Материалы по тегу: суперкомпьютер
|
21.11.2024 [12:23], Руслан Авдеев
Суперкомпьютеры Eviden заняли первые места в рейтинге энергоэффективных систем Green500Входящая в группу Atos компания Eviden объявила, что 55 её суперкомпьютеров вошли в список TOP500 наиболее производительных вычислительных машин, а два из них лидируют в рейтинге наиболее энергоэффективных суперкомпьютеров мира Green500. За последние 10 лет экспоненциально выросла вычислительная мощность, что в том числе обусловлено достижениями в области систем искусственного интеллекта. При этом растёт и энергопотребление — его снижение стало одной из главных задач при разработке и строительстве суперкомпьютеров. В первую десятку рейтинга Green500 вошли три машины Eviden, в каждой из которых применяется проприетарная технология прямого жидкостного охлаждения, предусматривающая охлаждение суперкомпьютера тёплой водой с температурой до +40 °C, это помогает добиться отвода более 97 % тепла. 
Источник изображения: Eviden Первое место в рейтинге занимает модуль JEDI суперкомпьютера JUPITER — первой системы экзафлопсного класса в Европе, созданный EuroHPC. На втором месте — ROMEO 2025, построенный для Университета Реймса Шампань-Арденн (URCA). Шестое место в Green500 занимает ещё один модуль суперкомпьютера JUPITER — JETI. Другими словами, Eviden стремится предлагать клиентам не только высокопроизводительные, но и экоустойчивые, экономичные машины. В TOP500 наиболее производительных суперкомпьютеров из построенных компанией вошли французская система Jean Zay (№ 27), новейший немецкий модуль JETI для JUPITER (№ 18) и система Gefion для Датского центра инноваций в области искусственного интеллекта (DCAI) под номером 21. По словам представителя Eviden, системы компании лидируют в рейтинге Green500 и «укрепляют лидерство Европы» на рынке HPC. Eviden, на которую работает 41 тыс. человек, предлагает решения в области ИИ, облачных платформ и предоставляет услуги более чем в 47 странах. Годовая выручка этого подразделения Atos Group составляет около €5 млрд. Сама же Atos находится не в лучшем состоянии.
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 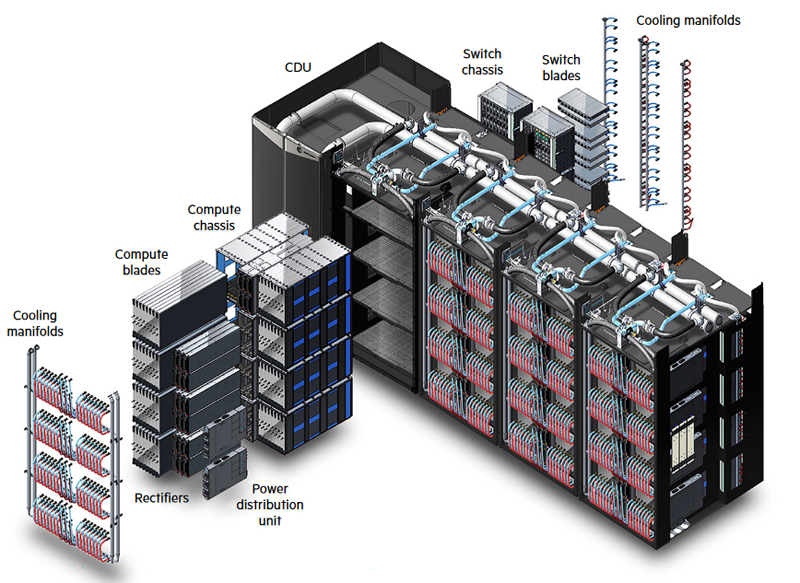 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
19.11.2024 [17:30], Сергей Карасёв
1,742 Эфлопс: El Capitan стал самым мощным в мире суперкомпьютером рейтинга TOP500Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США (DOE), Администрация по национальной ядерной безопасности США (NNSA), компании AMD и HPE официально представили El Capitan — самый производительный в мире суперкомпьютер. Эта машина возглавила ноябрьский рейтинг мощнейших вычислительных систем TOP500. Комплекс El Capitan создан специалистами HPE Cray. Суперкомпьютер обладает FP64-быстродействием 1,742 Эфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 2,746 Эфлопс. Прежний лидер TOP500 — система Frontier — с производительностью 1,353 Эфлопс теперь находится на втором месте рейтинга. Машина Aurora, так и не прибавившая в производительности, хотя и заявленная когда-то как 2-Эфлопс система, занимает теперь третье место. В основу El Capitan легла платформа HPE Cray Shasta. Используется гибридная архитектура AMD с APU Instinct MI300A: изделие содержит 24 ядра Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. В общей сложности в составе суперкомпьютера объединены 11 136 узлов, каждый из которых несёт на борту четыре экземпляра Instinct MI300A. Применён интерконнект HPE Slingshot-11 с пропускной способностью 200 Гбит/с. Система включает узлы Rabbit, которые формируют дезагрегированное NVMe-хранилище с прямым PCIe-подключением к вычислительным узлам. 
Источник изображений: LLNL Суммарное количество ядер CPU и GPU в составе El Capitan достигает 11 039 616, объём памяти — 5,4375 Пбайт. За отвод тепла отвечает система прямого жидкостного охлаждения HPE. Заявленная энергетическая эффективность составляет 58,89 Гфлопс/Вт: с таким показателем машина оказалась на 18-м месте в списке «зелёных» суперкомпьютеров GREEN500, но с учётом масштаба и общего энергопотребления 29,58 МВт — это хороший показатель. Система охлаждения HPC-объекта использует 28 тыс. т воды. Отмечается, что El Capitan станет главным вычислительным ресурсом для Tri-lab — группы, в которую вместе с LLNL входят Сандийские национальные лаборатории (SNL) и Лос-Аламосская национальная лаборатория (LANL). Использовать мощности нового суперкомпьютера планируется для обеспечения национальной безопасности и решения сложных задач, связанных с ядерным оружием. В частности, El Capitan обеспечит беспрецедентные возможности моделирования и имитации, необходимые для Программы управления ядерными запасами NNSA. Кроме того, НРС-комплекс поможет в модернизации и создании нового оружия, такого как боеголовки W87-1 и W93, которые в настоящее время находятся на стадии разработки.  Отмечается также, что на 10-й позиции в рейтинге TOP500 оказался суперкомпьютер Tuolumne, также построенный в рамках проекта LLNL и NNSA. Фактически Tuolumne — это младший брат El Capitan: машина использует ту же архитектуру на базе Instinct MI300A, но обладает примерно на порядок меньшей FP64-производительностью 208,10 Пфлопс с пиковым значением 288,88 Пфлопс. Применять мощности Tuolumne планируется для «несекретных» задач, таких как исследования в области энергетической безопасности, изменений климата, вычислительной биологии, разработки лекарственных препаратов следующего поколения и пр. Стоит отметить, что Frontier — не единственная система, которая уступила пальму первенства более новым НРС-комплексам в ноябрьском рейтинге TOP500. Та же участь постигла самый мощный суперкомпьютер Европы LUMI, который опустился с пятого на восьмое место. На пятой позиции оказалась совершенно новая система HPC6, расположенная в центре нефтегазовой компании Eni в Феррера-Эрбоньоне (Италия). Её производительность достигает 477,9 Пфлопс при пиковом показателе 606,97 Пфлопс.
19.11.2024 [12:57], Руслан Авдеев
Dell отобрала у Supermicro крупный заказ на ИИ-серверы для xAI Илона МаскаОснованный Илоном Маском (Elon Musk) стартап xAI, похоже, отнял все прежние заказы на ИИ-серверы у испытывающей не лучшие времена Supermicro, чтобы передать их её конкурентам. Как сообщает UDN, выгодоприобретателями станет Dell, а также её партнёры Inventec и Wistron. Для Supermicro, которой и без того грозит делистинг с Nasdaq, это станет очередным ударом. Ранее Dell и Supermicro поставляли оборудования компаниям Илона Маска, в т.ч. xAI и Tesla. Официально сообщалось, что xAI закупила ИИ-серверы с жидкостным охлаждением у Supermicro. Но после того, как Министерство юстиции США начало расследование деятельности поставщика в связи с вероятными махинациями с бухгалтерской отчётностью и нарушением санкционного режима, акции компании обрушились. После этого, по данным UDN, компании Маска и приняли решения передать заказы другим исполнителям. Среди поставщиков ИИ-серверов у Dell хорошие возможности получения заказов. Например, Wistron выпускает материнские платы для ИИ-серверов компании и выполняет некоторые задачи по сборке — партнёры станут одними из основных бенефициаров краха Supermicro. Фактически Wistron уже расширяет производственные мощности для удовлетворения спроса, в частности на трёх заводах на Тайване, а также в Мексике. В Wistron смотрят в будущее с большим оптимизмом и ожидают, что спрос на ИИ-серверы будет расти «трёхзначными» значениями в процентном отношении. 
Источник изображения: Bermix Studio/unsplash.com Inventec также является крупным поставщиком Dell и тоже получит свою долю «пирога» от заказа Supermicro. Компания давно участвует в производстве ИИ-систем и входит в тройку ведущих партнёров Dell, участвующих в сборке серверов. В 2024 году компания поставляла машины на чипах семейства NVIDIA Hopper, но в I квартале 2025 года она сможет поставлять уже варианты на платформе NVIDIA Blackwell — с ускорителями B200 и B200A. Считается, что у компании есть свободные производственные мощности в Мексике, поэтому она сможет нарастить выпуск ИИ-серверов для компаний, ранее работавших с Supermicro. 
Фото: Michael Dell Одной из ключевых причин проблем Supermicro считается задержка с подачей финансовых документов, из-за чего компания рискует покинуть биржу Nasdaq. Чтобы избежать делистинга, Supermicro должна была объяснить задержки с подачей материалов и подать доклад по форме K-10 к 16 ноября, но сделать этого не успела. Впрочем, первые неприятности у Supermicro начались значительно раньше, когда Hindenburg Research опубликовала разгромный доклад о финансовой отчётности компании. Если Supermicro дождётся делистинга на бирже, это приведёт к серьёзными финансовыми последствиями, включая стремительное падение акций и необходимость немедленного погашения долга $1,725 млрд по конвертируемым облигациям — обычно такие «триггеры» учитываются в соглашениях и активируются при делистинге. Буквально на днях сообщалось, что Supermicro лишилась заказа от индонезийской YTL Group (YTLP) на поставку суперускорителей NVIDIA GB200 NVL72 для одного из крупнейших в Юго-Восточной Азии ИИ-суперкомпьютеров. Теперь поставками будет заниматься только Wiwynn, которая принадлежит всё той же Wistron. При этом сама Wiwynn сейчас судится с X (Twitter), которой владеет Илон Маск.
18.11.2024 [13:38], Руслан Авдеев
Foxlink запустила мощнейший на Тайване суперкомпьютер для малого и среднего бизнесаFoxlink Group (Cheng Uei Precision Industry) открыла крупнейший на Тайване суперкомпьютерный центр Ubilink (Ubilink.AI). По данным DigiTimes, центр предназначен для обслуживания предприятий малого и среднего бизнеса (SME), которые не могут позволить себе собственных вычислительных мощностей. Хотя основной деятельностью Foxlink является производство разъёмов, компания расширяет бизнес, осваивая решения для управления электропитанием и коммуникаций, а также выпуск энергетических модулей. Центр Ubilink создан дочерней Shinfox Energy совместно с Asustek Computer и японской Ubitus, занимающейся предоставлением облачных услуг. В Ubitus сообщили, что инфраструктура Ubilink включает 128 серверов Asus, 1024 ускорителя NVIDIA H100 и интерконнект NVIDIA Quantum-2 InfiniBand. Конфигурация обеспечивает до 45,82 Пфлопс (FP64) — система занимает 31-е место в рейтинге TOP500. В будущем станут применять и более современные B100 и B200 — когда те будут доступны. Ожидается, что в 2025 году суммарно будет установлено 10 240 ускорителей H100, B100 и B200. Представители местных властей уже заявили, что Ubilink существенно улучшит позиции Тайваня на рынке ИИ-вычислений, на котором территория сегодня занимает 26-е место. В Asustek добавляют, что достигнутая производительность в 45,82 Пфлопс заметно превышает плановые 40 Пфлопс. Кроме того, центр имеет PUE на уровне 1,2 — ранее ожидалось, что удастся добиться энергоэффективности лишь на уровне 1,38. Благодаря использованию опыта Shinfox Energy в области возобновляемой энергетики, Ubilink стал первым в Азии суперкомпьютерным центром, использующим «зелёные» источники энергии — клиенты могут воспользоваться вычислениями без существенного ущерба окружающей среде. 
Источник изображения: UBITUS Предполагается, что Ubilink компенсирует отсутствие мощностей для местных малых и средних компаний, не имеющих доступа к значительным вычислительным ресурсам. Предлагая доступные вычислительные мощности, центр позволяет таким бизнесам расширить свои портфели предложений и конкурировать даже на мировом уровне. Суперкомпьютер уже востребован местными разработчиками чипов, компаний, занимающихся их упаковкой и тестированием, биотехнологическими бизнесами, а также исследовательскими институтами различной направленности. Из-за высокого спроса Foxlink уже рассматривает вторую и третью фазы расширения проекта.
17.11.2024 [11:32], Сергей Карасёв
NEC создаст в Японии суперкомпьютер на базе Intel Xeon 6900P и AMD Instinct MI300A для исследований термоядерного синтезаКорпорация NEC займётся созданием нового НРС-комплекса, который планируется ввести в эксплуатацию в Японии в июле 2025 года. Система, базирующаяся на компонентах AMD и Intel, будет использоваться для различных исследований и разработок в области термоядерного синтеза. Заказ на создание суперкомпьютера поступил от Национальных институтов квантовой науки и технологий Японии (QST) при Национальном агентстве исследований и разработок (ANID), а также от Национального института термоядерных наук (NIFS) в составе Национальных институтов естественных наук (NINS). Система будет установлена в Институте термоядерной энергии Rokkasho (входит в QST) в Аомори (Япония). Основой проектируемого суперкомпьютера послужат 360 узлов NEC LX 204Bin-3, в состав каждого из которых войдут два процессора Intel Xeon 6900P поколения Granite Rapids (всего 720 чипов) и память DDR5 MRDIMM. Кроме того, будут задействованы 70 узлов NEC LX 401Bax-3GA, несущих на борту по четыре ускорителя AMD Instinct MI300A (в общей сложности 280 изделий). Говорится о применении интерконнекта InfiniBand с 400G-коммутаторами NVIDIA QM9700, а также хранилища DDN EXAScaler ES400NVX2 вместимостью 42,2 Пбайт с файловой системой Lustre. Для управления рабочими нагрузками будет использоваться софт Altair PBS Professional. 
Источник изображения: NEC Ожидается, что производительность суперкомпьютера достигнет 40,4 Пфлопс. Это в 2,7 раза больше суммарных показателей двух нынешних НРС-систем, установленных в рамках независимых проектов QST и NIFS. Учёные намерены применять новый НРС-комплекс для точного прогнозирования экспериментов и создания сценариев работы для Международного экспериментального термоядерного реактора (ITER). Кроме того, мощности суперкомпьютера будут востребованы исследовательскими группами токамака Satellite Tokamak JT-60SA и электростанции DEMO (DEMOnstration Power Plant), использующей термоядерный синтез.
16.11.2024 [20:59], Сергей Карасёв
Стартап xAI Илона Маска получит от арабов $5 млрд на покупку ещё 100 тыс. ускорителей NVIDIAКак сообщает CNBC, стартап xAI Илона Маска (Elon Musk) привлёк многомиллиардные инвестиции: деньги будут направлены на закупку ускорителей NVIDIA для расширения вычислительных мощностей ИИ-суперкомпьютера. Напомним, в начале сентября нынешнего года компания xAI запустила ИИ-кластер Colossus со 100 тыс. ускорителей NVIDIA H100. В составе платформы применяются серверы Supermicro, узлы хранения типа All-Flash, адаптеры SuperNIC, а также СЖО. Суперкомпьютер располагается в огромном дата-центре в окрестностях Мемфиса (штат Теннесси). Как теперь стало известно, в рамках нового раунда финансирования xAI привлечёт $6 млрд. Из них $5 млрд поступит от суверенных фондов Ближнего Востока, а ещё $1 млрд — от других инвесторов, имена которых не раскрываются. При этом рыночная стоимость стартапа достигнет $50 млрд. О том, что xAI получит дополнительные средства на развитие, также сообщает Financial Times. По данным этой газеты, речь идёт о $5 млрд при капитализации стартапа на уровне $45 млрд. 
Источник изображения: NVIDIA Ранее Маск говорил о намерении удвоить производительность Colossus: для этого, в частности, планируется приобрести примерно 100 тыс. ИИ-ускорителей, включая 50 тыс. изделий NVIDIA H200. Судя по всему, привлеченные средства стартап также направит на покупку других решений NVIDIA, в том числе коммутаторов Spectrum-X SN5600 и сетевых карт на базе BlueField-3. Между тем жители Мемфиса выражают недовольство в связи с развитием ИИ-комплекса xAI. Активисты, в частности, обвиняют стартап в том, что используемые на территории его дата-центра генераторы ухудшают качество воздуха в регионе.
16.11.2024 [20:49], Сергей Карасёв
Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на огромных чипах Cerebras WSE-3Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) в рамках партнёрства с компанией Cerebras Systems объявили о запуске кластера Kingfisher, который будет использоваться в качестве испытательной платформы при разработке ИИ-технологий для обеспечения национальной безопасности. Основой Kingfisher служат узлы Cerebras CS-3, которые выполнены на фирменных ускорителях Wafer Scale Engine третьего поколения (WSE-3). Эти гигантские изделия содержат 4 трлн транзисторов, 900 тыс. ядер и 44 Гбайт памяти SRAM. Суммарная пропускная способность встроенной памяти достигает 21 Пбайт/с, внутреннего интерконнекта — 214 Пбит/с. На сегодняшний день платформа Kingfisher объединяет четыре узла Cerebras CS-3, а конечная конфигурация предусматривает использование восьми таких блоков. Узлы Cerebras CS-3 мощностью 23 кВт каждый содержат СЖО, подсистемы питания, сетевой интерконнект Ethernet и другие компоненты. 
Источник изображения: SNL Развёртывание кластера Cerebras CS-3 является частью программы Advanced Simulation and Computing (ASC), которая реализуется Национальным управлением по ядерной безопасности США (NNSA). Речь идёт, в частности, об инициативе ASC Artificial Intelligence for Nuclear Deterrence (AI4ND) — искусственный интеллект для ядерного сдерживания. Предполагается, что Kingfisher позволит разрабатывать крупномасштабные и надёжные модели ИИ с использованием защищённых внутренних ресурсов Tri-lab — группы, в которую входят Сандийские национальные лаборатории, Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе (DOE).
15.11.2024 [10:33], Сергей Карасёв
«Росэлектроника» создаст суперкомпьютер нового поколения для РАН
hardware
hpc
ангара
импортозамещение
ницэвт
погружное охлаждение
россия
росэлектроника
сделано в россии
сжо
суперкомпьютер
Холдинг «Росэлектроника», входящий в госкорпорацию «Ростех», анонсировал проект нового НРС-комплекса, который будет создан для Объединённого института высоких температур Российской академии наук (ОИВТ РАН). Особенностью суперкомпьютера станет применение российского интерконнекта «Ангара». Система разрабатывается в рамках соглашения, заключенного между НИЦЭВТ (входит в «Росэлектронику») и ОИВТ РАН. При проектировании машины планируется использовать опыт разработки и производства суперкомпьютеров НИЦЭВТ предыдущих поколений — «Ангара-К1», Desmos и Fisher. Отмечается, что коммуникационная сеть «Ангара», созданная специалистами НИЦЭВТ, предназначена для построения мощных суперкомпьютеров, вычислительных кластеров для обработки больших данных и расчётов на основе сверхмасштабируемых параллельных алгоритмов. Помимо «Ангары», в составе проектируемого HPC-комплекса будут задействованы технологии погружного охлаждения. На сегодняшний день участники проекта прорабатывают технические характеристики создаваемого суперкомпьютера — количество узлов, объём памяти, архитектуру процессоров и число ядер. Особое внимание будет уделяться максимально возможному использованию отечественной элементной базы. Целевые показатели производительности системы не раскрываются, но говорится, по величине пикового быстродействия она превзойдёт предшественников. 
Источник изображения: unsplash.com / Scott Rodgerson Суперкомпьютер планируется применять для проведения научно-исследовательских, опытно-конструкторских и технологических работ на базе образовательных учреждений и промышленных предприятий РФ. «Стратегическое партнёрство с НИЦЭВТ позволит нам совместно создать высокопроизводительную вычислительную систему и расширить наши возможности в исследовании сложных процессов в энергетике и теплофизике. ОИВТ РАН обладает большим опытом использования передовых вычислительных методов, включая методы первопринципного моделирования и молекулярной динамики для научных исследований. Увеличение мощности вычислительных ресурсов позволит значительно повысить точность, темп и эффективность наших исследований», — отметил директор ОИВТ РАН.
14.11.2024 [08:17], Владимир Мироненко
SoftBank построит в Японии первый в мире ИИ-суперкомпьютер на базе NVIDIA DGX B200NVIDIA объявила о серии совместных проектов с SoftBank, направленных на ускорение суверенных инициатив Японии в области ИИ, которые также обеспечат возможность получения дохода от ИИ для поставщиков телекоммуникационных услуг по всему миру. В выступлении на саммите NVIDIA AI Summit Japan генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что SoftBank создаёт самый мощный в Японии ИИ-суперкомпьютер с использованием платформы NVIDIA DGX SuperPOD B200 и интерконнекта Quantum-2 InfiniBand. Эта система станет первой в мире, которая получит системы DGX B200. Она будет использоваться компанией для разработки генеративного ИИ и развития других бизнес-решений, а также для предоставления вычислительных услуг университетам, научно-исследовательским институтам и предприятиям в стране. Суперкомпьютер идеально подойдёт для разработки больших языковых моделей (LLM), говорится в пресс-релизе. Пока что на звание самого мощного ИИ-суперкомьютера Японии претендует система ABCI 3.0 на базе NVIDIA H200. Впрочем, Softbank не сидит сложа руки и планирует построить ещё один суперкомпьютер, на этот раз на базе суперускорителей GB200 NVL72. Они же будут использоваться в проекте Sharp, KDDI и Supermicro по созданию «крупнейшего в Азии» ИИ ЦОД. 
Источник изображения: NVIDIA Также в ходе саммита было объявлено, что SoftBank, используя платформу ускоренных вычислений NVIDIA AI Aerial, успешно запустил первую в мире телекоммуникационную сеть, объединяющую возможности ИИ и 5G. В ходе испытаний, проведенных в префектуре Канагава, SoftBank продемонстрировала, что решение AI-RAN достигло производительности 5G операторского класса, используя ресурсы ускорителя для одновременной обработки сетевого трафика и инференса. Отмечается, что мобильные сети традиционно рассчитаны на обработку пиковых нагрузок и в среднем задействуют только треть аппаратных ресурсов, что позволяет монетизировать оставшиеся две трети путём предоставления ИИ-сервисов. NVIDIA и SoftBank также сообщили, что с помощью ПО NVIDIA AI Enterprise японская компания будет создавать локализованные безопасные ИИ-сервисы. |
|

