Материалы по тегу: cerebras
|
01.02.2025 [15:23], Сергей Карасёв
Самый быстрый инференс DeepSeek R1 в мире: ИИ-платформа Cerebras снова поставила рекорд производительностиАмериканский стартап Cerebras Systems объявил о том, что его инференс-платформа позволила установить мировой рекорд производительности при использовании «рассуждающей» ИИ-модели DeepSeek R1 в модификации с 70 млрд параметров (DeepSeek-R1-Distill-Llama-70B). DeepSeek R1 может содержать до 671 млрд параметров. Однако, как отмечает Cerebras, развёртывание модели со способностью к рассуждению столь большого масштаба представляет значительные проблемы. Версия с 70 млрд параметров позволяет совместить возможности рассуждений более крупной модели с MoE с широко поддерживаемой архитектурой Meta✴ Llama. 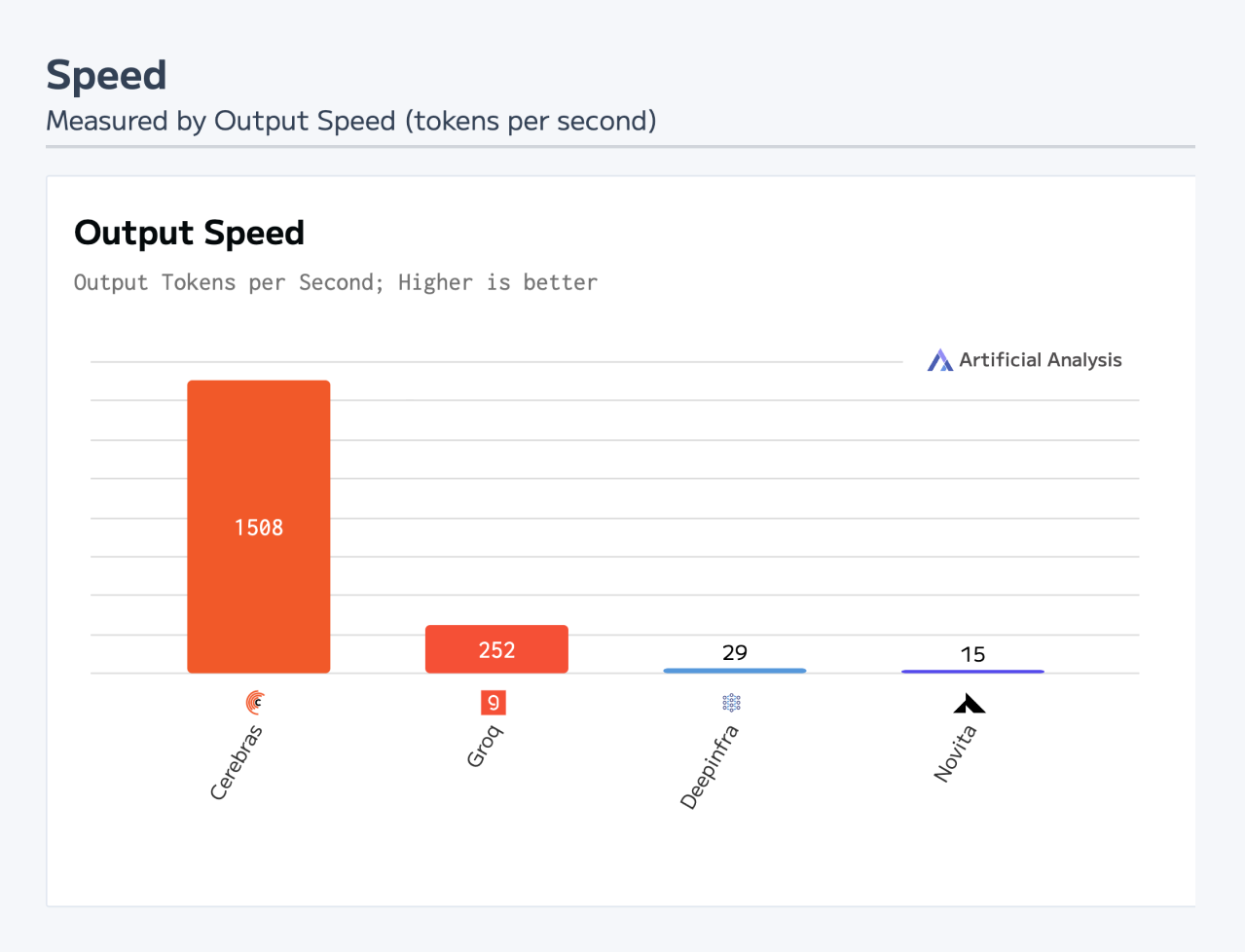
Источник изображений: Cerebras Основой платформы Cerebras являются царь-ускорители собственной разработки WSE (Wafer Scale Engine). Производительность DeepSeek R1 при работе на инфраструктуре Cerebras достигает 1508 токенов в секунду — это значительно быстрее по сравнению с конкурирующими решениями. В частности, в случае Groq показатель составляет 252 токена в секунду. Стандартный запрос на генерацию кода, который, как утверждает компания, занимает 22 секунды на конкурирующих платформах, в случае Cerebras завершается всего за 1,5 секунды, что соответствует 15-кратному повышению производительности. Cerebras подчёркивает, что DeepSeek-R1-Distill-Llama-70B превосходит как GPT-4o, так и o1-mini в сложных математических задачах и генерации кода. 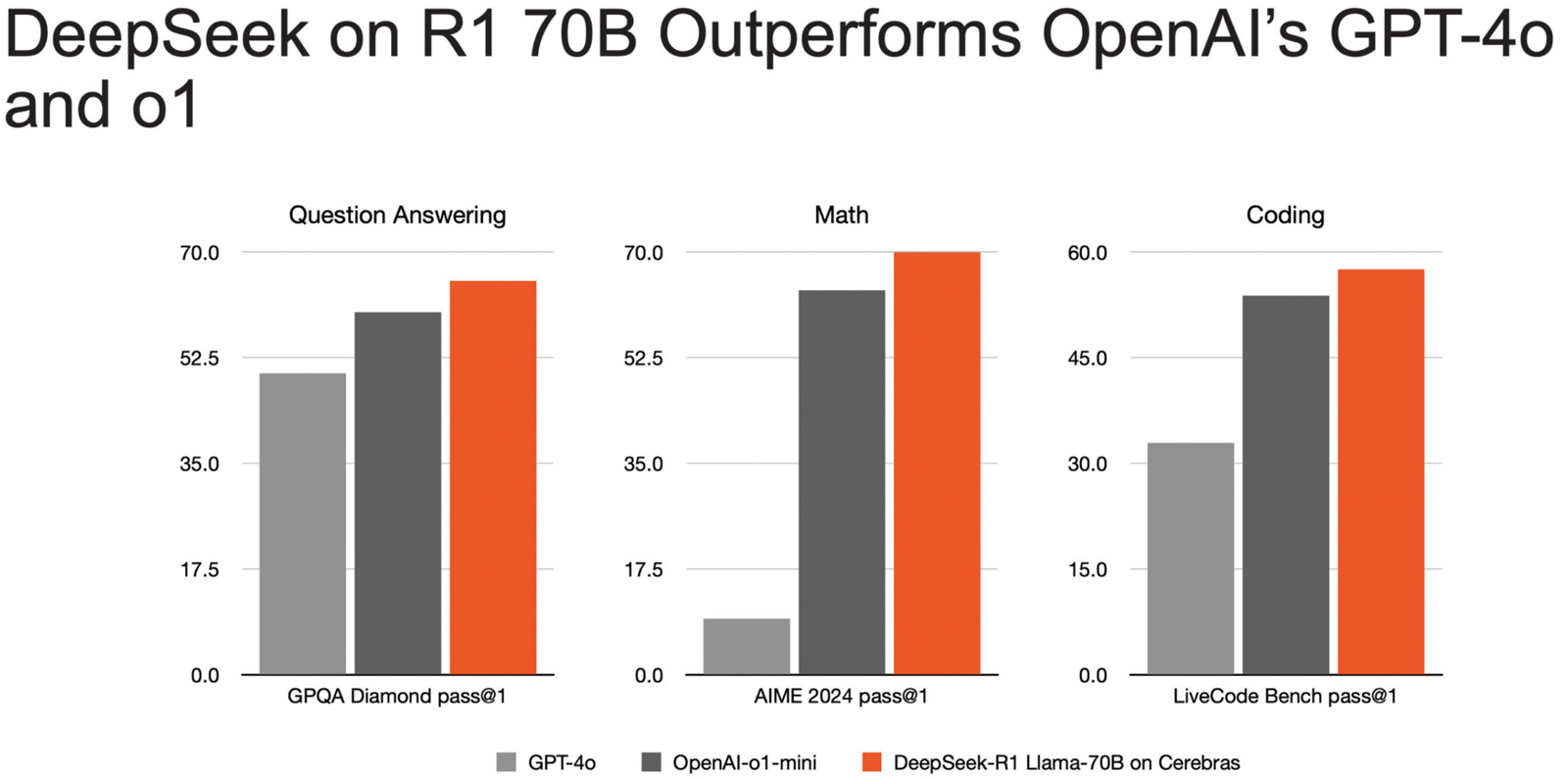 Cerebras также отмечает, что все вычисления осуществляются на базе ИИ-инфраструктуры в США, развёрнутой в собственных дата-центрах компании. При этом никакие данные не сохраняются, что гарантирует полную безопасность для клиентов. Кроме того, модель DeepSeek R1 может быть развёрнута локально в ЦОД заказчика для обеспечения максимального контроля.
12.12.2024 [23:59], Руслан Авдеев
Царь-ускоритель Cerebras WSE-3 в одиночку обучил ИИ-модель с 1 трлн параметровCerebras Systems совместно с Сандийскими национальными лабораториями (SNL) Министерства энергетики США (DOE) провели успешный эксперимент по обучению ИИ-модели с 1 трлн параметров с использованием единственной системы CS-3 с царь-ускорителем WSE-3 и 55 Тбайт внешней памяти MemoryX. Обучение моделей такого масштаба обычно требует тысяч ускорителей на базе GPU, потребляющих мегаватты энергии, участия десятков экспертов и недель на наладку аппаратного и программного обеспечения, говорит Cerebras. Однако учёным SNL удалось добиться обучения модели на единственной системе без внесения изменений как в модель, так и в инфраструктурное ПО. Более того, они смогли добиться и практически линейного масштабирования — 16 систем CS-3 показали 15,3-кратный прирост скорости обучения. 
Источник изображения: Cerebras Модель такого масштаба требует терабайты памяти, что в тысячи раз больше, чем доступно отдельному GPU. Другими словами, классические кластеры из тысяч ускорителей необходимо корректно подключить друг к другу ещё до начала обучения. Системы Cerebras для хранения весов используют внешнюю память MemoryX на базе 1U-узлов с самой обычной DDR5, благодаря чему модель на триллион параметров обучать так же легко, как и малую модель на единственном ускорителе, говорит компания. Ранее SNL и Cerebras развернули кластер Kingfisher на базе систем CS-3, который будет использоваться в качестве испытательной платформы при разработке ИИ-технологий для обеспечения национальной безопасности.
29.11.2024 [10:15], Сергей Карасёв
Система Cerebras с ускорителями WSE установила рекорд в молекулярной динамике, превзойдя суперкомпьютер FrontierАмериканский стартап Cerebras Systems, специализирующийся на создании чипов для систем машинного обучения и других ресурсоёмких задач, объявил об установлении нового мирового рекорда производительности в области молекулярной динамики. В эксперименте приняли участие Сандийские национальные лаборатории (SNL), Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе Министерства энергетики США (DOE). Вычисления выполнялись на системе, оснащённой фирменными ускорителями Cerebras Wafer Scale Engine (WSE). Говорится, что впервые в истории молекулярной динамики исследователи достигли результата более 1 млн шагов моделирования в секунду (timesteps per second, TPS). В частности, показано значение на уровне 1,1 млн TPS на платформе Cerebras CS-2, оборудованной чипами WSE-2, которые насчитывают 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Для сравнения: в случае суперкомпьютера экзафлопсного класса Frontier, который в нынешнем рейтинге TOP500 занимает второе место, результат составляет 1470 TPS. Таким образом, система Cerebras обеспечивает 748-кратный выигрыш в быстродействии на задачах молекулярной динамики. При этом энергопотребление комплекса Cerebras составляет 27 кВт против 21 МВт у Frontier. 
Источник изображения: Cerebras Кроме того, комплекс Cerebras превзошел Anton 3 — самый мощный в мире специализированный суперкомпьютер для молекулярной динамики. Anton 3 использует 512 кастомных ASIC, а его энергопотребление находится на уровне 400 кВт. Показатель быстродействия Anton 3 достигает 980 тыс. TPS. То есть, система Cerebras показывает выигрыш примерно в 20 %. Предполагается, что ускорители Cerebras предоставят качественно новые возможности для исследований в различных областях, включая разработку материалов следующего поколения, перспективных лекарственных препаратов и решений в сфере возобновляемой энергетики. Нужно отметить, что ранее Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на чипах Cerebras WSE-3. А сама компания Cerebras развернула «самую мощную в мире» ИИ-платформу для инференса.
18.11.2024 [10:59], Сергей Карасёв
OpenAI раздумывала, не купить ли разработчика ИИ-ускорителей Cerebras при участии TeslaКомпания OpenAI, по информации ресурса TechCrunch, изучала возможность приобретения американского стартапа Cerebras Systems, специализирующегося на разработке ИИ-ускорителей. Такие сведения вскрылись в рамках судебного процесса по иску Илона Маска (Elon Musk) против OpenAI. Маск является одним из основателей OpenAI — он покинул эту компанию в 2018 году. В начале августа нынешнего года Маск подал в суд на OpenAI и её генерального директора Сэма Альтмана (Sam Altman), обвинив их в нарушении прав и интересов, а также во введении в заблуждение. 
Источник изображения: Cerebras Как теперь сообщается, в электронном письме, адресованном Альтману и Маску, Илья Суцкевер (Ilya Sutskever), один из соучредителей OpenAI и бывший главный научный сотрудник компании, обсуждал идею покупки Cerebras через Tesla. В другом письме от июля 2017 года Суцкевер затрагивает ряд вопросов, связанных с Cerebras, таких как переговоры об условиях слияния и проверка благонадёжности финансового состояния Cerebras. «Если мы решим купить Cerebras, я твердо уверен, что это будет сделано через Tesla. Но зачем делать это таким образом, если мы могли бы провести сделку изнутри OpenAI? В частности, вызывает беспокойство то, что Tesla имеет обязательство перед акционерами максимизировать их доход, что не соответствует миссии OpenAI», — написал Суцкевер. Cerebras создаёт ИИ-суперускорители размером с целую кремниевую пластину. Флагманским продуктом стартапа является решение Wafer Scale Engine третьего поколения (WSE-3). Это гигантское изделие содержит 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт памяти SRAM. Предполагалось, что слияние с OpenAI будет выгодно обеим сторонам. В частности, Cerebras избежала бы сложного пути, связанного с IPO, тогда как OpenAI смогла бы получить в своё распоряжение мощные аппаратные ускорители для ресурсоёмких ИИ-задач. Однако сделка в итоге провалилась, хотя причины сворачивания переговоров не раскрываются.
16.11.2024 [20:49], Сергей Карасёв
Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на огромных чипах Cerebras WSE-3Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) в рамках партнёрства с компанией Cerebras Systems объявили о запуске кластера Kingfisher, который будет использоваться в качестве испытательной платформы при разработке ИИ-технологий для обеспечения национальной безопасности. Основой Kingfisher служат узлы Cerebras CS-3, которые выполнены на фирменных ускорителях Wafer Scale Engine третьего поколения (WSE-3). Эти гигантские изделия содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт памяти SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, внутреннего интерконнекта — 214 Пбит/с. На сегодняшний день платформа Kingfisher объединяет четыре узла Cerebras CS-3, а конечная конфигурация предусматривает использование восьми таких блоков. Узлы Cerebras CS-3 мощностью 23 кВт каждый содержат СЖО, подсистемы питания, сетевой интерконнект Ethernet и другие компоненты. 
Источник изображения: SNL Развёртывание кластера Cerebras CS-3 является частью программы Advanced Simulation and Computing (ASC), которая реализуется Национальным управлением по ядерной безопасности США (NNSA). Речь идёт, в частности, об инициативе ASC Artificial Intelligence for Nuclear Deterrence (AI4ND) — искусственный интеллект для ядерного сдерживания. Предполагается, что Kingfisher позволит разрабатывать крупномасштабные и надёжные модели ИИ с использованием защищённых внутренних ресурсов Tri-lab — группы, в которую входят Сандийские национальные лаборатории, Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе (DOE).
28.10.2024 [11:48], Сергей Карасёв
Cerebras втрое повысила производительность своей инференс-платформыАмериканский стартап Cerebras Systems, специализирующийся на разработке ИИ-ускорителей, объявил о самом масштабном обновлении ИИ-платформы Cerebras Inference с момента её запуска. Производительность системы поднялась примерно в три раза. Первый релиз Cerebras Inference состоялся в августе 2024 года. Основой облачной платформы являются ускорители собственной разработки WSE-3. На момент запуска быстродействие составляло до 1800 токенов в секунду на пользователя для ИИ-модели Llama3.1 8B и до 450 токенов в секунду для Llama3.1 70B (FP16). Разработчик заявлял, что Cerebras Inference — это «самая мощная в мире» ИИ-платформа для инференса. 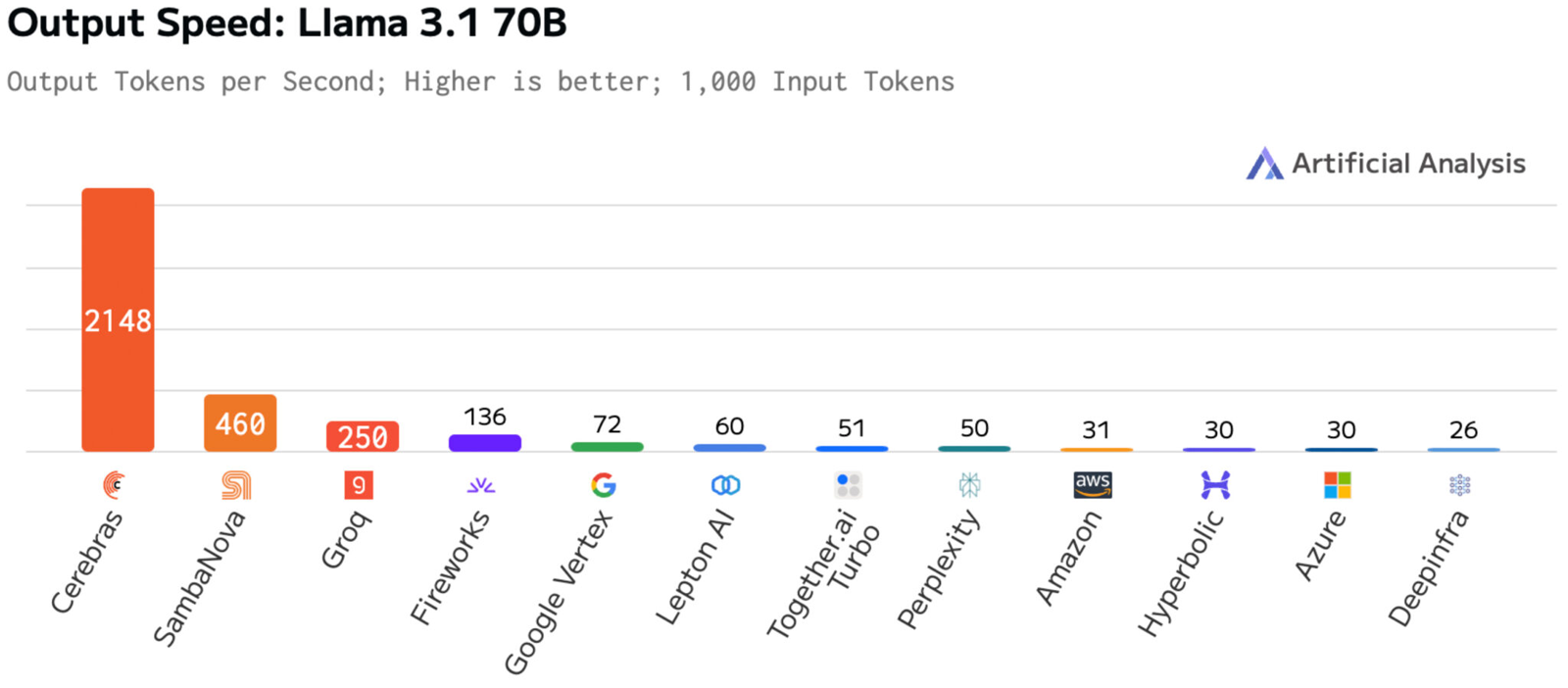
Источник изображений: Cerebras Systems Однако в сентябре нынешнего года у Cerebras Inference появился серьёзный конкурент. Компания SambaNova Systems запустила облачный сервис SambaNova Cloud, также назвав его «самой быстрой в мире платформой для ИИ-инференса». Система на основе чипов собственной разработки SN40L демонстрирует быстродействие до 461 токена в секунду при использовании Llama 3.1 70B. В ответ Cerebras Systems усовершенствовала своё решение путём «многочисленных улучшений программного обеспечения, оборудования и алгоритмов». 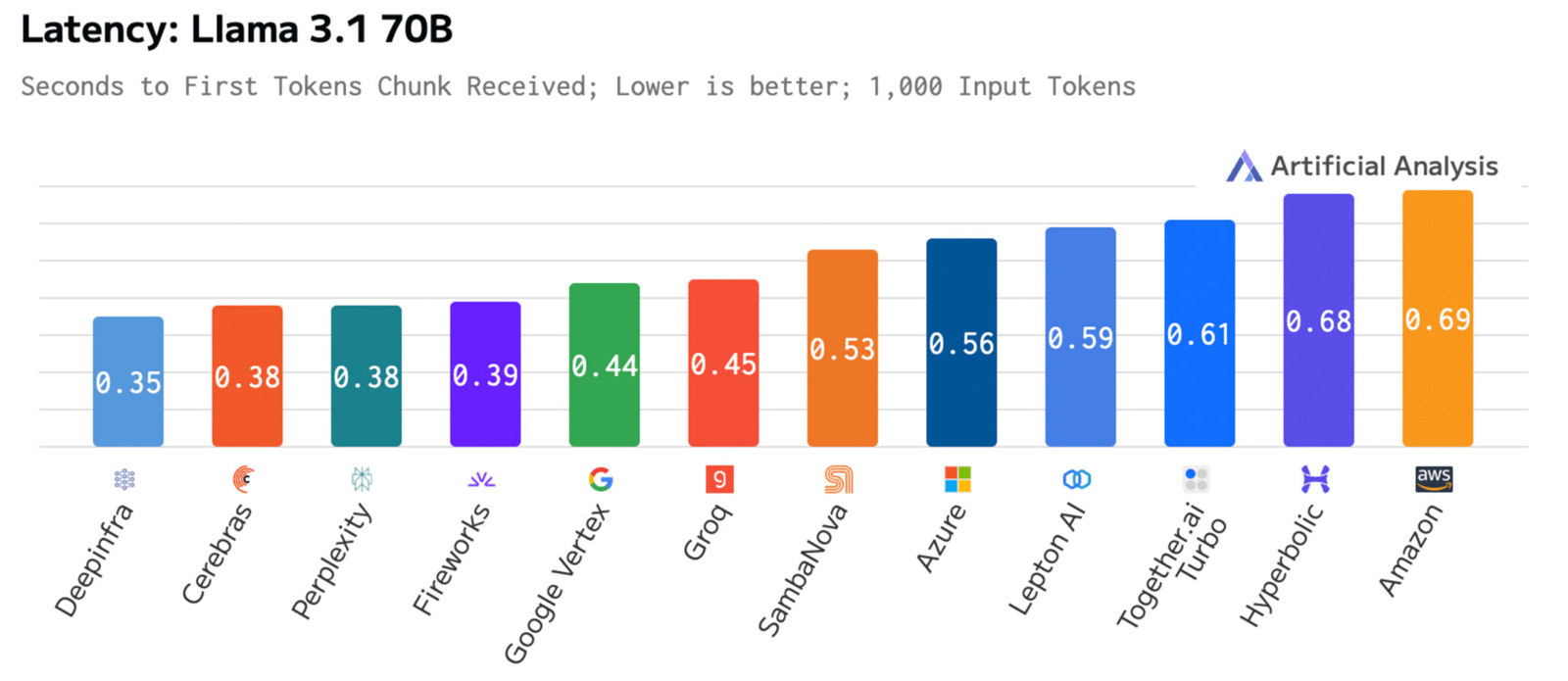 Утверждается, что обновлённая платформа Cerebras Inference при обслуживании Llama3.1 70B обеспечивает быстродействие 2148 токенов в секунду. Для сравнения: у AWS — лидера мирового облачного рынка — этот показатель равен 31 токену в секунду. А у Groq значение находится на уровне 250 токенов в секунду. Данные получены по результатам тестов Artificial Analysis. 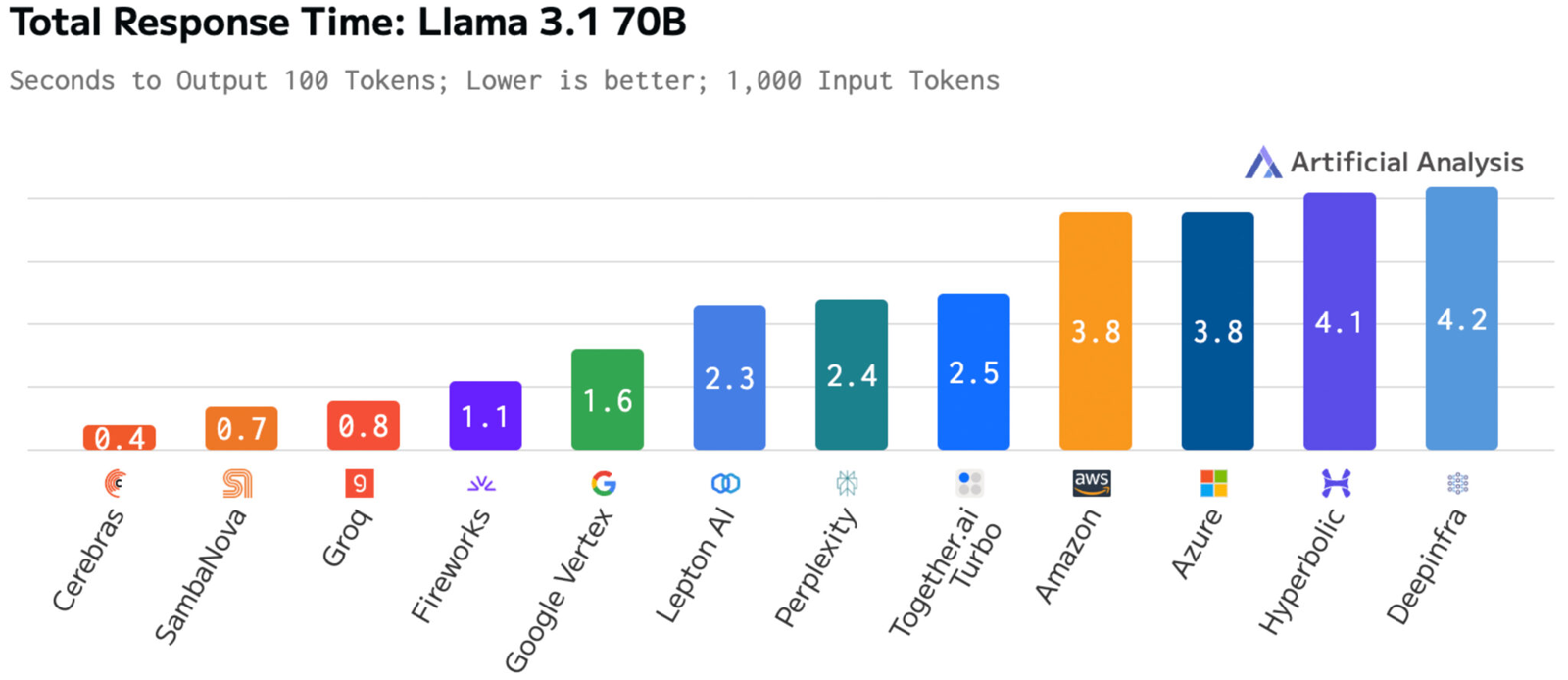 Время до получения первого токена имеет решающее значение для приложений реального времени. Cerebras находится на втором месте с показателем 0,38 с, уступая только Deep Infra (0,35 с). Вместе с тем Cerebras лидирует по общему времени отклика для 100 токенов на выходе с показателем 0,4 с против 0,7 с у SambaNova, которая находится на втором месте. В целом, как отмечается, платформа Cerebras Inference при работе с Llama3.1 70B опережает сервисы конкурентов на основе GPU, обрабатывающие модель Llama3.1 3B, которая в 23 раза меньше. 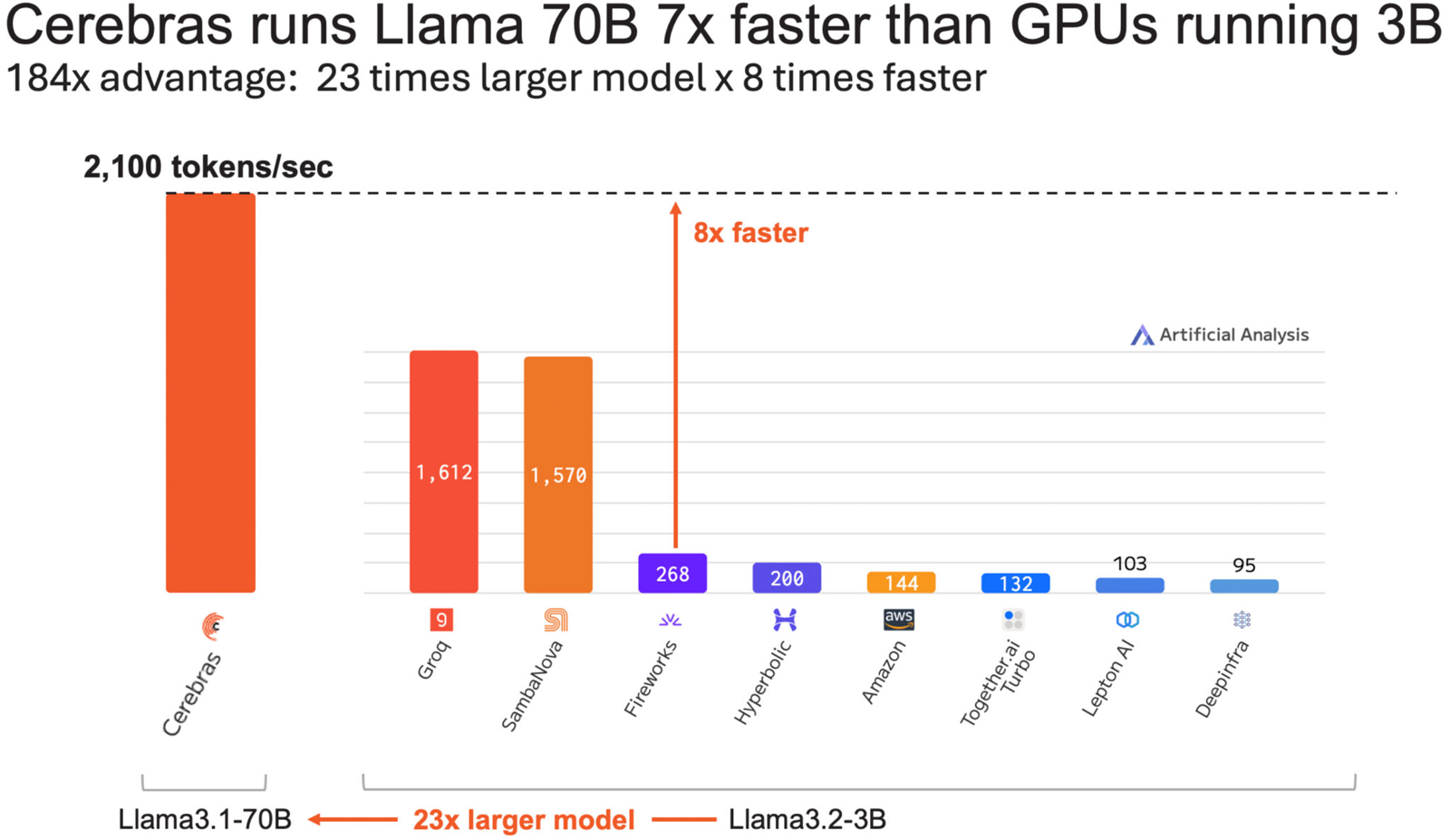
09.10.2024 [23:09], Руслан Авдеев
Cerebras отложит IPO: США опасаются, что Китай получит доступ к ИИ-суперчипам при посредничестве ОАЭПроизводитель ИИ-суперчипов Cerebras Systems, вероятнее всего, вынужден будет отложить IPO из-за задержки, связанной с проверкой иностранных инвестиций в компанию. По данным Reuters, миноритарным инвестором выступил конгломерат G42 (Core42) из ОАЭ, что и привлекло внимание регуляторов. Как сообщают источники издания, Cerebras, являющаяся молодым и перспективными конкурентом NVIDIA, наверное, отменит презентацию, запланированную на начало следующей недели и предваряющую IPO. Ведущими андеррайтерами запланированного IPO в Cerebras выбрали Citigroup и Barclays. Инвестиции G42 в Cerebras рассматривает Комитет по иностранным инвестициям в США (Committee on Foreign Investment in the United States, CFIUS). Он оценивает наличие угроз национальной безопасности в иностранных капиталовложениях в американский бизнес. В Cerebras ожидают, что CFIUS даст инвестициям G42 зелёный свет ещё до конца 2024 года. Производитель ускорителей будет стремиться выйти на IPO сразу после получения необходимых разрешений от регулятора, но планы компании могут измениться. В Министерстве финансов США комментировать IPO отказались, но сообщили, что регулятор примет все меры для защиты национальной безопасности США в пределах своей компетенции. Проблема в том, что G42, являющаяся инвестором и крупнейшим клиентом Cerebras, уже привлекала внимание сторонников суровых мер в отношении Китая. Считается, что компании с Ближнего Востока могут использоваться КНР для обхода американских санкций, ограничивающих экспорт полупроводников в Поднебесную. Кроме того, G42 ранее уличили в ведении дел с Пекином. 
Источник изображения: Cerebras По имеющимся данным на закупки G42 приходится $65,1 млн или 83 % от всей выручки Cerebras за 2023 календарный год. В I полугодии 2024 года компания зарегистрировала $136,4 млн, тогда как в прошлом году за аналогичный период выручка составила $8,7 млн. Иными словами, G42 является ключевым покупателем продуктов компании. Кроме того, к апрелю G42 обязалась выкупить акции Cerbras на $335 млн, доведя долю до более чем 5 %. Сначала Cerebras и G42 подали в CFIUS заявку о продаже акций, но позже скорректировали её объявив, что продаваемые акции не голосующие, поэтому их проверка регулятором не нужна. В сентябре было подано заявление на отзыв уведомления. Сегодня калифорнийская Cerebras, оценивавшаяся приблизительно в $4 млрд в 2021 году, строит серию ИИ-суперкомпьютеров в интересах G42, в том числе в США. Разработанная Cerebras технология уже использовалась для обучения большой языковой модели (LLM) для арабского языка. Разработанные Cerebras ускорители конкурируют с решениями NVIDIA. По мнению экспертов, ИИ-чипы огромного размера, предлагаемые стартапом, имеются ряд преимуществ в сравнении с ускорителями NVIDIA и другими решениями. Примечательно, что инвестиции Microsoft в G42 были одобрены после того, как последняя, по слухам, заключила тайное соглашение с администрацией США, которое как раз оговаривало взаимодействие с Китаем.
01.10.2024 [15:39], Руслан Авдеев
Конкурент NVIDIA — Cerebras Systems выходит на IPO на биржу NasdaqСтартап Cerebras Systems Inc., разрабатывающий ИИ-суперускорители размером с целую кремниевую пластину, подал заявку для выхода на публичные торги. По данным Silicon Angle, шаг вполне ожидаемый — компания подала проект документации в Комиссию по ценным бумагам и биржам США (SEC) ещё летом текущего года. На прошлой неделе сообщалось, что компания надеется привлечь в ходе IPO от $750 млн до $1 млрд, а оценочная стоимость компании составит до $8 млрд. На Nasdaq компания намерена выйти под тикером CBRS. Флагманским продуктом компании является суперчип WSE-3 с 4 трлн транзисторов, формирующих 900 тыс. ядер и 44 Гбайт SRAM. Компания утверждает, что WSE-3 может обучать ИИ-модели значительно быстрее, чем традиционные чипы. При этом энергоэффективность WSE-3 значительно лучше, поскольку один большой чип просто эффективнее во всех отношениях множества более компактных. Компания поставляет WSE-3 в составе модуля CS-3 размером с небольшой холодильник, также вмещающего и охлаждающее оборудование, модули питания и прочие компоненты. Клиенты могут использовать до 2048 CS-3 в одном ИИ-кластере. 
Источник изображения: Cerebras Cerebras пока не приносит прибыли, но рассчитывает на быстрый рост выручки. С 2022 по 2023 годы продажи компании выросли более чем втрое с $24,62 млн до $78,7 млн. Чистый убыток за те же периоды составил $177,72 млн и $127,16 млн соответственно. В 2024 году за первые шесть месяцев выручка составит $136,4 млн при убытке $66,6 млн. Однако отмечается очень большая концентрация продаж — 87 % продукции в I полугодии предназначалось компании G42 (ныне Core42) из ОАЭ. Более того, этот же заказчик до середины следующего года закупит ускорителей на почти $1,5 млрд. При этом у G42 есть 5 % акций Cerebras, столько же имеется только у основателя компании Эндрю Фельдмана (Andrew Feldman). Среди других известных инвесторов есть глава OpenAI Сэм Альтман (Sam Altman) также является акционером Cerebras, как и сооснователь Sun Microsystems Энди Бехтольшайм (Andy Bechtolsheim). Впрочем, Cerebras уже готовится сотрудничать с Aramco и другими компаниями. В документах, посвящённых выходу на IPO, Cerebras заявила, что намерена сохранить рост выручки, привлекая больше клиентов и расширяя технологическое портфолио, создавая новые продукты и форм-факторы. Ещё одним потенциальным источникам роста стал недавний запуск облачного сервиса для инференса. При этом Reuters сообщает, что ранее в этом году некоторые инвесторы ушли с рынка акций ИИ-компаний из-за опасений того, что тот слишком раздут. Попытка Cerebras выйти на IPO покажет, сохранился ли в должной мере интерес к отрасли. Компанию поддерживает ряд крупных инвесторов, включая Abu Dhabi Growth Fund и Coatue Management. Андеррайтерами предложения, помимо прочих, являются Citigroup, Barclays, UBS Investment, Wells Fargo Securities и Mizuho.
16.09.2024 [10:51], Руслан Авдеев
Aramco Digital объявила о партнёрстве с Cerebras, Groq и Qualcomm для развития ИИ и 5G IoT в Саудовской АравииПодразделение нефтегазовой саудовской Aramco — Aramco Digital анонсировало серию соглашений с компаниями, действующими в сфере ИИ и беспроводных технологий. По информации Datacenter Dynamics, компания подписала меморандумы о взаимопонимании с Cerebras Systems, развитии передовой ИИ-модели Norous совместно с Groq и сотрудничестве в сфере 5G-технологий совместно с Qualcomm. Aramco принадлежит государству и является крупнейшим в мире добытчиком нефти и газа, располагая вторыми по величине разведанными запасами сырой нефти в мире. Её подразделение Aramco Digital — попытка диверсифицировать бизнес, уделив внимание освоению информационных технологий. Сотрудничество с Cerebras Systems позволит обеспечить высокопроизводительными ИИ-решениями промышленность, университеты и коммерческие предприятия Саудовской Аравии. В рамках соглашения компания будет применять вычислительные системы Cerebras CS-3 на сусперускорителях WSE-3 в облачном бизнесе, чтобы ускорить создание, обучение и внедрение больших языковых моделей и ИИ-приложений. Тем временем партнёрство с Groq поможет Aramco Digital вывести на рынок управляемую голосом ИИ-модель Norous. 
Источник изображения: M Zaedm/unsplash.com В будущем планируется создать систему управления цепочками поставок, способную генерировать миллиарды токенов в секунду. Как сообщают арабские СМИ, пока Aramco Digital планирует обеспечивать до 25 млн токенов к концу I квартала 2025 года, а в этом году будет обеспечено 20 % от заявленных показателей. В Groq заявляют, что компания намерена стать экспортёром вычислительных мощностей для приблизительно 4 млрд человек, этого будет достаточно для «близлежащих континентов» и позволит обеспечивать части Европы, Африки и, возможно, даже часть Индии. Также совместно с Qualcomm компания Aramco Digital задействует 5G-чипы для частотного диапазона 450 МГц. IoT-решения Qualcomm QCS8550/QCS6490 будут поддерживать умные устройства с возможностью периферийных вычислений. Решение включает ряд компонентов, от модема до собственно передатчика, усилителя и систем фильтрации сигнала, а также другие элементы. Эксперты утверждают, что этот диапазон можно эффективно использовать как в помещениях, так и вне их, поэтому новое решение станет одним из важнейших элементов цифровой трансформации Саудовской Аравии. Партнёры также работают над «инкубатором стартапов» совместно с саудовским Управлением по вопросам исследований, развития и инноваций (RDIA). Программа Design in Saudi Arabia (DISA) будет поддерживать стартапы, занимающиеся разработкой и внедрением ИИ, беспроводных технологий и Интернета вещей, обеспечив им техническую помощь, бизнес-коучинг и прочую помощь. Резиденты инкубатора также получат доступ к технологическим платформам Qualcomm и Aramco Saudi Accelerated Innovation Lab. Предполагается, что это простимулирует новую волну технологических инноваций в Саудовской Аравии и коммерциализацию разработок стартапов.
13.09.2024 [14:05], Руслан Авдеев
Cerebras и Aramco займутся развитием ИИ-инноваций в Саудовской АравииАмериканская компания Cerebras Systems объявила о подписании меморандума о взаимопонимании с саудовской нефтяной компанией Aramco. В рамках соглашения компании предоставят промышленности, университетам и коммерческим организациям Саудовской Аравии современные ИИ-решения. По данным HPC Wire, Aramco намерена создавать, обучать и внедрять большие языковые модели (LLM) мирового класса с использованием систем Cerebras CS-3. Ранее Aramco заключила похожее соглашение с другим американским производителем ИИ-ускорителей — Groq. Новая высокопроизводительная инфраструктура Aramco будет концентрировать усилия на обеспечении местных коммерческих, научных и иных структур доступом к ИИ-системам CS-3. Предполагается, что организации будут использовать передовые аппаратные решения Cerebras для разработки современных LLM, масштабируя и настраивая их для получения оптимальной для того или иного сектора производительности. 
Источник изображения: Aramco Digital Как объявили в Cerebras, вместе компании планируют расширить возможности ИИ-систем, создав благоприятные условия для развития креативности, раскрытия ценности технологий и продвижения концепции экоустойчивости. В свою очередь, представитель Aramco заявил, что сотрудничество ускорит создание цифровой инновационной экономики в Саудовской Аравии, драйвером которой станет ИИ. Этого можно будет добиться, интегрируя передовые ИИ-решения и учитывая региональные особенности. Aramco рассчитывает оснастить свой облачный бизнес новыми системами CS-3. В основе систем Cerebras CS-3 лежат суперускорители WSE-3 размером с целую кремниевую пластину. Уже сегодня продукцией Cerebras пользуются крупные корпорации, исследовательские институты и даже государственные органы для разработки собственных моделей. Также они применяются для обучения open source LLM. Решения Cerebras доступны как «во плоти», так и в облаке. В конце августа 2024 года Cerebras Systems запустила «самую мощную в мире» ИИ-платформу для инференса. В целом Cerebras активно осваивает рынок ЦОД в регионе. Так, холдинг G42 (Core42) из ОАЭ финансово поддержал создание целой серии ИИ-суперкомпьютеров Condor Galaxy, одних из крупнейших в мире. Сейчас Cerebras готовится к IPO и намерена составить конкуренцию NVIDIA. При этом США, как выяснилось, разрешили NVIDIA поставлять современные ускорители G42. |
|

