Материалы по тегу: pc
|
15.04.2021 [01:31], Владимир Мироненко
TSMC остановит выпуск Arm-процессоров Phytium — судьба китайского экзафлопсного суперкомпьютера Tianhe-3 под вопросомТайваньская компания Taiwan Semiconductor Manufacturing Company (TSMC) приостановила поставку чипов по новым заказам китайской компании Phytium, которая на прошлой неделе была добавлена властями США в «чёрный» список Министерства торговли. Внесение компаний в этот перечень означает запрет для американских компаний на работу с ними и предоставление продуктов или услуг без получения соответствующих лицензий. Иностранные компании, такие как TSMC, теоретически могут продолжать работать с компаниями из «чёрного списка», но США могут оказывать на них давление через их американских поставщиков. Например, когда США занесли Huawei в «чёрный» список, TSMC была вынуждена отказаться от сотрудничества с ней, поскольку многие ключевые технологии, лежащие в основе её производственных процессов, были разработаны американскими фирмами. Пока неясно, оказывалось ли сейчас подобное давление на TSMC, и были ли ею прекращены поставки остальным шести суперкомпьютерным китайским фирмам из «чёрного» списка. Как сообщает South China Morning Post, TSMC выполнит заказы, размещённые Phytium до внесения в «чёрный список», но больше поставлять ей чипы не будет. 
Прототип Tianhe-3. Фото: Xinhua Предполагается, что Phytium стоит за развёртыванием систем высокопроизводительных вычислений для китайского военно-промышленного комплекса, использующего её разработки при создании гиперзвуковых ракет. Компания сотрудничает с Оборонным научно-техническим университетом Народно-освободительной армии Китая (NUDT), который ранее создал суперкомпьютеры Tianhe-1 и Tianhe-2, в своё время занимавшие первые строчки рейтинга TOP500. Tianhe-3, один из трёх проектов китайских суперкомпьютеров экзафлопсного класса, должен был быть закончен в прошлом году, однако осенью было объявлено, что из-за пандемии коронавируса сроки сдвигаются. Летом 2020 года в распоряжении исследователей уже был прототип новой машины, имевший теоретическую производительность 3,146 Пфлопс. Он включал 512 плат с тремя процессорами Phytium MT2000+ и 128 плат с четырьмя Phytium FT2000+. Точные параметры этих 7-нм Arm-чипов не приводятся, но в одной из свежих научных публикаций упоминается, что на каждый 64-ядерный FT2000+ в прототипе Tianhe-3 приходилось 64 Гбайт RAM. А каждый MT2000+ можно поделить на четыре NUMA-узла с 32 ядрами и 16 Гбайт RAM, то есть, судя по описанию, это 128-ядерный чип, о котором ранее ничего не было известно. Теперь же судьба этих CPU и суперкомпьютера Tianhe-3 и вовсе под вопросом.
12.04.2021 [19:26], Игорь Осколков
NVIDIA анонсировала серверные Arm-процессоры Grace и будущие суперкомпьютеры на их базеВ рамках GTC’21 NVIDIA анонсировала Arm-процессоры Grace серверного класса, которые станут компаньонами будущих ускорителей компании. Это не означает полный отказ от x86-64, но это позволит компании предложить клиентам более глубоко оптимизированные, а, значит, и более быстрые решения. NVIDIA говорит, что новый CPU позволит на порядок повысить производительность систем на его основе в ИИ и HPC-задачах в сравнении с современными решениями. Процессор назван в честь Грейс Хоппер (Grace Hopper), одного из пионеров информатики и создательницы целого ряда основополагающих концепций и инструментов программирования. И это имя нам уже встречалось в контексте NVIDIA — в конце 2019 года компания зарегистрировала торговую марку Hopper для MCM-решений.  Компания не готова раскрыть полные технически характеристики новинки, которая станет доступна в начале 2023 года, но приводит некоторые интересные детали. В частности, процессор будет использовать Arm-ядра Neoverse следующего поколения (надо полагать, уже на базе ARMv9), которые позволят получить в SPECrate2017_int_base результат выше 300. Для сравнения — система с парой современных AMD EPYC 7763 в том же бенчмарке показывает результат на уровне 800. Вторая особенность Grace — использование памяти LPDRR5X (с ECC, естественно). В сравнении с DDR4 она будет иметь вдвое большую пропускную способность (ПСП) и в 10 раз меньшее энергопотребление. Число и скорость каналов памяти не уточняются, но говорится о суммарной ПСП в более чем 500 Гбайт/с на процессор. А у того же EPYC 7763 теоретический пик ПСП чуть больше 200 Гбайт/с. Очевидно, что другие процессоры к моменту выхода NVIDIA Grace тоже увеличат и производительность, и пропускную способность памяти. Гораздо более интересный вопрос, сколько линий PCIe 5.0 они смогут предложить. Если допустить, что у них будет 128 линий, то общая скорость для них составит чуть больше 500 Гбайт/с. 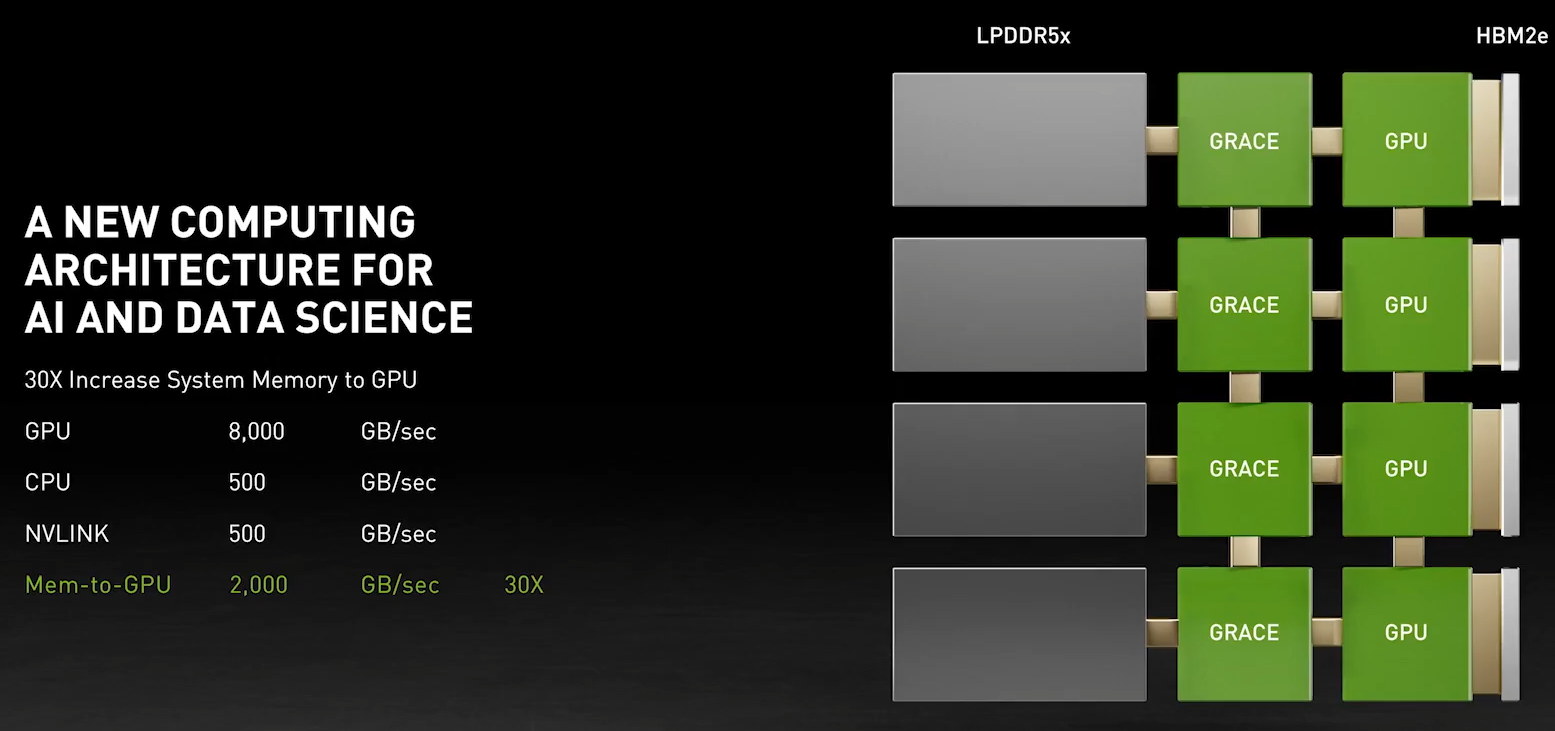 И NVIDIA этого мало — процессоры Grace получат прямое, кеш-когерентное подключение к GPU по NVLInk 4.0 (14x) с суммарной пропускной способностью боле 900 Гбайт/с. GPU тоже, как и прежде, будут общаться напрямую друг с другом по NVLink. Скорость связи между двумя CPU превысит 600 Гбайт/с, а в сборке из четырёх модулей CPU+GPU суммарная скорость обмена данными между системной памятью процессоров и GPU в такой mesh-сети составит 2 Тбайт/с. Но самое интересное тут то, что у памяти CPU (LPDDR5X) и GPU (HBM2e) в такой системе будет единое адресное пространство. Собственно говоря, таким образом компания решает давно назревшую проблему дисбаланса между скоростью обмена данными и доступным объёмом памяти в различных частях вычислительного комплекса. Для сравнения можно посмотреть на архитектуру нынешних DGX A100 или HGX. У каждого ускорителя A100 есть 40 или 80 Гбайт набортной памяти HBM2e (1555 или 2039 Гбайт/с соответственно) и NVLInk-подключение на 600 Гбайт/c, которое идёт к коммутатору NVSwitch, имеющего суммарную пропускную способность 1,8 Тбайт/с. Всего таких коммутаторов шесть, а объединяют они восемь ускорителей. Внутри этой NVLInk-фабрики сохраняется достаточно высокая скорость обмена данными, но как только мы выходим за её пределы, ситуация меняется. 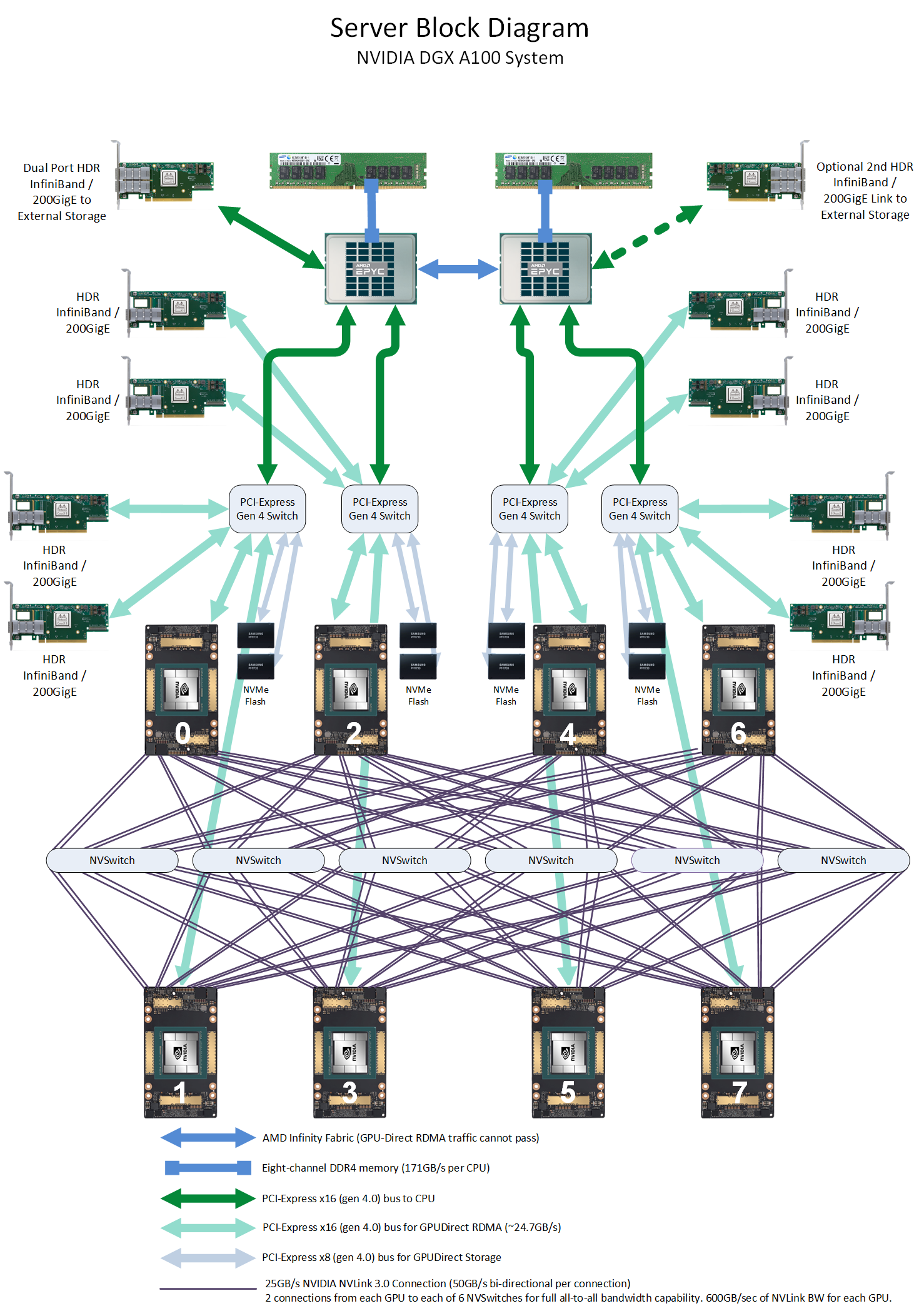
Схема NVIDIA DGX A100. Источник: Microway Каждый ускоритель A100 имеет второй интерфейс — PCIe 4.0 x16 (64 Гбайт/с), который уходит к PCIe-коммутатору, каковых в DGX A100 имеется четыре. Коммутаторы, в свою очередь, объединяют между собой сетевые 200GbE-адаптеры (суммарно в дуплексе до 1,6 Тбайт/с для связи с другими DGX A100), NVMe-накопители и CPU. У каждого CPU может быть довольно много памяти (от 512 Гбайт), но её скорость ограничена упомянутыми выше 200 Гбайт/c.  Узким местом во всей этой схеме является как раз PCIe, поэтому переход исключительно на NVLInk позволит NVIDIA получить большой объём памяти при сохранении приемлемой ПСП, не тратясь лишний раз на дорогую локальную HBM2e у каждого GPU. Впрочем, если компания не переведёт на NVLink и собственные будущие DPU Bluefield-3 (400GbE), которые будут скармливать связке CPU+GPU по, например, GPUDirect Storage данные из внешних NVMe-oF хранилищ и объединять узлы DGX POD, то PCIe 5.0 в составе Grace стоит ждать. Это опять-таки упростит и повысит эффективность масштабирования.  В целом, всё это необходимо из-за быстрого роста объёма ИИ-моделей — в GPT-3 уже 175 млрд параметров, а в течение пары лет можно ожидать модели уже с 0,5-1 трлн параметров. Им потребуются не только новые решения для обучения, но и для инференса. То же касается и физических расчётов — модели становятся всё больше и требовательнее + ИИ здесь тоже активно внедряется. Параллельно с разработкой Grace NVIDIA развивает программную экосистему вокруг Arm и своих решений, готовя почву для будущих систем на их основе.  Одной из такой систем станет суперкомпьютер Alps в Швейцарском национальном компьютерном центре (Swiss National Computing Centre, CSCS), который придёт на смену Piz Daint (12 место в нынешнем рейтинге TOP500). Этот суперкомпьютер серии HPE Cray EX, в частности, сможет в семь раз быстрее обучить модель GPT-3, чем машина NVIDIA Selene (5 место в TOP500). Впрочем, на нём будут выполняться и классические HPC-задачи в области метеорологии, физики, химии, биологии, экономики и так далее. Ввод в эксплуатацию намечен на 2023 год. Тогда же в США появится аналогичная машина от HPE в Лос-Аламосской национальной лаборатории (LANL). Она дополнит систему Crossroads, использующую исключительно процессоры Intel Xeon Sapphire Rapids.
21.12.2020 [18:41], Алексей Степин
128-ядерные супепроцессоры Tachyum Prodigy стали на шаг ближе к реальностиЛетом уходящего года компания Tachyum объявила о том, что собирается отправить Xeon «на свалку истории». Сделать это должен 128-ядерный процессор нового поколения Prodigy. Хотя массово он пока не производится, компания продолжает активно работать над проектом и совсем недавно объявила начало предзаказов на эмуляторы нового процессора, как программные, так и базирующиеся на ПЛИС. Также она продемонстрировала рабочий UEFI для будущих CPU. 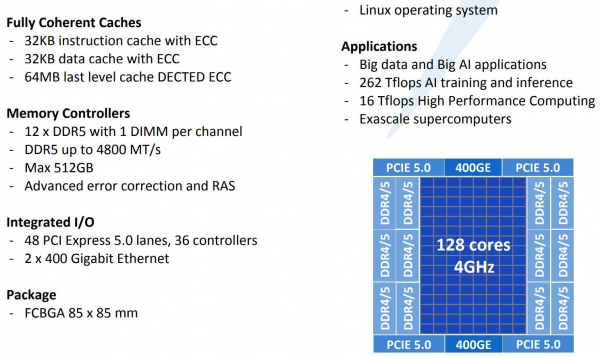 Молодая словацкая компания замахнулась на многое. Её процессор должен получить до 128 ядер, работающих на частоте до 4 ГГц. Чтобы «накормить» его данными, предусмотрен 12-канальный контроллер памяти DDR5. С периферией Prodigy будет общаться посредством 48 линий PCIe 5.0, но также получит и два контроллера Ethernet класса 400G. Характеристики весьма впечатляют.  Разработчики заявляют, что Prodigy найдёт своё место в системах класса Big Data и мощных системах машинного обучения. Если верить Tachyum, производительность разрабатываемого процессора должна достигнуть 16 и 8 Тфлопс на классичесих вычислениях FP32/FP64. В режиме машинного обучения и инференса возможности новой архитектуры выглядят ещё внушительнее, поскольку речь идёт о цифре 262 Тфлопс. 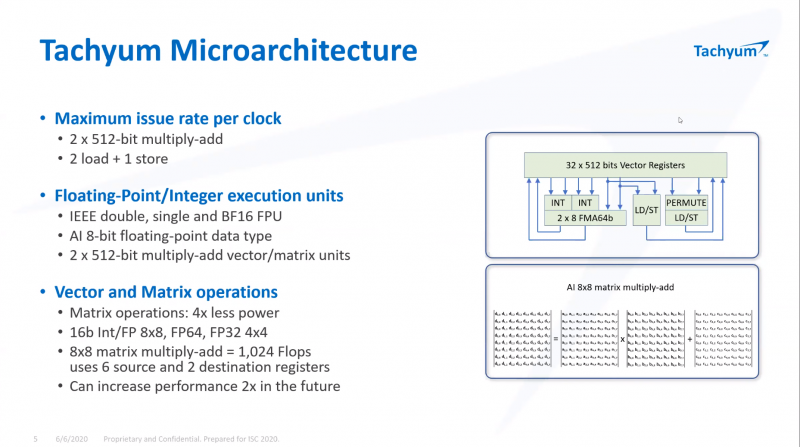 Столь громкие анонсы в истории вычислительной техники часто заканчивались «на бумаге», но Tachyum действительно работает над реализацией Prodigy. Как это обычно бывает, новая процессорная архитектура отрабатывается разработчиками с помощью эмуляции — как чисто программной, так и базирующейся на мощных ПЛИС. Это позволяет понять возможности и особенности поведения архитектуры, пусть и работающей с меньшей производительностью.  В начале декабря Tachyum объявила об открытии предзаказов на ПЛИС-эмулятор Prodigy, позволяющий начать разработку программного обеспечения для будущих систем на базе нового процессора уже сейчас. Поставки должны начаться в первом квартале 2021 года. В середине месяца Tachyum анонсировала и возможность заказа программного эмулятора Prodigy. Главная ценность такого эмулятора — более низкая стоимость в сравнении с вариантом на базе ПЛИС. Любой процессор неработоспособен без сопутствующего системного программного обеспечения — BIOS или, что сейчас встречается намного чаще, UEFI. В начале месяца Tachyum объявила о том, что передаст OEM и ODM-партнёрам UEFI, разработанное для новой архитектуры. При этом ПО будет поставляться не только в бинарном виде, разработчики получат и исходные коды. 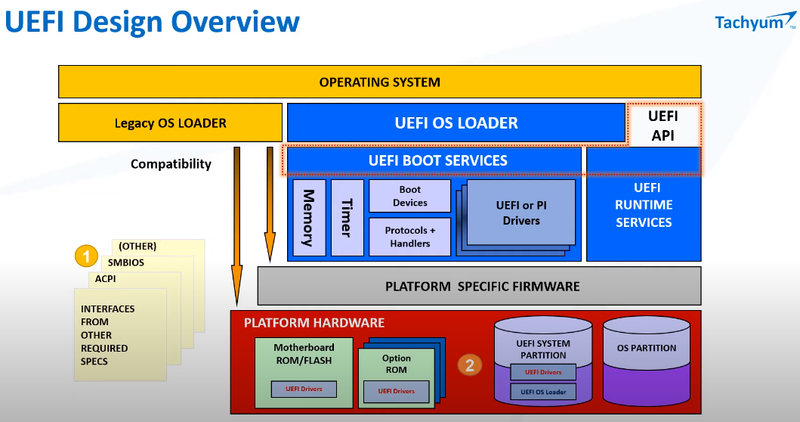 К настоящему времени, таким образом, компания предлагает программные и ПЛИС-эмуляторы нового процессора, и сопутствующее программное обеспечение. К чести Tachym, разработан не только UEFI — имеется и ядро Linux с поддержкой новой архитектуры, набор средств разработки, включая компиляторы (в том числе, для ИИ-задач) и отладчики кода. Успешно продемонстрирована возможность работы на Prodigy бинарного кода, созданного для архитектур x86, ARM и RISC-V. Первые чипы Prodigy должны появиться уже в следующем году. Если запуск будет успешным, Tachym может сильно изменить привычную картину мира в сфере HPC и ИИ, ведь новая архитектура обещает быть производительнее классических Xeon и EPYC при на порядок более низком энергопотреблении, втрое более низкой стоимостью в пересчёте на MIPS, и вчетверо более низкой стоимостью владения. Более того, Prodigy угрожает даже ускорителям, обеспечивая сравнимый или более высокий уровень производительности в задачах, где последние традиционно сильны, например, в системах машинного обучения. Остаётся лишь пожелать Tachyum удачи в столь смелом начинании.
20.11.2020 [16:45], Сергей Карасёв
NEC выводит на рынок векторный ускоритель SX-Aurora TSUBASA Vector Engine 2.0Компания NEC сообщила о том, что с января следующего года заказчикам по всему миру станет доступен акселератор Vector Engine 2.0 серии SX-Aurora TSUBASA, анонсированный ещё летом. Изделие Type 20B выполнено в виде двухслотовой карты расширения с интерфейсом PCIe. Оно содержит восемь векторных блоков с частотой 1,6 ГГц, обеспечивающих производительность на уровне 2,45 Тфлопс FP64, и 48 Гбайт памяти HBM2 с пропускной способностью приблизительно 1,53 Тбайт/с. При этом энергопотребление находится на уровне 200 Вт. Также есть версия ускорителя Type 20A, которая имеет 10 векторных блоков и производительность 3,07 Тфлопс FP64.  Благодаря векторной архитектуре крупные объёмы данных можно обрабатывать в пределах каждого цикла. Это открывает широкие возможности при решении задач в области искусственного интеллекта, машинного обучения, интенсивных научных вычислений и пр. 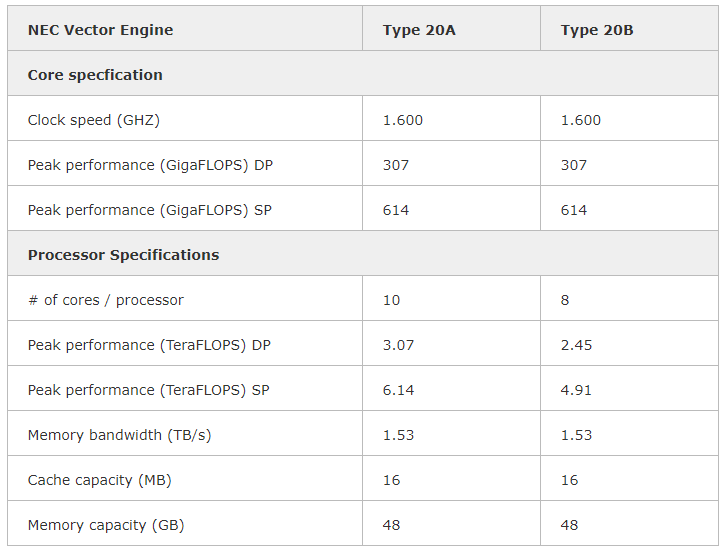 Векторный ускоритель Vector Engine 2.0 может использоваться в составе стандартных серверов и рабочих станций с архитектурой х86 от сторонних поставщиков оборудования. Таким образом, заказчики смогут сформировать вычислительную платформу в соответствии со своими требованиями и объёмом финансирования. Данное решение, по словам NEC, ориентировано на предприятия малого и среднего бизнеса, у которых есть потребность в формировании платформы высокопроизводительных вычислений (HPC).
18.11.2020 [00:17], Владимир Мироненко
SC20: РСК представила all-flash СХД Tornado AFS с функцией высокой доступностиГруппа компаний РСК, российский разработчик HPC-решений, представила на всемирной виртуальной суперкомпьютерной выставке SC20 целый ряд новых решений. В частности, было объявлено, что высокоплотные и энергоэффективные вычислительные узлы «РСК Торнадо» будут поддерживать 10-нм серверные процессоры Intel с кодовым наименованием Ice Lake-SP, намеченные к выпуску в начале 2021 года. Как ожидается, новые чипы получат поддержку интерфейса PCI Express 4.0 и памяти Intel Optane DC второго поколения. Также была представлена интеллектуальная СХД Tornado AFS с поддержкой функции высокой доступности для создания систем хранения с большим объемом данных. Решение отличается высокой надёжностью и доступностью данных благодаря объединению узлов Tornado AFS в функциональные пары, так как в случае выхода из строя одного из узлов работа обеспечивается с помощью второго.  Это обеспечивает надёжное хранение данных объёмом до 2 Пбайт в форм-факторе 2U с помощью 64-х NVMe SSD в форм-факторе E1.L. Также используются процессоры семейства Intel Xeon Scalable 2-го поколения, твердотельные диски Optane SSD и модули энергонезависимой PMem-памяти Optane DC Persistent Memory (DCPMM). В RSC Tornado AFS используется 100 % жидкостное охлаждение в режиме «горячая вода» с показателем эффективности использования электроэнергии PUE на уровне 1,04. РСК подтвердила заявленную ранее поддержку DAOS в решениях RSC Storage on-Demand и объявила о переходе на обновлённую платформу оркестрации «РСК БазИС» для создания высокопроизводительных составных архитектур хранения данных. Это позволит вместо жёсткого регламентирования конфигурации применять компонуемый подход для управления DAOS. Использование высокопроизводительных адаптеров с поддержкой RDMA, NVMe-накопителей и памяти Optane DCPMM позволит произвести такую дезагрегацию и дальнейшую компоновку «по запросу» без снижения производительности. Такой подход позволит заметно увеличить допустимый объем системы хранения данных благодаря отмене ограничений по объёму PMem в DAOS. При этом благодаря компонуемости, неиспользуемые в какой-то момент времени диски можно подключить к другому серверу на основе DAOS или Lustre. В дополнение можно разделить серверы с DAOS и серверы c NVMe-дисками на два пула, тем самым максимально устранив ограничения аппаратной архитектуры сервера (нехватку линий шины PCIe, используемой как накопителями, так и сетевыми адаптерами, а также физических ограничений шасси сервера по размещению дополнительных устройств и их охлаждению). РСК также разработала пользовательский интерфейс для RSC Storage on-Demand, позволяющий быстро создать сложную многоуровневую компонуемую систему хранения «по требованию». Новый интерфейс поддерживает создание параллельных файловых систем Lustre, распределённых объектных систем хранения DAOS и их комбинаций.
16.11.2020 [17:00], Игорь Осколков
SC20: NVIDIA представила ускоритель A100 с 80 Гбайт HBM2e и настольный «суперкомпьютер» DGX STATIONNVIDIA представила новую версию ускорителя A100 с увеличенным вдвое объёмом HBM2e-памяти: 80 Гбайт вместо 40 Гбайт у исходной A100, представленной полгода назад. Вместе с ростом объёма выросла и пропускная способность — с 1,555 Тбайт/с до 2 Тбайт/с. В остальном характеристики обоих ускорителей совпадают, даже уровень энергопотребления сохранился на уровне 400 Вт. Тем не менее, объём и скорость работы быстрой набортной памяти влияет на производительность ряда приложений, так что им такой апгрейд только на пользу. К тому же MIG-инстансы теперь могут иметь объём до 10 Гбайт. PCIe-варианта ускорителя с удвоенной памятью нет — речь идёт только об SXM3-версии, которая используется в собственных комплексах NVIDIA DGX и HGX-платформах для партнёров. 
NVIDIA A100 80 Гбайт  Последним ориентировочно в первом квартале следующего года будут предоставлены наборы для добавления новых A100 в существующие решения, включая варианты плат на 4 и 8 ускорителей. У самой NVIDIA обновлению подверглись, соответственно, DGX A100 POD и SuperPOD for Enterprise. Недавно анонсированные суперкомпьютеры Cambridge-1 и HiPerGator на базе SuperPOD одними из первых получат новые ускорители с 80 Гбайт памяти. Ожидается, что HGX-решения на базе новой A100 будут доступны от партнёров компании — Atos, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta и Supermicro — в первой половине 2021 года.   Но, пожалуй, самый интересный анонс касается новой рабочей станции NVIDIA DGX STATION A100, которую как раз и можно назвать настольным «суперкомпьютером». В ней используются четыре SXM3-ускорителя A100 с не требующей обслуживания жидкостной системой охлаждения и полноценным NVLink-подключением. Будут доступны две версии, со 160 или 320 Гбайт памяти с 40- и 80-Гбайт A100 соответственно. Базируется система на 64-ядерном процессоре AMD EPYC, который можно дополнить 512 Гбайт RAM.   Для ОС доступен 1,92-Тбайт NVMe M.2 SSD, а для хранения данных — до 7,68 Тбайт NVMe U.2 SSD. Сетевое подключение представлено двумя 10GbE-портами и выделенным портом управления. Видеовыходов четыре, все mini Display Port. DGX STATION A100 отлично подходит для малых рабочих групп и предприятий. В том числе благодаря тому, что функция MIG позволяет эффективно разделить ресурсы станции между почти тремя десятками пользователей. В продаже она появится у партнёров компании в феврале следующего года.  Вероятно, все выпускаемые сейчас A100 c увеличенным объёмом памяти идут на более важные проекты. Новинкам предстоит конкурировать с первым ускорителем на базе новой архитектуры CDNA — AMD Instinct MI100.
13.11.2020 [18:00], Алексей Степин
Южная Корея близка к созданию собственного процессора для суперкомпьютеровМощные многоядерные процессоры, могущие служить основой суперкомпьютерных комплексов и кластерных систем могут разрабатывать, а тем более производить, не так уж много стран. Но любое государство, претендующее на независимость в IT, хорошо понимает, что в современном мире такая возможность может оказаться ключевой. Именно поэтому создан консорциум European Processor Initiative, именно для этого КНР, Япония и Россия разрабатывают свои многоядерные чипы. Теперь в игру вступает и Южная Корея. Концепция процессора для сферы супервычислений может отличаться кардинально: так, Европа и Япония предпочитают архитектуру ARM, Европа присматривается и к RISC-V, а Россия делает основную ставку на VLIW (семейство «Эльбрус»). Японские процессоры Fujitsu A64FX тоже основаны на ARM, но заметно отличаются от всех остальных чипов: набор инструкций SVE, HBM-память и встроенный интерконнект.  Южнокорейский институт электроники и телекоммуникаций (ETRI), ведущий свой проект совместно с ARM, объявил о том, что стал ещё на шаг ближе к созданию собственного уникального процессора класса HPC. Уникальность южнокорейской разработки в том, что она должна обеспечивать как высокую производительность в традиционных суперкомпьютерных задачах, обычно использующих вычисления двойной точности (FP64), так и невысокий уровень энергопотребления в «низкоточных» задачах (инференс, машинное обучение и тому подобные сценарии). 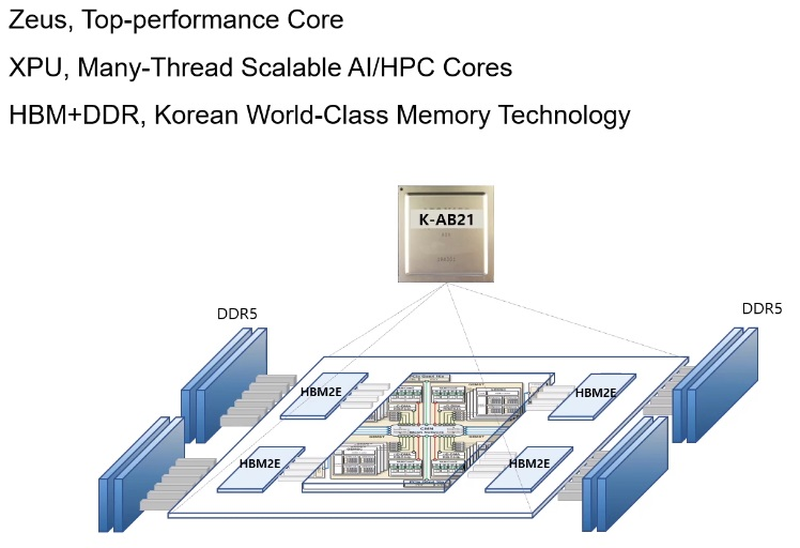 Спецификации, поставленные перед южнокорейскими разработчиками, довольно серьёзны: финальный вариант процессора должен обеспечивать 2,5-кратное превосходство над классическими ускорителями (обычно на базе графических чипов), но при этом быть на 60% экономичнее них. Это должно достигаться за счёт уникальной реализации управления питанием и тактовыми частотами отдельных компонентов процессора. Речь идёт как об аппаратной составляющей, так и о разработке собственного программного стека, позволяющего тонко манипулировать режимами работы нового ЦП. Заявлена возможность интеграции собственных блоков ускорителей, совместимых с уже существующими фреймворками за счёт поддержки OpenMP и OpenCL. Процессор в полной мере сохранит классический режим вычислений с двойной точностью. Текущий прототип получил название K-AB21, причём AB означает «Artificial Brain» (искусственный мозг) — разработчики заявляют, что за счет активного использования матричных ядер (XPU) им удалось достичь производительности 16 Тфлопс на процессор. Это обещает до 1600 Тфлопс на стойку. Процессор с такой производительностью должен открыть Южной Корее дорогу к собственным суперкомпьютерам экзафлопсного класса. 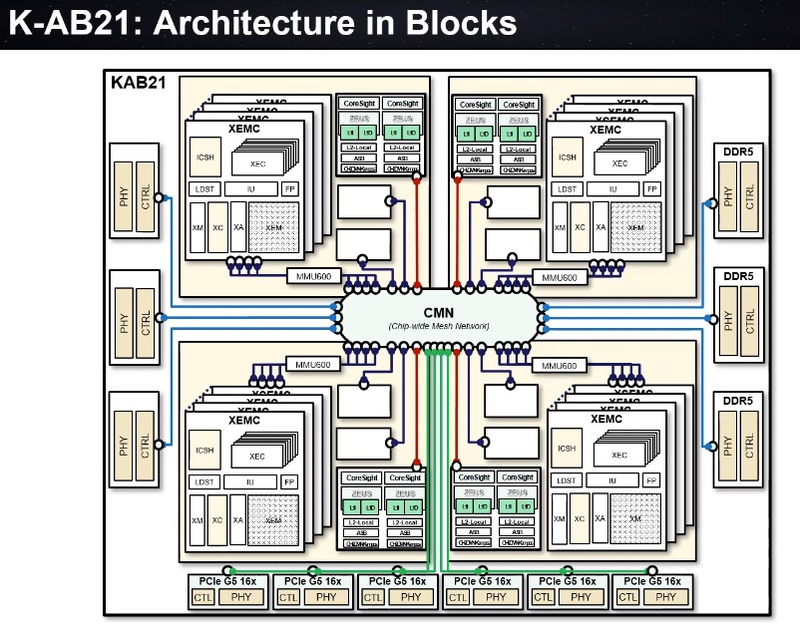 Компоновкой K-AB21 отчасти напоминает Fujitsu A64FX, поскольку также предусматривает наличие пула HBM2 в виде четырёх сборок, однако это не единственная его память. HBM выступает скорее в роли ещё одного уровня кеша, а основной объём составляют модули DDR5. Вычислительная часть состоит из классических ARM-ядер Zeus и многопоточных масштабируемых ядер XPU собственной разработки ETRI. Их-то разработчики и называют «матричными ядрами», поскольку работа с матричной математикой главная задача этих ядер. Группы таких ядер, называемые доменами XEMC на схеме (всего их в каждом процессоре 4), имеют свой MMU, а также собственные подсистемы кешей и программируемых блоков логики с поддержкой SMT. За соединение частей процессора между собой отвечает внутренняя сеть с ячеистой (mesh) топологией. Текущая реализация K-AB21 также включает в себя шесть контроллеров шины PCI Express 5.0, каждый на 16 линий. В настоящее время разработчики заняты финализацией отдельных элементов дизайна K-AB21, но в целом разработка близка к завершению. Полноценная реализация «в кремнии» ожидается к концу 2021 года, что для проекта такого масштаба достаточно быстро и позволит Южной Корее вовремя войти в эру суперкомпьютеров экза-класса. В настоящее время самым мощным южнокорейским кластером является Nurion, занимающий 17 место в Top500. Однако это система Cray CS500 на базе Intel Xeon Phi 7250, которая целиком базируется на технологиях США, а выпуск собственного HPC-процессора позволит Южной Корее стать более независимой в этом аспекте.
24.07.2020 [00:50], Игорь Осколков
Phytium Tengyun S2500: 64-ядерный ARM-чип для восьмипроцессорных системКак сообщает cnTechPost, Phytium, китайский разработчик процессоров, анонсировал новый 64-ядерный чип Tengyun S2500, ориентированный на высокопроизводительные вычисления (HPC). Компания и прежде была известна разработками в этой области — её процессоры легли в основу суперкомпьютеров Tiahne, занимавших первые строчки рейтинга TOP500. 
Изображения: cnTechPost В отличие от своего предшественника FT-2000+/64, тоже 64-ядерного, ядра новинки в дополнение к L2-кешу объёмом 512 Кбайт получили общий L3-кеш на 64 Мбайт. Кроме того, чип поддерживает восемь каналов памяти DDR4-3200. Отличительной чертой Tengyun S2500 является возможность объединения — судя по всему, бесшовного — от двух до восьми процессоров в рамках одной системы. Для связи между CPU используется несколько линий собственной шины со скоростью 800 Гбит/с.  В основе CPU лежат ядра FTC663, работающие на частоте 2 – 2,2 ГГц. Они же используются в представленном в прошлом году младшем чипе Phytium FT2000/4. Ядра серии FTC600 базируются на модифицированной архитектуре ARMv8 и включают переделанные блоки для целочисленных вычислений и вычислений с плавающей запятой, ASIMD-инструкции, новый динамический предсказатель переходов, поддержку виртуализации, а также традиционные для китайских CPU блоки шифрования и безопасности, соответствующие локальным стандартам.  Энергопотребление новинок достигает 150 Вт. Изготавливаться они будут на TSCM по техпроцессу 16-нм FinFET. Начало массового производства запланировано на четвёртый квартал этого года. Тогда же появятся и 14-нм десктопные чипы Phytium Tengrui D2000, которым через года не смену придут Tengrui D3000. Выход 7-нм серверных процессоров Phytium Tengyun S5000 запланирован на третий квартал 2021 года, а 5-нм чипы Tengyun S6000 появятся уже в 2022-ом.
27.06.2020 [18:54], Алексей Степин
ISC 2020: NEC анонсировала новые векторные ускорители SX-AuroraВ японском сегменте рынка супервычислений продолжает доминировать свой, уникальный подход к построению систем класса HPC. Fujitsu сделала ставку на гомогенную архитектуру A64FX с памятью HBM2 и заняла первое место в Top500, но и другая японская компания, NEC, не отказалась от своего видения суперкомпьютерной архитектуры. На предыдущей конференции SC19 NEC пополнила свой арсенал новыми ускорителями SX-Aurora 10E, которые получили более быстрые сборки HBM2. О новых ускорителях «Type 20» речь заходила ещё до начала эпидемии COVID-19; к сожалению, она внесла свои коррективы и анонс новинок состоялся лишь сейчас, летом 2020 года.  Изначально процессор SX-Aurora, используемый во всей серии ускорителей «Type 10» имеет 8 векторных блоков, каждый из которых дополнен 2 Мбайт кеша и 6 сборок памяти HBM2 общим объёмом 24 или 48 Гбайт. Из-за сравнительно грубого 16-нм техпроцесса уровень тепловыделения достаточно высок и составляет примерно 225 Ватт. В отличие от Fujitsu A64FX, NEC SX-Aurora требует для своей работы управляющего хост-процессора, и обычно компания комбинирует его с Intel Xeon, но существуют варианты и с AMD EPYC второго поколения. 
ISC 2018: HPC-модуль с восемью векторными ускорителями NEC SX-Aurora Type 10 Это роднит SX-Aurora с более широко распространёнными ускорителями на базе графических процессоров, однако позиционирование у них всё-таки выглядит иначе. ГП-ускорители, по мнению NEC, гораздо сложнее в программировании, хотя и обеспечивают высокую производительность.  Свою же разработку компания относит к решениям с похожим уровнем производительности, но гораздо более простым в программировании. Упор также делается на высокую пропускную способность памяти, составляющую у новинок «Type 20» 1,5 Тбайт/с.  Новая версия NEC Vector Engine, VE20, структурно, скорее всего, не изменилась. Вместо восьми ядер новый процессор получил 10, и, как уже было сказано, новые сборки HBM2, в результате чего ПСП удалось поднять с 1,35 до 1,5 Тбайт/с, а вычислительную мощность с 2,45 до 3,07 Тфлопс.  В серии пока представлено два новых ускорителя, Type 20A и 20B, последний аналогичен по конфигурации решениям Type 10 и использует усечённый вариант процессора с 8 ядрами. Говорится о неких архитектурных улучшениях, но деталей компания пока не раскрывает. Оба варианта процессора VE20 работают на частоте 1,6 ГГц, а прирост производительности в сравнении с VE10 достигается в основном за счёт повышения ПСП.  Похоже, VE20 лишь промежуточная ступень. В 2022 году планируется выпуск процессора VE30, который получит подсистему памяти с пропускной способностью свыше 2 Тбайт/с, в 2023 должен появиться его наследник VE40, но настоящий прорыв, судя по всему, откладывается до 2024 года, когда NEC планирует представить VE50, об архитектуре и возможностях которого пока ничего неизвестно. 
25.06.2020 [21:10], Алексей Степин
ISC 2020: Tachyum анонсировала 128-ядерные ИИ-процессоры Prodigy и будущий суперкомпьютер на их основеМашинное обучение в последние годы развивается и внедряется очень активно. Разработчики аппаратного обеспечения внедряют в свои новейшие решения поддержку оптимальных для ИИ-систем форматов вычислений, под этот круг задач создаются специализированные ускорители и сопроцессоры. 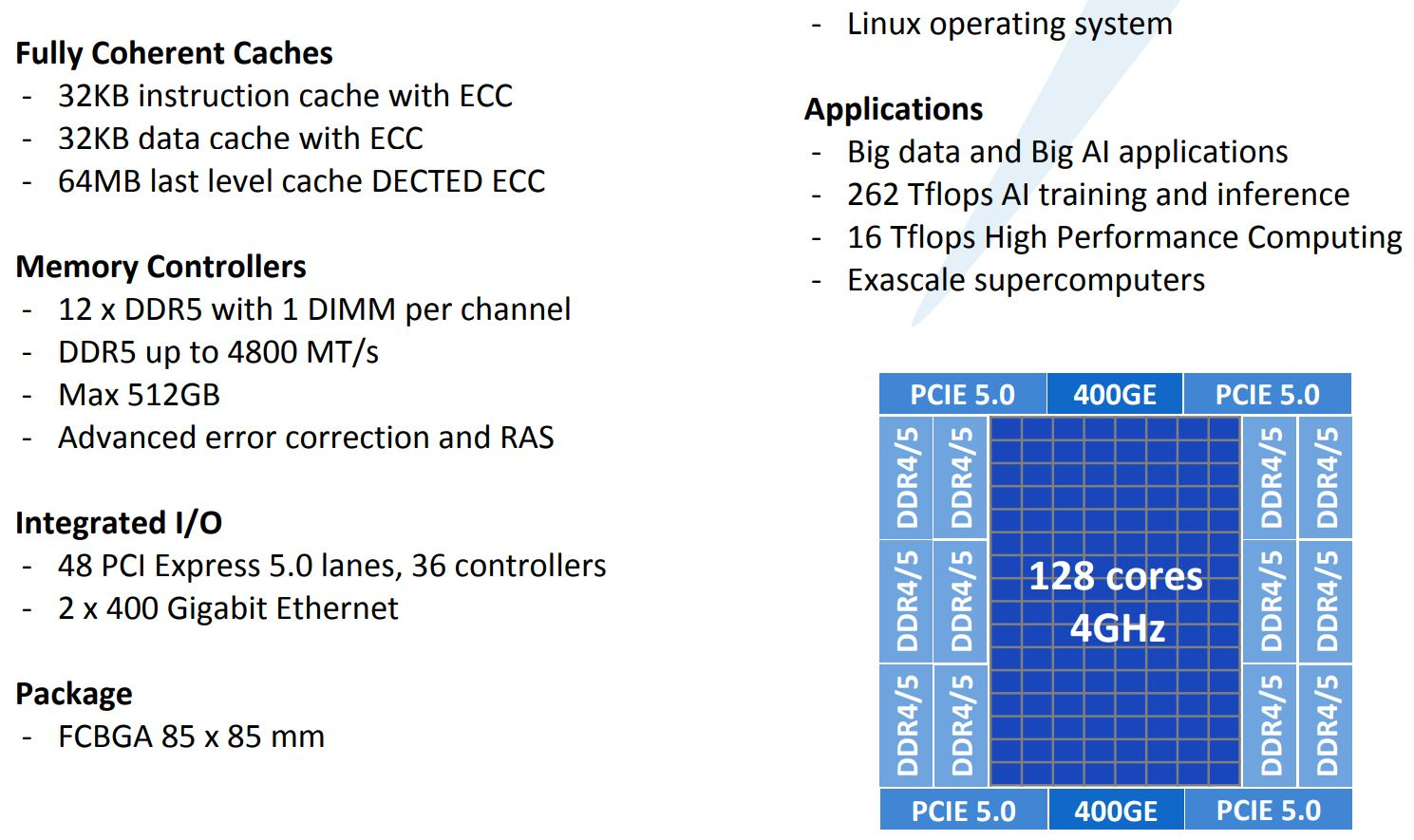 Словацкая компания Tachyum достаточно молода, но уже пообещала выпустить процессор, который «отправит Xeon на свалку истории». О том, что эти чипы станут основой для суперкомпьютеров нового поколения, мы уже рассказывали читателям, а на конференции ISC High Performance 2020 Tachyum анонсировала и сами процессоры Prodigy, и ИИ-комплекс на их основе.  Запуск готовых сценариев машинного интеллекта достаточно несложная задача, с ней справляются даже компактные специализированные чипы. Но обучение таких систем требует куда более внушительных ресурсов. Такие ресурсы Tachyum может предоставить: на базе разработанных ею процессоров Prodigy она создала дизайн суперкомпьютера с мощностью 125 Пфлопс на стойку и 4 экзафлопса на полный комплекс, состоящий из 32 стоек высотой 52U.  Основой для новой машины является сервер-модуль собственной разработки Tachyum, системная плата которого оснащается четырьмя чипами Prodigy. Каждый процессор, по словам разработчиков, развивает до 625 Тфлопс, что дает 2,5 Пфлопс на сервер. Компания обещает для новых систем трёхкратный выигрыш по параметру «цена/производительность» и четырёхкратный — по стоимости владения. При этом энергопотребление должно быть на порядок меньше, нежели у традиционных систем такого класса. 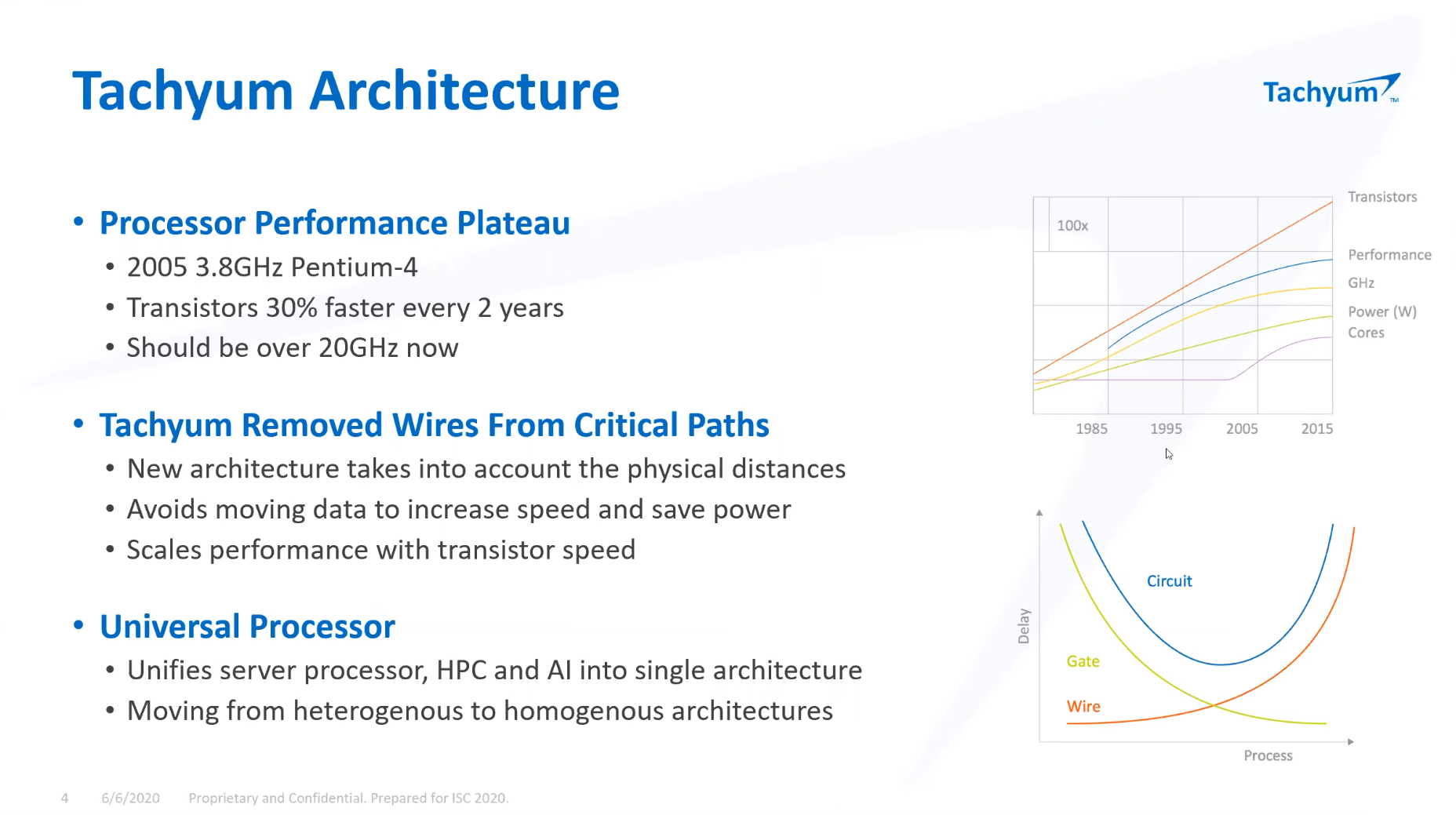 Архитектура Prodigy представляет существенный интерес: это не узкоспециализированный чип, вроде разработок NVIDIA, а универсальный процессор, сочетающий в себе черты ЦП, ГП и ускорителя ИИ-операций. Структура кристалла построена вокруг концепции «минимального перемещения данных». При разработке Tachyum компания принимала во внимание задержки, вносимые расстоянием между компонентами процессора, и минимизировала их. 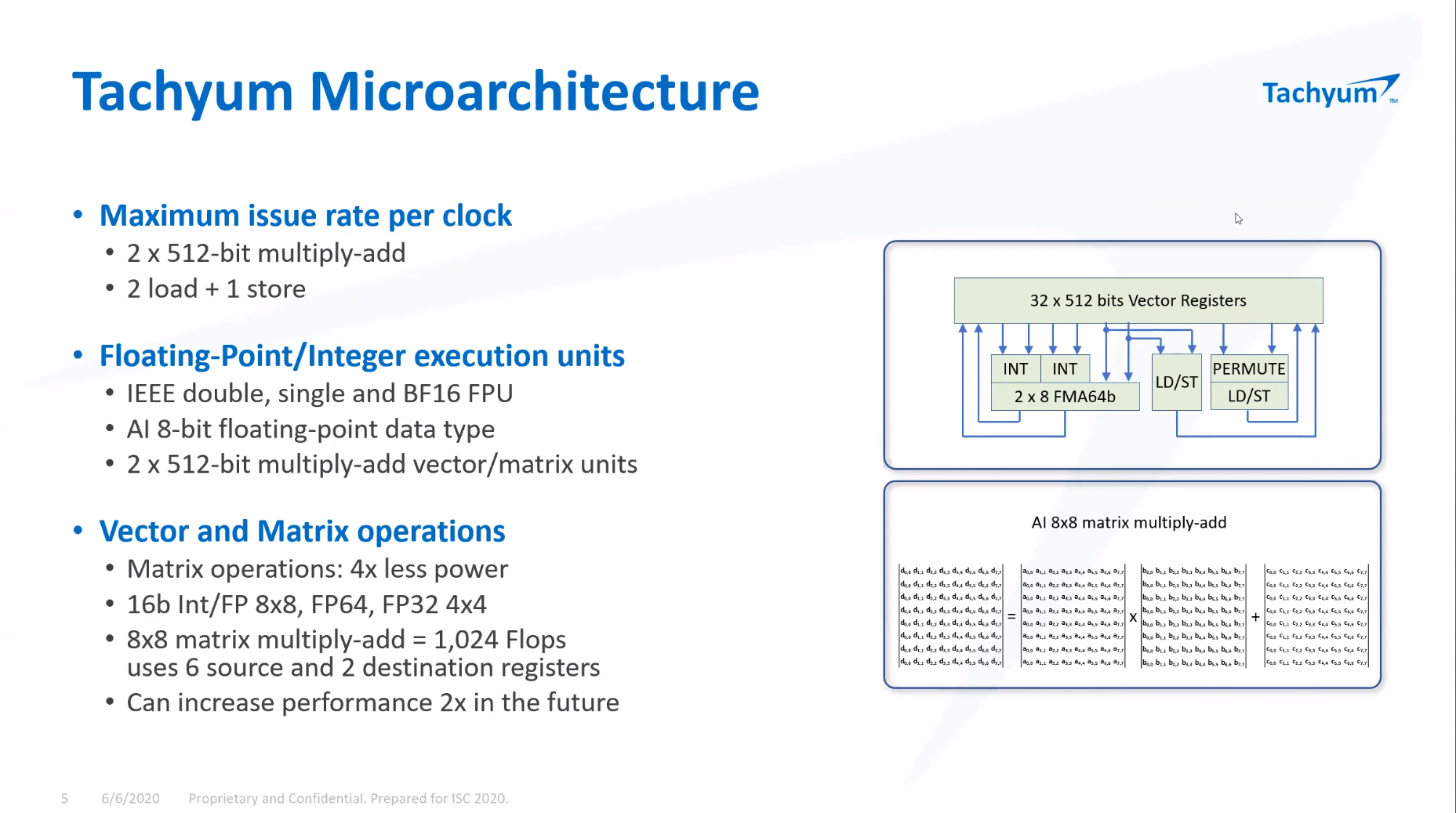 Процессор Prodigy может выполнять за такт две 512-битные операции типа multiply-add, 2 операции load и одну операцию store. Соответственно то, что каждое ядро Prodigy имеет восемь 64-бит векторных блока, похожих на те, что реализованы в расширениях Intel AVX-512 IFMA (Integer Fused Multiply Add, появилось в Cannon Lake). Блок вычислений с плавающей точкой поддерживает двойную, одинарную и половинную точность по стандартам IEEE. Для ИИ-задач имеется также поддержка 8-битных типов данных с плавающей запятой.  Векторные и матричные операции — сильная сторона Prodigy. На перемножении-сложении матриц размерностью 8 × 8 ядро развивает 1024 Флопс, используя 6 входных и 2 целевых регистра (в сумме есть тридцать два 512-бит регистра). Это не предел, разработчик говорит о возможности увеличения скорости выполнения этой операции вдвое. Tachyum обещает, что система на базе Prodigy станет первым в мире ИИ-кластером, способным запустить машинный интеллект, соответствующий человеческому мозгу.  С учётом заявлений о 10-кратной экономии электроэнергии и 1/3 стоимости от стоимости Xeon, это заявление звучит очень сильно. Но Prodigу — не бумажный продукт-однодневка. Tachyum разработала не только сам процессор, но и всю необходимую ему сопутствующую инфраструктуру, включая и компилятор, в котором реализованы оптимизации в рамках «минимального перемещения данных». Новинка разрабона с использованием 7-нм техпроцесса, максимальное количество ядер с вышеописанной архитектурой — 64. Помимо самих ядер, кристалл T864 содержит восьмиканальный контроллер DDR5, контроллер PCI Express 5.0 на 64 (а не 72, как ожидалось ранее) линии и два сетевых интерфейса 400GbE. При тактовой частоте 4 ГГц Prodigy развивает 8 Тфлопс на стандартных вычислениях FP32, 1 Пфлоп на задачах обучения ИИ и 4 Петаопа в инференс-задачах. Самая старшая версия, Tachyum Prodigy T16128, предлагает уже 128 ядер с частотой до 4 ГГц, 12 каналов памяти DDR5-4800 (но только 1DPC и до 512 Гбайт суммарно), 48 линий PCI Express 5.0 и два контроллера 400GbE. Производительность в HPC-задачах составит 16 Тфлопс, а в ИИ — 262 Тфлопс на обучении и тренировке.  Системные платы для Prodigy представлены, как минимум, в двух вариантах: полноразмерные четырёхпроцессорные для сегмента HPC и компактные однопроцессорные для модульных систем высокой плотности. Полноразмерный вариант имеет 64 слота DIMM и поддерживает модули DDR5 объёмом до 512 Гбайт, что даёт 32 Тбайт памяти на вычислительный узел. Сам узел полностью совместим со стандартами 19″ и Open Compute V3, он может иметь высоту 1U или 2U и поддерживает питание напряжением 48 Вольт. Плата имеет собственный BIOS UEFI, но для удалённого управления в ней реализован открытый стандарт OpenBMC.  Tachyum исповедует концепцию универсальности, но всё-таки узлы для HPC-систем на базе Prodigy могут быть нескольких типов — универсальные вычислительные, узлы хранения данных, а также узлы управления. В качестве «дисковой подсистемы» разработчики выбрали SSD-накопители в формате NF1, подобные представленному ещё в 2018 году накопителю Samsung. Таких накопителей в корпусе системы может быть от одного до 36; поскольку NF1 существенно крупнее M.2, поддерживаются модели объёмом до 32 Тбайт, что даёт почти 1,2 Пбайт на узел. Стойка с модулями Prodigy будет вмещать до 50 модулей высотой 1U или до 25 высотой 2U. Согласно идее о минимизации дистанций при перемещении данных, сетевой коммутатор на 128 или 256 портов 100GbE устанавливается в середине стойки.  Такая конфигурация работает в системе с числом стоек до 16, более масштабные комплексы предполагается соединять между собой посредством коммутатора высотой 2U c 64 портами QSFP-DD, причём поддержка скорости 800 Гбит/с появится уже в 2022 году. 512 стоек могут объединяться посредством высокопроизводительного коммутатора CLOS, он имеет высоту 21U и также получит поддержку 800 Гбит/с в дальнейшем. Компания активно поддерживает открытые стандарты: применён загрузчик Core-Boot, разработаны драйверы устройств для Linux, компиляторы и отладчики GCC, поддерживаются открытые приложения, такие, как LAMP, Hadoop, Sparc, различные базы данных. В первом квартале 2021 года ожидается поддержка Java, Python, TensorFlow, PyTorch, LLVM и даже операционной системы FreeBSD.  Любопытно, что существующее программное обеспечение на системах Tachyum Prodigy может быть запущено сразу в виде бинарных файлов x86, ARMv8 или RISC-V — разумеется, с пенальти. Производительность ожидается в пределах 60 ‒ 75% от «родной архитектуры», для достижения 100% эффективности всё же потребуется рекомпиляция. Но в рамках контрактной поддержки компания обещает помощь в этом деле для своих партнёров. Разумеется, пока речи о полномасштабном производстве новых систем не идёт. Эталонные платформы Tachyum обещает во второй половине следующего года. Как обычно, сначала инженерные образцы получают OEM/ODM-партнёры компании и системные интеграторы, а массовые поставки должны начаться в 4 квартале 2021 года. Однако ПЛИС-эмуляторы Prodigy появятся уже в октябре этого года, инструментарий разработки ПО — и вовсе в августе.  Планы у Tachyum поистине наполеоновские, но её разработки интересны и содержат целый ряд любопытных идей. В чём-то новые процессоры можно сравнить с Fujitsu A64FX, которые также позволяют создавать гомогенные и универсальные вычислительные комплексы. Насколько удачной окажется новая платформа, говорить пока рано. |
|

