Материалы по тегу: чиплеты
|
29.09.2025 [17:53], Владимир Мироненко
Euclyd разрабатывает ИИ-ускоритель Craftwerk с фирменной памятью UBM: 1 Тбайт и 8 Пбайт/сСтартап Euclyd, вышедший из скрытого режима (stealth mode), рассказал на саммите AI Infra Summit некоторые подробности о разрабатываемом чипе, который обеспечит более низкое энергопотребление и более низкую стоимость в расчёте на токен по сравнению с существующими решениями, пишет ресурс EE Times. Сама компания называет его первым в мире «кремнием» для агентного ИИ. Ингольф Хелд (Ingolf Held), соучредитель и вице-президент по продуктам Euclyd, сообщил ресурсу EE Times, что чип представляет собой огромную конструкцию из множества чиплетов, объединённых в модуль SiP (System-in-Package) под названием Craftwerk. Он будет включать 16 384 SIMD-блоков и обеспечивать производительность до 8 Пфлопс (FP16) или 32 Пфлопс (FP4). Эти вычислительные элементы разработаны Euclyd с нуля. В устройстве будет использоваться кремниевый интерпозер с максимально крупными размерами (примерно 100 × 100 мм) с 2,5D- и 3D-компонентами. 
Источник изображений: Euclyd «Мы разработаем его сами — мы не будем наследовать ничего от Arm или RISC-V, и он будет полностью программируемым с помощью наших собственных инструментов», — сказал он. По словам Хелда, дизайн будет поддерживать программируемость, чтобы гарантировать возможность ускорения будущих нагрузок, будь то мультимодальный инференс, логические рассуждения, рекуррентные модели, модели пространства состояний или диффузионные модели. Euclyd объединит вычислительные чиплеты с кастомной памятью Ultra Bandwidth Memory (UBM) — 1 Тбайт DRAM с пропускной способностью 8000 Тбайт/с в той же упаковке Craftwerk. По словам Хелда, ИИ-ускорители со SRAM работают быстро, но при их использовании приходится разделять обработку ИИ-нагрузки между множеством чипов из-за малого объёма такой памяти. HBM имеет достаточную ёмкость, но её пропускная способность мала для решения задач, поставленных Euclyd. И хотя UBM от Euclyd отличается кастомным дизайном, для её изготовления не потребуется какой-то экзотический технологический процесс. Craftwerk позволит реализовать многоагентные рабочие процессы на одном кристалле кремния с TDP в пределах 3 кВт, отметил Хелд. По словам компании, NVIDIA DGX-B200 может обрабатывать 1038 токенов/с для одного пользователя Llama4-Maverick (400B), Cerebras предлагает 2554 токена/с для одного пользователя, а один SiP Craftwerk будет обрабатывать 20 тыс. токенов/с для одного пользователя. Стойка Euclyd будет включать 16 хост-процессоров и 32 модуля Craftwerk в шасси с жидкостным охлаждением с общим TDP 125 кВт. По оценкам Euclyd, в типичном многопользовательском сценарии эта система будет предлагать 7,68 млн токенов/с для Llama4-Maverick. 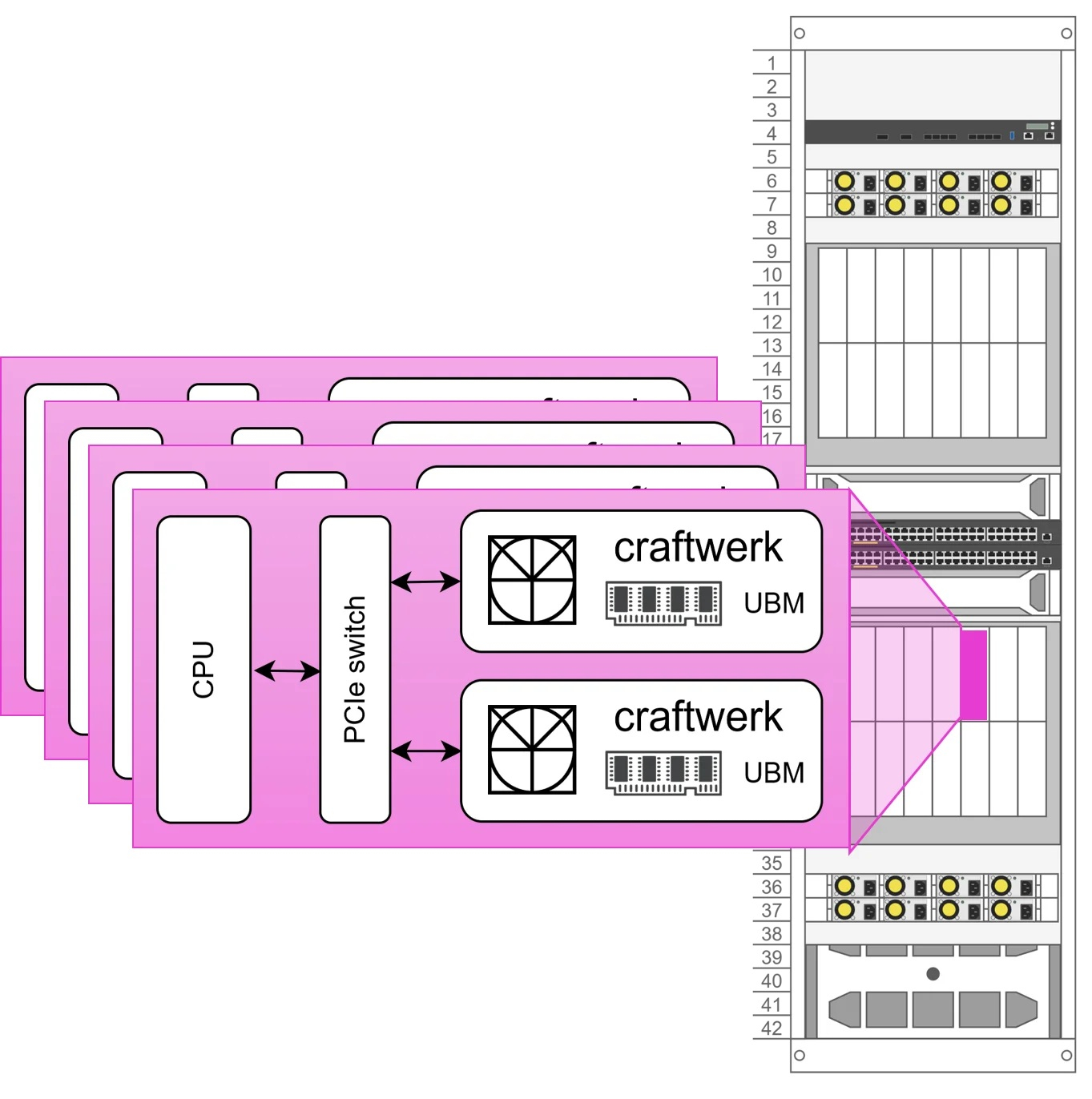 На данный момент у Euclyd три частных инвестора: Питер Веннинк (Peter Wennink, бывший генеральный директор ASML), Федерико Фаггин (Federico Faggin, один из изобретателей микропроцессора и основатель Zilog и Synaptics) и Стивен Шурман (Steven Schuurman, основатель Elastic). В ближайшее время компания планирует привлечь венчурный капитал для запуска производства и масштабирования, но, по словам Хелда, посевного финансирования должно быть достаточно для демонстрации работоспособности кремниевых чипов. Сооснователь и консультант Euclyd Атул Синха (Atul Sinha) заявил EE Times, что Европа лучшее место для талантливых дизайнеров, чем Кремниевая долина. Он подтвердил, что Euclyd планирует оставаться в юрисдикции Нидерландов со штаб-квартирой ИТ-кампусе Эйндховена, где также находится штаб-квартира NXP. «Чего люди не понимают, так это то, что в Европе есть места, где действительно есть значительный набор технологий и кадровая база, — сказал Синха. — Для полупроводников Эйндховен, безусловно, на первом месте. Я бы сказал, что лучше места нет».
03.04.2025 [16:42], Владимир Мироненко
Ayar Labs анонсировала фотонный UCIe-чиплет TeraPHY с пропускной способностью 8 Тбит/сКомпания Ayar Labs, занимающаяся разработкой интерконнекта на базе кремниевой фотоники, анонсировала чиплет оптического I/O TeraPHY, способный обеспечить пропускную способность 8 Тбит/с и использующий оптический источник света SuperNova с поддержкой 16 длин волн. Чиплет поддерживает интерфейс Universal Chiplet Interconnect Express (UCIe), что означает возможность объединения в одном решении чиплетов от разных поставщиков. Ayar Labs отметила, что совместимость со стандартом UCIe позволяет создать более доступную и экономичную экосистему, которая упрощает внедрение передовых оптических технологий, необходимых для масштабирования рабочих ИИ-нагрузок и преодоления ограничений традиционных медных соединений. 
Источник изображений: Ayar Labs Ayar Labs сообщила, что объединила кремниевую фотонику с производственными процессами CMOS, чтобы обеспечить использование оптических соединений в форм-факторе чиплета в многочиповых корпусах. Это позволяет GPU и другим ускорителям взаимодействовать на широком диапазоне расстояний, от миллиметров до километров, при этом эффективно функционируя как единый гигантский ускоритель. Ранее компания совместно с Fujitsu показал концепт процессора A64FXс UCIe-чиплетом TeraPHY.  Марк Уэйд (Mark Wade), генеральный директор и соучредитель Ayar Labs заявил, что в компании давно увидели потенциал совместно упакованной оптики (CPO), и поэтому занялись внедрением оптических решений в ИИ-приложениях. «Продолжая расширять границы оптических технологий, мы объединяем цепочку поставок, производство, а также процессы тестирования и проверки, необходимые клиентам для масштабного развёртывания этих решений», — подчеркнул он. Среди партнёров Ayar Labs крупнейшие компании отрасли, включая AMD, Intel, NVIDIA и TSMC. В последнем раунде финансирования, прошедшем в декабре прошлого года, компания привлекла $155 млн. Рыночная стоимость Ayar Labs, по оценкам, составляет $1 млрд.
12.03.2025 [20:37], Владимир Мироненко
Евросоюз потратит €240 млн на создание трёх RISC-V чиплетов для суперкомпьютеров в рамках проекта DARE
eurohpc
hardware
hpc
risc-v
европа
ии
импортозамещение
инвестиции
суперкомпьютер
ускоритель
финансы
чиплеты
Digital Autonomy with RISC-V in Europe (DARE), крупнейший проект по разработке чипов из когда-либо финансируемых Европейским союзом, созданный с целью укрепления технологического суверенитета Европы в области высокопроизводительных вычислений (HPC) и искусственного интеллекта (ИИ), официально начал первый этап DARE SGA1, на реализацию которого выделено €240 млн ($262 млн), сообщается на сайте проекта. Европа и Китай делают ставку на RISC-V. Финансирование инициативы обеспечат 38 участников, включая ИТ-компании, исследовательские институты и университеты по всей Европе. Проект поддерживается EuroHPC JU и координируется Барселонским суперкомпьютерным центром (BSC-CNS). Последний имеет богатый опыт разработки чипов RISC-V и суперкомпьютерных систем. Половина инвестиций в проект DARE будет предоставлена Европейской комиссией через EuroHPC, а другая половина поступит напрямую от европейских партнёров, включая €34 млн от Министерства науки, инноваций и университетов Испании. Рассчитанный на три года DARE SGA1 является первым этапом шестилетней инициативы DARE. Цель — создание полноценного независимого европейского суперкомпьютерного программно-аппаратного стека для HPC и ИИ, включая чипы, системы на основе чиплетов и ПО. Инициатива направлена на удовлетворение стратегической потребности Европы в цифровом суверенитете и получения полного контроля над критической вычислительной инфраструктурой. 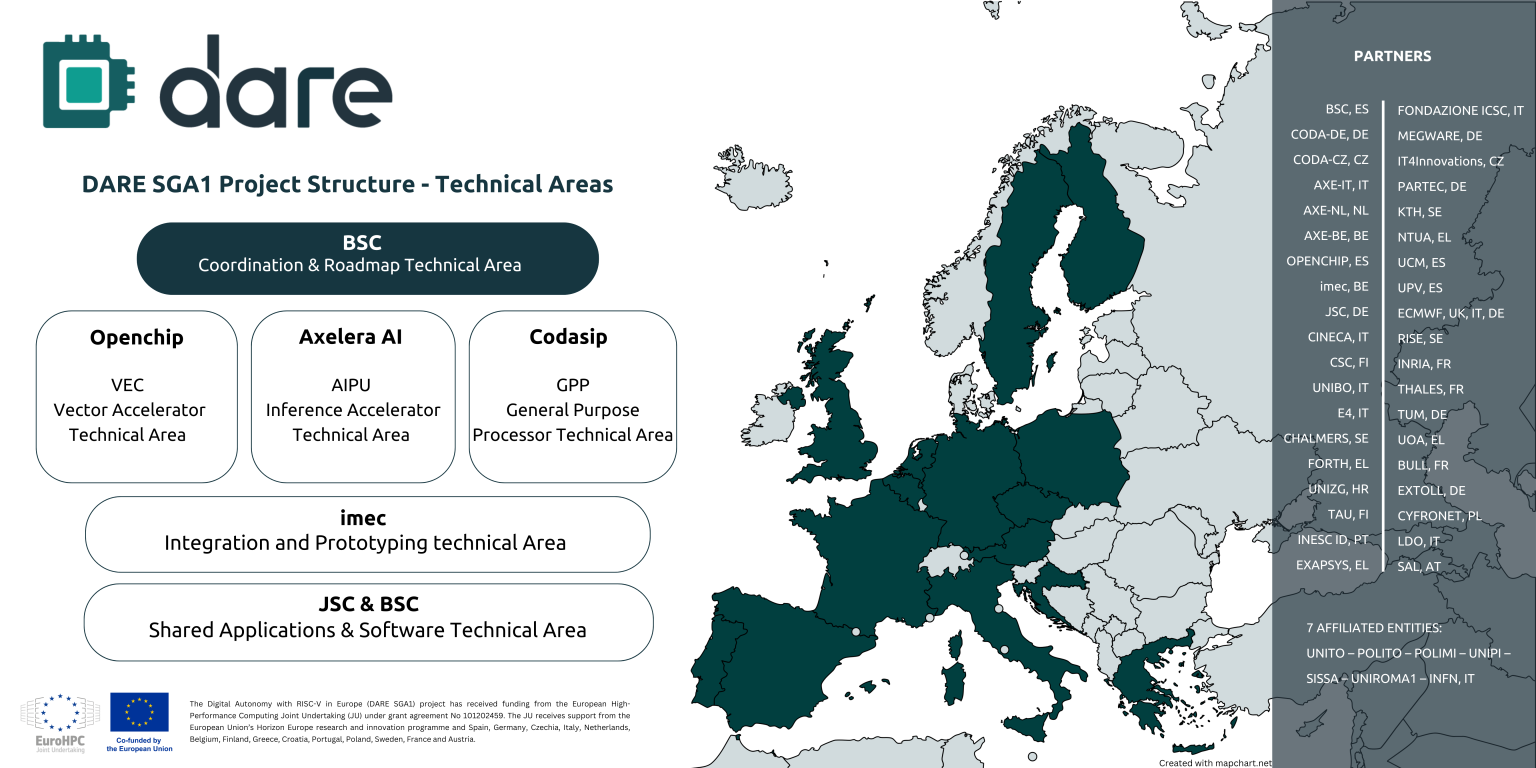
Источник изображения: DARE Проектом DARE SGA1 предусмотрена разработка трёх чиплетов на основе архитектуры RISC-V, каждый из которых будет выполнять критически важную функцию в вычислениях HPC и ИИ:
В дополнение к указанным компаниям в качестве технических лидеров названы imec и Юлихский исследовательский центр (JÜLICH Supercomputing centre, JSC), которые будут продвигать ключевые инновации в рамках проекта. Помимо координации усилий, BSC также возглавит разработку планов и будет участвовать в разработке программных и аппаратных решений. Изготавливаться чиплеты будут по технологии CMOS с использованием современных техпроцессов. Axelera получит на разработку до €61 млн при условии выполнения различных задач в течение следующих трёх лет, рассказал ресурсу EE Times генеральный директор Axelera Фабрицио дель Маффео (Fabrizio del Maffeo). Хотя нынешний чип Axelera Metis AIPU предназначен для периферийных систем, дель Маффео сказал, что разрабатываемый в рамках DARE продукт на основе чиплетов не несёт кардинальные изменения, речь скорее о масштабировании. Codasip в прошлом году анонсировала 64-бит чип X730 на базе RISC-V с архитектурной защитой CHERI. По данным The Next Platform, за последнее десятилетие компания привлекла $34,6 млн общего финансирования, включая средства в рамках различных инициатив ЕС, а также посевной раунд в размере $2,5 млн в 2016 году и раунд A в размере $10 млн в 2018 году.
17.07.2024 [15:49], Руслан Авдеев
DreamBig Semiconductor получила $75 млн на развитие чиплетной платформы нового поколенияСтартап DreamBig Semiconductor получил $75 млн инвестиций. Всего, по данным Silicon Angle, за время своего существования компания привлекла $93 млн. Основанный в 2019 году стартап является создателем MARS Platform — открытой чиплетной платформы для создания решений с передовой 3D-упаковкой. Она, по словам компании, позволит создать новое поколение ИИ-чипов. Последний раунд финансирования возглавляли Samsung Catalyst Fund и Sutardja Family, участие приняли новые инвесторы в лице Hanwha, Event Horizon и Raptor. Средства дали и партнёры, уже поддержавшие проект — UMC Capital, BRV, Ignite Innovation Fund и Grandfull Fund. В компании объявили, что полученные средства потратят на ускорение развития стандарта чиплетов и коммерциализацию, а также на платформу разработки Chiplet Hub. 
Источник изображения: DreamBig Ожидается, что MARS позволит клиентам сконцентрировать усилия на достижении нужных именно им характеристик чипов, а открытость платформы позволит сэкономить средства. По словам DreamBig, стандарт чиплетов MARS позволит решит проблему масштабирования вычислений и интерконнекта. Заказчики смогут использоваться базовые чиплеты для добавления той или иной функциональности к своему чипу. Заявляется, что MARS, впервые сможет обеспечить прямой доступ к SRAM и DRAM в дополнение к HBM. Для объединения кристаллов будут использоваться UCIe и BoW (Bunch of Wires), а для общения — протоколы AMBA. Платформа подходит для конструирования вычислительных чипов, ИИ-ускорителей или сетевых решений (DPU). DreamBig стала последней в серии стартапов, занятых разработкой ИИ-чипов, сумевших привлечь миллионы долларов инвестиций в этом году. Так, Etched.ai сообщил о привлечении $120 млн для того, чтобы помериться силами с NVIDIA. DEEPX привлёк $80,5 млн, SiMA Technologies получила $70 млн, а Hailo выделили $120 млн.
21.10.2023 [01:01], Алексей Степин
Собери сам: Arm открывает эру кастомных серверных процессоров инициативой Total DesignСегодня на наших глазах в мире процессоростроения происходит серьёзная смена парадигм: от унифицированных архитектур общего назначения и монолитных решений разработчики уходят в сторону модульности и активного использования специфических аппаратных ускорителей. Разумеется Arm не осталась в стороне — на мероприятии 2023 OCP Global Summit компания рассказала о новой инициативе Arm Total Design. Эта инициатива должна помочь как создателям новых процессоров за счёт ускорения процесса разработки и снижения его стоимости, так и владельцам крупных вычислительных инфраструктур. Последние всё больше склоняются к специализации и дифференциации в процессорных архитектурах новых поколений, но ожидают также энергоэффективности, дружественности к экологии и как можно более низкой совокупной стоимости владения. 
Источник изображений здесь и далее: Arm В основе инициативы Arm лежит анонсированная ещё в августе на HotChips 2023 процессорная платформа Arm Neoverse Compute Subsystem (CSS). Neoverse CSS N2 (Genesis) представляет собой готовый набор IP-решений Arm, включающий в себя процессорные ядра, внутреннюю систему интерконнекта, подсистемы памяти, ввода-вывода, управлениям питанием, но оставляющий место для интеграции партнёрских разработок — различных движков, ускорителей и т.п.  По сути, речь идёт о почти готовых процессорах, не требующих длительной разработки процессорной части с нуля и всех связанных с этим процессом действий — верификации, тестирования на FPGA, валидации дизайна и многого другого. По словам Arm такой подход позволяет сэкономить разработчикам до 80 человеко-лет труда инженеров. 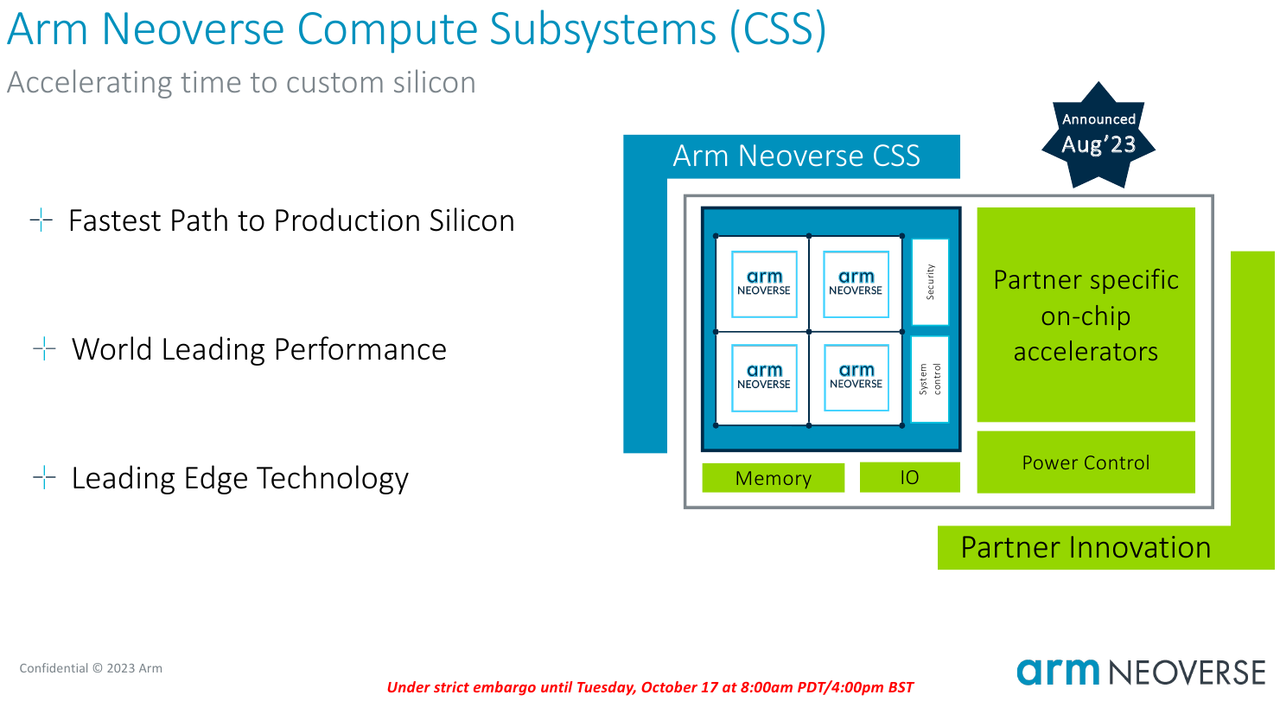 Дизайн Neoverse CSS N2 довольно гибок: финальный процессор может включать в себя от 24 до 64 ядер Arm, работающих в частотном диапазоне 2,1–3,6 ГГц. Предусмотрено по 64 Кбайт кеша инструкций и данных, а вот объёмы кешей L2 и L3 настраиваются и могут достигать 1 и 64 Мбайт соответственно. Ядра реализуют набор инструкций Arm v9 и содержат по два 128-битных векторных блока SVE2. Имеется поддержка инструкций, характерных для ИИ-задач и криптографиии. 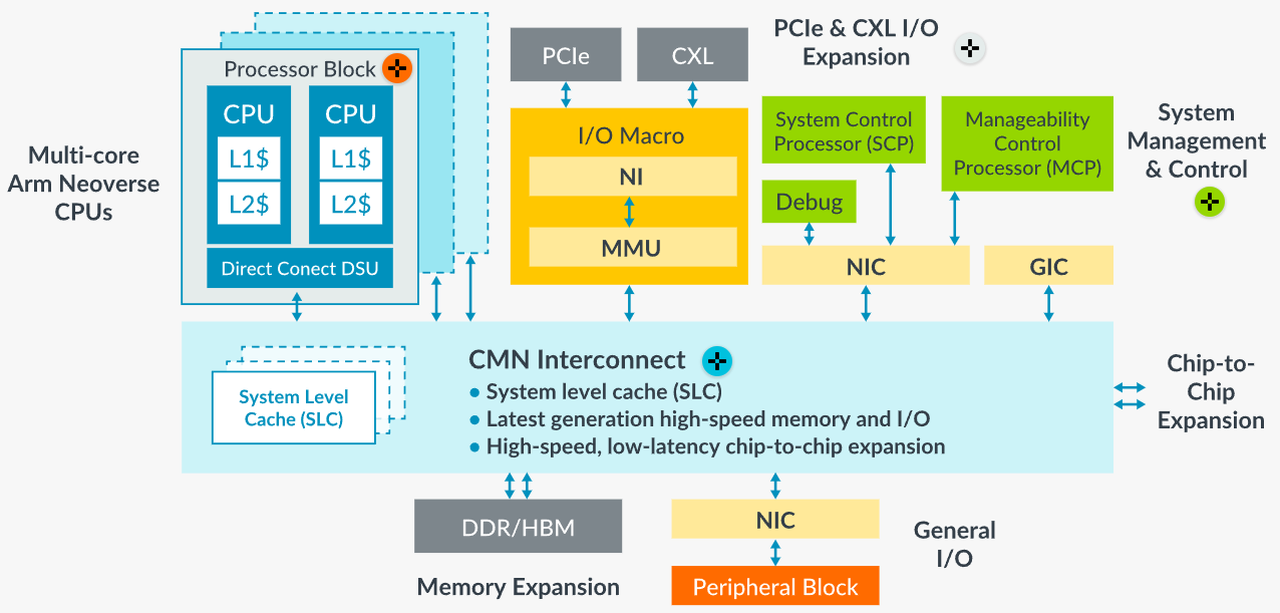 Подсистема памяти может иметь до 8 каналов DDR5, а возможности ввода-вывода включают в себя 4 блока по 16 линий PCIe или CXL. Также возможно объединение двух чипов CSS N2 в едином корпусе, что даёт до 128 ядер на чип. В качестве внутреннего интерконнекта используется меш-сеть Neoverse CMN-700. В дизайне Neoverse CSS N2 имеются и вспомогательные ядра Cortex-M7. Они работают в составе блоков System Control Processor (SCP) и Management Control Processor (MCP), то есть управляют работой основного вычислительного массива, в том числе отвечая за его питание и тактовые частоты.  Инициатива Arm Total Design расширяет рамки Neoverse Compute Subsystem: речь идёт о создании полноценной экосистемы, обеспечивающей эффективную коммуникацию между партнёрами программы Neoverse CSS и предоставление им полноценного IP-инструментария и EDA, созданных при участии Cadence, Rambus, Synopsys и др. Также подразумевается поддержка ведущих производителей «кремния» и разработчиков прошивок, в частности, AMI. В число участников проекта уже вошли такие компании, как ADTechnology, Alphawave Semi, Broadcom, Capgemini, Faraday, Socionext и Sondrel. Ожидается поддержка от Intel Foundry Services и TSMC, позволяющая говорить об эффективной реализации необходимых для мультичиповых решений технологий AMBA CHI C2C и UCIe. 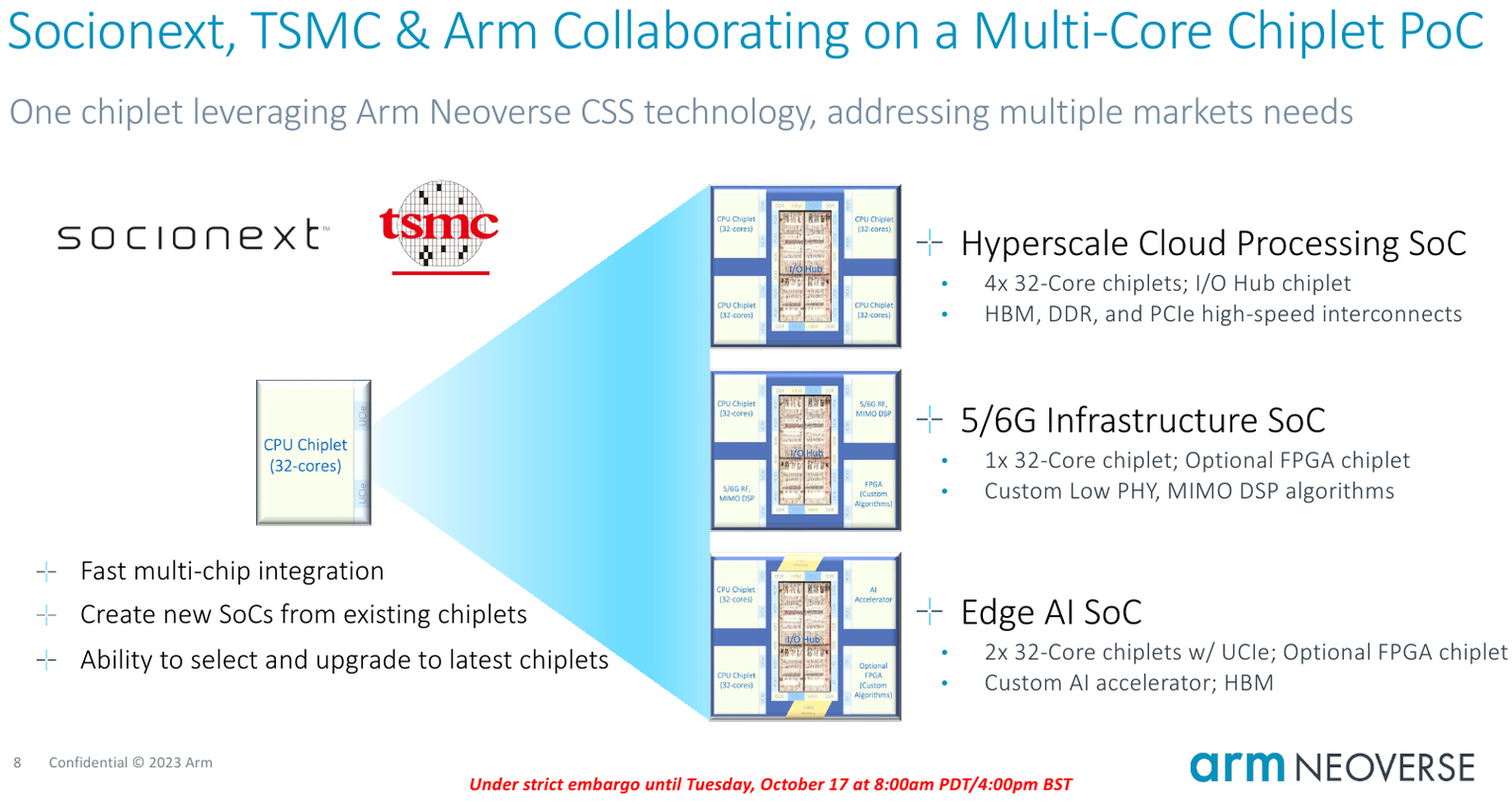 Будучи объединённым под одной крышей инициативы Arm Total Design, такой конгломерат ведущих разработчиков и производителей микроэлектроники и системного ПО для него, сможет в кратчайшие сроки не просто создавать новые процессоры, но и гибко отвечать на вызовы рынка ЦОД и HPC, наделяя чипы поддержкой востребованных технологий и ускорителей. В качестве примера можно привести совместный проект Arm, Socionext и TSMC, в рамках которого ведётся разработка универсального чиплетного процессора, который в различных вариантах компоновки будет востребован гиперскейлерами, поставщиками инфраструктуры 5G/6G и разработчиками периферийных ИИ-систем. |
|

