Материалы по тегу: cerebras
|
31.08.2024 [14:12], Сергей Карасёв
Cerebras Systems запустила «самую мощную в мире» ИИ-платформу для инференсаАмериканский стартап Cerebras Systems, занимающийся разработкой чипов для систем машинного обучения и других ресурсоёмких задач, объявил о запуске, как утверждается, самой производительной в мире ИИ-платформы для инференса — Cerebras Inference. Ожидается, что она составит серьёзную конкуренцию решениям на основе ускорителей NVIDIA. В основу облачной системы Cerebras Inference положены ускорители WSE-3. Эти гигантские изделия, выполненные с применением 5-нм техпроцесса TSMC, содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. Для сравнения: один чип HBM3e в составе NVIDIA H200 может похвастаться пропускной способностью «только» 4,8 Тбайт/с. 
Источник изображений: Cerebras По заявлениям Cerebras, новая инференс-платформа обеспечивает до 20 раз более высокую производительность по сравнению с сопоставимыми по классу решениями на чипах NVIDIA в сервисах гиперскейлеров. В частности, быстродействие составляет до 1800 токенов в секунду на пользователя для ИИ-модели Llama3.1 8B и до 450 токенов в секунду для Llama3.1 70B. Для сравнения, у AWS эти значения равны соответственно 93 и 50. Речь идёт об FP16-операциях. Cerebras заявляет, что лучший результат для кластеров на основе NVIDIA H100 в случае Llama3.1 70B составляет 128 токенов в секунду. 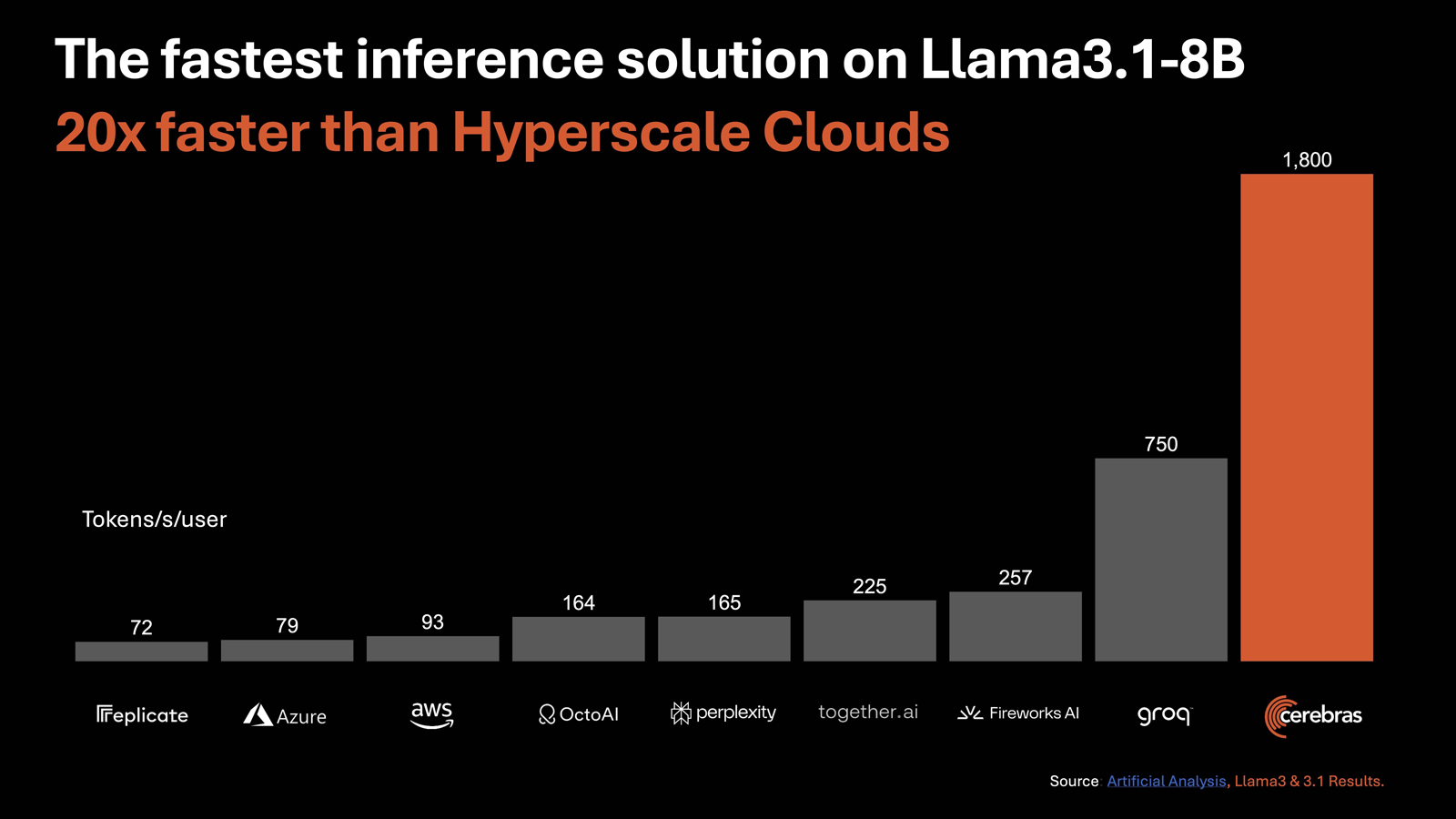 «В отличие от альтернативных подходов, которые жертвуют точностью ради быстродействия, Cerebras предлагает самую высокую производительность, сохраняя при этом точность на уровне 16 бит для всего процесса инференса», — заявляет компания. При этом услуги Cerebras Inference стоят в несколько раз меньше по сравнению с конкурирующими предложениями: $0,1 за 1 млн токенов для Llama 3.1 8B и $0,6 за 1 млн токенов для Llama 3.1 70B. Оплата взимается по мере использования. Cerebras планирует предоставлять инференс-услуги через API, совместимый с OpenAI. Преимущество такого подхода заключается в том, что разработчикам, которые уже создали приложения на основе GPT-4, Claude, Mistral или других облачных ИИ-моделей, не придётся полностью менять код для переноса нагрузок на платформу Cerebras Inference. 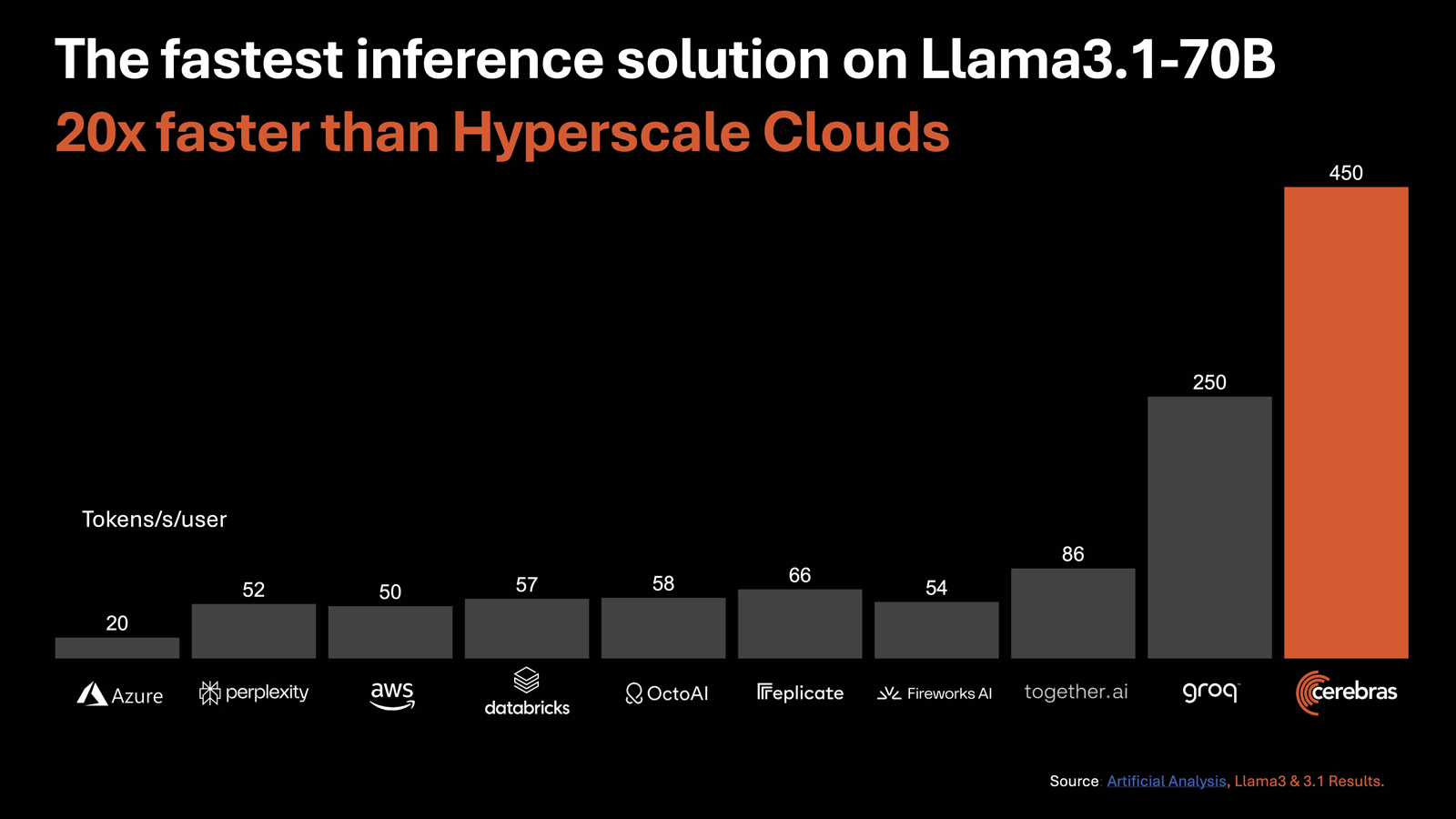 Для крупных предприятий предлагается план обслуживания Enterprise Tier, который предусматривает тонко настроенные модели, индивидуальные условия и специализированную поддержку. Стандартный пакет Developer Tier предполагает подписку по цене от $0,1 за 1 млн токенов. Кроме того, имеется бесплатный доступ начального уровня Free Tier с ограничениями. Cerebras говорит, что запуск платформы откроет качественно новые возможности для внедрения генеративного ИИ в различных сферах.
21.06.2024 [16:09], Руслан Авдеев
Производитель гигантских ИИ-суперчипов Cerebras Systems готовится к IPOСтартап Cerebras Systems Inc., выпускающий передовые ИИ-чипы и конкурирующий с NVIDIA, по слухам, подал регуляторам США документы для выхода на биржу Nasdaq. По данным Silicon Angle, IPO должно состояться позже в 2024 году. Компания выпускает специализированные и весьма производительные ИИ-чипы размером с кремниевую пластину. У NVIDIA немного конкурентов на мировом рынке, но Cerebras — как раз из их числа. Новейший флагманский чип компании WSE-3 был анонсирован в марте, ему предшествовала модель WSE-2, дебютировавшая в 2021 году. Ожидается, что WSE-3 станет доступен до конца текущего года. 
Источник изображения: Cerebras Cerebras говоит, что WSE-3 имеет в 52 раза больше ИИ-ядер, чем ускоритель NVIDIA H100. Чип будет доступен в составе модуля CS-3 размером с небольшой холодильник с интегрированной системой охлаждения и блоком питания. WSE-3 имеет пиковое быстродействие 125 Пфлопс в разреженных FP16-вычислениях. В компании утверждают, что таких характеристик более чем достаточно для конкуренции с лучшими ускорителями NVIDIA, а её чипы не только быстрее, но и энергоэффективнее. Статус компании, похоже, действительно способной конкурировать NVIDIA, должен привлечь внимание инвесторов. Например, с началом эры ИИ акции NVIDIA выросли почти на порядок, поэтому не исключено, что и Cerebras ожидает впечатляющий успех. По имеющимся данным, Cerebras уведомила регуляторов в Делавэре, где компания официально зарегистрирована, о намерении предложить в ходе ожидающегося раунда инвестиций привилегированные акции с большой скидкой. Хотя в самой Cerebras не комментируют слухи об IPO, Bloomberg сообщил, что компания выбрала Citigroup в качестве ведущего банка для первичного листинга. В Bloomberg отмечают, что IPO состоится не раньше II половины 2024 года, а руководство рассчитывает на оценку не менее $4 млрд, которую компания получила после последнего раунда финансирования серии F, позволившего привлечь $250 млн в 2021 году.
17.06.2024 [08:53], Руслан Авдеев
Cerebras и Dell предложат заказчикам современные ИИ-платформыРазработчик ИИ-суперчипов Cerebras Systems анонсировал сотрудничество с Dell. Вместе компании займутся созданием передовых вычислительных инфраструктур для генеративного ИИ. В рамках сотрудничества будут создаваться масштабируемые решения для ИИ-суперкомпьютеров Cerebras с платформами Dell на базе процессоров AMD EPYC Genoa. Источник изображения: Cerebras По словам участников проекта, новые технологические решения дадут возможность обучать модели, на порядки более крупные, чем те, что есть на данный момент. В частности, будут задействованы системы Dell PowerEdge R6615 на базе AMD EPYC 9354P, которые предоставят потоковый доступ к 82 Тбайт памяти — для обучения моделей практически любого размера. Совместные платформы Cerebras и Dell будут включать ИИ-системы и суперкомпьютеры. Также будет предложена тренировка ИИ-моделей и иные сервисы поддержки машинного обучения. Как утверждают в самой Cerebras, сотрудничество с Dell станет поворотной точкой, открывающие каналы глобальной дистрибуции. Компании предоставят ИИ-оборудование, ПО и экспертизу, что позволит заказчикам упростить и ускорить внедрении современных ИИ-технологий, попутно снизив TCO. В марте Cerebras представила новейшие суперчипы Cerebras WSE-3, а в мае появилась новость, что совместно с Core42 из ОАЭ компания создаст суперкомпьютер Condor Galaxy 3 (CG-3) со 172,8 млн ИИ-ядер.
13.03.2024 [22:40], Алексей Степин
Больше флопс за те же ватты: Cerebras представила царь-ускоритель WSE-3 и подружилась с QualcommКомпания Cerebras Systems, известная своими разработками в области сверхбольших ИИ-процессоров, рассказала о третьем поколении чипов Wafer Scale Engine. В своё время компания произвела фурор, представив процессор, занимающий всю площадь кремниевой пластины (46225 мм2). В первом поколении WSE речь шла о 1,2 трлн транзисторов при 400 тыс. ядер и 18 Гбайт сверхбыстрой памяти. WSE-2 состоял из 2,6 трлн транзисторов, имел 850 тыс. ядер и 40 Гбайт интегрированной памяти. В WSE-3 разработчики перешли на использование 5-нм техпроцесса TSMC, что позволило разместить на пластине такого же размера уже 4 трлн транзисторов, составляющих 900 тыс. ядер и 44 Гбайт SRAM. Суммарная пропускная способность набортной памяти достигает 21 Пбайт/с, а внутреннего интерконнекта — 214 Пбит/с. 
Источник изображений: Cerebras Казалось бы, выигрыш в количестве ядер по сравнению с WSE-2 не так уж велик, однако на этот раз Cerebras сделала упор на архитектуру. Если верить заявлениям разработчиков, WSE-3 практически вдвое быстрее WSE-2 при сопоставимом уровне энергопотребления (15 кВт) и той же цене: 125 Пфлопс против 75 Пфлопс в разреженных FP16-вычислениях. WSE-3 в 62 раза быстрее NVIDIA H100, хотя и сам чип WSE-3 в 57 раз больше. 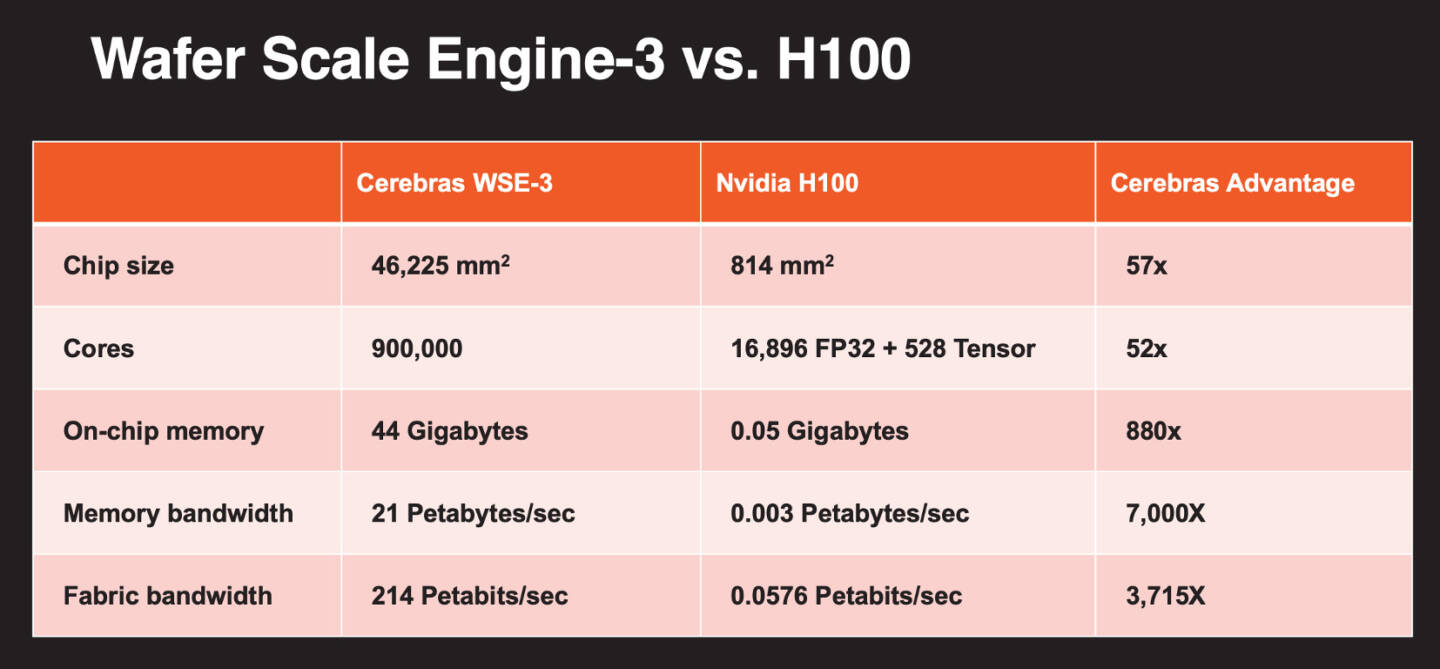 WSE-3 по-прежнему требует специфического окружения. Он станет сердцем новой системы CS-3 (23 кВт), содержащей всю необходимую сопутствующую инфраструктуру, включая СЖО, подсистемы питания, а также сетевого интерконнекта Ethernet. Последний не изменился и состоит из 12 каналов со скоростью 100 Гбит/с. Для подготовки «сырых» данных по-прежнему будет использоваться внешний суперсервер. А для их хранения будут использоваться узлы MemoryX ёмкостью до 1200 Тбайт (1,2 Пбайт). 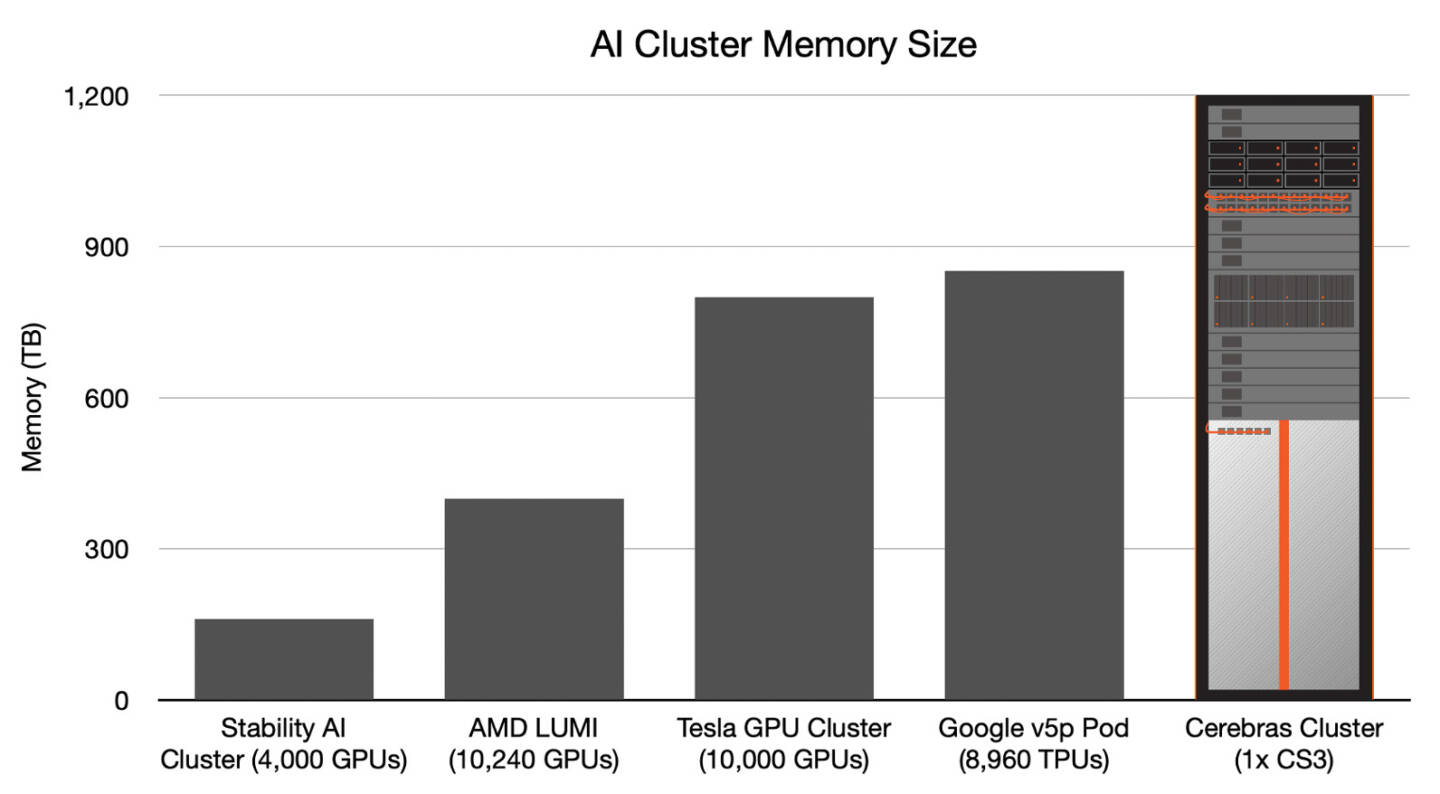 Главной задачей CS-3 станет «натаскивание» сверхбольших языковых моделей, в 10 раз превышающих по количеству параметров GPT-4 и Google Gemini. Cerebras говорит о 24 трлн параметров, причём без необходимости различных ухищрений для эффективного распараллеливания процесса обучения, что требуется в случае с GPU-кластерами. По словам компании, для обучения Megatron 175B на таких кластерах требуется 20 тыс. строка кода Python/C++/CUDA, а в случае WSE-3 потребуется лишь 565 строк на Python.  CS-3 поддерживает масштабирование вплоть до 2048 систем. Такая конфигурация вкупе с MemoryX сможет обучить модель типа Llama 70B всего за день. Первый суперкомпьютер на базе CS-3 — 8-Эфлопс Condor Galaxy 3 — будет скромнее и получит всего 64 стойки CS-3, которые разместятся в Далласе (США). В совокупности с уже имеющимися кластерами на базе CS-1 и CS-2 вычислительная мощность систем Cerebras должна достигнуть 16 Эфлопс. В сотрудничестве c группой G42 запланировано создание ещё шести систем CS-3, что в сумме позволит довести производительность до 64 Эфлопс.  Condor Galaxy 3 будет отличаться от предшественников ещё одним нововведением: в рамках сотрудничества с Qualcomm Cerebras установит в новом кластере существенное число инференс-ускорителей Qualcomm Cloud AI100 Ultra. Каждый такой ускоритель имеет 64 ядра, 128 Гбайт памяти LPDDR4x, потребляет 140 Вт и развивает 870 Топс на INT8-операциях. Причём програмнный стек полностью интегрирован, что позволит в один клик запустить обученные WSE-3 модели на ускорителях Qualcomm. 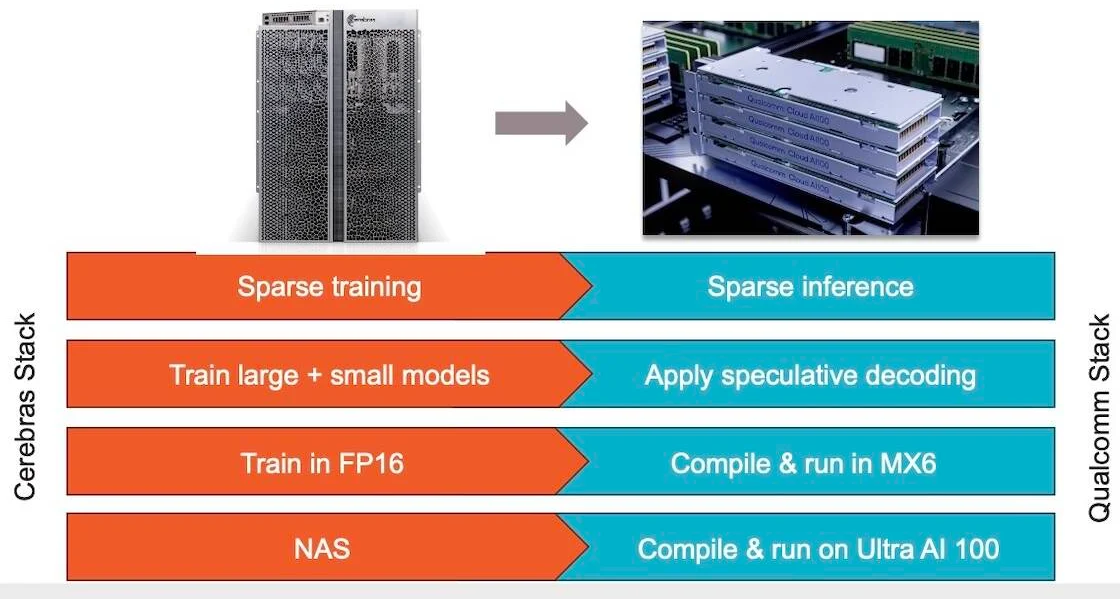 Сотрудничество Cerebras и Qualcomm носит официальный характер, его целью является оптимизация ИИ-моделей для запуска на AI100 Ultra с учетом различных продвинутых техник, таких как разреженные вычисления, спекулятивное исполнение (сочетание малых LLM для получения быстрого результата с проверкой большой LLM), использование «сжатого» формата MxFP6 для весов и других. Благодаря мощностям, предоставляемым WSE-3, цикл разработки, оптимизации и тестирования таких моделей удастся существенно ускорить, что в итоге должно обеспечить десятикратное улучшение удельной производительности новых решений.
29.11.2023 [01:21], Руслан Авдеев
Cerebras, критиковавшая NVIDIA за сотрудничество с Китаем, сама оказалась связана с компанией, ведущей дела с ПекиномХотя стартап Cerebras, занимающийся разработкой чипов, раскритиковал NVIDIA за попытки обойти санкционные ограничения в отношении Китая и призвал соблюдать не букву, но дух американского закона, у компании, похоже, нашлись свои скелеты в шкафу. Как сообщает The Register, сейчас в США расследуют деятельность клиента Cerebras — группы G42, возможно, помогавшей Поднебесной обходить санкционные ограничения. Американские спецслужбы подозревают, что базирующаяся в ОАЭ многопрофильная компания G42 поставляет в Китай передовые технологии. Для своих ИИ-исследований компания обратилась к Cerebras с целью постройки суперкомпьютерного кластера Condor Galaxy за $100 млн, а всего стартап намерен построить девять подобных объектов на $900 млн. При этом узлы кластера используют разработанные Cerebras чипы WSE-2, подходящие для обучения ИИ-систем. 
Источник изображения: Arthur Wang/unsplash.com Как показывают предварительные результаты расследования американских журналистов, властей и спецслужб, G42 пытается сотрудничать с Пекином и работает с китайскими компаниями вроде Huawei, давно находящимися под санкциями. В самой G42 утверждают, что принимают все меры для того, чтобы соблюдать американские ограничения. При этом, по данным журналистов, G42 считают прокси-компанией для работы в интересах КНР, помогающей Пекину получать вычислительные ресурсы и подсанкционные технологии. По словам главы Cerebras Эндрю Фельдмана (Andrew Feldman), его компания точно не будет вести бизнес с Китаем. Бизнесмен попал в неловкую ситуацию после того, как появилась информация о тесных связях G42 с Пекином. На запрос журналистов в Cerebras заявили, что кластеры Condor Galaxy находятся в США, а G42 получает к ним облачный доступ, так что любая активность контролируется и соответствует американским законам — государства-противники не имеют прямого доступа к ИИ-системам. Фельдман якобы не знал о сомнительном статусе G42, а в стартапе подчеркнули, что не комментируют слухи. Бюро промышленности и безопасности США уже обратилось к поставщикам облачных инфраструктур для консультаций о целесообразности дополнительных ограничений доступа к их услугам из некоторых стран. В частности, бюро интересует, как операторы намерены выявлять разработчиков ИИ-моделей, вызывающих обеспокоеность властей и что можно предпринять для устранения угроз. Кроме того, президент США предложил новые правила, согласно которым облакам потребуется докладывать о деятельности иностранцев, связанной с обучением больших языковых моделей (LLM).
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 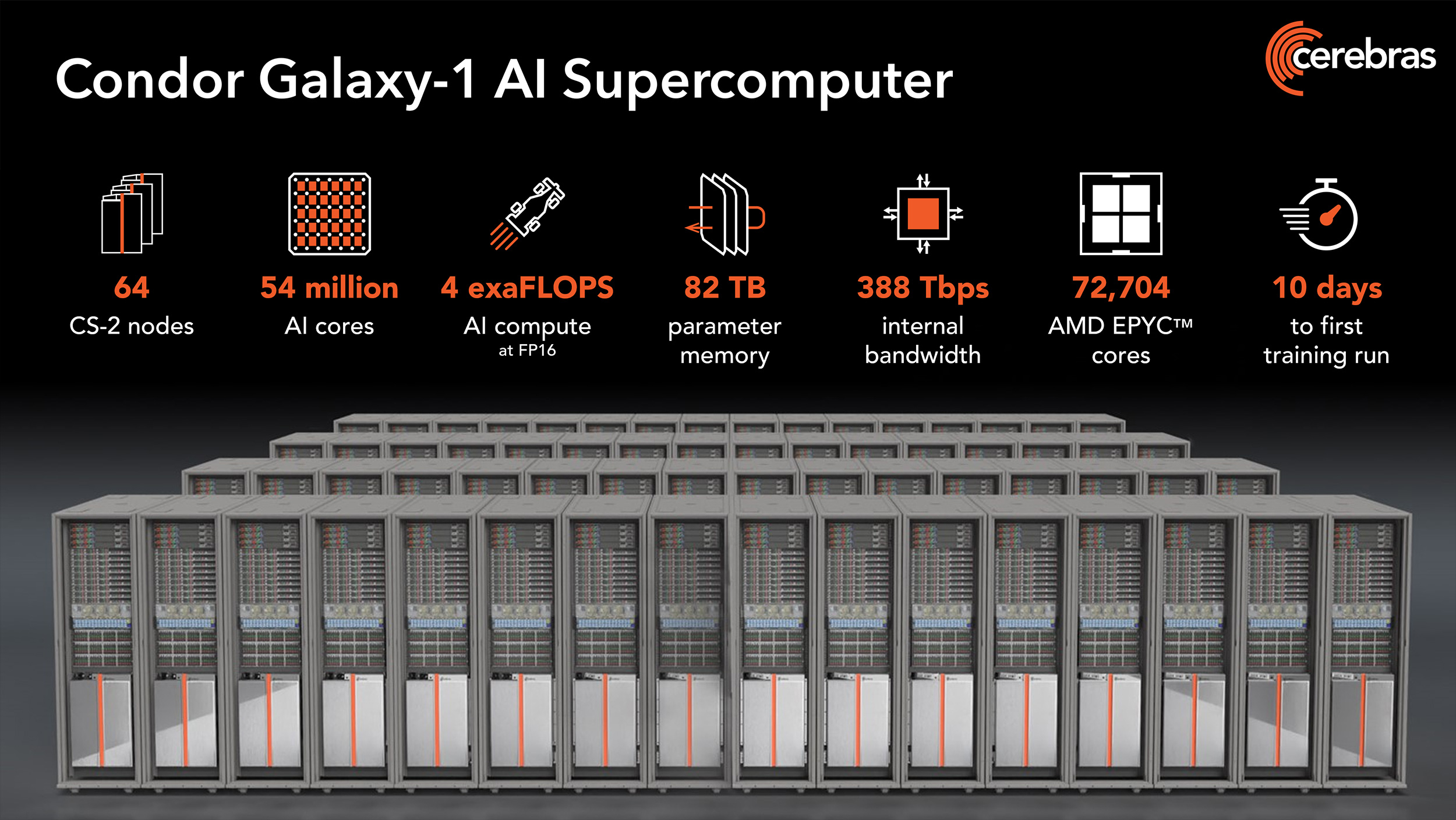
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
15.11.2022 [19:08], Сергей Карасёв
Cerebras построила ИИ-суперкомпьютер Andromeda с 13,5 млн ядерКомпания Cerebras Systems сообщила о запуске уникального вычислительного комплекса Andromeda для выполнения «тяжёлых» ИИ-нагрузок. В основу Andromeda положен кластер из 16 блоков Cerebras CS-2, объединённых 96,8-Тбит/с фабрикой. Каждый из них содержит чип WSE-2, насчитывающий 850 тыс. ядер. Таким образом, общее число ядер достигает 13,5 млн. Кроме того, непосредственно в состав каждого чипа входят 40 Гбайт сверхбыстрой памяти. Система уже доступна коммерческим заказчикам, а также различным научным организациям. 
Источник изображения: Cerebras Systems Суперкомпьютер также использует 284 односокетных сервера с процессорами AMD EPYC 7713. Суммарное количество вычислительных ядер общего назначения составляет 18 176. Каждый из этих серверов несёт на борту 128 Гбайт оперативной памяти, NVMe-накопитель вместимостью 1,92 Тбайт и две сетевые карты 100GbE. Эти узлы отвечают за предварительную обработку информации. 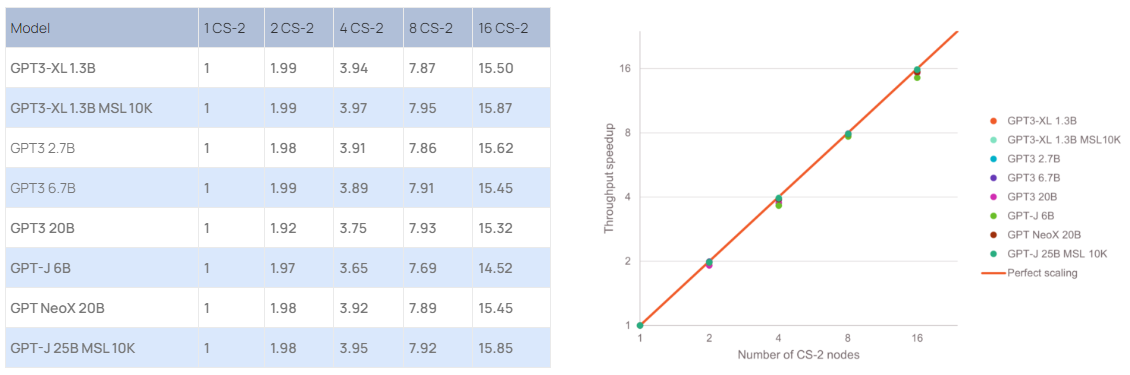
Источник: Cerebras Systems По заявлениям Cerebras, производительность системы превышает 1 Эфлопс на т.н. разреженных вычислениях и достигает 120 Пфлопс при обычных FP16-вычислениях. Это первый в мире суперкомпьютер, который обеспечивает практически идеальное линейное масштабирование при работе с GPT-моделями, в частности, GPT-3, GPT-J и GPT-NeoX. Иначе говоря, при каждом удвоении числа комплексов CS-2 время обучения моделей сокращается почти в два раза.  Суперкомпьютер смонтирован в дата-центре Colovore в Санта-Кларе (Калифорния, США). Стоимость системы составила приблизительно $30 млн, а на её развёртывание потребовалось всего три дня. Использовать ресурсы Andromeda могут одновременно несколько клиентов.
28.08.2021 [00:16], Владимир Агапов
Кластер суперчипов Cerebras WSE-2 позволит тренировать ИИ-модели, сопоставимые по масштабу с человеческим мозгомВ последние годы сложность ИИ-моделей удваивается в среднем каждые два месяца, и пока что эта тенденция сохраняется. Всего три года назад Google обучила «скромную» модель BERT с 340 млн параметров за 9 Пфлоп-дней. В 2020 году на обучение модели Micrsofot MSFT-1T с 1 трлн параметров понадобилось уже порядка 25-30 тыс. Пфлоп-дней. Процессорам и GPU общего назначения всё труднее управиться с такими задачами, поэтому разработкой специализированных ускорителей занимается целый ряд компаний: Google, Groq, Graphcore, SambaNova, Enflame и др.  Особо выделятся компания Cerebras, избравшая особый путь масштабирования вычислительной мощности. Вместо того, чтобы печатать десятки чипов на большой пластине кремния, вырезать их из пластины, а затем соединять друг с другом — компания разработала в 2019 г. гигантский чип Wafer-Scale Engine 1 (WSE-1), занимающий практически всю пластину. 400 тыс. ядер, выполненных по 16-нм техпроцессу, потребляют 15 кВт, но в ряде задач они оказываются в сотни раз быстрее 450-кВт суперкомпьютера на базе ускорителей NVIDIA.  В этом году компания выпустила второе поколение этих чипов — WSE-2, в котором благодаря переходу на 7-нм техпроцесс удалось повысить число тензорных ядер до 850 тыс., а объём L2-кеша довести до 40 Гбайт, что примерно в 1000 раз больше чем у любого GPU. Естественно, такой подход к производству понижает выход годных пластин и резко повышает себестоимость изделий, но Cerebras в сотрудничестве с TSMC удалось частично снизить остроту этой проблемы за счёт заложенной в конструкцию WSE избыточности. 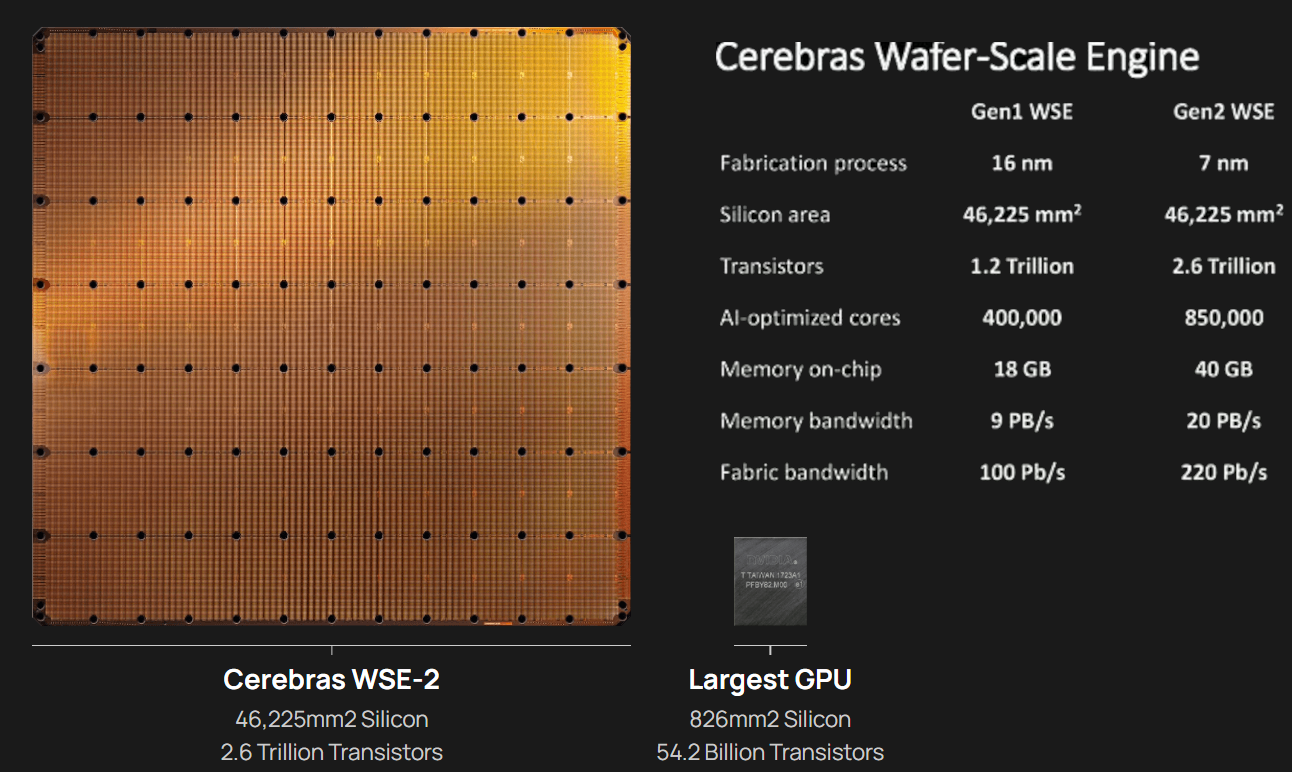 Благодаря идентичности всех ядер, даже при неисправности некоторых их них, изделие в целом сохраняет работоспособность. Тем не менее, себестоимость одной 7-нм 300-мм пластины составляет несколько тысяч долларов, в то время как стоимость чипа WSE оценивается в $2 млн. Зато система CS-1, построенная на таком процессоре, занимает всего треть стойки, имея при этом производительность минимум на порядок превышающую самые производительные GPU. Одна из причин такой разницы — это большой объём быстрой набортной памяти и скорость обмена данными между ядрами.  Тем не менее, теперь далеко не каждая модель способна «поместиться» в один чип WSE, поэтому, по словам генерального директора Cerebras Эндрю Фельдмана (Andrew Feldman), сейчас в фокусе внимания компании — построение эффективных систем, составленных из многих чипов WSE. Скорость роста сложности моделей превышает возможности увеличения вычислительной мощности путём добавления новых ядер и памяти на пластину, поскольку это приводит к чрезмерному удорожанию и так недешёвой системы.  Инженеры компании рассматривают дезагрегацию как единственный способ обеспечить необходимый уровень производительности и масштабируемости. Такой подход подразумевает разделение памяти и вычислительных блоков для того, чтобы иметь возможность масштабировать их независимо друг от друга — параметры модели помещаются в отдельное хранилище, а сама модель может быть разнесена на несколько вычислительных узлов CS, объединённых в кластер. 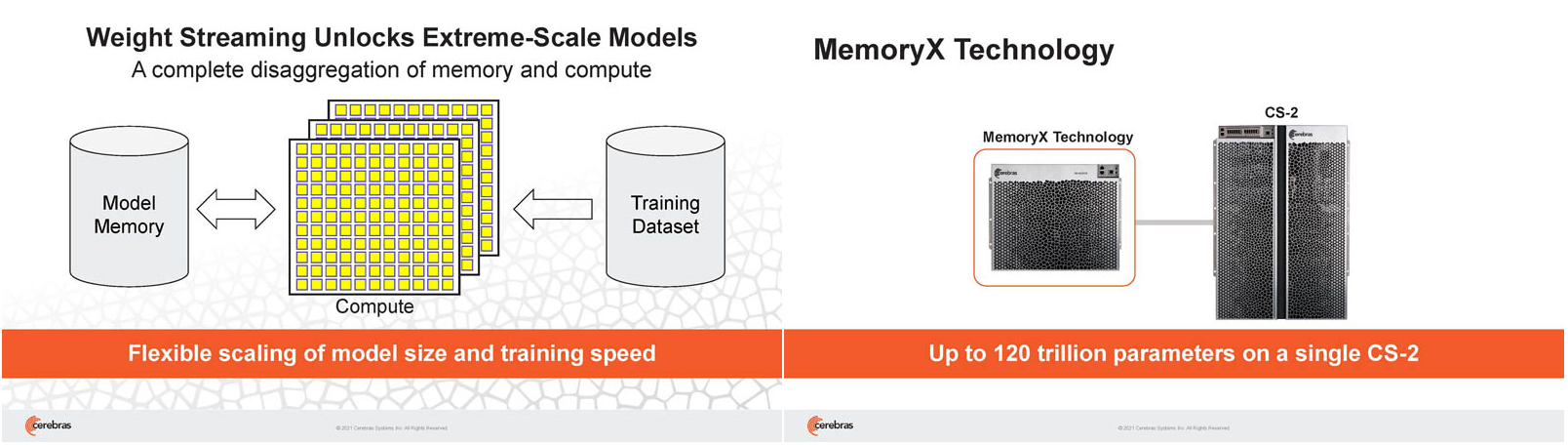 На Hot Chips 33 компания представила особое хранилище под названием MemoryX, сочетающее DRAM и флеш-память суммарной емкостью 2,4 Пбайт, которое позволяет хранить до 120 трлн параметров. Это, по оценкам компании, делает возможным построение моделей близких по масштабу к человеческому мозгу, обладающему порядка 80 млрд. нейронов и 100 трлн. связей между ними. К слову, флеш-память размером с целую 300-мм пластину разрабатывает ещё и Kioxia.  Для обеспечения масштабирования как на уровне WSE, так и уровне CS-кластера, Cerebras разработала технологию потоковой передачи весовых коэффициентов Weight Streaming. С помощью неё слой активации сверхкрупных моделей (которые скоро станут нормой) может храниться на WSE, а поток параметров поступает извне. Дезагрегация вычислений и хранения параметров устраняет проблемы задержки и узости пропускной способности памяти, с которыми сталкиваются большие кластеры процессоров. 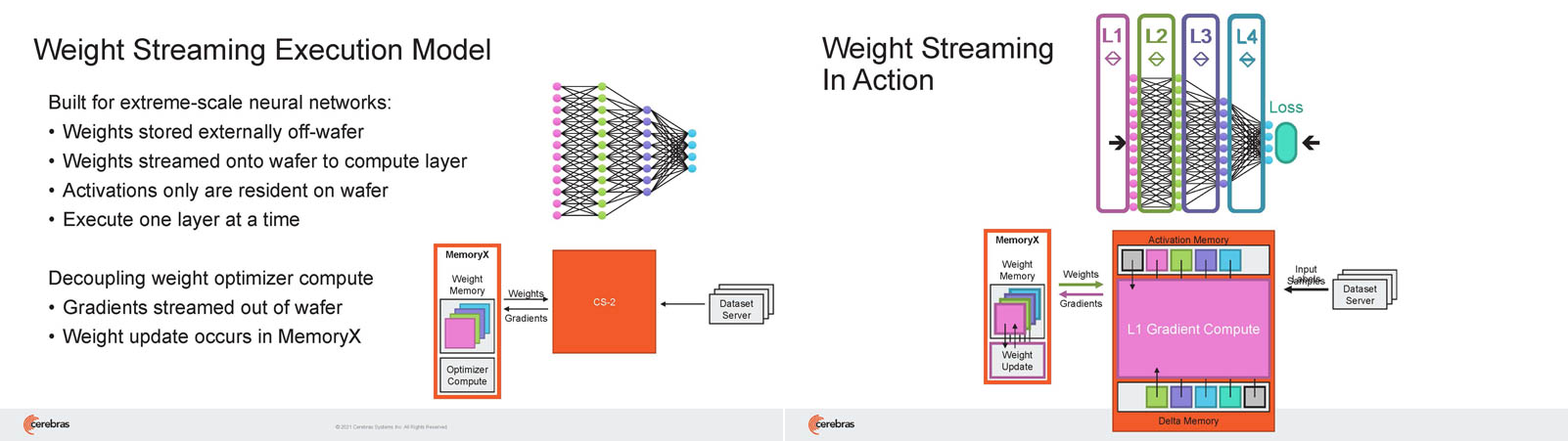 Это открывает широкие возможности независимого масштабирования размера и скорости кластера, позволяя хранить триллионы весов WSE-2 в MemoryX и использовать от 1 до 192 CS-2 без изменения ПО. В традиционных системах по мере добавления в кластер большего количества вычислительных узлов каждый из них вносит всё меньший вклад в решение задачи. Cerebras разработала интерконнект SwarmX, позволяющий подключать до 163 млн вычислительных ядер, сохраняя при этом линейность прироста производительности. 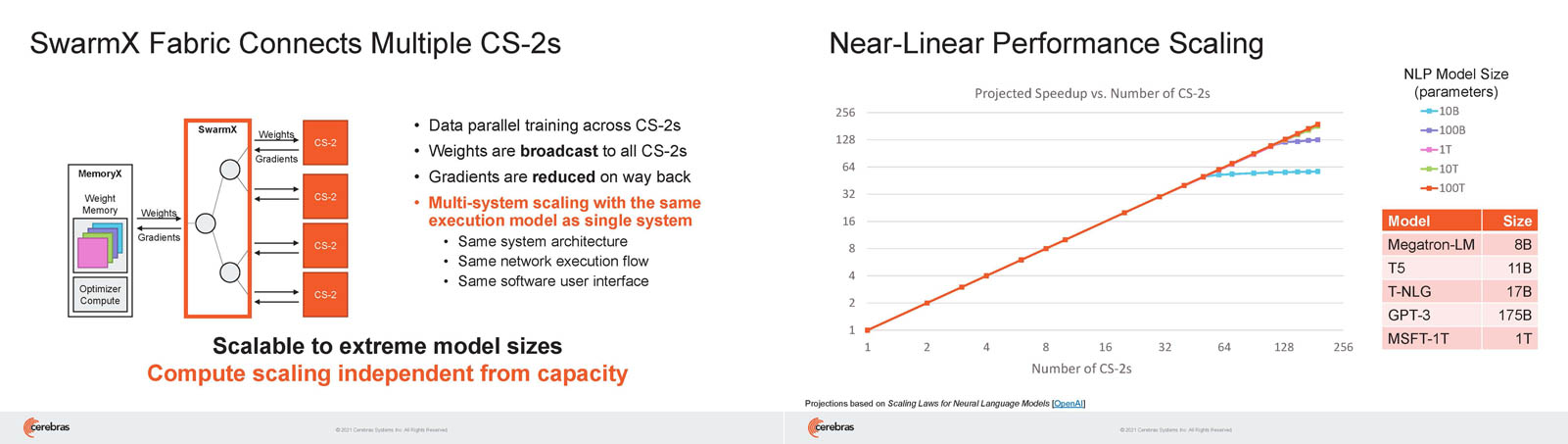 Также, компания уделила внимание разрежённости, то есть исключения части незначимых для конечного результата весов. Исследования показали, что должная оптимизации модели позволяет достичь 10-кратного увеличения производительности при сохранении точности вычислений. В CS-2 доступна технология динамического изменения разрежённости Selectable Sparsity, позволяющая пользователям выбирать необходимый уровень «ужатия» модели для сокращение времени вычислений.  «Крупные сети, такие как GPT-3, уже изменили отрасль машинной обработки естественного языка, сделав возможным то, что раньше было невозможно и представить. Индустрия перешла к моделям с 1 трлн параметров, а мы расширяем эту границу на два порядка, создавая нейронные сети со 120 трлн параметров, сравнимую по масштабу с мозгом» — отметил Фельдман.
09.06.2020 [19:49], Юрий Поздеев
Суперкомпьютер Neocortex: 800 тыс. ядер Cerebras для ИИПиттсбургский суперкомпьютерный центр (PSC) получит $5 млн от Национального научного фонда на создание суперкомпьютера нового типа Neocortex, который объединяет ИИ-серверы Cerebras CS-1 и HPE SuperDome Flex в единую систему с общей памятью. Планируется, что решение будет введено в эксплуатацию до конца 2020 года.  Каждый сервер Cerebras CS-1 имеет процессор Cerebras Wafer Scale Engine (WSE), который содержит 400 000 ядер, оптимизированных для работы с ИИ (46 225 мм2, 1,2 трлн транзисторов). В паре с ними работает HPE SuperDome Flex, который используется для предварительной обработки информации и постобработки после Cerebras. SuperDome Flex представлен в максимальной комплектации, то есть с 32 процессорами Intel Xeon, 24 Тбайт оперативной памяти, 205 Тбайт флеш-памяти и 24 интерфейсными картами.  Каждый сервер Cerebras CS-1 подключается к SuperDome Flex через 12 каналов со скоростью 100 Гбит/с каждый. Процессор WSE способен обрабатывать 9 Пбайт данных в секунду, что, по подсчетам Nystrom, эквивалентно примерно миллиону фильмов в HD-качестве. Характеристики решения действительно впечатляют! 
Neocortex назван в честь области мозга, отвечающей за функции высокого порядка, включая когнитивные способности, сновидения и формирование речи Архитектура решения строилась таким образом, чтобы не пришлось разбивать вычислительные блоки на множество узлов — это позволило снизить задержки в обработке информации и ускорить обучение моделей ИИ. Cerebras CS-1 разрабатывался специально для ИИ, поэтому он имеет преимущества перед серверами с графическими ускорителями, которые хорошо справляются с матричными операциями, но имеют многие конструктивные ограничения.  По заявлениям Neocortex, сервер CS-1 будет на несколько порядков мощнее системы PSC Bridges-AI. Один сервер Neocortex CS-1 будет эквивалентен примерно 800-1500 серверов с традиционной архитектурой с использованием графических ускорителей. Задачи, в которых Neocortex покажет себя максимально эффективно относятся к классу нейронных сетей DCIGN (deep convolutional inverse graphics networks) и RNN (recurrent neural networks). Если говорить простыми словами, то это более точное прогнозирование погоды, анализ геномов, поиск новых материалов и разработка новых лекарств. 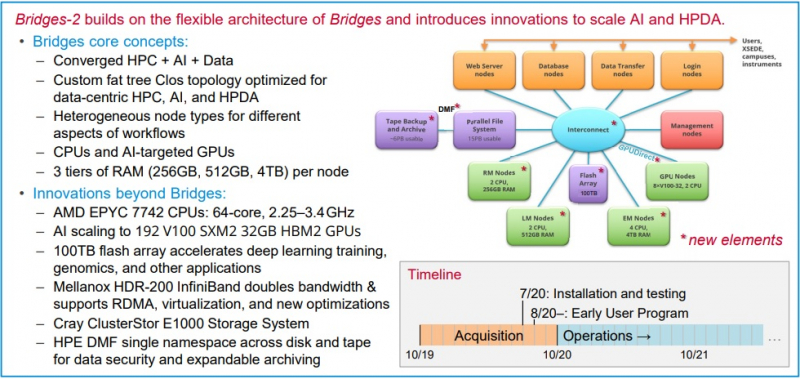 PSC, помимо Neocortex, запускает еще и новое поколение системы Bridges-2, которое будет развернуто осенью 2020 года. Таким образом, до конца этого года будут введены в эксплуатацию два мощных суперкомпьютера для ИИ. Neocortex и Bridges-2 будут поддерживать самые популярные фреймворки машинного обучения, что позволит создать гибкую и мощную экосистему для ИИ, анализа данных, моделирования и симуляции. До 90% машинного времени Neocortex будет выделяться через XSEDE (Extreme Science and Engineering Discovery Environment), финансируемую NSF организацию, которая координирует совместное использование передовых цифровых услуг, включая суперкомпьютеры и ресурсы для визуализации и анализа данных, с исследователями на национальном уровне. |
|

