Материалы по тегу: сервер
|
01.10.2020 [23:24], Юрий Поздеев
Сделано в США: HPE возвращается к «белой сборке» серверовHewlett Packard Enterprise (HPE) анонсировала новую систему безопасности цепочки поставок для клиентов из государственного сектора США, которые по тем или иным причинам предпочитают покупать продукцию, произведенную на территории США. Безопасность всей цепочки поставок серверного оборудования достигается за счет строгого соблюдения отраслевых стандартов США, что снижает риски для учреждений государственного сектора. Новую инициативу назвали HPE Trusted Supply Chain. Несколько лет назад HPE представила Silicon Root of Trust — функцию, которая обеспечивает безопасность непосредственно в iLO и создает неизменяемую цифровую подпись. Если прошивка или комплект драйверов для сервера не соответствует этой цифровой подписи, сервер не загрузится и изменения конфигурации не будут приняты. HPE не ограничивается только серверами, но и предлагает подобную систему для сетевой безопасности в решениях от Aruba.  Однако, есть некоторые проблемы с автономностью цепочки поставок: пандемия Covid-19 повлекла массовый сбой в производстве многих электронных компонентов для серверов. Еще одной проблемой стали участившиеся взломы микрочипов для кражи информации с различных устройств. Обе проблемы HPE решает, создавая готовый продукт в той стране, где он продается. В США наблюдается повышенный спрос на безопасные продукты собственного производства, особенно для клиентов из федерального, государственного и финансового секторов, а также организаций здравоохранения. У HPE есть собственная производственная площадка в штате Висконсин, где работает персонал с необходимым допуском. Поскольку весь процесс производства находится под контролем, вероятность нарушения безопасности очень мала. HPE также готова доставить и установить новые серверы в ЦОД заказчика.  Первым продуктом, прошедшим весь этот процесс является сервер HPE Proliant DL380T. Не все компоненты сервера произведены непосредственно в США, но те, что имеют локальное происхождение, уже позволяют официально заявить об американском происхождении оборудования (Country of Origin USA), а не просто об американском производстве (Made in USA). HPE выходит за рамки процесса производства, распространяя повышенную безопасность на весь жизненный цикл продукта:
HPE не останавливается на достигнутом и планирует в следующем году представить подобную программу для Европы. Похоже, что «белая сборка» возвращается. Впрочем, процесс этот начался не сегодня — ещё в прошлом году крупные контрактные производители серверов, которые обслуживали крупных американских и европейских клиентов начали переносить производственные линии из материкового Китая на Тайвань и в Мексику. HPE лишь довела дело до логического завершения.
22.09.2020 [20:32], Игорь Осколков
От периферии до облаков: Arm представила серверные платформы Neoverse V1 Zeus и N2 Perseus с поддержкой SVE, PCIe 5.0, DDR5 и HBMКомпания Arm объявила о расширении своего портфолио серверных решений семейства Neoverse, представив сразу два варианта платформы. Новая серия V и её первенец V1 под кодовым именем Zeus вместе с N2 (Perseus) получат поддержку SIMD-расширений SVE и формата bfloat16, а также интерфейсы PCIe 5.0, DDR5 и HBM. Однако отличия между ними весьма существенны. В Neoverse V1 в отличие от N2 Arm отказывается от традиционной оптимизации сразу по трём направлениям — энергопотребление, производительность и площадь кристалла — и делает упор на мощность. Вероятно, основой для них станут вариации Cortex-X1. Эти чипы будут потреблять больше энергии и будут физически больше, но взамен предложат значительное увеличение размеров буферов, кешей, окон и очередей. Показатель IPC для одного потока будет увеличен на впечатляющие 50% в сравнении с Neoverse N1. 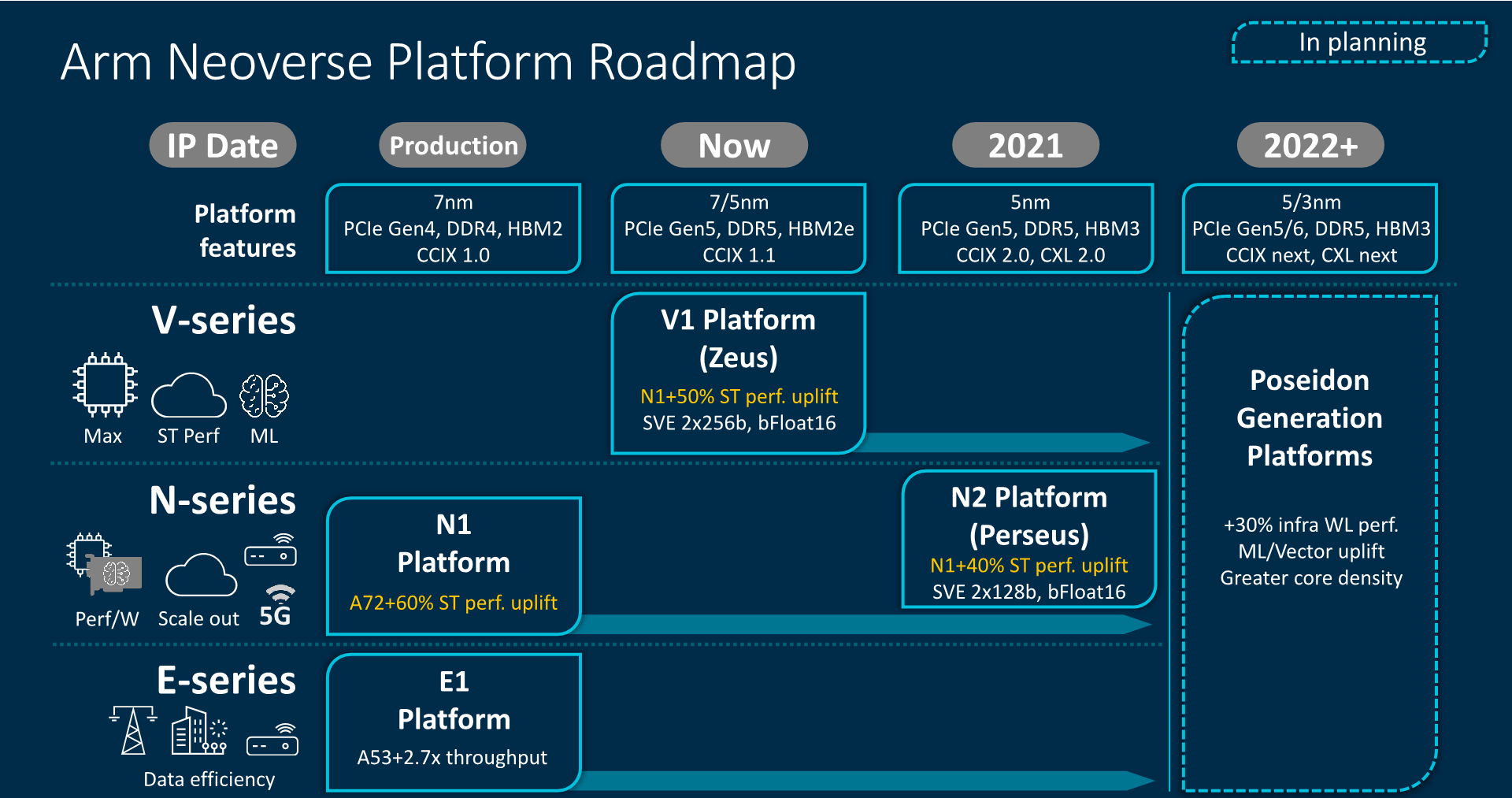 А новые техпроцессы 5 и 7 нм позволят повысить частоты будущих процессоров. Так что они потенциально смогут соревноваться с грядущими платформами x86-64 не только по показателю производительность на Ватт, но и в чистой производительности. Поспособствует этому и долгожданное официальное появление векторных инструкций Scalable Vector Extension (SVE) в составе самого ядра. Их отличительной чертой (от SSE/AVX) является нефиксированная ширина — производители конкретных SoC могут реализовать поддержку от 128 до 2048 бит с шагом в 128 бит. При этом SVE-код будет работать на любом из них, просто скорость обработки данных будет разной. 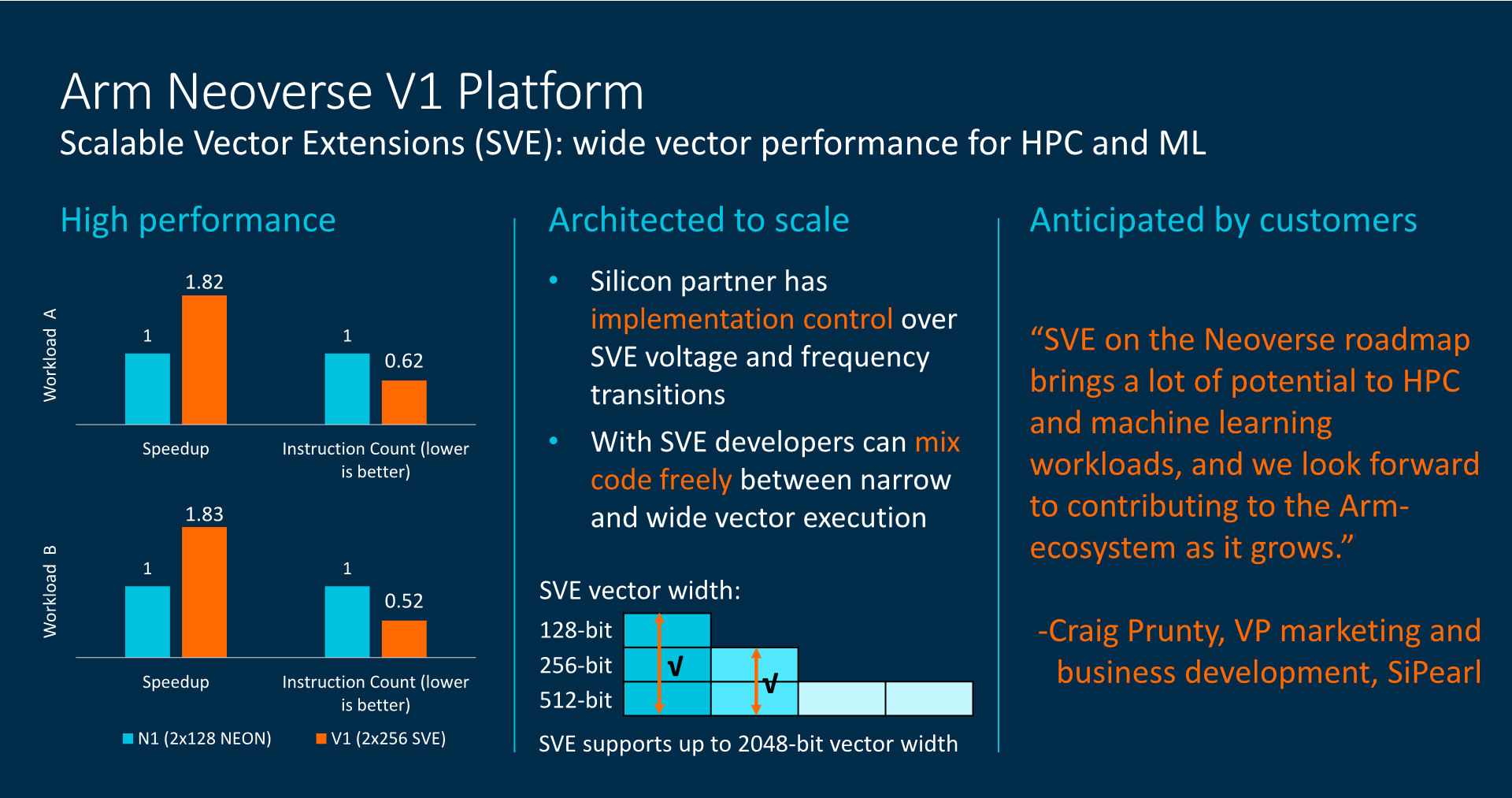 Конкретно в V1 Arm заложила два блока SVE-256. Это явно хуже пары SVE-512 в Fujitsu A64FX, единственном «кремнии», который уже поддерживает новые инструкции, но всё равно в два раза лучше, чем у N1 с двумя «старыми» 128-бит NEON. Так что мы вполне можем увидеть в будущем ориентированные на высокопроизводительные вычисления решения от других компаний. Этому поспособствует и поддержка памяти HBM2e. Опять-таки, в A64FX она была нужна именно для того, чтобы SVE-блоки не «голодали». Кроме того, обновлённые спецификации SVE включают и поддержку формата bfloat16, актуального для нейронных сетей. 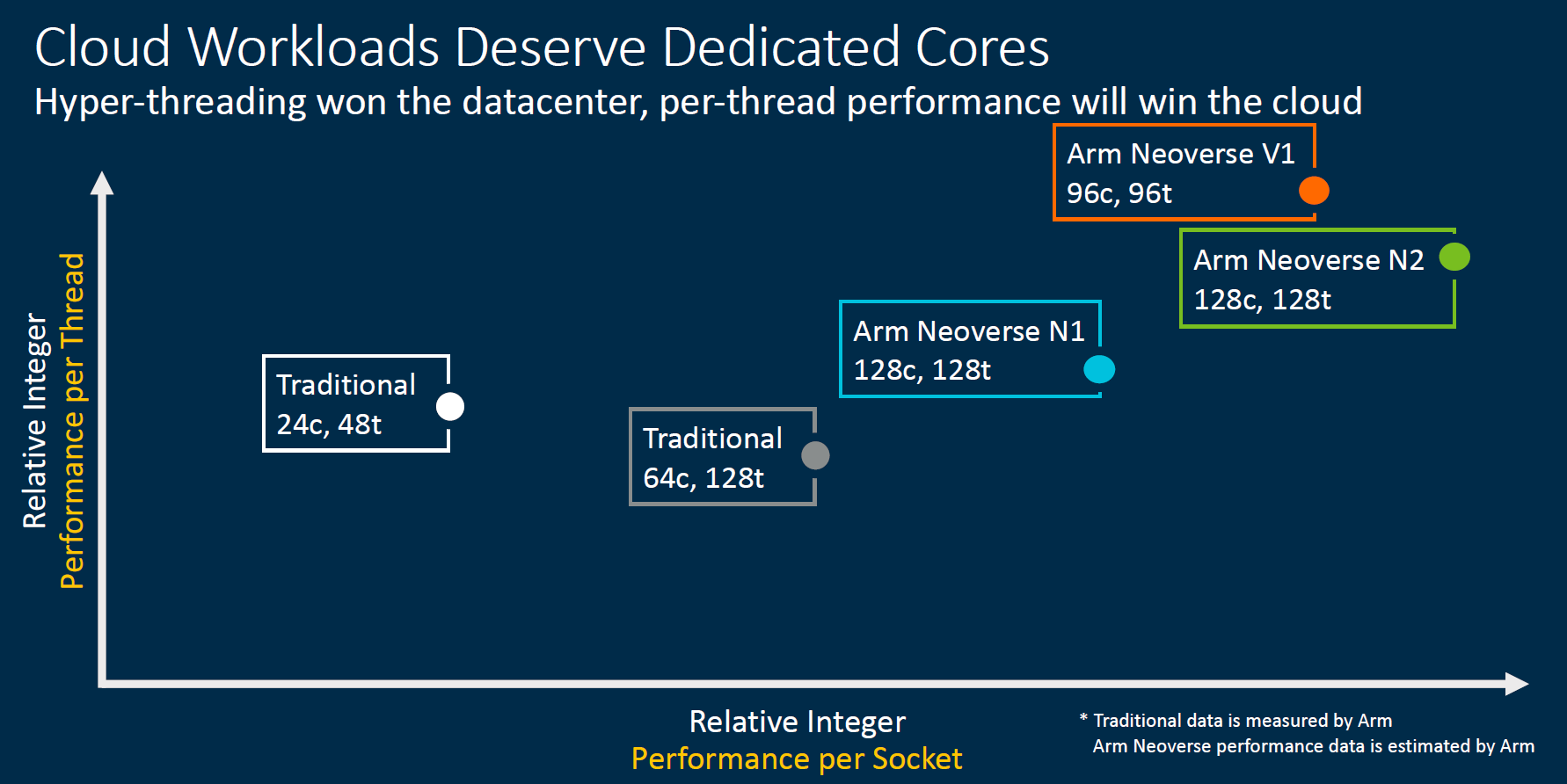 Arm Neoverse V1 формально доступен уже сейчас. Первыми процессорами на базе этой архитектуры должны стать 72-ядерные SiPearl Rhea, которые вместе с другими чипами, уже на базе открытой архитектуры RISC-V, лягут в основу будущих европейских суперкомпьютеров. Таким образом Евросоюз надеется получить большую независимость от технологий США. Впрочем, объявленная сделка между NVIDIA и Arm может расстроить эти планы. Следующим крупным лицензиатом V1 может стать Ampere, которая готовится выпустить в 2022 году процессоры Siryn. 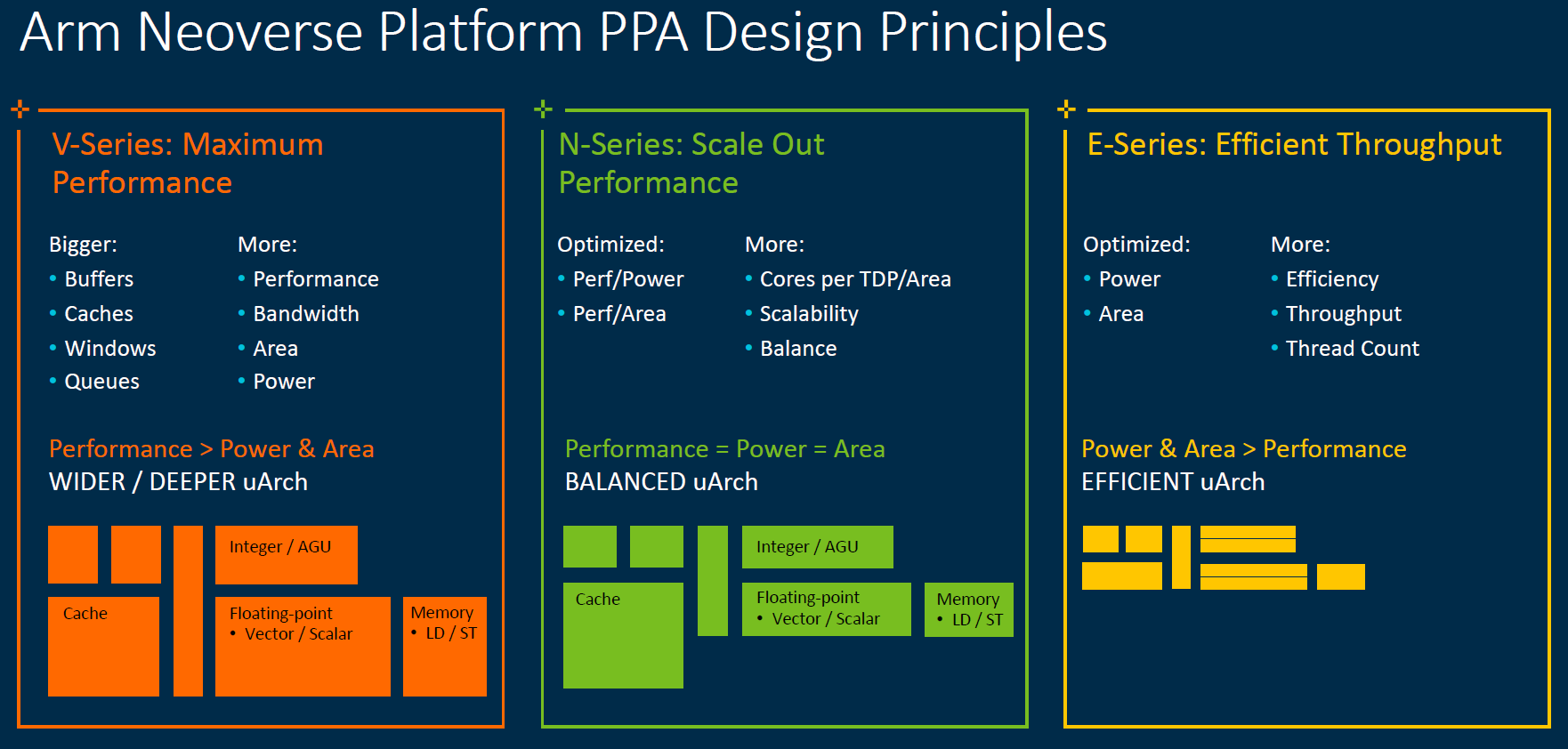 Что касается архитектуры Neoverse N2, то она появятся уже в следующем году, а лицензирование начнётся в конце этого. Она также получит поддержку SVE и bfloat16, но в виде двух 128-бит блоков. Будет внедрена поддержка HBM3, CXL 2.0 и CCIX 2.0. В N2 Arm придерживается своего традиционного подхода, так что прирост IPC в однопотоке составит «всего лишь» до 40% в сравнении с N1, но при этом сохранятся те же уровень энергопотребления и площадь ядра. Можно предположить, что основной для неё станет Cortex-A78. 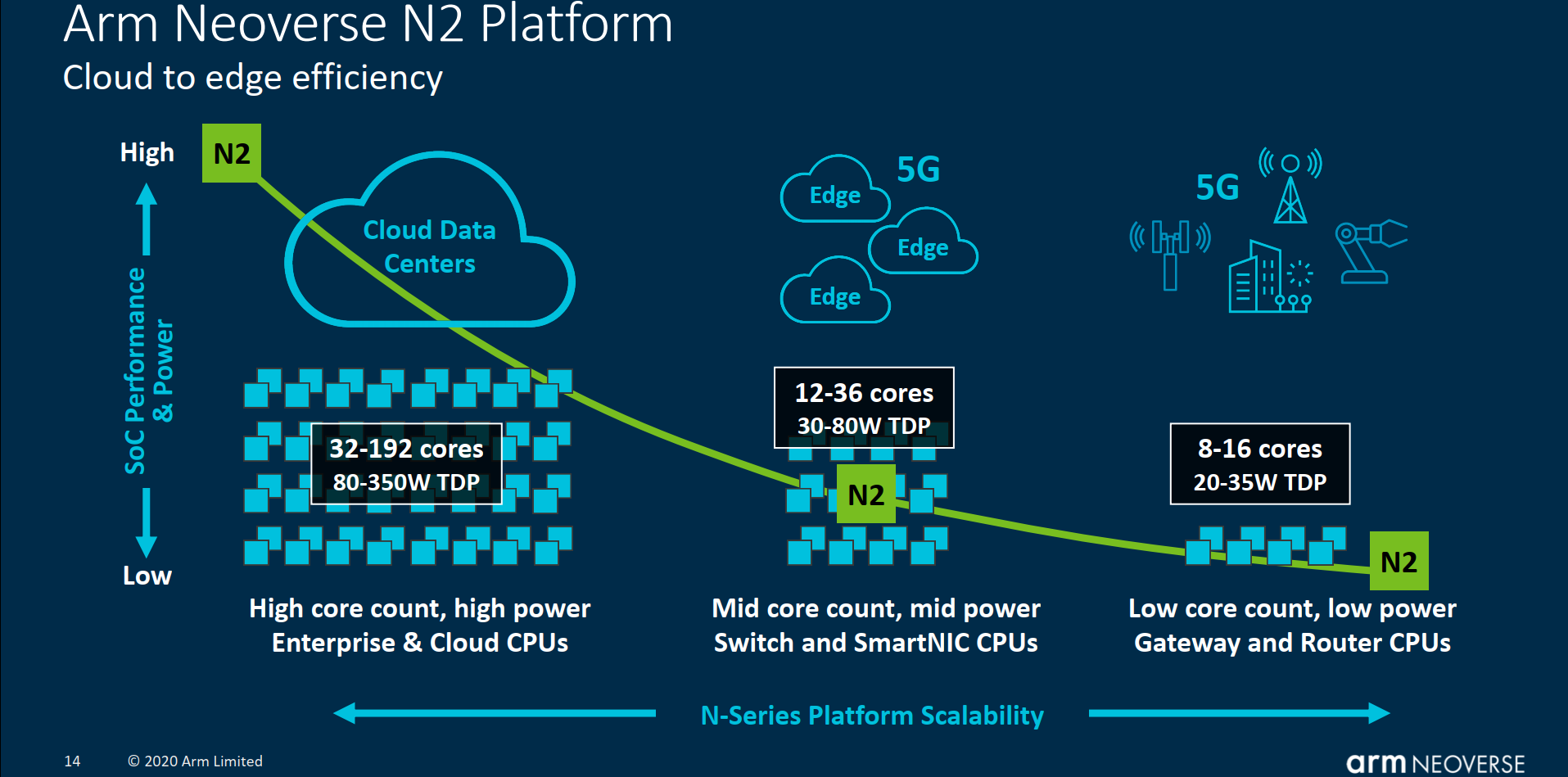 Именно N2 должна стать наиболее массовой платформой благодаря масштабируемости. Arm видит различные варианты дизайнов будущих SoC. От 8 до 16 ядер с TDP 20-35 Вт пойдут в экономичные решения на самой границе сети, варианты на 12-36 ядер с TDP от 30 до 80 Вт могут стать основой периферийных вычислений, а сборки с числом ядер от 32 до 192 и с TDP от 80 до 350 Вт займут место в мощных серверах, включая облачные. Пока что единственным более-менее массовым решением на базе Neoverse N1 владеет Amazon — в мае в AWS появились инстансы на базе 64-ядерных Graviton2.  После 2022 года выйдет следующее поколение Neoverse под кодовым именем Poseidon. Про него пока говорится в общих чертах, что оно станет производительнее на 30%, получит улучшения по части векторных инструкций и машинного обучения, обзаведётся поддержкой будущих версий CCIX и CXL, а также предложит более плотную упаковку ядер.
19.06.2020 [18:09], Юрий Поздеев
HPE анонсировала Superdome Flex 280: 224 ядра Cooper Lake и 24 Тбайт RAMHPE анонсировала Superdome Flex 280 с поддержкой процессоров Intel Xeon третьего поколения, которые вышли недавно. Данная модель дополняет портфель HPE Superdome Flex и ориентирована на средние предприятия, для которых избыточна масштабируемость до 32 сокетов. Оптимально данная модель подойдет для больших баз Oracle, SAP HANA или SQL-сервера. Новинка выпускается в форм-факторе 5U и поддерживает установку 2 или 4 процессоров Intel Xeon Gold или Intel Xeon Platinum. Это выгодно отличает Superdome Flex от других подобных систем, в которых можно использовать только Intel Xeon Platinum, который стоит значительно дороже.  Недавно анонсировали новые процессоры Intel Xeon третьего поколения, в которых не только добавили функции ускорения ИИ, но и поддержку более быстрой памяти DDR4-3200, что должно положительным образом сказаться на производительности. Максимально в одну платформу можно установить до 24 Тбайт оперативной памяти, а если и этого недостаточно, то можно использовать Intel Optane PMem 200 .  Слотов расширения PCIe тоже достаточно для большинства задач — до 32 на одну платформу, при этом можно установить до 16 графических ускорителей NVIDIA. Для локального хранилища можно использовать до 20 накопителей SAS/SATA/NVMe. Масштабируется платформа Superdome Flex 280 до 8 процессоров с шагом в 2 CPU, что позволяет работать с большими базами данных и моделями для ИИ, для которых требуется большой объем оперативной памяти. Суммарно можно получить до 224 ядер и до 24 Тбайт общей памяти. HPE Superdome Flex 280 будет доступен в 4 квартале 2020 года.
20.05.2020 [00:10], Юрий Поздеев
Б/У серверы Facebook✴ и Microsoft обретут новый дом благодаря ITRenew SesameГиганты Google, Facebook✴ и Microsoft каждый год покупают огромное количество серверов, которые могут работать и до 10 лет. Однако через 2–3 года они заменяются на новые, более производительные модели, так как для гиперскейлеров это проще и быстрее, чем строить или расширять ЦОД. При объемах закупок от 100 тыс. серверов в год каждый квартал более 10 тыс. единиц оборудования выводится из эксплуатации. Утилизировать всю эту технику было бы слишком расточительно, ведь даже серверы возрастом 2–3 года из ЦОД гиперскейлеров мощнее многих серверов, которые используются на предприятиях сегодня. ITRenew предлагает разумный выход из ситуации. ITRenew подписала с гиперскейлерами контракты на выкуп старого оборудования. Впрочем, «старое» — не совсем подходящее слово, так как оно отработало в среднем от 2 до 5 лет. Компания помогает значительно снизить издержки, дав, с одной стороны, возможность гипескейлерам вернуть часть вложенных средств, а с другой — снизить затраты на 40-50% для небольших предприятий, которые оснащают свои дата-центры. 
Стойки ITRenew Sesame Для многих компаний это единственная возможность купить оборудование такого класса, так как ODM вроде Wiwynn, Inspur, Quanta продают его только гиперскейлерам 1-го уровня (Amazon, Facebook✴, Google) и не собираются менять свою модель продаж, поскольку у них нет проблем со сбытом своей продукции. Еще один важный момент, на который обращают большое внимание в Европе и США, связан с экологией. То, что техника продолжает использоваться, а не уничтожается, позволяет экономить ресурсы и не загрязнять окружающую среду. Это особенно важно в свете того, что Китай закрыл ввоз подобного оборудования для утилизации и сортировки. И пока тенденция агрессивного обновления крупнейших дата-центров сохраняется, объем выведенной из эксплуатации техники будет расти. Может сложиться впечатление, что покупка б/у оборудования — это удел отсталых и бедных компаний, которые не хотят вкладывать деньги в развитие IT. Однако это далеко не так! Оборудованием от ITRenew комплектуются целые дата-центры, например, шведский ЦОД Hydro66. 
Узлы ITRenew Sesame Все оборудование в ITRenew проходит обязательную процедуру обслуживания: компоненты с малым остаточным ресурсом заменяются новыми или снятыми с других единиц техники. Затем всё проверяется, настраивается и упаковывается для транспортировки новым владельцам. Несмотря на то, что оборудование из дата-центров гиперскейлеров выпущено разными производителями (Wiwynn, Quanta и другими), оно проходит процедуру стандартизации и настройки, после чего управлять и поддерживать его гораздо проще, чем «зоопарком» обычного серверного оборудования разных брендов. Кроме того, многие компоненты таких систем открыты — они будут иметь полноценную поддержку долгие годы. Одна из причин, почему продажа б/у-оборудования от гиперскейлеров до сих по не стала действительно массовым явления, в том, что оно имеет OCP-исполнение, отличное от принятых в корпоративном мире стандартов. Это касается и шасси, и прошивок, и ПО. Именно поэтому ITrenew создала серию платформ, готовых принятть OCP-оборудование, со всем необходимым ПО для оркестрации Kubernetes. Sesame позволит объединить до 20 стоек (более 750 узлов) в один кластер с 25GbE-подключение. Слоган нового решения: «Сила гиперскейлеров для всех». Звучит довольно громко, однако так оно и есть. Теперь даже мелкие компании могут приобрести производительное оборудование, которое не стоит огромных денег. А для «самых маленьких» компания предлагает Sesame Fast Start, мини-стойку на колёсиках со всем необходимым. Fast-Start помещается под столом — она рассчитана на 5 узлов суммарной мощностью до 1600 Вт и имеет 10GbE-коммутатор.
23.02.2019 [20:20], Геннадий Детинич
Анонс серверных платформ ARM Neoverse E1 и N1: шах и мат, IntelУж извините за столь кричащий заголовок, но ARM давно мечтает сказать нечто подобное в отношении серверных платформ Intel. Пока получается не очень. Как говорят в самой ARM, не вышло с первого раза, попробуем во второй. Не получится во второй раз, на третий точно всё будет как надо. А сейчас и повод-то отличный! Разработчики оригинальных ядер ARM из одноимённой компании ударили сразу с двух направлений: по масштабируемым сетевым платформам (Neoverse E1) и по масштабируемым серверным (Neoverse N1). Очевидно, что пока «мата» в этой партии явно не будет. Intel крепко держится за серверные платформы и одновременно тянет руки к периферийным как в виде распределённых вычислительных ресурсов в составе базовых станций, так и в виде обычных периферийных ЦОД. Тем не менее, шансы объявить Intel «шах» у ARM определённо есть.  Рассчитанную на несколько лет вперёд стратегию Neoverse компания ARM представила в середине октября прошлого года. Она предполагает три крупных этапа, в ходе которых будут выходить доступные для широкого лицензирования 64-битные ядра ARM Ares (7 нм), Zeus (7 и 5 нм) и Poseidon (5 нм). Планируется, что каждый год производительность решений будет возрастать на 30 %. Сама компания ARM, напомним, не выпускает процессоры и SoC, а лишь продаёт лицензии на ядра и архитектуру, которые клиенты компании обустраивают нужными им контроллерами и интерфейсами. У ARM настолько многочисленная армия клиентов, что она ожидает буквально цунами из сотен и тысяч миллиардов ядер в год уже в недалёком будущем. Когда-нибудь в этот водоворот ядер будут вовлечены и серверные платформы, а затем количество перейдёт в качество. 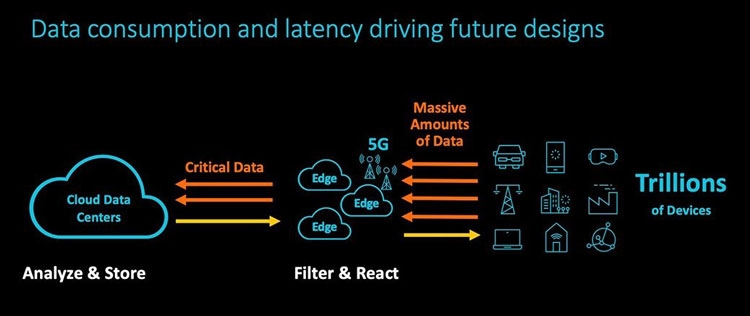 Разработка и анонс ядер Neoverse N1 ― это явление народу 7-нм ядер Ares. Процессоры могут нести от 4 до 128 ядер, объединённых согласованной ячеистой сетью. Платформа N1 может служить периферийным компьютером с 8-ядерным процессором с потреблением менее 20 Вт, а может стать сервером в ЦОД на 128-ядерных процессорах с потреблением до 200 Вт. Степень масштабируемости должна впечатлять. Кроме этого, как сообщают в ARM, производительность ядер N1 на облачных нагрузках в 2,5 раза выше, чем у 16-нм ядер предыдущего поколения Cosmos (Cortex-A72, A75 и A53). Кстати, прошлой осенью на платформе Cosmos компания Amazon представила фирменный процессор Graviton. 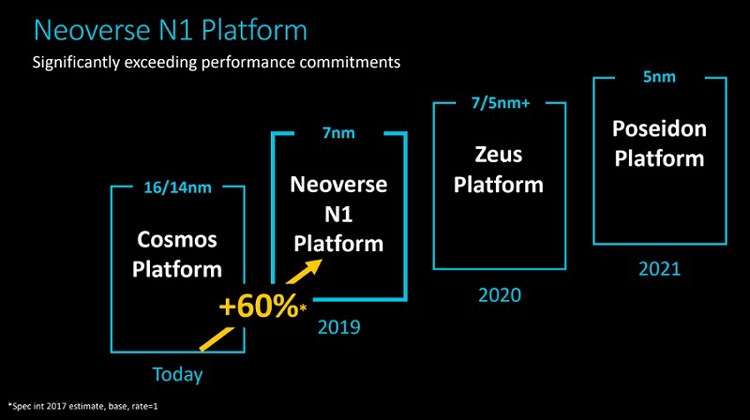 Производительность N1 при обработке целочисленных значений оказывается на 60 % больше, чем на ядрах Cortex-A72 Cosmos. При этом энергоэффективность ядер N1 также на 30 % выше, чем у ядер Cortex-A72. Как поясняют разработчики, платформа Neoverse N1 построена на «таких инфраструктурных расширениях, как виртуализация серверного класса, современная поддержка сервисов удалённого доступа, управление питанием и производительностью и профилями системного уровня». 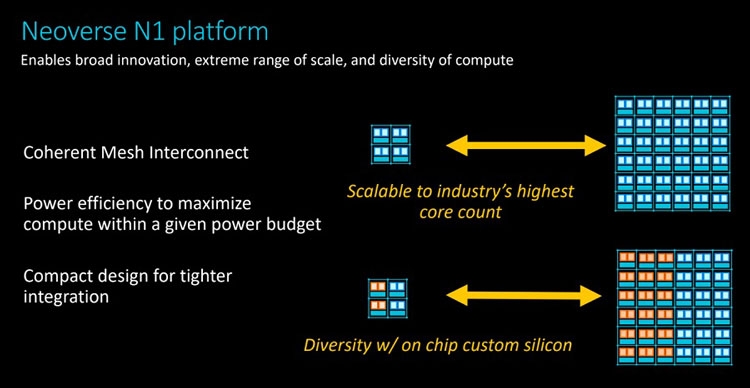 Когерентная ячеистая сеть (Coherent Mesh Network, CMN), о которой выше уже говорилось, разработана с учётом высокого соответствия вычислительным возможностям ядер. По словам ARM, сеть обменивается с ядрами такой служебной информацией, которая позволяет устанавливать объём загрузки в память данных для упреждающей выборки, распределяет кеш между ядрами и определяет, как он может быть использован, а также делает много других вещей, которые способствуют оптимизации вычислений. Интересно отметить, что в составе процессоров на платформе Neoverse N1 может быть существенно больше 128 ядер, но с оптимальной работой возникнут проблемы. Точнее, вычислительная производительность упрётся в пропускную способность памяти. Так, ARM рекомендует для CPU с числом ядер от 64 до 96 использовать 8-канальный контроллер DDR4, а для 96–128 ядерных версий ― контроллер памяти DDR5. Платформа Neoverse E1 ― это решение для сетевых шлюзов, коммутаторов и сетевых узлов, которое, например, облегчит переход от сетей 4G к сетям 5G с их возросшей требовательностью к каналам передачи данных. Так, Neoverse E1 обещает рост пропускной способности в 2,7 раза, увеличение эффективности при передаче данных в 2,4 раза, а также более чем 2-кратный рост вычислительной мощности по сравнению с предыдущими платформами (ядрами). С масштабируемостью ядер E1 тоже всё в порядке, они позволят создать решение как для базовых станций начального уровня с потреблением менее 35 Вт, так и маршрутизатор с пропускной способностью в сотни гигабайт в секунду. Что же, ARM расставила на доске новые фигуры. Будет интересно узнать, кто же начнёт игру?
29.06.2018 [13:00], Геннадий Детинич
Опубликованы финальные спецификации CCIX 1.0: разделяемый кеш и PCIe 4.0Чуть больше двух лет назад в мае 2016 года семёрка ведущих компаний компьютерного сектора объявила о создании консорциума Cache Coherent Interconnect for Accelerators (CCIX, произносится как «see six»). В число организаторов консорциума вошли AMD, ARM, Huawei, IBM, Mellanox, Qualcomm и Xilinx, хотя платформа CCIX объявлена и развивается в рамках открытых решений Open Compute Project и вход свободен для всех. В основе платформы CCIX лежит дальнейшее развитие идеи согласованных (когерентных) вычислений вне зависимости от аппаратной реализации процессоров и ускорителей, будь то архитектура x86, ARM, IBM Power или нечто уникальное. Скрестить ежа и ужа — вот едва ли не буквальный смысл CCIX. 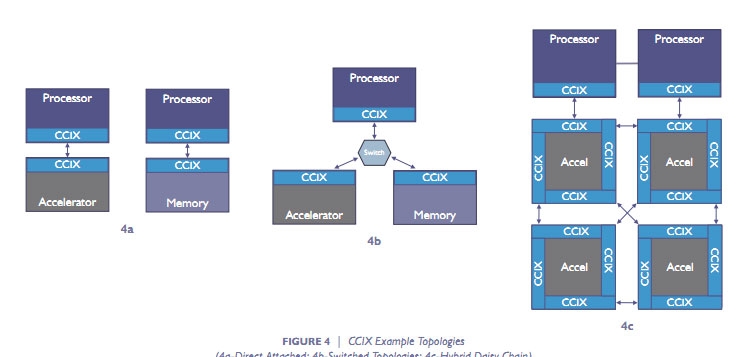
Варианты топологии CCIX На днях консорциум сообщил, что подготовлены и представлены финальные спецификации CCIX первой версии. Это означает, что вскоре с поддержкой данной платформы на рынок может выйти первая совместимая продукция. По словам разработчиков, CCIX позволит организовать новый класс подсистем обмена данными с согласованием кеша с низкими задержками для следующих поколений облачных систем, искусственного интеллекта, больших данных, баз данных и других применений в инфраструктуре ЦОД. Следующая ступенька в производительности невозможна без эффективных гетерогенных (разнородных) вычислений, которые смешают в одном котле исполнение кода общего назначения и спецкода для ускорителей на базе GPU, FPGA, «умных» сетевых карт и энергонезависимой памяти. 
Решение CCIX IP компании Synopsys Базовые спецификации CCIX Base Specification 1.0 описывают межчиповый и «бесшовный» обмен данными между вычислительными ресурсами (процессорными ядрами), ускорителями и памятью во всём её многообразии. Все эти подсистемы объединены разделяемой виртуальной памятью с согласованием кеша. В основе спецификаций CCIX 1.0, добавим, лежит архитектура PCI Express 4.0 и собственные наработки в области быстрой коррекции ошибок, что позволит по каждой линии обмениваться данными со скоростью до 25 Гбайт/с. 
Тестовая платформа с поддержкой CCIX Synopsys на FPGA матрице Но главное, конечно, не скорость обмена, хотя это важная составляющая CCIX. Главное — в создании программируемых и полностью автономных процессов по обмену данными в кешах процессоров и ускорителей, что реализуется с помощью новой парадигмы разделяемой виртуальной памяти для когерентного кеша. Это радикально упростит создание программ для платформ CCIX и обеспечит значительный прирост в ускорении работы гетерогенных платформ. Вместо механизма прямого доступа к памяти (DMA), со всеми его тонкостями для обмена данными, на платформе CCIX достаточно будет одного указателя. Причём обмен данными в кешах будет происходить без использования драйвера на уровне базового протокола CCIX. Ждём в готовой продукции. Кто первый, AMD, ARM или IBM? 
Тестовый набор CCIX 
Рабочая демо-система с неназванным CPU и FPGA, соединённых шиной CCIX
06.12.2017 [23:45], Сергей Юртайкин
IBM представила первый сервер на процессоре POWER9IBM представила свой первый собственный сервер на процессоре POWER9. Особенность решения под названием IBM Power Systems AC922 заключается в том, что новая аппаратная платформа разработана специально для работы с интенсивными вычислительными нагрузками технологий искусственного интеллекта (ИИ). 
CPU IBM POWER9 В IBM отмечают, что Power 9 позволяет ускорить тренировки фреймворков глубинного обучения обучения почти в четыре раза, благодаря чему клиенты смогут быстрее создавать более точные ИИ-приложения. Утверждается, что новый сервер разработан для получения значительных улучшений производительности всех популярных фреймворков ИИ, таких как Chainer, TensorFlow и Caffe, а также современных баз данных, использующих ускорители, например, Kinetica. 
Сервер IBM Power System AC922 Сервер IBM Power Systems AC922 использует шину PCI-Express 4.0 и технологии NVIDIA NVLink 2.0 и CAPI 2.0/OpenCAPI, способные ускорить пропускную способность в 9,5 раза по сравнению с системами x86 на базе PCI-E 3.0. Это, в частности, позволяет задействовать ускорителям (GPU или FPGA) системную ОЗУ без значительных, по сравнению с прошлыми решениями, потерь производительности, что важно для обработки больших массивов данных. Кроме того, новые поколения карт расширения и ускорителей уже поддерживают эту шину.  IBM Power Systems AC922 создан в нескольких конфигурациях, оснащаемых двумя процессорами POWER9. Стандартные версии включают CPU c 16 (2,6 ГГц, турбо 3,09 ГГц) и 20 (2,0/2,87 ГГц) ядрами (4 потока на ядро), а позже появятся версии с 18- и 22 -ядерными процессорами. Всего в сервере есть 16 слотов для модулей ECC DDR4-памяти, что на текущий момент позволяет оснастить его 1 Тбайт RAM. Для хранения данных предусмотрено два слота для 2,5" SSD/HDD (RAID-контроллера нет).  AC922 может иметь на борту от двух до четырёх ускорителей NVIDIA Tesla V100 форм-фактора SXM2 с памятью 16 Гбайт и шиной NVLink 2.0. В сумме они дают до 500 Тфлопс на расчётах половинной точности. Дополнительные ускорители можно подключить к слотам PCI-E 4.0.  Сервер рассчитан на установку четырёх дополнительных низкопрофильных карт расширения: два слота PCI-E 4.0 x16, один PCI-E 4.0 x8 и один PCI-E 4.0 x4. Все слоты, кроме последнего, также умеют работать с CAPI. Также есть два порта USB 3.0. Поддерживается ОС Red Hat Enterprise Linux 7.4 for Power LE.  Процессоры IBM Power 9, которые нашли применение в IBM Power Systems AC922, легли в основу суперкомпьютеров Summit и Sierra Министерства энергетики США, а также используются компанией Google. Чипы и использующие их системы стали частью совместной работы участников организации OpenPower Foundation, в которую входят IBM, Google, Mellanox, NVIDIA и др. 
Процессор IBM Power 9 «Мы создали уникальную в своём роде систему для работы с технологиями ИИ и когнитивными вычислениями, — говорит старший вице-президент подразделения IBM Cognitive Systems Боб Пиччиано (Bob Picciano). — Серверы на Power 9 являются не только основой самых высокопроизводительных компьютеров, они позволят заказчикам масштабировать невиданные ранее инсайты, что будет способствовать научным прорывам и революционным улучшениям бизнес-показателей».  Сервер имеет стандартное 2U-шасси и оснащается двумя (1+1) блоками питания мощностью 2,2 кВт каждый. Система охлаждения может быть гибридной. Начало продаж IBM Power Systems AC922 намечено на 22 декабря 2017 года. В 2018 году будут доступны конфигурации с шестью ускорителями Tesla и СЖО. 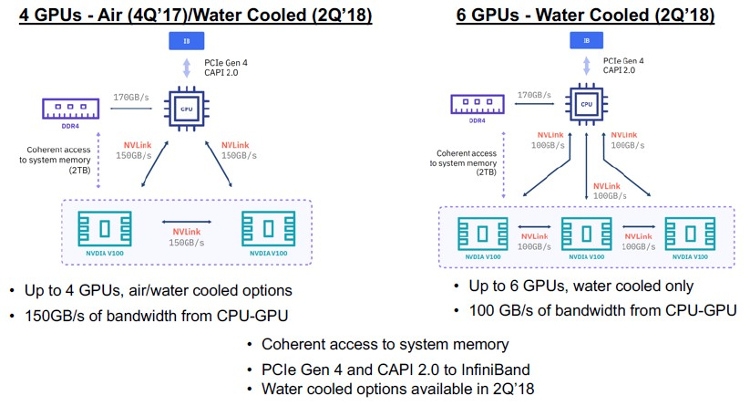
30.09.2017 [00:15], Алексей Степин
Терафлопс в космосе: на МКС тестируется компьютер HPE SpaceborneБытует мнение, что в космической отрасли используется всё самое лучшее, включая компьютерные компоненты. Это не совсем так: вы не встретите в космических аппаратах 18-ядерных Xeon и ускорителей Tesla. Во-первых, энергетические резервы за пределами Земли строго ограничены, и даже на МКС никто не будет тратить несколько киловатт на питание «космического суперкомпьютера». Во-вторых, практически вся электроника, работающая за пределами атмосферы, выпускается в специальном радиационно-стойком исполнении. Чаще всего за счёт техпроцессов «кремний на диэлектрике» (SOI) и «сапфировая подложка» (SOS), используется также биполярная логика вместо менее стойкой к внешним излучениям CMOS. 
Мини-кластер в космическом исполнении. Охлаждение жидкостное Мощными в космосе считаются такие решения, как BAE Systems серии RAD, особенно новая RAD5500 (от 1 до 4 ядер, 45-нм SOI, PowerPC, 64 бита). Четырёхъядерный вариант RAD5545 развивает производительность более 3,7 гигафлопс при потреблении около 20 ватт. Иными словами, вычислительные мощности в космосе тоже растут, но совсем иными темпами, нежели на Земле. Тому подтверждением служит недавно вступивший в строй на борту Международной космической станции компьютер HPE Spaceborne. Если на Земле мощность суперкомпьютеров измеряется десятками и сотнями петафлопс, то Spaceborne куда скромнее — судя по проведённым тестам, его вычислительная мощность достигает 1 терафлопса. Достигнута она путём сочетания современных процессоров Intel с ускорителями NVIDIA Tesla P100 (NVLink-версия). 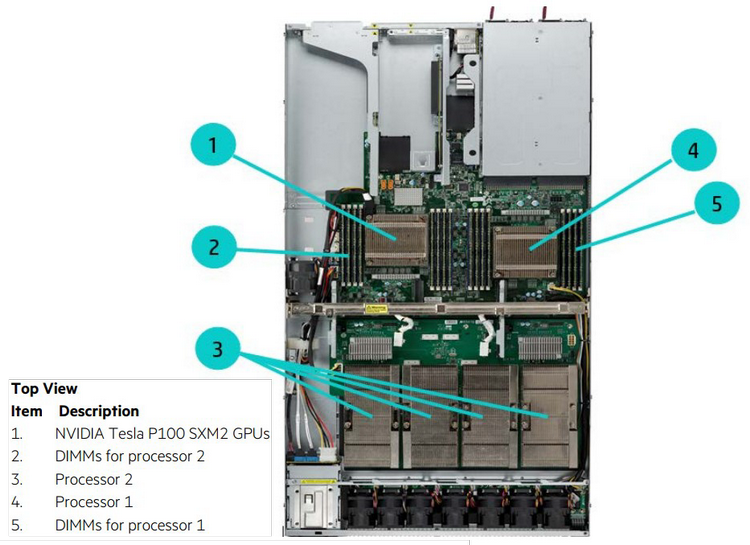
Конфигурация каждого из узлов Spaceborne Для космических систем это большое достижение, и не стоит иронизировать над этим показателем производительности. Интересно, что сама по себе система Spaceborne, доставленная на борт станции миссией SpaceX CRS-12, является своего рода экспериментом на тему «как чувствуют себя в космосе обычные компьютерные комплектующие». Это связка из двух серверов HPE Apollo 40 на базе Intel Xeon, объединённая сетью со скоростью 56 Гбит/с. 14 сентября на систему было подано питание (48 и 110 вольт), а недавно проведены первые тесты High Performance LINPACK. 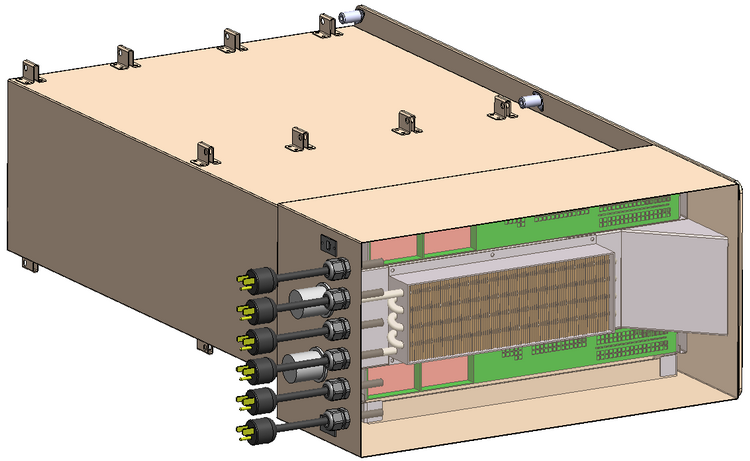
Системы охлаждения и электропитания Spaceborne Пока Spaceborne не будет использоваться для анализа научных данных или управления какими-либо системами станции. Его миссия — продемонстрировать то, насколько живучи обычные серверы в космосе. Результаты постоянных тестов будут сравниваться с аналогичной системой, оставшейся на Земле. Тем не менее, достижение первого терафлопса в космосе является своеобразным мировым рекордом. Это маленький шаг для супервычислений, но большой для всей космической индустрии, поскольку за Spaceborne явно последуют его более совершенные и мощные потомки.
23.08.2017 [12:40], Геннадий Детинич
Qualcomm поделилась деталями о 48-ядерных процессорах Centriq 2400Пять лет назад компания Qualcomm приступила к разработкам процессора для серверного рынка. Успешный разработчик уникальных вычислительных архитектур, совместимых с наборами команд ARM, вполне обоснованно решил перенести опыт создания SoC для смартфонов и планшетов в область высокопроизводительных серверных решений. К тому времени требования к серверным процессорам изменились в сторону снижения потребления и лучшей масштабируемости. Социальные сети и облачные сервисы создают настолько неравномерную нагрузку на вычислительные ресурсы ЦОД, что обычные x86-совместимые или RISC/UNIX-платформы перестают считаться эффективным инструментом для решения насущных задач.  В декабре 2016 года Qualcomm сообщила о завершении разработки и начале пробных поставок процессора Centriq 2400 с числом ядер до 48 штук. На днях компания подтвердила график вывода новинки на рынок, который предусматривает массовые коммерческие поставки SoC Centriq 2400 позднее в текущем году. Также Qualcomm поделилась деталями о строении и архитектуре Centriq 2400. Ниже мы расскажем о ключевых особенностях разработки.  Начнём с того, что внутренний согласованный интерфейс однокристальной сборки Centriq 2400 представляет собой сегментированную кольцевую шину. Компания Intel, как нам известно, в новых серверных и высокопроизводительных настольных процессорах перестанет использовать кольцевую шину в пользу ячеистой шины, что должно улучшить масштабируемость архитектуры для многоядерного окружения. Компания AMD использует другой принцип обмена данными между кластерами в процессорах на ядрах Zen. Все они соединены между собой двунаправленной шиной, топология которой ближе к кольцевой. Сегментированная кольцевая шина в составе Centriq 2400 использует преимущества кольцевой шины (простота, сравнительно низкое потребление) и элементы ячеистой сети внутри сегмента, что даёт возможность балансировать между скоростью, задержками и потреблением. 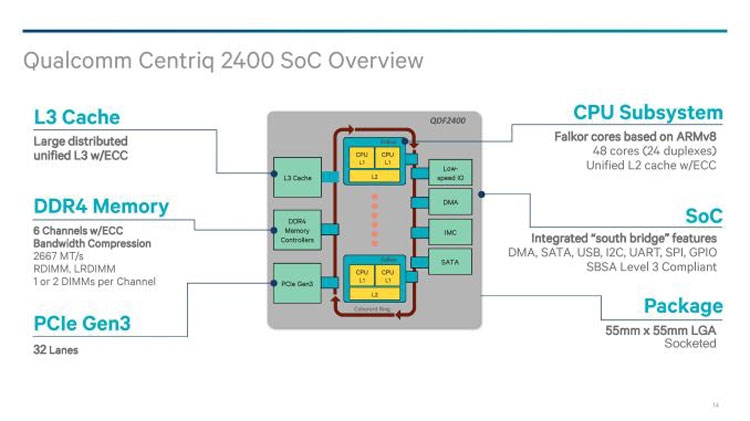 Вычислительные ядра в составе Centriq 2400 самостоятельно разработаны инженерами компании и носят кодовое имя Falkor. Это 64-битные решения с поддержкой команд ARMv8, которые разбиты на модули из двух связанных ядер (дуплексное строение, по определению Qualcomm). Подобное строение позволяет выпускать SoC Centriq 2400 с заданным числом ядер и облегчает масштабирование вычислительной структуры в процессе выполнения задачи. Каждая пара ядер имеет разделяемую кеш-память L2 и разделяемый доступ к кольцевой шине Qualcomm System Bus (QSB). 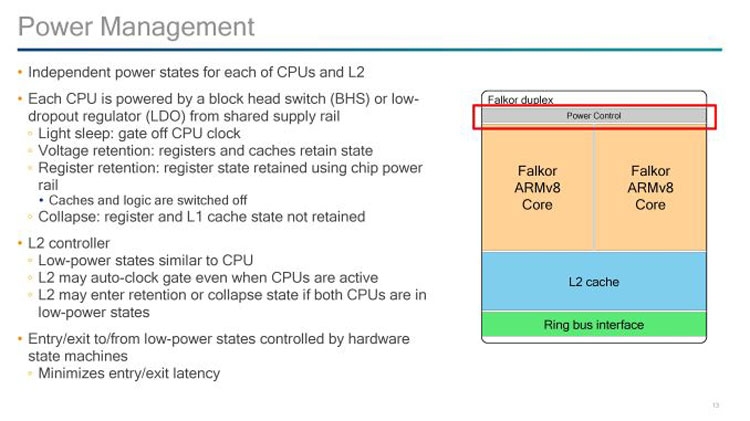 Для снижения потребления каждое ядро и кеш-память L2 имеют ряд состояний потребления энергии, которые контролируются на аппаратном уровне и могут переключаться с минимальными задержками. Вычислительные конвейеры Falkor имеют переменную длину с внеочередным исполнением команд. Это снижает вероятность простоя конвейеров в процессе работы с командами и инструкциями, не оптимизированными для немедленного исполнения. 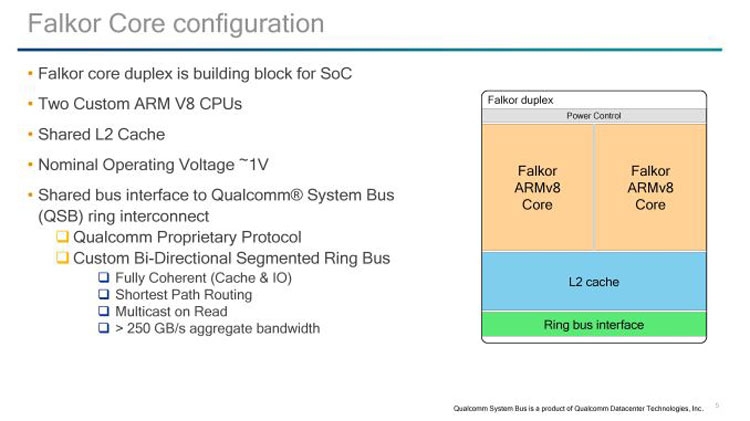 Иерархия кеш-памяти Falkor оптимизирована для обработки значительных массивов данных. Так, кеш-память первого уровня для приёма данных объёмом 32 Кбайт дополнена «несимметричной» кеш-памятью L1 для инструкций: 24 Кбайт L0 и 64 Кбайт L1 (всего 88 Кбайт). Всё это снабжено многоуровневым движком предварительной выборки, который динамически адаптируется под текущую нагрузку. В состав SoC Centriq 2400 вошли 6-канальный контроллер памяти с поддержкой DDR4-2667 МГц ECC (до двух модулей на канал), 32 линии PCI Express 3.0, интерфейсы SATA, USB и более специализированные сигнальные структуры. Также Centriq 2400 несёт интегрированный криптографический блок TrustZone и поддерживает аппаратную виртуализацию. В компании Qualcomm уверены, что данную разработку ждёт успешное будущее. |
|

