Материалы по тегу: виртуализация
|
03.07.2026 [10:02], Владимир Мироненко
Citrix анонсировала XenServer 9 — альтернативу решениям VMwareCitrix выпустила новую версию платформы для виртуализации XenServer 9. Как передаёт The Register со ссылкой на полученный пресс-релиз компании, ПО «создано для организаций, активно пересматривающих свою стратегию виртуализации в условиях ценового давления», то есть для тех, кто подыскивает альтернативу VMware. Это можно расценивать как заявление о решении вернуться на общий рынок виртуализации, поскольку XenServer 9 предлагает поддержку любых нагрузок, обеспечивая при этом более тесную операционную согласованность в средах Citrix DaaS. В свою очередь, немецкий ресурс igor´sLAB отметил, что на XenServer 8.4 по-прежнему указан в качестве актуальной версии, а XenServer 9 описывается как «публичная предварительная версия», полный релиз которой, как сообщается, ожидается не раньше конца 2026 года. Впрочем, ISO-образы новинки уже доступны для скачивания. XenServer пользовался популярностью в начале 2010-х годов, но не выдержал конкуренции с VMware и Hyper-V. Уже в 2014 году аналитики Gartner предположили, что Citrix перестала пытаться конкурировать за рабочие нагрузки, отличные от собственных продуктов для виртуализации рабочих столов и сетевой безопасности. После поглощения в 2022 году двумя частными инвестиционными компаниями Citrix вошла в состав Cloud Software Group (CSG) в качестве подразделения под названием XenServer. На прошлой неделе она сообщила о возвращении XenServer «под эгиду Citrix». Как стало известно The Register, это фактически означало прекращение существования XenServer как бизнес-подразделения. 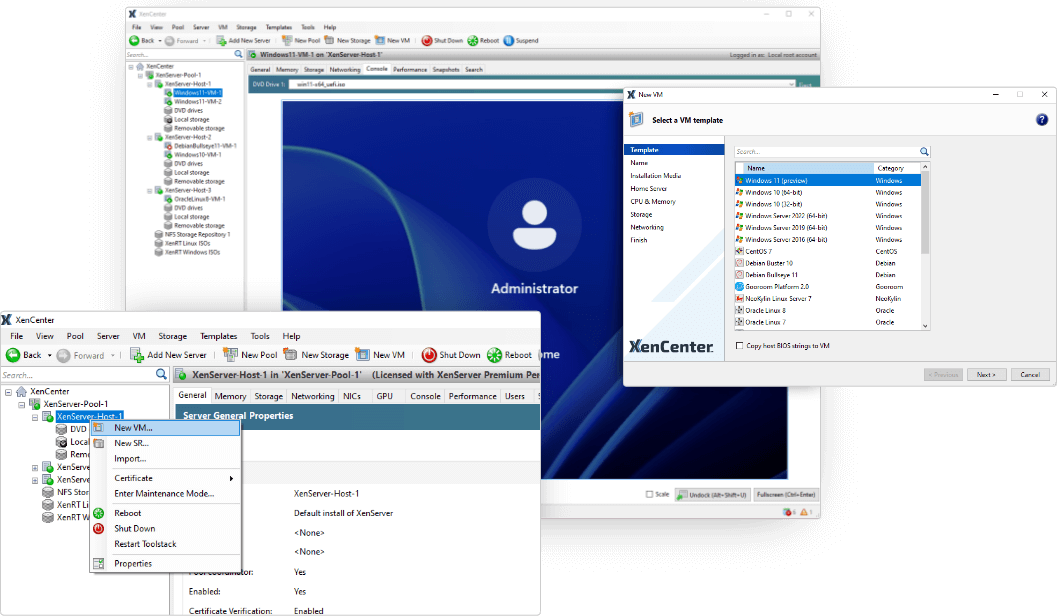
Источник изображений: XenServer / Citrix Citrix позиционирует новый продукт как центральный элемент своей стратегии по привлечению клиентов, пересматривающих свои расходы на инфраструктуру и управление ею. Многие крупные организации переоценивают стоимость и сложность запуска критически важных для бизнеса рабочих нагрузок в локальных и гибридных средах. XenServer 9 предлагается для клиентов, которые хотят сохранить эти рабочие нагрузки внутри компании, упростив при этом повседневное администрирование. При этом XenServer 9 включён в лицензии, которыми обладают многие решения Citrix — Citrix Platform Licence, Universal Hybrid Multi Cloud и Citrix for Private Cloud, охватывая развёртывания до 10 тыс. сокетов без дополнительной платы, что соответствует масштабу крупных корпоративных сред. Для команд с обширной инфраструктурой это означает, что Citrix хочет, чтобы XenServer рассматривался не только для нишевых развёртываний, но и для широкого внутреннего использования. Основные улучшения в новом релизе включают оптимизацию NUMA для повышения производительности ВМ, поддержку безопасной загрузки хоста, новую ОС для управляющего домена, улучшенную обработку сетевых имён хоста, использование недавно выпущенного открытого гипервизора Xen 4.21. Также сообщается об обновлении ядра Dom0 до версии 6.x. Поддерживаемые гостевые ОС включают Windows 10/11, Windows Server 2016 и нове, RHEL/Rocky Linux, SUSE, Debian/Ubuntu, а также Gooroom 2 — Linux-дистрибутив Министерства науки и технологий Южной Кореи.  Citrix обещает пятилетнюю поддержку XenServer 9. Вместо классической долгосрочной поддержки и текущих релизов платформа предполагает использование модели непрерывных обновлений. Citrix заявила, что это должно помочь организациям снизить риски, связанные с обновлениями продуктовых систем, особенно в распределённых или крупномасштабных средах, где простои и проблемы совместимости могут быть сложными в разрешении. Управление драйверами и жизненным циклом также было улучшено для уменьшения сбоев во время обновлений и замены оборудования. «XenServer 9 — это прагматичный ответ на давление, с которым сегодня сталкиваются команды разработчиков инфраструктуры, — заявила Citrix. — Это отражает рыночную реальность, в которой стоимость, простота эксплуатации и стабильность являются тесно взаимосвязанными требованиями, которые необходимо учитывать совместно». Вместе с тем, как отметил The Register, включение XenServer 9 в лицензии не всем придётся по душе, поскольку, как правило, они охватывают пакеты многих продуктов, некоторые из которых пользователи не всегда используют или не хотят, и это может повлечь за собой значительное повышение цен. Citrix обосновывает свою систему лицензирования тем, что она проще, чем покупка отдельных продуктов, и утверждает, что пакеты означают, что клиенты получают большую выгоду и более простую эксплуатацию. Но VMware использует те же аргументы, и это не всегда находит позитивную поддержку у клиентов.
02.07.2026 [10:30], Сергей Карасёв
GPU-серверы в 2026 году: когда видеокарта окупается, а когда достаточно VPSИнтерес к GPU-серверам вырос вместе с нейросетями и локальным запуском моделей. Но видеокарта нужна не каждому проекту. В одних задачах GPU сокращает обработку с часов до минут, в других остаётся дорогим ресурсом, который почти не используется. Специалисты AdminVPS отмечают: перед выбором сервера бизнесу важно оценивать не только запас мощности, но и характер нагрузки. Главное отличие GPU от CPU — не «больше мощности», а другой тип вычислений. Центральный процессор лучше подходит для последовательной логики: работы сайта, базы данных, API, CRM, интернет-магазина или бота. В таких проектах важны стабильные vCPU, RAM, быстрый NVMe-диск и корректно настроенное окружение. Если нагрузка связана с веб-сервисом, Docker-контейнерами, аналитикой или внутренними инструментами, обычно достаточно обычного виртуального сервера. 
Перекрёсток выбора: VPS или GPU (Источник изображений: AdminVPS) GPU нужен там, где задача хорошо распараллеливается: обучение ML-моделей, инференс локальных LLM, обработка изображений и видео, 3D-рендеринг, компьютерное зрение, распознавание объектов, большие массивы однотипных вычислений. В таких сценариях видеокарта берёт на себя тысячи параллельных операций, с которыми CPU справляется заметно медленнее. 
Сравнение процессоров: CPU против GPU Есть простой критерий: если проект использует готовые AI-сервисы через API, GPU на собственном сервере чаще всего не нужен. Нагрузка уходит на внешнюю платформу, а серверу остаются бизнес-логика, хранение данных, авторизация и интерфейс. Здесь важнее надёжный VPS, резервное копирование и возможность масштабировать CPU/RAM. Для таких задач рациональнее выбрать конфигурацию без видеокарты — например, сервер VPS с балансом производительности и стоимости. 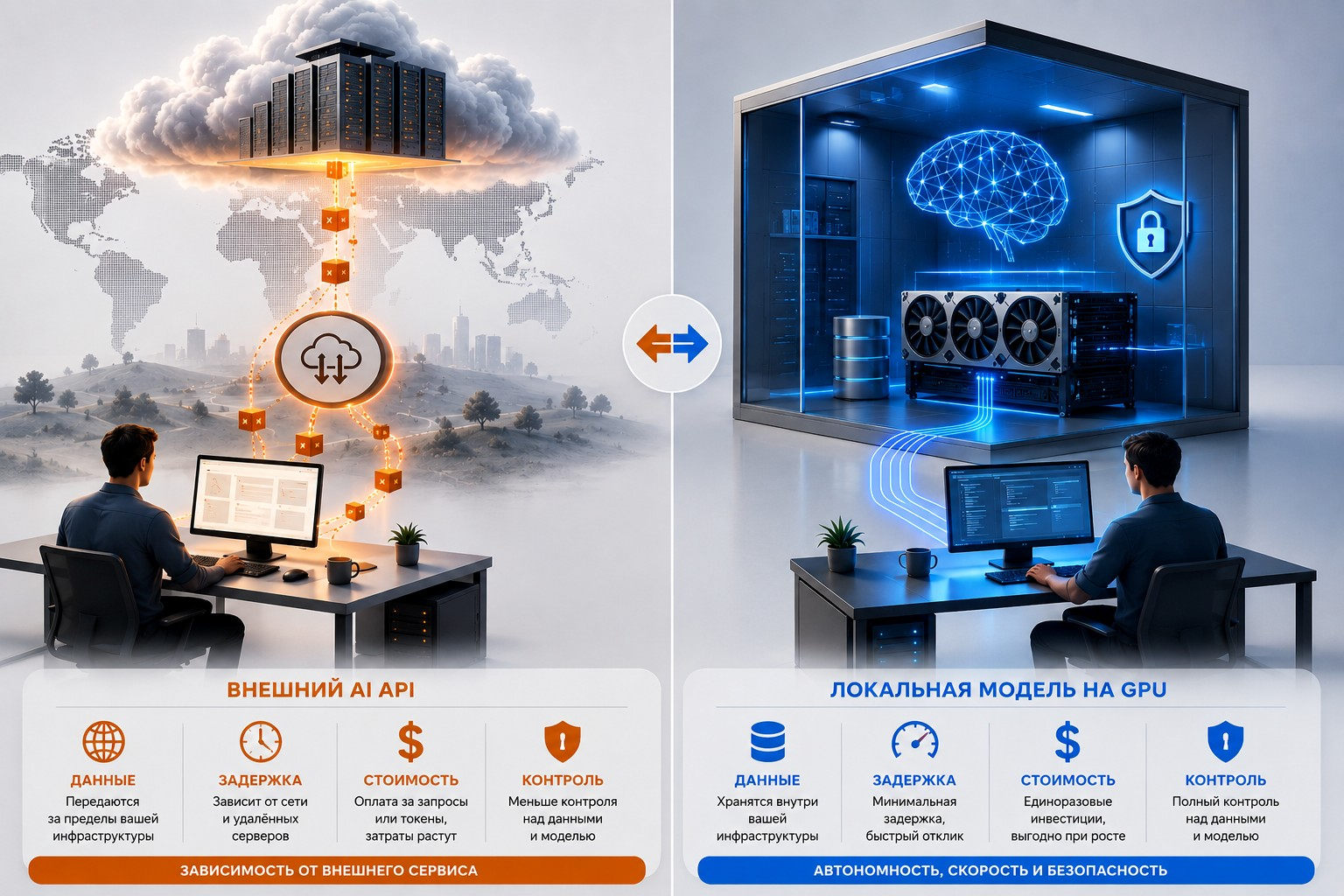
Сравнение внешнего API и локальных серверов Другая ситуация — когда модель нужно запускать локально: важна скорость ответа, работа с внутренними данными, контроль окружения или запуск вычислений без привязки к стороннему сервису. Тогда сервер с графическим ускорителем становится рабочим инструментом. В AdminVPS GPU-серверы комплектуются NVMe-накопителями и защищены от DDoS. Для инференса моделей в реальном времени важна техподдержка 24/7, которая помогает с настройкой драйверов и CUDA-окружения. 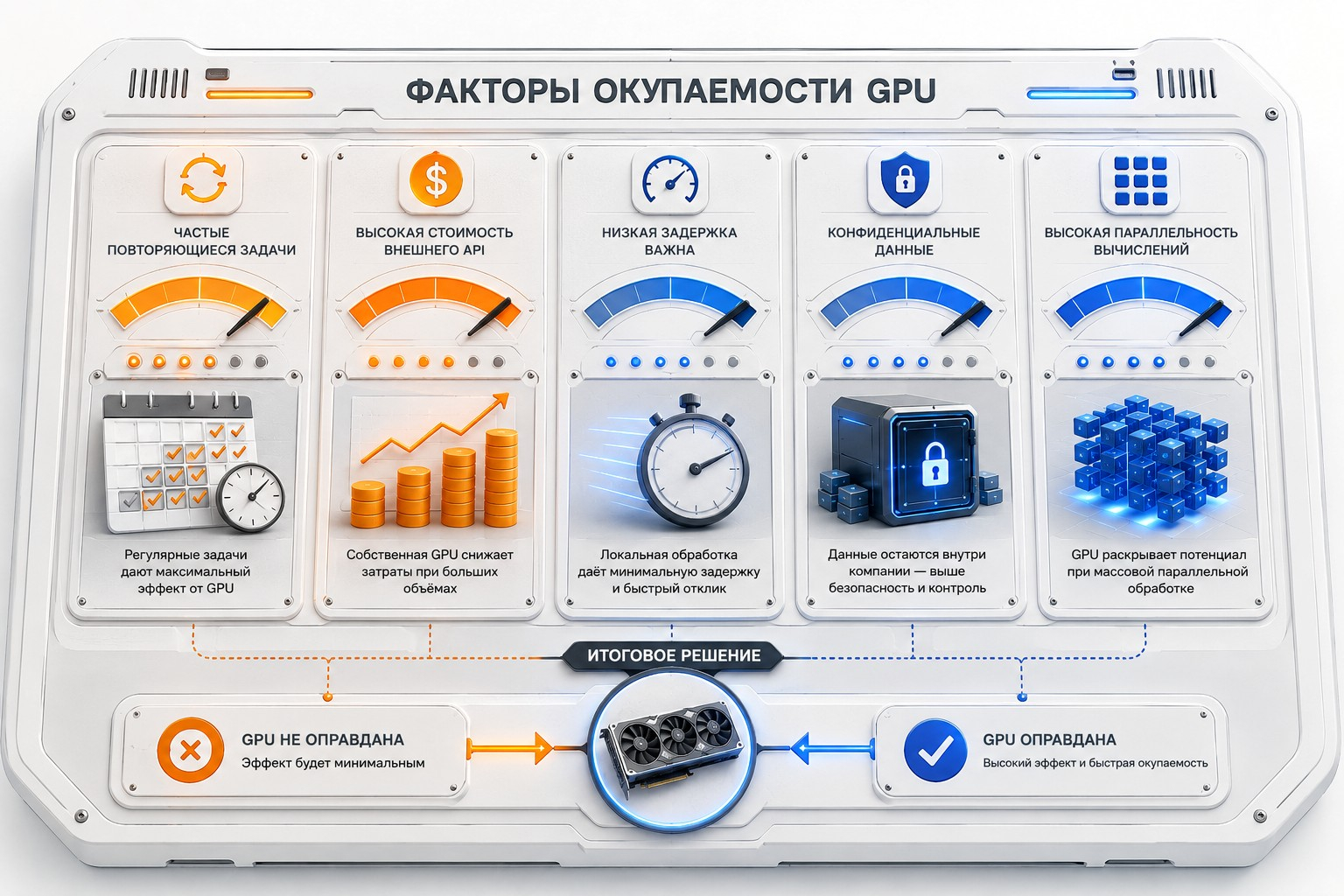
Факторы окупаемости GPU Перед переходом стоит ответить на несколько вопросов: есть ли у приложения параллельные вычисления; поддерживает ли стек CUDA или GPU-фреймворки; как долго идут расчёты на CPU; насколько часто они запускаются; что станет узким местом после ускорения — видеокарта, диск, память или сеть. Правильная стратегия — не сразу брать самый мощный сервер, а сопоставить инфраструктуру с задачей. Для сайтов, CRM, API, ботов и большинства корпоративных сервисов обычный VPS остаётся более экономичным решением. GPU-сервер нужен тогда, когда вычисления упираются в параллельную обработку данных, а ускоритель влияет на скорость продукта или себестоимость операций. Оценить конфигурации под ресурсоёмкие задачи можно в разделе VPS сервер с GPU на сайте AdminVPS.
16.06.2026 [10:00], SN Team
«Базис» и Т2 развернули первое в России импортонезависимое телеком-облако
базис
биллинг
виртуализация
импортозамещение
информационная безопасность
облако
сделано в россии
сети
теле2
«Базис», крупнейший российский разработчик ПО для управления динамической ИТ-инфраструктурой и Т2, российский оператор мобильной связи, запустили первое в стране телеком-облако отечественного производства. Теперь PCRF (функция правил политики тарификации) Т2 работает на базе отечественной платформы виртуализации Basis Dynamix. Проект стартовал в середине 2025 года. Технические специалисты Т2 и «Базиса» интегрировали платформу Basis Dynamix с системами хранения данных и адаптировали гипервизор под кластерную архитектуру сетевых функций. Также команды оптимизировали ресурсоемкость решения: вместо стандартного развертывания выделенных модулей безопасности для каждого кластера, специалисты настроили единый узел защиты всего сайта. Это кратно снизило потребность Т2 в сетевом оборудовании. После ухода с рынка иностранных вендоров рынок мобильных операторов лишился профильного инфраструктурного ПО. Т2 в течение нескольких лет проводила аудит рынка. При выборе решения оператор сделал ставку на производительность и отказоустойчивость ядра. Техническим фундаментом стала платформа Basis Dynamix. Гибкая архитектура решения позволила инженерам адаптировать процессы под требования телеком-инфраструктуры и напрямую интегрировать специфические механизмы управления трафиком, необходимые для стабильной работы мобильной сети. 
Источник изображения: «Базис» / Денис Насаев В 2026 году «Базис» завершит подготовку инфраструктуры еще в 10 вычислительных центрах Т2 — это позволит оператору масштабировать работу функции PCRF на все регионы присутствия. Созданная технологическая база даст возможность поэтапно перевести остальные сетевые компоненты на отечественное ПО в соответствии с требованиями регулятора. «До старта этого проекта на российском рынке отсутствовал практический опыт применения отечественных enterprise-платформ в качестве телеком-облака. Требования операторов связи в корне отличаются от запросов корпоративного бизнеса. Нам пришлось обеспечить полное резервирование всех без исключения компонентов и интегрировать специализированные механизмы аппаратного ускорения трафика. Совместно с инженерами Т2 мы фактически переизобрели архитектуру развертывания нашей платформы, найдя баланс между строгими требованиями ИБ и необходимостью экономии аппаратных ресурсов под узлы управления», — прокомментировал коммерческий директор «Базиса» Иван Ермаков. «Исторически мы решали инфраструктурные задачи покупкой комплексных узлов связи, но сегодня перешли к самостоятельному построению ИТ-ландшафта на базе независимых программных компонентов. Главным вызовом стала оптимизация нового программного стека: нам потребовалось достичь высоких показателей производительности сети при рациональном использовании аппаратных ресурсов. За несколько лет мы провели масштабную ревизию архитектурных стандартов и в ходе проекта совместно с вендором эффективно адаптировали платформу под нужды бизнеса. Успешный запуск в Санкт-Петербурге доказал надежность выбранного нами подхода», — отметил заместитель генерального директора по технической инфраструктуре Т2 Алексей Дмитриев.
10.06.2026 [14:00], Сергей Карасёв
Новый релиз Basis Dynamix Enterprise 4.6: автоматическая балансировка нагрузки, связанные клоны и поддержка современных протоколов работы с СХД«Базис», лидер российского рынка ПО для управления динамической инфраструктурой, объявляет о выпуске новой версии платформы серверной виртуализации Basis Dynamix Enterprise 4.6. Релиз сосредоточен на трёх ключевых направлениях: автоматической балансировке нагрузки между вычислительными узлами, экономии дискового пространства за счёт связанных клонов и поддержке современных протоколов работы с системами хранения данных. Всего в новую версию вошло более 60 улучшений и доработок. Динамическая балансировка нагрузкиВ Basis Dynamix Enterprise 4.6 добавлен механизм Distributed Resource Scheduler (DRS), который обеспечивает взаимодействие платформы и модуля Basis Resource Optimizer. Вместе они балансируют нагрузку на вычислительных узлах — следят за состоянием инфраструктуры и при необходимости перераспределяют виртуальные машины между узлами для более равномерного использования ресурсов кластера, что позволяет снизить простои оборудования. 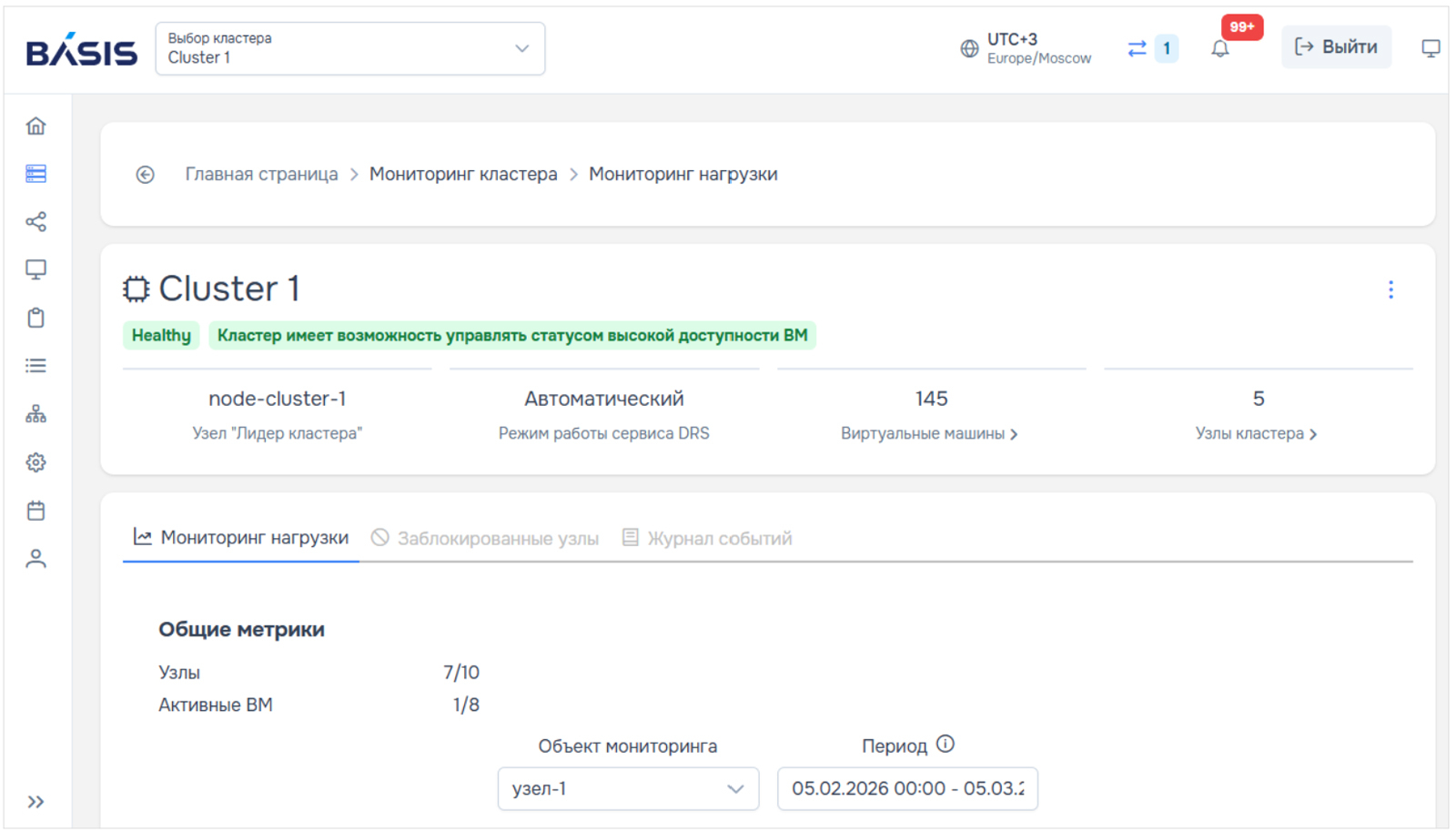
Центральная панель кластера Basis Resource Optimizer (Изображения «Базис») Basis Resource Optimizer анализирует метрики потребления процессора и памяти и на их основе формирует рекомендации: о переносе виртуальных машин между узлами для равномерной загрузки, об изменении количества vCPU и объема оперативной памяти, а также следит за соблюдением правил размещения — Affinity (держать ВМ на одном узле) и Anti-Affinity (разносить по разным узлам). В зависимости от выбранного режима и настроек правила рекомендации применяются автоматически или после подтверждения оператора. Операции, которые требуют перезагрузки виртуальной машины, например, изменение выделенных ей ресурсов, можно выполнять в заранее заданные интервалы. За это отвечает сервис технических окон: администратор задаёт разовые или повторяющиеся расписания, и подобные задачи планируются на ближайшее разрешённое окно в период минимальной нагрузки. 
Распределенный планировщик ресурсов Basis Dynamix Enterprise DRS в составе Basis Dynamix Enterprise устанавливается в кластере управления. Администратор может создавать планировщики внутри отдельных зон, добавлять и удалять узлы из их области действия, запускать и останавливать механизм через API. Это позволяет администраторам заказчика настраивать политики балансировки под особенности конкретной инфраструктуры — от компактных кластеров до крупных геораспределённых установок. Связанные клоны и экономия дискового пространстваДля хранения данных на локальных дисках вычислительных узлов (Local SEP) в платформе появилась поддержка тонких дисков и связанных клонов. Если виртуальная машина создаётся из образа, размещённого в том же пуле, её диск становится зависимым потомком этого образа — фактическое копирование данных не выполняется, а изменения записываются по принципу copy-on-write. Это сокращает расход дискового пространства при массовом развёртывании однотипных ВМ — например, в сценариях VDI, на тестовых стендах или в сервис-провайдерских инсталляциях. Параллельно внедрена поддержка механизма «множественный образ» (MultiImage), который объединяет ссылки на копии одного шаблонного образа, размещённые в разных пулах хранения. Это позволяет создавать связанные клоны из одного источника на различных СХД и снижает зависимость операций развёртывания от состояния отдельного пула. 
Доступные в Basis Dynamix Enterprise диски виртуальных машин В административном портале для пулов с тонкими дисками выводятся параметры физического лимита и фактически записанного объёма с цветовой индикацией заполнения: пул подсвечивается жёлтым при заполнении от 75% и красным при 90% и выше — администратор сразу видит, где требуется вмешательство. Поддержка NVMe-over-TCPПлатформа получила поддержку протокола NVMe-over-TCP для систем хранения данных, подключённых через SEP SHARED и SEP Tatlin в режиме RDM. Этот сетевой протокол обеспечивает доступ к блочным устройствам с производительностью, близкой к локальному NVMe, при использовании стандартной Ethernet-инфраструктуры — без необходимости развёртывания отдельной фабрики Fibre Channel или специализированного оборудования RDMA. Поддержка NVMe-over-TCP расширяет совместимость Basis Dynamix Enterprise с современными СХД и даёт заказчикам возможность строить высокопроизводительные системы хранения на привычной сетевой инфраструктуре. Управление через виртуальный контроллерВ новом релизе расширен набор инструментов для администрирования и эксплуатации платформы. В частности, была добавлена возможность администрирования Basis Dynamix Enterprise при помощи виртуальных узлов управления (контроллеров). Благодаря этому пользователи могут не выделять физические узлы для управляющего слоя платформы, если её размер не превышает 40 узлов. Также появилась возможность осуществлять резервное копирование управляющего узла классическими инструментами, быстрее проводить его восстановление в случае выхода из строя за счёт хранения узла на СХД, и перемещать виртуальные машины между узлами для управления нагрузкой. Помимо этого, в Basis Dynamix Enterprise 4.6 переработаны интерфейсы создания виртуальных машин и управления зонами, упрощено развёртывание новых инсталляций, расширены сетевые возможности и обновлены сервисные компоненты платформы. «В новом релизе мы сделали ещё один заметный шаг от ручного администрирования к автоматизированному управлению инфраструктурой, независимо от её размеров и сложности. Планировщик ресурсов DRS снимает с администратора рутинную задачу балансировки нагрузки, связанные клоны и тонкие диски сокращают расход дискового пространства, а поддержка NVMe-over-TCP открывает доступ к современным архитектурам хранения без изменения сетевой инфраструктуры. Это последовательное движение к платформе, которая берёт на себя всё больше задач эксплуатации и оставляет администраторам пространство для развития сервисов», — прокомментировал Дмитрий Сорокин, технический директор компании «Базис».
03.06.2026 [09:00], Сергей Карасёв
Гибкие сетевые настройки и информационная безопасность: обновление Basis SDNКомпания «Базис», лидер российского рынка ПО управления динамической инфраструктурой, представила версию 1.2 продукта Basis SDN, первого самостоятельного российского решения для организации программно-определяемых сетей (SDN). Акцент в новом релизе сделан на информационной безопасности: обновлена логика работы правил обработки трафика, реализовано детальное журналирование на уровне бэкенда, улучшена интеграция со сторонним ПО, работающим с политиками и событиями безопасности. Basis SDN переводит управление сетевой инфраструктурой организации (сегментация, маршрутизация, коммутация и т.д.) с уровня «железа» на программный уровень, упрощая реализацию сложных сценариев работы сети. Новые инструменты для гибкой настройки сетевой инфраструктурыВ релизе Basis SDN 1.2 добавлены шаблоны наиболее популярных сервисов, включая NTP, IMAP, RDP и др., с предустановленными протоколами и портами назначения для быстрой настройки типовых правил безопасности без ручного указания параметров. Их можно объединять в группы с сервисами, созданными пользователем самостоятельно, что в результате заметно упрощает для ИБ-специалистов заказчика создание и изменение этих правил. 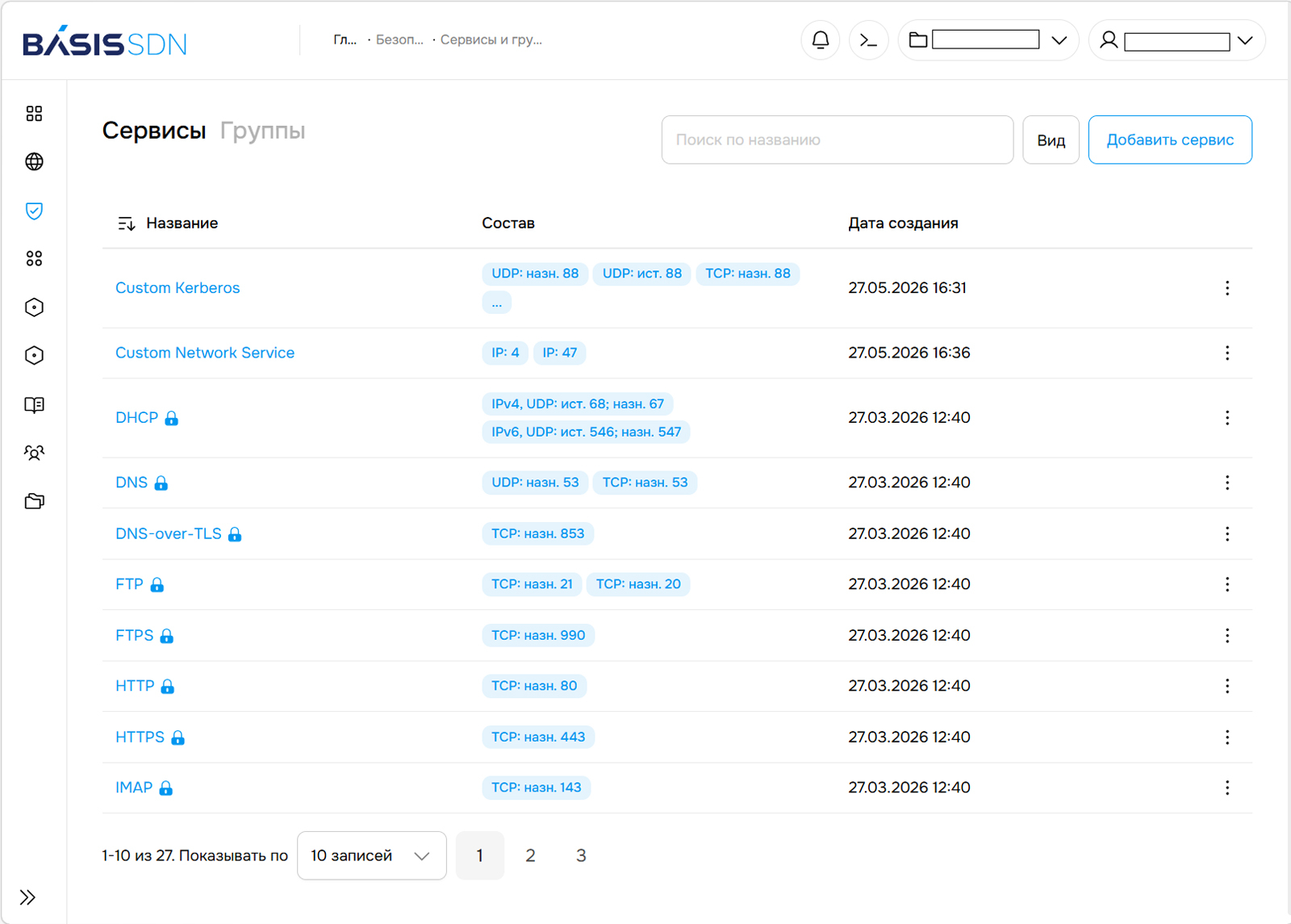
Предустановленные и пользовательские сервисы (Источник изображений: «Базис») Также в Basis SDN реализована возможность создавать сервисы не только на транспортном, но и на сетевом уровне, т. е. можно добавлять IP-протоколы в создаваемый сервис по числовому идентификатору (например, 4 — IP-in-IP, 47 — GRE, 50 — ESPP и др.). Это даёт дополнительную гибкость сетевой инфраструктуре заказчиков, поскольку они могут использовать внутри собственной сети различные специфические протоколы для решения конкретных задач, например, GRE позволяет создать виртуальный туннель для изолированной передачи IPv6-трафика внутри IPv4-сети. В релизе 1.2 появились группы безопасности — универсальные объекты, в которые можно добавлять порты, сети, адреса IPv4 и IPv6, MAC-адреса и другие компоненты инфраструктуры. Администратор Basis SDN может самостоятельно создать такой объект и затем оперировать им, например, при настройке политик безопасности. 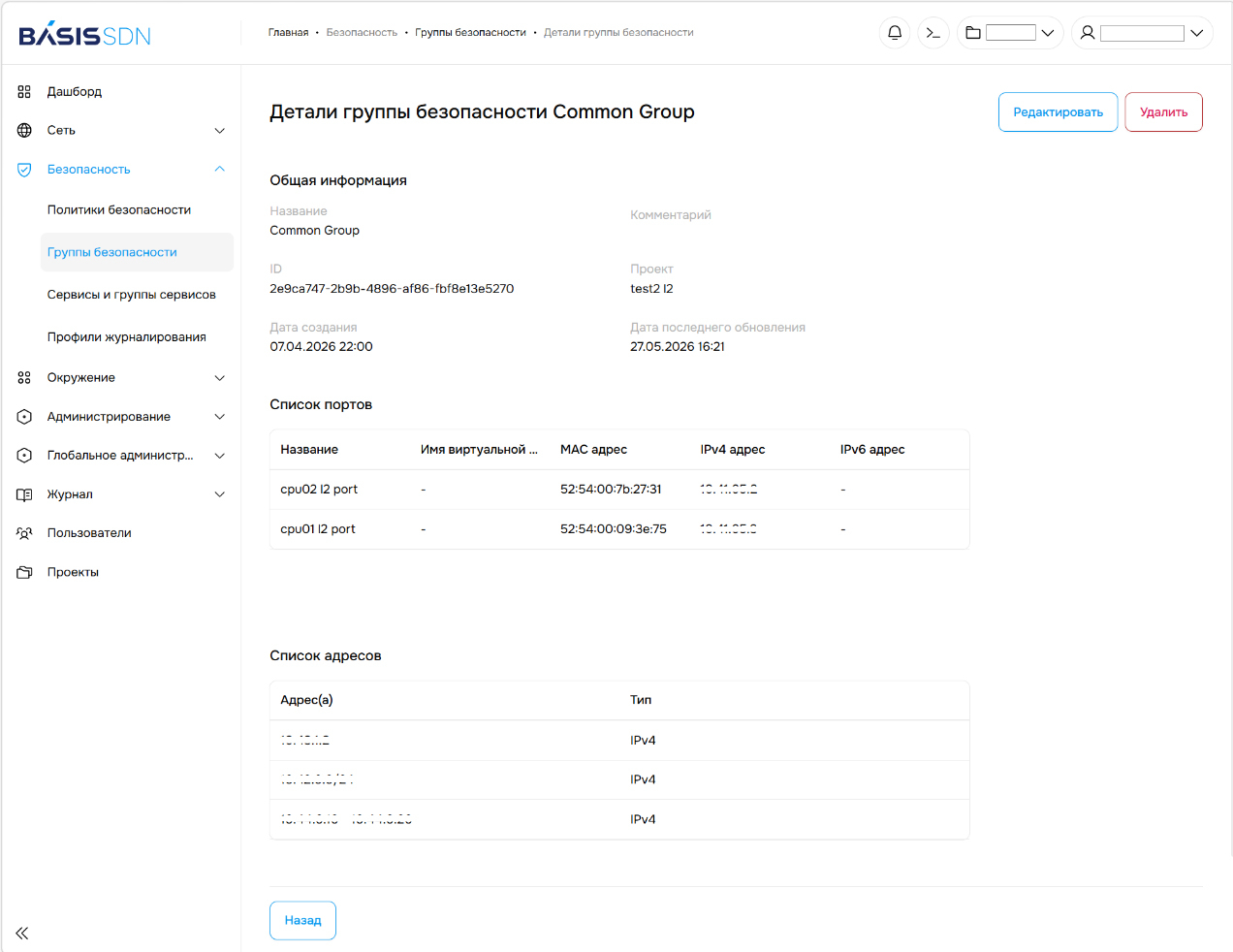
Группы безопасности Basis SDN Улучшенное журналирование событий для контроля за происходящим в сети организацииЗаписи в журнале правил безопасности обновлённого Basis SDN содержат более подробную информацию о событии: какое правило сработало, время срабатывания, тип трафика, протокол, адрес и порт источника, адрес и порт назначения, данные транспортного уровня и т. д. Эта информация упрощает для ИБ-специалистов выявление и анализ аномалий внутри сети организации. 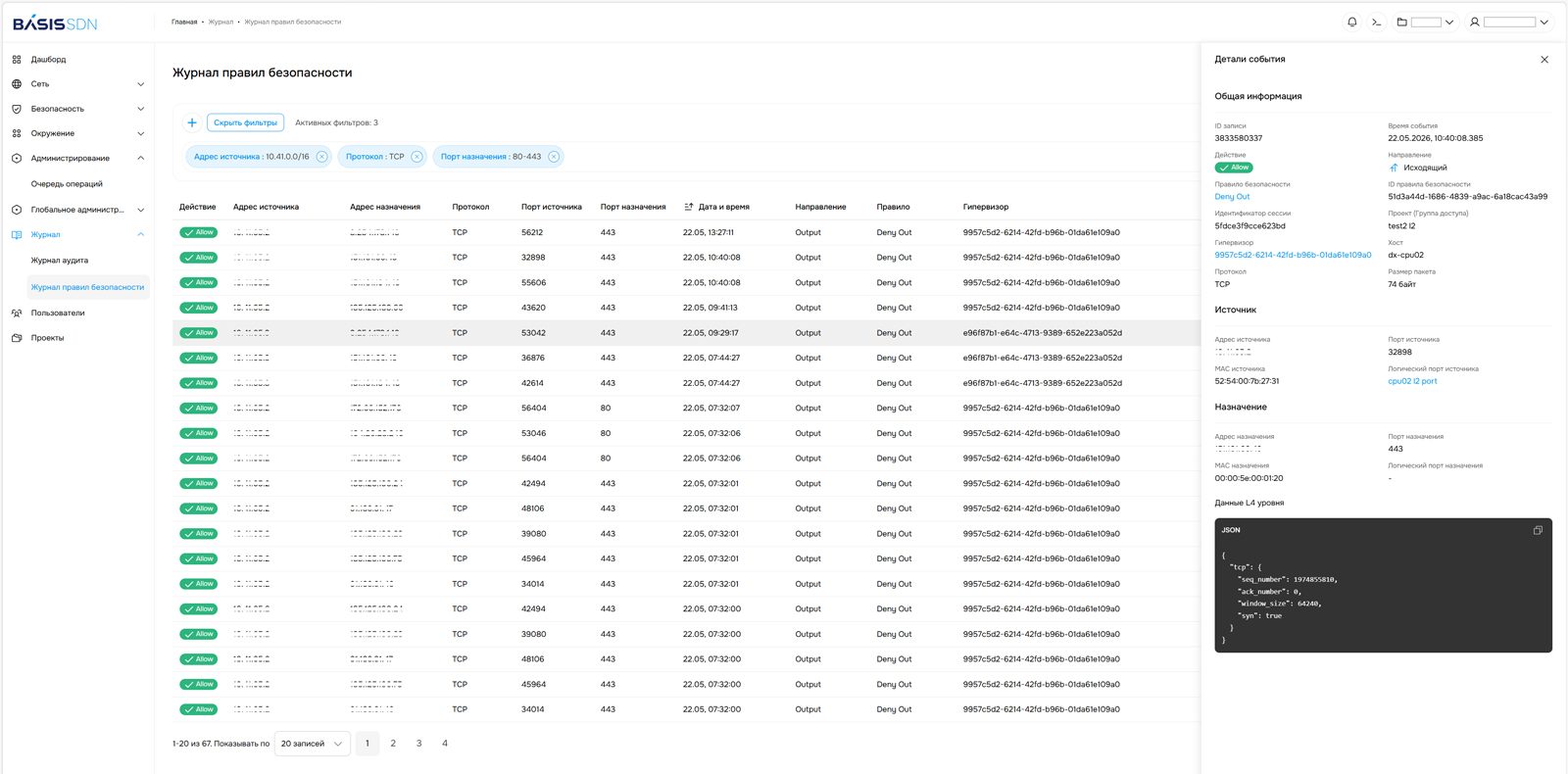
Запись в журнале правил безопасности Необходимую специалистам гибкость журналирования трафика в Basis SDN обеспечивает наличие профилей. В профиле журналирования можно управлять интенсивностью логирования трафика для новых и уже установленных сессий, а также задавать направление логирования: только входящий трафик, только исходящий, двунаправленный. Профили применяются к правилам безопасности и трафику «на лету», без перезапуска. Фильтрация записей в журнале правил безопасности Basis SDN реализована через специальный API. Такой подход позволяет специалистам искать нужные данные в журнале по их значениям, в том числе искать внутри диапазона портов, по маскам подсетей и т. д. Такой поиск намного более эффективен по сравнению с текстовым, поскольку, например, если правило действует для диапазона портов с 22 по 80, его можно найти по любому порту внутри этого диапазона, а не только по граничным значениям «22» или «80» как в текстовой форме записи. Аналогичный подход реализован для самих правил безопасности, что даёт возможность быстро находить необходимые правила и обеспечивает качественную интеграцию со сторонними решениями, работающими с сетевыми политиками безопасности (NSPM). 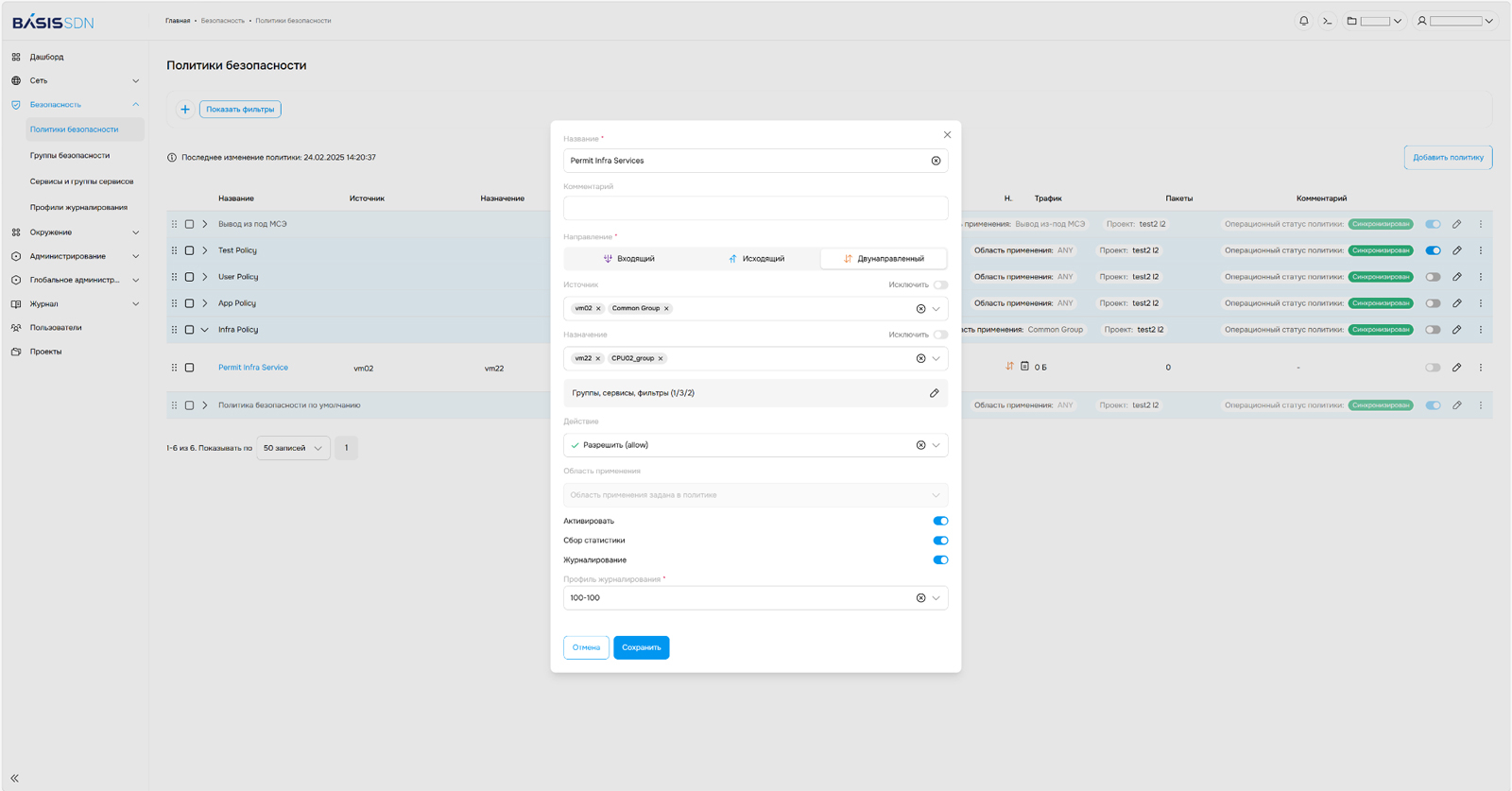
Политики и правила безопасности Для эффективного взаимодействия Basis SDN с современными решениями класса SIEM была реализована отправка событий правил безопасности на внешние серверы в формате RAW и CEF. Поддержка формата CEF избавляет ИБ-специалистов от необходимости самостоятельно размечать события, что значительно облегчает обработку данных. При необходимости специалисты заказчика могут дополнительно настроить фильтрацию передаваемых из Basis SDN данных по уровню критичности сработавшего правила. Соответствующие настройки есть как для журнала правил безопасности, так и для журнала аудита. 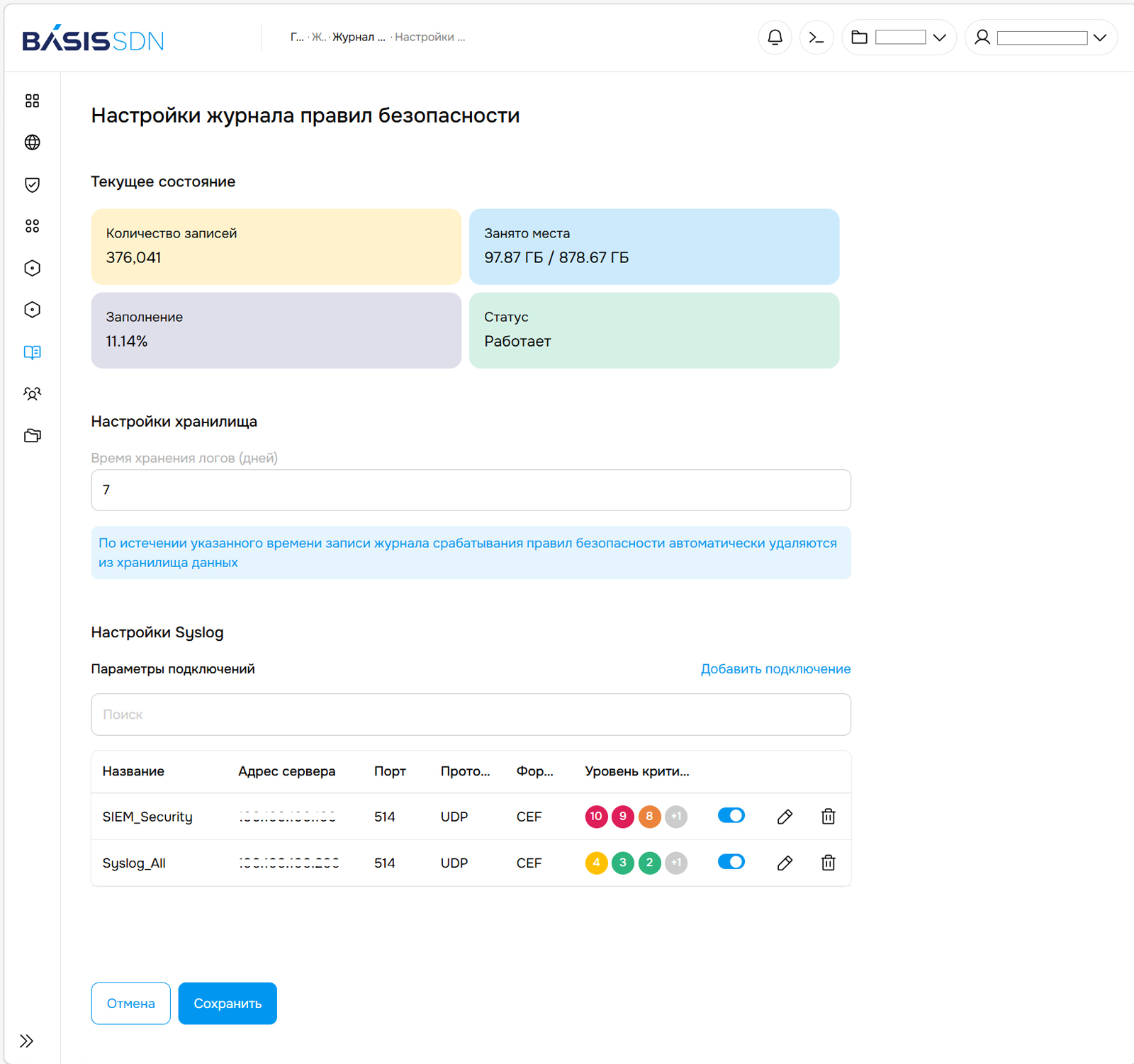
Настройки журнала правил безопасности «За год, прошедший с момента презентации Basis SDN, мы расширили функциональность решения до уровня мировых аналогов и сделали работу с ним более простой и удобной. В новом релизе мы не просто добавили ряд инструментов, а обновили логику работы Basis SDN: реализовали двунаправленные правила, создали несколько областей их применения и упорядочили наследование между этими областями. Получившаяся архитектура Basis SDN не уступает мировым аналогам и качественно опережает решения, построенные на открытом ПО», — отметил Дмитрий Сорокин, технический директор компании «Базис».
02.06.2026 [12:00], Сергей Карасёв
«Базис» реализовал нативную интеграцию с печатными устройствами «Катюша»Компания «Базис», лидер российского рынка ПО управления динамической ИТ-инфраструктурой, добавила в свою флагманскую платформу виртуализации рабочих мест Basis Workplace нативную интеграцию с многофункциональными устройствами (МФУ) российского производителя печатной техники «Катюша». Реализация проекта проходила в инфраструктуре банка ВТБ, который перевёл на решения «Базиса» более 60 тысяч сотрудников. В сотрудничестве с производителем печатного оборудования было реализовано техническое решение, обеспечивающее совместимость между протоколом TWAIN, используемым устройствами по умолчанию, и протоколом WIA 2, применяемым в виртуализированной инфраструктуре для взаимодействия через программные интерфейсы. Это позволило обеспечить трансляцию вызовов между протоколами и интеграцию сканирующих функций МФУ в контур виртуальных рабочих мест. Итоговое тестирование подтвердило корректную работу сканеров МФУ «Катюша» в Basis Workplace и их полную совместимость с виртуализированной инфраструктурой. 
Источник изображения: «Катюша» «Одним из ключевых преимуществ российских вендоров является работа в тесной связке с заказчиками и оперативная адаптация продуктов под их прикладные требования. Нативная интеграция нашей VDI-платформы с устройствами "Катюша" в инфраструктуре ВТБ является примером такого практического взаимодействия, когда запрос заказчика трансформируется в рабочий и тиражируемый результат. Подчеркну, что после реализации такую связку продуктов можно без опасений рекомендовать другим заказчикам, как уже проверенную», — прокомментировал Дмитрий Сорокин, технический директор «Базиса». «Для нас сотрудничество с "Базисом" – это не разовая интеграция, а системная работа. Когда два российских производителя — платформы виртуализации и печатной техники — эффективно взаимодействуют в работе с протоколами, выигрывает прежде всего заказчик. Он получает готовую, проверенную связку, где не надо ничего "допиливать" своими силами. Банк ВТБ уже оценил это на практике. Уверены, что наш опыт будет востребован и другими компаниями, которые строят собственные VDI-инфраструктуры на российском стеке», — отметил генеральный директор компании «Катюша» Максим Виноградов. «Для нас как для заказчика важно, чтобы сотрудники банка работали с удобным и надёжным инструментом, не уступающим иностранным аналогам. Проведённое тестирование подтвердило нативное взаимодействие МФУ "Катюша" с Basis Workplace, в том числе корректную работу функций сканирования в инфраструктуре виртуальных рабочих мест. Данная связка продуктов российских вендоров может успешно применяться в масштабной корпоративной инфраструктуре», — прокомментировал заместитель руководителя департамента развития инфраструктуры, вице-президент ВТБ Николай Шуткин.
28.05.2026 [09:00], Сергей Карасёв
«Базис» представляет Basis Workplace 3.3 с собственным протоколом доставки Basis Connect и интеграцией с Basis SDNКомпания «Базис», лидер российского рынка ПО для управления динамической инфраструктурой, выпустила обновление платформы для управления инфраструктурой виртуальных рабочих столов (VDI) — Basis Workplace 3.3. Главным событием релиза стала нативная интеграция протокола передачи данных Basis Connect, разработанного «Базис» для расширения возможностей VDI-платформы и упрощения её развёртывания. Помимо этого в версии 3.3 появились новые возможности для работы в крупных и территориально распределённых инсталляциях, добавлена поддержка программно-определяемых сетей Basis SDN при работе с Basis Dynamix Enterprise, а также реализован ряд улучшений в области администрирования, безопасности и интеграции с корпоративными системами. Собственный протокол доставкиКлючевым нововведением Basis Workplace 3.3 стала интеграция Basis Connect — собственного протокола передачи данных между клиентом и виртуальным рабочим местом. При этом «Базис» сохраняет поддержку сторонних протоколов доставки, среди которых RX и Loudplay — это одно из востребованных у заказчиков преимуществ платформы. Качество и скорость обмена данными напрямую определяют уровень комфорта пользователя при работе в виртуальной среде: сможет ли он использовать ресурсоёмкие приложения, периферийные устройства и участвовать в видеоконференциях без потерь качества. Для обеспечения необходимого уровня комфорта могут использоваться проприетарные протоколы, требующие отдельных лицензий, либо open-source протоколы, нуждающиеся в доработке и поддержке. Наличие собственного протокола передачи данных в составе Basis Workplace позволяет избежать зависимости от сторонних решений, упростить внедрение платформы и обеспечить заказчикам более предсказуемую эксплуатацию. 
Настройки протокола Basis Connect (Источник изображений: «Базис») В первой публичной версии Basis Connect реализована передача изображения и звука, работа с буфером обмена (текст, файлы, папки, изображения), поддержка клавиатуры, мыши, принтеров, сканеров и других периферийных устройств, включая USB-токены для использования сертификатов внутри виртуального рабочего места. Нативная интеграция с Basis SDNВ новой версии продолжается развитие модульной архитектуры драйверов, которая в Basis Workplace 3.2 обеспечила нативное подключение к Basis Dynamix Enterprise и OpenStack. Теперь платформа виртуализации на основе Basis Dynamix Enterprise может работать в связке с Basis SDN — решением, отвечающим в экосистеме «Базиса» за управление сетевой инфраструктурой. Это позволяет заказчикам построить полностью отечественный стек инфраструктуры виртуальных рабочих мест на продуктах «Базис»: от серверной виртуализации и управления сетью до VDI-платформы. Усиленная отказоустойчивость крупных инсталляцийВ Basis Workplace 3.3 была реализована возможность установки резервного бэкенда: при неисправности основного, система автоматически переключается на резервный, обеспечивая непрерывность работы. Добавлена балансировка нагрузки на брокеров через механизм Global Server Load Balancing (GSLB). Появилась возможность задавать в параметрах службы каталогов сразу несколько IP-адресов и портов: при недоступности одного из них система переключается на следующий по списку, что исключает зависимость от единственного контроллера домена. 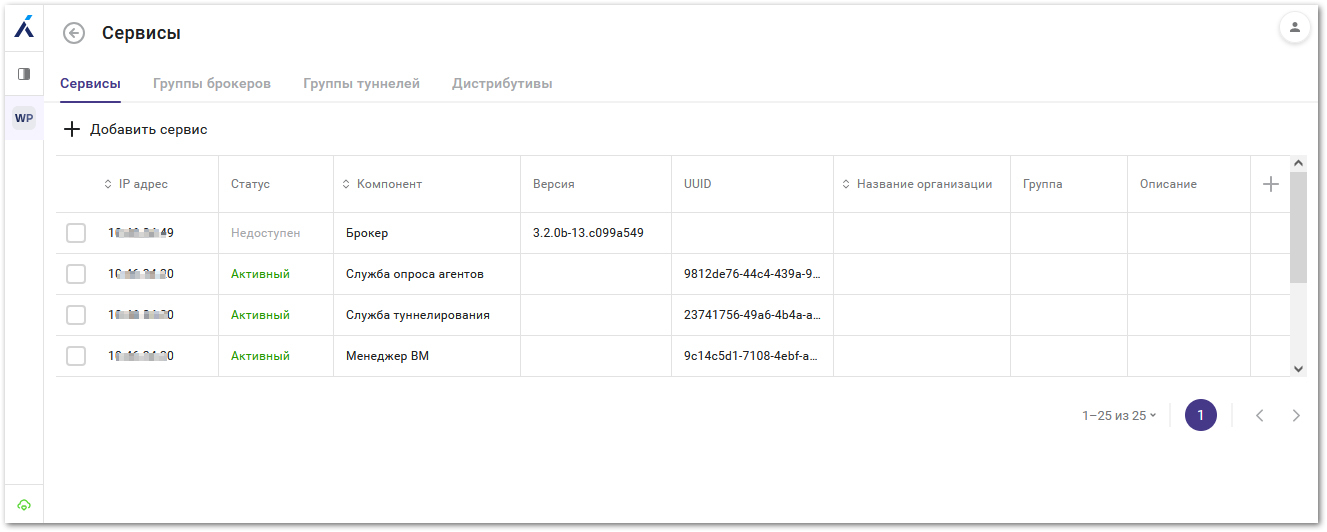
Управление сервисами и брокерами Развитие получила и реализация геораспределённой VDI. Теперь каждая площадка такой конфигурации имеет собственный сертификат для безопасного доступа, а ключи площадок генерируются непосредственно в списке площадок — это упрощает процедуру их подключения и обеспечивает изоляцию доверия между ЦОД. Дополнительный механизм надёжности — возможность отката на предыдущую версию сервиса. Если после обновления возникают непредвиденные проблемы, администратор может вернуться к работоспособной версии без сложных операций восстановления. Новые инструменты администрированияВ Basis Workplace 3.3 был расширен набор средств управления и мониторинга платформы. Появились новые инструменты для визуализации текущего состояния системы и анализа исторических данных о работе виртуальных машин, в результате администраторы получили более полную картину происходящего в инфраструктуре. Также была ускорена повседневная работа — ряд операций теперь можно выполнять над несколькими пулами и виртуальными машинами одновременно, а часть задач по управлению инфраструктурой переведена в панель управления. Дополнительно, были расширены возможности аудита: по основным сценариям работы пользователей и администраторов теперь можно формировать отчёты за произвольный период. 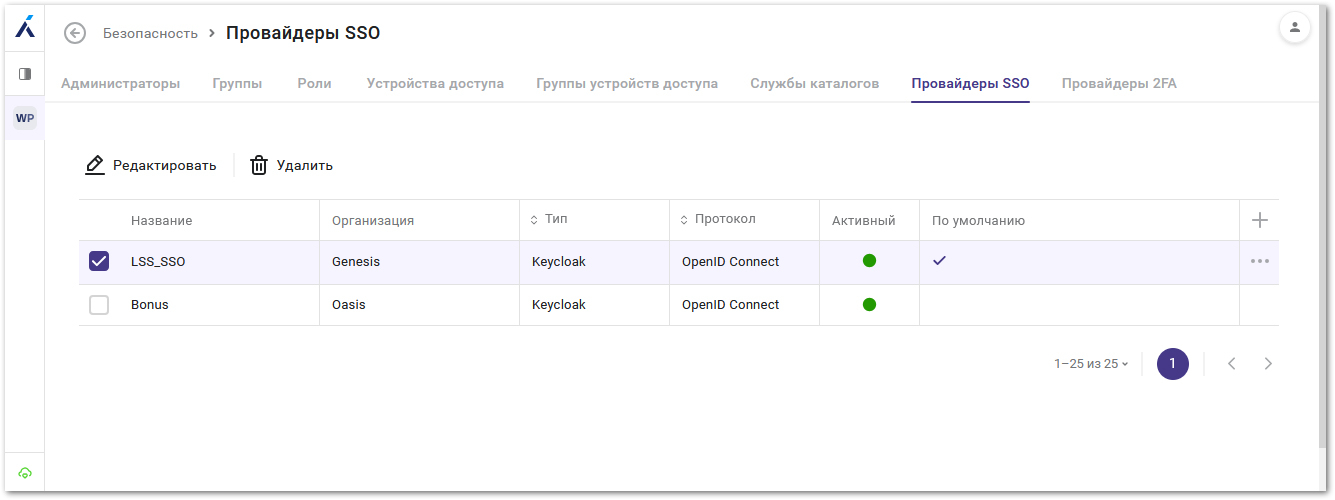
Список SSO-провайдеров В версии 3.3 расширен список поддерживаемых служб каталогов и провайдеров аутентификации, а также добавлены инструменты для интеграции с корпоративным контуром информационной безопасности. В результате повысилось удобство управления подключениями, улучшился контроль доступа администраторов и пользователей. «При создании Basis Connect мы ориентировались на запросы заказчиков на нативный протокол передачи данных в составе Basis Workplace. Он позволяет обеспечивать высокое качество работы в виртуальной среде, не требует отдельных лицензий на проприетарные протоколы и упрощает эксплуатацию платформы. Что касается интеграции с Basis SDN, то здесь мы считаем принципиально важным, чтобы возможности нашего программно-определяемого решения были доступны в других продуктах экосистемы. Для заказчиков это означает более удобное управление сетевой частью виртуальной инфраструктуры, более быстрое развёртывание рабочих мест и более высокий уровень контроля над безопасностью и сегментацией среды», — прокомментировал Дмитрий Сорокин, технический директор компании «Базис».
26.05.2026 [09:00], Сергей Карасёв
Гибкие настройки безопасности и новые инструменты для работы с шаблонами — «Базис» обновил конструктор Basis Automation Studio до версии 2.4Компания «Базис», лидер российского рынка ПО управления динамической инфраструктурой, представила версию 2.4 конструктора платформенных сервисов Basis Automation Studio — модуля, входящего в расширенную версию облачной платформы Basis Dynamix Cloud Control. Свежий релиз предлагает интеграцию со средством защиты виртуализации Basis Virtual Security, гибкую ролевую модель и поддержку работы с внешними системами версионирования через веб-портал. Basis Automation Studio представляет собой среду автоматизации развёртывания сервисов с инструментами визуального проектирования виртуальной инфраструктуры на основе готовых компонентов и связей между ними. В состав конструктора входит расширяемый каталог шаблонов виртуальных инфраструктур и платформенных сервисов, а также расширяемая библиотека компонентов с образцами популярного ПО — ClickHouse, Consul, Docker, MariaDB, PostgreSQL и других. Алгоритм развёртывания построен на архитектуре TOSCA с использованием языков YAML, Ansible, Python и Bash. Управление правами и доступомОдной из ключевых доработок релиза стала интеграция конструктора с решением защиты Basis Virtual Security. Конструктор использует Basis Virtual Security в качестве единого провайдера идентификации, что даёт администраторам возможность централизованно управлять учётными записями и правами доступа пользователей, а также обеспечивает поддержку технологии единого входа (Single Sign-On, SSO). В результате можно централизованно применять политики безопасности, что снижает нагрузку на администраторов, а пользователей платформы избавляет от необходимости вводить учётные данные при переходе между компонентами экосистемы «Базиса». 
Источник изображений: «Базис» В Basis Automation Studio 2.4 — в дополнение к имеющейся ролевой модели — была представлена её расширенная версия, которая позволяет тонко настраивать права доступа пользователей: администратор может собирать собственные роли из атомарных разрешений и назначать их в нужном объёме конкретным пользователям. Миграция на новую модель уже выполнена на уровне архитектуры конструктора. Интеграция с внешними Git-репозиториямиВ новой версии Basis Automation Studio появилась возможность загружать компоненты и шаблоны сервисов из Git-репозиториев. Загрузка и обновление компонентов и шаблонов сервисов осуществляется, используя графический интерфейс, по выбранному Git-тегу с возможностью пакетной загрузки. Поддерживаются разные способы аутентификации (пароль, токен). Загруженный компонент шаблон сервиса поддерживает версионирование (с возможностью обновления «вперед и назад»).  Тем самым продолжается развитие веб-портала как единой точки работы с конструктором. Ранее в портал были добавлены инструменты создания и редактирования компонентов и шаблонов. В новой версии конструктора добавилась интеграция с внешними Git-репозиториями. Это позволяет встроить разработку TOSCA-шаблонов в привычные для команд процессы работы с исходным кодом, обеспечить отслеживаемость изменений и упростить совместную работу над каталогом сервисов. В новом релизе также была добавлена оценка ресурсов для развёрнутых сервисов. Это позволяет пользователям анализировать ресурсные требования сервисов и точнее планировать их эксплуатацию. «Ключевая задача, которую Basis Automation Studio решает для бизнеса — упрощение процесса развёртывания ИТ-систем и сервисов внутри виртуального ЦОД. Поэтому мы развиваем продукт сразу в нескольких направлениях, связанных с решением этой задачи. В частности, мы уже реализовали централизацию управления доступом через интеграцию с другим нашим продуктом, Basis Virtual Security, а также более гибкое разграничение прав пользователей и включение конструктора в стандартные процессы разработки через поддержку Git в веб-портале», — отметил Дмитрий Сорокин, технический директор компании «Базис».
21.05.2026 [23:43], Владимир Мироненко
Без техподдержки, апдейтов и прав: почти треть крупного российского бизнеса использует зарубежное ПО
software
виртуализация
импортозамещение
информационная безопасность
исследование
лицензия
облако
почта
резервное копирование
россия
телеметрия
техподдержка
цкит
Согласно исследованию аналитического центра АНО «ЦКИТ» «Ландшафт российского рынка прикладного программного обеспечения и его сопоставление с мировым рынком и общими тенденциями (2019–2026)», отчёты об устойчивом росте российского рынка прикладного ПО во всех ключевых сегментах скрывают реальное положение и эксплуатационную «серую зону». Согласно приведённым данным, в 2025 году российский рынок облачных платформ (IaaS+PaaS) вырос с 28 млрд руб. в 2019 году до 235 млрд руб., рынок систем виртуализации — с 10,7 млрд руб. в 2021 году до 19,4 млрд руб., рынок корпоративной почты — с 5,5 млрд руб. в 2021 году до 6,98 млрд руб. В облачном сегменте доля иностранных провайдеров не превышает 1 % легальных продаж при общем объёме рынка в 416,5 млрд руб. (оценка iKS-Consulting); в виртуализации на российские продукты приходится 80 % новых продаж; в системах резервного копирования доля отечественных решений превышает 70 %; в новых продажах почтовых систем доля отечественных систем выросла с 10 % в 2021 году до 58 % в 2025 году. Если же копнуть глубже, выясняется, что многие крупные компании, в том числе из числа системообразующих, продолжают использовать иностранное ПО, приобретённое до 2022 года. По данным ЦКИТ, расходы крупнейших потребителей в 2022–2025 гг. фактически не выросли, поскольку они по-прежнему используют оплаченные лицензии с истёкшим сроком поддержки. В сегменте резервного копирования Veeam до 2022 года занимал более 50 % российского рынка, а сейчас около 30 % крупных компаний продолжают эксплуатировать его без поддержки, так как личные кабинеты заблокированы с марта 2024 года. Виртуализация VMware до 2022 года использовалась на ~80 % корпоративных серверов страны — сейчас её около 39 %, а это десятки тысяч серверов, причём без обновлений, поскольку новые лицензии недоступны. 
Источник изображения: Surface / Unsplash Наиболее плачевно обстоят дела в сегменте корпоративных почтовых систем. Около половины компаний по-прежнему используют Microsoft Exchange или Microsoft 365 без продления лицензий, технической поддержки и обновлений безопасности. До 2022 года Microsoft занимала 70–80 % российского рынка корпоративной почты. В 2025 году её доля снизилась примерно до 50 %, хотя эти цифры отражают лишь новые продажи в пользу отечественных решений — в действительности инсталляционная база Microsoft в B2B остаётся массивной и продолжает работать без актуальных патчей, утверждают исследователи. Помимо того, что речь идёт о нарушении законодательства, те же почтовые серверы без патчей — первоочередная цель для атак. По данным Positive Technologies, в 2023 году на Microsoft Exchange пришлось 50 % всех расследованных атак на публично доступные приложения в России, а 92 % вредоносной доставки осуществляется именно посредством email. По данным ФСТЭК, только одна уязвимость в Exchange затронула около 77 тыс. российских серверов. Как сообщают в BI.ZONE, 68 % целевых атак начинаются с почты. При этом корпоративные адреса сотрудников 94 из 100 крупнейших российских компаний можно найти в публичных утечках. Ещё один фактор риска — телеметрия: механизмы передачи диагностических данных Microsoft (MS Diagnostic Data) продолжают бесконтрольно направлять сведения за рубеж. 
Источник изображения: Surface / Unsplash Также существует риск удалённого отключения инфраструктуры, что наряду с несовместимостью с российскими ОС, деградацией SLA и утратой внутренних компетенций по обслуживанию устаревающих систем делают корпоративную почту точкой потенциального операционного коллапса. К тому же серый импорт лицензий и компонентов несёт дополнительные издержки, поскольку обходится на 30–100 % дороже официальных предложений. Следует добавить, что публичный инцидент, связанный с компрометацией почтовой инфраструктуры на объекте КИИ, грозит компании большими репутационными потерями. ЦКИТ систематизировал риски продолжения эксплуатации западного ПО по шести категориям. Три из них (технологические, кибербезопасность и юридико-регуляторные) отнесены к критическим. Операционные, экономические и репутационно-финансовые риски оцениваются как высокие. Исследователи отметили, что российский рынок корпоративной почты, систем резервного копирования, виртуализации и облачных платформ предлагает зрелые продукты, уже прошедшие испытания в крупных корпоративных средах. Плановый переход на них позволит пройти процедуры сертификации без спешки, обеспечить обучение персонала и сохранить непрерывность бизнес-процессов, устранив риски работы в серой зоне.
20.05.2026 [11:10], Сергей Карасёв
Базис, СберТех и Гистех создадут конвейер безопасной разработки для ГосТехаРазработчик высокотехнологичного ПО для бизнеса СберТех, крупнейший российский разработчик решений для управления динамической ИТ-инфраструктурой Базис и ИТ-компания Гистех объявили о старте технологического сотрудничества. Компании займутся созданием единого конвейера безопасной разработки для платформы ГосТех, объединив компетенции всех участников соглашения. Меморандум подписан в рамках конференции ЦИПР. В основе архитектуры CI/CD-контур — автоматизированный инструмент для непрерывной интеграции и доставки кода. В нём госсистемы создаются и развиваются с учётом требований безопасности, совместимости и управляемости. СберТех, Базис и Гистех реализуют поэтапное сотрудничество. Стороны согласуют целевое видение продукта, сформируют дорожные карты и создадут совместные рабочие группы для координации деятельности. Далее последует анализ совместимости всех технических решений, определение архитектуры конвейера и вариантов интеграции отдельных его элементов. Партнёры обменяются экспертизой, предоставят доступ к документации, проведут совместные технические сессии, а также обеспечат внедрение и развитие экосистемы вокруг нового решения. 
Источник изображения: ГосТех Максим Тятюшев, генеральный директор СберТеха: «В результате нашего сотрудничества появится среда, в которой команды смогут работать быстрее, эффективнее и с меньшим числом ошибок. Мы надеемся, что опыт и экспертиза СберТеха поможет в этом — компания долгие годы создаёт востребованные продукты для разработчиков, такие как GitVerse. Платформой уже пользуется более 200 тыс. человек, она эволюционировала от решения для небольших команд до корпоративного продукта, которому доверяют крупные организации». Давид Мартиросов, генеральный директор Базиса: «Государственным заказчикам требуется функциональная и управляемая среда разработки с полным контролем над технологическим стеком. Объединив инфраструктурную основу «Базиса», инструменты и операционную экспертизу партнёров, мы получим отечественное решение, которое будет закрывать этот запрос целиком — от технологического фундамента до поддержки в продуктиве». Алексей Стержантов, генеральный директор Гистеха: «Архитектура для госплатформ должна работать в реальных эксплуатационных условиях, а не только в теории. Мы строим продукт, который будет развиваться вместе с потребностями сектора и даст командам практический инструмент для зрелой, управляемой разработки — с соблюдением регламентов заказчика и требований безопасности». |
|

