителей, Parasail создаёт масштабируемую и эффективную глобальную инфраструктуру, способную оперативно адаптироваться к нагрузкам и сбоям. Оркестрация и оптимизация рабочих нагрузок в ИИ-инфраструктуре усложняются из-за огромного разнообразия моделей, архитектур, типов GPU и ASIC, а также множества способов их комбинирования. Parasail решает эту проблему с помощью гибридного подхода, сочетающего математическое моделирование, ИИ-алгоритмы и участие живых специалистов, что позволяет эффективно масштабироваться даже с небольшой командой. 
Источник изображения: Campaign Creators/unsplash.com Закрытое бета-тестирование началось в январе, а позже спрос только вырос до той степени, что Parasail достигла семизначного ежегодного регулярного дохода (ARR). Теперь технология доступна всем, в числе клиентов — производитель чипов SambaNova, ИИ-платформа Oumi, ИИ-стартап Rasa и Elicit, позволяющий автоматизировать научные изыскания. В будущем стартап намерен быстро расширить штат из 12 работников, рассматриваются и варианты добавления в портфолио новых доступных ускорителей — сейчас там безусловно лидирует NVIDIA, но рынок вполне может измениться. В то же время отмечается парадоксальная ситуация, когда на рынке наблюдается и дефицит ускорителей, и простой мощностей в некоторых ЦОД одновременно. Предполагается, что дело в плохой оптимизации процессов на рынке ИИ. При этом в компании отмечают, что в данное время спрос на ИИ-приложения «почти бесконечен» и главная проблема — эффективно их использовать. Платформа Parasail для инференса максимально упрощает масштабное внедрение ИИ. |
|

