Amazon Web Services (AWS) и Cerebras Systems объявили о сотрудничестве, «которое позволит создать в ближайшие месяцы самые быстрые решения для инференса в системах генеративного ИИ и рабочих нагрузок машинного обучения». Решение, которое будет развёрнуто на платформе Amazon Bedrock в ЦОД AWS, объединяет серверы на базе ускорителей Trainium, системы Cerebras CS-3 на базе царь-чипов WSE-3 и DPU EFA. Ожидается, что эта технология увеличит скорость генерации результатов ИИ-моделями в пять раз. Позже в этом году AWS предложит ведущие open source решения машинного обучения и собственные ИИ-модели Amazon Nova, использующие оборудование Cerebras.
Как отметил Дэвид Браун (David Brown), вице-президент по вычислительным и машинным сервисам AWS, при инференсе критическим узким местом для ресурсоёмких рабочих нагрузок, таких как помощь в кодировании в реальном времени и интерактивные приложения, остаётся скорость: «Решение, которое мы разрабатываем совместно с Cerebras, решает эту проблему: разделяя нагрузку по инференсу между Trainium и CS-3 и соединяя их с помощью EFA, каждая система делает то, что у неё лучше всего получается. В результате инференс будет на порядок быстрее и производительнее, чем сегодня».

Источник изображения: Amazon
Совместное решение использует «дезагрегацию вывода» — метод, который разделяет ИИ-инференс на два этапа: этап интенсивной обработки подсказок, или «предварительного заполнения» (процесс обработки запроса LLM), и этап генерации выходных данных, известный как «декодирование», на котором модель формирует ответ на вопрос пользователя.

Источник изображений: Cerebras
Предварительное заполнение является параллельным, вычислительно интенсивным процессом и не требует большой пропускной способности памяти. Декодирование, с другой стороны, является последовательным процессом с минимальными требованиями к вычислительным ресурсам, но интенсивно использует пропускную способность памяти. Декодирование обычно занимает большую часть времени при инференсе, поскольку каждый выходной токен должен генерироваться последовательно, отметила AWS.
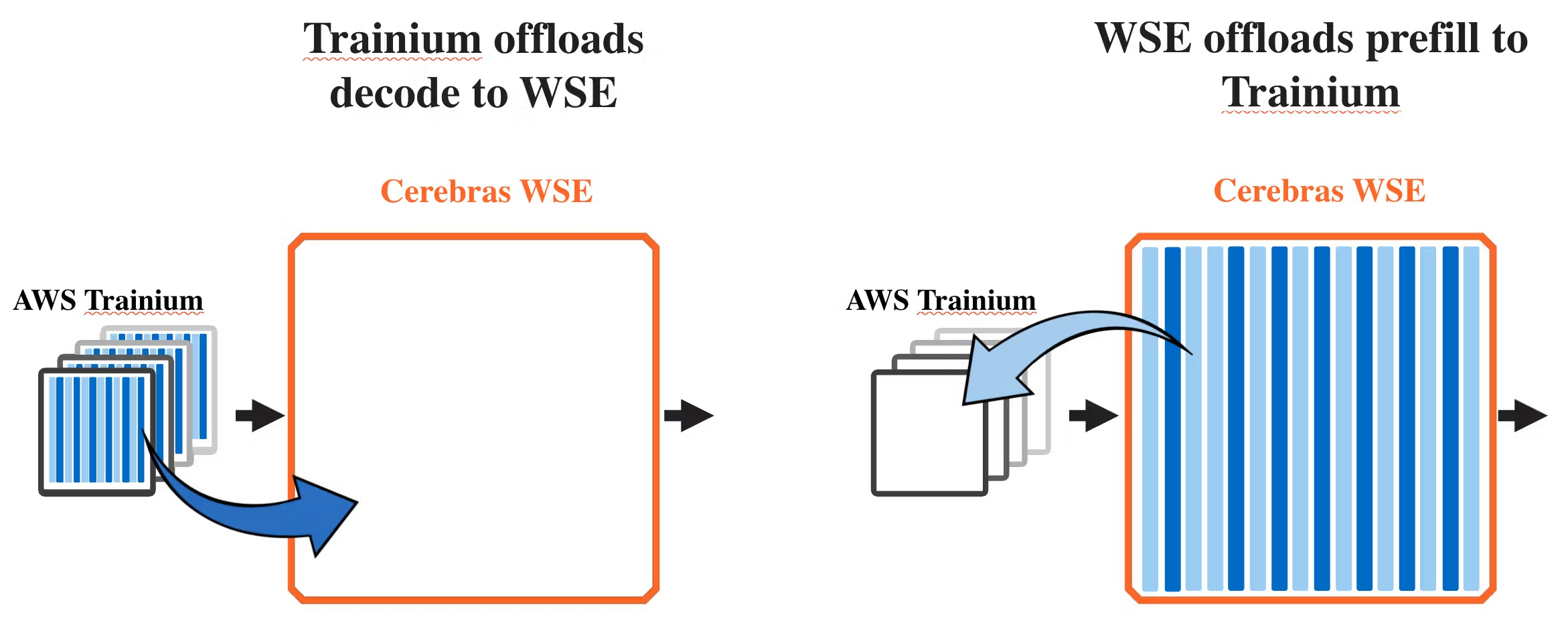
Задачи предварительного заполнения и декодирования обычно выполняются одним и тем же чипом. В дезагрегированной архитектуре AWS чипы Trainium обеспечивают этап предварительного заполнения, а чипы WSE-3 выполняют декодирование. «Дезагрегированный подход идеален, когда у вас большие, стабильные рабочие нагрузки, — сообщил в блоге директор по маркетингу продукции Cerebras Джеймс Ванг (James Wang). — Большинство клиентов используют смешанные рабочие нагрузки с различными коэффициентами предварительного заполнения/декодирования, где традиционный агрегированный подход по-прежнему идеален. Мы ожидаем, что большинство клиентов захотят иметь доступ к обоим вариантам».

Одним из главных преимуществ WSE-3 является то, что он может передавать данные между своими логическими схемами и цепями памяти быстрее, чем многие другие чипы. По данным Cerebras, WSE-3 обеспечивает внутреннюю пропускную способность памяти в 21 Пбайт/с, что значительно превышает пропускную способность NVLink для ускорителей от NVIDIA. Впрочем, у NVIDIA теперь есть ускорители Groq, которые тоже помогают ускорить инференс.
Несколько недель назад Cerebras заключила с OpenAI сделку на $10 млрд по поставке чипов общей мощностью 750 МВт до 2028 года. Сделка была объявлена в период между двумя раундами финансирования, которые в совокупности принесли Cerebras более $2 млрд. Ожидается, что компания подаст заявку на IPO уже во II квартале 2026 года. Сделки с AWS и OpenAI могут способствовать повышению интереса инвесторов к листингу, отметил SiliconANGLE.
Источник:

