Лента новостей
|
18.09.2024 [20:29], Владимир Мироненко
3Logic Group создал системного интегратора «Берегит»Российский дистрибьютор электроники 3Logic Group объявил о создании системного интегратора «Берегит», ориентированного на крупные и средние компании. Он использует решения зарубежных вендоров и их аналоги, а также оборудование и ПО из реестров Минпромторга и Минцифры России, опираясь на возможности 3Logic Group в части обеспечения наличия необходимого заказчикам ИТ-оборудования. Как сообщили в 3Logic Group «Коммерсанту», интегратор будет использовать и решения собственных торговых марок дистрибутора, включая Crusader и «Гравитон» (50 % у 3Logic Group). В настоящее время «Берегит» предлагает полный спектр услуг по проектированию, внедрению и поддержке комплексных ИТ-решений, в том числе построение телеком- и ИТ-инфраструктур:
В числе преимуществ интегратора заявлены гарантированная доступность необходимого для проектов ИТ-оборудования благодаря имеющимся возможностям 3Logic Group в логистике и обеспечении поставок, а также наличию у неё необходимого портфеля ИТ-решений, что позволит сохранить стоимость проектов и соблюсти срокы их выполнения. 
Источник изображения: «Берегит» Команда «Берегит» включает опытных специалистов, участвовавших в реализации более 100 проектов построения ИТ-инфраструктуры. Сотрудники «Берегит» сертифицированы по работе с зарубежными и российскими ИТ-решениями. Штат компании насчитывает более 80 специалистов, работающих в настоящее время над выполнением 70 проектов. «В современных реалиях доступность оборудования и экспертиза, подкреплённая разносторонним опытом внедрения, — два слагаемых успеха интегратора нового времени», — отметил исполнительный директор «Берегит», добавив, что в ближайшее время будут представлены первые значимые проекты, которые продемонстрируют большой потенциал компании.
18.09.2024 [18:04], Руслан Авдеев
Microsoft Research занялась разработкой нового поколения эффективных облачных хранилищПодразделение Microsoft Research, работающая в Кембридже (штат Массачусетс, США), занялась разработкой и созданием прототипов систем облачного хранения нового поколения. Datacenter Dynamics напоминает, что именно это подразделение стоит за проектом Project Silica, в рамках которого создавались носители, способные хранить данные 10 тыс. лет. В описании одной из вакансий говорится, что исследователи пересматривают фронт работ, переключаясь с создания носителей для архивных хранилищ на более «горячие» решения. В частности, упоминается, что недавние успехи с сфере ИИ и машинного обучения фундаментально изменили рамки возможного во многих сферах, включая разработку новых материалов, создание научных симуляций, обработку сигналов и т.п. От кандидата требуется докторская степень в области информатики или компьютерной инженерии или эквивалентный опыт работы в R&D в области СХД, ОС, сетей, распределённых систем и т.п. 
Источник изображения: Microsoft Новые подходы приводят к пересмотру возможностей облачных хранилищ в эпоху ЦОД, ограниченных в энергии — никогда запрос на недорогие и устойчивые хранилища данных не был столь высок. В рамках нового проекта исследователи намерены внедрять инновации на уровне носителей и методов записи и чтения информации. Проект потребует «изобретения новых методов исследования» для быстрой оценки того, как изменения на физическом уровне повлияют на ключевые показатели производительности хранилища. Создание эффективной системы с нуля также включает решение более традиционных задач — оценку рабочих нагрузок, планирование записи и чтения данных оптимальным образом, эффективное размещение информации на носителе, коррекция ошибок для защиты данных от ошибок и стирания. Главой проект является Ричард Блэк (Richard Black), который ранее работал над инициативой Pelican — под его руководством компания пыталась создать наиболее дешёвый массив дисковых накопителей.
18.09.2024 [17:52], Руслан Авдеев
Куда по мокрому?! Alibaba Cloud ждёт пока просохнет оборудование, пострадавшее от пожара в сингапурском ЦОД Digital RealtyКатастрофический пожар, произошедший во вторник на прошлой неделе в сингапурском дата-центре Digital Realty, всё ещё осложняет работу облачных операторов. The Register, в частности, сообщает, что к полноценной работе не может приступить облачный регион Alibaba Cloud — в компании ждут, когда просохнет оборудование, чтобы попытаться восстановить данные. Согласно данным Alibaba Cloud, миграция и восстановление данных в повреждённом ЦОД SIN11 идёт по плану. Работа облачных сервисов постепенно восстанавливается. В компании подчеркнули, что часть оборудования по-прежнему находится в небезопасной и заблокированной зоне дата-центра. О возможном затоплении ряда помещений пожарные предупредили оператора заранее. Некоторое оборудование требует тщательной просушки до того, как можно будет попытаться запустить его без дополнительной угрозы целостности данных. На их восстановление уйдёт некоторое время. Из-за сбоя Alibaba Cloud, как выяснилось, пострадали и различные сервис-провайдеры, включая Lazada и ByteDance. 
Источник изображения: Adam Wilson/unsplash.com Причиной пожара, вероятно, стало возгорание Li-Ion элементов ИБП. Сообщалось, что для тушения и охлаждения АКБ пришлось задействовать пожарного робота, поскольку аккумуляторы могли повторно воспламениться, взорваться и выделить токсичные вещества. Ситуация усугублялась тем, что АКБ находились на третьем этаже четырёхэтажного ЦОД. Хотя современные нормы Сингапура предписывают размещать ИБП на первом этаже, объект Digital Realty ввели в эксплуатацию задолго до принятия этих норм. Это единственный из трёх кампусов Digital Realty в Сингапуре, созданный на основе уже имеющейся инфраструктуры. Ещё два были возведены с нуля. 
Источник изображения: Daan Mooij / Unsplash Как сообщает Alibaba Cloud, к вечеру злополучного вторника всё ещё звучала пожарная сигнализация, а некоторое сетевое оборудование функционировало со сбоями из-за высоких температур. Клиентов предупредили о возможных сбоях во всех зонах доступности данного облачного региона. В среду большинство облачных сервисов восстановили работу в результате переноса части нагрузок. В пятницу было объявлено, что часть оборудования находится «в стадии безопасной миграции». В субботу уже проводилась подготовка к установке оборудования, включая его сушку. От грандиозного пожара в своём время пострадал ЦОД OVHCloud в Страсбурге, долгое время оператор разбирался многочисленными претензиями пользователей. В самом Сингапуре после крупного сбоя дата-центра Equinix в прошлом году власти пообещали жёстко отрегулировать деятельность ЦОД и облаков.
18.09.2024 [15:05], Руслан Авдеев
Земля и энергия в обмен на долю в ЦОД: «зелёная» энергокомпания Iberdrola предложила застройщикам Испании необычную сделкуИспанский поставщик возобновляемой электроэнергии Iberdrola SA намерен обеспечить испанскому дата-центру подключение к энергосети и поставки возобновляемой энергии. При этом, как сообщает Bloomberg, в обмен застройщикам передадут ей до 20 % доли в новом ЦОД. Строительство обойдётся в €2 млрд. Как свидетельствуют источники издания, крупнейший производитель «чистой» энергии в Европе сейчас активно обсуждает условия сделки с неназванными контрагентами. Iberdrola готова предоставить находящуюся в её собственности землю и уже имеющую энергетическую инфраструктуру, но финансовый вклад в строительство и эксплуатацию ЦОД придётся сделать именно партнёрам. Необычная конфигурация сделки косвенно свидетельствует о том, в какой степени Iberdrola стремиться пополнить своё глобальное портфолио дата-центрами. Предполагается, что совместное предприятие создадут в I половине 2025 года и изначально его деятельность будет сосредоточена на «домашнем» для Iberdrola рынке в Бильбао. Позже компания расширит деятельность и на другие рынки. 
Источник изображения: Eduardo Kenji Amorim/unsplash.com Ожидается, что развитие ИИ приведёт к росту спроса на электроэнергию для ЦОД к 2030 году на 160 %, в целом потребление электричества дата-центрами достигнет 4 % от общемирового. Конечно, такие прогнозы делают данный рынок весьма привлекательным для компаний, генерирующих возобновляемую энергию — крупнейшие операторы вроде Microsoft и Meta✴ ставят перед собой весьма амбициозные цели по переходу на чистую энергию. При этом именно дефицит энергии тормозит развитие ИИ ЦОД. Iberdrola уже является опосредованным поставщиком «чистой» энергии для нескольких ЦОД в рамках соглашений о покупке энергии (Power Purchase Agreement, PPA). Новый кампус получит землю с возможностью подключения до 200 МВт. Для бесперебойного снабжения электричеством будут применяться гидроаккумуляторные источники, хотя позже может добавиться и солнечная электростанция. 
Источник изображения: Des Mc Carthy / Unsplash Первый объект нового кампуса должен заработать к 2030 году. К тому времени Ibedrola рассчитывает занять 20 % рынка ЦОД в Испании. Уже создано подразделение CPD4Green, которое займётся развитием нового бизнеса. Испания выбрана в качестве исходного, якорного рынка из-за доступности земли и наличия хорошо развитой энергосети общей мощностью более 22 ГВт. Ранее сообщалось о намерении Iberdrola инвестировать в ЦОД, но некоторые детали были неизвестны. Другие энергетические компании из Испании также проявляют интерес к рынку ЦОД. Ранее разработчик солнечных элементов питания Solaria Energia y Medioambiente SA заключил соглашение с японской Datasection Inc., предусматривающей строительство дата-центра ёмкостью до 200 МВт, а в июле текущего года специализирующаяся на недвижимости Merlin Properties Socimi SA привлекла около €1 млрд ($1,1 млрд) для расширения бизнеса в сфере ЦОД.
18.09.2024 [14:50], Руслан Авдеев
Microsoft и BlackRock совместно инвестируют до $100 млрд в ИИ-инфраструктуруMicrosoft и BlackRock совместно инвестируют в строительство дата-центров и энергетику для поддержки быстроразвивающейся ИИ-отрасли. По данным Silicon Angle, для этого сформирована новая группа Global AI Infrastructure Investment Partnership (GAIIP). Помимо Microsoft и BlackRock, в неё входят купленная последней в январе за $12,5 млрд инвестиционная компания Global Infrastructure Partners (GIP), а также дубайский инвестор MGX. Предполагается, что партнёры будут вкладывать средства в новые ЦОД и расширение уже действующих для удовлетворения растущего спроса на вычислительные мощности. Также средства будут тратиться на энергетическую инфраструктуру для создания новых источников энергии для этих ЦОД. Целевым рынком для вложения средств считается США, а остатки потратят на территории «американских стран-партнёров». Согласно пресс-релизу GIP, планируется поддерживать открытую архитектуру и обширную экосистему, обеспечивая полный доступ к наработкам самому широкому кругу компаний. NVIDIA будет поддерживать GAIIP, предлагая экспертные консультации, связанные с технической частью ИИ-проектов. GAIIP рассчитывает получить в распоряжение $30 млрд инвестиционных капиталов для начальных вложений в проекты, что, в свою очередь, позволит увеличить общий инвестиционный потенциал до $100 млрд с учётом долгового финансирования. 
Источник изображения: Sebastian Herrmann/unsplash.com Помимо участия в новой структуре, Microsoft уже инвестировала в связанные с ИИ многочисленные проекты немало средств. Так, в мае Microsoft обязалась выделить $2,2 млрд на облачную и ИИ-инфраструктуру в Малайзии, чуть позже в том же месяце — $3,3 млрд на строительство ИИ ЦОД в Висконсине (США). В июне компания объявила о планах потратить $3,2 млрд для расширения ЦОД в Швеции. Крупнейшие «внешние» инвестиции Microsoft в ИИ связаны с небезызвестной компанией OpenAI, в которую IT-гигант вложил уже около $13 млрд с 2019 года, вполне вероятны и дальнейшие инвестиции. Global Infrastructure Partners, основанная в 2006 год, управляет активами на сумму более $100 млрд. Среди активов есть крупные транспортные узлы, поставщики энергии из возобновляемых источников, а также оператор ЦОД CyrusOne и ряд других инфраструктурных компаний. Кроме того, фонд неоднократно инвестировал в других операторов дата-центров.
18.09.2024 [11:23], Владимир Мироненко
Генеративный ИИ «оживляет» мейнфреймыМейнфреймы по-прежнему сохраняют актуальность, несмотря бурное развитие ИИ-технологий и облачных сервисов, пишет The Register со ссылкой на новое исследование State of Mainframe Modernization компании Kyndryl. Согласно данным опроса 500 топ-менеджеров ИТ-индустрии, многие организации интегрируют свои мейнфреймы с публичными и частными облачными платформами и совершенствуют свои программы модернизации, перемещая некоторые рабочие нагрузки с мейнфрейма и обновляя другие на месте, чтобы продолжать пользоваться такими преимуществами мейнфреймов, как безопасность и надёжность. Kyndryl сообщила, что 86 % респондентов развёртывают или планируют развёртывать инструменты и приложения генеративного ИИ в своей среде мейнфреймов. Исходя из этого Kyndryl назвала 2024 год «годом внедрения ИИ на мейнфреймах». Сама IBM заявила, что генеративный ИИ стал движущей силой в её бизнесе мейнфреймов, проносящим больше выручки в последние кварталы. 
Источник изображения: IBM Большая часть участников опроса (80 %) всё ещё находится на стадии изучения возможностей генеративного ИИ, но вместе с тем 41 % респондентов надеется использовать его для ускорения операций и снижения их подверженности человеческим ошибкам. Между тем, 33 % респондентов нацелены на улучшение клиентского опыта, например, за счёт повышения персонализации, а также разблокировании критически важных данных и преобразование неструктурированных данных в полезную информацию, в то время как треть участников опроса планирует использовать генеративный ИИ для извлечения бизнес-информации из своих данных, управляемых мейнфреймами, чтобы помочь в разработке новых продуктов или услуг. Согласно Kyndryl, генеративный ИИ также может помочь в модернизации, «проливая свет на внутреннюю работу монолитных приложений», что, как утверждается, может компенсировать нехватку навыков работы с мейнфреймами у нынешних сотрудников. Вместе с тем меньшая часть респондентов, чьи компании применяют мейнфреймы, не планирует использовать генеративный ИИ в какой-либо форме, ссылаясь на проблемы безопасности и регулирования в качестве причины своего нежелания или говоря о наличии других приоритетов. Опрос показал, что компании, продолжающие эксплуатировать мейнфреймы, стремятся использовать их с максимальной эффективностью, но также и пользоваться гибкостью облачных сервисов. Хотя 96 % респондентов заявили, что перемещают некоторые рабочие нагрузки с мейнфреймов (около трети), 89 % согласились, что эти системы по-прежнему чрезвычайно или очень важны для их бизнес-операций. В отчёте Kyndryl выделено три основных варианта модернизации мейнфреймов, причём большинство организаций использует их сочетания. Один из них — миграция, перенос некоторых или всех приложений и данных в облако или на локальную альтернативу. Второй вариант — интеграция данных и приложений мейнфрейма с другими платформами, что позволяет, например, новым облачным приложениям получать к ним доступ. Как ожидается, эта модель будет использоваться чаще с продолжающейся эволюцией генеративного ИИ, сообщила Kyndryl. Третий вариант — модернизация рабочих нагрузок на мейнфрейме, определение того, какие приложения следует сохранить, заменить или удалить, что подразумевает модернизацию исходного кода приложений или использование более современных языков, а также использование новых технологий, таких как ИИ и контейнеризация. Это уже второе исследование State of Mainframe Modernization компании Kyndryl, и в этом году больше респондентов заявили, что они сосредоточены в первую очередь на модернизации или интеграции с облаком, в то время как меньшее количество выбрали в качестве первоочередной задачи перенос рабочих нагрузок с мейнфрейма. Около 53 % респондентов заявили о росте использования мейнфреймов в этом году, а 49 % сообщили, что ожидают дальнейшего роста использования в течение следующих 12 месяцев. По словам Kyndryl, окупаемость инвестиций в проекты модернизации мейнфреймов составляет от 114 до 225 %. Что также важно, 66 % респондентов заявили, что уровень безопасности, предлагаемый мэйнфреймами, является для них самым важным фактором, и почти половина опрошенных назвала обеспечение безопасности основной причиной инвестиций в модернизацию. Один из руководителей ИТ-отдела оптовой компании в США сообщил, что был принят гибридный облачный подход, поскольку он позволяет хранить конфиденциальные данные в защищённой среде мейнфрейма, используя облако для менее важных рабочих нагрузок. Также в исследовании сообщается о сохранении проблемы с нехваткой персонала с соответствующим опытом работы с мейнфреймами. 18 % респондентов из компаний, интегрирующих мейнфреймы с другими платформами, заявили, что недостаточный опыт был основным препятствием для успеха проекта, в то время как более четверти участников опроса выразили обеспокоенность тем, что их организациям не хватает необходимого уровня навыков для эффективной модернизации мейнфреймов. IBM пытается решить проблему с кадрами, представив в начале этого года пару инициатив по решению проблемы нехватки инженеров. Также отмечено, что что 43 % респондентов указали, что у них нет навыков использования возможностей ИИ и генеративного ИИ, что заставляет всё больше организаций обращаться к внешним поставщикам, таким как Kyndryl, для реализации своих проектов модернизации. Подводя итоги, Kyndryl сделала вывод о том, что мейнфрейм остаётся важнейшей ИТ-средой для многих предприятий и даже становится всё более актуальным благодаря своей безопасности, надёжности и производительности.
17.09.2024 [23:07], Игорь Осколков
Швейцария ввела в эксплуатацию гибридный суперкомпьютер Alps: 11 тыс. NVIDIA GH200, 2 тыс. AMD EPYC Rome и щепотка A100, MI250X и MI300AШвейцарская высшая техническая школа Цюриха (ETH Zurich) провела церемонию официального запуска суперкомпьютера Alps в Швейцарском национальном суперкомпьютерном центре (CSCS) в Лугано. Система, построенная HPE, уже заняла шестую строчку в последнем рейтинге TOP500 и имеет устоявшеюся FP64-производительность 270 Пфлопс (теоретический пик — 354 Пфлопс). К ноябрю будут введены в строй остальные модули машины, и её максимальная производительность составит порядка 500 Пфлопс. 
Источник изображений: CSCS В июньском рейтинге TOP500 участвовал раздел из 2688 узлов HPE Cray EX254n с «фантастической четвёркой» NVIDIA Quad GH200. Если точнее, это всё же «старый» вариант ускорителя с H100 (96 Гбайт HBM3), 72-ядерным Arm-процессором Grace и 128 Гбайт LPDDR5x — суммарно 10 752 Grace Hopper. Данный раздел потребляет 5,2 МВт и в Green500 находится на 14 месте. Узлы, конечно же, используют СЖО. Это основной, но не единственный раздел суперкомпьютера. Ещё в 2020 году HPE развернула 1024 двухпроцессорных узла с 64-ядерными AMD EPYC 7742 (Rome) и 256/512 Гбайт RAM. Его производительность составляет 4,7 Пфлопс. Кроме того, в состав Alps входят 144 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя NVIDIA A100 (80 или 96 Гбайт HBM2e).  Наконец, машина получит 24 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя AMD Instinct MI250X (128 Гбайт HBM2e) и 128 узлов с четырьмя гибридными ускорителями AMD Instinct MI300A. Большая часть узлов будет объединена интерконнектом HPE Slingshot-11: 200G-подключение на узел или ускоритель. Более точную конфигурацию системы раскроют в ноябре. Lustre-хранилище для будущей машины обновили ещё в прошлом году. Основной СХД является Cray ClusterStor E1000 с подключением Slingshot-11. Так, было добавлено 100 Пбайт полезной HDD-ёмкости (8480 × 16 Тбайт) с пропускной способностью 1 Тбайт/с (300 тыс. IOPS на запись, 1,5 млн IOPS на чтение) и 5 Пбайт SSD, а также резервные ёмкости. За архивное хранение отвечают две ленточные библиотеки объёмом 130 Пбайт каждая.  Особенностью системы является её геораспределённость (фактически узлы размещены в четырёх местах) и облачная модель использования. Так, метеослужба страны MeteoSwiss получила в своё распоряжение выделенный виртуальный кластер, что уже позволило перейти на использование метеомодели более высокого разрешения, которая лучше отражает сложный рельеф Швейцарии. Кроме того, для подстраховки часть узлов Alps размещена на территории Федеральной политехнической школы Лозанны (EPFL). Alps приходит на смену суперкомпьютеру Piz Daint (Cray XC50/40, 21,2 Пфлопс), о завершении жизненного цикла которого было объявлено в конце июля 2024 года. В CSCS пока останутся машины Arolla + Tsa (для нужд MeteoSwiss) и Blue Brain 5 (решает задачи реконструкции и симуляции мозга). Alps же помимо традиционных HPC-нагрузок, будет использоваться для разработки ИИ-решений.
17.09.2024 [20:59], Владимир Мироненко
Объявленный Intel план реструктуризации ставит под сомнение будущее ускорителей Falcon ShoresВ начале недели Intel разослала сотрудникам письмо с описанием плана выхода из кризиса, который ставит под сомнение будущее ускорителей Falcon Shores, ранее намеченных к выпуску в 2025 году, пишет ресурс HPCwire. Согласно плану, компания сосредоточится на выпуске продуктов на архитектуре x86, что может отразиться на производстве Falcon Shores, поскольку глава Intel Пэт Гелсингер (Pat Gelsinger) ранее заявил, что не будет конкурировать с NVIDIA и AMD в области обучения ИИ. Следующий этап реструктуризации также включает сокращение расходов ещё на $10 млрд и увольнение 15 тыс. сотрудников, из которых 7,5 тыс. уже выразили согласие сделать это на добровольной основе. «Мы должны сосредоточиться на нашей сильной франшизе x86, поскольку мы реализуем нашу стратегию ИИ, одновременно оптимизируя наш портфель продуктов для обслуживания клиентов и партнёров Intel», — подчеркнул в письме Гелсингер. В прошлом месяце на аналитической конференции Deutsche Bank он заявил, что компания покидает рынок обучения ИИ с тем, чтобы сосредоточиться на инференсе, используя сильную сторону чипов x86. 
Источник изображения: Intel Желание Intel сократить расходы и отказаться от неактуальных продуктов может повлиять на реализацию проекта по выпуску Falcon Shores, ускорителя для ЦОД, выход которого неоднократно откладывался. Он является преемником ускорителя Intel Ponte Vecchio (Data Center GPU Max 1550) на базе архитектуры Xe, массовый выпуск которого был фактически прекращён после ввода в эксплуатацию суперкомпьютера Aurora. Ранее Intel отказалась от ускорителей серии Rialto Bridge, а в Falcon Shores было решено отказаться от гибридного подхода, к которому к этому моменту пришли и AMD, и NVIDIA. Впрочем, от ИИ-ускорителей Gaudi компания не отрекается. Intel не ответила на запрос о комментарии о будущем Falcon Shores. И основные разработчики, занимавшиеся этим проектом — Джейсон Маквей (Jason McVeigh) и Раджа Кодури (Raja Koduri) — либо ушли, либо были назначены на другие должности. Гелсингер признал, что Intel сильно отстаёт от своих конкурентов в области GPU и чипов для обучения ИИ, включая NVIDIA, AWS, Google Cloud и AMD. Впрочем, для AWS Intel будет производить в США кастомные процессоры Xeon 6 и ИИ-ускорители (вероятно, это наследники Trainium/Inferentia). 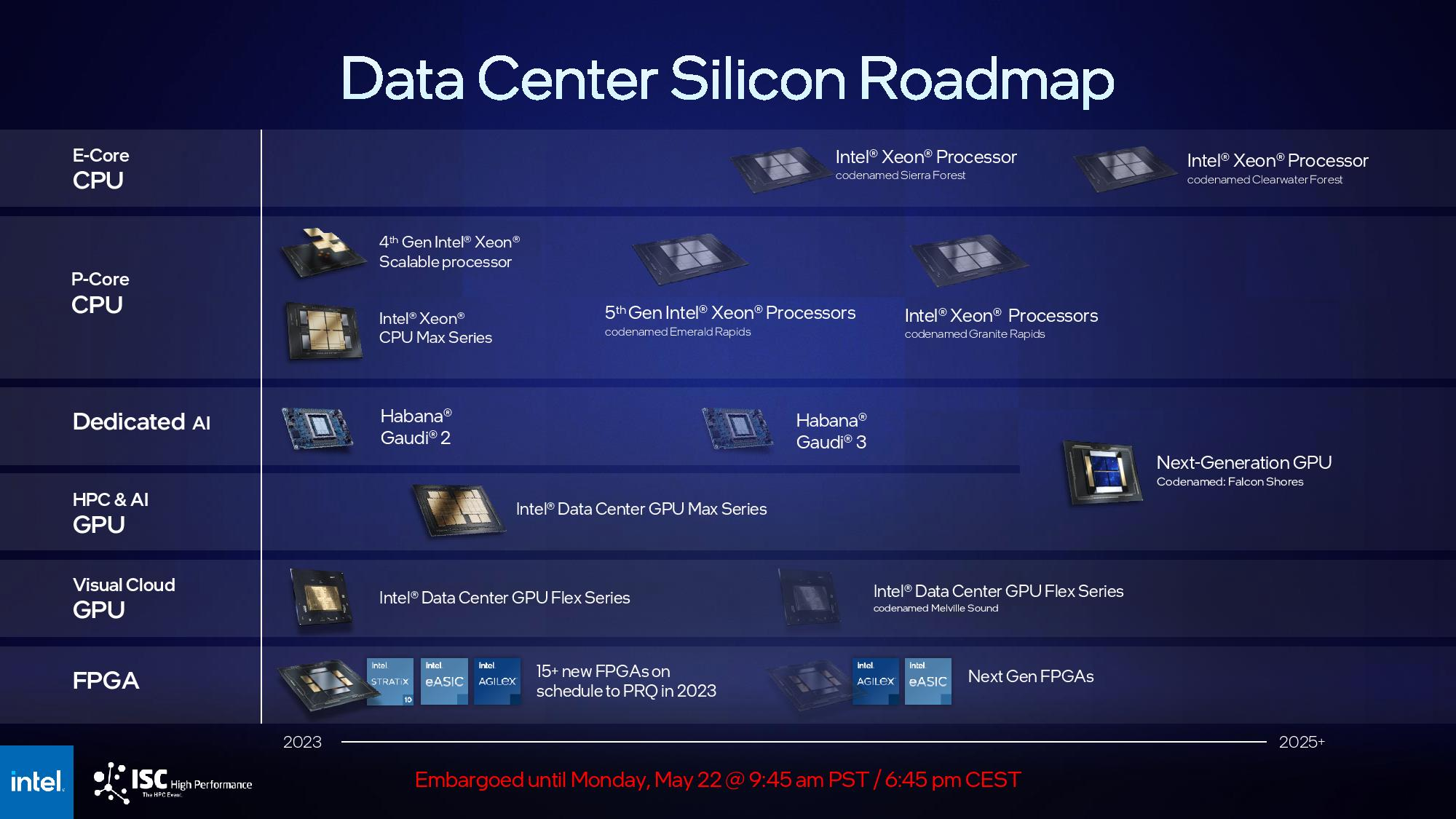
Источник изображения: Intel Также компания отметила отставание на рынке серверов для ЦОД, где сейчас большим спросом пользуются серверы с ИИ-ускорителями. «Где мы ещё не полностью вывели бизнес на хорошие позиции, так это в области CPU для ЦОД», — сообщил в этом месяце финансовый директор Intel Дэйв Цинснер (Dave Zinsner) на конференции Citi Global Technology Conference. Процессоры Xeon Emerald Rapids не оправдали ожиданий компании. Обычный цикл обновления гиперскейлеров в этот раз значительно растянулся, поскольку они активно вкладываются в развитие ИИ-инфраструктуры, попутно увеличивая срок службы традиционных серверов. Следующее поколение Granite Rapids (Xeon 6) должно выйти в начале следующего года. А Diamond Rapids, которые будут выпускаться по техпроцессу Intel 18A (1,8 нм), как ожидается, помогут вывести Intel на лидирующие позиции. Выход на производство по техпроцессу 18A с использованием новой структуры транзисторов RibbonFET и технологии PowerVia является для Intel одной из приоритетных задач. В частности, это техпроцес будет использоваться для выпуска серверных процессоров Clearwater Forest. Пока Intel под натиском AMD активно теряет долю рынка серверных CPU.
17.09.2024 [14:54], Руслан Авдеев
ByteDance разрабатывает собственные ИИ-ускорителями, но и от закупок чипов NVIDIA пока не отказываетсяПо данным The Information, китайская ByteDance, владеющая популярной социальной сетью TikTok, работает над выпуском собственных ИИ-чипов. Два вида чипов начнут производить на TSMC к 2026 году. Предполагается, что собственные разработки позволят китайскому IT-гиганту избавиться от зависимости от поставщиков вроде NVIDIA. Принято считать, что решения NVIDIA использует большинство компаний, участвующих в разработке ИИ-систем. Тем не менее, получить передовые ускорители довольно сложно из-за американских санкций, не раз ужесточавшихся и распространившихся даже на ослабленные ускорители. Из-за этого ByteDance приходится искать альтернативы. Экспорт чипов из США и других стран, использующих американские технологии, неоднократно ограничивали, а в июне появилась информация о том, что ByteDance сотрудничает с Broadcom над 5-нм решением, соответствующим всем ограничениям — его будет производить тайваньская TSMC. Также сообщалось, что ByteDance закупила в прошлом году чипы Ascend 910B, разработанные и продаваемые Huawei. Однако, по данным The Information, ByteDance пока что всё равно заказала 200 тыс. ускорителей NVIDIA H20 за более чем $2 млрд. С ними намного проще и удобнее работать, чем с решениями Huawei. 
Источник изображения: Claudio Schwarz/unsplash.com Разработка собственных чипов в ByteDance объясняется ростом интереса менеджмента компании к ИИ-технологиям — они применяются во многих решениях IT-гиганта, в том числе в рекомендательных системах TikTok. Разработка собственных продуктов позволит повысить производительность систем ByteDance при обучении моделей и инференсе. В Китае над собственными решениями в сфере ИИ-ускорителей работает не только ByteDance, но и, например, Baidu. ИИ-ускоритель Kunlun 3 тоже будет производить TSMC. При этом у Baodi гораздо более богатый опыт разработки ускорителей. Начав в 2010 году с FPGA, к 2020 году она перешла к созданию ASIC. В августе 2022 года ByteDance представила чат-бота на основе ИИ Doubao, он стал главным конкурентом Ernie Bot (разработан Baidu) в Китае. В мае под «зонтиком» бренда Doubao компания ByteDance представила большие языковые модели (LLM), рассчитанные на корпоративных клиентов. Модели относительно дёшевы в сравнении с продуктами конкурентов, предлагающими аналогичную функциональность.
17.09.2024 [13:20], Руслан Авдеев
ИИ без заморочек: VK запускает ML-платформу, которая не требует IT-навыковСилами центра аналитических продуктов VK Predict, входящего в группу VK, создана платформа для автоматического создания ML-моделей и работы с ИИ-решениями без глубокого знания информационных технологий. По данным Forbes, AutoML-платформа поможет выстроить стратегии развития, станет подспорьем маркетологам и позволит обучать ИИ-модели с компаниями-партнёрами без обмена закрытыми данными — на основе федеративного обучения. При этом ставка сделана на неспециалистов. Запускаемая VK платформа, например, позволяет оценивать бизнес-аналитикам рыночные позиции компании, выстроить стратегию развития бизнеса, решать маркетинговые задачи от сегментации аудитории до выявления самых рентабельных клиентов. Платформа подходит для прогнозирования показателей, сортировки данных по группам, включая формирование прогноза выручки той или иной торговой точки или сортировки пользователей по разным критериям. Платформу можно будет использовать в реальных проектах, для дополнительного обучения модели на базе новых источников и сведений. Далее появятся и другие возможности, включая тонкую настройку ИИ-моделей. 
Источник изображения: Possessed Photography / Unsplash Важной особенностью новой платформы является возможность совместного обучения компаниями общих ML-моделей с вертикальным федеративным обучением. Компании смогут использовать для обучения собственные датасеты, но обмен осуществляется только зашифрованными промежуточными данными — такая схема подходит для компаний разного профиля, включая бизнесы, действующие в сфере интернет-торговли и финтеха. Например, так можно рассчитать эффект от партнёрского маркетинга с общей аудиторией (в связке производитель-ретейлер). Автоматизации способствует поддержка принципа Low-Code. Целевой аудиторией для платформы считаются любые проекты, имеющие потребность в автоматизации работы с массивами данных, причём в компаниях могут работать специалисты без знаний в области Data Science. Впрочем, такая платформа хорошо подойдёт и экспертам в IT, желающим сэкономить время. 
Источник изображения: Wes Hicks / Unsplash В VK утверждают, что использование AutoML позволит в разы быстрее внедрять ML-модели, чем раньше. Монетизировать её планируется как по подписке в формате Self-Service, так и продавать в виде ядра для IT-отделов крупных компаний. По некоторым данным, в первом случае речь может идти о сумме от 250 тыс. руб./мес. Кастомизированное решение в варианте on-premise может стоить от 10 млн рублей за проект, без учёта оплаты поддержки и сопровождения. Эксперты сходятся в том, что подобные платформы вряд ли полностью заменят специалистов Data Science. При этом они смогут оказать им немалую помощь и ускорить вывод ML-моделей на рынок. Опрошенные Forbes эксперты отметили, что AutoML-платформы уже давно и активно применяются в крупных компаниях. Отечественные инструменты такого класса предлагааются в Yandex DataSphere, у «Сбера» есть фреймворк LightAutoML. Также используются открытые решения AutoGluon или FEDOT. |
|

