Материалы по тегу: s
|
19.09.2019 [21:46], Андрей Созинов
Atos BullSequana XH2000 на процессорах EPYC 7H12 установила ряд мировых рекордовНовая версия суперкомпьютерного узла BullSequana XH2000 компании Atos, построенная на новейших 64-ядерных процессорах AMD EPYC 7H12, смогла установить сразу несколько абсолютных мировых рекордов производительности.  Новинка была протестирована самой Atos в пакете бенчмарков SPECrate 2017, который как раз и предназначен для оценки производительности мощных вычислительных систем. По результатам тестов, новинка претендует на звание рекордсмена среди всех двухпроцессорных систем в четырёх бенчмарках пакета: 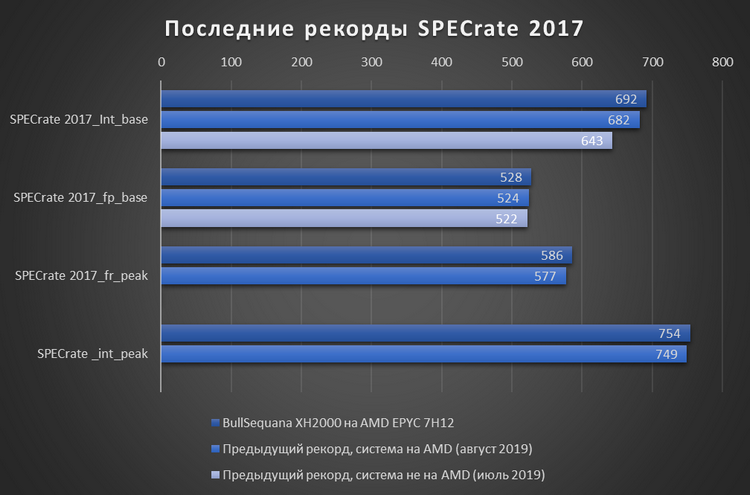 На данный момент представленные Atos результаты тестов проходят проверку комитетом SPEC. Кроме того, Atos заявляет, что система BullSequana XH2000 на базе EPYC 7H12 установила рекорд в бенчмарке HPL Linpack для систем на процессорах AMD. Новинка показала результат в 4,296 Тфлопс, что на 11 % больше результата системы с процессорами AMD EPYC 7742. 
Atos оставляет системы AMD для ряда европейских суперкомпьютеров Прирост производительности обусловлен тем, что средняя рабочая частота процессора EPYC 7H12 выше по сравнению с моделью EPYC 7742. А чтобы справиться с тепловыделением, увеличившимся вместе с частотой, компания Atos использует в BullSequana XH2000 систему жидкостного охлаждения. |
|

