Лента новостей
|
30.08.2023 [16:04], Алексей Степин
Google Cloud анонсировала новое поколение собственных ИИ-ускорителей TPU v5eКак известно, Google Cloud использует в своей инфраструктуре не только сторонние ускорители, но и TPU собственной разработки. Эти кастомные ASIC компания продолжает активно развивать — она анонсировала предварительную доступность виртуальных машин с новейшими TPU v5e, разработка которых заняла более двух лет. Сам чип TPU v5e позиционируется Google как эффективный со всех точек зрения ускоритель, предназначенный для обучения нейросетей или инференс-систем среднего и большого классов. В сравнении с TPU v4 он, по словам Google, обеспечивает вдвое более высокую производительность в пересчёте на доллар для обучения больших языковых моделей (LLM) и генеративных нейросетей. Для инференс-систем преимущество по тому же критерию составляет 2,5x. В сравнении с аналогичными решениями на базе других чипов, например, GPU, выигрыш может составить и 4x. Каждый чип TPU v5e включает четыре блока матричных вычислений, по одному блоку для скалярных и векторных расчётов, а также HBM2-память. 
Источник изображения: Google Компания отмечает, что не экономит на технических характеристиках TPU v5e в угоду рентабельности. Кластеры могут включать до 256 чипов TPU v5e, объединённых высокоскоростным интерконнектом с совокупной пропускной способностью более 400 Тбит/с. Производительность такой платформы составляет 100 Попс (Петаопс) в INT8-вычислениях. Правда, здесь есть нюанс: INT8-производительности TPU v5e составляет 393 Тфлопс против 275 Тфлопс у v4, но вот BF16-производительность у TPU v4 составляет те же 275 Тфлопс, тогда как у v5e этот показатель равен уже 197 Тфлопс. 
Источник изображения: Google В настоящее время для предварительного тестирования доступно уже восемь вариантов инстансов на базе v5e, а в зависимости от конфигурации количество TPU может составлять от 1 до более чем 250. В рамках платформы обеспечена полная интеграция с Google Kubernetes Engine, собственной платформой Vertex AI, а также с большинством современных фреймворков, включая PyTorch, TensorFlow и JAX. Работа с TPU v5e будет значительно дешевле, чем с TPU v4 — $1,2/час против $3,4/час (за чип). 
Источник изображения: Google В настоящее время машины с TPU v5e доступны только в североамериканском регионе (us-west4), но в дальнейшем возможность их использования появится в регионах EMEA (Нидерланды) и APAC (Сингапур). Также Google предлагает опробовать технологию Multislice, позволяющей объединять в единый комплекс десятки тысяч TPU v5e или TPU v4, где каждый «слайс» может содержать до 3072 чипов TPU (v4). В максимальной конфигурации можно развернуть 64 инстанса, работающих с 256 кластерами TPU v5e. Сама компания уже использует новые чипы для своего поисковика и Google Photos.
24.08.2023 [13:29], Сергей Карасёв
IBM представила ленточный привод TS1170 для JF-картриджей с эффективной ёмкостью 150 ТбайтКорпорация IBM анонсировала ленточный привод TS1170, предназначенный для применения в системах архивирования данных большой ёмкости. Решение обеспечивает высокий уровень безопасности благодаря возможности использования «воздушного зазора» (air gap) и шифрования AES-256. Задействованы картриджи JF вместимостью 50 Тбайт. С учётом компрессии 3:1 такие носители способны хранить до 150 Тбайт информации. Для сравнения: ленточные картриджи LTO-9 имеют «чистую» ёмкость в 18 Тбайт и эффективную ёмкость в 45 Тбайт со сжатием данных. 
Источник изображения: IBM Поверхность ленты в картриджах JF покрыта частицами феррита стронция, что позволило повысить плотность хранения информации. Ранее IBM и Fujifilm демонстрировали ленточный накопитель вместимостью 580 Тбайт, выполненный по указанной технологии. Таким образом, в перспективе на коммерческом рынке появятся гораздо более ёмкие картриджи. Привод TS1170 поддерживает интерфейсы SAS-3 и FC16. Заявленная скорость передачи данных достигает 400 Мбайт/с. Габариты составляют 93 × 186 × 467 мм, вес — 5,57 кг. Диапазон рабочих температур — от +16 до +25 °C. Около года назад участники консорциума LTO — компании HPE, IBM и Quantum — обнародовали план развития стандарта ленточных накопителей LTO Ultrium. С появлением LTO-10 ёмкость картриджа вырастет до 36 Тбайт, а объём хранимых в сжатом виде данных — до 90 Тбайт. Картриджи 14-го поколения обеспечат объём до 576 Тбайт и 1,44 Пбайт соответственно.
23.08.2023 [14:47], Руслан Авдеев
Гигабит по воздуху: австралийский интернет-провайдер Move Up Internet развернёт Terragraph-сеть в КвинслендеКак сообщает портал SCN, провайдер Move Up Internet (MUI) объявил о намерении предоставлять гигабитный интернет-доступ в австралийском регионе Саншайн-Кост (Квинсленд) — для этого будут применяться сети на базе технологии Meta✴ Terragraph. Доступ будет предоставляться как корпоративным клиентам, так и физическим лицам. Сама MUI является подразделением Graph Networks, специализирующейся на беспроводных решениях. Terragraph подходит для труднодоступных мест, куда прокладка кабелей обойдётся слишком дорого или будет вовсе невозможной. Применяется 60-ГГц (mmWave) радиочастотный спектр и стандарт WiGig. Для эффективной связи терминалы должны располагаться друг от друга на расстоянии 200–250 м. Весной этого года Meta✴ передала наработки проекту LF Connectivity (Linux Foundation). 
Фото: MOVE UP Internet MUI намерена применить технологию для покрытия связью юго-востока Квинсленда. Graph Networks разработала SDN-архитектуру, обеспечивающую быстрое внедрение в офисных и многоквартирных зданиях и отдельных домах. Аналогичный сервис уже работает в Брисбене. MUI также недавно подключила свою Terragraph-сеть к посадочной станции подводного интернет-кабеля JGA-S.
19.08.2023 [16:19], Сергей Карасёв
Новый инструмент Microsoft позволит управлять нагрузками в ЦОД для минимизации углеродного следаКорпорация Microsoft, по сообщениям ресурсов Datacenter Dynamics и Motley Fool, создаёт специализированный инструментарий, который позволит автоматически планировать выполнение рабочих нагрузок в ЦОД в зависимости от их срочности и воздействия на окружающую среду. Идея заключается в том, чтобы выполнять определённые задачи в определённое время, что позволит минимизировать выбросы вредных газов в атмосферу. Например, те ресурсоёмкие задачи, выполнение которых не является срочным, могут быть отложены до момента, когда станет доступно необходимое количество энергии из возобновляемых источников. 
Источник изображения: Microsoft Microsoft патентует систему управления поведением оборудованием, «ориентированную на устойчивое развитие». Данный комплекс учитывает состояние энергосистемы в целом, а также другие факторы. На начальном этапе собирается информация о текущей нагрузке на сеть, о погодных условиях и температурах и т.д. После этого специальные алгоритмы делают прогноз использования ресурсов и распределяют выполнение задач так, чтобы они оказало «сравнительно меньшее воздействие на окружающую среду». По заявлениям Microsoft, подобный подход позволит снизить нагрузку на энергосеть в часы-пик, а также увеличить срок службы оборудования. Кроме того, станет возможным более эффективное использование «зелёной» энергии. В частности, Microsoft может использовать систему для приостановки и возобновления некоторых операций в ЦОД для балансировки энергопотребления. Нужно отметить, что Google ещё два года назад начала динамически и прозрачно для конечных потребителей перемещать нагрузки между различными дата-центрами, опираясь на уровень доступности для них «зелёной» энергии. При этом речь идёт только о задачах, для которых не критичны задержки или требования о суверенитете данных. Для этого Google составляет прогнозы доступности энергии на день вперёд.
17.08.2023 [20:16], Алексей Степин
Brocade представила новые FC64-продукты — 512-портовый директор X7 и Ethernet-мост 7850 Extension SwitchПодразделение Brocade Storage Networking компании Broadcom представило новые коммутаторы класса Director, предлагающие до 512 портов FC64. Предельная пропускная способность заявлена на уровне 39,6 Тбайт/с. При этом сохранена совместимость с предыдущими поколениями Fibre Channel. Кроме того, был представлен и новый мост Ethernet ↔ Fibre Channel, который позволяет создавать распределённые SAN. Новые устройства серии Brocade X7 Directors являются наиболее высокоплотными в индустрии — они представлены в вариантах с 256 и 512 портами Fibre Channel седьмого поколения (64 Гбит/с на порт) в исполнениях 8U и 14U соответственно. Первое поколение X7 увидело свет ещё в 2020 году, но тогда оно было ограничено использованием 48-портовых лезвий FC64, что давало максимум 384 порта. Новый вариант использует новые 64-портовые модули с трансиверами SFP-DD, позволившими на треть поднять плотность портов. Устройства работают под управлением Fabric OS 9.0.x. 
Источник изображений здесь и далее: Broadcom Другой интересной новинкой Brocade является коммутатор Brocade 7850 Extension Switch, делающий более простым построение географически распределённой SAN. По сути, это мост с 24 портами FC64/FICON, обеспечивающий проброс FC-трафика, для чего имеется 16 портов 25/10GbE, а также два WAN-порта 100GbE. WAN-трафик шифруется на лету на полной скорости по алгоритму AES с 256-битным ключом. Имеются механизмы защиты от кибер-атак, а также автоматическая проверка целостности ПО и аппаратного обеспечения. 
17.08.2023 [18:10], Руслан Авдеев
Ленточные накопители дешевле и намного экологичнее жёстких дисков для хранения «холодных» данныхНа накопители приходится значительная доля углеродных выбросов и энергозатрат IT-индустрии. Как сообщает портал IEEE Spectrum, эксперты уверены — в обозримом будущем обеспечить экологическую безопасность и экономическую эффективность хранения можно с помощью технологии хранения информации на магнитных лентах. По данным экспертов, в 2019 году 60 % всех данных были «холодными», т.е. редко востребованными, но всё ещё очень важными. Полный переход на ленточные накопители (LTO) для таких данных позволит снизить не только выбросы CO2, но и улучшить экономические показатели. По некоторым оценкам, при переходе на LTO мировые выбросы углекислого газа, связанные с накопителями, снизятся на 58 % или на 79 млн т. 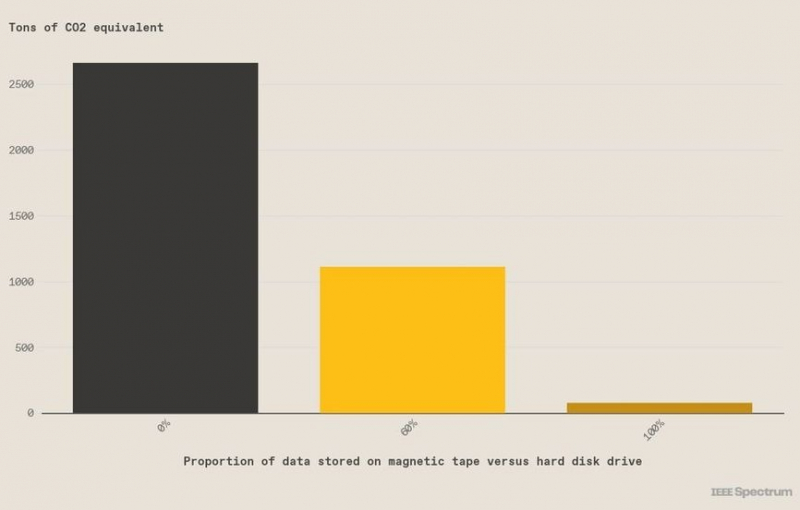
Источник изображения: Brad Johns Consulting Потребность в накопителях только растёт, и уже в 2025 году, по данным IDC, придётся хранить 17 Збайт данных. Как выяснили IDC совместно с Seagate, в 2021 году 62 % данных хранились на HDD, 9 % на SSD и 15 % — на LTO. Хотя HDD объективно удобнее и значительно быстрее LTO, средний срок эксплуатации жёстких дисков составляет всего 5 лет, в течение которых генерируется эквивалент 2,55 кг CO2 на 1 Тбайт ежегодно. Для ленточных хранилищ этот показатель составляет всего 0,07 кг/год. При переходе на LTO снизятся и объёмы электронных отходов. Если HDD в среднем работают 5 лет, то ленточные накопители — 10; поэтому их придётся менять вдвое реже. Например, если ЦОД хранит 100 Пбайт данных в течение 10 лет, то использование HDD приведёт к появлению 7,4 т электронных отходов. Если 60 % информации перенести на ленты, отходов станет меньше на 51 % — 3,6 т. Таким образом, по ряду параметров ленточные накопители будут предпочтительнее HDD ещё минимум десятилетие. 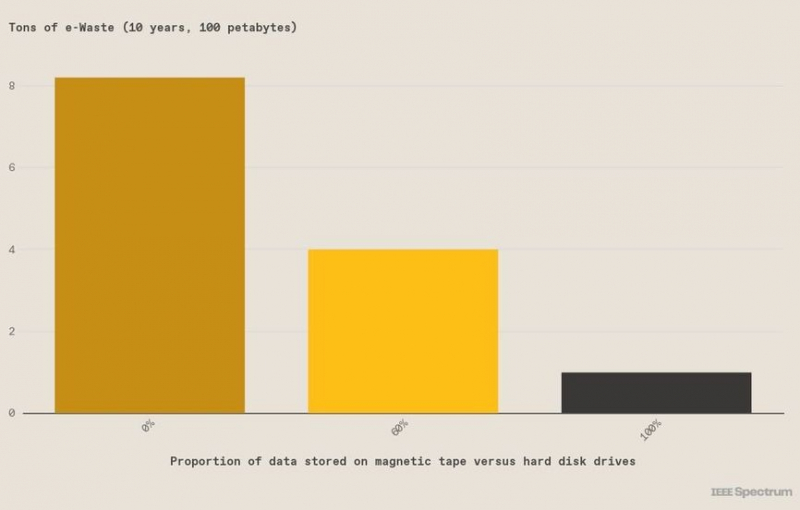
Источник изображения: Brad Johns Consulting Финансовая выгода такого подхода тоже очевидна. По оценкам Fujifilm, хранение 100 Пбайт обойдётся в $17 707 468, тогда как при переносе 60 % данных на ленты стоимость хранения снизится до $9 476 339. И если крупные операторы активно закупают LTO, то для многих других верная оценка того, какие именно данные являются «холодными», является непростой и дорогой задачей — это одна из причин медленного отказа от HDD в пользу ленточных решений в малых ЦОД. Тем не менее, будущее ленточных накопителей остаётся под вопросом. Хотя у них пока имеется конкурентное преимущество перед жёсткими дисками, уже ведутся разработки накопителей нового типа. Впрочем, технологии LTO тоже не стоят на месте. Так, в начале года Western Digital предложила новый тип накопителей — высокоинтегрированный LTO-картридж в корпусе HDD.
14.08.2023 [17:37], Алексей Степин
CXL-пул Panmnesia втрое быстрее RDMA-систем и может предложить 6 Тбайт RAMНа конференции Flash Memory Summit южнокорейская компания Panmnesia продемонстрировала свою версию CXL-пула DRAM объёмом 6 Тбайт на базе программно-аппаратного стека собственной разработки. Новинка продемонстрировала более чем троекратное превосходство над системой, построенной на базе технологии RDMA, в нагрузках, связанной с работой рекомендательной ИИ-системы Meta✴. Panmnesia разработана в сотрудничестве с Корейским инститом передовых технологий (KAIST). О более раннем варианте разработок KAIST в этой области мы рассказывали в 2022 году. Коммерческий вариант комплекса поддерживает CXL 3.0 и состоит из CXL-процессора, коммутатора и модулей расширения памяти. Все модули выполнены в форм-факторе, чрезвычайно напоминающем FHFL-карты. Модули устанавливаются в универсальное шасси, при этом их можно произвольно комбинировать. 
Источник изображений здесь и далее: Panmnesia Демо-платформа содержала два процессорных модуля, три модуля коммутации и шесть 1-Тбайт модулей памяти. Модули памяти построены на базе обыкновенных DIMM-планок и поддерживают их замену и расширение. Реализован не только режима CXL.mem, но и CXL.cache и CXL.io. При этом компания предлагает не только готовые IP-решения, но и их кастомизацию под конкретного заказчика, что поможет оптимизировать цикл создания продукта и снизить общую стоимость разработки и валидации. 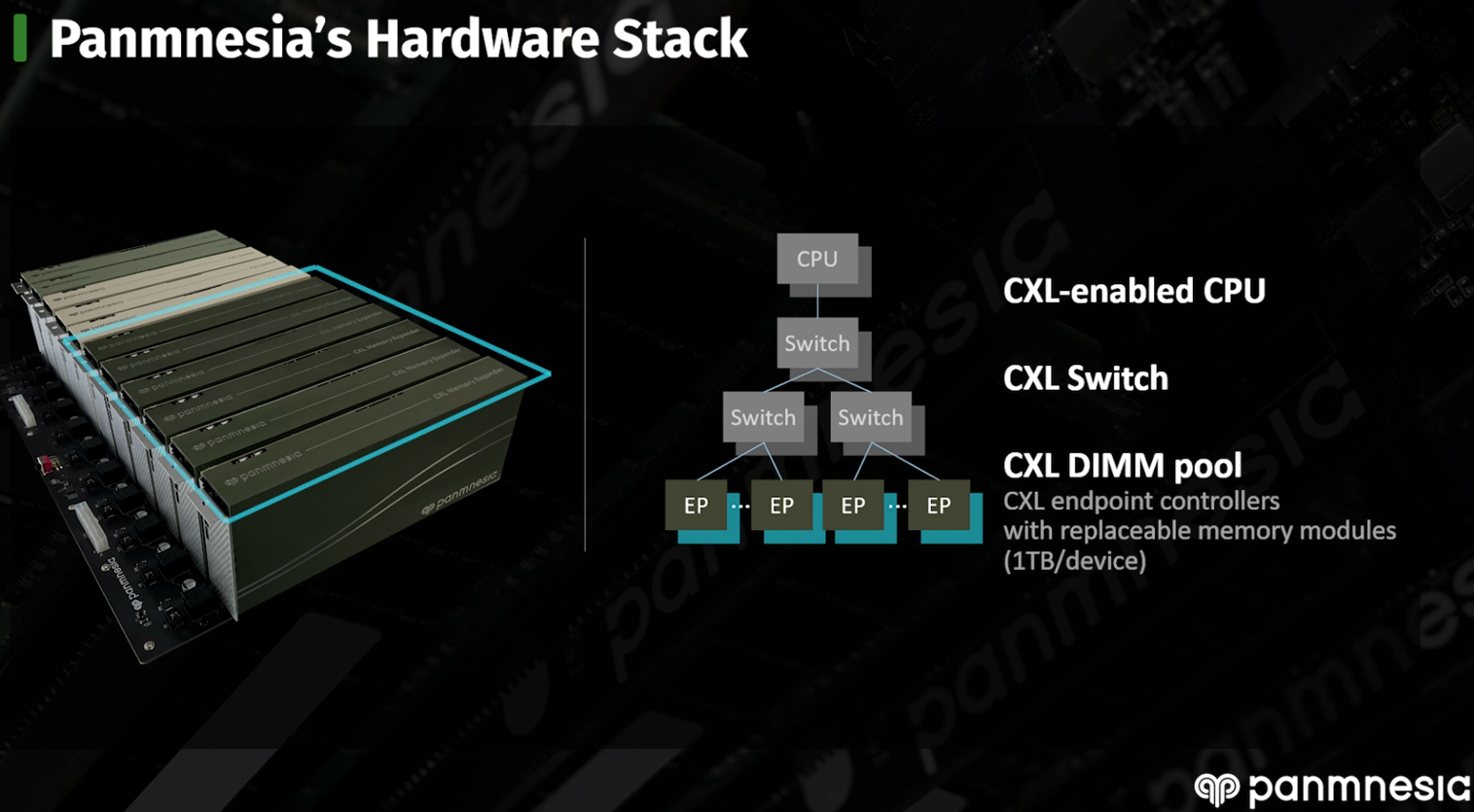 Фирменное ПО базируется на Linux и содержит необходимые драйверы, а также специализированную виртуальную машину, с помощью которой пространство памяти представляется в виде безпроцессорного NUMA-узла. Поверх этих компонентов функционирует пользовательская часть, отвечающая за эффективное размещение и предвыборку (prefetching) данных. По ряду параметров Panmnesia можно назвать лидером в области CXL-решений. В частности, по объёму DRAM она уже обгоняет совместное решение Samsung, MemVerge, H3 и XConn, а использование DIMM-модулей только придаёт ей гибкости. Развитая программная часть, как утверждается, упрощает и удешевляет интеграцию в существующую инфраструктуру ЦОД. Спектр применения, как и у всех систем CXL-пулинга, крайне широкий и включает в себя не только ИИ-сценарии, но и любые задачи, требующие большого объёма оперативной памяти.
10.08.2023 [00:10], Алексей Степин
XConn Technologies представила гибридный коммутатор CXL 2.0/PCIe 5.0XConn Technologies представила первый, по её словам, в индустрии гибридный чип-коммутатор CXL 2.0/PCIe 5.0 XC50256, получивший кодовое название Apollo. Утверждается, что он обеспечивает самую низкую латентность port-to-port, а также самое низкое энергопотребление в отрасли. Коммутатор способен работать с 256 линиями интерфейса и разработан с учётом потребностей, характерных для мира ИИ и машинного обучения, а также HPC-сегмента. Чип Apollo совместим с существующей инфраструктурой CXL 1.1, но поддерживает и режим 2.0, включая актуальные режимы CXL.mem или CXL.cache. 
Источник изображений здесь и далее: XConn Technologies Но наиболее интересной особенностью Apollo является возможность работы нового коммутатора в гибридном режиме — он способен одновременно обслуживать CXL и PCI Express, что в ряде случаев позволит избежать использования дополнительных коммутаторов под каждый стандарт, а значит, и снизить стоимость и сложность разработки конечной системы. 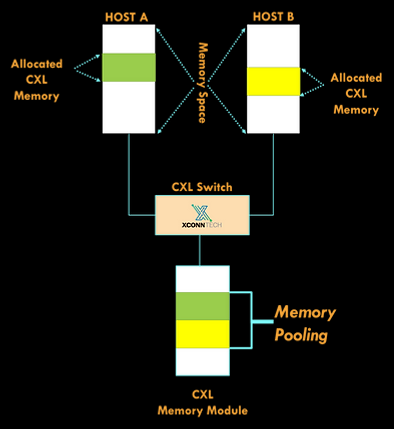
Новый коммутатор поддерживает подключение нескольких хостов к единому CXL-пулу памяти Также компания анонсировала другой коммутатор, XC51256. Он также работает с 256 линиями, но поддерживает только PCI Express 5.0. Тем не менее, это самый высокоплотный PCIe-коммутатор на сегодня, поскольку большинство решений конкурентов обеспечивает в лучшем случае вдвое меньше линий PCI Express, утверждает XConn. ТXC51256 идеален для построения систем класса JBOA (Just-a-Bunch-Of-Accelerators). В настоящее время образцы Apollo XC50256 и XC51256 уже доступны для заказчиков.
09.08.2023 [18:00], Алексей Степин
NVIDIA анонсировала L40S — новый универсальный ускоритель на базе Ada LovelaceКорпорация NVIDIA обновила серию укорителей L40, представленных осенью прошлого года в рамках платформы OVX. Новинка под названием NVIDIA L40S позиционируется как универсальный ускоритель в форм-факторе двухслотовой FHFL-карты расширения с интерфейсом PCIe 4.0 x16, пригодный для решения практически любых задач. Во многом L40S повторяет L40 — она также базируется на архитектуре Ada Lovelace, оснащена графическим процессором AD102, дополненным 48 Гбайт памяти GDDR6 ECC (384 бит, 864 Гбайт/с). В составе ускорителя работают 18176 ядер CUDA, 142 RT-ядра третьего поколения и 568 тензорных ядер четвёртого поколения. То есть в этом отличий от L40 нет. Но значение TDP у новинки выше на 50 Вт и составляет 350 Вт, она все ещё имеет пассивное охлаждение. 
Источник изображений здесь и далее: NVIDIA При этом L40S умудряется быть практически вдвое быстрее L40 во всех форматах вычислений с использованием тензорных ядер, а вот без Tensor Core её FP32-производительность выросла минимально — с 90,5 до 91,6 Тфлопс. Поддержкой NVLink-мостика новинка так и не обзавелась. L40S оснащён четырьмя портами DP 1.4a с поддержкой NVIDIA Mosaic и Quadro Sync. Также доступны профили vGPU для vDWS, GRID vApps/vPC, vCS. Имеется поддержка Secure Boot с Root of Trust и соответствие стандарту NEBS Level 3.  Таким образом, новинка подходит не только в качестве ускорителя для обучения ИИ-моделей или инференс-систем, но и в качестве основы для систем рендеринга 3D-графики, визуализации или создания и запуска приложений для мета✴-вселенных. NVIDIA отмечает, что в ИИ-задачах L40S опережает A100 в 1,2–1,7 раза, а наличие трёх движков NVENC/NVDEC с поддержкой AV1 позволяет использовать новый ускоритель в качестве эффективной платформы транскодирования видео.
04.08.2023 [16:23], Руслан Авдеев
CoreWeave взяла в долг $2,3 млрд под залог ускорителей NVIDIA, чтобы купить ещё больше ускорителей NVIDIAПровайдер облачной ИИ-инфраструктуры CoreWeave объявил о привлечении $2,3 млрд долгового финансирования под залог ускорителей NVIDIA. По данным Silicon Angle, компания намерена полностью потратить вырученные средства на закупку аппаратного обеспечения от всё той же NVIDIA. Это уже не первый раунд финансирования, суммарно компания привлекла $571 млн, причём от NVIDIA она получила около $100 млн и приоритет в отгрузке новейших ускорителей. Текущая ситуация уникальна тем, что CoreWeave взяла деньги в долг, оставив в качестве залога используемые ею ускорители NVIDIA. Со взрывным ростом интереса к генеративным ИИ-системам, гонка по созданию всё более масштабных и совершенных ИИ-моделей и инфраструктуры для их обучения потребовала огромного количества дополнительных вычислительных мощностей. Обладая большим числом ускорителей NVIDIA ещё со времён своего «увлечения» криптовалютами, CoreWeave способна превзойти конкурирующих облачных провайдеров. 
Источник изображения: CoreWeave Компания обеспечивает облачный доступ к самым передовым технологиям NVIDIA, включая ускорители H100. Также доступны A100, A40 и RTX A6000. Эти решения можно использовать для систем ИИ и машинного обучения, работы с графикой и других ресурсоёмких задач. В компании утверждают, что уже обладают одним из крупнейших HGX-кластеров в мире и поддерживает более 3500 ускорителей NVIDIA H100 в своей суперкомпьютерной инфраструктуре. В прошлом месяце компания объявила о строительстве крупного ЦОД в Техасе за $1,6 млрд. Ожидается, что он будет полностью готов к работе в конце текущего года и будет использован для создания ИИ-супероблака. |
|

