Материалы по тегу: hpc
|
16.02.2022 [21:17], Алексей Степин
Atos анонсировала экзафлопсные суперкомпьютеры BullSequana XH3000 — гибридные и «зелёные»Atos представила суперкомпьютерную платформу BullSequana XH3000, которая придёт на смену XH2000 и станет основой для машин экзафлопсного класса, ориентированных на такие требовательные к вычислениям области науки как климатология, фармакология и генетика. Суперкомпьютер имеет гибридную архитектуру и на данный момент является самым мощным и энергоэффективным решением в арсенале Atos. Что немаловажно, новая система разработана в Европе и будет производиться на заводе Atos в городе Анже ( Франция). Начало коммерческих поставок запланировано на IV квартал 2022 года.  Наиболее интересной особенностью BullSequana XH3000, пожалуй, можно назвать действительно беспрецедентный уровень гибридизации архитектур «под одной крышей». В рамках одного кластера могут быть задействованы вычислительные архитектуры AMD, Intel, NVIDIA и даже чипы, разрабатываемые консорциумом EPI, в том числе SiPearl. А в будущем возможна интеграция квантовых систем. Такая гибкость позволяет компании-разработчику говорить о шестикратном превосходстве новинки над решениями предыдущего поколения.  Кроме того, Atos весьма серьёзное внимание уделяет проблеме энергоэффективности и экологичности. В BullSequana XH3000 используется последнее, четвёртое поколение систем жидкостного охлаждения с «прямым контактом», которое минимум на 50% эффективнее предыдущего поколения. К тому же, вся платформа спроектирована таким образом, чтобы весь её жизненный цикл, от добычи материалов и производства до демонтажа и утилизации, был как можно более «зелёным». Новый суперкомпьютер изначально спроектирован как масштабируемое решение — будут доступны конфигурации производительностью от 1 Пфлопс до 1 Эфлопс, а к моменту появления ускорителей следующего поколения появятся и варианты с производительностью 10 Экзафлопс. Также разработчики обращают внимание на крайнюю гибкость BullSequana XH3000 по части интерконнекта — она будет совместима с фирменной фабрикой BXI, Ethernet, а также InfiniBand HDR/NDR.
25.01.2022 [03:33], Владимир Мироненко
Meta✴ и NVIDIA построят самый мощный в мире ИИ-суперкомпьютер RSC: 16 тыс. ускорителей A100 и хранилище на 1 ЭбайтMeta✴ (ранее Facebook✴) анонсировала новый крупномасштабный исследовательский кластер — ИИ-суперкомпьютер Meta✴ AI Research SuperCluster (RSC), предназначенный для ускорения решения задач в таких областях, как обработка естественного языка (NLP) с обучением всё более крупных моделей и разработка систем компьютерного зрения. На текущий момент Meta✴ RSC состоит из 760 систем NVIDIA DGX A100 — всего 6080 ускорителей. К июлю этого года, как ожидается, система будет включать уже 16 тыс. ускорителей. Meta✴ ожидает, что RSC станет самым мощным ИИ-суперкомпьютером в мире с производительностью порядка 5 Эфлопс в вычислениях смешанной точности. Близкой по производительность системой станет суперкомпьютер Leonardo, который получит 14 тыс. NVIDIA A100. 
Изображения: Meta✴ Meta✴ RSC будет в 20 раз быстрее в задачах компьютерного зрения и в 3 раза быстрее в обучении больших NLP-моделей (счёт идёт уже на десятки миллиардов параметров), чем кластер Meta✴ предыдущего поколения, который включает 22 тыс. NVIDIA V100. Любопытно, что даже при грубой оценке производительности этого кластера он наверняка бы попал в тройку самых быстрых машин нынешнего списка TOP500.  Новый же кластер создаётся с прицелом на возможность обучения моделей с триллионом параметров на наборах данных объёмом порядка 1 Эбайт. Именно такого объёма хранилище планируется создать для Meta✴ RSC. Сейчас же система включает массив Pure Storage FlashArray объемом 175 Пбайт, 46 Пбайт кеш-памяти на базе систем Penguin Computing Altus и массив Pure Storage FlashBlade ёмкостью 10 Пбайт. Вероятно, именно этой СХД и хвасталась Pure Storage несколько месяцев назад, не уточнив, правда, что речь шла об HPC-сегменте.  Итоговая пропускная способность хранилища должна составить 16 Тбайт/с. Meta✴ RSC сможет обучать модели машинного обучения на реальных данных, полученных из социальных сетей компании. В качестве основного интерконнекта используются коммутаторы NVIDIA Quantum и адаптеры HDR InfiniBand (200 Гбит/с), причём, судя по видео, с жидкостным охлаждением. Каждому ускорителю полагается выделенное подключение. Фабрика представлена двухуровневой сетью Клоза.  Meta✴ также разработала службу хранения AI Research Store (AIRStore) для удовлетворения растущих требований RSC к пропускной способности и ёмкости. AIRStore выполняет предварительную обработку данных для обучения ИИ-моделей и предназначена для оптимизации скорости передачи. Компания отдельно подчёркивает, что все данные проходят проверку на корректность анонимизации. Более того, имеется сквозное шифрование — данные расшифровываются только в памяти узлов, а ключи регулярно меняются. 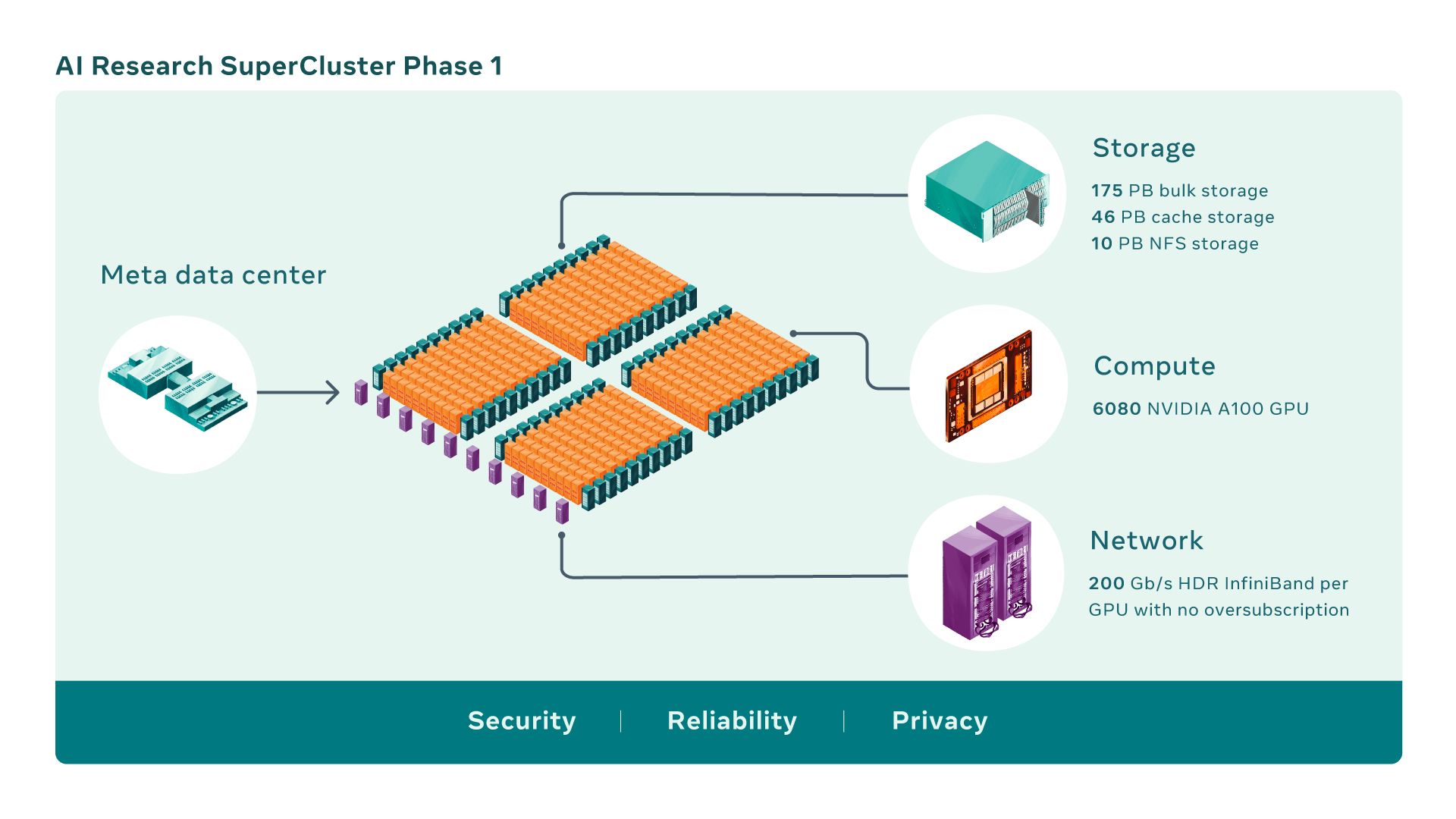 Однако ни о стоимости проекта, ни о потребляемой мощности, ни о физическом местоположении Meta✴ RSC, ни даже о том, почему были выбраны узлы DGX, а не HGX (или вообще другие ускорители), Meta✴ не рассказала. Для NVIDIA же эта машина определённо стала очень крупным и важным заказом.
11.01.2022 [16:02], Сергей Карасёв
NVIDIA купила Bright Computing, разработчика решений для управления НРС-кластерамиКомпания NVIDIA сообщила о заключении соглашения по приобретению фирмы Bright Computing, разработчика специализированных программных продуктов для управления кластерами. О сумме сделки ничего не сообщается. Bright Computing была выделена из состава нидерландской ClusterVision в 2009 году; последняя после банкротства в 2019 году была поглощена Taurus Group. Штаб-квартира Bright Computing базируется в Амстердаме. Основным направлением деятельности компании является разработка инструментов, позволяющих автоматизировать процесс построения и управления Linux-кластерами. 
Источник изображения: Bright Computing В число клиентов Bright Computing входят более 700 корпораций и организаций по всему миру. Среди них упоминаются Boeing, Siemens, NASA, Университет Джонса Хопкинса и др. Отмечается, что NVIDIA и Bright сотрудничают уже более десяти лет. Речь идёт об интеграции ПО с аппаратными платформами и другими продуктами NVIDIA. Поглощение Bright Computing, как ожидается, позволит NVIDIA предложить новые решения в области НРС, которые будут отличаться относительной простотой развёртывания и управления. Эти решения могут применяться в дата-центрах, в составе различных облачных платформ и edge-систем. В рамках сделки вся команда Bright Computing присоединится к NVIDIA.
16.11.2021 [03:33], Игорь Осколков
TOP500: уж ноябрь на дворе, а экзафлопса не видатьПоследняя версия публичного рейтинга самых производительных в мире суперкомпьютеров TOP500 так и осталась без экзафлопсных машин. Китай не захотел включать в него две системы такого класса и пошёл обходным путём, номинировав работы своих учёных на премию Гордона Белла — в соответствующих научных работах даны неполные характеристики машин и показатели их производительности. Поэтому лидером списка остаётся обновлённая японская система Fugaku, 7,6 млн ядер которой выдают 442 Пфлопс. И она всё ещё втрое быстрее своего ближайшего конкурента Summit. Первые результаты сборки Frontier в список попасть не успели. Всего в ноябрьском рейтинге есть порядка 70 новых систем, но, как и прежде, больше половины из них — однотипные системы Lenovo, массово устанавливаемые в Китае. На Китай вообще приходится более трети (34,6%) систем в списке. На втором месте находятся США (29,8%), а на третьем — Япония (6,4%). По суммарной производительности Топ-3 тот же, но порядок иной: США (32,5%), Япония (20,7%), Китай (17,5%). В число лидеров также входят Германия, Франция, Нидерланды, Канада, Великобритания, Южная Корея и Россия. У РФ теперь есть сразу семь машин в списке с суммарной производительностью 73,715 Пфлопс. Для сравнения — Perlmutter (5 место) после апгрейда выдаёт 70,87 Пфлопс, а у Южной Кореи тоже есть семь машин, но с чуть более высокой суммарной производительностью в 82,177 Пфлопс. 
Суперкомпьютер Chervonenkis (Фото: Яндекс) К уже имевшимся в TOP500 российским системам MTS GROM (294 место), Lomonosov-2 (Ломоносов-2, 241 место) и Christofari (Кристофари, 72 место) добавились Christofari Neo (Кристофари Нео, 43 место), а также сразу три системы Яндекса: Ляпунов (Lyapunov, 40 место), Галушкин (Galushkin, 36 место) и Червоненкис (Chervonenkis, 19 место). Примечательно, что все российские системы этого года используют AMD EPYC Rome и NVIDIA A100, а также интерконнект Infininiband. Машины для МТС и Сбера сделала сама NVIDIA (это всё DGX), а вот у Яндекса путь особый. Ляпунов (12,81 Пфлопс) создан китайским Национальным университетом оборонных технологий (National University of Defense Technology, NUDT) и Inspur на базе серверов NF5488A5 (AMD EPYC 7662@2 ГГц + A100 40 Гбайт). Червоненкис (21,53 Пфлопс) и Галушкин (16,02 Пфлопс) разработаны IPE, NVIDIA и Tyan. В этих системах используются EPYC 7702 (тоже 64-ядерные с базовой частотой 2 ГГц) и более новые A100 (80 Гбайт). Среди прочих новых систем TOP500 особо выделяется Voyager-EUS2, которая замыкает Топ-10. Это ещё система на базе обновлённых инстансов Microsoft Azure ND A100 v4 с 80-Гбайт версией A100. Однако ещё одной облачной машиной уже никого не удивить, в отличие от совершенно неожиданного возврата японской PEZY, пропавшей с радаров после скандала 2017 года. Новая ZettaScaler3.0 занимает 453 место и базируется на AMD EPYC 7702P и фирменных ускорителях PEZY-SC3. 
Изображение: OGAWA, Tadashi (twitter.com/ogawa_tter) В целом, последний год был удачным и для AMD, и для NVIDIA. Первая почти втрое нарастила число систем на базе EPYC — их теперь в списке 74 (или почти треть новых участников списка), если учитывать Naples/Hygon (таких систем 3). Если же смотреть более детально именно на CPU, то тут лидером всё равно остаётся Intel, хотя она и потеряла несколько процентных пунктов за последние полгода — всего 408 машин используют её процессоры. Правда, новейших Ice Lake-SP среди них всего 10, тогда как у EPYC Milan уже 17. Без акселераторов обходятся 350 суперкомпьютеров списка, зато из 150 оставшихся 143 используют различные поколения ускорителей NVIDIA. Удивительно, но ни одной системы с ускорителями AMD Instinct в ноябрьском рейтинге нет. Остальные акселераторы представлены в единичном экземпляре. И это либо устаревшие системы, либо экзотика из Китая и Японии. Последняя в лице MN-3 всё ещё лидирует по энергоэффективности в Green500. Систем с Infiniband в списке 178, с Ethernet — 242. Как обычно, по производительности систем лидирует именно IB — 44,5% против 22,4% у Ethernet. Это, к слову, несколько отличается от показателей HPC-индустрии в целом, где в количественном выражении у них практически равные доли. На Omni-Path пришлось 40 систем в TOP500, и столько же на проприетарные интерконнекты. Тут интересно разве что появление второй машины с Atos BXI V2. 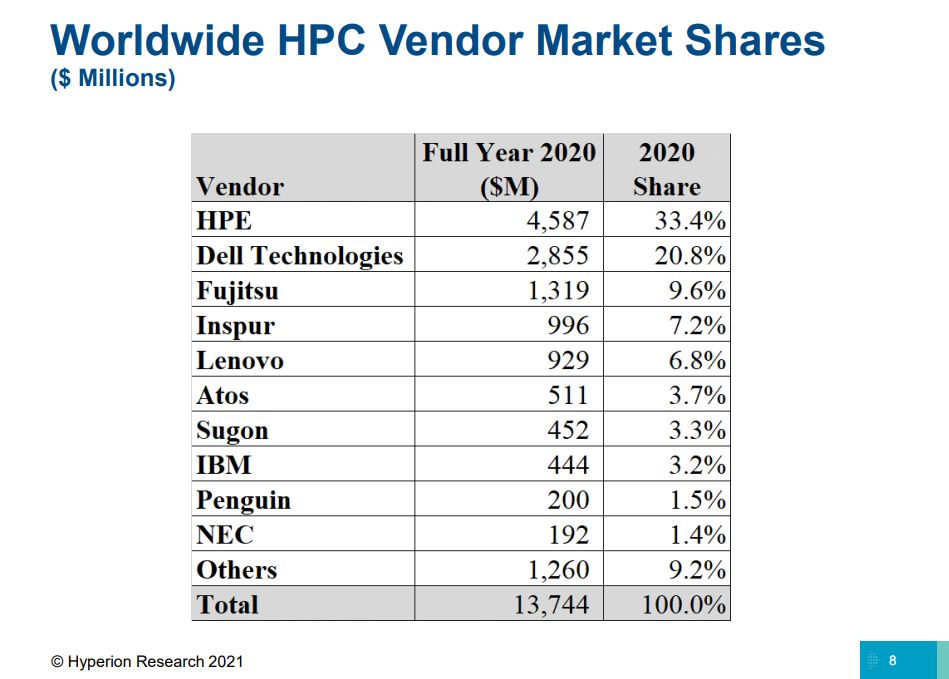 Среди производителей по количеству машин лидируют Lenovo (180 шт., это в основном уже упомянутые типовые развёртывания в Китае), HPE (84 шт., сюда же входит наследие Cray и SGI) и Inspur (50 шт.). По производительности картина иная, в Топ-3 входят HPE, Fujitsu (во многом благодаря Fugaku) и Lenovo. По HPC-рынку в целом, согласно данным Hyperion Research, в денежном выражении тройка лидеров включает HPE, Dell и Fujitsu (да, опять «виноват» Fugaku).
28.10.2021 [17:02], Алексей Степин
Rockport Networks представила интерконнект с пассивным оптическим коммутаторомПроизводительность любого современного суперкомпьютера или кластера во многом зависит от интерконнекта, объединяющего вычислительные узлы в единое целое, и практически обязательным компонентом такой сети является коммутатор. Однако последнее не аксиома: компания Rockport Networks представила своё видение HPC-систем, не требующее использования традиционных коммутирующих устройств. Проблема межсоединений существовала в мире суперкомпьютеров всегда, даже в те времена, когда сам процессор был набором более простых микросхем, порой расположенных на разных платах. В любом случае узлы требовалось соединять между собой, и эта подсистема иногда бывала неоправданно сложной и проблемной. Переход на стандартные сети Ethernet, Infiniband и их аналоги многое упростил — появилась возможность собирать суперкомпьютеры по принципу конструктора из стандартных элементов. 
Пассивный оптический коммутатор SHFL Тем не менее, проблема масштабирования (в том числе и на физическом уровне кабельной инфраструктуры), повышения скорости и снижения задержек никуда не делась. У DARPA даже есть особый проект FastNIC, нацеленный на 100-кратное ускорение сетевых интерфейсов, чтобы в конечном итоге сгладить разницу в скорости обмена данными внутри узлов и между ними.  Сам по себе высокоскоростной коммутатор для HPC-систем — устройство непростое, требующее использования недешёвого и сложного кремния, и вкупе с остальными компонентами интерконнекта может составлять заметную долю от стоимости всего кластера в целом. При этом коммутаторы могут вносить задержки, по определению являясь местами избыточной концентрации данных, а также требуют дополнительных мощностей подсистем питания и охлаждения.  Подход, продвигаемый компанией Rockport Networks, свободен от этих недостатков и изначально нацелен на минимизацию точек избыточности и возможных коллизий. А достигнуто это благодаря архитектуре, в которой концепция традиционного сетевого коммутатора отсутствует изначально. Вместо этого имеется специальный модуль SHFL, в котором топология сети задаётся оптически, а все логические задачи берут на себя специализированные сетевые адаптеры, работающие под управлением фирменной ОС rNOS и имеющие на борту сконфигурированную нужным образом ПЛИС. 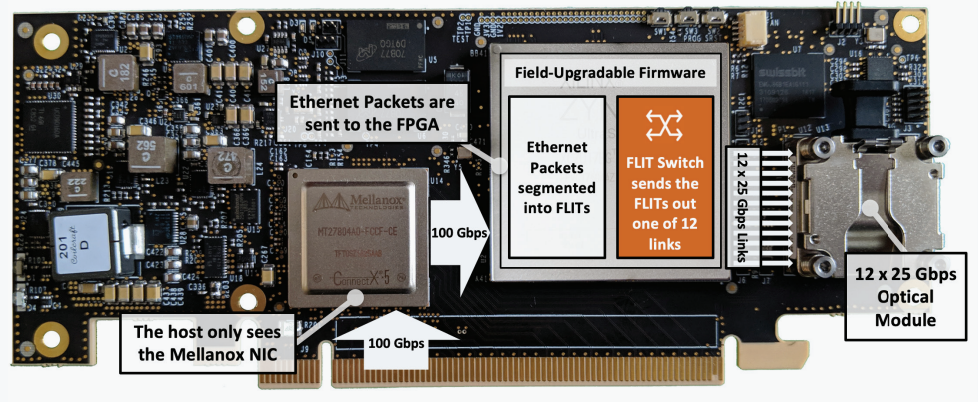 Модуль SHFL даже не требует отдельного электропитания, а вот адаптеры Rockport NC1225 его хотя и требуют, но умещаются в конструктив низкопрофильного адаптера с разъёмом PCIe x16 и потребляют всего 36 Вт. Правда, в настоящий момент речь идёт только о PCIe 3.0, поэтому полнодуплексного подключения на скорости 200 Гбит/с пока нет. Тем не менее, Техасский центр передовых вычислений (TACC) посчитал, что этого уже достаточно и стал одним из первых заказчиков — 396 узлов суперкомпьютера Frontera используют решение Rockport. 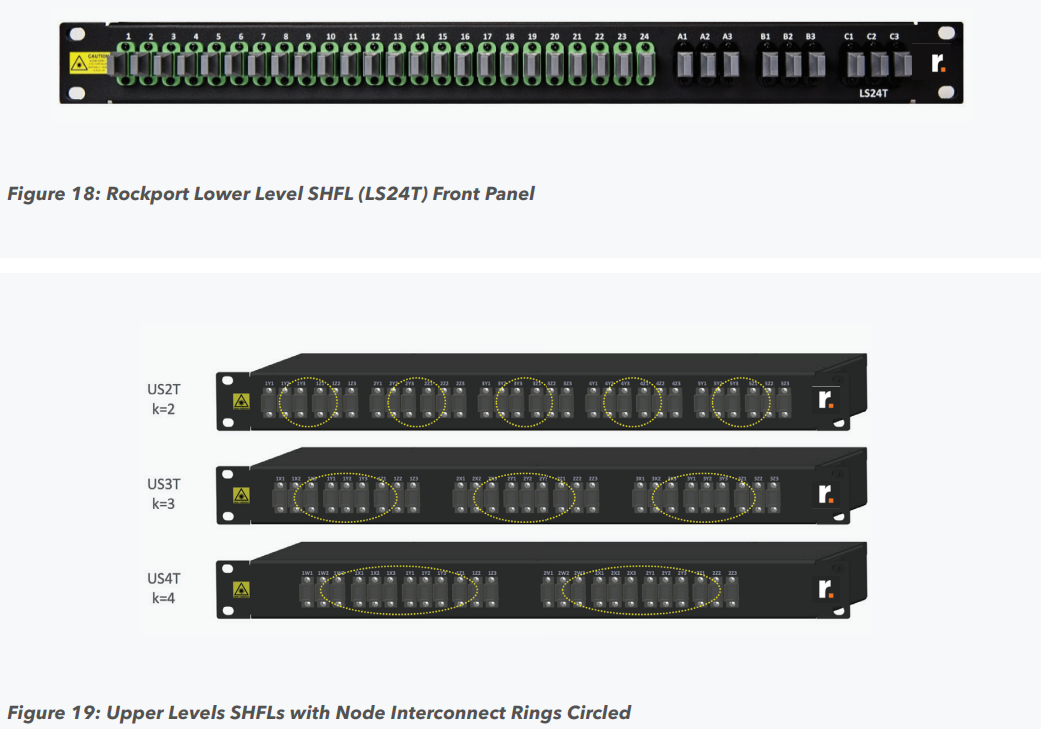 Использование не совсем традиционной оптической сети, впрочем, накладывает свои особенности: вместо популярных *SFP-корзин используются разъёмы MTP/MPO-24, а каждый кабель даёт для подключения 12 отдельных волокон, что при скорости 25 Гбит/с на волокно позволит достичь совокупной пропускной способности 300 Гбит/с. ОС и приложениям адаптер «представляется» как чип Mellanox ConnectX-5, который и входит в его состав, а потому не требует каких-то особых драйверов или модулей ядра. 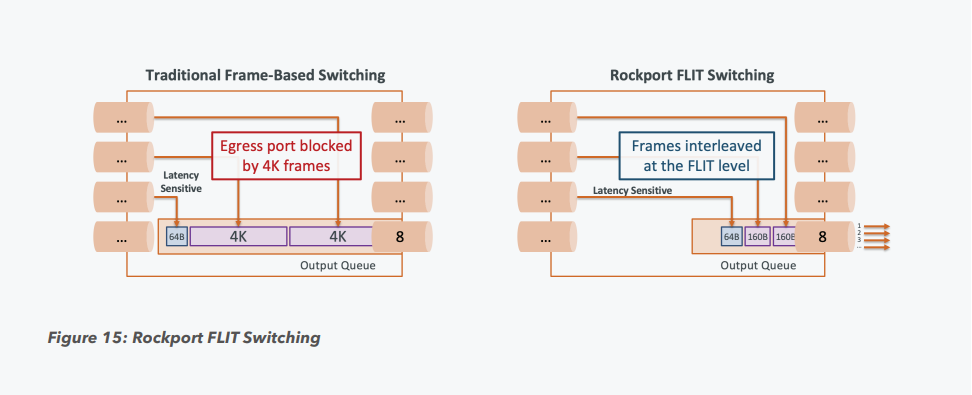 Rockport фактически занимается транспортировкой Ethernet и реализует уровень OSI 1/1.5, однако традиционной коммутации как таковой нет — адаптеры самостоятельно определяют конфигурацию сети и оптимальные маршруты передачи сигнала по отдельным волокнам с возможностью восстановления связности на лету при каких-либо проблемах. Весь трафик разбивается на маленькие кусочки (FLIT'ы) и отправляется по виртуальным каналам (VC) с чередованием, что позволяет легко управлять приоритизацией (в том числе на L2/L3) и снизить задержки.  SHFL имеет 24 разъёма для адаптеров и ещё 9 для объединения с другими SHFL и Ethernet-шлюзами для подключения к основной сети ЦОД (в ней сеть Rockport видна как обычная L2). Таким образом, в составе кластера каждый узел может быть подключён как минимум к 12 другим узлам на скорости 25 Гбит/с. Однако топологию можно менять по своему усмотрению. Компания-разработчик заявляет о преимуществе своего интерконнекта на классических HPC-задачах, могущем достигать почти 30% при сравнении c InfiniBand класса 100G и даже 200G. Кроме того, для Rockport требуется на 72% меньше кабелей.
22.10.2021 [20:03], Руслан Авдеев
Для обеспечения работы суперкомпьютера El Capitan потребуется 28 тыс. тонн воды и 35 МВт энергииК моменту ввода в эксплуатацию в 2023 году суперкомпьютер El Capitan на базе AMD EPYC Zen4 и Radeon Instinct, как ожидается, будет иметь самую высокую в мире производительность — более 2 Эфлопс. А это означает, что ему потребуются гигантские мощности для питания и охлаждения. Ливерморская национальная лаборатория (LLNL), в которой и будет работать El Capitan, поделилась подробностями о масштабном проекте, призванном обеспечить HPC-центр необходимой инфраструктурой. В основе плана модернизации лежит проект Exascale Computing Facility Modernization (ECFM) стоимостью около $100 млн. В его рамках будет обновлена уже существующая в LLNL инфраструктура. Для реализации проекта необходимо получить очень много разрешений от местных регуляторов и очень тесно взаимодействовать с местными поставщиками электроэнергии. Тем не менее, LLNL заявляет, что проект «почти готов», по некоторым оценкам — на 93%. Функционировать новая инфраструктура должна с мая 2022 года (с опережением графика).  Сам проект стартовал ещё в 2019 году и, согласно планам, должен быть полностью завершён в июле 2022 года. В его рамках модернизируют территорию центра, введённого в эксплуатацию в 2004 году, общей площадью около 1,4 га. Если раньше центр, в котором работали системы вроде лучшего для 2012 года суперкомпьютера Sequoia (ныне выведенного из эксплуатации), обеспечивал подачу до 45 МВт, то теперь инфраструктура рассчитана уже на 85 МВт. Конечно, даже для El Capitan такие мощности будут избыточны — ожидается, что суперкомпьютер будет потреблять порядка 30-35 МВт. Однако LLNL заранее думает о «жизнеобеспечении» преемника El Capitan. Следующий суперкомпьютер планируется ввести в эксплуатацию до того, как его предшественник будет отключён в 2029 году. Кроме того, для новой системы потребуется установка нескольких 3000-тонных охладителей. Если раньше общая ёмкость системы охлаждения составляла 10 000 т воды, то теперь она вырастет до 28 000 т.
22.09.2021 [21:16], Алексей Степин
Выпущена тестовая партия европейских высокопроизводительных RISC-V процессоров EPI EPAC1.0Наличие собственных высокопроизводительных процессоров и сопровождающей их технической инфраструктуры — в современном мире вопрос стратегического значения для любой силы, претендующей на первые роли. Консорциум European Processor Initiative (EPI), в течение долгого времени работавший над созданием мощных процессоров для нужд Евросоюза, наконец-то, получил первые весомые плоды. О проекте EPI мы неоднократно рассказывали читателям в 2019 и 2020 годах. В частности, в 2020 году к консорциуму по разработке мощных европейских процессоров для систем экза-класса присоединилась SiPearl. Но сегодня достигнута первая серьёзная веха: EPI, насчитывающий на данный момент 28 членов из 10 европейских стран, наконец-то получил первую партию тестовых образцов процессоров EPAC1.0. 
Источник изображений: European Processor Initiative (EPI) По предварительным данным, первичные тесты новых чипов прошли успешно. Процессоры EPAC имеют гибридную архитектуру: в качестве базовых вычислительных ядер общего назначения в них используются ядра Avispado с архитектурой RISC-V, разработанные компанией SemiDynamics. Они объединены в микро-тайлы по четыре ядра и дополнены блоком векторных вычислений (VPU), созданным совместно Барселонским Суперкомпьютерным Центром (Испания) и Университетом Загреба (Хорватия). 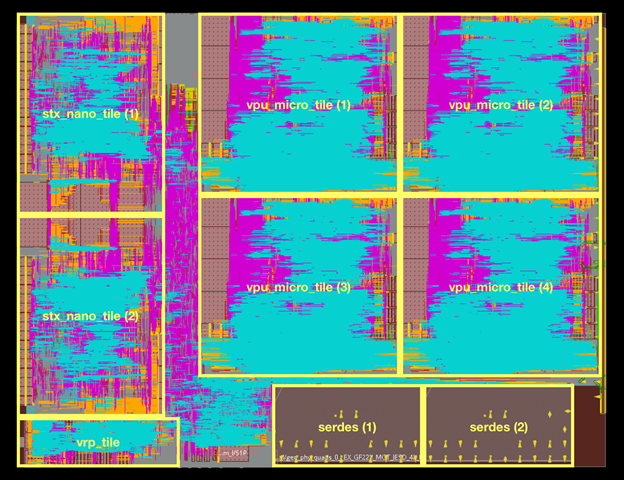
Строение кристалла EPAC1.0 Каждый такой тайл содержит блоки Home Node (интерконнект) с кешем L2, обеспечивающие когерентную работу подсистем памяти. Имеется в составе EPAC1.0 и описанный нами ранее тензорно-стенсильный ускоритель STX, к созданию которого приложил руку небезызвестный Институт Фраунгофера (Fraunhofer IIS). Дополняет картину блок вычислений с изменяемой точностью (VRP), за его создание отвечала французская лаборатория CEA-LIST. Все ускорители в составе нового процессора связаны высокоскоростной сетью, использующей SerDes-блоки от EXTOLL.  Первые 143 экземпляра EPAC произведены на мощностях GlobalFoundries с использованием 22-нм техпроцесса FDX22 и имеют площадь ядра 27 мм2. Используется упаковка FCBGA 22x22. Тактовая частота невысока, она составляет всего 1 ГГц. Отчасти это следствие использования не самого тонкого техпроцесса, а отчасти обусловлено тестовым статусом первых процессоров. Но новорожденный CPU жизнеспособен: он успешно запустил первые написанные для него программы, в числе прочего, ответив традиционным «42» на главный вопрос жизни и вселенной. Ожидается, что следующее поколение EPAC будет производиться с использованием 12-нм техпроцесса и получит чиплетную компоновку.
28.08.2021 [00:16], Владимир Агапов
Кластер суперчипов Cerebras WSE-2 позволит тренировать ИИ-модели, сопоставимые по масштабу с человеческим мозгомВ последние годы сложность ИИ-моделей удваивается в среднем каждые два месяца, и пока что эта тенденция сохраняется. Всего три года назад Google обучила «скромную» модель BERT с 340 млн параметров за 9 Пфлоп-дней. В 2020 году на обучение модели Micrsofot MSFT-1T с 1 трлн параметров понадобилось уже порядка 25-30 тыс. Пфлоп-дней. Процессорам и GPU общего назначения всё труднее управиться с такими задачами, поэтому разработкой специализированных ускорителей занимается целый ряд компаний: Google, Groq, Graphcore, SambaNova, Enflame и др.  Особо выделятся компания Cerebras, избравшая особый путь масштабирования вычислительной мощности. Вместо того, чтобы печатать десятки чипов на большой пластине кремния, вырезать их из пластины, а затем соединять друг с другом — компания разработала в 2019 г. гигантский чип Wafer-Scale Engine 1 (WSE-1), занимающий практически всю пластину. 400 тыс. ядер, выполненных по 16-нм техпроцессу, потребляют 15 кВт, но в ряде задач они оказываются в сотни раз быстрее 450-кВт суперкомпьютера на базе ускорителей NVIDIA.  В этом году компания выпустила второе поколение этих чипов — WSE-2, в котором благодаря переходу на 7-нм техпроцесс удалось повысить число тензорных ядер до 850 тыс., а объём L2-кеша довести до 40 Гбайт, что примерно в 1000 раз больше чем у любого GPU. Естественно, такой подход к производству понижает выход годных пластин и резко повышает себестоимость изделий, но Cerebras в сотрудничестве с TSMC удалось частично снизить остроту этой проблемы за счёт заложенной в конструкцию WSE избыточности. 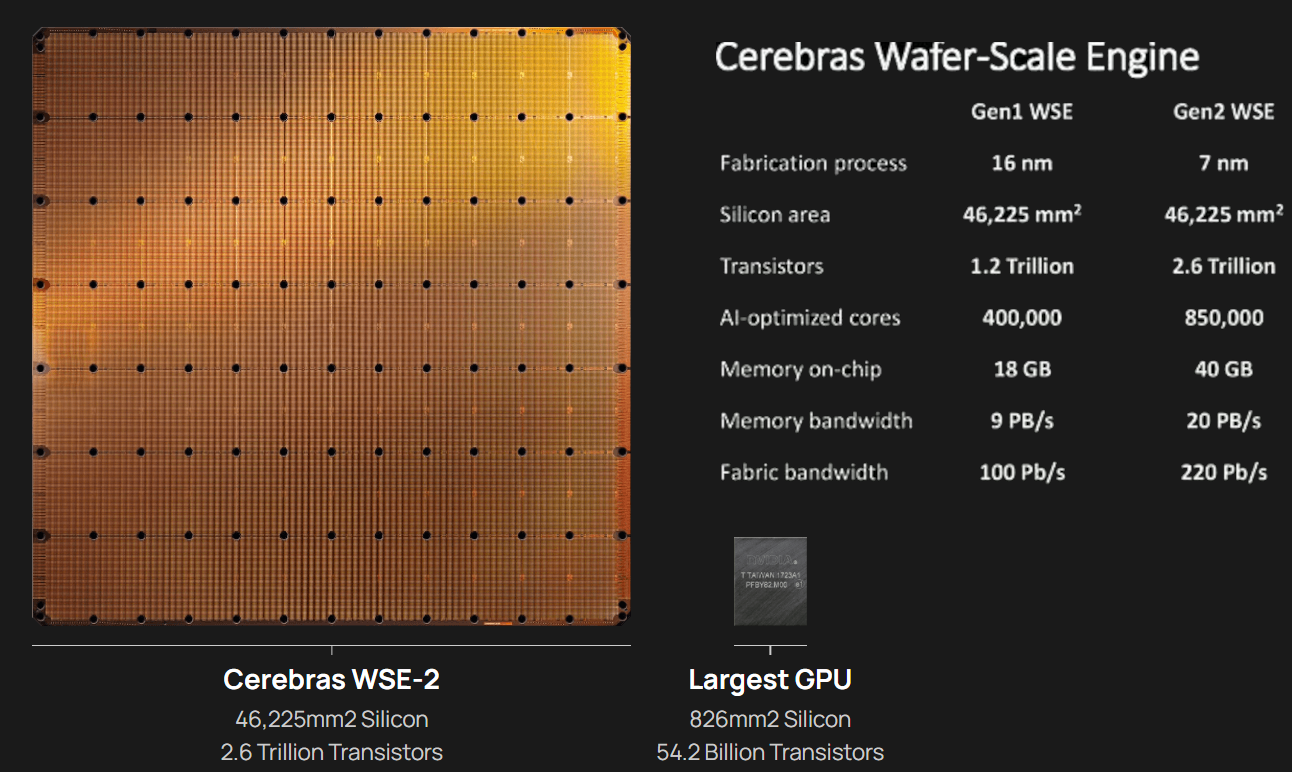 Благодаря идентичности всех ядер, даже при неисправности некоторых их них, изделие в целом сохраняет работоспособность. Тем не менее, себестоимость одной 7-нм 300-мм пластины составляет несколько тысяч долларов, в то время как стоимость чипа WSE оценивается в $2 млн. Зато система CS-1, построенная на таком процессоре, занимает всего треть стойки, имея при этом производительность минимум на порядок превышающую самые производительные GPU. Одна из причин такой разницы — это большой объём быстрой набортной памяти и скорость обмена данными между ядрами.  Тем не менее, теперь далеко не каждая модель способна «поместиться» в один чип WSE, поэтому, по словам генерального директора Cerebras Эндрю Фельдмана (Andrew Feldman), сейчас в фокусе внимания компании — построение эффективных систем, составленных из многих чипов WSE. Скорость роста сложности моделей превышает возможности увеличения вычислительной мощности путём добавления новых ядер и памяти на пластину, поскольку это приводит к чрезмерному удорожанию и так недешёвой системы.  Инженеры компании рассматривают дезагрегацию как единственный способ обеспечить необходимый уровень производительности и масштабируемости. Такой подход подразумевает разделение памяти и вычислительных блоков для того, чтобы иметь возможность масштабировать их независимо друг от друга — параметры модели помещаются в отдельное хранилище, а сама модель может быть разнесена на несколько вычислительных узлов CS, объединённых в кластер. 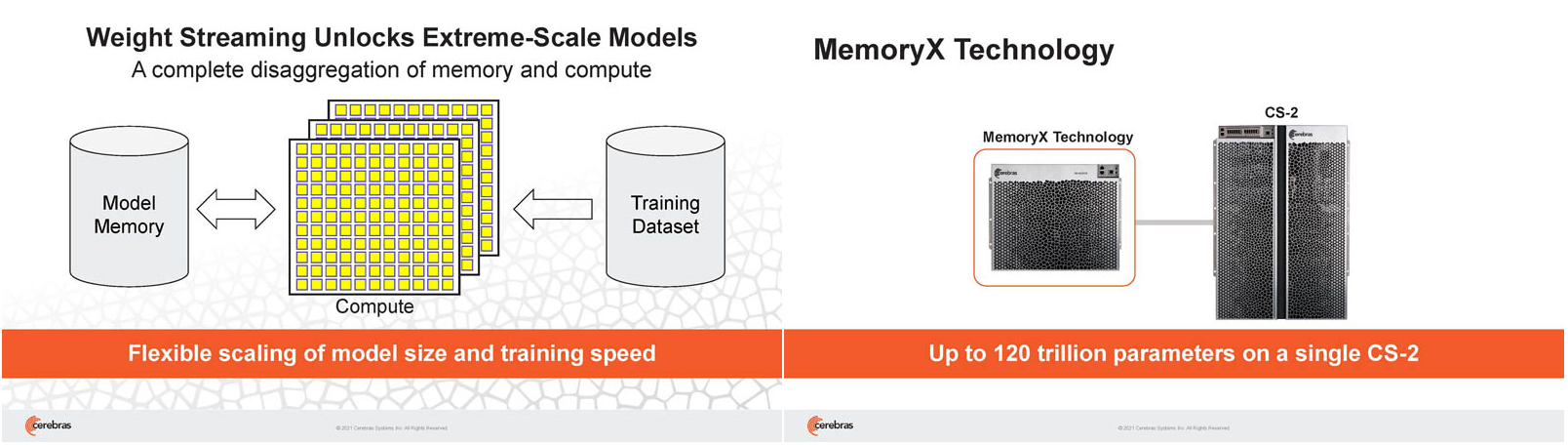 На Hot Chips 33 компания представила особое хранилище под названием MemoryX, сочетающее DRAM и флеш-память суммарной емкостью 2,4 Пбайт, которое позволяет хранить до 120 трлн параметров. Это, по оценкам компании, делает возможным построение моделей близких по масштабу к человеческому мозгу, обладающему порядка 80 млрд. нейронов и 100 трлн. связей между ними. К слову, флеш-память размером с целую 300-мм пластину разрабатывает ещё и Kioxia.  Для обеспечения масштабирования как на уровне WSE, так и уровне CS-кластера, Cerebras разработала технологию потоковой передачи весовых коэффициентов Weight Streaming. С помощью неё слой активации сверхкрупных моделей (которые скоро станут нормой) может храниться на WSE, а поток параметров поступает извне. Дезагрегация вычислений и хранения параметров устраняет проблемы задержки и узости пропускной способности памяти, с которыми сталкиваются большие кластеры процессоров. 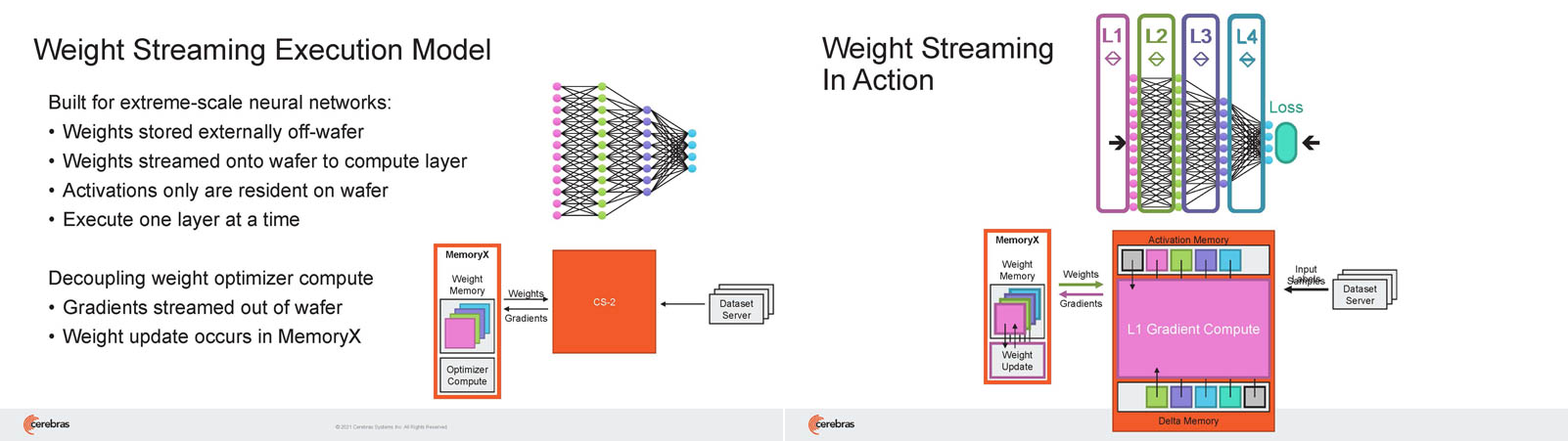 Это открывает широкие возможности независимого масштабирования размера и скорости кластера, позволяя хранить триллионы весов WSE-2 в MemoryX и использовать от 1 до 192 CS-2 без изменения ПО. В традиционных системах по мере добавления в кластер большего количества вычислительных узлов каждый из них вносит всё меньший вклад в решение задачи. Cerebras разработала интерконнект SwarmX, позволяющий подключать до 163 млн вычислительных ядер, сохраняя при этом линейность прироста производительности. 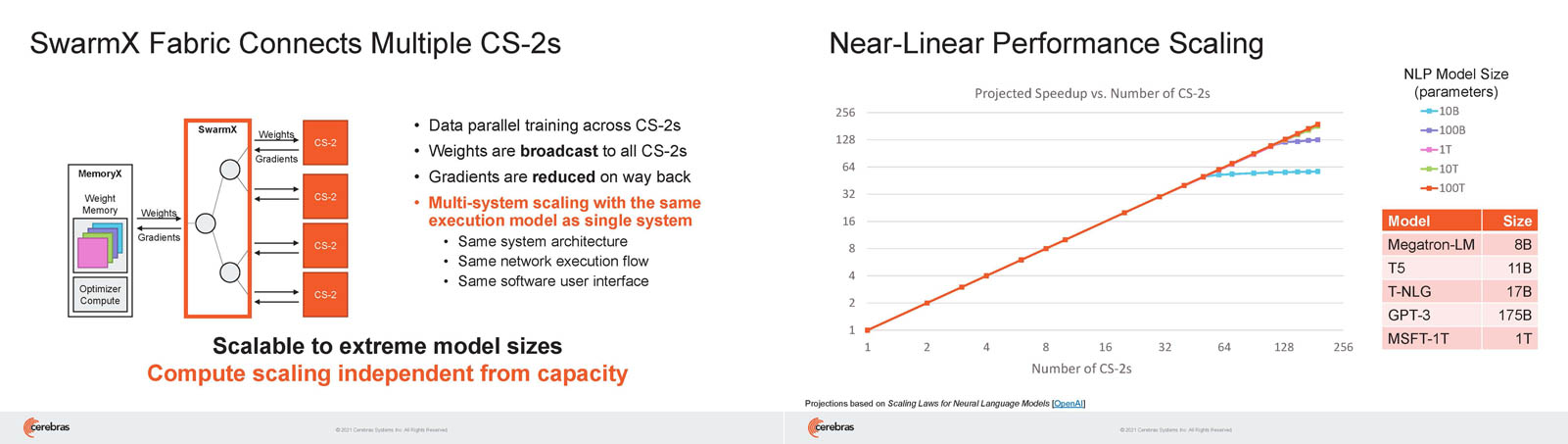 Также, компания уделила внимание разрежённости, то есть исключения части незначимых для конечного результата весов. Исследования показали, что должная оптимизации модели позволяет достичь 10-кратного увеличения производительности при сохранении точности вычислений. В CS-2 доступна технология динамического изменения разрежённости Selectable Sparsity, позволяющая пользователям выбирать необходимый уровень «ужатия» модели для сокращение времени вычислений.  «Крупные сети, такие как GPT-3, уже изменили отрасль машинной обработки естественного языка, сделав возможным то, что раньше было невозможно и представить. Индустрия перешла к моделям с 1 трлн параметров, а мы расширяем эту границу на два порядка, создавая нейронные сети со 120 трлн параметров, сравнимую по масштабу с мозгом» — отметил Фельдман.
19.08.2021 [16:00], Игорь Осколков
Intel анонсировала ускорители Xe HPC Ponte Vecchio: 100+ млрд транзисторов, микс 5/7/10-нм техпроцессов Intel и TSMC и FP32-производительность 45+ ТфлопсКак и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.  Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.  Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.  Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.  Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков. 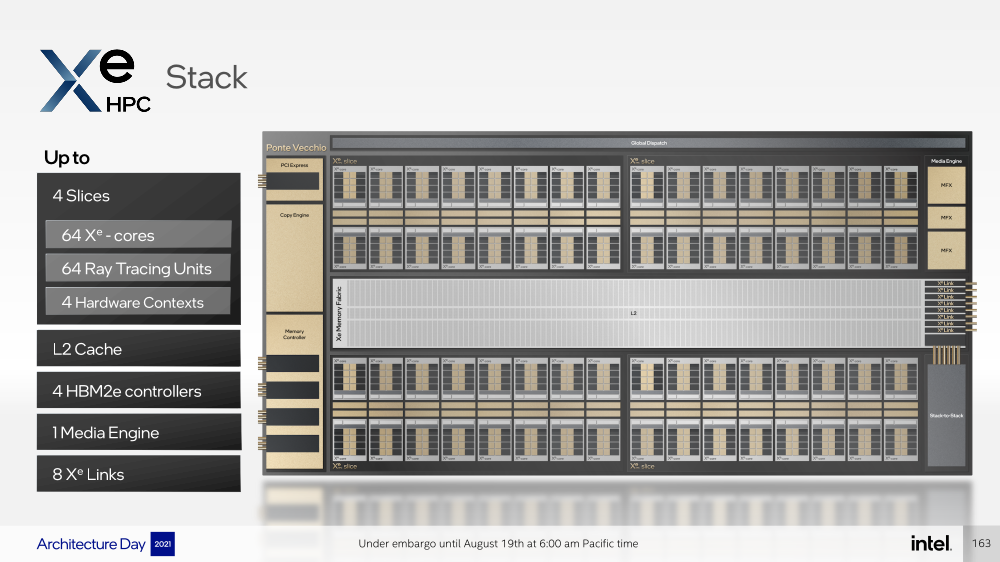 Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом. 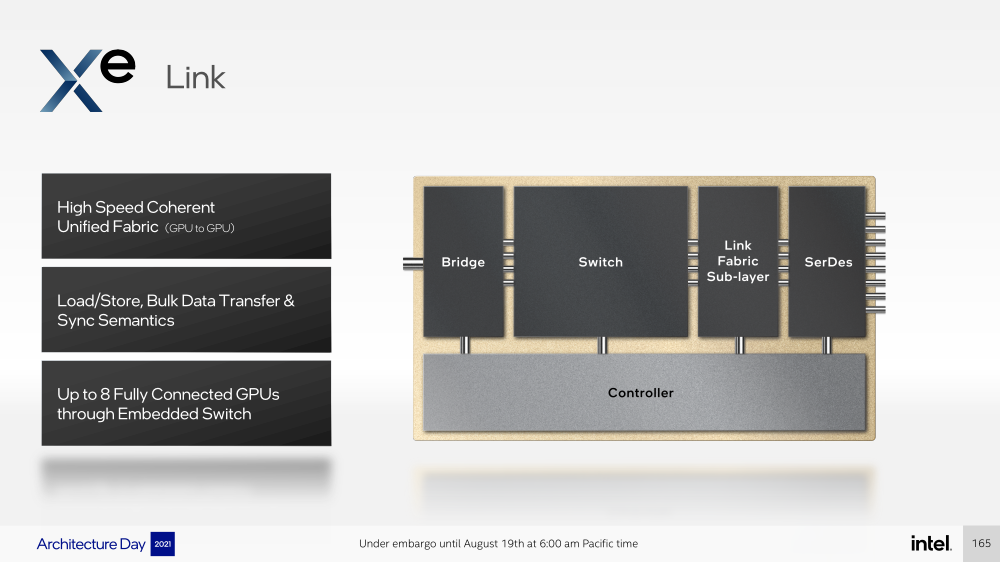  В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс. 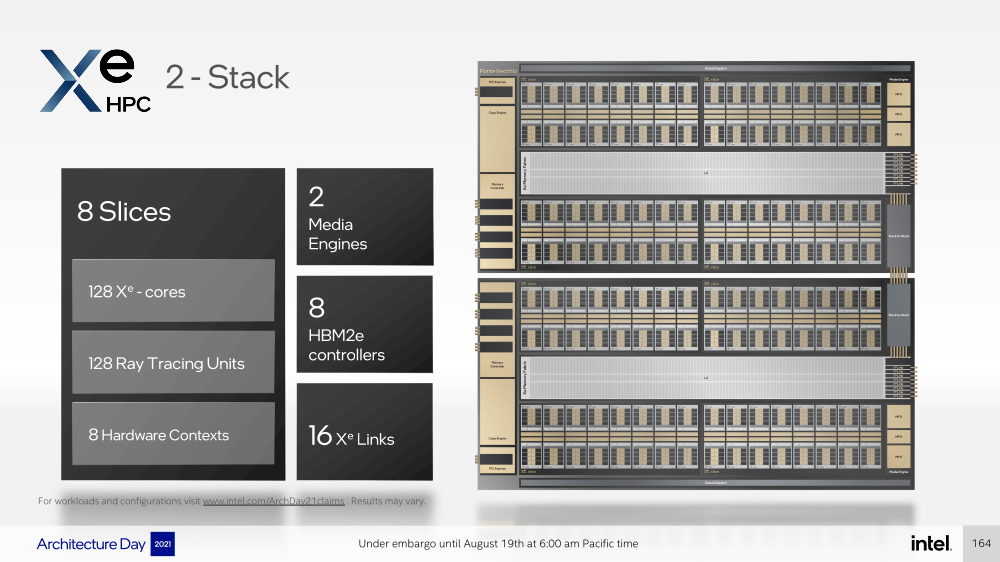 Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.  В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).  Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA.
16.07.2021 [17:31], Алексей Степин
Японский облачный суперкомпьютер ABCI подвергся модернизацииПопулярность идей машинного обучения и искусственного интеллекта приводит к тому, что многие страны и организации планируют обзавестись HPC-системами, специально предназначенными для этого класса задач. В частности, Токийский университет совместно с Fujitsu модернизировал существующую систему ABCI (AI Bridging Cloud Infrastructure), снабдив её новейшими процессорами Intel Xeon и ускорителями NVIDIA. Как правило, когда речь заходит о суперкомпьютерах Fujitsu, вспоминаются уникальные наработки компании в сфере HPC — процессоры A64FX, но ABCI имеет более традиционную гетерогенную архитектуру. Изначально этот облачный суперкомпьютер включал в себя вычислительные узлы на базе Xeon Gold и ускорителей NVIDIA V100, объединённых 200-Гбит/с интерконнектом. В качестве файловой системы применена разработка IBM — Spectrum Scale. Это одна систем, специально созданных для решения задач искусственного интеллекта, при этом доступная независимым исследователям и коммерческим компаниям. 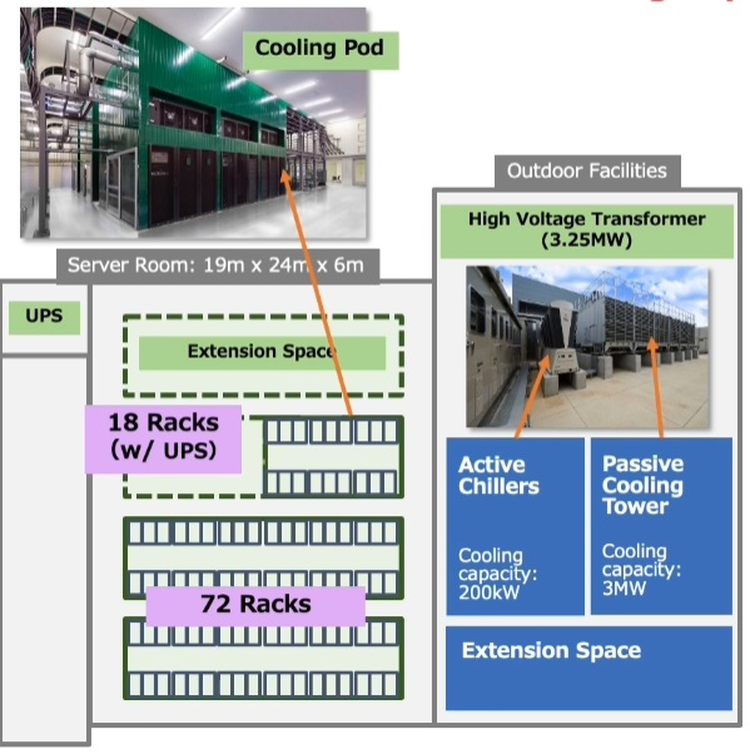 Так, 86% пользователей ABCI не входят в состав Японского национального института передовых технических наук (AIST); их число составляет примерно 2500. Но система явно нуждалась в модернизации. Как отметил глава AIST, с 2019 года загруженность ABCI выросла вчетверо, и сейчас на ней запущено 360 проектов, 60% из которых от внешних заказчиков. Сценарии использования самые разнообразные, от распознавания видео до обработки естественных языков и поиска новых лекарств. 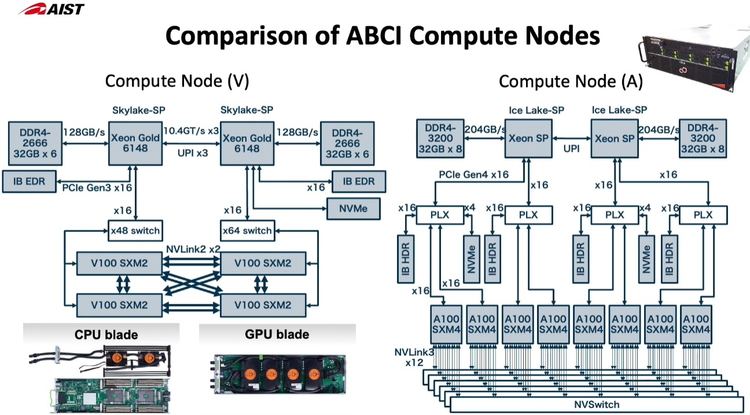
Новые узлы ABCI 2.0 заметно отличаются по архитектуре от старых Как и в большей части систем, ориентированных на машинное обучение, упор при модернизации ABCI был сделан на вычислительную производительность в специфических форматах, включая FP32 и BF16. Изначально в состав ABCI входило 1088 узлов, каждый с четырьмя ускорителями V100 формата SXM2 и двумя процессорами Xeon Gold 6148. После модернизации к ним добавилось 120 узлов на базе пары Xeon Ice Lake-SP и восьми ускорителей A100 формата SXM4. Здесь вместо InfiniBand EDR используется уже InfiniBand HDR. 
Стойка с новыми вычислительными узлами ABCI 2.0 Согласно предварительным ожиданиям, производительность обновлённого суперкомпьютера должна вырасти практически в два раза на задачах вроде ResNet50, в остальных случаях заявлен прирост производительности от полутора до трёх раз. На вычислениях половинной точности речь идёт о цифре свыше 850 Пфлопс, что вплотную приближает ABCI к системам экза-класса. Разработчики также надеются повысить энергоэффективность системы путём применения специфических ускорителей, включая ASIC, но пока речь идёт о связке Intel + NVIDIA. ABCI и сейчас можно назвать экономичной системой — при максимальной общей мощности комплекса 3,25 МВт сам суперкомпьютер при полной нагрузке потребляет лишь 2,3 МВт. Поскольку система ориентирована на предоставление вычислительных услуг сторонним заказчикам, модернизировано и системное ПО, в котором упор сместился в сторону контейнеризации. |
|

