Материалы по тегу: s
|
07.12.2021 [00:36], Алексей Степин
ИИ-ускорители AWS Trainium: 55 млрд транзисторов, 3 ГГц, 512 Гбайт HBM и 840 Тфлопс в FP32GPU давно применяются для ускорений вычислений и в последние годы обросли поддержкой специфических форматов данных, характерных для алгоритмов машинного обучения, попутно практически лишившись собственно графических блоков. Но в ближайшем будущем их по многим параметрам могут превзойти специализированные ИИ-процессоры, к числу которых относится и новая разработка AWS, чип Trainium. На мероприятии AWS Re:Invent компания рассказала о прогрессе в области машинного обучения на примере своих инстансов P3dn (Nvidia V100) и P4 (Nvidia A100). Первый вариант дебютировал в 2018 году, когда модель BERT-Large была примером сложности, и благодаря 256 Гбайт памяти и сети класса 100GbE он продемонстрировал впечатляющие результаты. Однако каждый год сложность моделей машинного обучения растёт почти на порядок, а рост возможностей ИИ-ускорителей от этих темпов явно отстаёт. 
Сложность моделей машинного обучения будет расти всё быстрее Когда в прошлом году был представлен вариант P4d, его вычислительная мощность выросла в четыре раза, а объём памяти и вовсе на четверть, в то время как знаменитая модель GPT-3 превзошла по сложности BERT-Large в 500 раз. А теперь и 175 млрд параметров последней — уже ничто по сравнению с 10 трлн в новых моделях. Приходится наращивать и объём локальной памяти (у Trainium имеется 512 Гбайт HBM с суммарной пропускной способностью 13,1 Тбайт/с), и активнее использовать распределённое обучение.  Для последнего подхода узким местом стала сетевая подсистема, и при разработке стека Elastic Fabric Adapter (EFA) компания это учла, наделив новые инстансы Trn1 подключением со скоростью 800 Гбит/с (вдвое больше, чем у P4d) и с ультранизкими задержками, причём доступен и более оптимизированный вариант Trn1n, у которого пропускная способность вдвое выше и достигает 1,6 Тбит/с. Для связи между самими чипами внутри инстанса используется интерконнект NeuroLink со скоростью 768 Гбайт/с. 
Прогресс подсистем сети и памяти в ИИ-инстансах AWS Но дело не только в возможности обучить GPT-3 менее чем за две недели: важно и количество используемых для этого ресурсов. В случае P3d это потребовало бы 600 инстансов, работающих одновременно, и даже переход к архитектуре Ampere снизил бы это количество до 200. А вот обучение на базе чипов Trainium требует всего 130 инстансов Trn1. Благодаря оптимизациям, затраты на «общение» у новых инстансов составляют всего 7% против 14% у Ampere и целых 49% у Volta. 
Меньше инстансов, выше эффективность при равном времени обучения — вот что даст Trainium Trainium опирается на систолический массив (Google использовала тот же подход для своих TPU), т.е. состоит из множества очень тесно связанных вычислительных блоков, которые независимо обрабатывают получаемые от соседей данные и передают результат следующему соседу. Этот подход, в частности, избавляет от многочисленных обращений к регистрам и памяти, что характерно для «классических» GPU, но лишает подобные ускорители гибкости.  В Trainium, по словам AWS, гибкость сохранена — ускоритель имеет 16 полностью программируемых (на С/С++) обработчиков. Есть и у него и другие оптимизации. Например, аппаратное ускорение стохастического округления, которое на сверхбольших моделях становится слишком «дорогим» из-за накладных расходов, хотя и позволяет повысить эффективность обучения со смешанной точностью. Всё это позволяет получить до 3,4 Пфлопс на вычислениях малой точности и до 840 Тфлопс в FP32-расчётах. 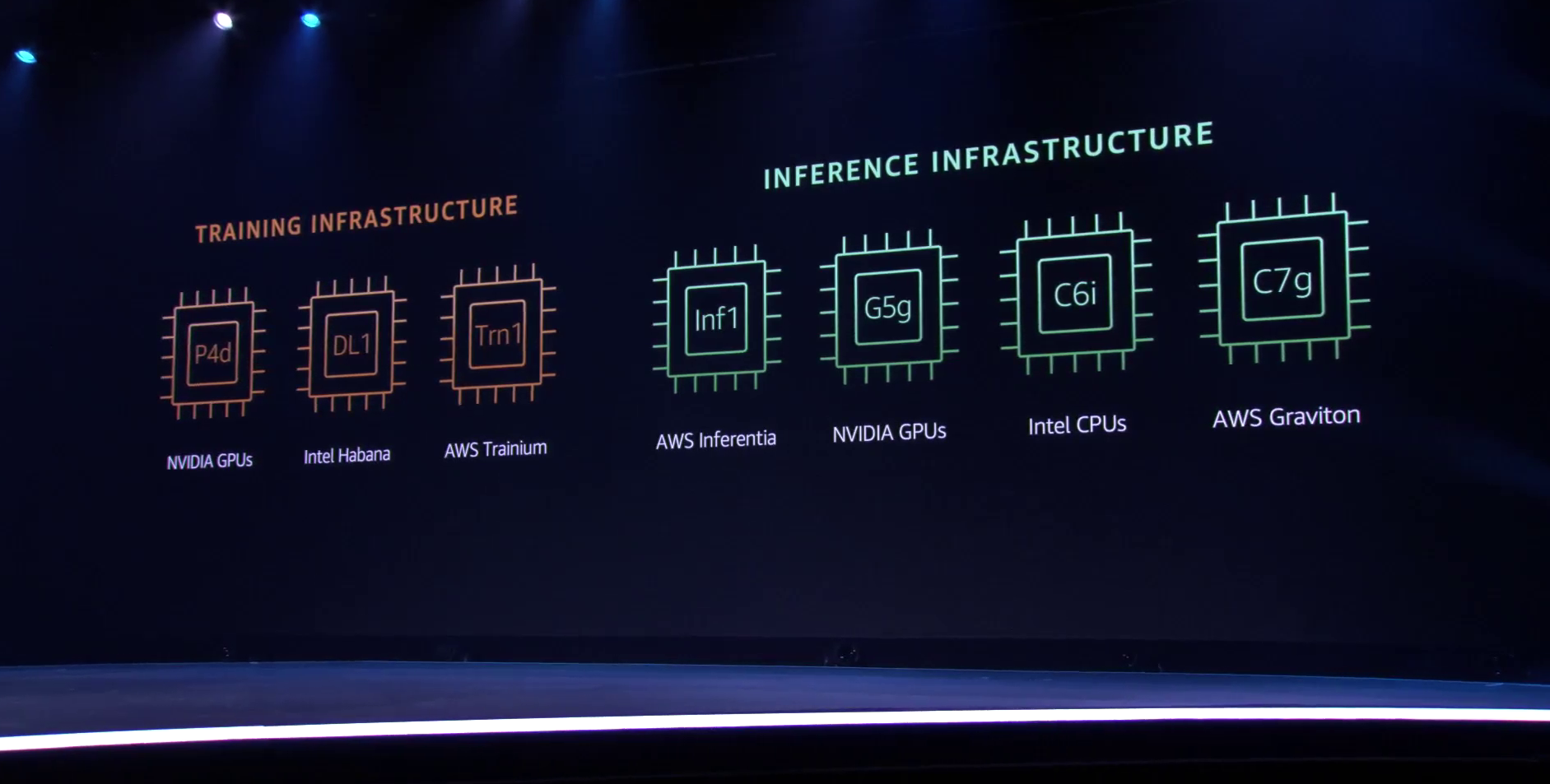 AWS постаралась сделать переход к Trainium максимально безболезненным для разработчиков, поскольку SDK AWS Neuron поддерживает популярные фреймворки машинного обучения. Впрочем, насильно загонять заказчиков на инстансы Trn1 компания не собирается и будет и далее предоставлять на выбор другие ускорители поскольку переход, например, с экосистемы CUDA может быть затруднён. Однако в вопросах машинного обучения для собственных нужд Amazon теперь полностью независима — у неё есть и современный CPU Graviton3, и инфереренс-ускоритель Inferentia.
04.12.2021 [03:42], Игорь Осколков
Процессор Amazon Graviton3: 64 ядра Arm, 5-нм техпроцесс, чиплетная компоновка и DDR5 с PCIe 5.0Анонсированный на днях Arm-процессор Graviton3, создававшийся специально для нужд Amazon и AWS, неожиданно оказался по ряду параметров на голову выше ещё даже не вышедших EPYC и Xeon следующего поколения. И это не самый хороший сигнал для AMD, Intel, Qualcomm и прочих производителей. 
Amazon Graviton3. Фото: Ian Colle Graviton3 — первый массовый (самой Amazon и рядом избранных клиентов он используется уже не один месяц) серверный процессор с поддержкой DDR5 и PCIe 5.0. CPU выполнен по 5-нм техпроцессу TSMC и содержит примерно 55 млрд транзисторов. Для удешевления он использует BGA-корпусировку и чиплетную компоновку из семи отдельных кристаллов — два PCIe-контроллера и четыре двухканальных контроллера DDR5 вынесены за пределы собственно CPU. 
Узел EC2 C7g. Здесь и ниже изображения Amazon AWS Более того, их упаковка использует передовые решения с каналами длиной менее 55 мкм, что вдвое меньше, чем у других серверных CPU. Уменьшение длины проводников положительно сказывается на энергоэффективности, которая очень важна для любого гиперскейлера. Этим же объясняется и относительно небольшое по современным меркам число ядер (всего 64) и их частота (2,6 ГГц). Всё это позволило добиться энергопотребления примерно в 100 Вт. 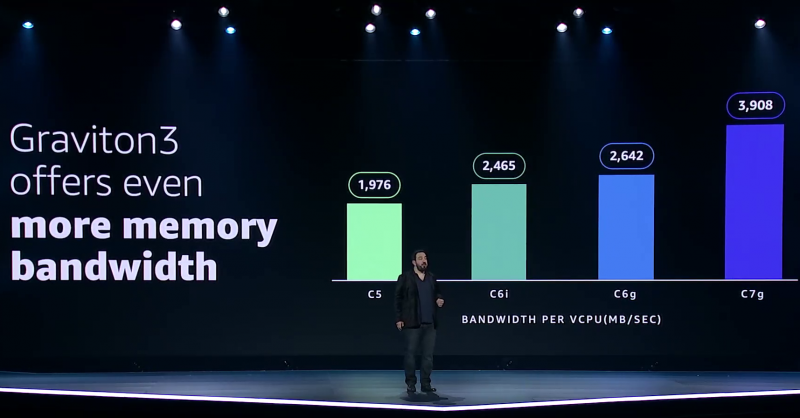 Есть и ещё один важный плюс в сохранении числа ядер — переход на DDR5-4800 позволил не только достичь пиковой суммарной пропускной способности памяти в 300 Гбайт/с на чип, но и повысить реальную скорость работы с памятью каждого vCPU (фактически ядра) в полтора раза по сравнению с прошлым поколением. Та же ситуация и с PCIe 5.0 — для достижения той же пропускной способности, что ранее, нужно вдвое меньше линий.  Для удешевления используются готовые IP-блоки сторонних компаний и, судя по всему, ядра тоже несильно отличаются от референсов Arm. А вот какие именно, узнаем не сразу, поскольку Amazon явно не указала, будут ли это Neoverse V1 (Zeus) или N2 (Perseus). Вероятно, это всё же V1 (ARMv8.5-A), поскольку по описанию Graviton3 похожи именно на эту архитектуру. Новые ядра стали значительно «шире» прежних — они забирают 8 инструкций, декодируют от 5 до 8 из них и отправляют на исполнение сразу 15 инструкций. Соответственно и число исполнительных блоков по сравнению с Neoverse-N1 (Graviton2) практически удвоилось. 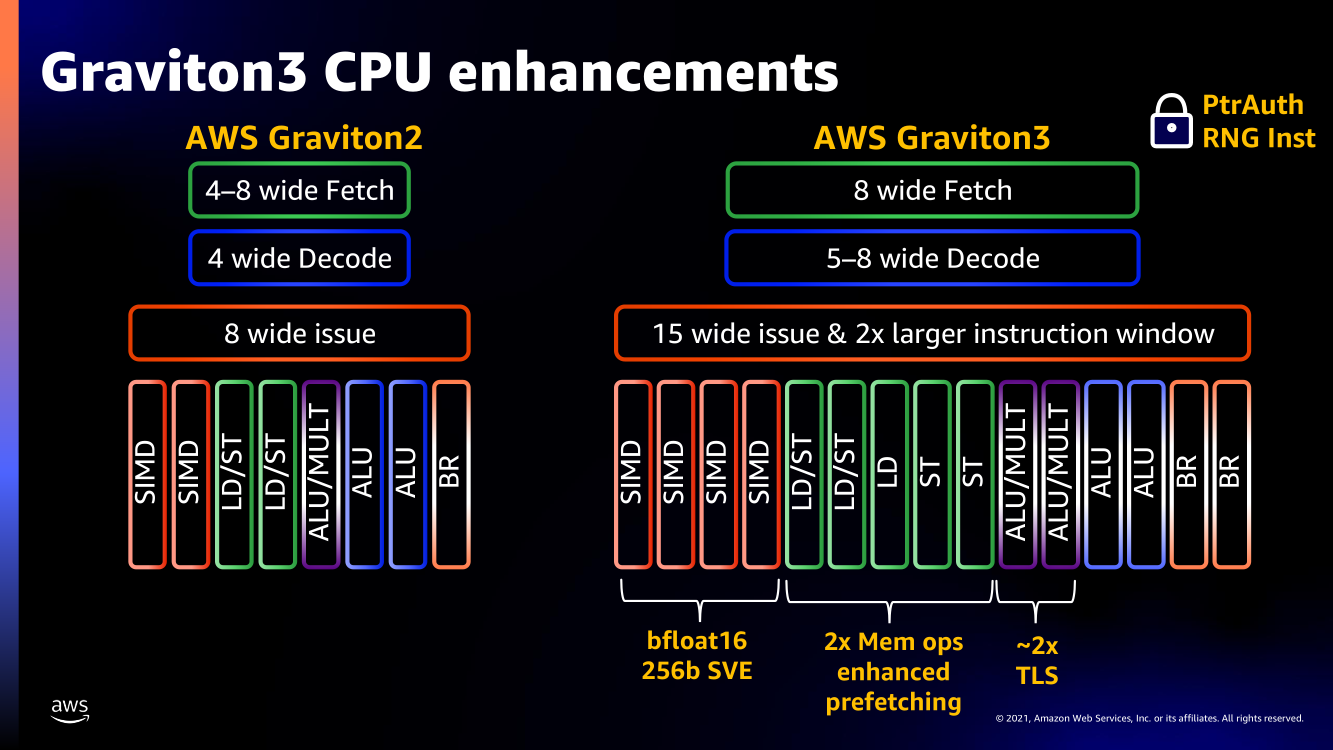  Кроме того, они обзавелись поддержкой 256-бит векторных инструкций SVE, что повысило не только скорость выполнения «классических» FP-операций (например, для задач медиакодирования и шифрования), но и благодаря поддержке bfloat16 позволило утверждать Amazon, что новые чипы годятся и для инференса. Среди упомянутых ранее мер защиты есть, например, принудительное шифрование оперативной памяти, изолированные кеши для каждого vCPU (ядра), аппаратная защита стека. 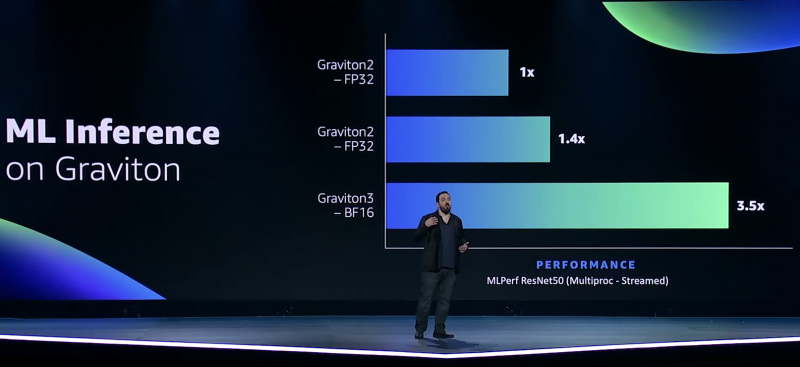
В подписи второго столбца явная опечатка В целом, средний прирост производительности Graviton3 по сравнению с Graviton2 составил 25 %, но в некоторых задачах он достигает 60 %. И всё это при сохранении того же уровня энергопотребления и тепловыделения. Всё это позволило уместить в одном 1U-узле с воздушным охлаждением сразу три процессора Graviton3. И они разительно отличаются от грядущих 128-ядерных процессоров Altra Max и EPYC Bergamo, которые Ampere и AMD позиционируют как решения для гиперскейлеров. Зато в чём-то похожи на Yitian 710 от Alibaba Cloud. 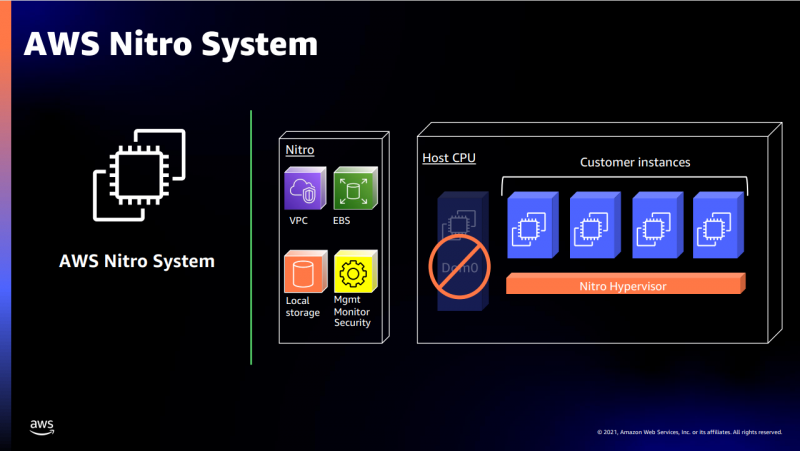 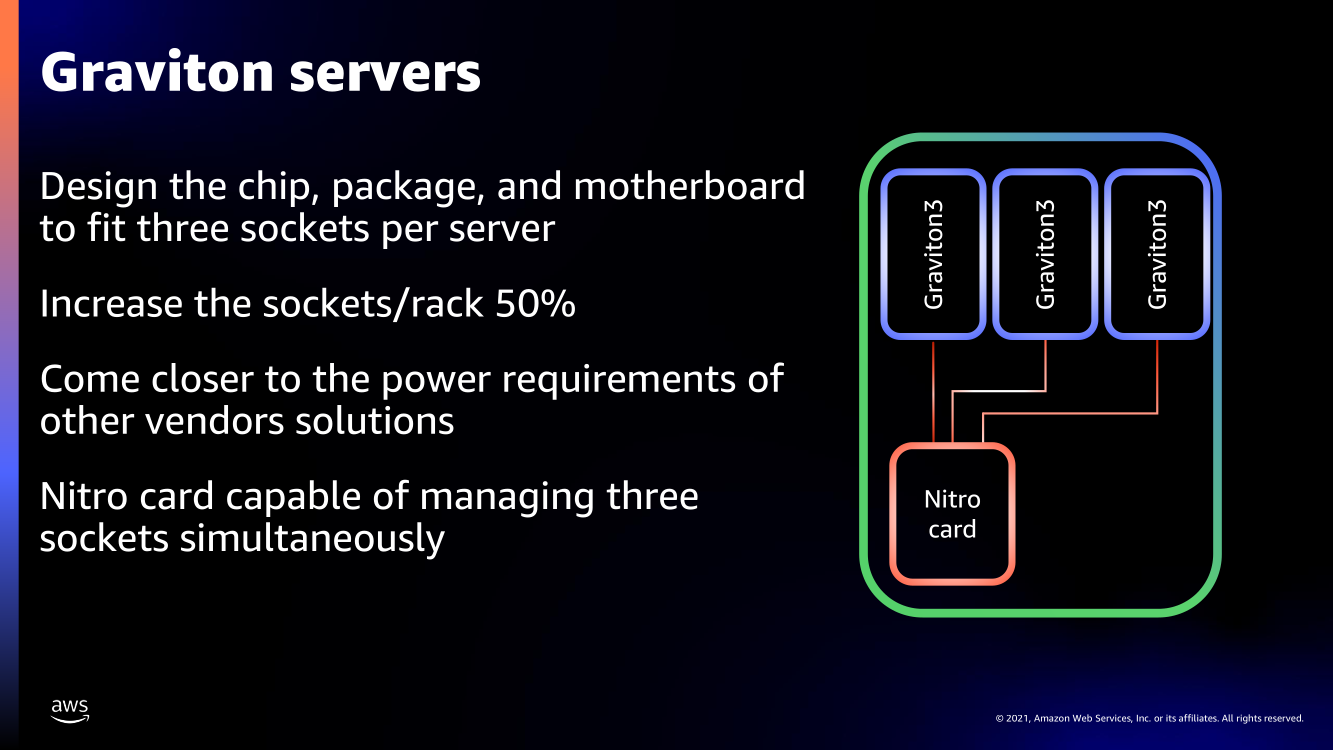 Но CPU — это лишь часть платформы, фундамент для которой несколько лет назад заложило появление чипов Nitro. Их сейчас стоило бы назвать DPU/IPU, хотя на момент их появления такого понятия, можно сказать, и не было. Nitro берёт на себя все задачи по обслуживанию гипервизора, обеспечению безопасности, работе с хранилищем и сетью и т.д., высвобождая, с одной стороны, все ресурсы CPU, памяти и SSD для обработки задачи клиента, а с другой — позволяя практически полностью дезагрегировать всю инфраструктуру. 
Узел с Nitro SSD Впрочем, Amazon пошла ещё дальше — теперь она самостоятельно закупает NAND-чипы и производит SSD, тоже под управлением Nitro. То есть у компании под контролем практически полный стек современных аппаратных решений: CPU, DPU, SSD, ИИ-ускорители для обучения (Trainium) и инференса (Inferentia). Она активно переносит на него собственные сервисы и предлагает их клиентам. И именно это и должно обеспокоить крупных вендоров, поскольку их решения вряд ли позволят добиться такого же уровня TCO, а гиперскейлеров, желающих перейти на аналогичную модель, немало.  UPD 06.12.21: презентация новых процессоров стала доступна публично, поэтому в материал добавлены некоторые иллюстрации, а в галерее ниже приведены результаты тестов производительности.
28.10.2021 [17:02], Алексей Степин
Rockport Networks представила интерконнект с пассивным оптическим коммутаторомПроизводительность любого современного суперкомпьютера или кластера во многом зависит от интерконнекта, объединяющего вычислительные узлы в единое целое, и практически обязательным компонентом такой сети является коммутатор. Однако последнее не аксиома: компания Rockport Networks представила своё видение HPC-систем, не требующее использования традиционных коммутирующих устройств. Проблема межсоединений существовала в мире суперкомпьютеров всегда, даже в те времена, когда сам процессор был набором более простых микросхем, порой расположенных на разных платах. В любом случае узлы требовалось соединять между собой, и эта подсистема иногда бывала неоправданно сложной и проблемной. Переход на стандартные сети Ethernet, Infiniband и их аналоги многое упростил — появилась возможность собирать суперкомпьютеры по принципу конструктора из стандартных элементов. 
Пассивный оптический коммутатор SHFL Тем не менее, проблема масштабирования (в том числе и на физическом уровне кабельной инфраструктуры), повышения скорости и снижения задержек никуда не делась. У DARPA даже есть особый проект FastNIC, нацеленный на 100-кратное ускорение сетевых интерфейсов, чтобы в конечном итоге сгладить разницу в скорости обмена данными внутри узлов и между ними.  Сам по себе высокоскоростной коммутатор для HPC-систем — устройство непростое, требующее использования недешёвого и сложного кремния, и вкупе с остальными компонентами интерконнекта может составлять заметную долю от стоимости всего кластера в целом. При этом коммутаторы могут вносить задержки, по определению являясь местами избыточной концентрации данных, а также требуют дополнительных мощностей подсистем питания и охлаждения.  Подход, продвигаемый компанией Rockport Networks, свободен от этих недостатков и изначально нацелен на минимизацию точек избыточности и возможных коллизий. А достигнуто это благодаря архитектуре, в которой концепция традиционного сетевого коммутатора отсутствует изначально. Вместо этого имеется специальный модуль SHFL, в котором топология сети задаётся оптически, а все логические задачи берут на себя специализированные сетевые адаптеры, работающие под управлением фирменной ОС rNOS и имеющие на борту сконфигурированную нужным образом ПЛИС. 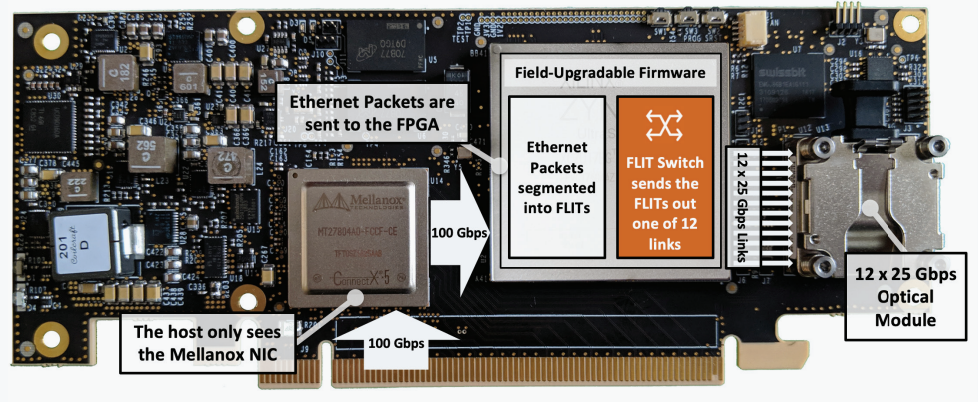 Модуль SHFL даже не требует отдельного электропитания, а вот адаптеры Rockport NC1225 его хотя и требуют, но умещаются в конструктив низкопрофильного адаптера с разъёмом PCIe x16 и потребляют всего 36 Вт. Правда, в настоящий момент речь идёт только о PCIe 3.0, поэтому полнодуплексного подключения на скорости 200 Гбит/с пока нет. Тем не менее, Техасский центр передовых вычислений (TACC) посчитал, что этого уже достаточно и стал одним из первых заказчиков — 396 узлов суперкомпьютера Frontera используют решение Rockport. 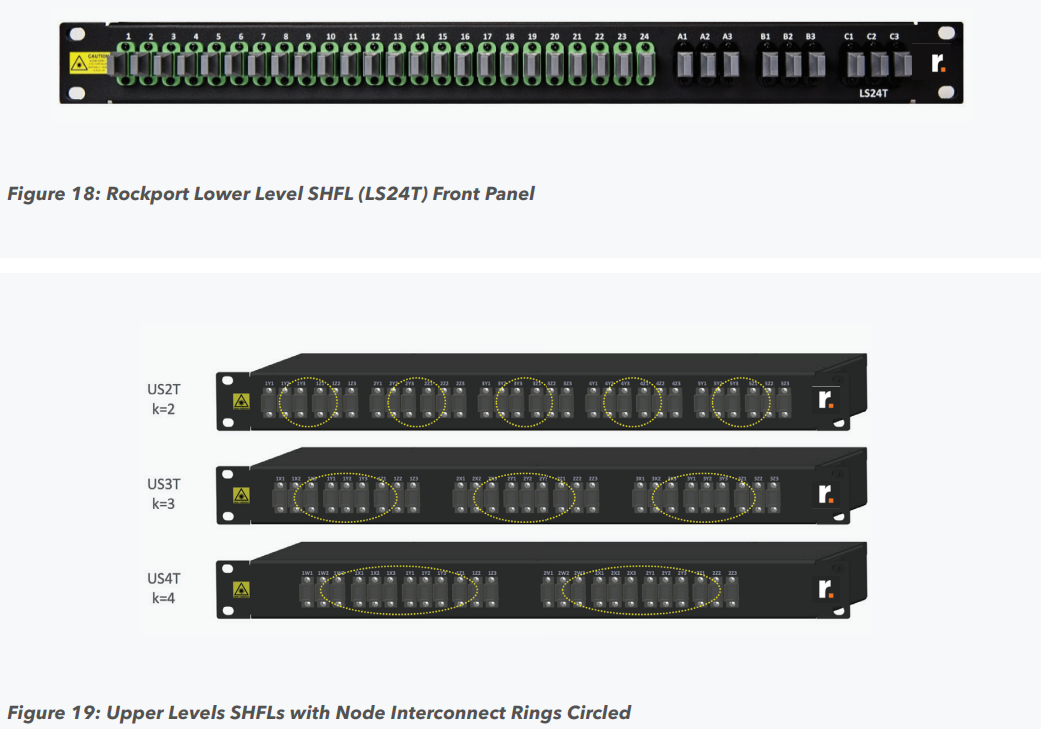 Использование не совсем традиционной оптической сети, впрочем, накладывает свои особенности: вместо популярных *SFP-корзин используются разъёмы MTP/MPO-24, а каждый кабель даёт для подключения 12 отдельных волокон, что при скорости 25 Гбит/с на волокно позволит достичь совокупной пропускной способности 300 Гбит/с. ОС и приложениям адаптер «представляется» как чип Mellanox ConnectX-5, который и входит в его состав, а потому не требует каких-то особых драйверов или модулей ядра. 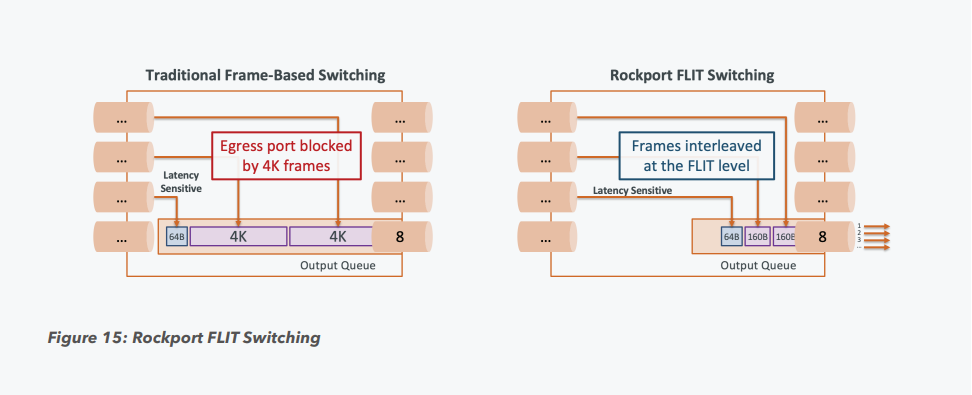 Rockport фактически занимается транспортировкой Ethernet и реализует уровень OSI 1/1.5, однако традиционной коммутации как таковой нет — адаптеры самостоятельно определяют конфигурацию сети и оптимальные маршруты передачи сигнала по отдельным волокнам с возможностью восстановления связности на лету при каких-либо проблемах. Весь трафик разбивается на маленькие кусочки (FLIT'ы) и отправляется по виртуальным каналам (VC) с чередованием, что позволяет легко управлять приоритизацией (в том числе на L2/L3) и снизить задержки.  SHFL имеет 24 разъёма для адаптеров и ещё 9 для объединения с другими SHFL и Ethernet-шлюзами для подключения к основной сети ЦОД (в ней сеть Rockport видна как обычная L2). Таким образом, в составе кластера каждый узел может быть подключён как минимум к 12 другим узлам на скорости 25 Гбит/с. Однако топологию можно менять по своему усмотрению. Компания-разработчик заявляет о преимуществе своего интерконнекта на классических HPC-задачах, могущем достигать почти 30% при сравнении c InfiniBand класса 100G и даже 200G. Кроме того, для Rockport требуется на 72% меньше кабелей.
26.10.2021 [22:45], Игорь Осколков
Получена первая партия российских серверных Arm-процессоров Baikal-S: 48 ядер, 6 каналов DDR4-3200 и 80 линий PCIe 4.0Компания «Байкал Электроникс» сообщила о получении первой партии инженерных образцов серверных Arm-процессоров Baikal-S объёмом 400 шт. Следующую партию компания ожидает получить в первом квартале следующего года, а первые массовые поставки (партия более 10 тыс. шт.) должны начаться до конца третьего квартала. Инженерные платы для разработчиков, созданы «Гаоди рус» (Dannie Group) и выпущены компанией «Рутек». Baikal-S, изготавливаемый по 16-нм техпроцессу на TSMC, имеет 48 ядер Arm Cortex-A75 на базе достаточно свежей 64-бит архитектуры ARMv8.2-A, которая была анонсирована в 2017 году. Частота составляет до 2,2 ГГц, а уровень TDP равен 120 Вт. Заявленный диапазон рабочих температур простирается от 0 до +70 °C. Производительность в HPL составляет 385 Гфлопс, а рейтинг в SPEC CPU2006 INT — до 600. Ориентировочная цена одного процессора ожидается на уровне $3 тыс.  L1-кеш имеет объём по 64 Кбайт для данных и инструкций, а L2 — 512 Кбайт на ядро. Любопытно, что в дополнение к L3-кешу (по 2 Мбайт на кластер) есть ещё и L4-кеш на 32 Мбайт. Контроллер памяти имеет шесть каналов DDR4-3200 ECC и обслуживает до 128 Гбайт на канал (суммарно 768 Гбайт на сокет). Кроме того, каждый процессор имеет 80 линий PCIe 4.0, из которых 48 линий делятся тремя интерфейсами CCIX x16. Также есть пара 1GbE-интерфейсов. 
Источник: CNews При этом новинка поддерживает аппаратную виртуализацию, Arm TrustZone и позволяет создавать четырёхсокетные платформы. Всё это делает её привлекательным решением не только для традиционных серверов и СХД, но и для и HCI- и HPC-систем. С экосистемой ПО проблемы вряд ли будут. Во-первых, для «малого» Байкал-М уже сейчас есть отечественные ОС и другие продукты. Во-вторых, серверные платформы Arm в мире развивают сразу несколько игроков, да и сама Arm стимулирует процесс разработки и портирования ПО. Кроме того, «Байкал Электроникс» имеет тесные связи с ГК Astra Linux.
07.10.2021 [18:09], Руслан Авдеев
AWS потратила на дата-центры $35 млрд в одной только Северной ВирджинииЗа прошедшие 10 лет облачный провайдер AWS потратила $35 млрд на строительство инфраструктуры на севере штата Вирджиния (США). Строительство такого масштаба оказало важное влияние на региональную экономику. Обычно гиперскейлеры не делятся детальными сведениями о своих затратах на ЦОД, но в данном случае речь идёт об отчёте, который призван показать, как сотрудничество местных органов власти и индустрии дата-центров может положительно влиять на возможности развития региона. Сегодня Amazon относится к числу техногигантов, способных играть ведущие роли при создании облачных систем. На северо-востоке штата сейчас находится более 50 дата-центров, формирующих крупнейшее в мире облачное пространство. При этом кластер в Северной Вирджинии — это только часть инфраструктуры AWS, включающей шесть облачных регионов на территории США и 25 по всему миру. Однако именно регион US-East исторически является наиболее важным и крупным для AWS, поскольку здесь развёрнуто сразу шесть зон доступности (AZ).  Провайдеры облачных сервисов сыграли важную роль для развития финансовых систем всего мира в период пандемии. В то же время и заработок AWS в 2020 году составил $45 млрд — больше, чем у многих подразделений Amazon, связанных с торговлей. Деятельность Amazon в штате позволяет акцентировать внимание на двух фактах — по данным компании, создание облачных кластеров несёт большие преимущества для локальных экономик, но вместе с тем требует финансирования в объёмах, доступных лишь немногим компаниям. 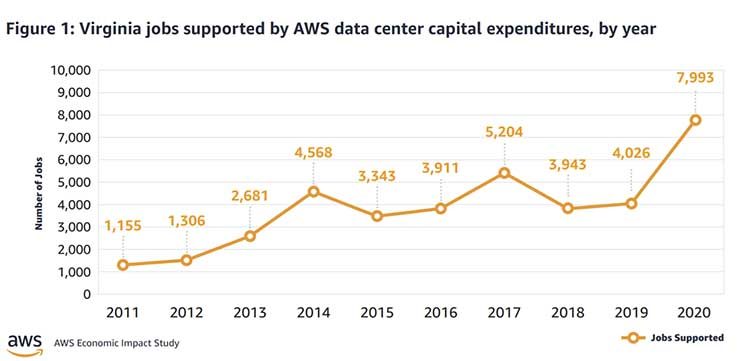
datacenterfrontier.com Расширение проекта Amazon в Северной Вирджинии потребовало закупки местных земель, строительства большего числа дата-центров — это позволяет с запасом обеспечить корпоративный спрос на облачные решения. Прямым следствием становится появление рабочих мест среди местных жителей и рост затрат на местах на обслуживание инфраструктуры, обеспечение безопасности, а также рост поступлений налогов в местные бюджеты:
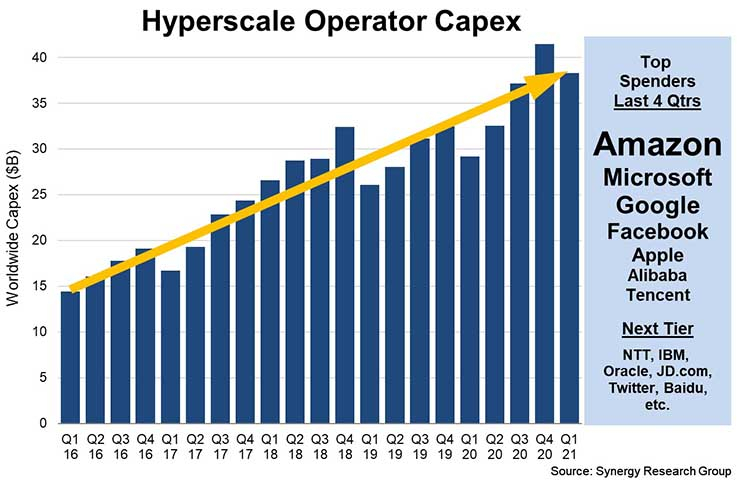 Инвестиции объёмом $35 млрд в Вирджинии — самые масштабные для одного штата. Такие большие расходы соответствуют масштабным потребностям в затратах, необходимых для создания соответствующей инфраструктуры — конкурирующие компании вроде Google, Microsoft и Facebook✴ обычно тратят на строительство каждого облачного кампуса от $600 млн до $4 млрд. Тем не менее, в последнее время капитальные вложения всей индустрии выросли почти на треть.
25.09.2021 [17:29], Руслан Авдеев
На Аляске появился быстрый беспроводной интернет на базе Facebook✴ TerragraphСложный рельеф и суровый климат Аляски создают серьёзные трудности при обеспечении пользователей стабильным быстрым интернетом-соединением. С распространением пандемии и переходом многих жителей на удалённую работу потребность в устойчивых соединениях только выросла. На помощь местным жителям пришёл провайдер Alaska Communications с беспроводной технологией Terragraph, разработанной Facebook✴ Connectivity. Провайдер использует оборудование компании Cambium Networks, получившего лицензию от Facebook✴ на использование Terragraph в своих решениях. Технология использует спектр 60 ГГц и позволяет наладить быструю связь значительно дешевле, чем обходится прокладка под землёй кабельных соединений. Многие интернет-провайдеры штата уже убедились, что в местных суровых условиях прокладывать кабели конечным потребителям не только дорого, но и долго. Если же возникает обрыв, установить его местонахождение и устранить поломку очень сложно, особенно зимой. Cambium Networks предоставляет беспроводные решения на основе Terragraph — от Пинанга в Малайзии до Пуэрто-Рико. 
tech.fb.com Facebook✴ Connectivity разработала Terragraph, намереваясь расширить доступность стабильного беспроводного интернет-соединения в регионах с плохим или отсутствующим соединением. Лицензии на технологию выдаются партнёрам по всему миру — производители оборудования и провайдеры могут сосредоточить усилия на её внедрении вместо проведения собственных разработок. Первая фаза развёртывания на Аляске планируется с использованием клиентских узлов cnWave 60 ГГц производства Cambium Networks, обеспечивающих скорость передачи данных до 1 Гбит/с для 6500 локаций. «Доступный, надёжный высокоскоростной интернет сегодня отсутствует на рынке Аляски. Поэтому мы здесь — для того, чтобы обеспечить местным жителям связь с тем, что наиболее важно для них», — говорит вице-президент по маркетингу Alaska Communications Бет Барнс (Beth Barnes). Вместо использования кабельных соединений, Terragraph полагается на ячеистую mesh-топологию, в которой клиентские беспроводные узлы размером с книгу размещаются на уже существующих объектах вроде крыш или телефонных столбов. Отдельные узлы не только обеспечивают интернетом конкретные дома, но и передают сигнал другим аналогичным узлам, находящимся в зоне досягаемости. Структура mesh-сетей предусматривает многочисленные альтернативные пути соединения между узлами, поэтому связь в сети остаётся стабильной почти в любых условиях. Для сравнения, обрыв связи на «последней миле» кабельного соединения требует обязательного ремонта, иначе доступ к Интернету прервётся. 
tech.fb.com Местные жители уже начали пользоваться преимуществами Terragraph. Даже тем, кому по роду деятельности приходится пересылать очень большие файлы, теперь доступны по-настоящему быстрые соединения. По данным некоторых пользователей, скорость соединения выросла почти в 100 раз в сравнении с проводными решениями, применявшимися прежде: на отправку файла чуть более 10 Гбайт уходит около 10 минут. Из-за низкой плотности населения на Аляске связь имеет ещё большее значение, чем в густонаселённых регионах. Например, Аляска в 2,5 раза больше Техаса или в 77 раз больше Нью-Джерси, при этом здесь приходится приблизительно по одному человеку на 2,5 км2. Если трудно предоставить высокоскоростное интернет-соединение даже населению городов вроде Анкориджа, то ещё труднее обеспечить связь за пределами городов. При этом в период пандемии критически важно оставаться на связи. До конца текущего года Terragraph намерены использовать в 6500 локациях по всему штату, а скоро в Alaska Communications планируется обеспечить и более широкое распространение технологии. В следующие несколько лет сервис появится в новых районах вблизи Анкориджа, а также Фэрбенксе, Джуно, на Кенайском полуострове.
01.09.2021 [23:58], Андрей Галадей
Ветераны индустрии основали стартап Ventana для создания чиплетных серверных процессоров RISC-VСтартап Ventana Micro Systems, похоже, намерен перевернуть рынок серверов. Компания заявила о разработке высокопроизводительных процессоров на архитектуре RISC-V для центров обработки данных. Первые образцы фирменных CPU будут переданы клиентам во второй половине следующего года, а поставки начнутся в первой половине 2023 года. При этом процессоры получат чиплетную компоновку — различные модули и кристаллы на общей подложке. Основные процессорные ядра разработает сама Ventana, а вот остальные чиплеты будут создаваться под нужды определённых заказчиков. CPU-блоки будут иметь до 16 ядер, которые, как обещается, окажутся быстрее любых других реализаций RV64. Использование RISC-V позволит разрабатывать сверхмощные решения в рекордные сроки и без значительного бюджета. Ядра будут «выпекаться» на TSMC по 5-нм нормам, но для остальных блоков могут использовать другие техпроцессы и фабрики. Ventana будет следить за процессом их создания и упаковывать до полудюжины блоков в одну SoC. Для соединения ядер, кеша и других компонентов будет использоваться фирменная кеш-когерентная шина, которая обеспечит задержку порядка 8 нс и скорость передачи данных 16 Гбит/с на одну линию. Основными заказчиками, как ожидается, станут гиперскейлеры и крупные IT-игроки, которым часто требуется специализированное «железо» для ЦОД, 5G и т.д. Сегодня Ventana объявила о привлечении $38 млн в рамках раунда B. Общий же объём инвестиций составил $53 млн. Компания была основана в 2018 году. Однако это не совсем обычный стартап — и сами основатели, и команда являются настоящими ветеранами индустрии. Все они имеют многолетний опыт работы в Arm, AMD, Intel, Samsung, Xilinx и целом ряде других крупных компаний в области микроэлектроники. Часть из них уже имела собственные стартапы, которые были поглощены IT-гигантами.
31.08.2021 [20:34], Игорь Осколков
Western Digital анонсировала «концептуально новые» жёсткие диски с технологией OptiNAND: 20+ Тбайт без SMRWestern Digital анонсировала технологию OptiNAND, которая, по её словам, полностью меняет архитектуру жёстких дисков и вместе с ePMR открывает путь к созданию накопителей ёмкостью более 20 Тбайт (от 2,2 Тбайт на пластину) даже при использовании CMR — вплоть до 50 Тбайт во второй половине этого десятилетия. OptiNAND предполагает интеграцию индустриального UFS-накопителя серии iNAND непосредственно в HDD. Но это не просто ещё один вариант NAND-кеша. Увеличение ёмкости одной пластины происходит благодаря повышению плотности размещения дорожек, что, правда, на современном этапе развития жёстких дисков требует различных ухищрений: заполнение корпуса гелием, использование продвинутых актуаторов, применение новых материалов, требующих энергетической поддержки записи (MAMR, HAMR и т.д.). Вместе с тем механическая часть накопителей не столь «тонка» и подвержена различным колебаниям, которые могут повлиять на запись и считывание столь плотно упакованных дорожек.  При производстве жёстких дисков делается калибровка и учёт этих ошибок в позиционировании головки (RRO, repeatable run out), а данные (речь идёт о гигабайтах) обычно записываются непосредственно на пластины, откуда и считываются во время работы накопителя. В случае OptiNAND эти мета✴-данные попадают во флеш-память, позволяя высвободить место. Правда, пока не уточняется, насколько это значимо на фоне общей ёмкости пластины.  Второй важный тип мета✴-данных, который теперь попадает в iNAND, — это информация о произведённых операциях записи. При повышении плотности размещения риск того, что запись на одну дорожку повлияет на данные в соседней, резко увеличивается. Поэтому, опираясь на данные о прошлых записях, жёсткий диск периодически перезаписывает данные соседних дорожек для повышения сохранности информации.  В старых накопителях одна такая операция приходилась примерно на 10 тыс. записей, в современных — на менее, чем на 10 записей. Причём учёт ведётся именно на уровне дорожек. iNAND же позволяет повысить точность отслеживания записей до секторов, что, в свою очередь, позволяет разнести операции перезаписи в пространстве и времени, снизив общую нагрузку на накопитель и повысив плотность размещения дорожек без ущерба для производительности, поскольку надо тратить меньше времени на «самообслуживание».  Наконец, быстрая и ёмкая UFS (вплоть до 3.1) позволяет сохранить в 50 раз больше данных и мета✴-данных из DRAM в сравнении с жёсткими дисками без OptiNAND в случае аварийного отключения накопителя и в целом повысить его производительность, причём в независимости от того, включено ли кеширование записи или нет. Кроме того, новый слой памяти позволяет лучше оптимизировать прошивку под конкретные задачи — будут использоваться 162-слойные TLC-чипы от Kioxia, которые можно настроить в том числе на работу в режиме SLC. Western Digital планирует использовать OptiNAND в большинстве серий своих жёстких дисков, предназначенных для облаков и гиперскейлеров, корпоративных нужд (Gold), систем видеонаблюдения (Purple) и NAS (Red). Первые образцы 20-Тбайт накопителей (CMR + ePMR) с OptiNAND уже тестируются избранными клиентами компании. А вот о потребительских решениях пока ничего сказано не было.
28.08.2021 [00:16], Владимир Агапов
Кластер суперчипов Cerebras WSE-2 позволит тренировать ИИ-модели, сопоставимые по масштабу с человеческим мозгомВ последние годы сложность ИИ-моделей удваивается в среднем каждые два месяца, и пока что эта тенденция сохраняется. Всего три года назад Google обучила «скромную» модель BERT с 340 млн параметров за 9 Пфлоп-дней. В 2020 году на обучение модели Micrsofot MSFT-1T с 1 трлн параметров понадобилось уже порядка 25-30 тыс. Пфлоп-дней. Процессорам и GPU общего назначения всё труднее управиться с такими задачами, поэтому разработкой специализированных ускорителей занимается целый ряд компаний: Google, Groq, Graphcore, SambaNova, Enflame и др.  Особо выделятся компания Cerebras, избравшая особый путь масштабирования вычислительной мощности. Вместо того, чтобы печатать десятки чипов на большой пластине кремния, вырезать их из пластины, а затем соединять друг с другом — компания разработала в 2019 г. гигантский чип Wafer-Scale Engine 1 (WSE-1), занимающий практически всю пластину. 400 тыс. ядер, выполненных по 16-нм техпроцессу, потребляют 15 кВт, но в ряде задач они оказываются в сотни раз быстрее 450-кВт суперкомпьютера на базе ускорителей NVIDIA.  В этом году компания выпустила второе поколение этих чипов — WSE-2, в котором благодаря переходу на 7-нм техпроцесс удалось повысить число тензорных ядер до 850 тыс., а объём L2-кеша довести до 40 Гбайт, что примерно в 1000 раз больше чем у любого GPU. Естественно, такой подход к производству понижает выход годных пластин и резко повышает себестоимость изделий, но Cerebras в сотрудничестве с TSMC удалось частично снизить остроту этой проблемы за счёт заложенной в конструкцию WSE избыточности. 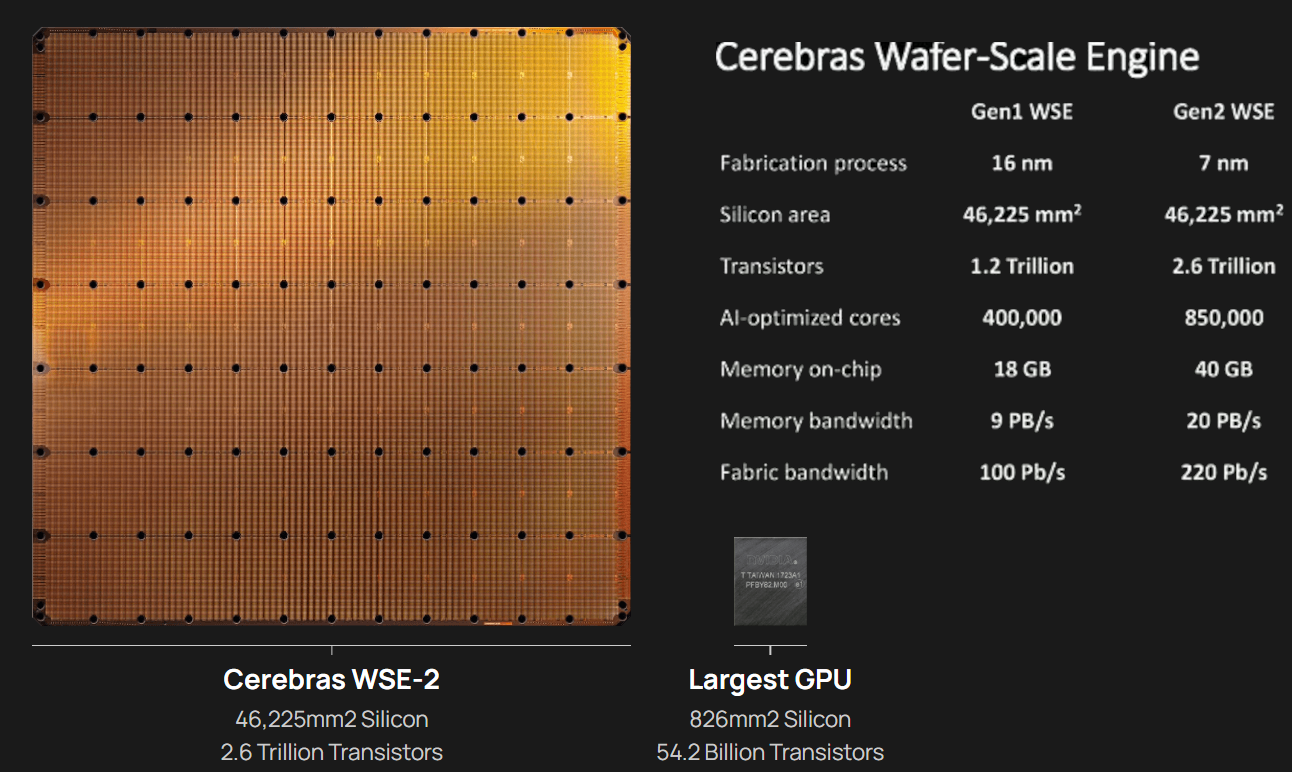 Благодаря идентичности всех ядер, даже при неисправности некоторых их них, изделие в целом сохраняет работоспособность. Тем не менее, себестоимость одной 7-нм 300-мм пластины составляет несколько тысяч долларов, в то время как стоимость чипа WSE оценивается в $2 млн. Зато система CS-1, построенная на таком процессоре, занимает всего треть стойки, имея при этом производительность минимум на порядок превышающую самые производительные GPU. Одна из причин такой разницы — это большой объём быстрой набортной памяти и скорость обмена данными между ядрами.  Тем не менее, теперь далеко не каждая модель способна «поместиться» в один чип WSE, поэтому, по словам генерального директора Cerebras Эндрю Фельдмана (Andrew Feldman), сейчас в фокусе внимания компании — построение эффективных систем, составленных из многих чипов WSE. Скорость роста сложности моделей превышает возможности увеличения вычислительной мощности путём добавления новых ядер и памяти на пластину, поскольку это приводит к чрезмерному удорожанию и так недешёвой системы.  Инженеры компании рассматривают дезагрегацию как единственный способ обеспечить необходимый уровень производительности и масштабируемости. Такой подход подразумевает разделение памяти и вычислительных блоков для того, чтобы иметь возможность масштабировать их независимо друг от друга — параметры модели помещаются в отдельное хранилище, а сама модель может быть разнесена на несколько вычислительных узлов CS, объединённых в кластер. 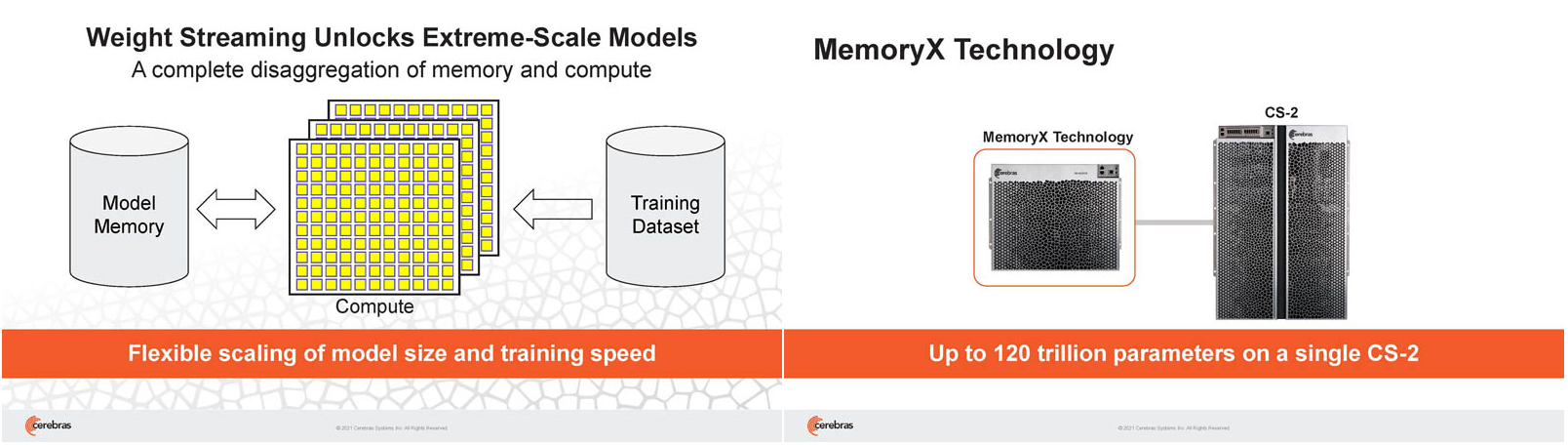 На Hot Chips 33 компания представила особое хранилище под названием MemoryX, сочетающее DRAM и флеш-память суммарной емкостью 2,4 Пбайт, которое позволяет хранить до 120 трлн параметров. Это, по оценкам компании, делает возможным построение моделей близких по масштабу к человеческому мозгу, обладающему порядка 80 млрд. нейронов и 100 трлн. связей между ними. К слову, флеш-память размером с целую 300-мм пластину разрабатывает ещё и Kioxia.  Для обеспечения масштабирования как на уровне WSE, так и уровне CS-кластера, Cerebras разработала технологию потоковой передачи весовых коэффициентов Weight Streaming. С помощью неё слой активации сверхкрупных моделей (которые скоро станут нормой) может храниться на WSE, а поток параметров поступает извне. Дезагрегация вычислений и хранения параметров устраняет проблемы задержки и узости пропускной способности памяти, с которыми сталкиваются большие кластеры процессоров. 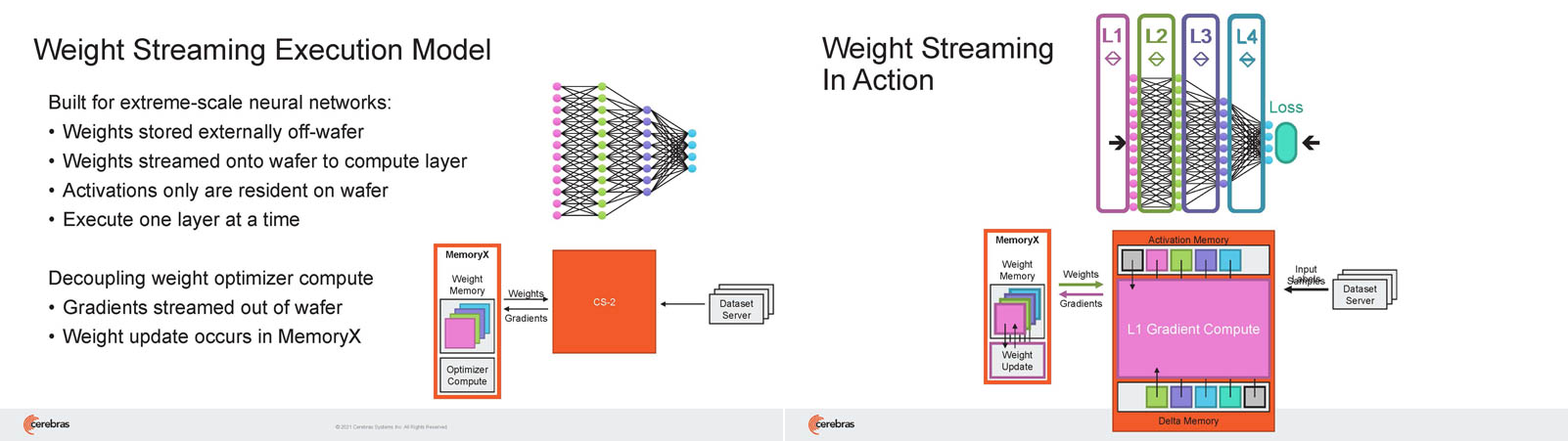 Это открывает широкие возможности независимого масштабирования размера и скорости кластера, позволяя хранить триллионы весов WSE-2 в MemoryX и использовать от 1 до 192 CS-2 без изменения ПО. В традиционных системах по мере добавления в кластер большего количества вычислительных узлов каждый из них вносит всё меньший вклад в решение задачи. Cerebras разработала интерконнект SwarmX, позволяющий подключать до 163 млн вычислительных ядер, сохраняя при этом линейность прироста производительности. 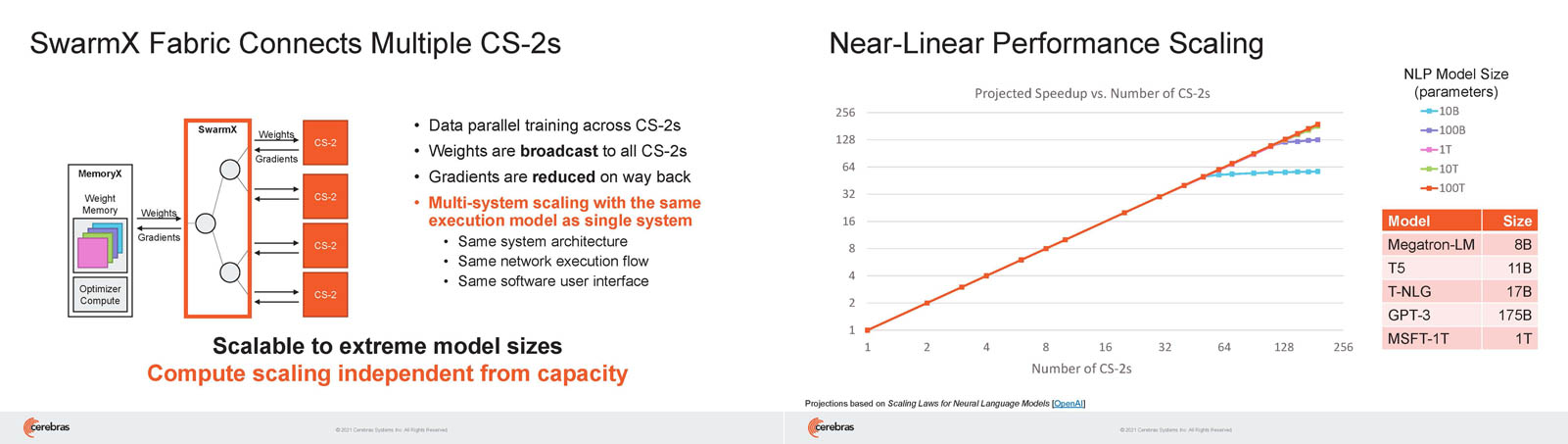 Также, компания уделила внимание разрежённости, то есть исключения части незначимых для конечного результата весов. Исследования показали, что должная оптимизации модели позволяет достичь 10-кратного увеличения производительности при сохранении точности вычислений. В CS-2 доступна технология динамического изменения разрежённости Selectable Sparsity, позволяющая пользователям выбирать необходимый уровень «ужатия» модели для сокращение времени вычислений.  «Крупные сети, такие как GPT-3, уже изменили отрасль машинной обработки естественного языка, сделав возможным то, что раньше было невозможно и представить. Индустрия перешла к моделям с 1 трлн параметров, а мы расширяем эту границу на два порядка, создавая нейронные сети со 120 трлн параметров, сравнимую по масштабу с мозгом» — отметил Фельдман.
19.08.2021 [16:00], Игорь Осколков
Intel представила Xeon Sapphire Rapids: четырёхкристалльная SoC, HBM-память, новые инструкции и ускорителиВ рамках Architecture Day компания Intel рассказала о грядущих серверных процессорах Sapphire Rapids, подтвердив большую часть опубликованной ранее информации и дополнив её некоторыми деталями. Intel позиционирует новинки как решение для более широкого круга задач и рабочих нагрузок, чем прежде, включая и популярные ныне микросервисы, контейнеризацию и виртуализацию. Компания обещает, что CPU будут сбалансированы с точки зрения вычислений, работой с памятью и I/O. Новые процессоры, наконец, получили чиплетную, или тайловую в терминологии Intel, компоновку — в состав SoC входят четыре «ядерных» тайла на техпроцессе Intel 7 (10 нм Enhanced SuperFIN). Каждый тайл объединён с соседом посредством EMIB. Их системные агенты, включающие общий на всех L3-кеш объём до 100+ Мбайт, образуют быструю mesh-сеть с задержкой порядка 4-8 нс в одну сторону. Со стороны процессор будет «казаться» монолитным.  Каждые ядро или поток будут иметь свободный доступ ко всем ресурсам соседних тайлов, включая кеш, память, ускорители и IO-блоки. Потенциально такой подход более выгоден с точки зрения внутреннего обмена данными, чем в случае AMD с общим IO-блоком для всех чиплетов, которых в будущих EPYC будет уже 12. Но как оно будет на самом деле, мы узнаем только в следующем году — выход Sapphire Rapids запланирован на первый квартал 2022-го, а массовое производство будет уже во втором квартале.  Ядра Sapphire Rapids базируются на микроархитектуре Golden Cove, которая стала шире, глубже и «умнее». Она же будет использована в высокопроизводительных ядрах Alder Lake, но в случае серверных процессоров есть некоторые отличия. Например, увеличенный до 2 Мбайт на ядро объём L2-кеша или новый набор инструкций AMX (Advanced Matrix Extension). Последний расширяет ИИ-функциональность CPU и позволяет проводить MAC-операции над матрицами, что характерно для такого рода нагрузок.  Для AMX заведено восемь выделенных 2D-регистров объёмом по 1 Кбайт каждый (шестнадцать 64-байт строк). Отдельный аппаратный блок выполняет MAC-операции над тремя регистрами, причём делаться это может параллельно с исполнением других инструкций в остальной части ядра. Настройкой параметров и содержимого регистров, а также перемещением данных занимается ОС. Пока что в процессорах представлен только MAC-блок, но в будущем могут появиться блоки и для других, более сложных операций. 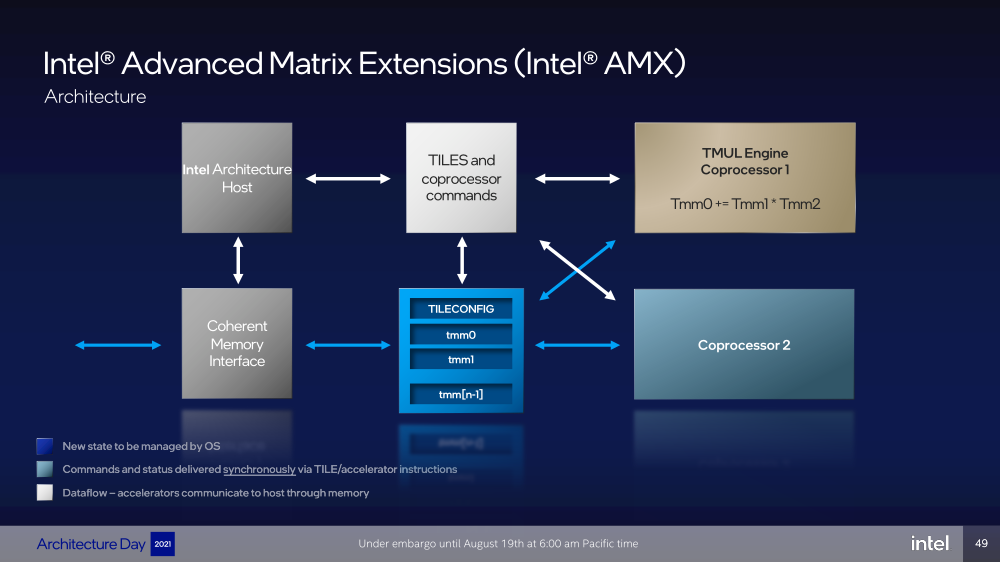 В пике производительность AMX на INT8 составляет 2048 операций на цикл на ядро, что в восемь раз больше, чем при использовании традиционных инструкций AVX-512 (на двух FMA-портах). На BF16 производительность AMX вдвое ниже, но это всё равно существенный прирост по сравнению с прошлым поколением Xeon — Intel всё так же пытается создать универсальные ядра, которые справлялись бы не только с инференсом, но и с обучением ИИ-моделей. Тем не менее, компания говорит, что возможности AMX в CPU будут дополнять GPU, а не напрямую конкурировать с ними.  К слову, именно Sapphire Rapids должен, наконец, сделать BF16 более массовым, поскольку Cooper Lake, где поддержка этого формата данных впервые появилась в CPU Intel, имеет довольно узкую нишу применения. Из прочих архитектурных обновлений можно отметить поддержку FP16 для AVX-512, инструкции для быстрого сложения (FADD) и более эффективного управления данными в иерархии кешей (CLDEMOTE), целый ряд новых инструкций и прерываний для работы с памятью и TLB для виртуальных машин (ВМ), расширенную телеметрию с микросекундными отсчётами и так далее.  Последние пункты, в целом, нужны для более эффективного и интеллектуального управления ресурсами и QoS для процессов, контейнеров и ВМ — все они так или иначе снижают накладные расходы. Ещё больше ускоряют работу выделенные акселераторы. Пока упомянуты только два. Первый, DSA (Data Streaming Accelerator), ускоряет перемещение и передачу данных как в рамках одного хоста, так и между несколькими хостами. Это полезно при работе с памятью, хранилищем, сетевым трафиком и виртуализацией. 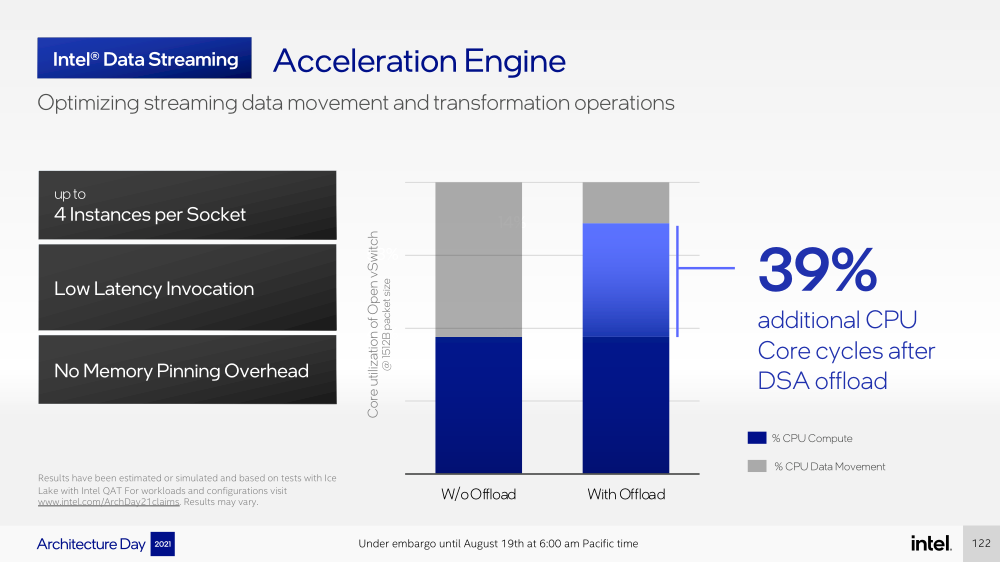 Второй упомянутый ускоритель — это движок QAT (Quick Assist Engine), на который можно возложить операции или сразу цепочки операций (де-)компрессии (до 160 Гбит/с в обе стороны одновременно), хеширования и шифрования (до 400 Гбитс/с) в популярных алгоритмах: AES GCM/XTS, ChaChaPoly, DH, ECC и т.д. Теперь блок QAT стал частью самого процессора, тогда как прежде он был доступен в составе некоторых чипсетов или в виде отдельной карты расширения. Это позволило снизить задержки и увеличить производительность блока. 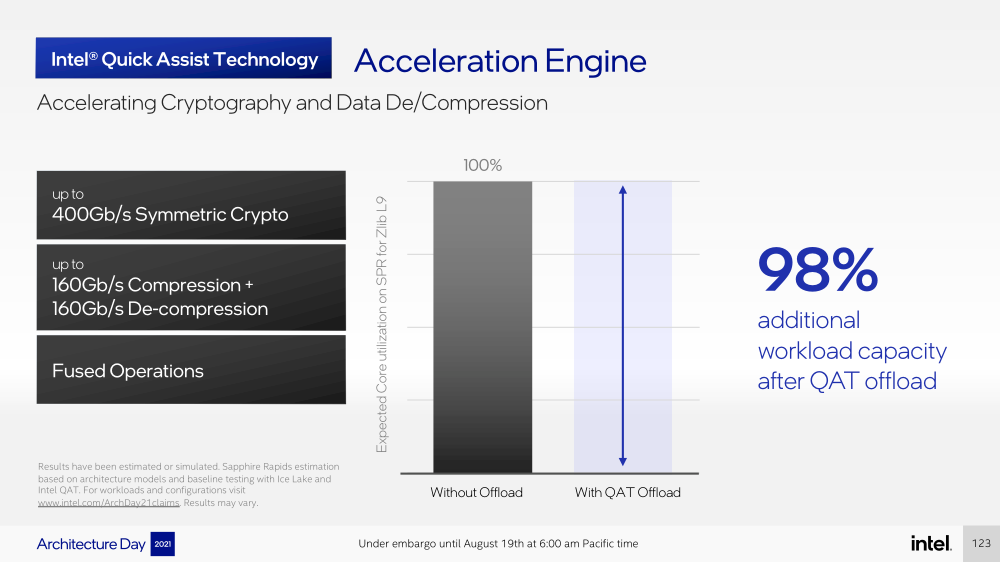 Кроме того, QAT можно будет задействовать, например, для виртуализации или Intel Accelerator Interfacing Architecture (AiA). AiA — это ещё один новый набор инструкций, предназначенный для более эффективной работы с интегрированными и дискретными ускорителями. AiA помогает с управлением, синхронизацией и сигнализацией, что опять таки позволит снизить часть накладных расходов при взаимодействии с ускорителями из пространства пользователя. 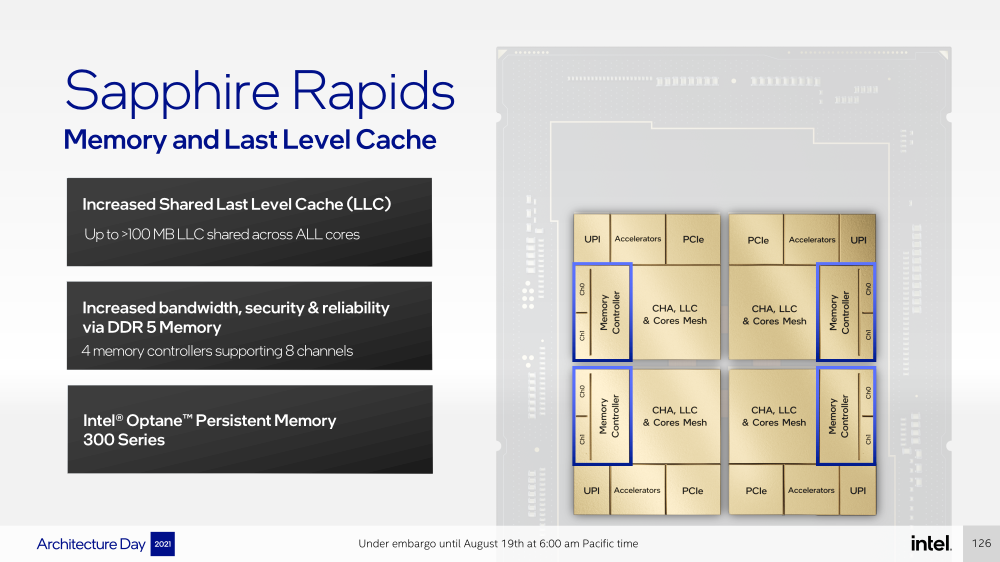 Подсистема памяти включает четыре двухканальных контроллера DDR5, по одному на каждый тайл. Надо полагать, что будут доступные четыре же NUMA-домена. Больше деталей, если не считать упомянутой поддержки следующего поколения Intel Optane PMem 300 (Crow Pass), предоставлено не было. Зато было официально подтверждено наличие моделей с набортной HBM, тоже по одному модулю на тайл. HBM может использоваться как в качестве кеша для DRAM, так и независимо. В некоторых случаях можно будет обойтись вообще без DRAM. 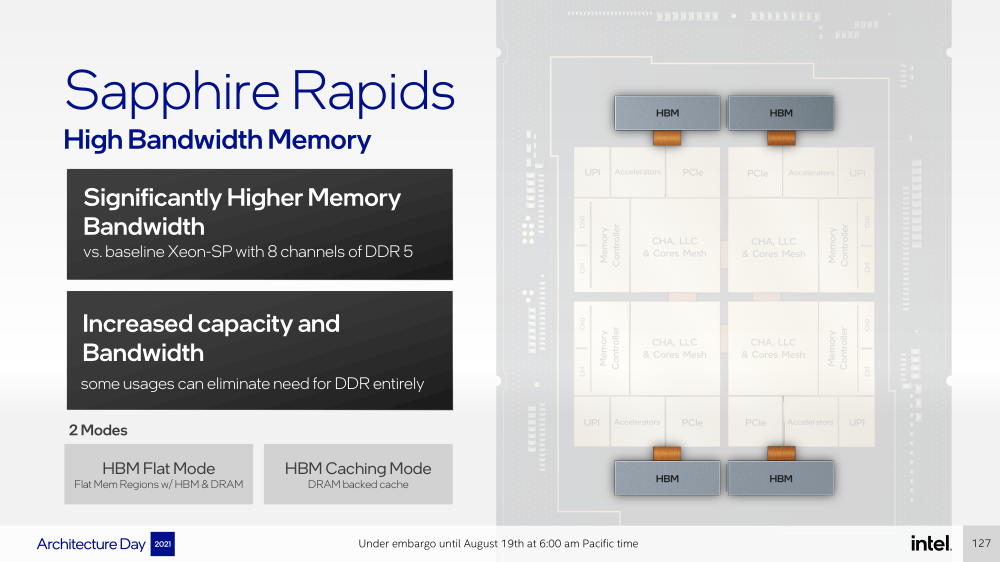 Про PCIe 5.0 и CXL 1.1 (CXL.io, CXL.cache, CXL.memory) добавить нечего, хотя в рамках другого доклада Intel ясно дала понять, что делает ставку на CXL в качестве интерконнекта не только внутри одного узла, но и в перспективе на уровне стойки. Для объединения CPU (бесшовно вплоть до 8S) всё так же будет использоваться шина UPI, но уже второго поколения (16 ГТ/с на линию) — по 24 линии на каждый тайл. 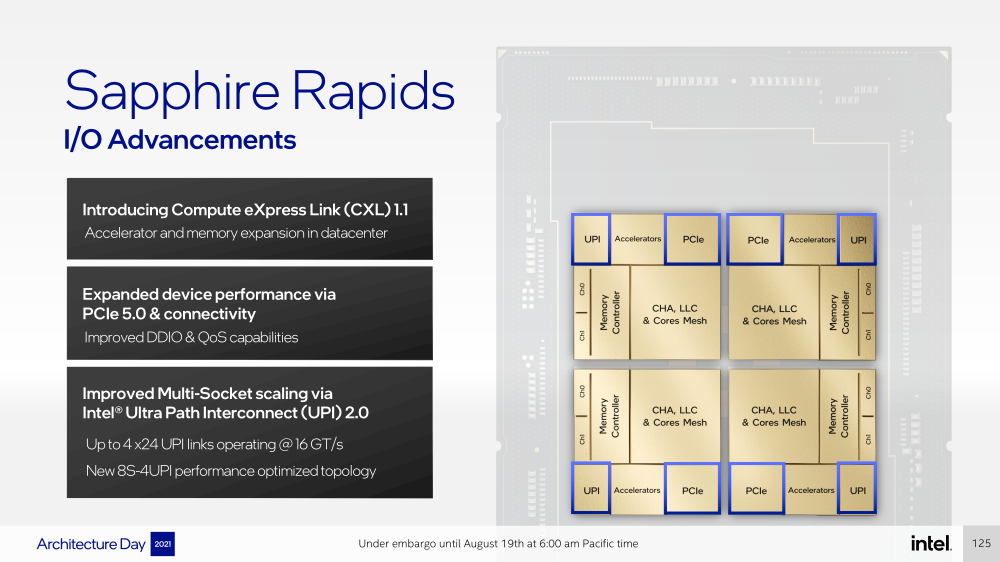 Конкретно для Sapphire Rapids Intel пока не приводит точные данные о росте IPC в сравнении с Ice Lake-SP, ограничиваясь лишь отдельными цифрами в некоторых задачах и областях. Также не был указан и ряд других важных параметров. Однако AMD EPYC Genoa, если верить последним утечкам, даже по чисто количественным характеристикам заметно опережает Sapphire Rapids. |
|


