Материалы по тегу: marvell
|
08.06.2025 [23:35], Владимир Мироненко
Marvell получила рекордную выручку и рассчитывает на дальнейшее успешное сотрудничество с гиперскейлерамиАмериканская компания Marvell Technology, специализирующаяся на производстве процессоров, микроконтроллеров и телекоммуникационных решений, сообщила результаты I квартала 2026 финансового года, завершившегося 3 мая 2025 года, отметив рекордную выручку в размере $1,89 млрд, что на 63 % больше год к году и на $20 млн превысило собственный прогноз в средней точке диапазона. Также показатель превысил консенсус-прогноз аналитиков, опрошенных LSEG, в размере $1,88 млрд, пишет Reuters. Чистая прибыль компании (GAAP) составила за I квартал 2026 финансового года $177,9 млн, или $0,20 на разводненную акцию, тогда как годом ранее у неё были убытки в размере $215,6 млн или $0,25 на разводнённую акцию. Скорректированная прибыль (Non-GAAP) равняется $540,0 млн или $0,62 на разводнённую акцию. 
Источник изображений: Microsoft Выручка сегмента решений для ЦОД, на который приходится 76 % от общего дохода компании, составила $1,44 млрд, увеличившись год к году на 76 % во многом благодаря сделкам по разработке ИИ-ускорителей AWS Trainium и Microsoft Maia. По словам Мэтта Мерфи (Matt Murphy), председателя и гендиректора Marvell Technology, программа по разработке XPU для крупного американского клиента-гиперскейлера продвигается успешно, она стала ключевым источником дохода для бизнеса, связанного с заказами. Broadcom уже разрабатывает ИИ-ускорители для трёх крупных клиентов и обсуждает разработку с ещё четырьмя потенциальными клиентами. «Как я упоминал в прошлом квартале, мы активно сотрудничаем с этим заказчиком в разработке следующего поколения чипов, и я хочу сообщить, что теперь мы обеспечили производство 3-нм пластин и усовершенствованной упаковки и планируем начать производство в 2026 году. В то же время наша команда архитекторов работает с заказчиком, чтобы поддержать подгтовку следующего поколения», — сообщил Мерфи. Речь идёт об AWS, и Мерфи имеет в виду находящийся в производстве Trainium 2, платформу для Trainium 3 и спецификации для будущего Trainium 4, пояснил ресурс The Next Platform. Мерфи добавил, что проект по созданию ИИ-ускорителя следующего поколения, разработанного для другого американского гиперскейлера, по всей видимости, чипа Maia 100 для Microsoft, «продолжает успешно развиваться» и что компания уже сотрудничает с тем же заказчиком в разработке следующего ИИ XPU с предположительным названием Maia 200. 17 июня Marvell планирует провести мероприятие, на котором, возможно, предоставит более подробную информацию о текущих разработках и о своих планах по дальнейшему развитию этого бизнеса.  В сегменте корпоративных сетевых продуктов, включая коммутаторы Prestera и Innovium, и сетевые интерфейсные платы, выручка выросла на 16 % до $177,5 млн, в сегменте операторских инфраструктур — на 93 % до $138,4 млн. В потребительском сегменте продажи выросли год к году на 50 % до $61,1 млн, но упали последовательно на 29 %, что связано с сезонными изменениями в спросе. Сегмент решений для автомобильной сферы и промышленной отрасли принёс $75,7 млн, что на 12 % меньше, чем в предыдущем квартале и на 2 % меньше, чем годом ранее. В текущем, II квартале 2026 финансового года Marvell ожидает получить выручку в размере $2,0 млрд ± 5 % по сравнению со средней оценкой аналитиков в $1,98 млрд согласно данным опроса аналитиков компанией LSEG. Прогнозируемая прибыль (GAAP) на разводнённую акцию равна $0,21 ± $0,05, ожидаемая скорректированная прибыль (Non-GAAP) на разводнённую акцию — $0,67 ± $0,05.
28.05.2025 [17:22], Руслан Авдеев
Amazon раскрыла, что владеет долями в AMD, Astera Labs и MarvellAmazon раскрыла данные о получении доли в компании AMD на сумму $84,5 млн. «Опосредованные» инвестиции стали возможными после покупки AMD поставщика инфраструктурных решений для гиперскейлеров ZT Systems, в котором Amazon владела небольшим пакетом акций, сообщает Datacenter Dynamics. Согласно декларации 13-F, поданной в этом месяце, Amazon владеет 822 234 акциями AMD на общую сумму $84,5 млн. Помимо AMD, компания также имеет $16,6-млн долю в компании Astera Labs, занимающейся интерконнектами для ИИ-ускорителей и других чипов, а также долю в разработчике полупроводниковых решений Marvell Technology на сумму $13,9 млн. Ранее Amazon принадлежала небольшая доля в ZT Systems, занимающейся проектированием, сборкой и поставкой серверов, в т.ч. для AWS. В марте 2025 года AMD закрыла сделку по покупке ZT Systems за $4,9 млрд. Фактически компания вошла в состав подразделения AMD Data Center Solutions. После покупки AMD рассчитывает предлагать комплексные решения в сфере ИИ, объединяющие собственные процессоры, ИИ-ускорители и сетевые чипы. 
Источник изображения: ZT Systems Буквально на днях AMD, наконец, продала Sanmina производственное подразделение ZT Systems за $3 млрд и оставила за собой команду разработчиков и людей, ответственных за взаимодействие с клиентами. Непосредственно производство переходит Sanmina. Другими словами, Amazon «опосредованно» стала миноритарным акционером AMD благодаря тому, что владела долей в ZT Systems до того, как её распродали.
10.03.2025 [08:54], Владимир Мироненко
Из-за слабого прогноза акции Marvell пережили самое большое падение за 24 годаАмериканская компания Marvell Technology, специализирующаяся на производстве процессоров, микроконтроллеров и телекоммуникационных решений, объявила итоги IV квартала и 2025 финансового года, завершившегося 1 февраля 2025 года. В целом показатели Marvell Technology за отчётный квартал соответствуют оценкам Уолл-стрит, но слабый прогноз на I квартал 2026 финансового года не оправдал ожиданий инвесторов — акции компании обрушились на 19,8 %, пишет CNBC. Как отметило агентство Reuters, это было самое большое падение ценных бумаг Marvell за 24 года деятельности. Впрочем, другие участники ИИ-рынка сейчас сталкиваются с повышенными ожиданиями инвесторов по поводу финансовых результатов. В связи с этим наряду с Marvell снизилась стоимость акций HPE обрушилась на 19 %, Semiconductor ETF — на 4 %, ценные бумаги производителя ИИ-чипов Broadcom подешевели на 7 %, NVIDIA — на 5 %, акции TSMC упали в цене почти на 4 %. Чистая выручка Marvell за IV квартал составила $1,82 млрд, что 27 % больше год к году, на $17,0 млн выше среднего значения её собственного прогноза и больше консенсус-прогноза аналитиков, опрошенных LSEG, в размере $1,80 млрд. Выручка от поставок продуктов для ЦОД составила $1,37 млрд, превзойдя среднюю оценку Уолл-стрит в размере $1,36 млрд.  По словам Мэтта Мерфи (Matt Murphy), председателя и гендиректора Marvell, основным драйверами роста выручки были рост доходов от поставок ЦОД, увеличившихся на 78 % в годовом исчислении в IV квартале, а также продолжающееся восстановление многоотраслевых направлений. Мерфи заявил, что компания превысила в отчётном финансовом году целевой показатель по выручке от поставок ИИ-продуктов в размере $1,5 млрд и планирует превысить цель на 2026 финансовый год в $2,5 млрд по выручке от этого направления. Чистая прибыль (GAAP) равняется $200,2 млн или $0,23 на разводнённую акцию, тогда как год назад у компании были убытки $392,7 млн или $0,45 на разводнённую акцию. Скорректированная чистая прибыль (Non-GAAP) выросла с $401,6 млн или $0,46 на разводнённую акцию год назад до $531,4 млн или $0,60 на разводнённую акцию в IV квартале 2025 финансового года при прогнозе аналитиков от LSEG в $0,59 на разводнённую акцию. Денежный поток составил за квартал $514,0 млн. Мерфи отметил, что за 2025 финансовый год этот показатель достиг рекордной величины в $1,68 млрд. Выручка за год составила $5,77 млрд, что больше чем в 2024 финансовом году на 5 %. Компания завершила год с чистым убытком (GAAP) в размере $885,0 млн или $1,02 на разводнённую акцию. Годом ранее у неё был убыток в размере $933,4 млн или $1,08 на разводнённую акцию. Скорректированная чистая прибыль (Non-GAAP) за 2025 финансовый год равняется $1,37 млрд или $1,57 на разводнённую акцию по сравнению с $1,31 млрд или $1,51 на разводнённую акцию годом ранее. 
Источник изображения: Marvell Technology В I квартале 2026 финансового года Marvell ожидает получить выручку около $1,875 млрд ± 5 %, что немного больше консенсус-прогноза аналитиков, опрошенных LSEG, в размере $1,87 млрд. По данным LSEG, самый высокий прогноз аналитиков выручки компании в текущем квартале составляет $1,94 млрд. Аналитики J.P. Morgan объяснили слабый прогноз «замедлением в поставках продуктов для локальных ЦОД», подразумевая более слабый спрос на сетевые решения. Поскольку крупные технологические компании перераспределяют больше средств чипы ИИ, спрос на сетевое оборудование — один из ключевых бизнесов Marvell — стал слабее. Кастомные чипы также приносят более низкую прибыль, чем готовые процессоры. Marvell ожидает, что скорректированная валовая прибыль (Non-GAAP) за I финансовый квартал составит около 60 %, что на 2 п.п. меньше год к году. Более слабые прогнозы игроков ИИ-рынка связаны с неопределённостью, вызванной вводом повышенных тарифов администрацией Дональда Трампа, в отношении ряда стран, включая Китай и Мексику. Сектор микросхем также пострадал от этого. В частности, индекс Philadelphia Semiconductor Index (SOX) снизился на 5 % в 2025 году после роста почти на 20 % в прошлом году. Акции Marvell выросли более чем на 83 % в 2024 году, а с начала 2025 года упали примерно на 18 %.
28.01.2025 [00:14], Владимир Мироненко
Дороговизна и высокое энергопотребление ИИ-ускорителей NVIDIA открыли новые горизонты для Marvell и BroadcomВзрывной рост популярности ChatGPT и других решений на базе генеративного ИИ вызвал беспрецедентный спрос на вычислительные мощности, что привело к дефициту ИИ-ускорителей, пишет DIGITIMES. NVIDIA занимает львиную долю рынка ИИ-чипов, а ведущие поставщики облачных услуг, такие как Google, Amazon и Microsoft, активно занимаются проектами по разработке собственных ускорителей, стремясь снизить свою зависимость от внешних поставок. Всё большей популярностью у крупных облачных провайдеров пользуются ASIC, поскольку они стремятся оптимизировать чипы под свои конкретные требования, отметил DIGITIMES. ASIC обеспечивают высокую производительность и энергоэффективность в узком спектре задач, что делает их альтернативой универсальным ускорителям NVIDIA. Несмотря на доминирование NVIDIA на рынке, высокое энергопотребление её чипов в сочетании с высокой стоимостью позволило ASIC занять конкурентоспособную нишу. Особенно хорошо ASIC подходят для обучения и инференса ИИ-моделей, предлагая значительно более высокие показатели производительности в пересчёте на 1 Вт по сравнению с GPU общего назначения. Также ASIC предоставляют заказчикам больший контроль над своим технологическим стеком. На рынке разработки ASIC основными конкурентами являются Broadcom и Marvell, которые используют разные технологии и стратегические подходы. 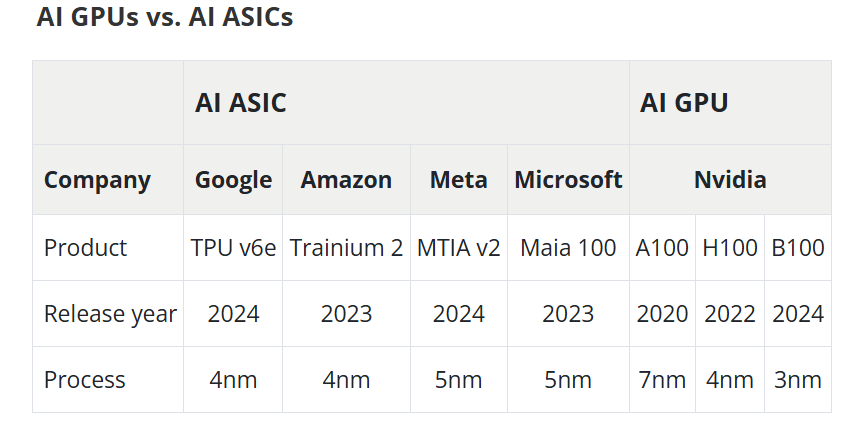
Источник изображений: DIGITIMES Marvell укрепила свои позиции на рынке, в частности, благодаря партнёрству с Google в разработке серверных Arm-чипов, расширив при этом стратегическое сотрудничество со своим основным клиентом — Amazon. TPU v6e от Google представляет собой самую передовую ASIC ИИ среди чипов, разработанных четырьмя ведущими облачными провайдерам, приближаясь по производительности к H100. Однако она всё ещё отстает от ускорителей NVIDIA примерно на два года, утверждает DIGITIMES. Созданный Marvell и Amazon ускоритель Trainium 2 по производительности находится между NVIDIA A100 и H100. В ходе последнего отчёта о финансовых результатах Marvell поделилась прогнозом значительного роста выручки от ASIC, начиная с 2024 года (2025 финансовый год), обусловленного Trainium 2 и Google Axion. В частности, совместный с Amazon проект Marvell Inferential ASIC предполагается запустить в массовое производство в 2025 году (2026 финансовый год), в то время как Microsoft Maia, как ожидается, начнет приносить доход с 2026 года (2027 финансовый год). 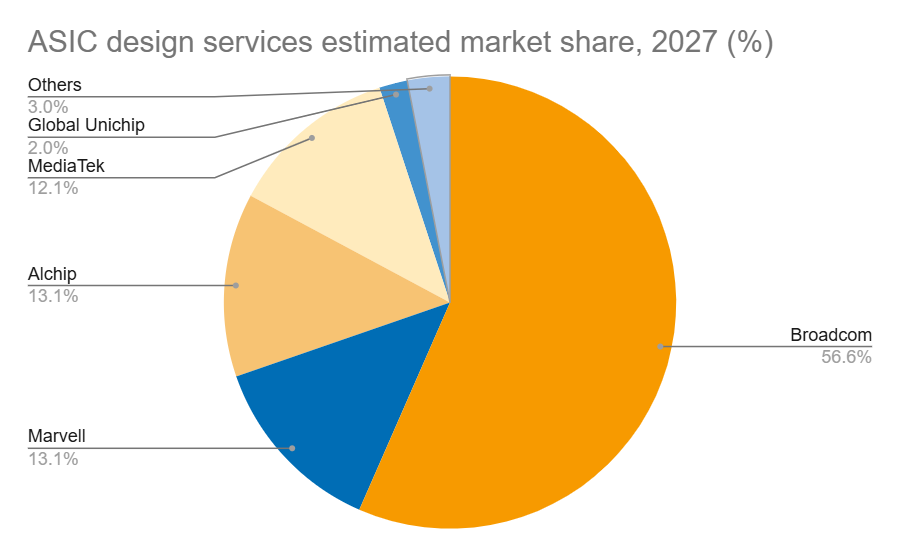 Как утверждают в Morgan Stanley, хотя бизнес Marvell по производству кастомных чипов является ключевым драйвером роста его подразделения по разработке решений для ЦОД, он также несёт в себе значительную неопределённость. Краткосрочные прогнозы Morgan Stanley для продуктов Marvell/Trainium положительны, что подтверждается возросшими мощностями TSMC по упаковке чипов методом CoWoS, планами Amazon по расширению производства и уверенностью Marvell в рыночном спросе. Однако в долгосрочной перспективе конкурентная среда создает проблемы. Появление компаний вроде WorldChip Electronics в секторе вычислительных чипов может заставить Marvell переориентироваться на сетевые решения. Кроме того, потенциальное снижение прибыли от Trainium после 2026 года означает, что Marvell нужно будет обеспечить запуск новых проектов для поддержания динамики роста, говорят аналитики. Broadcom и Marvell являют собой примеры разных стратегий развития в секторе ASIC, отмечает DIGITIMES. Broadcom отдаёт приоритет крупномасштабной интеграции и проектированию платформ, подкрепляя свой подход значительными инвестициями в НИОКР и сложной технологической интеграцией. В свою очередь, Marvell развивается за счёт стратегических приобретений, например, Cavium, Avera и Innovium, благодаря чему расширяет своё портфолио технологий.
12.12.2024 [22:54], Владимир Мироненко
Всё дальше от народа: Marvell предложила гиперскейлерам кастомизацию HBM для ИИ-ускорителейMarvell Technology анонсировала новый подход к интеграции HBM (CHBM) в специализированные XPU, который предоставляет адаптированные интерфейсы для оптимизации производительности, мощности, размера кристалла и стоимости для конкретных конструкций ИИ-ускорителей. Как указано в пресс-релизе, этот подход учитывает вычислительный «кремний», стеки HBM и упаковку. Marvell сотрудничает с облачными клиентами и ведущими производителями HBM, такими, как Micron, Samsung и SK hynix. CHBM повышает возможности XPU, ускоряя ввода-вывод между внутренними кристаллами самого ускорителя и базовыми кристаллами HBM. Это приводит к повышению производительности и снижению энергопотребления интерфейса памяти до 70 % по сравнению со стандартными интерфейсами HBM. Оптимизированные интерфейсы также уменьшают требуемую площадь кремния в каждом кристалле, позволяя интегрировать логику для поддержки HBM в базовый кристалл и сэкономить до 25 % площади. 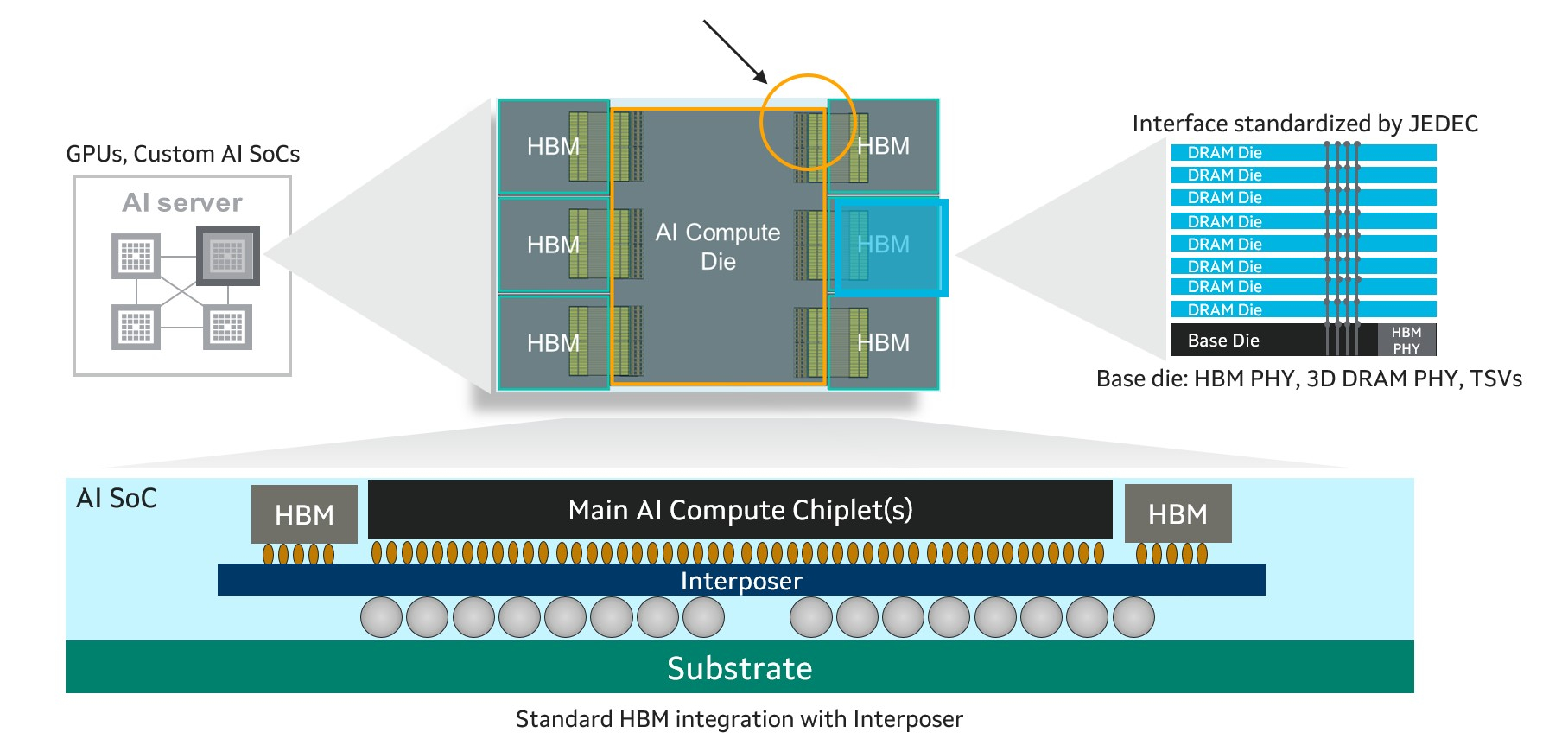
Источник изображений: Marvell Высвободившееся пространство может быть использовано для размещения дополнительных вычислительных или функциональных блоков и поддержки до 33 % большего количества стеков HBM. Всё это повышает производительность и энергоэффективность XPU, одновременно снижая совокупную стоимость владения для операторов облачных инфраструктур. Правда, это же означает и несоответствие стандартами JEDEC. Как отметил ресурс ServeTheHome, HBM4 требует более 2000 контактов, т.е. вдвое больше, чем HBM3. Для кастомного решения нет необходимости в таком количестве контактов, что также высвобождает место для размещения других компонентов. 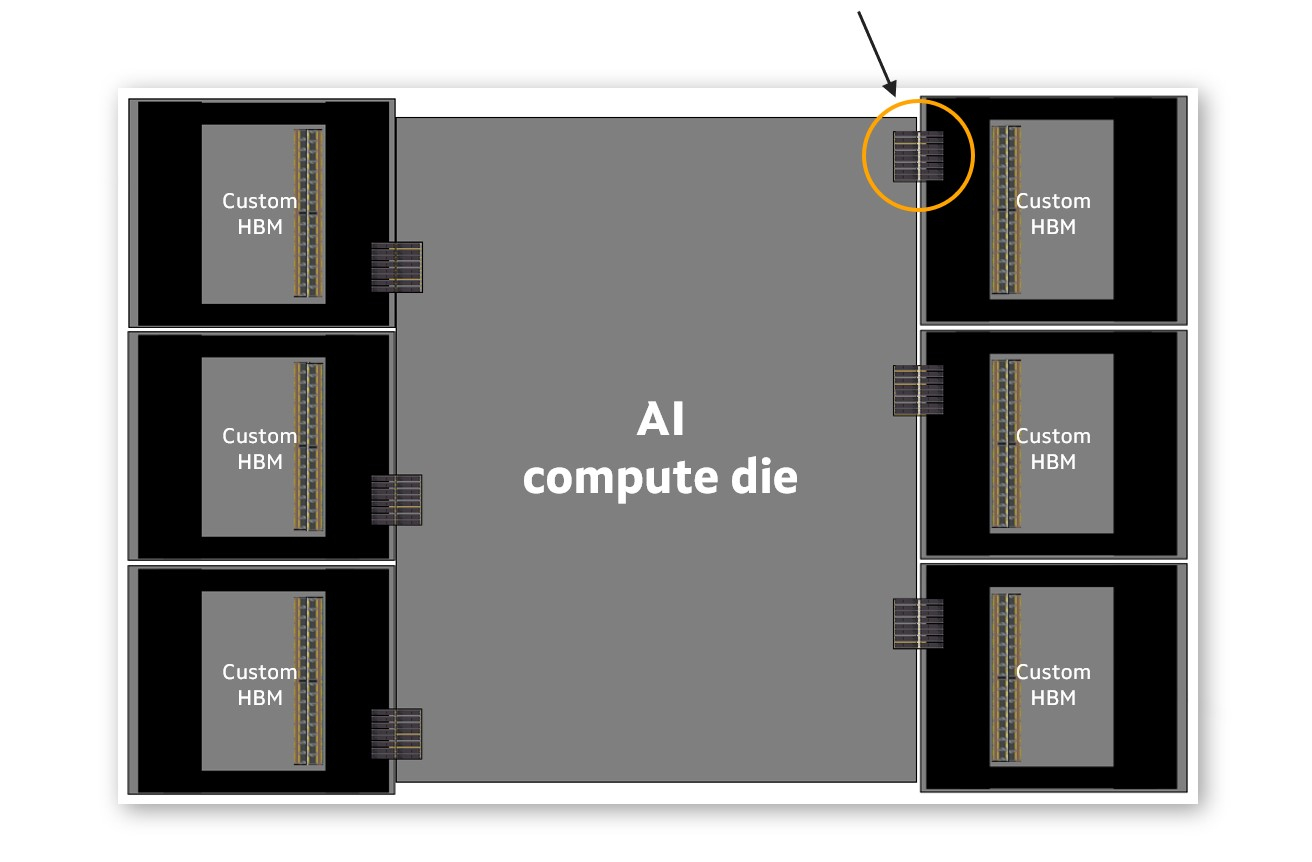 «Ведущие операторы ЦОД масштабируются с помощью индивидуальной инфраструктуры. Улучшение XPU путем адаптации HBM к конкретной производительности, мощности и общей стоимости владения — это последний шаг в новой парадигме разработки и поставки ускорителей ИИ», — сказал Уилл Чу (Will Chu), старший вице-президент Marvell и генеральный менеджер группы Custom, Compute and Storage. В свою очередь, Гарри Юн (Harry Yoon), корпоративный исполнительный вице-президент Samsung Electronics, отметил, что оптимизация HBM для конкретных XPU и программных сред значительно повысит производительность облачной инфраструктуры операторов и её энергоэффективность. Согласно данным ServeTheHome, в этом году гиперскейлеры увеличили капзатраты примерно на $100 млрд. Следующее поколение ИИ-кластеров будет в десять и более раз превосходить по мощности систему xAI Colossus на базе 100 тыс. NVIDIA H100. Отказ от стандартов JEDEC и появление возможности настройки памяти с учётом потребностей гиперскейлеров является монументальным шагом для отрасли. Также этого говорит о нацеленности архитектуры Marvell XPU на гиперскейлеров, поскольку в таком «тюнинге» памяти небольшие заказчики не нуждаются.
04.12.2024 [15:44], Руслан Авдеев
Marvell перенесёт разработку чипов в облако AWS, а AWS получит от Marvell новые чипы для своих ЦОДКомпания Marvell Technology, занимающаяся полупроводниковыми инфраструктурными решениями, объявила о расширении стратегического партнёрства с Amazon Web Services (AWS). Стороны заключили соглашение сроком на пять лет, включающее сотрудничество в работе над несколькими продуктами AWS, а также использование облачной инфраструктуры техногиганта, сообщает пресс-служба Marvell. Соглашение касается широкого спектра решений Marvell, предназначенных для дата-центров. В том числе речь идёт о поставке кастомизированных ИИ-чипов для AWS, оптических и электрических DSP, PCIe-ретаймеров, оптических сетевых решениях, чипсетов для коммутаторов и др. Компетенции Marvell позволят AWS усовершенствовать собственные продукты, сетевое оборудование и СХД, добившись большей эффективности и снижения стоимости эксплуатации. 
Источник изображения: LinkedIn Sales Solutions/unsplash.com Для автоматизации проектирования электроники (EDA) в Marvell приняли подход cloud first, разработка ведётся с использованием облака AWS, где компании доступны практически неограниченные вычислительные ресурсы. В Marvell уже заявили, что решения AWS EDA помогут компании быстро, гибко и безопасно масштабировать проектирование полупроводников с лучшим в своём классе временем выхода на рынок. Сотрудничество играет на руку и AWS — продукты Marvell активно используются в инфраструктуре Amazon.
30.07.2024 [11:30], Сергей Карасёв
Быстрее и надёжнее: DapuStor и Marvell улучшат эффективность и производительность QLC SSDКомпании DapuStor и Marvell объявили о расширении сотрудничества с целью внедрения технологии Flexible Data Placement (FDP) в SSD, построенные на основе чипов памяти QLC и TLC. Применение FDP позволит повысить долговечность, производительность и эффективность накопителей указанных типов. Отмечается, что устройства QLC SSD обеспечивают значительные преимущества в плане вместимости и совокупной стоимости владения (TCO) по сравнению с другими видами твердотельных накопителей. Однако существуют и проблемы: изделия QLC сталкиваются с меньшим сроком службы и более низкой скоростью записи. Совместное решение DapuStor и Marvell призвано устранить эти недостатки. Речь идёт об использовании контроллера Marvell Bravera SC5 и специальной прошивки DapuStor FDP. Технология FDP интеллектуально распределяет данные по флеш-памяти QLC, оптимизируя использование доступных ячеек и сводя к минимуму влияние усиления записи (Write Amplification, WA). Особые алгоритмы динамически контролируют размещение информации в зависимости от рабочей нагрузки и моделей использования, гарантируя, что наиболее часто используемые данные хранятся в самых быстрых и надёжных областях памяти. В результате, повышаются производительность и долговечность накопителя. 
Источник изображения: DapuStor Тестирование показало, что алгоритмы FDP вкупе с контроллером Marvell Bravera SC5 и прошивкой DapuStor позволяют получить значение WA, близкое к 1,0. Иными словами, накопитель использует флеш-память NAND максимально эффективно и без потерь. Кроме того, решение DapuStor FDP включают в себя усовершенствованные методы коррекции ошибок и выравнивания износа. Благодаря этому достигается дополнительное увеличение срока службы и улучшение надёжности QLC SSD. Новая технология будет применяться в накопителях DapuStor QLC серии H5000.
30.06.2021 [22:44], Алексей Степин
Marvell анонсировала 5-нм DPU Octeon 10: 36 ядер ARM Neoverse N2, 400GbE, PCIe 5.0 и DDR5Концепция ускорителя для работы с данными, выделенного DPU, продолжает набирать популярность. В последнее время целый ряд компаний представил свои решения. А на днях очередь дошла до крупного разработчика микроэлектроники, компании Marvell, которая анонсировала DPU серии Octeon 10. Новые сопроцессоры построены на основе наиболее совершенного 5-нм техпроцесса TSMC и должны на равных сражаться с такими соперниками, как ускорители NVIDIA BlueField. Сама Marvell известна разработкой собственных вычислительных ядер, однако в Octeon 10 от этого подхода компания отошла, вернувшись к лицензированию ядер ARM — в основу новой серии чипов легли ядра Neoverse N2. 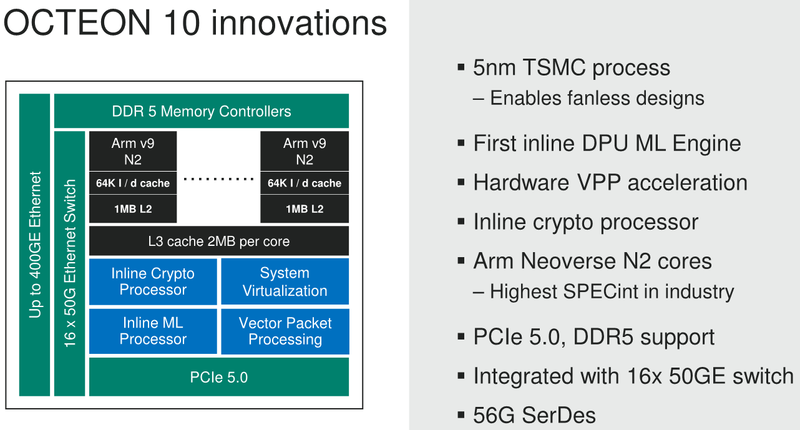 В основе данной архитектуры лежит набор команд ARM v9, появившийся не так уж давно. В сравнении с решениями на базе ARM v8.x эта архитектура может обеспечивать до 40% прироста в производительности, в том числе, за счёт поддержки 128-битных векторных расширений SVE2 и развитой подсистемы кешей. Процессорные ядра в Octeon 10 располагают по 1 и 2 Мбайт кешей второго и третьего уровня на каждое ядро. 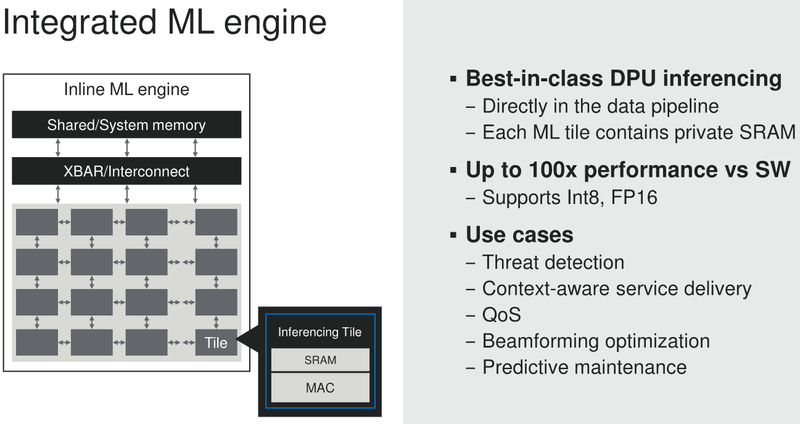 В составе новой SoC также присутствуют блоки ускорения сетевых задач и криптографические акселераторы. Кроме этого, кремний Octeon 10 получил и сетевой коммутатор, обеспечивающий работу 16 портов Ethernet со скоростью 50 Гбит/с. «Прокормить» столь требовательную «семью» непросто, но в плане подсистем ввода-вывода новые DPU также отвечают современным реалиям: они рассчитаны на работу с памятью DDR5-5200 и поддерживают интерфейс PCI Express 5.0, блоки SerDes относятся к поколению 56G. 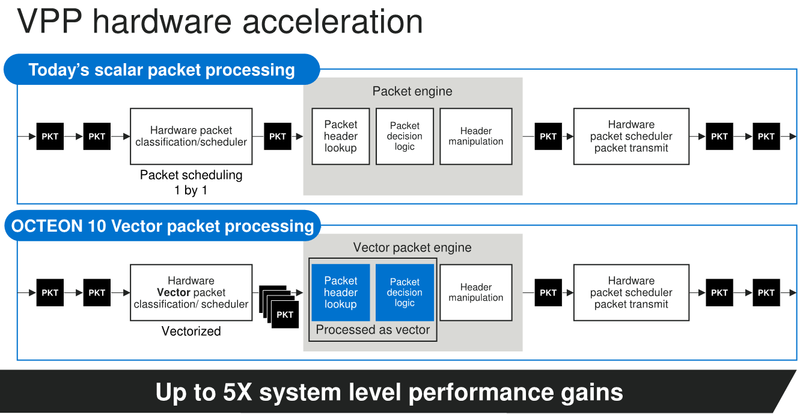 Отдельного упоминания заслуживает движок векторной обработки пакетов (Vector Packet Processing Engine), способный объединять в единую серию сетевые пакеты и «переваривать» их одновременно, как векторные данные. Такой подход позволяет серьёзно снизить латентность, что для DPU очень важно. Имеются в составе Octeon 10 и средства для работы с алгоритмами машинного обучения, причём каждый «тайл», поддерживающий INT8 и FP16, имеет свой объём SRAM. 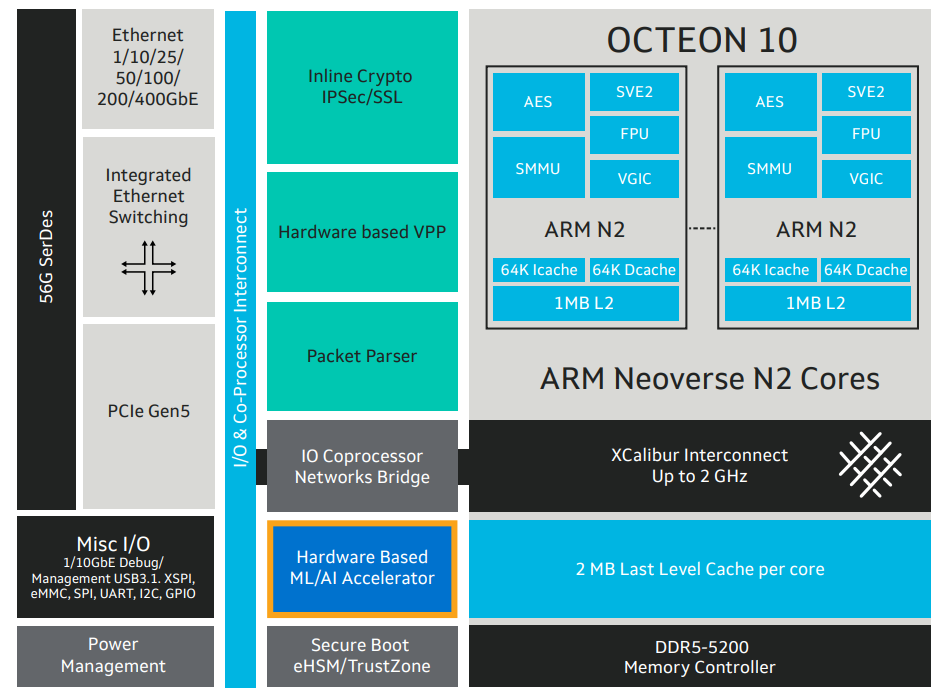 Пока семейство Octeon 10 представлено четырьмя моделями, младшая из которых может содержать до 8 ядер Neoverse N2, а старшая — до 36 таких ядер, причём о масштабировании подсистемы памяти разработчики также подумали и число контроллеров DDR5 в новых чипах варьируется от 2 до 12. Несмотря на столь солидные характеристики, теплопакеты удалось удержать в разумных рамках, и даже у наиболее мощной версии DPU400 TDP составляет всего 60 Ватт. 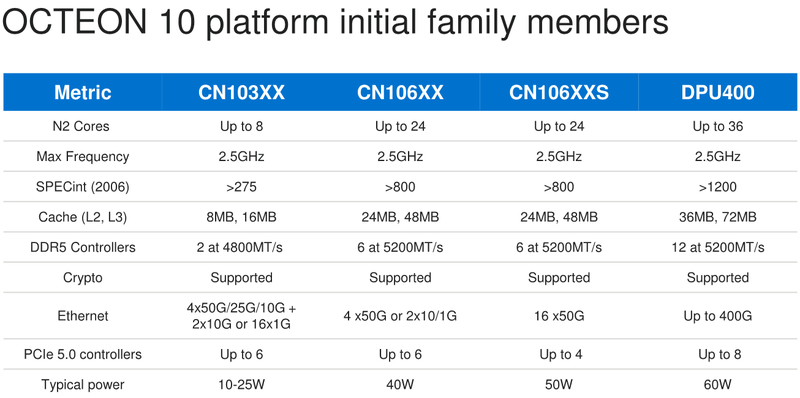 В настоящее время Marvell Octeon 10 уже находится в производстве, первые же партии новых чипов должны поступить к заказчикам во второй половине этого года. Столь многогранные DPU должны найти применение в самых разных сценариях, от поддержания инфраструктуры 5G RAN до работы в составе облачных систем, а также в высокопроизводительных маршрутизаторах.
28.05.2021 [15:28], Сергей Карасёв
Marvell Bravera SC5 — первый в мире SSD-контроллер с поддержкой PCIe 5.0Компания Marvell анонсировала контроллеры Bravera SC5, предназначенные для построения серверных SSD нового поколения с интерфейсом PCIe 5.0. Представлены изделия MV-SS1331 и MV-SS1333 с восемью и шестнадцатью каналами доступа к NAND-памяти (до 1600 МТ/с) соответственно. В семейство Bravera впоследствии войдут и другие продукты. Здесь и ниже изображения Marvell Заявленная скорость последовательного чтения информации может достигать 14 Гбайт/с, скорость последовательной записи — 9 Гбайт/с. Производительность случайного чтения достигает 2 млн IOPS, записи — 1 млн IOPS. Задержка составляет менее 6 мкс, а функция Elastic SLA Enforcer позволит более тонко управлять приоритетами и очередями, а также собирать телеметрию на аппаратном уровне.  В составе изделий задействованы наборы ядер ARM Cortex-R8, Cortex-M7 и Cortex-M3. Есть аппаратные движки для шифрования и обеспечения безопасности. Контроллер поддерживает ECC-память DDR4-3200 и LPDDR4x-4266, а также NAND-чипы SLC/MLC/TLC/QLC от крупнейших производителей: Kioxia, Micron, Samsung, SK hynix, Western Digital и YMTC. Партнёрами в рамках запуска названы AMD, Intel и Renesas. 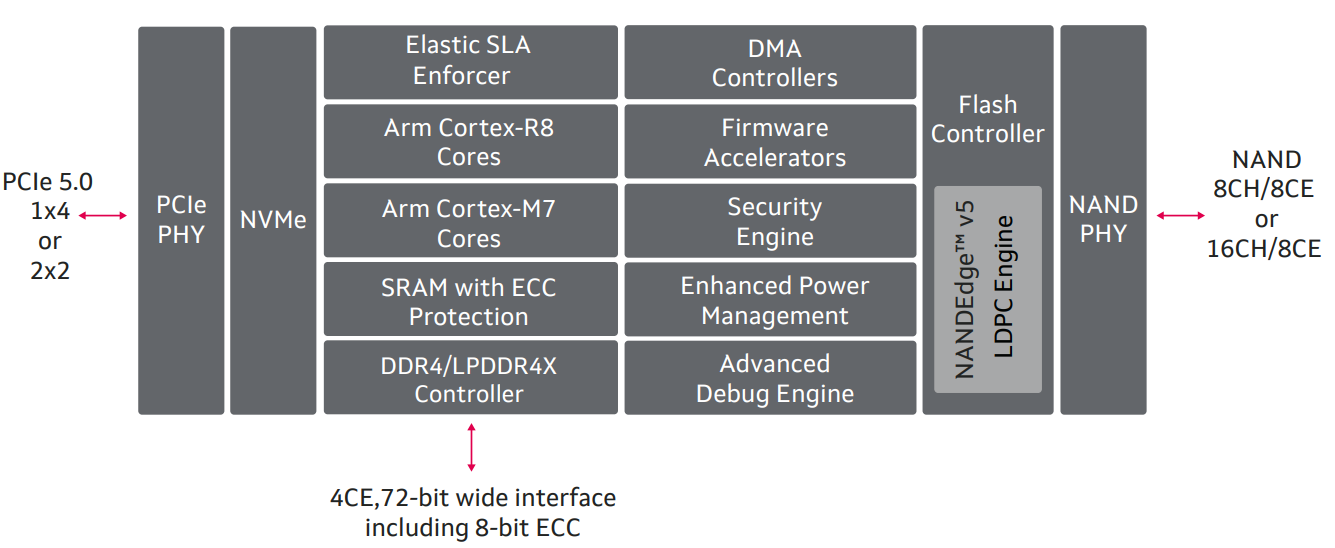 Контроллер поддерживает спецификации NVMe 1.4b и предлагает четыре линии PCIe 5.0 (x4 или два порта x2). Компания постаралась сделать его как можно более универсальным и подходящим как для нужд гиперскейлеров, так и для корпоративных решений. Он поддерживает стандарты ZNS, >Open Channel SSD, Kioxia SEF.  Пробные поставки образцов контроллеров уже начались. Первыми заказчиками стали Facebook✴ и Microsoft, развивающие стандарт OCP Cloud SSD, который несколько шире спецификаций NVMe. Именно на них ориентирована старшая, 16-канальная версия контроллера, которая благодаря своим габаритам (20 × 20 мм) позволяет создавать накопители в форм-факторе EDSFF E1.S. Правда, энергопотребление у неё выше, чем у 8-канальной — 9,8 Вт против 8,7 Вт.
18.08.2020 [22:16], Алексей Степин
Серверные ARM-процессоры Marvell ThunderX3: 60 ядер в SCM, 96 ядер в MCM, SMT4 в подарокПоследние дни оказались богатыми на анонсы новых процессоров. Компания IBM представила новейшие POWER10 с поддержкой памяти OMI DDR5 и PCI Express 5.0, Intel анонсировала Xeon Ice Lake-SP, которые, наконец, получили поддержку PCIe 4.0. Третьей в этом списке можно назвать Marvell, которая на мероприятии Hot Chips 32 рассказала подробности о последнем, третьем поколении ARM-процессоров ThunderX, формально анонсированном ещё весной этого года. 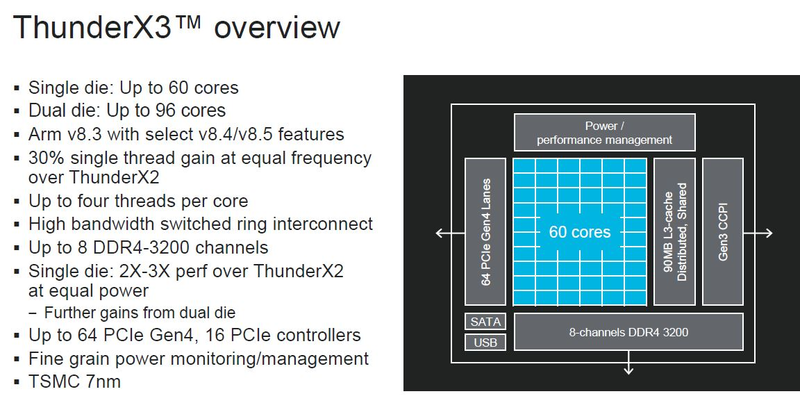
Источник изображений: ServeTheHome Процессоры с архитектурой ARM покорили сегмент мобильных устройств, но в последние несколько лет интереснее другая тенденция — данная архитектура ложится в основу всё новых и новых «крупных» процессоров, предназначенных для серверного применения. И как показывает практика, когда-то считавшаяся «слабой» архитектура оказывается вовсе не такой. 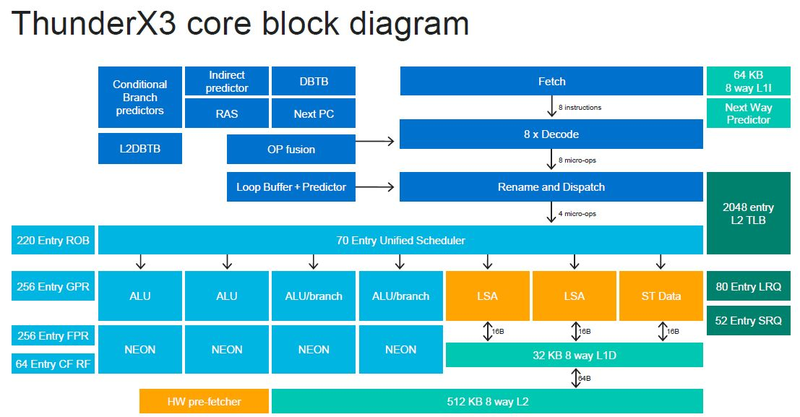 Она успешно соперничает с x86, особенно там, где необходима высокая плотность упаковки вычислительных мощностей и высокая энергоэффективность. Примеры AWS Graviton2 и кастомных процессоров Google тому доказательством, а разработка Fujitsu, процессор A64FX, и вовсе лежит в основе мощнейшего суперкомпьютера планеты, японского кластера Fugaku. 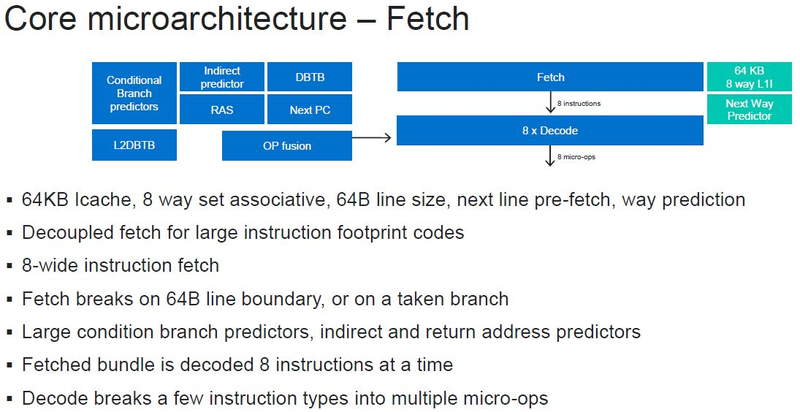 Одной из компаний, прилагающих серьёзные усилия к освоению серверного рынка с помощью архитектуры ARM, является Marvell. Если первые процессоры ThunderX, доставшиеся в наследство от Broadcom, сложно назвать успешным, то уже второе поколение показало себя неплохо, и, судя по всему, третье, наконец, готово к массовому внедрению. Напомним, в отличие от домашних проектов AWS и Google, процессоры ThunderX3 должны получить развитую поддержку многопоточности, на уровне SMT4, что больше, чем у x86, но меньше, чем у POWER10. 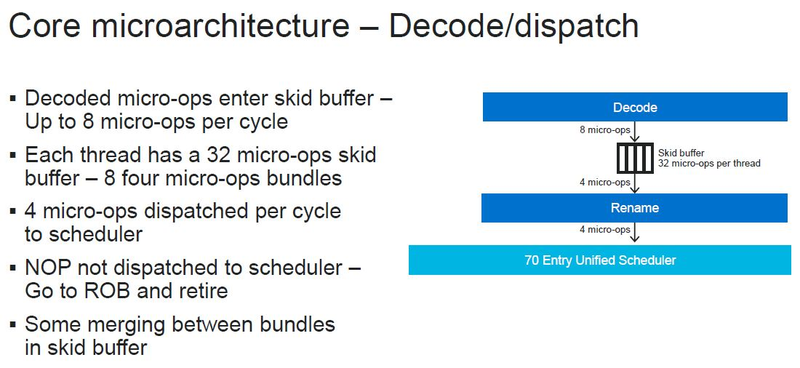 При этом максимальное количество ядер у ThunderX3 впечатляет. Теперь известно, что о 96 ядрах речь идёт только в двухкристалльной компоновке (этим подход Marvell напоминает IBM POWER10, также существующий в двух вариантах). Один кристалл может нести до 60 ядер, что меньше, чем у Graviton2, но, во-первых, ненамного, а во-вторых, с лихвой компенсируется наличием SMT. SMT4 может дать 240 или 384 потока в зависимости от версии, и наверняка это понравится крупным облачным провайдерам, поскольку позволит разместить беспрецедентное количество VM в рамках одного сокета. 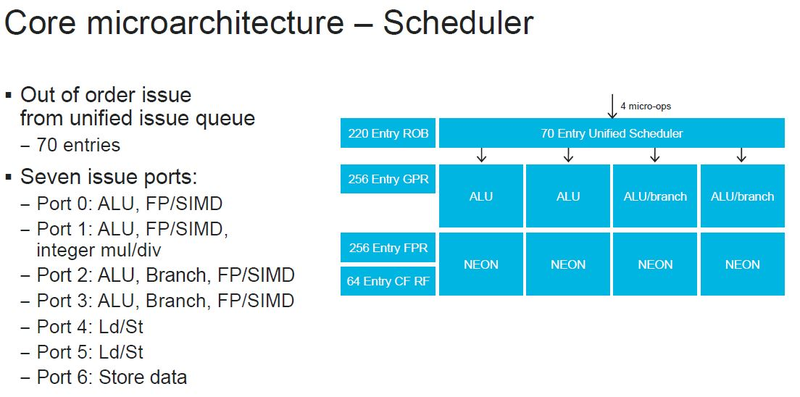 Однопоточная производительность не осталась без внимания. Компания заявила о 30% превосходстве над ThunderX2 в пересчёте на поток. В целом же, третье поколение ThunderX должно быть в 2-3 раза быстрее второго. Архитектурно процессор основывается на наборе инструкций ARM v8.3, однако сказано о частичной поддержке ARM v8.4/8.5. 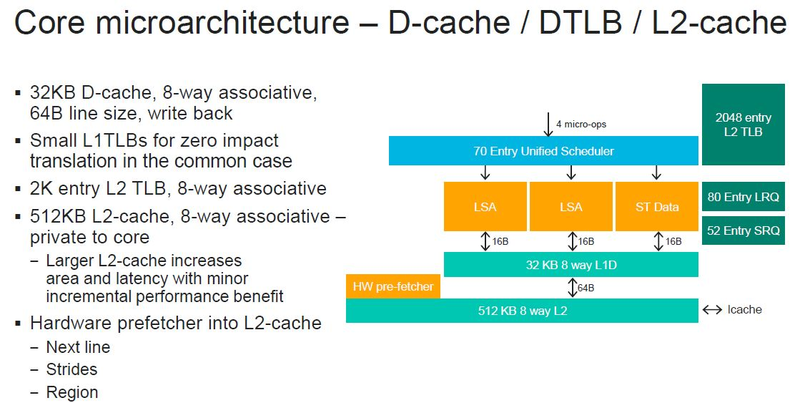 В споре о том, что эффективнее для связи ядер между собой, кольцевые шины или единая mesh-сеть, единого мнения нет. Intel предпочитает первый подход, но Marvell остановила свой выбор на втором. Как обычно, на внешнем кольце расположены кеш (80 Мбайт L3 на кристалл), блоки управление питанием, а также контроллеры памяти, PCI Express и межпроцессорной шины (в данном случае CCPI). 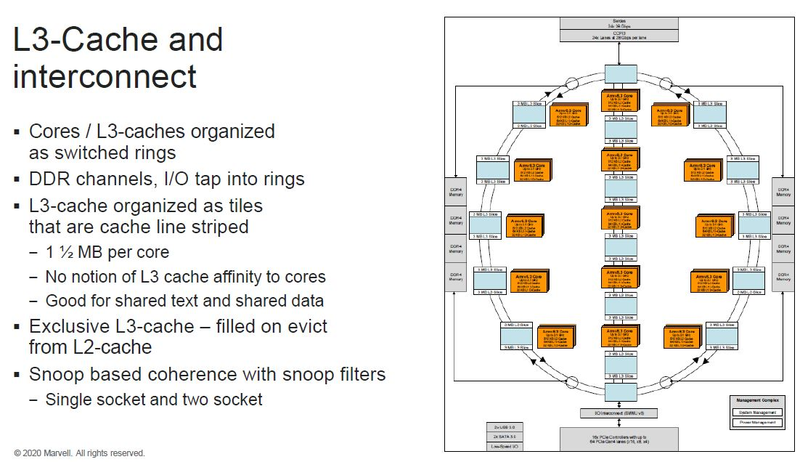 Поддержка SMT4 реализована полностью аппаратно. С точки зрения операционной системы каждый поток ThunderX3 выглядит, как обычный процессор с архитектурой ARM. При этом реализация столь развитой многопоточности привела всего лишь к 5% увеличению площади кристалла в сравнении с однопоточной реализацией.  Разделение ресурсов ядра у нового процессора динамическое, осуществляется оно в четырёх точках: выборка, когда потока с меньшим количеством инструкций получают более высокий приоритет; выполнение, работающее по такому же принципу; планирование, которое базируется на «возрасте» потока; наконец, «отставка» — здесь приоритет получают потоки с наибольшим количеством инструкций. Оптимизация многопоточности позволяет Marvell говорить о практически линейной масштабируемости новых процессоров, по крайней мере, в пределах одного разъёма. В зависимости от числа инструкций на ядро коэффициент прироста может варьироваться от x1,28 до 2,21. 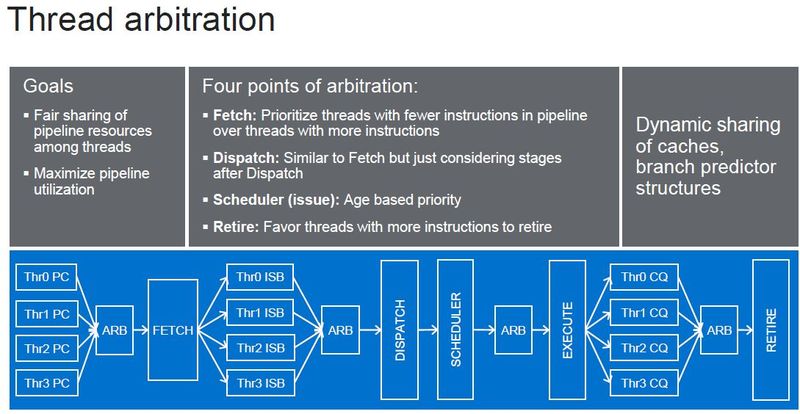 Подсистема ввода-вывода у новинок достаточно развитая. Контроллер памяти имеет 8 каналов и поддерживает DDR4-3200. За поддержку PCI Express отвечают 16 раздельных контроллеров, поддерживающих четвёртую версию стандарта. Это должно обеспечивать высокий уровень производительности при подключении 16 NVMe-накопителей, на каждый из которых придётся по четыре линии PCIe. 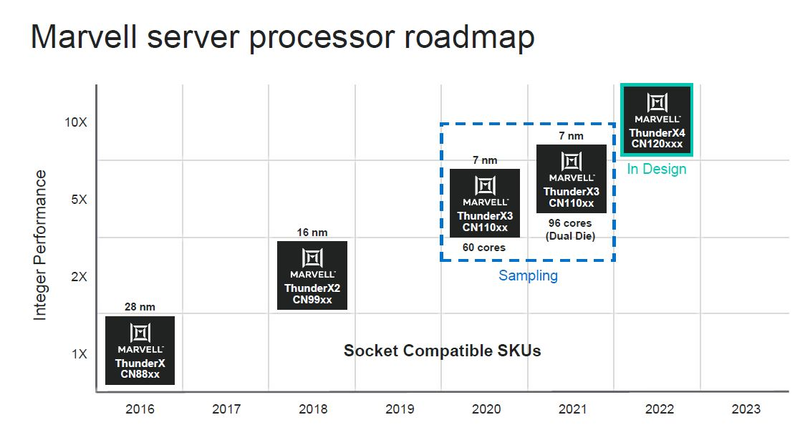 Заявлено о «тонком» управлении питанием, но деталей Marvell не приводит и остаётся только догадываться, насколько эта подсистема ThunderX3 продвинута. Производится новый процессор на мощностях TSMC с использованием техпроцесса 7 нм. Версия с одним 60-ядерным кристаллом выйдет на рынок уже в этом году, а вариант с двумя кристаллами и большим общим количеством ядер начнет поставляться позже, в 2021 году. Компания уже работает над ThunderX4, ожидается что эти процессоры будут использовать техпроцесс 5 нм и увидят свет в 2022 году. |
|

