Материалы по тегу: s
|
17.01.2023 [15:33], Сергей Карасёв
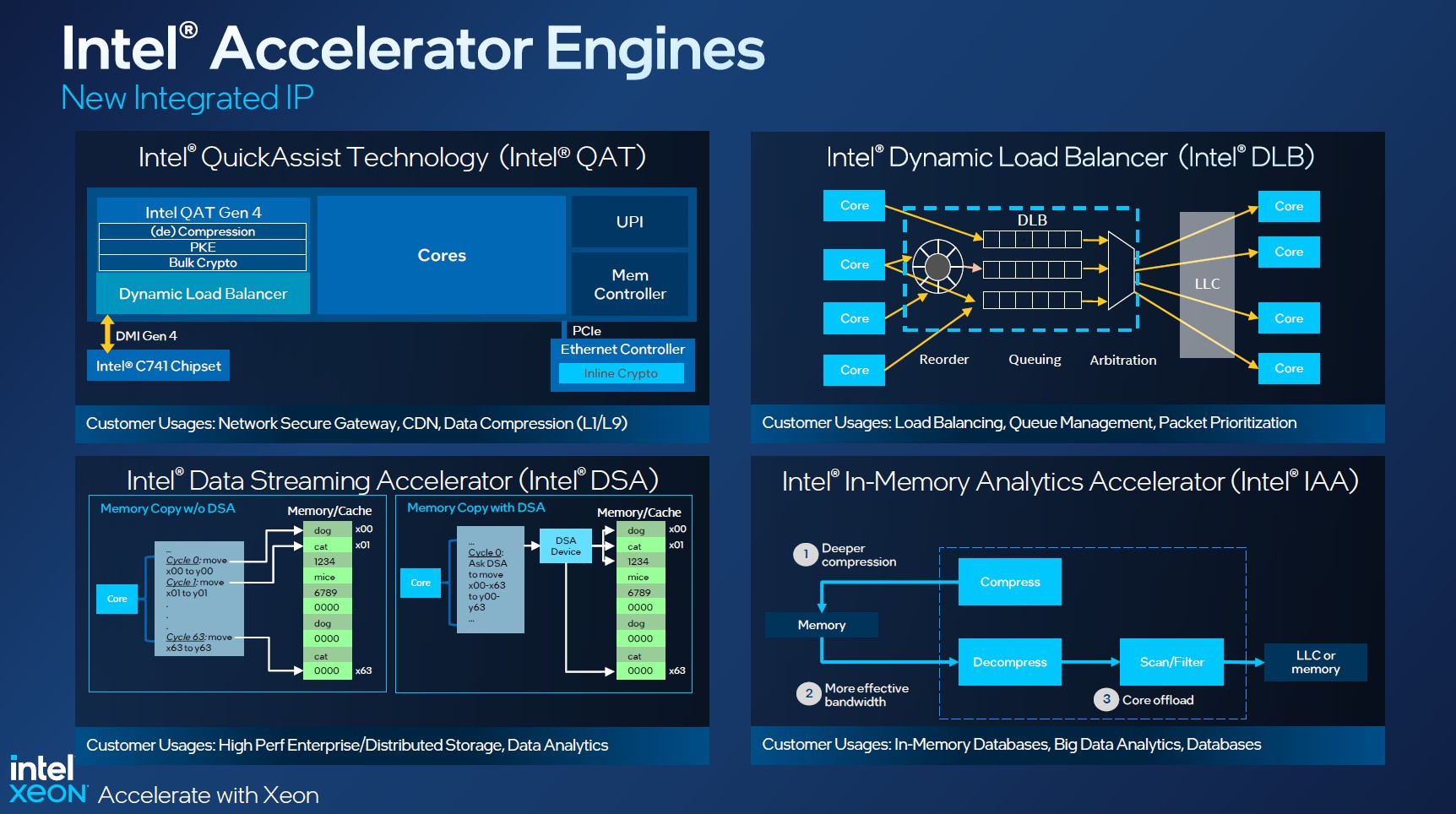
Intel Xeon на китайский лад: Montage представила защищённые процессоры Jintide четвёртого поколения на базе Sapphire RapidsКитайская компания Montage Technology анонсировала процессор Jintide четвёртого поколения, рассчитанный на облачные платформы, корпоративные нагрузки, ИИ-приложения и системы НРС. В основу решения положен новейший чип Intel Xeon Sapphire Rapids, о котором можно подробно узнать в нашем материале. Ключевые отличия Jintide от стандартных Xeon заключаются в расширенных функциях безопасности. В новинках используются технологии PrC и DSC, которые обеспечивают различные уровни аппаратной защиты. Кроме того, такие чипы лучше адаптированы под потребности китайских поставщиков серверного оборудования. Решения Jintide совместимы с экосистемой x86, обладают хорошей масштабируемостью, гибкостью и удобством использования. Jintide — это комплексная платформа Montage, работающая в тандеме с фирменными гибридными модулями оперативной памяти HSDIMM, которые также обеспечивают защиту на аппаратном уровне. 
Источник изображения: Montage Technology Конфигурация Jintide четвёртого поколения включает до 48 вычислительных ядер и до 105 Мбайт кеша. Максимальная частота в турбо-режиме составляет 4,2 ГГц. Заявлена поддержка инструкций AMX (Advanced Matrix Extensions), памяти DDR5-4800 и 80 линий PCIe 5.0/CXL 1.1. Ранее Montage также представила CXL-экспандеры DDR4/DDR5. По запросу могут быть активированы дополнительные функции: Dynamic Load Balancer (DLB), Intel Data Streaming Accelerator (DSA), Intel In-Memory Analytics Accelerator (IAA), Intel In-Memory Analytics Accelerator и Intel QuickAssist (QAT).
12.01.2023 [15:47], Алексей Степин
Atos представила серверы BullSequana SH и edge-платформы EXR и EXD на базе Sapphire RapidsНовые процессоры Intel Xeon с архитектурой Sapphire Rapids навёрстывают упущенное и находят своё место в новых моделях серверов. На этот раз о новинках объявила компания Atos, представившая вычилительную систему BullSequana SH класса HPC и новые серверы в серии EX. Система BullSequana SH является модульной и расширяемой, базовым строительным блоком служит модуль SH20 с двумя процессорам Sapphire Rapids и 32 слотами DDR5 с поддержкой Optane PMem 300. Опциально такой модуль может нести на борту и пару DPU или GPU. До четырёх таких блоков можно объединить в единую систему с 8 процессорами, 32 Тбайт оперативной памяти и 8 ускорителями. Для этого нужны лишь UPI-коннекторы. Однако это не предел: с помощью специального модуля UBox высотой 3U, систему можно расширять и далее, не прибегая к помощи InfiniBand или иных сетей. Модуль UBox содержит внутри два контроллера Intel Ultra Path Interconnect (UPI), что позволяет с помощью одного модуля объединить в единую NUMA-систему до 16 процессоров. С помощью ещё одного UBox это число можно довести до 32 — именно такую конфигурацию имеет старшая модель BullSequana SH320. 
Источник изображений здесь и далее: Atos Все решения в серии SH поддерживают новые модели Xeon с числом ядер от 8 до 60 и частотами до 4,2 ГГц. Каждый модуль располагает двумя (1+1) блоками питания мощностью от 2200 до 3000 Вт, а также 12 вентиляторами с возможностью горячей замены. Для загрузки ОС в каждом модуле имеется 2 слота M.2, но опционально доступны дополнительные модули для установки NVMe-накопителей, а также корзины для GPU и PCIe-устройств с поддержкой горячей замены.  Компания также уделила внимание периферийным вычислениям: для этой сферы предназначены новые серверы BullSequana Edge EXR и EXD в корпусах 1U и 2U соответственно. Системы рассчитаны на использование процессоров Sapphire Rapids с числом ядер не более 24 и теплопакетом, не превышающим 185 Вт. Серверы могут функционировать при температурах от 0 до +45 °C в диапазоне влажности от 5% до 95%. Предусмотрена возможность крепления на стену. 
Модельный ряд BullSequana SH При этом предусмотрена возможность установки широкого ассортимента различных ускорителей — в спецификациях упоминаются NVIDIA T4, L40, H100, A2 и A16. Опционально в состав систем может входить поддержка беспроводных сетей LTE/5G, LoRA и Wi-Fi 6, поэтому серверы отлично подойдут и для развёртывания на периферии беспроводной инфраструктуры нового поколения. 
BullSequana Edge EXD (сверху) и EXR Модель EXR располагает 2 слотами M.2, но может комплектоваться дополнительной корзиной на 6 дисков SATA или 8 NVMe-накопителей, а EXD в некоторых конфигурациях может вмещать до 8 накопителей M.2 NVMe. Обе модели комплектуются двухпортовым 10GbE-контроллером (опционально 25GbE). Все новые системы Atos на базе новых процессоров Intel Xeon обеспечивают высокую степень безопасности благодаря поддержке Atos Root of Trust и Atos Chain-of-Trust.
11.01.2023 [03:00], Игорь Осколков
Асимметричный ответ: Intel официально представила процессоры Xeon Sapphire RapidsIntel официально представила серверные процессоры Xeon семейства Sapphire Rapids (SPR), выход которых изрядно задержался, а также ускорители ранее известные как Ponte Vecchio и теперь объединённые вместе с HBM-версиями SPR в отдельную HPC-серию Max. В этом поколении Intel не смогла догнать AMD EPYC Genoa по числу ядер, числу каналов памяти и линий PCIe, но заготовила ассиметричный, хотя и очень странно реализованный ответ. Всего представлено 52 модели с числом P-ядер от 8 до 60 и с TDP от 125 до 350 Вт. По числу ядер это существенный апгрейд по сравнению с Ice Lake-SP (до 40 ядер), да и IPC вырос у Golden Cove на 15 % в сравнении с Sunny Cove. Но это существенный проигрыш в сравнении с Genoa (до 96 ядер), особенно если учитывать их максимальный TDP в 360 Вт (cTDP до 400 Вт). Правда, у Sapphire Rapids есть ещё и экономичный режим работы, в котором энергопотребление снижается на 20 %, а производительность для некоторых нагрузок — всего на 5 %. 
Изображения: Intel Sapphire Rapids предлагают 8 каналов памяти DDR5-4800 (1DPC) и DDR5-4400 (2DPC). 2DPC у Genoa пока что нет. Кроме того, контроллеры поддерживают и модули Optane PMem 300 (Crow Pass), но с учётом того, что производство 3D XPoint прекращено, достаться они могут не всем (впрочем, не всем они и нужны). Ну а маленькая серия Max также включает 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с). Остались и отличия в максимальном объёме SGX-анклавов в зависимости от модели CPU. 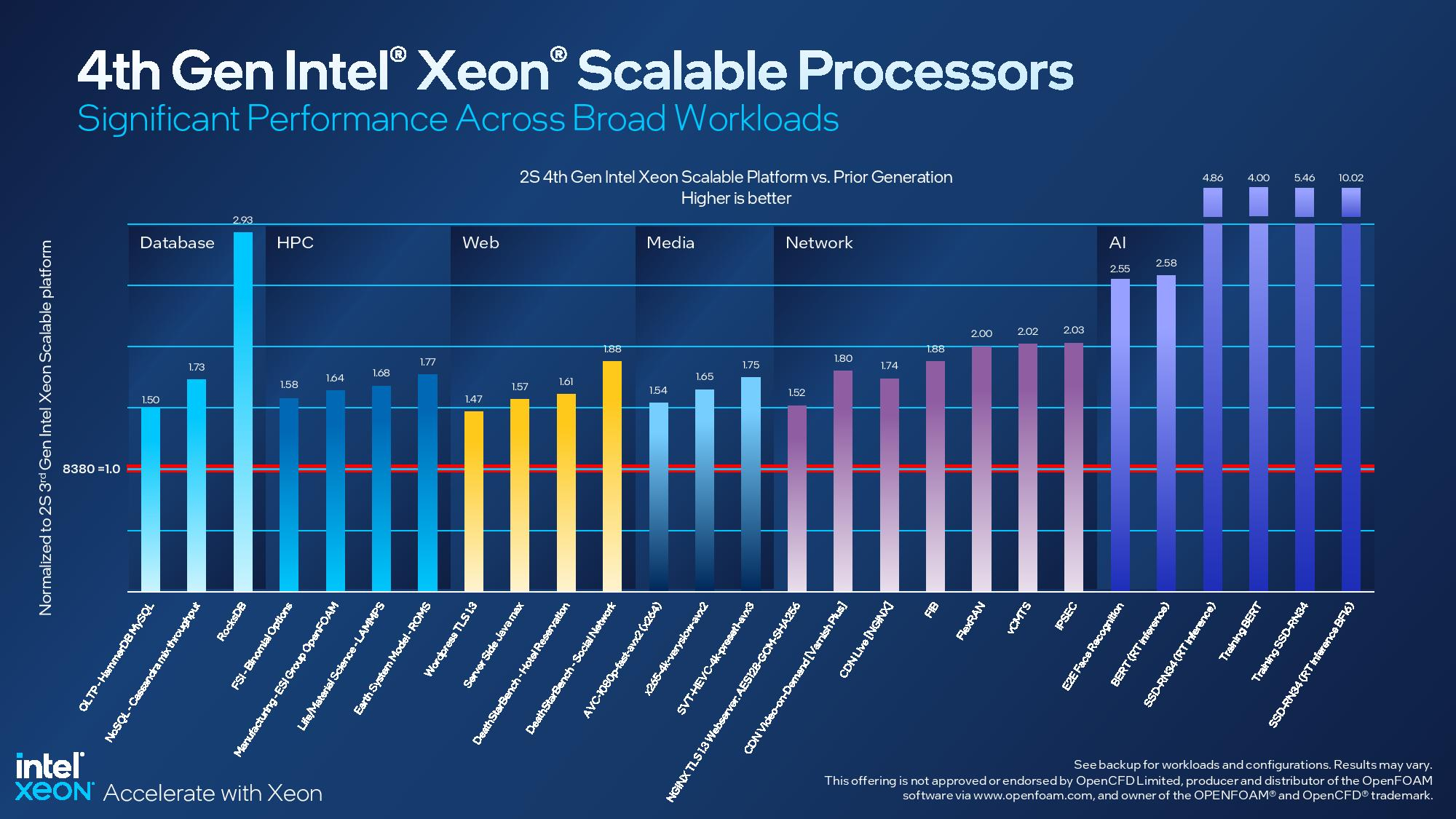 Однако по числу ядер на узел всё равно лидирует Intel. Если AMD поддерживает только 2S-конфигурации, то Intel снова предлагает и 4S, и 8S (а с момента выхода Cooper Lake-SP прошло немало времени) — на процессор доступно до 4 линий UPI 2.0 (16 ГТ/с в сравнении с 11,2 ГТ/с у Ice Lake-SP). В 2S-платформах Sapphire Rapids также формально обгоняет Genoa по числу линий PCIe 5.0, которых тут по 80 шт. на сокет. Формально потому, что в случае Genoa при желании всё же можно получить 160 линий, пожертвовав скоростью шины между CPU, но в односокетном варианте EPYC в любом случае интереснее Xeon. 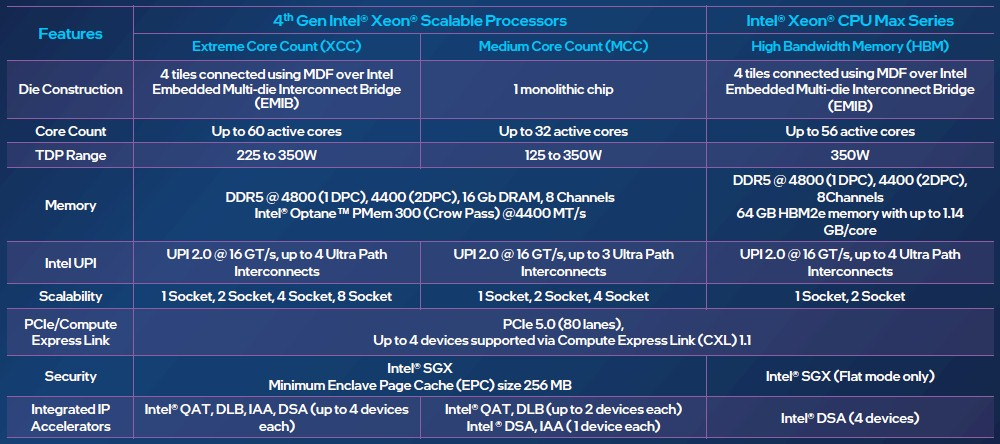 Без нюансов тут не обошлось. Так, при бифуркации до 8 x2 скорость падает до PCIe 4.0. Зато каждый root-комплекс поддерживает CXL 1.1, тогда как у Genoa CXL есть только у половины! Впрочем, поддержка всё равно ограничена 4x CXL-устройствами на CPU. Что ещё более странно, официально заявлена поддержка только устройств Type 1 и Type 2, но не Type 3, хотя последние весьма пригодились бы в ряде конфигураций, где требуется больше относительно недорогой, пусть и несколько более медленной, RAM. 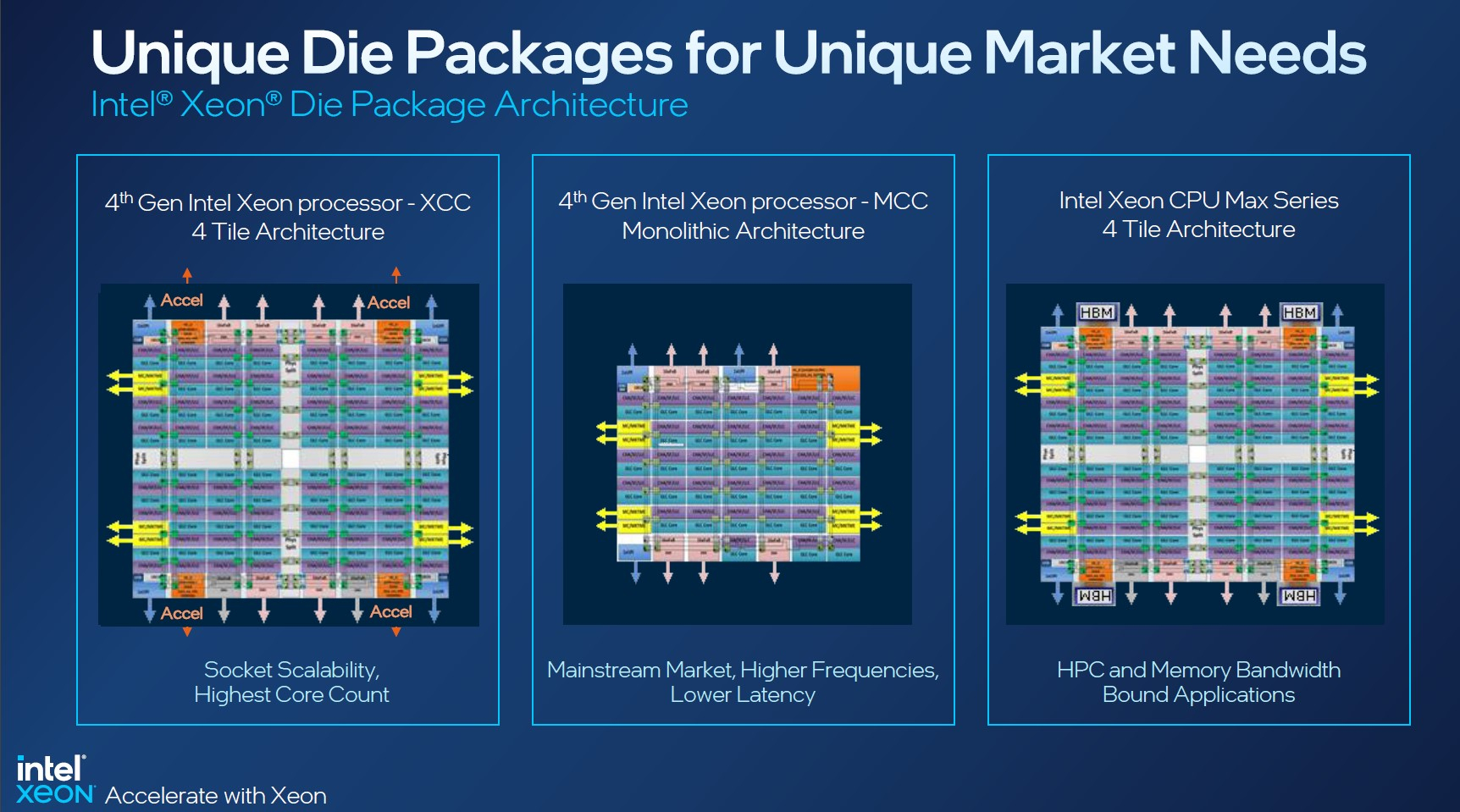 Сохранилось традиционное разделение на серии Platinum (8000), Gold (6000/5000), Silver (4000) и Bronze (3000), к которым теперь добавилась серия Max (9400). Список суффиксов, означающих оптимизацию под те или иные задачи и наличие каких-то особенностей, стал чуть шире: Y (SST-PP 2.0), Q (рассчитаны на работу с СЖО), U (односокетные общего назначения), T (увеличенный жизненный цикл), H (in-memory СУБД, аналитика, виртуализация), N (сетевые решения, в том числе для 5G), облачные P/V/M (IaaS/Paa/медиа), S (СХД и HCI). 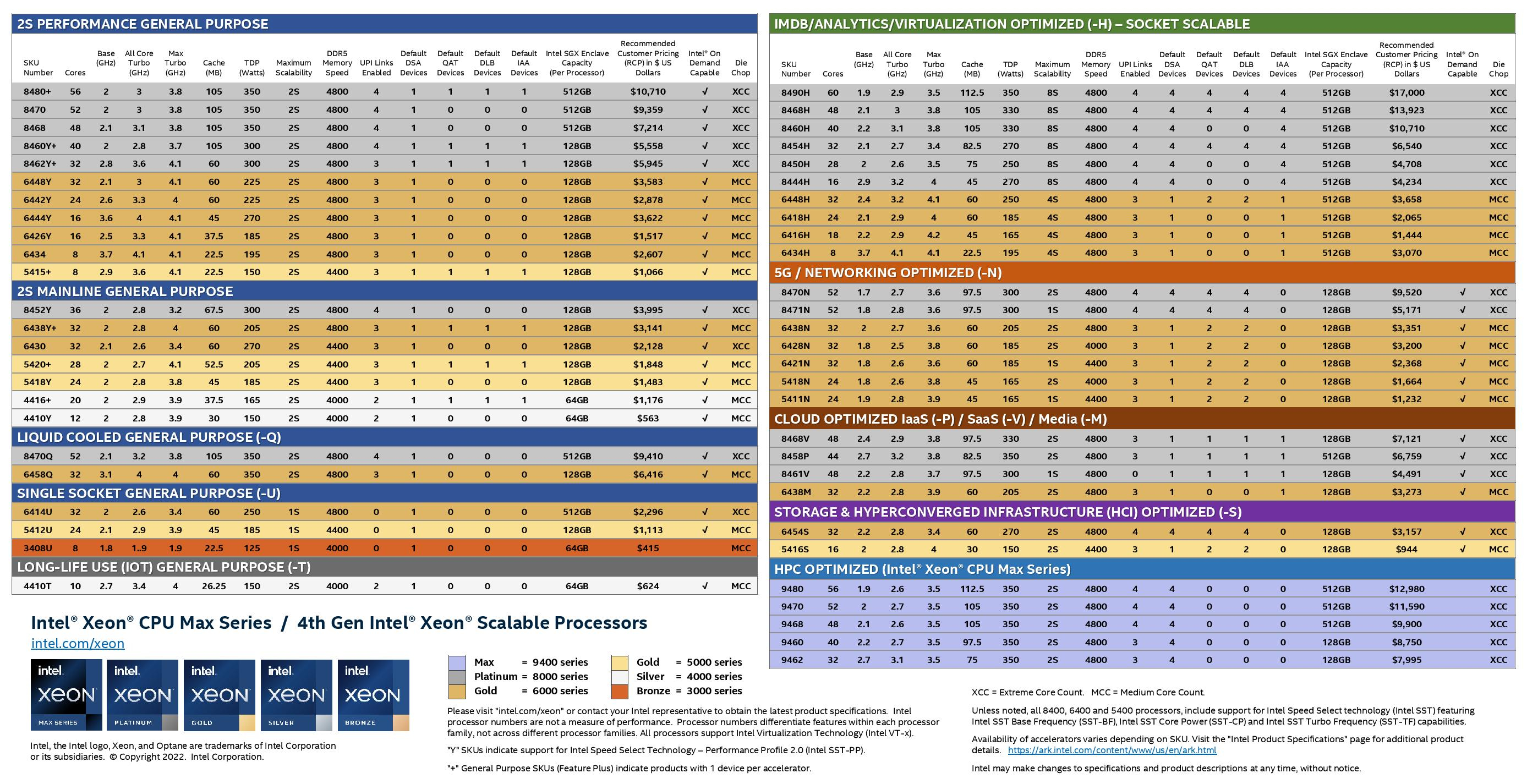 Но некоторые модели также имеют в названии «+». И вот тут начинается самое интересное! Все процессоры получили «традиционную» (в сравнении с Genoa) реализацию AVX-512, включая DL Boost, а также целый новый набор ИИ-инструкций AMX (до 10 раз быстрее обучение и инференс в сравнении с Ice Lake-SP). Есть и всяческие Speed Select, DDIO, TDX, CET и т.д. Но Sapphire Rapids также получили четыре отдельных ускорителя:
 Intel заявляет, что средний прирост производительности Sapphire Rapids в сравнении с Ice Lake-SP составил 1,53 раза. А вот для ряда нагрузок, которые могут задействовать новые ускорители прирост производительности на Вт составляет уже до 2,9 раз! То есть Intel продолжает придерживаться стратегии создания максимально универсальных CPU для различных нагрузок. И действительно, спорить с гибкостью Sapphire Rapids трудно. Но какой ценой это достигается? Т.е. буквально: во сколько это обойдётся заказчику? Ответа пока нет.  Дело в том, что в зависимости от модели отличается число доступных и число активированных ускорителей. Фактически в новом поколении используется два вида кристаллов: XCC, «сшитые» из четырёх отдельных тайлов, и монолитные MCC (до 32 ядер, причём 32-ядерных моделей в серии большинство). У каждого тайла в XCC есть по одному блоку QAT, DSA, DLB и IAA, т.е. суммарно на CPU приходится до четырёх ускорителей каждого типа. В случае MCC может быть по два QAT и DLB и по одному DSA и IAA на процессор. Например, у тех моделей, что помечены «+», активно по одному блоку каждого типа, а минимум один DSA активен есть вообще у всех CPU.  За не активированные по умолчанию ускорители придётся заплатить в рамках программы Intel On Demand (SDSi), причём есть опции как с единовременным платежом за постоянную активацию, так и с оплатой по факту использования (это удобно в случае облаков и платформ по типу HPE Greenlake). Исключением являются H-модели, куда входит и самый дорогой ($17000) 60-ядерный процессор 8490H с полностью разблокированными ускорителями и поддержкой 8S-конфигураций, а также процессоры Max, которым доступно только четыре DSA-блока и 2S-платформы, например, 56-ядерный 9480 ($12980). 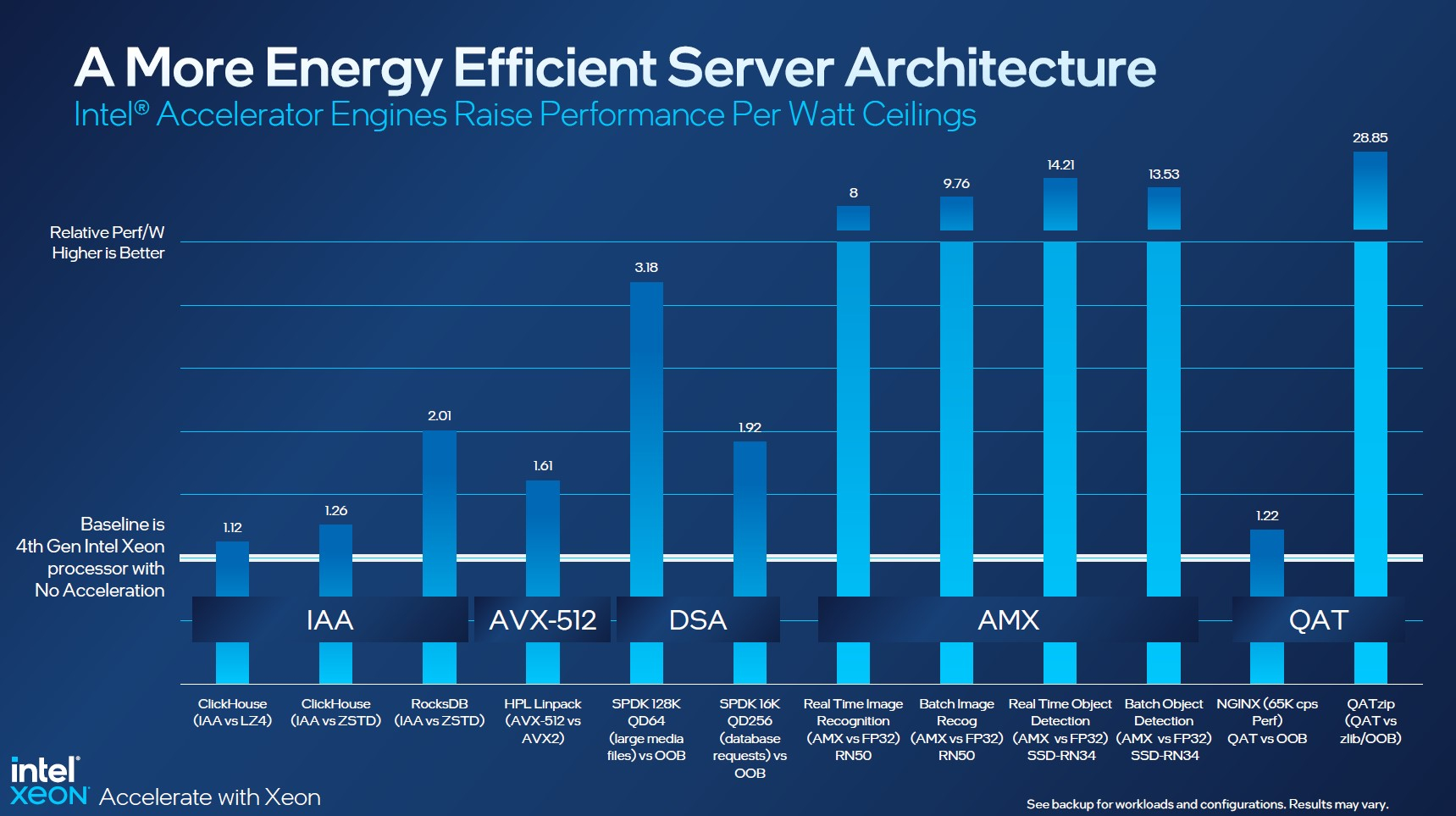 С одной стороны, желание Intel предоставить больше гибкости заказчикам, а заодно чуть увеличить выход годных к продаже процессоров, понятно. С другой — не очень-то и похоже, что CPU без «лишних» ускорителей отдаются с какой-то существенной скидкой. При этом транзисторный бюджет на них всё равно расходуется. Кроме того, есть ещё момент востребованности этих ускорителей и готовности ПО. У Intel есть и опыт ресурсы для помощи разработчикам, но процесс адаптации в любом случае не мгновенен.  Впрочем, у Intel по сравнению с AMD есть и ещё одно важное преимущество — в среднем более высокая доступность процессоров для большинства заказчиков. Так что с Sapphire Rapids может повториться та же история, что с Ice Lake-SP, когда вендоры здесь и сейчас готовы были предложить Intel-платформы.  В целом же, в новом семействе наиболее любопытны Xeon Max, которые, по словам Intel, по сравнению с прошлым поколением в 3,7 раз производительнее в задачах, завязанных на пропускную способность памяти (а это целый пласт HPC-нагрузок), и которые не так уж дороги. Правда, и здесь без приключений не обошлось — несчастный суперкомпьютер Aurora ожидает утомительный апгрейд его 10 тыс. узлов c простых Xeon Sapphire Rapids на Xeon Max — по полчаса на каждый узел.
13.12.2022 [21:52], Алексей Степин
Ventana анонсировала первый по-настоящему серверный RISC-V процессор Veyron V1: 192 ядра с частотой 3,6 ГГцАрхитектура RISC-V достаточно молода и обычно ассоциируется с экономичными чипами на платах, подобных Raspberry Pi. Однако технически она позволяет создавать и мощные процессоры, способные поспорить с лучшими решениями на базе архитектур Arm и x86. На саммите RISC-V компания Ventana Micro Systems анонсировала целое семейство высокопроизводительных процессоров, первенцем в котором стал чип Veyron V1, который, по словам разработчиков, сможет потягаться в однопоточной производительности с самыми современными CPU класса High-End. 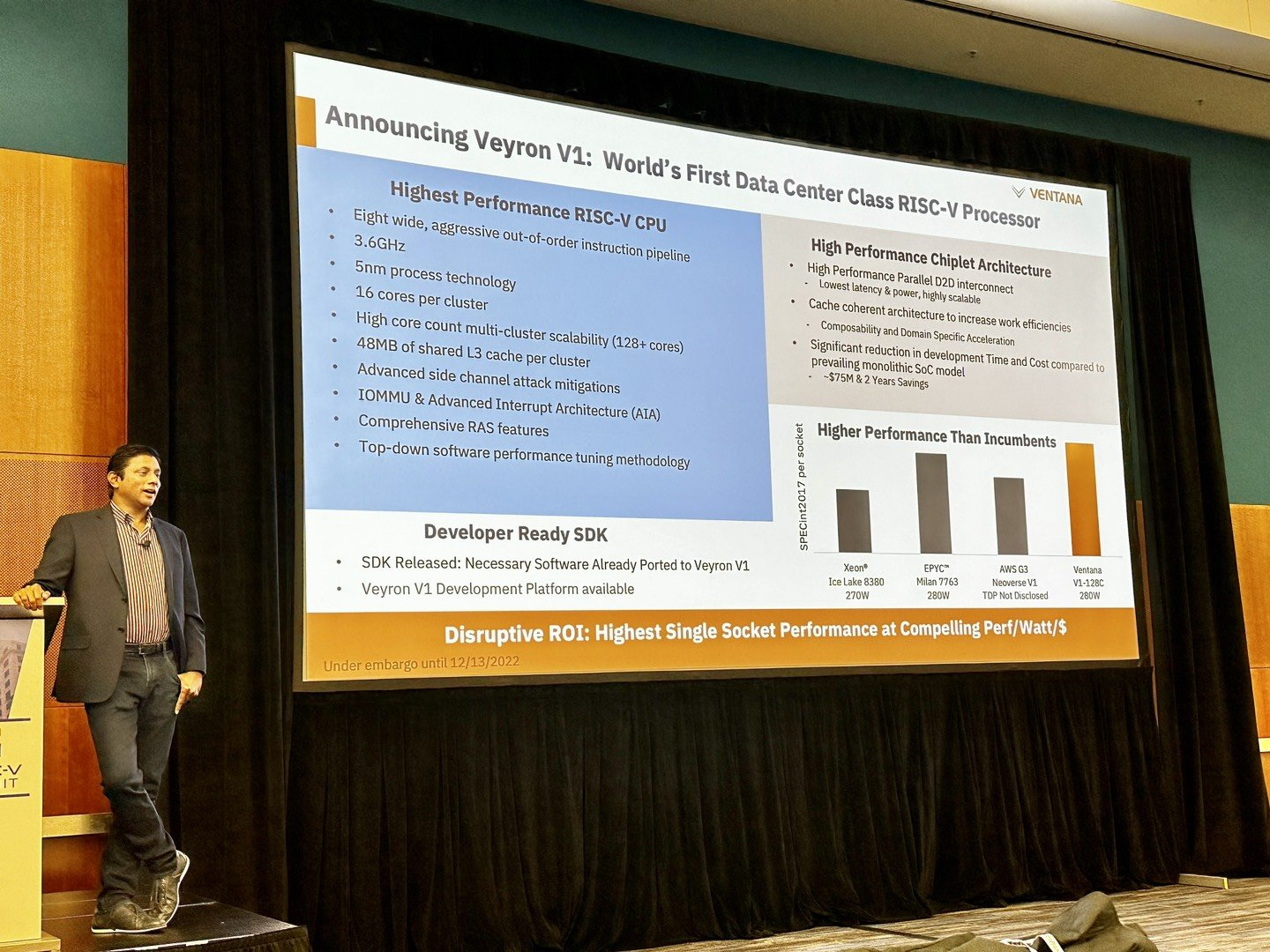
Veyron V1 должен стать самым быстрым процессором с архитектурой RISC-V. Источник: Twitter@risc_v Новинка нацелена на рынок гиперскейлеров, причём благодаря чиплетному дизайну новый процессор изначально разрабатывался как кастомизируемый под задачи заказчика. Veyron V1 будет предлагаться в виде своеобразного набора-конструктора, включающего в себя один или несколько вычислительных чиплетов Veyron, I/O-хаба и интерконнекта, позволяющего связать все компоненты воедино. Это, по словам разработчиков, должно серьёзно ускорить и удешевить процесс внедрения новой процессорной платформы, снизив расходы на разработку чипов на 75 %, а время создания — до не более чем двух лет. 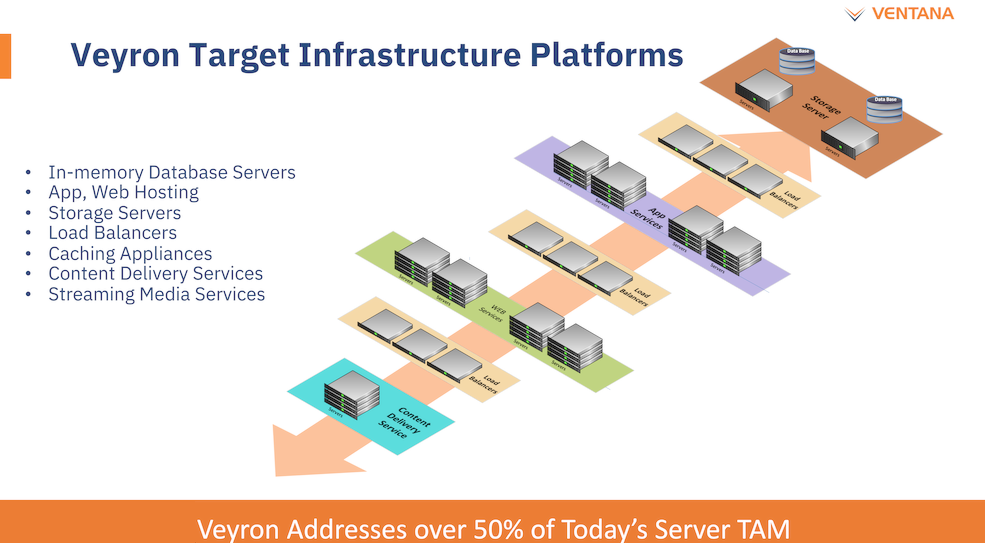
Платформа Veyron V1 универсальна и покрывает широкий спектр задач. Источник здесь и далее: StorageReview Вычислительный чиплет Veyron V1 использует продвинутые 64-битные ядра RISC-V и располагает 2 Мбайт кеша L2, а также многопоточным контроллером памяти. Предусмотрены конфигурации чиплета с 6, 8, 12 или 16 ядрами с частотой в районе 3 ГГц, что сопоставимо с решениями Google и AWS. Использоваться процессор может не только в ЦОД, но и в различных встраиваемых системах, базовых станциях 5G или даже клиентских рабочих станциях. 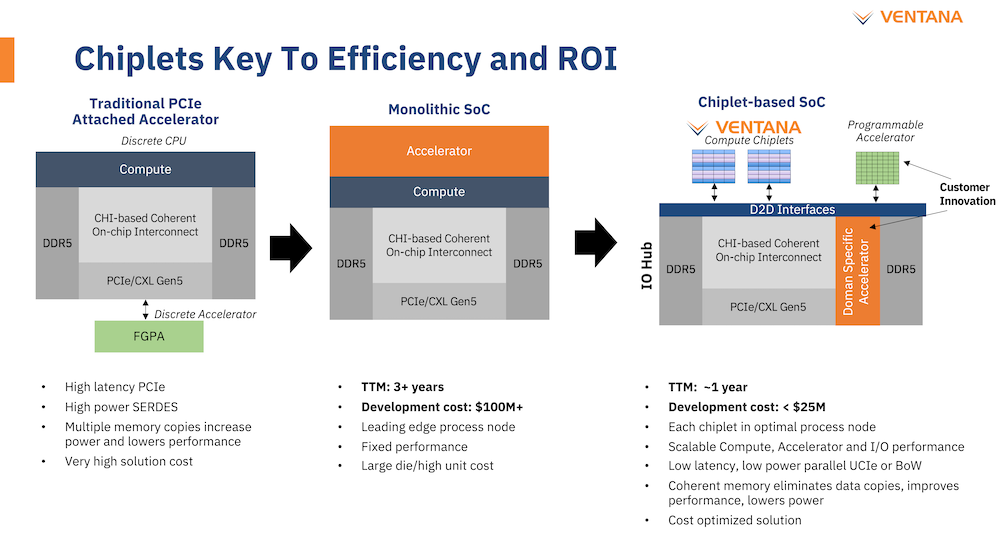
Чиплетная архитектура ускорит цикл разработки и внедрения, а также упростит задачу подключения кастомных ускорителей Архитектурно дизайн Veyron V1 использует агрессивный конвейер шириной восемь инструкций и с внеочередным исполнением. Чип способен работать на частоте до 3,6 ГГц благодаря использованию 5 нм техпроцесса TSMC. I/O-хаб может производиться с использованием более дешёвых 12 или даже 16-нм техпроцессов. Для соединения компонентов процессора разработан специальный низколатентный интерконнект D2D. 
Платформа разработки Veyron V1 и её технические характеристики Каждый чиплет включает в себя до 16 ядер, предусмотрена возможность масштабирования процессора до 192 ядер в 12 чиплетах. Общий объём разделяемого кеша L3 составляет 48 Мбайт. Заявлен высокий уровень защищённости архитектуры от атак по сторонним каналам. Разработчики заявляют о беспрецедентно низком энергопотреблении: 128 ядер V1 уложатся в 280 Вт; AMD EPYC 7763 потребляет столько же при вдвое меньшем числе ядер. 
Ventana поддержит новую платформу на всех уровнях разработки системного и прикладного ПО Анонс Ventana нельзя назвать «бумажным» — компания говорит о доступности комплектов разработчика, причём сразу в двух типах шасси: в настольном и в серверном корпусе высотой 2U. Конфигурация включает в себя 16-ядерную версию V1, 128 гбайт памяти DDR5, подключенной с помощью интерфейса CXL (PCIe 5.0) x16, два свободных слота расширения PCIe 5.0 x16, загрузочный накопитель NVMe M.2 и 8 NVMe SFF SSD формата 2,5" для хранения данных. Для удалённого управления предусмотрен 1GbE-порт. 
Большая часть критически важного программного обеспечения уже портирована на архитектуру RISC-V Компания не забыла и о поддержке со стороны программного обеспечения: платформы разработчика Ventana Veyron V1 будут сопровождаться полноценным SDK с основным ПО, уже портированным на новую архитектуру. В список входят компиляторы GCC и LLVM, отладчик OpenOCD/GDB, исходные коды и бинарные файлы загрузчиков U-Boot и Tianocore UEFI EDK2.1. Поддерживается ряд дистрибутивов Linux, а также другое системное и прикладное ПО. Ожидается, что новые системы будут доступны в начале следующего года.
30.11.2022 [16:55], Алексей Степин
AWS представила пятое поколение аппаратных гипервизоров NitroНа днях крупный провайдер облачных услуг, компания Amazon Web Services представила новые варианты инстансов на базе новейших процессоров Graviton3E, но данный чип — не единственная новинка AWS. Одновременно с Graviton3E было представлено и пятое поколение аппаратных гипервизоров Nitro, существенно выигрывающих по ключевым показателям у решений предыдущего, четвёртого поколения. 
Здесь и далее источник изображений: ServeTheHome Главная идея Nitro — сочетание «кремния» гипервизора, DPU и сопроцессора безопасности с поддержкой Root of Trust в едином чипе. В системах AWS плата с чипом Nitro полностью управляет распределением вычислительных ресурсов и памяти, избавляя от этой нагрузки хост-процессоры. По результатам тестов, проведённых AWS, производительность облачных инстансов с использованием ускорителей Nitro практически не отличается от производительности классической bare metal-системы.  AWS Nitro v5 использует кастомный кристалл, разработанный Annapurna Labs. По сравнению с Nitro v4, количество транзисторов было удвоено, но за счёт этого удалось на 60 % поднять скорость обработки сетевых пакетов, на 30 % снизить латентность, а также, благодаря продвинутому техпроцессу, обеспечить лучшую удельную производительность. 
Платы AWS Nitro v5 используют проприетарные разъёмы Улучшились и другие характеристики: на 50 % выросла пропускная способность памяти и вдвое возросла производительность подсистемы PCI Express. Платы Nitro v5 станут сердцем новых инстансов C7gn, где обеспечат полную изоляцию критически важных подсистем, таких, как прошивки BIOS, BMC и накопителей от гостевого доступа извне и позволят обновлять эти прошивки без влияния на клиентские нагрузки.  Также они возьмут на себя обслуживание сетей VPC/EBS, включая переход на использование SRD вместо TCP, и накопителей Nitro SSD. AWS уже объявила о возможности предварительного тестирования систем C7gn на базе Nitro v5 и новейших процессоров Graviton3/3E.
29.11.2022 [18:07], Сергей Карасёв
Служба AWS Time Sync стала доступна в виде публичного NTP-сервисаОблачная платформа Amazon Web Services (AWS) сообщила о том, что система синхронизации часов Time Sync теперь доступна в виде публичного NTP-сервиса. Ранее данная функция действовала только в рамках серверов AWS. Сервис Amazon Time Sync представляет собой высокоточный, надёжный и доступный источник времени для сервисов AWS, включая инстансы EC2. Система компенсирует отклонения, синхронизируя часы с парком резервных спутниковых и атомных часов в каждом регионе AWS. Синхронизация часов важна, в частности, при ведении журналов: дело в том, что сравнение двух файлов журналов на серверах с рассинхронизированными часами делает устранение неполадок гораздо сложнее. 
Источник изображения: Ahmad Ossayli / Unsplash Доступность Time Sync в виде публичного NTP-сервиса означает, что воспользоваться системой могут любые серверы и устройства Интернета вещей. Время синхронизируется с точностью до нескольких миллисекунд относительно всемирного координированного времени (UTC). Однако, как отмечается, сервис значительно менее точен, чем у конкурирующего Google, а Meta✴ начала полностью отказываться от NTP. Владелец Facebook✴ заявил, что перейдёт на протокол точного времени (PTP), что обеспечит точность в пределах наносекунд. При этом всем компаниям приходится иметь дело с дополнительной секундой, которая иногда добавляется в шкалу UTC для согласования со средним солнечным временем UT1. Эта практика, действующая с 1972 года, привела к ряду проблем, поэтому с 2000-х годов в международных организациях обсуждается отказ от введения дополнительной секунды.
29.11.2022 [17:12], Алексей Степин
AWS представила Arm-процессор Graviton3E, оптимизированный для задач ИИ и HPCОдин из крупнейших облачных провайдеров, компания Amazon Web Services объявила о доступности новых инстансов EC2 на базе процессора Graviton3E. Новый чип — наследник анонсированного в конце 2021 года Graviton3, 5-нм 64-ядерного процессора на дизайне Arm Neoverse V1 (Zeus) с поддержкой DDR5 и PCI Express 5.0. Graviton3 использует набор команд Armv8.4 c расширениями Neon (4×128 бит) и SVE (2×256 бит) и поддерживает работу с популярными в сфере машинного обучения форматами данных INT8 и BF16. В сравнении c Graviton2 процессор быстрее на 25-60 % при сохранении аналогичного уровня тепловыделения. Дизайн серверов AWS предусматривает наличие трёх процессоров на узел высотой 1U. 
Изображения: AWS Новый процессор Graviton3E представляет собой дальнейшее развитие Graviton3. Чип оптимизирован с учётом потребностей рынка высокопроизводительных вычислений и основное внимание в его архитектуре уделено повышению производительности на операциях с плавающей запятой и вычислениях с использованием векторной математики. AWS, к сожалению, пока не раскрывает деталей относительно архитектуры Graviton3E, но прирост производительности на векторных операциях относительно обычного Graviton3 может достигать 35 %. Помимо классического теста HPL новый процессор хорошо проявляет себя в тестах, имитирующих медико-биологические и финансовые задачи.  Сценарии нагрузок, характерные для HPC, как правило, активно оперируют перемещением крупных объемов данных. Чтобы оптимизировать этот процесс, в новых инстансах AWS использует сеть на базе Elastic Fabric с новыми адаптерами Elastic Network Adapter (ENA). Такая сеть оперирует т. н. Scalable Reliable Datagram (SRD) вместо всем привычных TCP-пакетов. SRD позволяет организовать повторную отправку пакетов за микросекунды вместо миллисекунд в классическом Ethernet. Сердцем же новых инстансов AWS стало пятое поколение аппаратных гипервизоров Nitro 5. В сравнении с предыдущим поколением, Nitro 5 обладает вдвое более высокой вычислительной производительностью, на 50 % повышенной пропускной способностью памяти, а также позволяет обрабатывать на 60 % больше сетевых пакетов при сниженной на 30 % латентности. 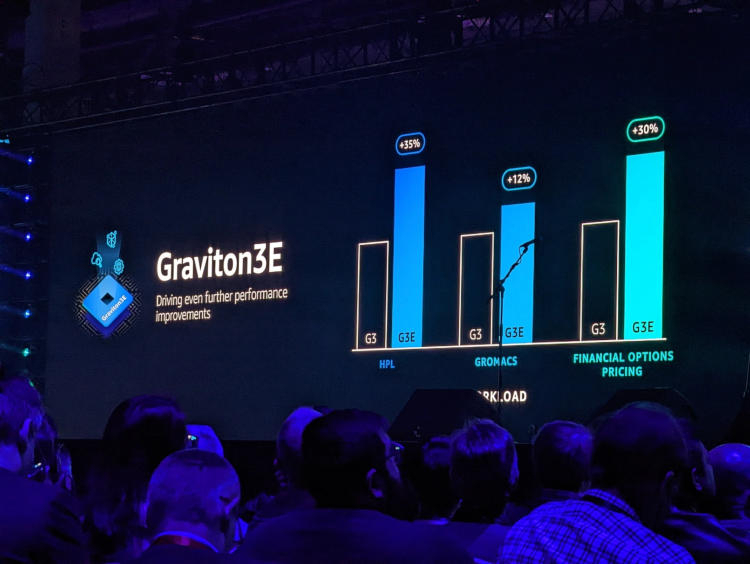
Здесь и далее источник изображений: AWS Инстансы Hpc7g с процессорами Graviton3E получат внутреннюю сеть с пропускной способностью 200 Гбит/с и станут доступны в различных конфигурациях вплоть до 64 vCPU и 128 ГиБ памяти. Аналогичные параметры имеют инстансы C7gn, предназначенные для задач с интенсивным сетевым трафиком: виртуальных маршрутизаторов, сетевых экранов, балансировщиков нагрузки и т.п. Также компания анонсировала инстансы R7iz, в которых используются процессоры Intel Xeon Scalable четвёртого поколения (Sapphire Rapids) с постоянной частотой всех ядер 3,9 ГГц. Они могут иметь конфигурацию до 128 vCPU с 1 ТиБ памяти.
29.11.2022 [12:20], Сергей Карасёв
В Италии официально запущен суперкомпьютер Leonardo — четвёртая по мощности HPC-система в миреСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU и некоммерческий консорциум CINECA, состоящий из 69 итальянских университетов и 21 национальных исследовательских центров, провели церемонию запуска суперкомпьютера Leonardo. В основу комплекса положены платформы Atos BullSequana X2610 и X2135. Система Leonardo состоит из двух секций — общего назначения и с ускорителями вычислений (Booster). Когда строительство системы будет завершено, первая будет включать 1536 узлов, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids с 56 ядрами и TDP в 350 Вт, 512 Гбайт оперативной памяти DDR5-4800, интерконнект NVIDIA InfiniBand HDR100 и NVMe-накопитель на 8 Тбайт. 
Источник изображения: HPCwire Секция Booster объединяет 3456 узлов, каждый из которых содержит один чип Intel Xeon 8358 с 32 ядрами, 512 Гбайт ОЗУ стандарта DDR4-3200, четыре кастомных ускорителя NVIDIA A100 с 64 Гбайт HBM2-памяти, а также два адаптера NVIDIA InfiniBand HDR100. Кроме того, в состав комплекса входят 18 узлов для визуализации: 6,4 Тбайт NVMe SSD и два ускорителя NVIDIA RTX 8000 (48 Гбайт) в каждом. Вычислительный комплекс объединён фабрикой с топологией Dragonfly+. 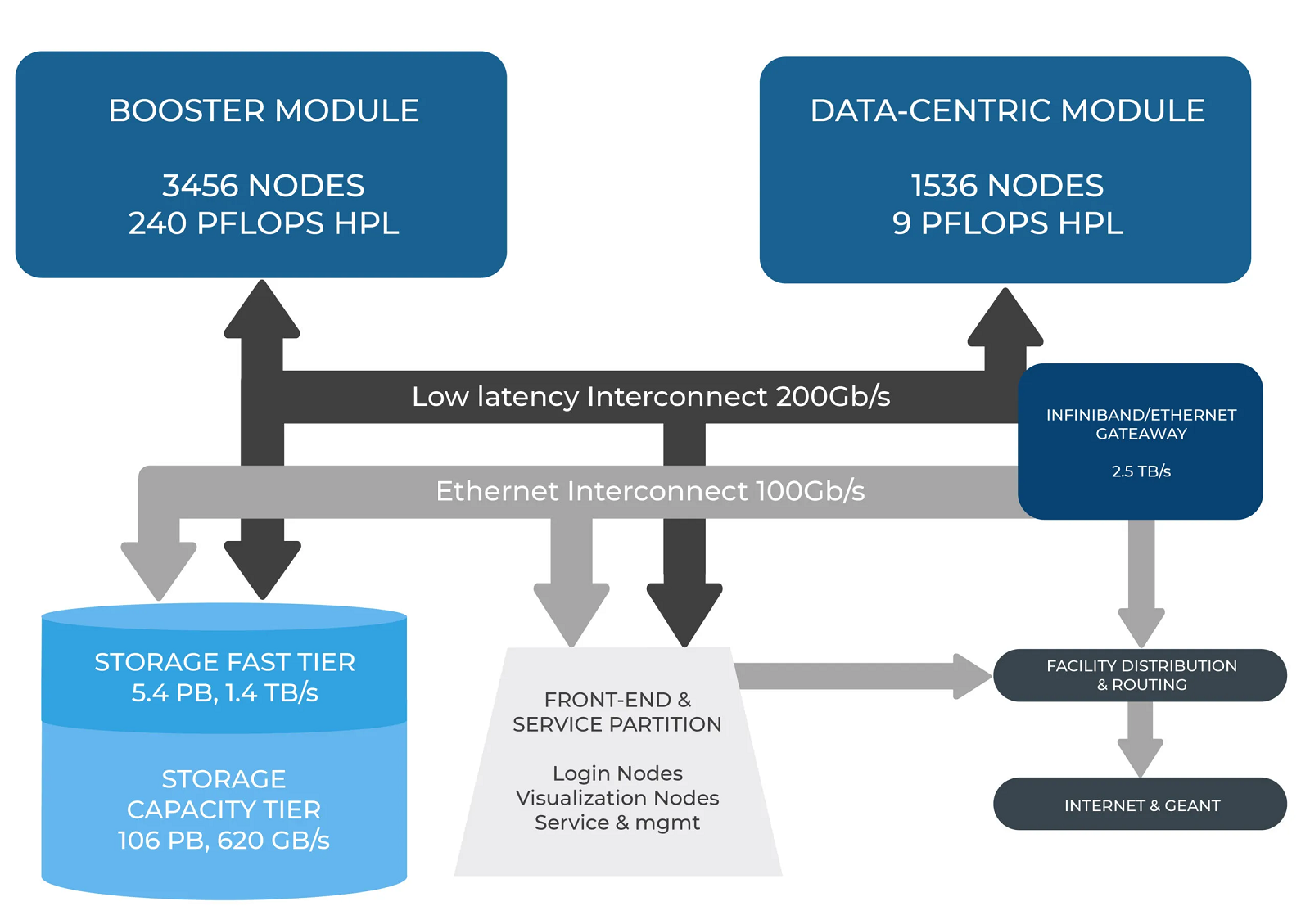
Источник: CINECA Для хранения данных служит двухуровневая система. Производительный блок (5,4 Пбайт, 1400 Гбайт/с) содержит 31 модуль DDN Exascaler ES400NVX2, каждый из которых укомплектован 24 NVMe SSD вместимостью 7,68 Тбайт и четырьмя адаптерами InfiniBand HDR. Второй уровень большой ёмкости (106 Пбайт, чтение/запись 744/620 Гбайт/с) состоит из 31 массива DDN EXAScaler SFA799X с 82 SAS HDD (7200 PRM) на 18 Тбайт и четырьмя адаптерами InfiniBand HDR. Каждый из массивов включает два JBOD-модуля с 82 дисками на 18 Тбайт. Для хранения метаданных используются 4 модуля DDN EXAScaler SFA400NVX: 24 × 7,68 Тбайт NVMe + 4 × InfiniBand HDR. 
Изображение: CINECA В настоящее время Leonardo обеспечивает производительность более 174 Пфлопс. Ожидается, что суперкомпьютер будет полностью запущен в первой половине 2023 года, а его пиковое быстродействие составит 250 Пфлопс. Уже сейчас система занимает четвёртое место в последнем рейтинге самых мощных суперкомпьютеров мира TOP500. В Европе Leonardo является второй по мощности системой после LUMI. Leonardo оборудован системой жидкостного охлаждения для повышения энергоэффективности. Кроме того, предусмотрена возможность регулировки энергопотребления для обеспечения баланса между расходом электричества и производительностью. Суперкомпьютер ориентирован на решение высокоинтенсивных вычислительных задач, таких как обработка данных, ИИ и машинное обучение. Половина вычислительных ресурсов Leonardo будет предоставлена пользователям EuroHPC.
15.11.2022 [19:08], Сергей Карасёв
Cerebras построила ИИ-суперкомпьютер Andromeda с 13,5 млн ядерКомпания Cerebras Systems сообщила о запуске уникального вычислительного комплекса Andromeda для выполнения «тяжёлых» ИИ-нагрузок. В основу Andromeda положен кластер из 16 блоков Cerebras CS-2, объединённых 96,8-Тбит/с фабрикой. Каждый из них содержит чип WSE-2, насчитывающий 850 тыс. ядер. Таким образом, общее число ядер достигает 13,5 млн. Кроме того, непосредственно в состав каждого чипа входят 40 Гбайт сверхбыстрой памяти. Система уже доступна коммерческим заказчикам, а также различным научным организациям. 
Источник изображения: Cerebras Systems Суперкомпьютер также использует 284 односокетных сервера с процессорами AMD EPYC 7713. Суммарное количество вычислительных ядер общего назначения составляет 18 176. Каждый из этих серверов несёт на борту 128 Гбайт оперативной памяти, NVMe-накопитель вместимостью 1,92 Тбайт и две сетевые карты 100GbE. Эти узлы отвечают за предварительную обработку информации. 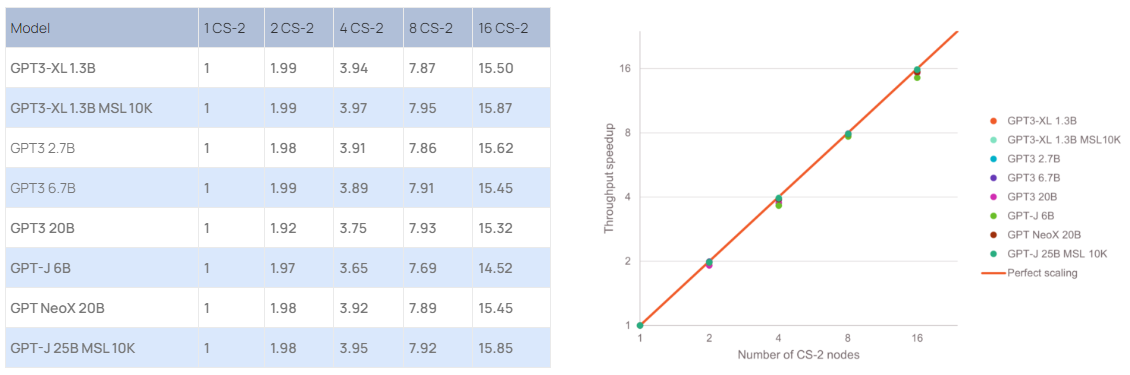
Источник: Cerebras Systems По заявлениям Cerebras, производительность системы превышает 1 Эфлопс на т.н. разреженных вычислениях и достигает 120 Пфлопс при обычных FP16-вычислениях. Это первый в мире суперкомпьютер, который обеспечивает практически идеальное линейное масштабирование при работе с GPT-моделями, в частности, GPT-3, GPT-J и GPT-NeoX. Иначе говоря, при каждом удвоении числа комплексов CS-2 время обучения моделей сокращается почти в два раза.  Суперкомпьютер смонтирован в дата-центре Colovore в Санта-Кларе (Калифорния, США). Стоимость системы составила приблизительно $30 млн, а на её развёртывание потребовалось всего три дня. Использовать ресурсы Andromeda могут одновременно несколько клиентов.
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 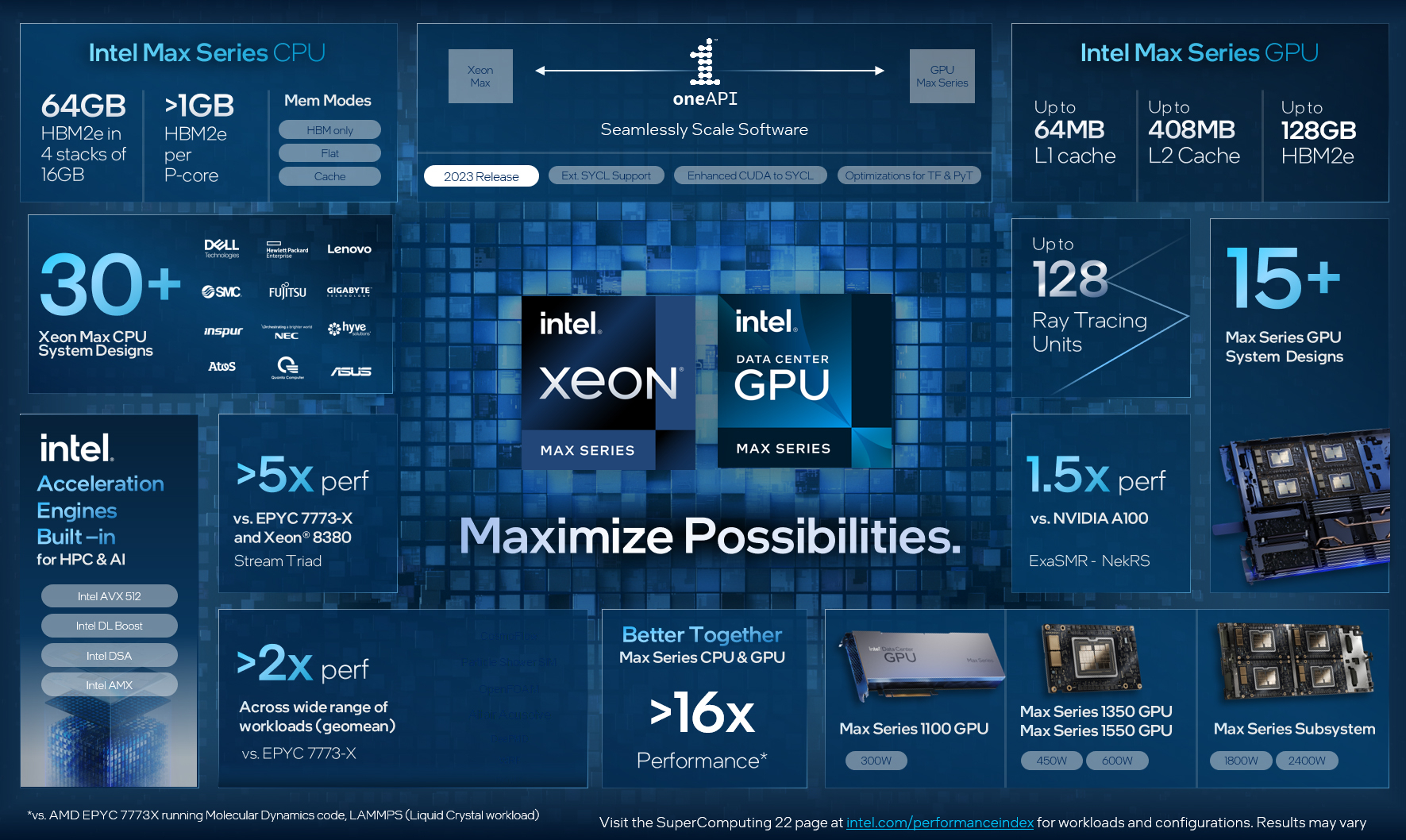
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 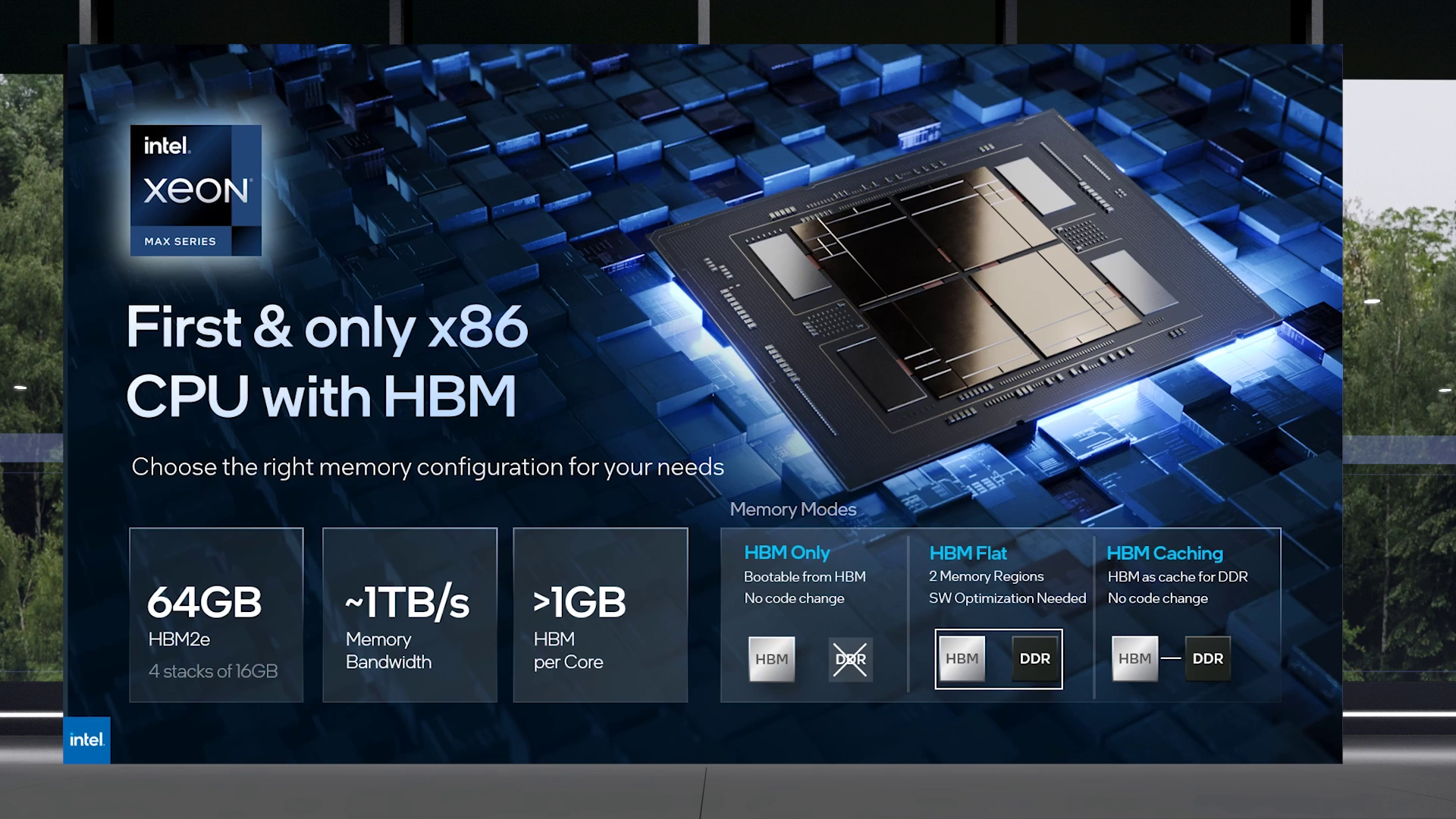 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA. |
|


