Материалы по тегу: nvidia
|
13.09.2024 [10:22], Сергей Карасёв
Некогда самый мощный в мире суперкомпьютер Summit уйдёт на покой в ноябреВысокопроизводительный вычислительный комплекс Summit, установленный в Окриджской национальной лаборатории (ORNL) Министерства энергетики США, будет выведен из эксплуатации в ноябре 2024 года. Обслуживать машину становится всё дороже, а по эффективности она уступает современным суперкомпьютерам. Summit был запущен в 2018 году и сразу же возглавил рейтинг мощнейших вычислительных систем мира TOP500. Комплекс насчитывает 4608 узлов, каждый из которых оборудован двумя 22-ядерными процессорами IBM POWER9 с частотой 3,07 ГГц и шестью ускорителями NVIDIA Tesla GV100. Узлы соединены через двухканальную сеть Mellanox EDR InfiniBand, что обеспечивает пропускную способность в 200 Гбит/с для каждого сервера. Энергопотребление машины составляет чуть больше 10 МВт. 
Источник изображения: ORNL FP64-быстродействие Summit достигает 148,6 Пфлопс (Linpack), а пиковая производительность составляет 200,79 Пфлопс. За шесть лет своей работы суперкомпьютер ни разу не выбывал из первой десятки TOP500: так, в нынешнем рейтинге он занимает девятую позицию. 
Источник изображения: ORNL Отправить Summit на покой планировалось в начале 2024-го. Однако затем была запущена инициатива SummitPLUS, и срок службы вычислительного комплекса увеличился практически на год. Отмечается, что этот суперкомпьютер оказался необычайно продуктивным. Он обеспечил исследователям по всему миру более 200 млн часов работы вычислительных узлов. В настоящее время ORNL эксплуатирует ряд других суперкомпьютеров, в число которых входит Frontier — самый мощный НРС-комплекс в мире. Его пиковое быстродействие достигает 1714,81 Пфлопс, или более 1,7 Эфлопс. При этом энергопотребление составляет 22 786 кВт: таким образом, система Frontier не только быстрее, но и значительно энергоэффективнее Summit. А весной этого года из-за растущего количества сбоев и протечек СЖО на аукционе был продан 5,34-ПФлопс суперкомпьютер Cheyenne.
13.09.2024 [00:17], Владимир Мироненко
Производительность суперкомпьютера «Сергей Годунов» выросла вдвое — до 114,67 Тфлопс
a100
hardware
hpc
ice lake-sp
intel
nvidia
rtx
xeon
новосибирск
россия
рск
сделано в россии
суперкомпьютер
Группа компаний РСК сообщила о завершении плановой модернизации суперкомпьютера «Сергей Годунов» в Институте математики имени С.Л. Соболева Сибирского отделения Российской академии наук (ИМ СО РАН), благодаря чему его суммарная пиковая FP64-производительность теперь составляет 114,67 Тфлопс: 75,87 Тфлопс на CPU и 38,8 Тфлопс на GPU. 
Источник изображений: РСК Работы по запуску машины были завершены РСК в ноябре 2023 года, а её официальное открытие состоялось в феврале этого года. На тот момент производительность суперкомпьютера составляла 54,4 Тфлопс. Директор ИМ СО РАН Андрей Евгеньевич Миронов отметил, что использование нового суперкомпьютера позволило существенно повысить эффективность научных исследований, и выразил уверенность, что он также будет способствовать развитию новых технологий. Миронов сообщил, что после запуска суперкомпьютера появилась возможность решать мультидисциплинарные задачи, моделировать объёмные процессы и предсказывать поведение сложных математических систем. По его словам, на суперкомпьютере проводятся вычисления по критически важным проблемам и задачам, среди которых:

Источник изображений: РСК Суперкомпьютер «Сергей Годунов» является основным инструментом для проведения исследований и прикладных разработок в Академгородке Новосибирска и создания технологической платформы под эгидой Научного совета Отделения математических наук РАН по математическому моделированию распространения эпидемий с учётом социальных, экономических и экологических процессов. Он был назван в память об известном советском и российском математике с мировым именем Сергее Константиновиче Годунове. Отечественный суперкомпьютер создан на базе высокоплотной и энергоэффективной платформы «РСК Торнадо» с жидкостным охлаждением. Система включает вычислительные узлы с двумя Intel Xeon Ice Lake-SP, узел на базе четырёх ускорителей NVIDIA A100 и сервер визуализации с большим объёмом памяти: Intel Xeon Platinum 8368, 4 Тбайт RAM, пара NVIDIA RTX 5000 Ada с 32 Гбайт GDDR6.
11.09.2024 [18:55], Игорь Осколков
Oracle анонсировала зеттафлопсный облачный ИИ-суперкомпьютер из 131 тыс. NVIDIA B200Oracle и NVIDIA анонсировали самый крупный на сегодняшний день облачный ИИ-кластер, состоящий из 131 072 ускорителей NVIDIA B200 (Blackwell). По словам компаний, это первая в мире система производительностью 2,4 Зфлопс (FP8). Кластер заработает в I половине 2025 года, но заказы на bare-metal инстансы и OCI Superclaster компания готова принять уже сейчас. Заказчики также смогут выбрать тип подключения: RoCEv2 (ConnectX-7/8) или InfiniBand (Quantum-2). По словам компании, новый ИИ-кластер вшестеро крупнее тех, что могут предложить AWS, Microsoft Azure и Google Cloud. Кроме того, компания предлагает и другие кластеры с ускорителями NVIDIA: 32 768 × A100, 16 384 × H100, 65 536 × H200 и 3840 × L40S. А в следующем году обещаны кластеры на основе GB200 NVL72, объединяющие более 100 тыс. ускорителей GB200. В скором времени также появятся и куда более скромные ВМ GPU.A100.1 и GPU.H100.1 с одним ускорителем A100/H100 (80 Гбайт). Прямо сейчас для заказы доступны инстансы GPU.H200.8, включающие восемь ускорителей H200 (141 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 200G-подключение. Семейство инстансов на базе NVIDIA Blackwell пока включает лишь два варианта. GPU.B200.8 предлагает восемь ускорителей B200 (192 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 400G-подключение. Наконец, GPU.GB200 фактически представляет собой суперускоритель GB200 NVL72 и включает 72 ускорителя B200, 36 Arm-процессоров Grace и локальное NVMe-хранилище ёмкостью 533 Тбайт. Агрегированная скорость сетевого подключения составляет 7,2 Тбит/с. 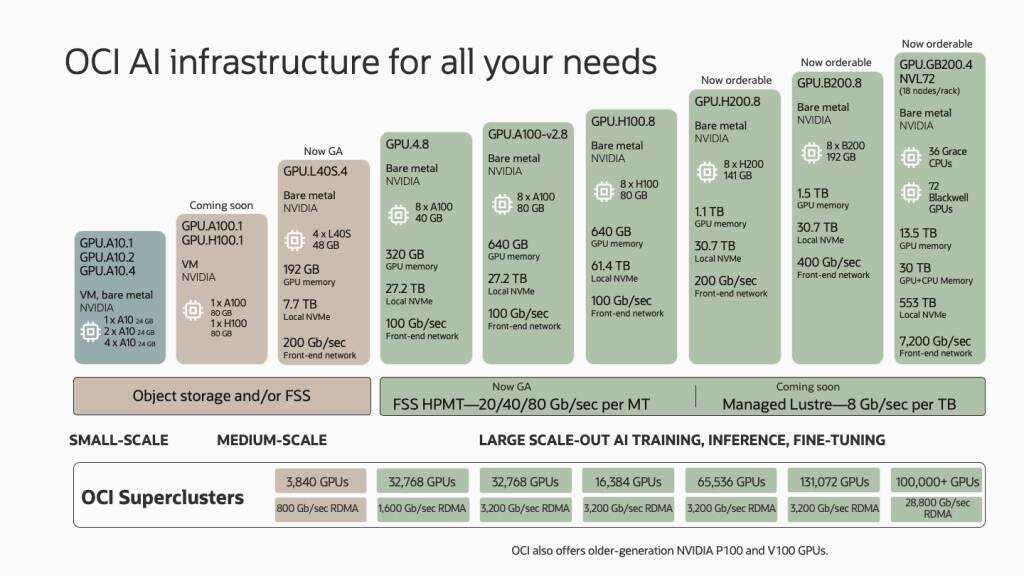
Источник изображения: Oracle Для всех новых инстансов Oracle подготовит управляемое Lustre-хранилище с производительностью до 8 Гбит/с на каждый Тбайт. Кроме того, компания предложит расширенные средства мониторинга и управления, помощь в настройке инфраструктуры для достижения желаемого уровня реальной производительности, а также набор оптимизированного ПО для работы с ИИ, в том числе для Arm.
10.09.2024 [14:55], Сергей Карасёв
TACC ввёл в эксплуатацию Arm-суперкомпьютер Vista на базе NVIDIA GH200 для ИИ-задачТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) объявил о том, что мощности нового НРС-комплекса Vista полностью доступны открытому научному сообществу. Суперкомпьютер предназначен для решения ресурсоёмких задач, связанных с ИИ. Формальный анонс машины Vista состоялся в ноябре 2023 года. Тогда говорилось, что Vista станет связующим звеном между существующим суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Vista состоит из двух ключевых частей. Одна из них — кластер из 600 узлов на гибридных суперчипах NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель H100/H200. Обеспечивается производительность на уровне 20,4 Пфлопс (FP64) и 40,8 Пфлопс на тензорных ядрах. Каждый узел содержит локальный накопитель вместимостью 512 Гбайт, 96 Гбайт памяти HBM3 и 120 Гбайт памяти LPDDR5. Интероконнект — Quantum 2 InfiniBand (400G). Второй раздел суперкомпьютера объединяет 256 узлов с процессорами NVIDIA Grace CPU Superchip, содержащими два кристалла Grace в одном модуле (144 ядра). Узлы укомплектованы 240 Гбайт памяти LPDDR5 и накопителем на 512 Гбайт. Интерконнект — Quantum 2 InfiniBand (200G). Узлы произведены Gigabyte, а за интеграцию всей системы отвечала Dell. 
Источник изображения: TACC Общее CPU-быстродействие Vista находится на отметке 4,1 Пфлопс. В состав комплекса входит NFS-хранилише VAST Data вместимостью 30 Пбайт. Суперкомпьютер будет использоваться для разработки и применения решений на основе генеративного ИИ в различных секторах, включая биологические науки и здравоохранение.
10.09.2024 [08:59], Руслан Авдеев
Гигаватт на орбите: Lumen Orbit предложила гигантские космические ЦОД с питанием от солнечной энергии и пассивным охлаждениемПока многие операторы ЦОД бьются за место и ресурсы для своих дата-центров на Земле, стартап Lumen Orbit трудится над созданием гигантских гигаваттных дата-центров на земной орбите. По словам компании, работа уже началась — первый спутник компании отправится в космос в 2025 году. Он, как ожидается, получит на два порядка более мощные ускорители, чем те, что когда-либо отправлялись в космос. Информация о проекте Lumen Orbit появилась ещё весной, но теперь обнародованы новые подробности. Как сообщается в материалах компании, будущие ЦОД гиперскейл-класса будут серьёзно нагружать энергосети (и уже делают это сегодня), станут потреблять немало питьевой воды, а их работа будет всё хуже сочетаться с законами и правилами регуляторов «западного» мира. Другими словами, многогигаваттные ЦОД будет чрезвычайно трудно строить. Поэтому Lumen Orbit предлагает размещать дата-центры на околоземной орбите, лежащей в плоскости терминатора. Таким образом, солнечные элементы питания будут всегда освещены, а радиаторы пассивного охлаждения всегда в тени. А космическое излучение здесь не так сильно, чтобы быстро выводить из строя электронику. 
Источник изображений: Lumen Orbit Одно из важнейших свойств решения Lumen Orbit — возможность почти бесконечного масштабирования из-за минимума регуляторных запретов и ограничений на потребляемые ресурсы, говорит компания. Согласно расчётам, солнечная энергия в космосе будет обходиться в $0,002/кВт∙ч, тогда как электричество в США, Великобритании и Японии сегодня в среднем стоит $0,045, $0,06 и $0,17 за кВт∙ч соответственно. Кроме того, вода в космосе совершенно не понадобится, а системы пассивного охлаждения (путём излучения) будут многократно эффективнее и стабильнее земных аналогов. Не понадобятся и резервные источники питания. 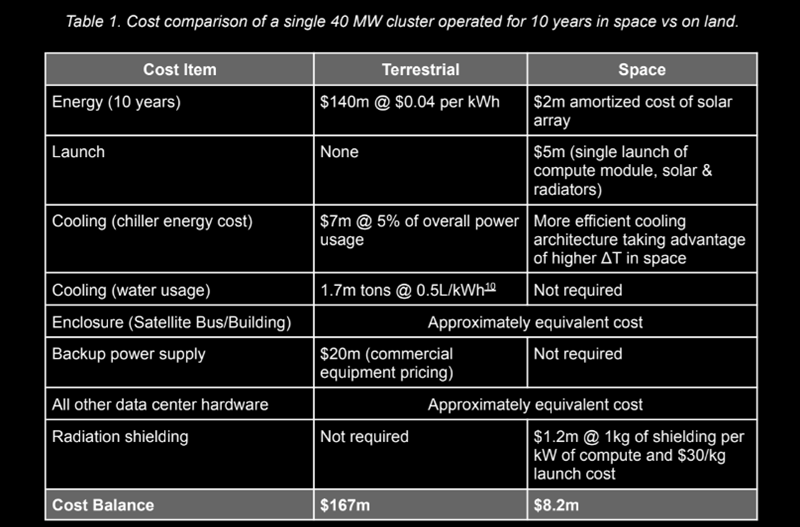 Компания уже разработала и начала строительство первого космического аппарата. Разработан концептуальный дизайн микро-ЦОД, развёртывание которых запланировано на 2026 год,. Также планируется запуск крупного дата-центра Hypercluster — это будет возможно, когда начнётся коммерческая эксплуатация кораблей уровня SpaceX Starship. Сообщается, что уже заключены меморандумы о взаимопонимании, предполагающие использование ускорителей NVIDIA H100 в космосе. 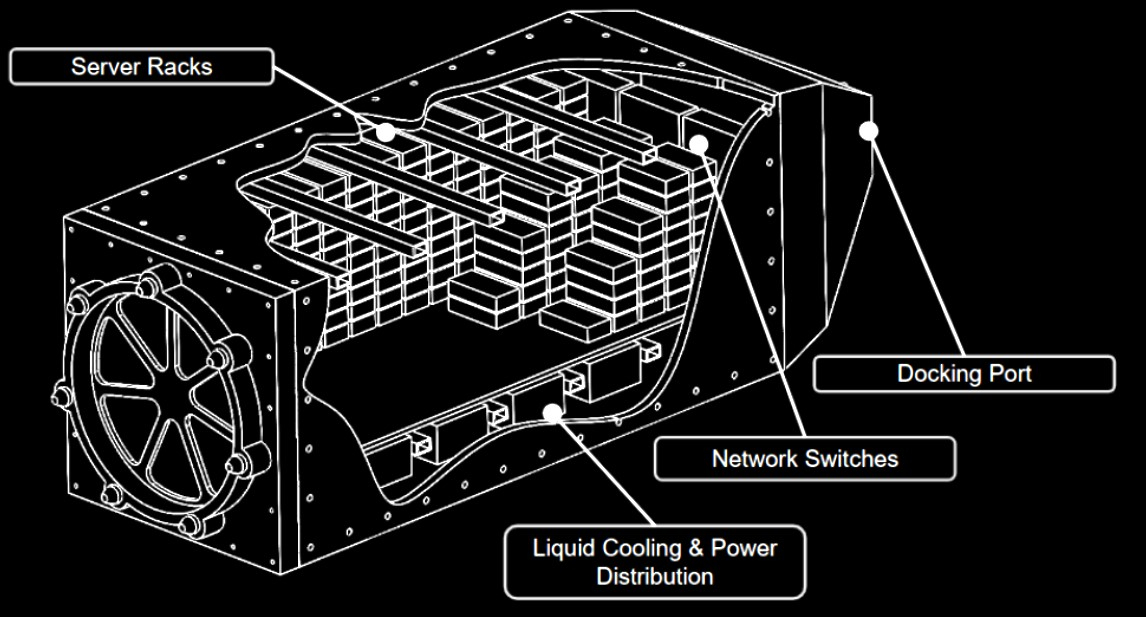 В компании утверждают, что для обучения больших языковых моделей вроде Llama 5 или GPT-6 в 2027 году потребуются 5-ГВт кластеры, которые создадут огромную нагрузку на электростанции и энергосети. Но в космосе можно будет создавать компактные модульные 3D-структуры. Передача данных может осуществляться с помощью лазеров. Более того, возможна совместимость с системами вроде Starlink, а когда необходимо — даже переброс данных специальными шаттлами. Об астрономах тоже не забыли — космические ЦОД будут заметны в основном на рассветах и закатах. 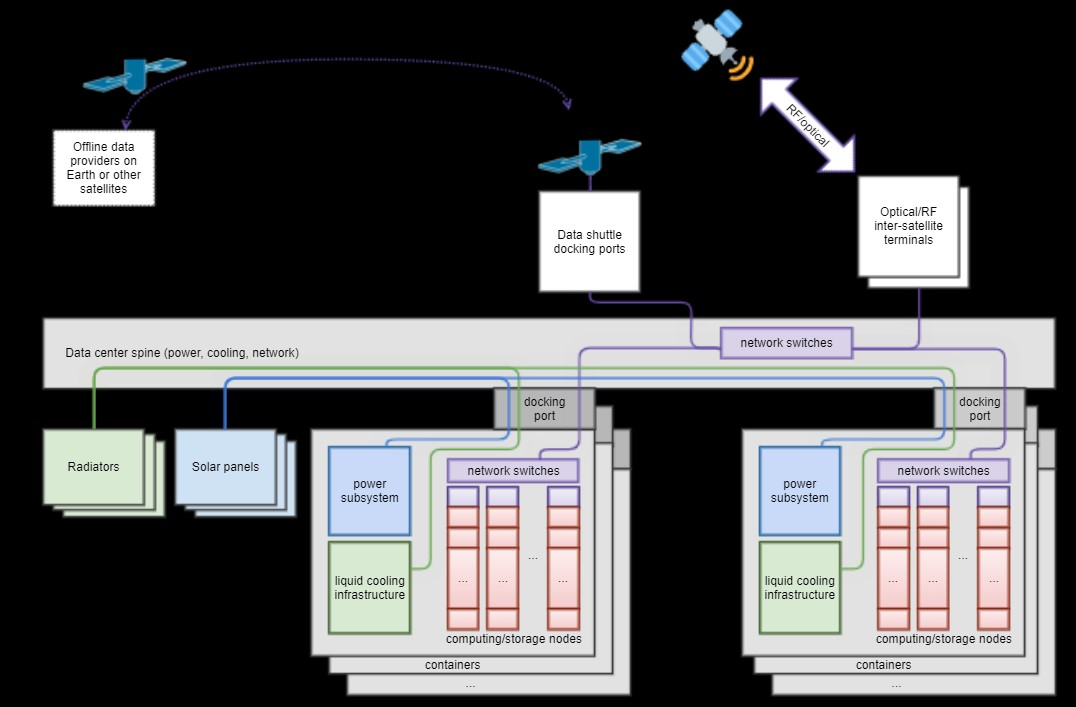 Lumen Orbit предлагает отправлять укомплектованные контейнеры с серверами и всем необходимым оборудованием, который имеют универсальный порт для питания, сети, охлаждения и т.д. Через этот порт они подключаются к единой «шине». ЦОД мощностью 5 ГВт потребует развёртывание солнечных элементов размером приблизительно 4 × 4 км. Подходящие панели уже выпускаются и стоят порядка $0,03/Ватт. Тяжёлые ракеты будущего смогут поднимать на орбиту около 100 т. Этого достаточно для доставки модуля с 300 наполовину заполненными стойками (остальное пойдёт на вспомогательные системы).  На 5-Гвт ЦОД ориентировочно потребуется менее 100 запусков при цене до $10/кг, а одной многоразовой ракеты будет достаточно для вывода на орбиту большого ЦОД за два-три месяца. Размещение на оптимальных орбитах и отсутствие некоторых агрессивных факторов влияния от нестабильных температур до окисления воздухом позволят эксплуатировать ЦОД в течение 15 лет, а многие компоненты можно будет использовать и после этого срока, говорит компания. Впрочем, в намерении Lumen Orbit нет ничего уникального. Ещё в конце 2023 года появлялась информация о том, что Axiom Space намерена построить космический дата-центр. Космический буксир Blue Ring Джеффа Безоса (Jeff Bezos) должен выполнять функции ЦОД, группировку спутников-суперкомпьютеров намерены создать даже итальянские военные, аналогичные проекты вынашивают и другие компании. Lumen Orbit тем временем получила финансовую поддержку от Y Combinator и NVIDIA.
09.09.2024 [16:00], Владимир Мироненко
Корпоративная ИИ-платформа под ключ: HPE и NVIDIA объявила о доступности HPE Private Cloud AI(HPE) объявила о доступности входящей в портфель NVIDIA AI Computing by HPE программно-аппаратной платформы HPE Private Cloud AI на базе GreenLake, разработанной совместно с NVIDIA для создания и запуска корпоративных приложений генеративного ИИ. По словам компании, ключевым отличием HPE Private Cloud AI являются решения для автоматизации и оптимизации приложений ИИ, позволяющие предприятию сократить сроки запуска виртуальных помощников с нескольких месяцев до мгновений. К числу таких решений («ускорителей» в терминологии HPE) относится виртуальный помощник на базе генеративного ИИ, который поможет разработчикам быстро создавать интерактивные чат-боты, отвечающие на вопросы на естественном языке, на основе собственных данных организации и открытых больших языковых моделей (LLM). Компании смогут с их помощью настраивать свои приложения ИИ для различных целей, таких как техническая поддержка, формирование коммерческих предложений, создание маркетингового контента и многое другое. Виртуального помощника можно усовершенствовать, добавив в будущем голосовой ввод, возможность работы с изображениями и многокомпонентную поддержку, обеспечивая более продвинутую генерацию контента и работу в режиме многозадачности. 
Источник изображений: HPE Как утверждает HPE, будущие пакеты решений будут включать в себя широко используемые приложения ИИ для вертикальных отраслей, включая финансовые услуги, здравоохранение, розничную торговлю, энергетику и государственный сектор. Они будут основаны на NVIDIA NIM Agent Blueprints, эталонных вариантах ИИ-решений, которые предприятия смогут постоянно совершенствовать на основе собственных данных и отзывов клиентов. «Предприятия ищут ускоренные, настраиваемые инструменты ИИ, подходящие для конкретных вариантов использования с учётом их специфики, — говорит Джастин Бойтано (Justin Boitano), вице-президент по корпоративным программным продуктам ИИ в NVIDIA. — NVIDIA NIM Agent Blueprints позволяет приложениям ИИ, разработанным с помощью HPE Private Cloud AI, совершенствоваться с использованием обратной связи от живых пользователей, улучшая модели в рамках непрерывного цикла обучения». 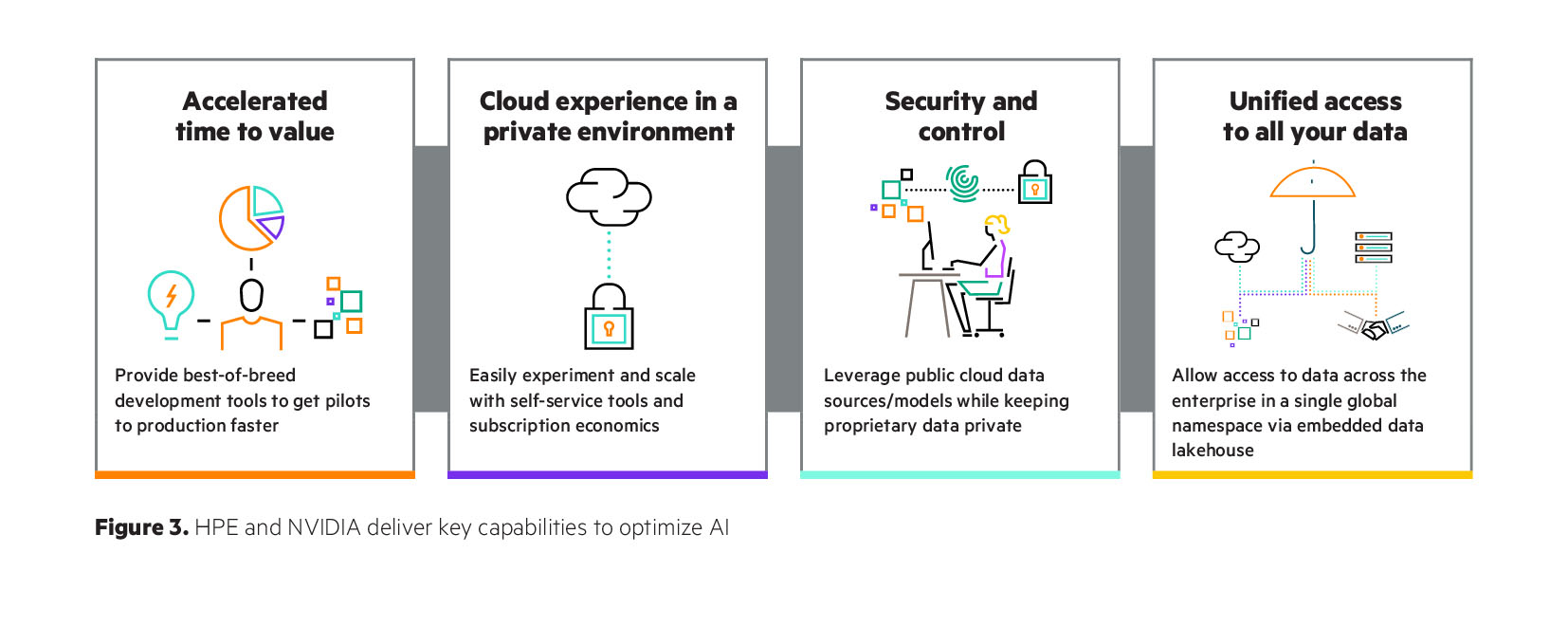 «Ускорители» HPE — это настраиваемые модульные low-code или no-code приложения, использующие микросервисы NVIDIA NIM. Эти проверенные и воспроизводимые решения упрощают развёртывание приложений ИИ, которое обычно включает приобретение новых навыков, принятие сложных рабочих нагрузок, а также интеграцию и настройку агентов, нескольких микросервисов, векторных баз данных, хранилищ данных, разрозненных источников данных, систем управления пользователями, масштабируемых серверов инференса, наборов данных, моделей ИИ и других ИТ-ресурсов. HPE также объявила о запуске партнёрской программы Unleash AI, разработанной для поддержки обширной экосистемы ведущих организаций-партнёров. Unleash AI является частью Technology Partner Program, входящей в инициативу HPE Partner Ready, которая дополнит HPE Private Cloud AI. Новая программа будет включать поставщиков на всех уровнях — от данных, моделей и приложений технологического стека до системных интеграторов и поставщиков услуг консалтинга, проектирования, внедрения и управления комплексными решениями для клиентов на основе ИИ. 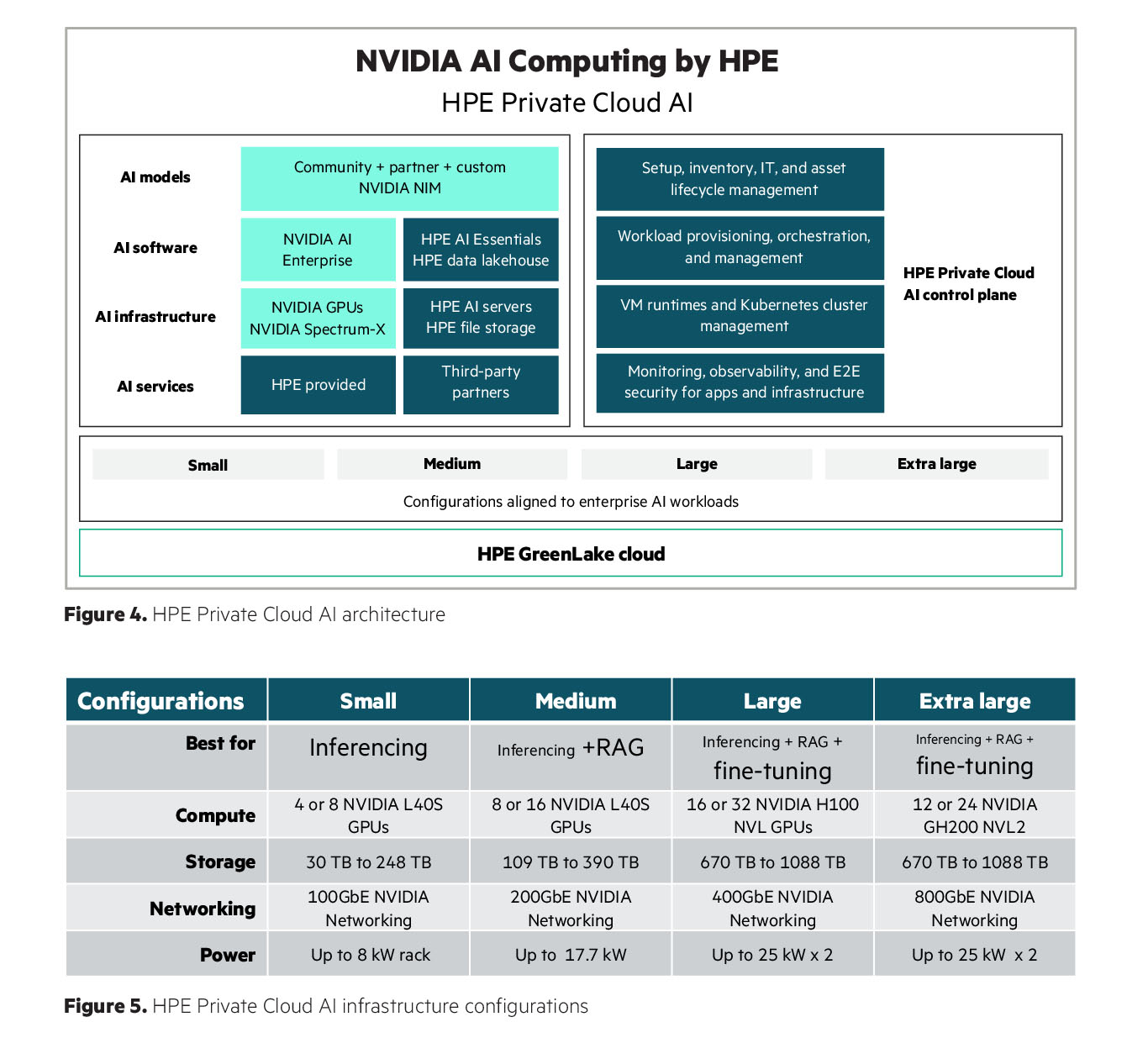 Решения партнёров, в том числе основанные на NVIDIA NIM Agent Blueprints, будут курироваться и предварительно проверяться для работы в HPE Private Cloud AI. Эта программа дополнит новую стратегию партнёрства в области ИИ, которую HPE объявила в сотрудничестве с NVIDIA.
09.09.2024 [11:08], Сергей Карасёв
Gigabyte представила серверы с ускорителями NVIDIA HGX H200 и СЖО
amd
coolit systems
emerald rapids
epyc
genoa
gigabyte
h200
hardware
intel
nvidia
sapphire rapids
xeon
сервер
Компания Giga Computing, подразделение Gigabyte, анонсировала серверы G593-ZD1-LAX3 и G593-SD1-LAX3, предназначенные для ресурсоёмких нагрузок, связанных с ИИ. Устройства, оснащённые системой прямого жидкостного охлаждения (DLC) от CoolIT, могут нести на борту до восьми ускорителей NVIDIA HGX H200. 
Источник изображений: Gigabyte Модель G593-ZD1-LAX3 выполнена в форм-факторе 5U. Допускается установка двух процессоров AMD EPYC 9004 поколения Genoa с показателем TDP до 400 Вт. Предусмотрены 24 слота для модулей оперативной памяти DDR5-4800. Во фронтальной части расположены отсеки для восьми SFF-накопителей (NVMe/SATA/SAS-4). Есть два коннектора М.2 для SSD типоразмера 2280/22110 с интерфейсом PCIe 3.0 x4 и PCIe 3.0 x1.  Доступны восемь слотов PCIe 5.0 x16 для низкопрофильных карт расширения и четыре разъёма PCIe 5.0 x16 для карт FHHL. В оснащение входят два порта 10GbE (Intel X710-AT2), два выделенных сетевых порта управления 1GbE, два разъёма USB 3.2 Gen1. В свою очередь, сервер G593-SD1-LAX3 рассчитан на два процессора Intel Xeon Emerald Rapids или Sapphire Rapids, величина TDP которых может достигать 350 Вт. Для модулей ОЗУ DDR5-4800/5600 предусмотрены 32 слота. Прочие характеристики (за исключением разъёмов М.2) аналогичны модели на платформе AMD.  Новые серверы укомплектованы шестью блоками питания мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Присутствует контроллер Aspeed AST2600. Диапазон рабочих температур — от 10 до +35 °C. Система DLC предназначена для отвода тепла от ускорителей NVIDIA HGX H200. При этом в области материнской платы и слотов PCIe установлены вентиляторы охлаждения.
08.09.2024 [23:18], Владимир Мироненко
Стартап Xockets обвинил NVIDIA и Microsoft в нарушении патентов на DPU и требует запретить выпуск ИИ-систем на базе BlackwellТехасский стартап Xockets подал в Окружной суд США по Западному округу Техаса в городе Уэйко (Waco) на NVIDIA и Microsoft, обвинив их в нарушении антимонопольного законодательства и патентных прав. Сам иск был опубликован на этой неделе на сайте Xockets. Согласно иску, NVIDIA незаконно использунт запатентованную Xockets технологию нового класса процессоров — Data Processing Unit (DPU), изобретённую соучредителем Xockets Парином Далалом (Parin Dalal) в 2012 году. Эта технология повышает эффективность облачной инфраструктуры, позволяя разгружать CPU, перенося на DPU рабочие нагрузки с интенсивным использованием данных, такие как обеспечение безопасности, обслуживание сетей и хранилищ, которые делают возможными распределённые вычисления в облачных ЦОД, а также обучение больших языковых моделей. Xockets подала свою первую патентную заявку на DPU в мае 2012 года и теперь владеет несколькими патентами, которые касаются её архитектуры и компоненты DPU. Как утверждает Xockets, технология является основополагающей для систем ИИ на базе ускорителей NVIDIA и ИИ-платформ Microsoft. По её словам, решения NVIDIA BlueField, ConnectX и NVLink Switch, основаны на её запатентованной технологии. Xockets сообщила, что её патенты были изначально нарушены компанией Mellanox после того, как DPU Xockets был продемонстрирован на конференции в 2015 году. И NVIDIA продолжила деор Mellanox после её приобретения в марте 2019 года за $6,9 млрд. Microsoft также указана в качестве нарушителя патентных прав, поскольку, являясь клиентом NVIDIA, имеет «привилегированный доступ к нарушающим права GPU-серверам NVIDIA для ИИ». 
Источник изображения: Xockets После подачи иска Xockets заявила: «Использование NVIDIA запатентованной технологии DPU Xockets позволило NVIDIA монополизировать сферу серверов ИИ на базе GPU, а Microsoft — сферу ИИ-платформ на базе GPU, что имеет решающее значение для их успеха и рыночной капитализации». Xockets также обвинила компании в картельном соглашении, выразившемся в создании организации под названием RPX по управлению патентными рисками, которая, по словам стартапа, была «сформирована по просьбе крупных технологических компаний для создания картелей покупателей интеллектуальной собственности», чтобы избежать уплаты справедливой рыночной цены за запатентованную технологию DPU Xockets. В иске указано, что Xockets пыталась лицензировать свою технологию NVIDIA и Microsoft, но компании заключили соглашение о проведении любых переговоров по лицензированию через RPX, которая также указана в иске в числе ответчиков. Xockets потребовала установить судебный запрет на деятельность незаконного картеля и выпуск новых ИИ-систем на базе ускорителей NVIDIA Blackwell, а также использование Microsoft систем Blackwell для своих платформ генеративного ИИ. Xockets также требует возмещения ущерба в максимально допустимом законом объёме.
08.09.2024 [13:28], Сергей Карасёв
CoreWeave и Run:ai помогут заказчикам в обучении ИИКомпания CoreWeave, предоставляющая облачные услуги для ИИ-задач, объявила о заключении партнёрского соглашения со стартапом Run:ai. В рамках сотрудничества клиентам будут предоставляться услуги для эффективного обучения ИИ и улучшения инференса. CoreWeave, учреждённая в 2017 году, изначально занималась майнингом криптовалют, а затем переориентировалась на вычисления общего назначения и хостинг проектов генеративного ИИ. Компания активно развивает инфраструктуру дата-центров. В апреле 2023-го CoreWeave получила $221 млн в ходе раунда финансирования Series B, а позднее привлекла на развитие ещё $200 млн. В августе 2023-го было объявлено о долговом финансировании в размере $2,3 млрд под залог ускорителей NVIDIA. В декабре прошлого года CoreWeave провела ещё один раунд финансирования — на $642 млн. В мае 2024-го компания получила $1,1 млрд, а затем привлекла дополнительно $7,5 млрд в виде долгового финансирования. 
Источник изображения: CoreWeave В свою очередь, стартап Run:ai основан в 2018 году: в марте 2022-го он получил $75 млн в ходе раунда финансирования Series C. Фирма специализируется на разработке ПО для управления рабочими нагрузками ИИ. Такие инструменты позволяют более эффективно использовать вычислительные ресурсы при работе с ИИ-приложениями. В апреле 2024 года NVIDIA заключила соглашение о приобретении Run:ai. Условия сделки не раскрываются, но, по имеющейся информации, стоимость может составлять до $1 млрд. При этом NVIDIA также является и инвестором CoreWeave. В рамках нового партнёрства клиенты CoreWeave смогут управлять рабочими нагрузками ИИ в своей инфраструктуре с помощью платформы Run:ai. Решения Run:ai разработаны для оптимизации использования вычислительных ресурсов в облачных средах. Утверждается, что платформа Run:ai, обеспечивающая масштабируемость, гибкость и экономическую эффективность, идеально дополняет облачную архитектуру CoreWeave. Среди ключевых преимуществ для заказчиков названы:
06.09.2024 [18:32], Руслан Авдеев
NVIDIA и другие инвесторы вложили $160 млн в оператора ИИ ЦОД Applied DigitalВзрывной рост ИИ сделал индустрию ЦОД одной из самых привлекательных сфер для вложения средств. Как сообщает The Register, NVIDIA совместно с другими инвесторами намерена вложить $160 млн в техасского оператора дата-центров Applied Digital, ранее известного как Applied Blockchain. Это не первый заметный игрок на рынке майнинговых ЦОД, которые переключился на ИИ и получил поддержку NVIDIA. Акции Applied Digital торгуются на Nasdaq, но по данным Silicon Angle, в данном случае компания привлекла финансирование посредством т.н. «частного размещения» (private placement), которое предусматривает прямую передачу акций инвесторам без посредничества биржи. При этом в сделке обычно участвуют заранее одобренные компании. Applied Digital выпустила 49,38 млн акций по $3,24 за каждую. Applied Digital занимается строительством дата-центров с СЖО для высокоплотных вычислений. Компания также сдаёт в аренду кластеры ускорителей, в частности, NVIDIA H200 и A40. Облачное подразделение — довольно весомая часть бизнеса Applied Digital. В финансовом году, закончившемся 31 марта, на его долю пришлось $29 млн из $165,6 млн общей выручки. За четыре последних месяца в эксплуатацию введено четыре новых ИИ-кластера, а ещё два запустят в ближайшие месяцы. 
Источник изображения: Applied Digital В августе Applied Digital объявила о строительстве 400 МВт ёмкостей для неназванного американского облачного оператора. Речь идёт о строящемся 100-МВт кампусе в Эллендейле (Северная Дакота) и двух других объектах. По данным СМИ, $160 млн новых инвестиций потратят на создание основы для раундов долгового финансирования, а оно уже будет истрачено на расширение кампуса ЦОД в Северной Дакоте и облачные инициативы компании. Интересно, что именно в этом штате две неизвестных компании готовы потратить $250 млрд на гигантские ИИ ЦОД. Поскольку передовые ускорители NVIDIA стоят порядка $30-40 тыс. каждый, некоторые операторы вынуждены обращаться за крупными займами. Так, в июле оператор CyrusOne занял $7,9 млрд для покупки новейших ускорителей, не считая $1,8 млрд, привлечённых ещё весной. В мае CoreWeave привлекла $1,1 млрд, а несколькими неделями позже убедила инвесторов одолжить ещё $7,5 млрд. Lambda Labs начала текущий год с раунда финансирования на $320 млн, ещё $500 млн она привлекла весной и теперь планирует закупить десятки тысяч новых ускорителей. Помимо традиционных венчурных инвесторов вроде BlackRock, Magnetar Capital и Coatue, в некоторых из подобных проектов участвует и сама NVIDIA, ранее уже поддерживавшая CoreWeave, которая прославилась тем, что взяла в долг $2,3 млрд под залог ускорителей, чтобы купить ещё больше ускорителей. Мотивация NVIDIA очевидна — продавать ускорители компания сможет до тех пор, пока на них есть спрос, а спрос может обеспечить только строительство новых дата-центров. |
|

