Материалы по тегу: ии
|
21.07.2023 [15:35], Сергей Карасёв
NVIDIA, подвинься: Cerebras представила 4-Эфлопс ИИ-суперкомпьютер Condor Galaxy 1 и намерена построить ещё восемь таких жеКомпания Cerebras Systems анонсировала суперкомпьютер Condor Galaxy 1 (CG-1), предназначенный для решения ресурсоёмких задач с применением ИИ. Это одна из первых действительно крупных машин на базе уникальных чипов Cerebras. В проекте стоимостью $100 млн приняла участие холдинговая группа G42 из ОАЭ, которая занимается технологиями ИИ и облачными вычислениями. G42 является основным заказчиком комплекса. В текущем виде комплекс CG-1, расположенный в Санта-Кларе (Калифорния, США), объединяет 32 системы Cerebras CS-2 и обеспечивает производительность на уровне 2 Эфлопс (FP16). В IV квартале ткущего года будут добавлены ещё 32 системы Cerebras CS-2, что позволит довести быстродействие до 4 Эфлопс (FP16). Ожидаемый уровень энергопотребления составит порядка 1,5 МВт или более. 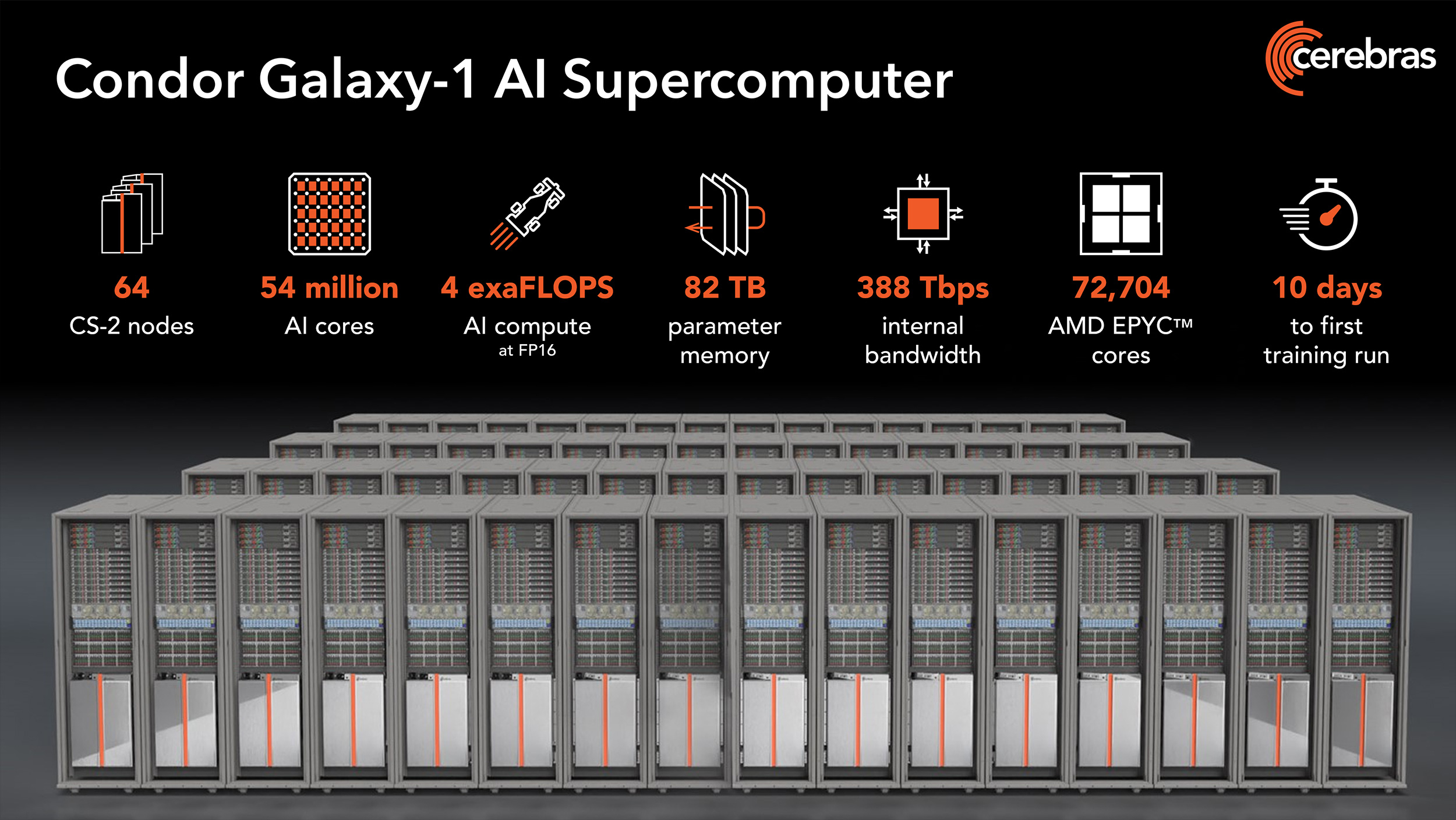
Источник изображений: Cerebras (via ServeTheHome) В системах Cerebras CS-2 применяются гигантские чипы Wafer-Scale Engine 2 (WSE-2), насчитывающие 2,6 трлн транзисторов. Такие чипы имеют 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Системы выполнены в формате 15 RU и укомплектованы шестью блоками питания мощностью 4 кВт каждый. Задействована технология жидкостного охлаждения. Отдельно отмечается, что программный стек позволит без проблем и существенных модификаций кода работать с ИИ-моделями.  После ввода в строй второй очереди комплекс CG-1 суммарно получит 54,4 млн ИИ-ядер, 2,56 Тбайт SRAM и внутренний интерконнект со скоростью 388 Тбит/с. Их дополнят 72 704 ядра AMD EPYC Milan и 82 Тбайт памяти для хранения параметров. По словам создателей, мощностей суперкомпьютера хватит для обучения модели с 600 млрд параметров и на очередях длиной до 50 тыс. токенов. При этом производительность масштабируется практически линейно.  Cerebras и G42 будут предоставлять доступ к CG-1 по облачной схеме, что позволит заказчикам использовать ресурсы ИИ-суперкомпьютера без необходимости управлять моделями или распределять их по узлам и ускорителям. CG-1 — первый из трёх ИИ-суперкомпьютеров нового поколения. В I полугодии 2024 года будут построены комплексы CG-2 и CG-3, полностью аналогичные CG-1, которые будут объединены в распределённый ИИ-кластер. А к концу следующего года у Cerebras будет уже девять систем CG.  Для Cerebras это означает, что компания более не является стартапом, поскольку в её решения заказчики поверили и без участия в индустриальных тестах вроде MLPerf. Кроме того, теперь компания является не просто очередным производителем «железа», а предоставляет услуги, которые и помогут ей заработать в будущем.
20.07.2023 [23:30], Игорь Осколков
AMD, Broadcom, Cisco, Intel и другие вендоры создадут интерконнект Ultra Ethernet для HPC и ИИAMD, Arista, Broadcom, Cisco, Eviden (Atos), HPE, Intel, Meta✴ и Microsoft в рамках Linux Foundation сформировали новый консорциум Ultra Ethernet Consortium, который намерен создать на базе Ethernet новый масштабируемый и эффективный с точки зрения стоимости коммуникационный стек, ориентированный на высокопроизводительные вычисления (HPC) и ИИ. Иными словами, речь идёт о создании спецификаций интерконнекта нового поколения на базе Ethernet для современных кластеров, облаков и иных платформ. UEC сформировал четыре рабочих группы, ответственных за физический, канальный и транспортный уровни, а также за уровень ПО. Целью же является создание современного сетевого стека, который учитывает потребности HPC- и ИИ-нагрузок, включая новые методы борьбы с заторами в сети, высокий уровень утилизации канала (в том числе 800G/1.6T), многопутевую и гарантированную доставку, сквозную телеметрию, консистентность и низкий уровень задержек, автоматизацию, безопасность и защищённость, масштабируемость, стабильность, надёжность, снижение TCO и так далее. 
Источник: Ultra Ethernet Consortium Фактически отдельные вендоры уже наделили рядом перечисленных свойств свои продукты, однако унификация и объединение усилий, как считается, должны пойти на пользу всем. Всем, кроме, по-видимому, NVIDIA, которой в списке основателей UEC нет (как и Marvell, к слову). NVIDIA после поглощения Mellanox фактически стала монополистом на рынке InfiniBand, который она активно продвигает, не забывая, впрочем, и о своём проприетарном интерконнекте NVLink, который в последней своей версии выбрался за пределы узла. Справедливости ради — про Ethernet компании тоже не забывает. В обзоре UEC аккуратно критикуется и InfiniBand, и его адаптация в виде RoCE. Авторы указывают на правильность и успешность идеи RDMA, но жалуются на не слишком высокую практичность и удобство современных реализаций. И именно поэтому они первым делом предлагают внедрить новый транспортный протокол Ultra Ethernet Transport (UET), который и позволит реализовать интерконнект будущего, а заодно ещё раз доказать эффективность и гибкость технологии Ethernet, которой в этом году исполнилось 50 лет. Впрочем, это только один из кирпичиков UEC. Примечательно, что первые продукты на базе новых спецификаций обещали показать уже в 2024 году.
09.06.2023 [22:52], Сергей Карасёв
Анонсирован китайский ускоритель Metax Xisi N100 для ИИ и потоковой обработки видеоКитайская компания Metax, по сообщению ресурса ITHome, разработала ускоритель Xisi N100, предназначенный для решения задач, связанных с обработкой видеоматериалов, алгоритмами ИИ и пр. Новинка уже готова к серийному производству и в скором времени поступит на местный рынок. Технических подробностей относительно Xisi N100 пока не слишком много. Известно, что основой ускорителя служит GPU с обозначением MXN100. Обеспечивается 128-канальное кодирование и 96-канальное декодирование. Заявлена поддержка форматов HEVC, H.264, AV1 и AVS2, а также разрешений вплоть до 8К. Ускоритель выполнен в виде однослотовой карты расширения с интерфейсом PCIe. Применено пассивное охлаждение. Заявленное быстродействие достигает 160 TOPS при вычислениях INT8 и 80 Тфлопс на операциях FP16. 
Источник изображений: ITHome Metax намерена в 2025 году выпустить GPU для игровых приложений. Чип получит поддержку всех основных методов рендеринга графики и сможет использовать современные API. Кроме того, Metax обещает предоставить оптимизированное ПО и необходимые драйверы: это, как ожидается, поможет в продвижении продукта на коммерческом рынке.  Разработка собственных GPU важна для Китая в условиях торговой войны с США. Из-за американских санкций NVIDIA прекратила поставки в Поднебесную ускорителей A100 и H100: компании пришлось выпустить экспортные варианты названных изделий, не подпадающие под ограничения.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения.
19.05.2023 [10:20], Сергей Карасёв
Meta✴ представила ИИ-процессор MTIA для дата-центров — 128 ядер RISC-V и потребление всего 25 ВтMeta✴ анонсировала свой первый кастомизированный процессор, разработанный специально для ИИ-нагрузок. Изделие получило название MTIA v1, или Meta✴ Training and Inference Accelerator: оно оптимизировано для обработки рекомендательных моделей глубокого обучения. Проект MTIA является частью инициативы Meta✴ по модернизации архитектуры дата-центров в свете стремительного развития ИИ-платформ. Утверждается, что чип MTIA v1 был создан ещё в 2020 году. Это интегральная схема специального назначения (ASIC), состоящая из набора блоков, функционирующих в параллельном режиме. 
Источник изображений: Meta✴ Известно, что при производстве MTIA v1 используется 7-нм технология. Конструкция включает 128 Мбайт памяти SRAM. Чип может использовать до 64/128 Гбайт памяти LPDDR5. Задействован фреймворк машинного обучения Meta✴ PyTorch с открытым исходным кодом, который может применяться для решения различных задач в области компьютерного зрения, обработки естественного языка и пр. 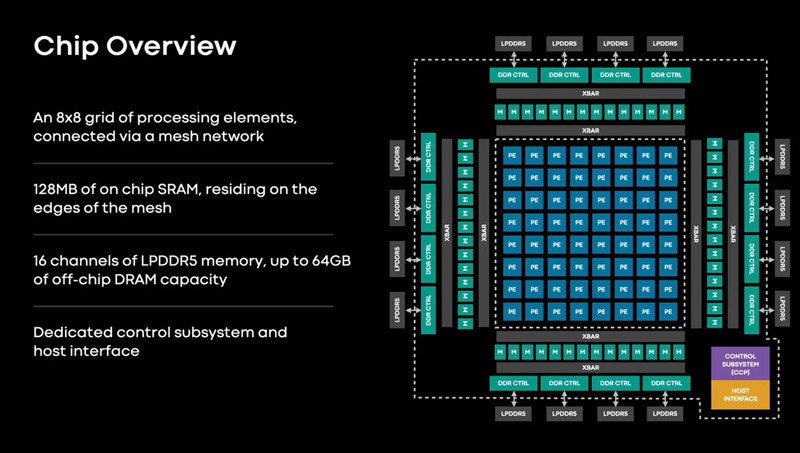 Процессор MTIA v1 имеет размеры 19,34 × 19,1 мм. Он содержит 64 вычислительных элемента в виде матрицы 8 × 8, каждый из которых объединяет два ядра с архитектурой RISC-V. Тактовая частота достигает 800 МГц, заявленный показатель TDP — 25 Вт. Meta✴ признаёт, что у MTIA v1 присутствуют «узкие места» при работе с ИИ-моделями большой сложности: требуется оптимизация подсистем памяти и сетевых соединений. Однако в случае приложений низкой и средней сложности платформа, как утверждается, обеспечивает более высокую эффективность по сравнению с GPU. 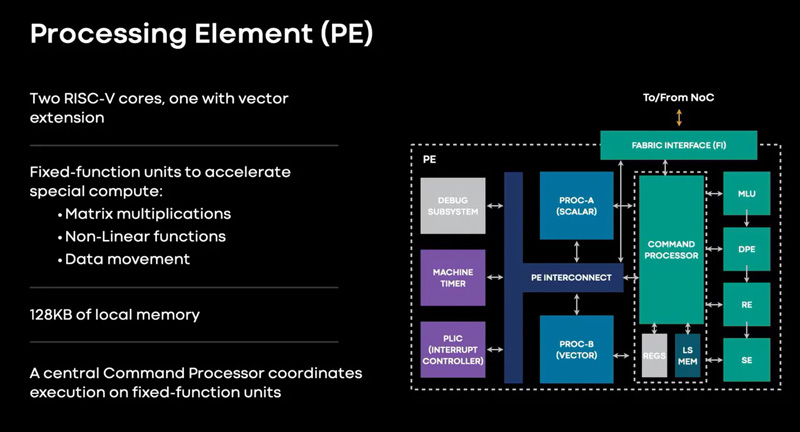 В дальнейшем в семействе MTIA появятся более производительные изделия, но подробности о них не раскрываются. Ранее говорилось, что Meta✴ создаёт некий секретный чип, который подойдёт и для обучения ИИ-моделей, и для инференса: это решение может увидеть свет в 2025 году.
16.05.2023 [19:10], Руслан Авдеев
Поллитра воды на полсотни вопросов: ИИ-серверы с ChatGPT потребляют не только много энергии, но и немало воды для охлажденияХотя в генеративных ИИ-моделях вроде GPT-4 или Midjourney отдельные эксперты усматривают много угроз человечеству, далеко не все обращают внимание на важный фактор — не исключено, что скоро ИИ и люди будут конкурировать за обычную пресную воду. Как сообщает The Register, по прогнозам учёных, её будет всё больше требоваться для охлаждения ЦОД. Проблема привлекла внимание учёных Калифорнийского университета в Риверсайде и Техасского университета в Арлингтоне. По оценкам исследователей, обучение языковой модели уровня GPT-3 требует использования около 700 тыс. литров воды — столько тратится на выпуск 320 электромобилей Tesla. Более того, на простой диалог из 20-50 вопросов ChatGPT требуется около 500 мл воды, а с развитием ИИ потребление воды такими системами достигнет огромных масштабов — если заранее не принять меры по оптимизации охлаждения ЦОД. 
Источник изображения: Drew Dizzy Graham/unsplash.com При этом эксперты обещают, что к середине века огромные территории в США будут страдать от засухи. Уже сейчас ЦОД крайне неохотно делятся информацией о потреблении воды, при этом используя разные системы подсчёта и, как Google, пытаясь скрыть следы в судебном порядке. В результате учёным приходится при расчётах пользоваться преимущественно косвенными данными. Впрочем, утверждается, что можно повсеместно использовать модель, разработанную SPX Cooling Technologies, и это позволит определить, сколько воды уходить на обучение и эксплуатацию языковых моделей. Но, как считают в Dell'Oro Group, проблема на деле не в ИИ — он не испытывает настоящей жажды. В первую очередь речь идёт о рационализации систем терморегулирования. Даже от того, где находится ЦОД с ИИ, может значительно меняться потребление воды. Многие ЦОД используют не жидкостное охлаждение, а другие варианты. Например, в прошлом месяце Microsoft говорит об использовании систем с нулевым водопотреблением в ЦОД Аризоны — но они потребляют больше энергии. Предлагается немало вариантов — от воздушного до водяного или погружного охлаждения, каждый из которых имеют свои преимущества и недостатки. Впрочем, вендоры вроде Submer и LiquidStack предлагают системы иммерсионного охлаждения, обеспечивающие PUE на уровне менее 1,05, тогда как системы воздушного охлаждения обычно обеспечивают лишь 1,4–1,5. 
Источник изображения: redcharlie | @redcharlie1/unsplash.com В научной работе приводятся не только возможные пути оптимизации систем охлаждения, но и рекомендации для того, чтобы ЦОД в принципе выделяли меньше тепла. В частности, речь идёт о том, что дата-центры стоит строить в местах с прохладным климатом вместо жарких азиатских стран, а некоторые задачи можно выполнять во второй половине дня, когда становится прохладнее. Хотя это ограничивает использование солнечных элементов питания, сам собой напрашивается вывод о применении резервных аккумуляторных источников вместо генераторов для накопления энергии днём. Учёные считают, что залогом эффективного использования энергетических систем и охлаждения является большая прозрачность деятельности ЦОД. В Европе, например, пересматривают поправки к Директиве об энергоэффективности, которые заставят отчитываться по многим параметрам всё ЦОД кроме самых мелких. Как заявил один из учёных, «индустрия ЦОД столь скрытна, что иногда трудно получить подходящие данные для построения моделей». Впрочем, учёные опасаются, что у гиперскейлеров может не хватить времени на внедрение качественной отчётности — индустрия ИИ развивается чересчур быстро.
26.04.2023 [19:50], Сергей Карасёв
Meta✴ вынужденно пересмотрела архитектуру своих ЦОД из-за отказа от выпуска собственных ИИ-чипов в пользу ускорителей NVIDIAКомпания Meta✴, по сообщению Reuters, была вынуждена пересмотреть конфигурацию своих дата-центров из-за отставания от конкурентов в плане развития ИИ-платформ. Компания, в частности, решила отказаться от дальнейшего внедрения инференс-чипов собственной разработки. Отмечается, что до прошлого года Meta✴ применяла архитектуру, в которой традиционные CPU соседствуют с кастомизированными решениями. Однако выяснилось, что такой подход менее эффективен по сравнению с применением ускорителей (GPU). При этом ранее компания отказалась от ИИ-ускорителей Qualcomm, указав на недоработки ПО, которые, судя по всему, были устранены только недавно. А с Esperanto, вероятно, отношения у Meta✴ пока не сложились. Впрочем, теперь компании интересен генеративный ИИ, а не только рекомендательные системы, что накладывает иные требования к оборудованию. 
Источник изображения: Meta✴ В течение почти всего 2022 года Meta✴ активно инвестировала в развите инфраструктуры, однако в конце года стало известно, что она приостановила строительство целого ряда ЦОД, а затем пересмотрела расходы на дата-центры. Компания решила кардинально переосмыслить архитектуру своих ЦОД, сделав ставку на СЖО. Как теперь выясняется, связано это с тем, что Meta✴ отказалась от собственных ИИ-чипов в пользу ускорителей NVIDIA: объём заказов последних исчисляется «миллиардами долларов». Соответствующую платформу Grand Teton компания показала в конце прошлого года. 
Источник изображения: Meta✴ Но ускорители потребляют больше энергии и выделяют больше тепла, нежели CPU или узкоспециализированные ASIC. Кроме того, ускорители должны физически находиться довольно близко друг к другу, хотя с интерконнектом компания тоже уже экспериментирует. Всё это влияет на архитектуру ЦОД. Тем не менее, Meta✴ всё же разрабатывает некий секретный чип, который сгодится и для обучения ИИ-моделей, и для инференса. Ожидается, что это решение увидит свет в 2025 году. Пока что для обучения ИИ компания намерена использовать собственный ИИ-суперкомпьютер RSC и облачные кластеры Microsoft Azure. Похожий путь избрала Microsoft, решившая создать свой ИИ-чип, не отказываясь пока от ускорителей NVIDIA. The Information добавляет, что вице-президент Microsoft по разработке «кремния» Жан Буфархат (Jean Boufarhat) присоединится к Meta✴. Он возглавит команду Facebook✴ Agile Silicon Team (FAST), чтобы помочь компании в реализации проектов по созданию чипов. Ранее Meta✴ переманила из Intel руководителя разработки сетевых решений для дата-центров. У Google и Amazon уже есть свои ИИ-чипы для обучения и инференса.
22.04.2023 [00:15], Алексей Степин
Ловкость роборук: TopoOpt от Meta✴ и MIT поможет ускорить и удешевить обучение ИИТехнологии искусственного интеллекта (ИИ) сегодня бурно развиваются и требуют всё более серьёзных вычислительных мощностей. Но наряду с наращиванием этих мощностей растут требования и к сетевой подсистеме, поэтому крупные компании и исследовательские организации ищут всё новые способы оптимизации инфраструктуры. Компания Meta✴ в сотрудничестве с Массачусетским технологическим институтом (MIT) и рядом прочих исследовательских организаций опубликовала данные любопытного эксперимента, в котором ИИ-кластер мог менять топологию своего интерконнекта с помощью механической «роборуки». Система получила название TopoOpt, поскольку вычислительные узлы в ней использовали полностью оптическую сеть с оптической же патч-панелью. Эта сеть объединяла 12 вычислительных узлов ASUS ESC4000A-E10, каждый из которых был оснащён ускорителем NVIDIA A100, сетевыми адаптерами HPE и Mellanox ConnectX-5 (100 Гбит/с) с оптическими трансиверами. 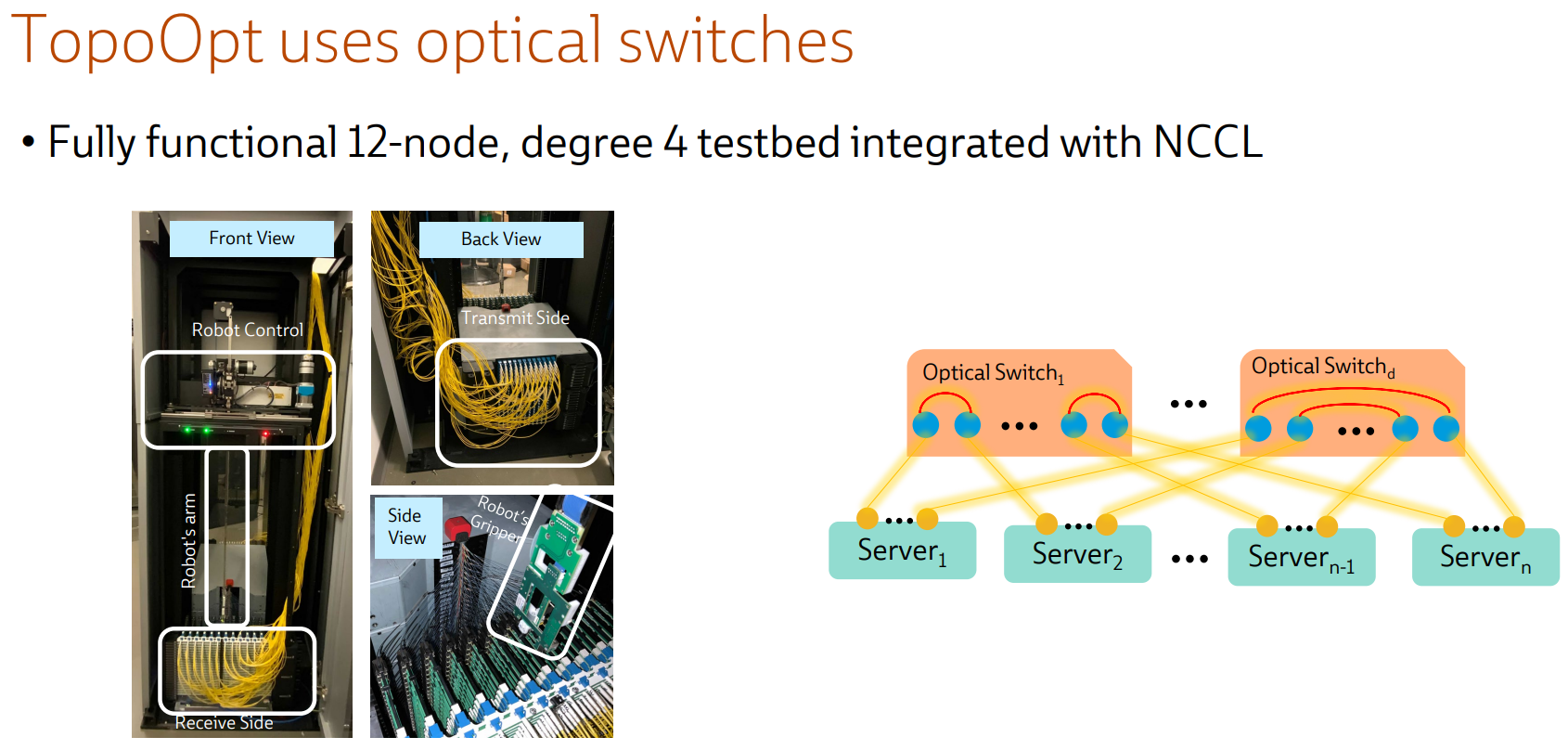
Источник здесь и далее: USENIX Наиболее интересное устройство в эксперименте — оптическая патч-панель Telescent, оснащённая механическим манипулятором, способным производить перекоммутацию на лету. Эта «роборука» работала под управлением специализированного ПО, целью которого ставилось нахождение оптимальной сетевой топологии и сегментации сети применительно к различным задачам машинного обучения. 
Система с перекоммутируемой оптической сетью не требует энергоёмких высокоскоростных коммутаторов и обеспечивает ряд других преимуществ Такая роботизированная патч-панель не столь расторопна, как оптические коммутаторы Google с микрозеркальной механикой, но стоит впятеро дешевле и имеет больше портов. Опубликованные экспериментальные данные уверенно свидетельствуют о том, что топология «толстого дерева» (fat tree), использующая несколько слоёв коммутаторов, не оптимальна и даже избыточна для ряда нейросетевых задач. К тому же перекоммутируемая оптическая сеть без традиционных высокоскоростных коммутаторов требует меньше оборудования, а значит, может быть не только быстрее сети fat tree в ряде ИИ-задач, но и существенно дешевле в развёртывании и поддержании в рабочем состоянии — как минимум за счёт отсутствия затрат на питание множества коммутаторов.
19.04.2023 [22:00], Алексей Степин
Broadcom представила чип-коммутатор Jericho3-AI для ИИ-платформ, попутно раскритиковав NVIDIAКомпания Broadcom, один из ведущих поставщиков «кремния» для сетевых решений, анонсировала новый сетевой процессор Jerico3-AI, который ориентирован на ИИ-системы. Более того, Broadcom считает подход NVIDIA к «интеллектуальным сетевым решениям» с использованием InfiniBand неверным и даже вредным для кластерных ИИ-систем. Ethernet-коммутаторы компании можно разделить три ветви: наиболее высокопроизводительные чипы Tomahawk, ориентированная на дополнительные возможности ветвь Trident и, наконец, серия Jericho, отличающаяся наибольшей гибкостью в программировании и располагающая более ёмкими буферами. Чип Jericho3-AI BCM88890 — новинка в последней категории, относящаяся к классу 28,8 Тбит/с. Новый коммутатор имеет 144 линка SerDes (106Gbps, PAM4) и может работать в конфигурации 18×800GbE, 36×400GbE или 72×200GbE. 
Источник здесь и далее: Broadcom (via ServeTheHome) В своей презентации Broadcom раскритиковала традиционный подход NVIDIA и других крупных игроков на сетевом рынке, заявив о том, что прямое наращивание пропускной способности и снижение латентности кластерной сети якобы является тупиковой ветвью развития. Вместо этого фабрика на базе Jericho3-AI, по словам компании, позволяет сделать так, чтобы процесс обучения нейросети как можно меньше времени тратил не сетевые операции.  Новый коммутатор обеспечивает идеальную балансировку загрузки, гарантирующую отсутствие заторов, и автоматическое переключение отказавшего соединения на резервное менее, чем за 10-нс, а также позволяет создавать большие «плоские» сети (до 32 тыс. портов 800GbE), характерные для ИИ-кластеров. Каждый ускоритель может получить 800G-подключение, а суммарная производительность фабрики на базе новых коммутаторов может достигать 26 Пбит/с. 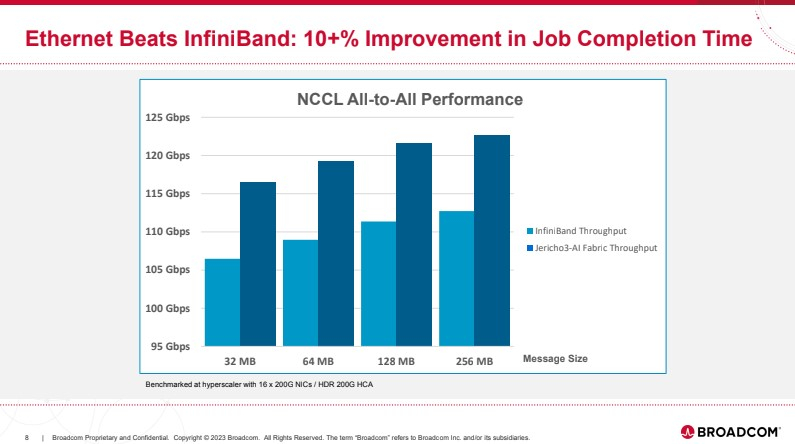 Broadcom утверждает, что сеть Ethernet на базе Jericho3-AI превосходит аналогичную по классу сеть NVIDIA InfiniBand в тестах с использованием NCCL. При этом новый коммутатор не содержит никаких вычислительных мощностей общего назначения — он проще, а за счёт использования стандарта Ethernet сети на его основе универсальны, что также снижает стоимость владения инфраструктурой.  Высокая степень интегрированности обеспечит и большую экономичность, а значит, решения на базе нового коммутатора Broadcom окажутся и более дружелюбны к экологии. Новые чипы уже доступны избранным клиентам Broadcom. |
|

