Материалы по тегу: epyc
|
27.09.2024 [16:40], Сергей Карасёв
Cloudflare представила серверы 12-го поколения на базе AMD EPYC Genoa-XАмериканская компания Cloudflare, предоставляющая в числе прочего услуги CDN, анонсировала серверы 12-го поколения для своей инфраструктуры. В основу 2U-узлов легла аппаратная платформа AMD EPYC Genoa-X. По словам компании, новая платформа на 145 % производительнее и при этом на 63 % энергоэффективнее систем 11-го поколения. Серверы имеют односокетное исполнение. Применён процессор EPYC 9684X с 96 ядрами (192 потока инструкций), работающий на базовой частоте 2,55 ГГц с возможностью повышения до 3,42 ГГц для всех ядер. Объём L3-кеша составляет 1152 Мбайт, а объём оперативной памяти DDR5-4800 в 12-канальной конфигурации составляет 384 Гбайт. В оснащения входят два накопителя формата EDSFF E1.S (15 мм) с интерфейсом PCIe 4.0 х4 вместимостью 7,68 Тбайт каждый (Samsung PM9A3 и Micron 7450 Pro). Заявленная скорость последовательного чтения информации достигает 6700 Мбайт/с, скорость последовательной записи — 4000 Мбайт/с. Показатель IOPS (операций ввода/вывода в секунду) при произвольном чтении — до 1,0 млн, при произвольной записи — до 200 тыс. Изделия рассчитаны на одну полную перезапись в сутки (DWPD). 
Источник изображений: Cloudflare Серверы оснащены двумя 25GbE-адаптерами OCP 3.0 — Intel Ethernet Network Adapter E810-XXVDA2 и NVIDIA Mellanox ConnectX-6 Lx. Присутствуют контроллеры ASPEED AST2600 (BMC), AST1060 (HRoT), а также TPM-модуль. Примечательно, что все они, а также сдвоенные чипы памяти BMC и BIOS/UEFI, находятся на внешней карте стандарта OCP DC-SCM 2.0. Их разработкой в рамках Project Argus компания занималась совместно с Lenovo.  За питание отвечают два блока мощностью 800 Вт с сертификатом 80 Plus Titanium. Допускается установка одной карты расширения FHFL двойной ширины или двух карт FHFL одинарной ширины. В частности, могут быть добавлены ускорители на базе GPU с показателем TDP до 400 Вт. Во фронтальной части корпуса располагаются вентиляторы охлаждения.
19.09.2024 [20:06], Юрий Лебедев
HPE представила компактный edge-сервер ProLiant DL145 Gen11 на базе AMD EPYC SienaHPE представила компактный однопроцессорный 2U-сервер ProLiant DL145 Gen11 на базе AMD EPYC 8004 Siena, предназначенный для перифийных вычислений, для которых характерен дефицит энергии, пространства или возможностей охлаждения. Сервер способен функционировать при температурах от -5 °C до +55 °C, имеет защиту от пыли и устойчив к вибрациям. 
Источник изображений: HPE Возможна установка 64-ядерного CPU с TDP до 200 Вт. Есть шесть слотов (1DPC) для модулей памяти DDR5-4800 ECC суммарной ёмкостью до 768 Гбайт. Дисковая корзина поддерживает установку двух SATA SFF или шести NVMe E3.S-накопителей. Опционально можно установить проприетарный модуль с двумя 480-Гбайт M.2 NVMe SSD, собранных в RAID1, для ОС. Для карт расширения доступно три слота PCIe 5.0 x16: два FHFL и один FHHL. Также есть слот OCP 3.0, тоже PCIe 5.0 x16.  Сервер оснащён системой удалённого управления iLO 6 с выделенным 1GbE-портом. Также на заднюю панель выведены четыре порта USB 3.0 Type-A и разъём DisplayPort. Опционально доступен последовательный порт с разъёмом RJ45. Для питания используются один или два (1+1) БП с сертификацией Platinum/Titanium мощностью 700 или 1000 Вт. Доступен и 700-Вт блок питания 48 В DC. Система вентиляции включает четыре вентилятора с резервированием N+1.  БП, все порты и слоты для удобства выведены на переднюю панель сервера. Фронтальная крышка может быть оснащена воздушным фильтром для защиты от пыли. Есть датчик вскрытия корпуса, блокировка передней панели и гнездо замка Kensington. Устройство имеет габариты 875 × 359 × 406 мм и весит до 15,6 кг. Возможно размещение как на столе/стене, так и в телекоммуникационной стойке. Новинка будет доступна в рамках HPE GreenLake.
17.09.2024 [23:07], Игорь Осколков
Швейцария ввела в эксплуатацию гибридный суперкомпьютер Alps: 11 тыс. NVIDIA GH200, 2 тыс. AMD EPYC Rome и щепотка A100, MI250X и MI300AШвейцарская высшая техническая школа Цюриха (ETH Zurich) провела церемонию официального запуска суперкомпьютера Alps в Швейцарском национальном суперкомпьютерном центре (CSCS) в Лугано. Система, построенная HPE, уже заняла шестую строчку в последнем рейтинге TOP500 и имеет устоявшеюся FP64-производительность 270 Пфлопс (теоретический пик — 354 Пфлопс). К ноябрю будут введены в строй остальные модули машины, и её максимальная производительность составит порядка 500 Пфлопс. 
Источник изображений: CSCS В июньском рейтинге TOP500 участвовал раздел из 2688 узлов HPE Cray EX254n с «фантастической четвёркой» NVIDIA Quad GH200. Если точнее, это всё же «старый» вариант ускорителя с H100 (96 Гбайт HBM3), 72-ядерным Arm-процессором Grace и 128 Гбайт LPDDR5x — суммарно 10 752 Grace Hopper. Данный раздел потребляет 5,2 МВт и в Green500 находится на 14 месте. Узлы, конечно же, используют СЖО. Это основной, но не единственный раздел суперкомпьютера. Ещё в 2020 году HPE развернула 1024 двухпроцессорных узла с 64-ядерными AMD EPYC 7742 (Rome) и 256/512 Гбайт RAM. Его производительность составляет 4,7 Пфлопс. Кроме того, в состав Alps входят 144 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя NVIDIA A100 (80 или 96 Гбайт HBM2e).  Наконец, машина получит 24 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя AMD Instinct MI250X (128 Гбайт HBM2e) и 128 узлов с четырьмя гибридными ускорителями AMD Instinct MI300A. Большая часть узлов будет объединена интерконнектом HPE Slingshot-11: 200G-подключение на узел или ускоритель. Более точную конфигурацию системы раскроют в ноябре. Lustre-хранилище для будущей машины обновили ещё в прошлом году. Основной СХД является Cray ClusterStor E1000 с подключением Slingshot-11. Так, было добавлено 100 Пбайт полезной HDD-ёмкости (8480 × 16 Тбайт) с пропускной способностью 1 Тбайт/с (300 тыс. IOPS на запись, 1,5 млн IOPS на чтение) и 5 Пбайт SSD, а также резервные ёмкости. За архивное хранение отвечают две ленточные библиотеки объёмом 130 Пбайт каждая.  Особенностью системы является её геораспределённость (фактически узлы размещены в четырёх местах) и облачная модель использования. Так, метеослужба страны MeteoSwiss получила в своё распоряжение выделенный виртуальный кластер, что уже позволило перейти на использование метеомодели более высокого разрешения, которая лучше отражает сложный рельеф Швейцарии. Кроме того, для подстраховки часть узлов Alps размещена на территории Федеральной политехнической школы Лозанны (EPFL). Alps приходит на смену суперкомпьютеру Piz Daint (Cray XC50/40, 21,2 Пфлопс), о завершении жизненного цикла которого было объявлено в конце июля 2024 года. В CSCS пока останутся машины Arolla + Tsa (для нужд MeteoSwiss) и Blue Brain 5 (решает задачи реконструкции и симуляции мозга). Alps же помимо традиционных HPC-нагрузок, будет использоваться для разработки ИИ-решений.
09.09.2024 [11:08], Сергей Карасёв
Gigabyte представила серверы с ускорителями NVIDIA HGX H200 и СЖО
amd
coolit systems
emerald rapids
epyc
genoa
gigabyte
h200
hardware
intel
nvidia
sapphire rapids
xeon
сервер
Компания Giga Computing, подразделение Gigabyte, анонсировала серверы G593-ZD1-LAX3 и G593-SD1-LAX3, предназначенные для ресурсоёмких нагрузок, связанных с ИИ. Устройства, оснащённые системой прямого жидкостного охлаждения (DLC) от CoolIT, могут нести на борту до восьми ускорителей NVIDIA HGX H200. 
Источник изображений: Gigabyte Модель G593-ZD1-LAX3 выполнена в форм-факторе 5U. Допускается установка двух процессоров AMD EPYC 9004 поколения Genoa с показателем TDP до 400 Вт. Предусмотрены 24 слота для модулей оперативной памяти DDR5-4800. Во фронтальной части расположены отсеки для восьми SFF-накопителей (NVMe/SATA/SAS-4). Есть два коннектора М.2 для SSD типоразмера 2280/22110 с интерфейсом PCIe 3.0 x4 и PCIe 3.0 x1.  Доступны восемь слотов PCIe 5.0 x16 для низкопрофильных карт расширения и четыре разъёма PCIe 5.0 x16 для карт FHHL. В оснащение входят два порта 10GbE (Intel X710-AT2), два выделенных сетевых порта управления 1GbE, два разъёма USB 3.2 Gen1. В свою очередь, сервер G593-SD1-LAX3 рассчитан на два процессора Intel Xeon Emerald Rapids или Sapphire Rapids, величина TDP которых может достигать 350 Вт. Для модулей ОЗУ DDR5-4800/5600 предусмотрены 32 слота. Прочие характеристики (за исключением разъёмов М.2) аналогичны модели на платформе AMD.  Новые серверы укомплектованы шестью блоками питания мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Присутствует контроллер Aspeed AST2600. Диапазон рабочих температур — от 10 до +35 °C. Система DLC предназначена для отвода тепла от ускорителей NVIDIA HGX H200. При этом в области материнской платы и слотов PCIe установлены вентиляторы охлаждения.
02.09.2024 [12:12], Сергей Карасёв
HPE создала суперкомпьютер Iridis 6 на платформе AMD для Саутгемптонского университетаКомпания НРЕ поставила в Саутгемптонский университет в Великобритании высокопроизводительный вычислительный комплекс Iridis 6, построенный на аппаратной платформе AMD. Использовать суперкомпьютер планируется для проведения исследований в таких областях, как геномика, аэродинамика и источники питания нового поколения. В основу Iridis 6 положены серверы HPE ProLiant Gen11 на процессорах AMD EPYC семейства Genoa. Задействованы 138 узлов, каждый из которых насчитывает 192 вычислительных ядра и несёт на борту 3 Тбайт памяти. Таким образом, в общей сложности используются 26 496 ядер. В частности, в состав Iridis 6 включены четыре узла с 6,6 Тбайт локального хранилища, а также три узла входа с хранилищем вместимостью 15 Тбайт. Используется интерконнект Infiniband HDR100. В HPE сообщили, что в настоящее время система обеспечивает производительность HPL (High-Performance Linpack) на уровне примерно 1 Пфлопс. В дальнейшем количество узлов планируется увеличивать, что позволит поднять быстродействие. 
Источник изображения: НРЕ Отмечается, что Iridis 6 приходит на смену суперкомпьютеру Iridis 4, который имел немногим более 12 тыс. вычислительных ядер. При этом новая система будет сосуществовать с комплексом Iridis 5, который использует процессоры Intel Xeon Gold 6138, AMD 7452 и AMD 7502, а также ускорители NVIDIA Tesla V100, GTX 1080 Ti и А100. Эта машина была запущена в 2018-м и заняла 354-е место в списке TOP500 самых мощных суперкомпьютеров мира, опубликованном в июне того же года. Быстродействие Iridis 5 достигает 1,31 Пфлопс.
21.08.2024 [15:02], Елена Копытова
AMD взялась за поддержку современных EPYC во FreeBSDПроект FreeBSD опубликовал отчёт за II квартал 2024 года, в котором описана проделанная работа ведущими разработчиками BSD. По данным Phoronix, среди выполненных за последний квартал задач FreeBSD Foundation выделяются проекты по улучшению аудиостека, улучшению OpenZFS, переносу VPP (Vector Packet Processing) на FreeBSD и улучшению поддержки беспроводных сетей. Также стало известно, что AMD и FreeBSD Foundation сотрудничают в разработке полноценного драйвера AMD IOMMU. Цель проекта — улучшить поддержку серверов на базе AMD EPYC во FreeBSD, в том числе с более чем 256 ядрами, сделать интеграцию с системой виртуализации Bhyve и другие усовершенствования. «Продолжалась работа над совместным проектом Advanced Micro Devices (AMD) и FreeBSD Foundation по разработке драйвера AMD IOMMU. Этот драйвер позволит FreeBSD полностью поддерживать более 256 ядер с такими функциями, как отображение [mapping] CPU, а также будет включать интеграцию Bhyve. Константин Белоусов работал над различными частями проекта, включая подключение драйвера, определение регистров, парсер таблиц ACPI и реализацию служебных функций. Два ключевых компонента, которые необходимо доделать, — это обработка контекста, которая в основном является обобщением кода Intel DMAR, и создание таблиц страниц. После этого можно будет активировать драйвер AMD для тестирования. Чтобы следить за работой Константина, ищите коммиты в репозитории с тегом «Sponsored by fields for Advanced Micro Devices (AMD) and The FreeBSD Foundation»», — говорится в отчёте. Источник изображения: FreeBSD Появление поддержки со стороны AMD для сообщества FreeBSD является значимым событием, поскольку ранее только Intel славилась активным вкладом в развитие проекта и предоставлением инженерных ресурсов на протяжении многих лет. В этом свете интересно, является ли поддержка AMD жестом доброй воли или же у компании есть клиенты, которым необходимы совместимость и оптимизации для FreeBSD. Среди крупных игроков, в инфраструктуре которых активно используется FreeBSD, есть, например, Netflix. В последние годы Arm также начала активно участвовать в развитии ОС. Кроме того, FreeBSD продолжает активную работу по поддержке архитектуры RISC-V. Так, уже существует экспериментальная поддержка Bhyve. Кроме того, одной из новых разработок для ядра FreeBSD стало создание Zcond — легковесного механизма условного выполнения, аналогичного интерфейсу static_key в Linux.
19.08.2024 [10:10], Сергей Карасёв
Gigabyte представила ИИ-серверы с ускорителями NVIDIA H200 и процессорами AMD и IntelКомпания Gigabyte анонсировала HGX-серверы G593-SD1-AAX3 и G593-ZD1-AAX3, предназначенные для задач ИИ и НРС. Устройства, выполненные в форм-факторе 5U, включают до восьми ускорителей NVIDIA H200. При этом используется воздушное охлаждение. 
Источник изображений: Gigabyte Модель G593-SD1-AAX3 рассчитана на два процессора Intel Xeon Emerald Rapids с показателем TDP до 350 Вт, а версия G593-ZD1-AAX3 располагает двумя сокетами для чипов AMD EPYC Genoa с TDP до 300 Вт. Доступны соответственно 32 и 24 слота для модулей оперативной памяти DDR5.  Серверы наделены восемью фронтальными отсеками для SFF-накопителей NVMe/SATA/SAS-4, двумя сетевыми портами 10GbE на основе разъёмов RJ-45 (выведены на лицевую панель) и выделенным портом управления 1GbE (находится сзади). Есть четыре слота FHHL PCIe 5.0 x16 и восемь разъёмов LP PCIe 5.0 x16. Модель на платформе AMD дополнительно располагает двумя коннекторами М.2 для SSD с интерфейсом PCIe 3.0 x4 и x1.  Питание у обоих серверов обеспечивают шесть блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. Габариты новинок составляют 447 × 219,7 × 945 мм. Диапазон рабочих температур — от +10 до +35 °C. Есть два порта USB 3.2 Gen1 и разъём D-Sub. Массовое производство серверов Gigabyte серии G593 запланировано на II половину 2024 года. Эти системы станут временной заменой (G)B200-серверов, выпуск которых задерживается.
13.08.2024 [11:19], Сергей Карасёв
MSI представила сервер S2301 с поддержкой CXL на базе AMD EPYC TurinКомпания MSI в ходе выставки Future of Memory and Storage 2024 (FMS) анонсировала сервер S2301, предназначенный для работы с резидентными базами данных, НРС-приложениями, платформами для автоматизации проектирования электроники (EDA) и пр. Сервер поддерживает стандарт CXL 2.0 на основе интерфейса PCIe. Технология обеспечивает высокоскоростную передачу данных с малой задержкой между хост-процессором и такими устройствами, как серверные ускорители, буферы памяти и интеллектуальные IO-блоки. На основе CXL 2.0 функционирует высокопроизводительный механизм доступа к памяти, который позволяет модулям расширения напрямую взаимодействовать с иерархией памяти CPU. При этом дополнительные блоки памяти работают так, как если бы они были частью собственной памяти системы. Подключив к серверу модули расширения CXL, можно с высокой эффективностью масштабировать ресурсы для обработки сложных задач. 
Источник изображения: MSI Сервер MSI S2301 поддерживает установку двух процессоров AMD EPYC поколения Turin. Доступны 24 слота для модулей ОЗУ. Возможно применение CXL-модулей в форм-факторе E3.S 2T (PCIe 5.0 x8). Такие решения, в частности, в августе 2023 года представила компания Micron Technology. Устройства имеют вместимость 128 и 256 Гбайт. Кроме того, память DRAM с поддержкой CXL 2.0 предлагает Samsung. Во фронтальной части нового сервера располагаются отсеки для SFF-модулей. Говорится об использовании софта Memory Machine X разработки MemVerge, который оптимизирует затраты и помогает улучшить производительность ИИ-приложений и других ресурсоёмких рабочих нагрузок путём интеллектуального управления памятью.
25.07.2024 [10:12], Владимир Мироненко
AMD показала превосходство чипов EPYC над Arm-процессорами NVIDIA Grace в серии бенчмарков, но не всё так простоAMD провела серию тестов, чтобы доказать преимущество своих нынешних процессоров AMD EPYC над Arm-процессорами NVIDIA Grace Superchip. Как отметила AMD, в связи с растущей востребованностью ЦОД некоторые компании начали предлагать альтернативные варианты процессоров, «часто обещающие преимущества по сравнению с обычными решениями x86». «Обычно их представляют с большой помпой и заявлениями о значительных преимуществах в производительности и энергоэффективности по сравнению с x86. Слишком часто эти утверждения довольно сложно воплотить в реальные сценарии конкурентной рабочей нагрузки — с использованием устаревших, недостаточно оптимизированных альтернатив или плохо документированных предположений», — отметила AMD. С помощью серии стандартных отраслевых тестов AMD, по её словам, продемонстрировала преимущество EPYC над решениями на базе Arm. «Благодаря проверенной архитектуре x86-64, впервые разработанной AMD, вы можете получить всё это без дорогостоящего портирования или изменений в архитектуре», — подчеркнула компания. Иными словами, тесты AMD могут быть просто попыткой развеять опасения, что архитектура x86 «выдыхается» и что Arm берёт верх. 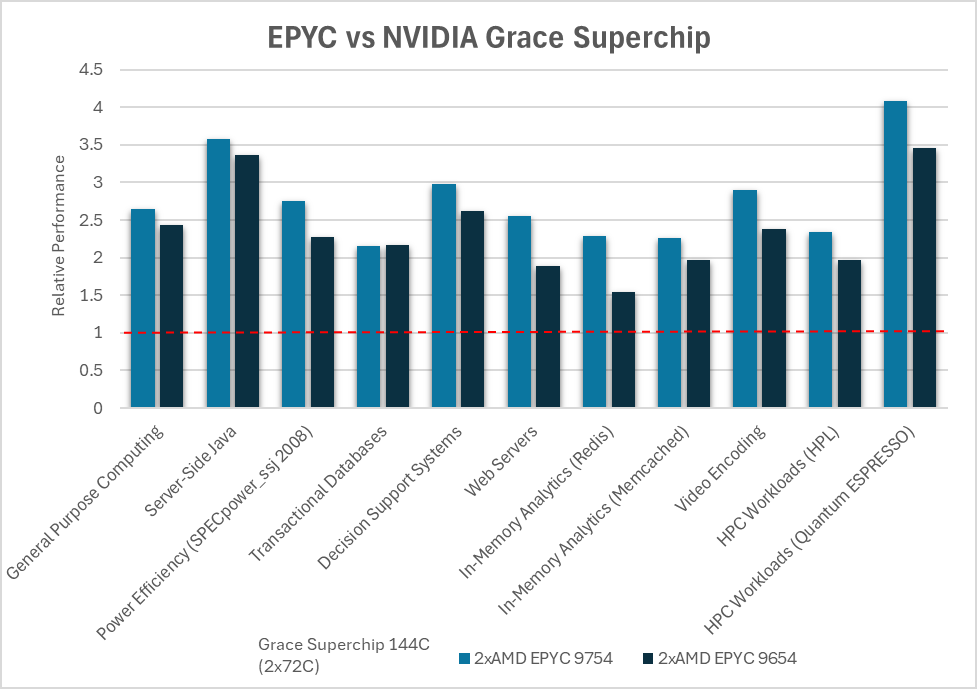
Источник изображений: AMD AMD сравнила производительность AMD EPYC и NVIDIA Grace CPU в десяти ключевых рабочих нагрузках, охватывающих вычисления общего назначения, Java, транзакционные базы данных, системы поддержки принятия решений, веб-серверы, аналитику, кодирование видео и нагрузки HPC. Согласно представленному выше графику, 128-ядерный процессор EPYC 9754 (Bergamo) и 96-ядерный EPYC 9654 (Genoa) более чем вдвое превзошли NVIDIA Grace CPU Superchip по производительности при обработке вышеуказанных нагрузок. Напомним, что Grace CPU Superchip содержит два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2, соединённых шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работает как единый 144-ядерный процессор. В свою очередь, ресурс The Register отметил, что речь идёт о версии с 480 Гбайт памяти LPDDR5x, а не с 960 Гбайт. 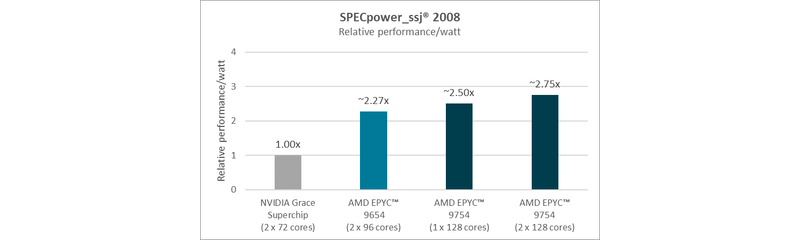 В тесте SPECpower-ssj2008, по данным AMD, одно- и двухсокетные системы на базе AMD EPYC 9754 превосходят систему NVIDIA Grace CPU Superchip по производительности на Вт примерно в 2,50 раза и 2,75 раза соответственно, а двухсокетная система AMD EPYC 9654 — примерно в 2,27 раза. Помимо производительности и эффективности, ещё одним важным фактором для операторов ЦОД является совместимость, сообщила AMD. По оценкам, во всем мире существуют триллионы строк программного кода, большая часть которого написана для архитектуры x86. EPYC основаны на архитектуре x86-64, впервые разработанной AMD, и эта архитектура является наиболее широко используемой и поддерживаемой в индустрии ЦОД, заявила компания, добавив, что изменения в архитектуре сложны, дороги и чреваты риском. AMD также отметила, что экосистема AMD EPYC включает более 250 различных конструкций серверов и поддерживает около 900 уникальных облачных инстансов. Также процессоры AMD EPYC установили более 300 мировых рекордов производительности и эффективности в широком спектре тестов. В то же время лишь немногие Arm-решения доказали свою эффективность. В свою очередь, ресурс The Register отметил, что ситуация не так проста, как AMD пытается всех убедить. В феврале сайт The Next Platform сообщил, что исследователи из университетов Стоуни-Брук и Буффало сравнили данные о производительности суперчипа NVIDIA Grace CPU Superchip и нескольких процессоров x86, предоставленные несколькими НИИ и разработчиком облачных решений. 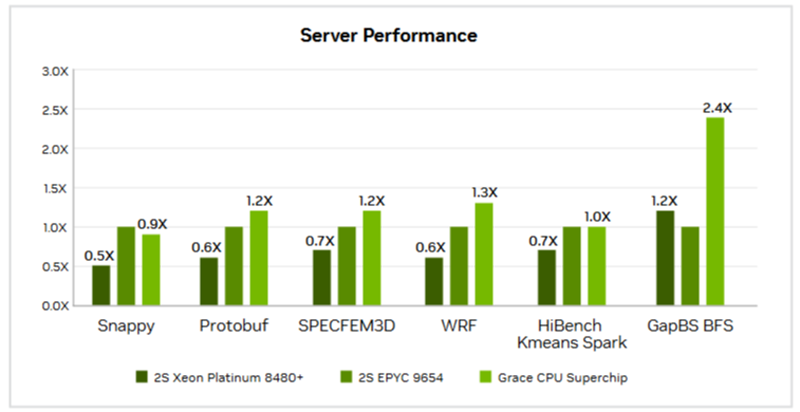
Источник изображений: NVIDIA Большинство этих тестов были ориентированы на HPC, включая Linpack, HPCG, OpenFOAM и Gromacs. И хотя производительность системы Grace сильно различалась в разных тестах, в худшем случае она находилась где-то между Intel Skylake-SP и Ice Lake-SP, превосходя AMD Milan и находясь в пределах досягаемости от показателей Xeon Max. Данные результаты отражают тот факт, что самые мощные процессоры AMD EPYC Genoa и Bergamo могут превзойти первый процессор NVIDIA для ЦОД — при правильно выбранном тесте. 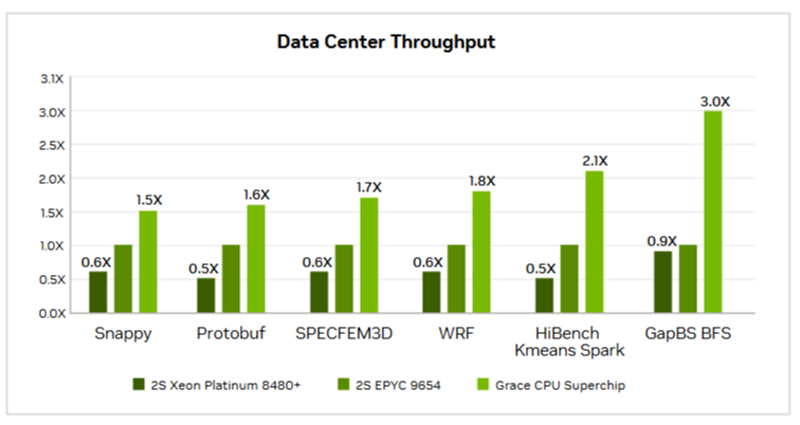 В техническом описании Grace CPU Superchip компания NVIDIA сообщает, что этот чип обеспечивает от 0,9- до 2,4-кратного увеличения производительности по сравнению с двумя 96-ядерными EPYC 9654 и предлагает до трёх раз большую пропускную способность в различных облачных и HPC-сервисах. NVIDIA отмечает, что Superchip предназначен для «обработки массивов для получения интеллектуальных данных с максимальной энергоэффективностью», говоря об ИИ, анализе данных, нагрузках облачных гиперскейлеров и приложениях HPC.
24.07.2024 [10:58], Сергей Карасёв
ASUS представила плату Pro WS 665-ACE для рабочих станций с ИИ на базе AMD EPYC 4004Компания ASUS анонсировала материнскую плату Pro WS 665-ACE, предназначенную для построения рабочих станций, рассчитанных на работу с приложениями ИИ. Новинка, выполненная в форм-факторе АТХ, допускает установку одного процессора AMD EPYC 4004 в исполнении AM5. Плата располагает четырьмя разъёмами для модулей оперативной памяти DDR5. Реализована фирменная технология OptiMem II: оптимизированная разводка слотов способствует снижению перекрёстных наводок и улучшает целостность сигнала, что обеспечивает стабильную работу даже при использовании памяти с высокой частотой. Для подключения накопителей доступны четыре порта SATA-3. Предусмотрены два разъёма OCuLink (PCIe 4.0 x4), а также три слота PCIe 4.0 x16. Применён сетевой контроллер Intel I225-LM с поддержкой 2.5GbE. 
Источник изображения: ASUS Плата поставляется с программным обеспечением ASUS Control Center Express, которое предназначено для эффективного централизованного управления компьютерной инфраструктурой на базе корпоративных и коммерческих продуктов через удобный пользовательский интерфейс. У модели Pro WS 665-ACE процессорный разъём развёрнут на 90°. Отмечается, что новинку можно применять в серверах начального уровня для дата-центров и облачных платформ. Компания ASUS также представила ряд других продуктов с поддержкой чипов AMD EPYC 4004. В их число вошли сервер Pro ER100A B6 формата 1U, рабочая станция ExpertCenter Pro ET500A B6 с поддержкой памяти DDR5-5200 и двумя коннекторами для накопителей M.2, компактная материнская плата Pro WS 600M-CL. |
|

