Материалы по тегу: intel max
|
21.07.2025 [09:27], Сергей Карасёв
10 долгих лет: состоялся официальный запуск экзафлопсного суперкомпьютера AuroraВ Аргоннской национальной лаборатории (ANL) Министерства энергетики США (DOE) в Иллинойсе состоялась церемония торжественного разрезания ленты в честь официального запуска суперкомпьютера Aurora экзафлопсного класса. В мероприятии приняли участие руководители и исследователи Intel, HPE и DOE. Церемония была скорее формальностью, поскольку Aurora стала доступна исследователям со всего мира в начале текущего года. Aurora является одним из трёх суперкомпьютеров DOE с производительностью более 1 Эфлопс. Наряду с El Capitan в Ливерморской национальной лаборатории имени Лоуренса (LLNL) и Frontier в Национальной лаборатории Оук-Ридж (ORNL) эти НРС-комплексы занимают первые три места как в списке TOP500 самых быстрых суперкомпьютеров мира, так и в бенчмарке HPL-MxP для оценки производительности ИИ. У суперкомпьютера непростая судьба. Анонс машины состоялся в 2015 году — система с FP64-производительностью на уровне 180 Пфлопс по плану должна была заработать в 2018 году. Однако планы неоднократно корректировались, а проект в конце концов был кардинально пересмотрен. Первые тестовые кластеры системы заработали более двух лет назад, а частично запущенная система попала в TOP500 в конце 2023 года. Целиком она заработала в 2024 году. 
Источник изображения: ANL / Intel В проекте по созданию Aurora принимали участие Intel и HPE. Машина построена на платформе HPE Cray EX — Intel Exascale Compute Blade: задействованы процессоры Intel Xeon CPU Max и ускорители Intel Data Center GPU Max, объединённые интерконнектом HPE Slingshot. В общей сложности применяются 63 744 ускорителей, что делает Aurora одним из крупнейших в мире суперкомпьютеров на базе GPU. 
Источник изображения: ANL / Intel Установлена ОС SUSE Linux Enterprise Server 15 SP4. Производительность в тесте Linpack составляет 1,012 Эфлопс, а теоретический пиковый показатель достигает 1,980 Эфлопс. НРС-комплекс занимает площадь около 930 м2. Развёрнута современная инфраструктура жидкостного охлаждения. Общая протяжённость соединений превышает 480 км, а количество конечных точек сети достигает 85 тыс.  Aurora останется по-своему уникальным суперкомпьютером: CPU с HBM на борту больше не планируются, от Ponte Vecchio компания отказалась в пользу Habana Gaudi и Falcon Shores. Но и последние на рынок не попадут, а будут использоваться для внутренних тестов и обкатки технологий. На смену им должны прийти Jaguar Shores, но точных дат Intel не называет.  Вычислительные мощности Aurora, как отмечается, помогают в решении сложнейших задач в самых разных областях. В биологии и медицине исследователи используют ИИ-возможности суперкомпьютера для прогнозирования эволюции вирусов, улучшения методов лечения рака и картирования нейронных связей в мозге. В аэрокосмической сфере Aurora используется для создания двигательных установок нового поколения и моделирования аэродинамических процессов. Комплекс играет важную роль в развитии технологий термоядерной энергетики, квантовых вычислений и пр.
30.01.2025 [08:58], Владимир Мироненко
Суперкомпьютер Aurora стал доступен исследователям со всего мираАргоннская национальная лаборатория (ANL) Министерства энергетики США объявила о доступности суперкомпьютера Aurora экзафлопсного класса для исследователей по всему миру. Как указано в пресс-релизе, благодаря широким возможностям моделирования, ИИ и анализа данных, Aurora будет способствовать прорывам в целом ряде областей, включая проектирование самолётов, космологию, разработку лекарств и исследования в сфере ядерной энергетики. Майкл Папка (Michael Papka), директор Argonne Leadership Computing Facility (ALCF), вычислительного центра Управления науки Министерства энергетики США, отметил, что уже первые проекты с использованием Aurora продемонстрировали его огромным потенциал. «С нетерпением ждём, как более широкое научное сообщество будет использовать систему для преобразования своих исследований», — заявил он. Aurora уже зарекомендовала себя как один мировых лидеров по производительности ИИ, заняв первое место в бенчмарке HPL-MxP в ноябре 2024 года, отметила ANL. Возможности машины для выполнения ИИ-задач используются учёными для открытия новых материалов для аккумуляторов, разработки новых лекарств и ускорения исследований в области термоядерной энергии. Перед его развёртыванием команда под руководством ANL продемонстрировала потенциал Aurora, используя его для обучения моделей ИИ для моделирования белков. 
Источник изображения: ANL В числе первых проектов, реализуемых с помощь Aurora, — разработка высокоточных моделей сложных систем, таких как кровеносная система человека, ядерные реакторы и сверхновые звезды. Кроме того, способность суперкомпьютера к обработке огромных наборов данных имеет решающее значение для анализа растущих потоков данных из крупных исследовательских установок, таких как Усовершенствованный источник фотонов (APS) Аргоннской национальной лаборатории, научные объекты Управления науки Министерства энергетики США (DoE) и Большой адронный коллайдер Европейской организации ядерных исследований (CERN). Чтобы гарантировать готовность Aurora к использованию для научных исследования с первого дня запуска, при его создании применили так называемое совместное проектирование. Используя этот подход, команда Aurora разработала в тандеме аппаратное и программное обеспечение для оптимизации производительности и удобства использования. Это потребовало многолетнего сотрудничества между ALCF, Intel, HPE и исследователями по всей стране, участвующими в проекте Exascale Computing Project (ECP) Министерства энергетики США и программе Aurora Early Science Program (ESP) центра. Пока велись работы по монтажу Aurora, команды ECP и ESP запускали приложения для стресс-тестирования оборудования, одновременно оптимизируя свой код для максимально эффективной работы в системе. В результате десятки научных приложений, а также широкий спектр ПО и инструментов разработки были готовы ещё до того, как Aurora ввели в строй, говорится в пресс-релизе.
03.12.2024 [10:00], Сергей Карасёв
Астрофизики Японии получили суперкомпьютер Aterui III на базе Intel Xeon MaxЦентр вычислительной астрофизики Национальной астрономической обсерватории Японии (NAOJ) объявил о вводе в эксплуатацию суперкомпьютера NS-06 Aterui III на платформе HPE Cray XD2000. Новый НРС-комплекс планируется применять в качестве «лаборатории теоретической астрономии» для исследования широкого спектра астрофизических явлений. Архитектура Aterui III предполагает применение модулей двух типов — System M с высокой пропускной способностью памяти (3,2 Тбайт/с на узел, что в 12,5 раза больше, чем у Aterui II) и System P с большим объёмом памяти (512 Гбайт в расчёте на узел, в 1,3 раза больше по сравнению с Aterui II). Все узлы оснащены двумя процессорами Intel Xeon Sapphire Rapids. В частности, задействованы 208 узлов System M с чипами Xeon CPU Max 9480 (56C/112T; 1,9–3,5 ГГц; 350 Вт). Таким образом, суммарное количество ядер достигает 23 296. Каждый узел несёт на борту 128 Гбайт памяти, а её совокупный объём составляет 26,6 Тбайт. Общая пропускная способность — 665 Тбайт/с. 
Источник изображения: NAOJ Кроме того, в состав Aterui III включены 80 узлов System P с парой процессоров Xeon Platinum 8480+ (56C/112T; 2,0–3,8 ГГц; 350 Вт). В общей сложности применяются 8960 ядер и 40,96 Тбайт памяти с суммарной пропускной способностью 98,24 Тбайт/с (614 Гбайт/с на узел). В целом, суперкомпьютер использует 288 узлов с 32 256 ядрами CPU. Кластер на базе System M обеспечивает производительность на уровне 1,4 Пфлопс, сегмент на основе System P — около 0,57 Пфлопс. Общее быстродействие НРС-комплекса достигает почти 2 Пфлопс.
22.10.2024 [12:49], Владимир Мироненко
В Пизанском университете установили суперкомпьютер Lenovo на базе Intel Xeon MaxКомпания Lenovo сообщила об установке в дата-центре Пизанского университета (UniPi) нового кластера, благодаря чему HPC-платформа UniPi стала крупнейшей среди университетских суперкомпьютеров в Италии. Система размещена в ЦОД Green Data Center, который включает 104 стойки, где уже размещено 700 узлов (30 тыс. ядер, более ускорителей разных поколений). 
Источник изображения: Lenovo Новая HPC-система Lenovo состоит из 16 узлов SD650 V3 с двумя процессорами Intel Xeon Max 9480 (Sapphire Rapids с HBM). Используемая СЖО Lenovo Neptune Direct Water-Cooling позволяет отводить до 98 % тепла, вырабатываемого суперкомпьютером, а также снизить энергопотребление на 40 %. Как утверждает компания, благодаря повышенной эффективности СЖО температура процессоров не достигает критических значений, что позволяет избежать снижения максимальной частоты ядер. Аналогичная платформа используется в суперкомпьютере Cassandra для Европейско-Средиземноморского центра по изменению климата (CMCC) в Лечче (Италия). Как отметил UniPi, решающим фактором при выборе решения Lenovo была адаптивность системы, поскольку проект был изначально разработан с учётом минимального воздействия на окружающую среду с целью создания экологичного ЦОД. Кроме того, стандартизированный подход Lenovo к созданию HPC-узлов упростила и ускорила её установку в ЦОД UniPi. Как ожидается, новый суперкомпьютер будет способен поддерживать рабочие нагрузки HPC и ИИ последнего поколения в течение следующих нескольких лет. UniPi имеет три ЦОД в Пизе. В 2016 году университет запустил проект строительства нового «Зелёного дата-центра» (Green Data Centre) для размещения HPC-нагрузок. По словам UniPi, новый университетский ЦОД является единственным объектом в стране, получившим классификацию «A» от AgID в начале этого года.
23.12.2023 [02:11], Владимир Мироненко
В Испании официально запустили 314-Пфлопс суперкомпьютер MareNostrum 5, который вскоре объединится с двумя квантовыми компьютерами21 декабря в Суперкомпьютерном центре Барселоны — Centro Nacional de Supercomputación (BSC-CNS) — в торжественной обстановке официально запустили европейский суперкомпьютер MareNostrum 5 производительностью 314 Пфлопс. В церемонии, посвящённой машине, созданной в рамках проекта European High Performance Computing Joint Undertaking (EuroHPC JU), принял участие председатель правительства Испании. MareNostrum 5 представляет собой крупнейшую инвестицию, когда-либо сделанную Европой в научную инфраструктуру Испании — суммарно €202 млн, из которых €151,4 млн ушло на приобретение суперкомпьютера. Финансирование было проведено EuroHPC JU через Фонд ЕС «Соединение Европы» и программу исследований и инноваций «Горизонт 2020», а также государствами-участниками: Испанией (через Министерство науки, инноваций и университетов и правительство Каталонии), Турцией и Португалией. С запуском MareNostrum 5 заметно укрепились позиции BSC в качестве одного из ведущих суперкомпьютерных центров мира с более чем 900 сотрудниками, занимающимися исследования в области информатики, наук о жизни и о Земле, а также вычислительных систем для науки и техники. Обладая максимальной общей производительностью 314 Пфлопс, MareNostrum 5 присоединяется к двум другим системам EuroHPC: Lumi (Финляндия) и Leonardo (Италия), тоже являющихся суперкомпьютерами предэкзафлопсного класса, единственными системами такого уровня в Европе. 
Источник изображений: BSC Eviden (Atos) была выбрана в качестве основного поставщика, но в создании машины приняли участие Lenovo, IBM, Intel и NVIDIA, а также Partec. Как отмечено в пресс-релизе, уникальная архитектура MareNostrum 5 была создана для того, чтобы предоставить исследователям лучшие из доступных технологий. Это гетерогенная машина, сочетающая в себе две отдельные системы: раздел общего назначения (GPP), предназначенный для классических вычислений, и GPU-раздел (ACC), ориентированный на ИИ. Обе системы по отдельности входят в первую двадцатку TOP500, занимая 19-е и 8-е места соответственно. Раздел общего назначения (GPP) является крупнейшим в мире x86-кластером на базе Intel Xeon Sapphire Rapids. Эта часть суперкомпьютера имеет пиковую производительность 45,9 Пфлопс. Система, произведённая Lenovo, специально разработана для решения сложных научных задач с разделением ресурсов, что обеспечивает большую гибкость и повышает эффективность системы, поскольку разные пользователи или проекты могут использовать её одновременно. GPP имеет 6408 стандарных узлов следующей конфигурации:
Дополнительно система имеет 72 узла с двумя 56-ядерными Xeon Max (1,7 ГГц) и набортной памятью HBM2e объёмом 128 Гбайт.  GPU-раздел (ACC) производства Eviden является третьим по мощности в Европе и восьмым в мире по версии TOP500, с пиковой производительностью 260 Пфлопс. Он основан на 4480 ускорителях NVIDIA H100. Раздел имеет 1120 узлов, каждый из которых включает:
Общая ёмкость хранилища MareNostrum 5 составляет 650 Пбайт, из которых, 402 Пбайт приходятся на LTO, 248 Пбайт — на HDD, а остальное — на NVMe SSD. Задействована ФС IBM Spectrum Scale. Машина использует интерконнект InfiniBand NDR200, объединяющий более 8000 узлов. Можно заметить, что NVIDIA предоставила BSC не совсем стандартные решения. В будущем ожидается появление ещё одного GPP-раздела на базе NVIDIA Grace, а вот расширение ACC узлами с Xeon Emerald Rapids и Rialto Bridge не состоится. 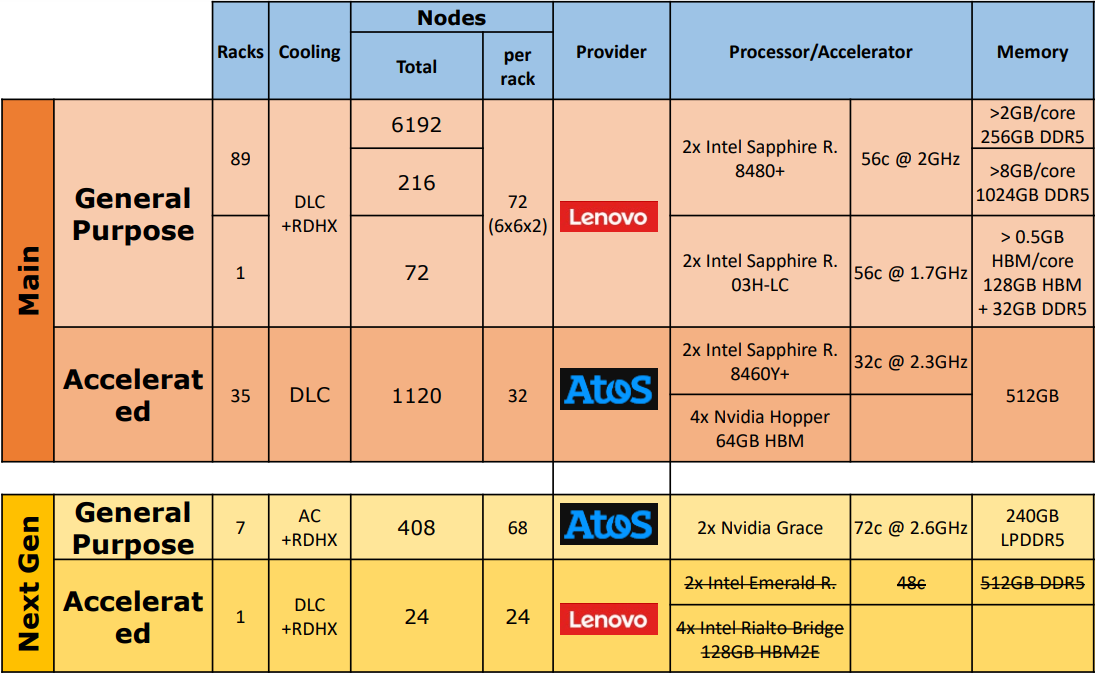 Благодаря увеличенной вычислительной мощности MareNostrum 5 позволяет решать всё более сложные задачи. Например, климатические модели получат более высокое разрешение, что сделает прогнозы гораздо более точными и надёжными. Также появится возможность решать гораздо более сложные проблемы в области ИИ и Big Data. Отдельное внимание уделено поддержке европейских медицинских исследований в области создания новых лекарств, разработки вакцин и моделирования распространения вирусов. Суперкомпьютер также станет важнейшим инструментом для материаловедения и инженерии, включая проектирование и оптимизацию самолётов, развитие более безопасной, экологически чистой и эффективной авиации. Аналогичным образом, машина будет использоваться для моделирования процессов энергогенерации, включая ядерный синтез. В ближайшие месяцы MareNostrum 5 объединится с двумя квантовыми компьютерами: первой системой испанской суперкомпьютерной сети (RES), которая является частью инициативы Quantum Spain, и одним из первых европейских квантовых компьютеров EuroHPC JU. Оба квантовых компьютера будут одними из первых, которых запустили в Южной Европе.
23.05.2023 [15:26], Сергей Карасёв
Intel рассказала о суперкомпьютере Aurora производительностью более 2 ЭфлопсКорпорация Intel в ходе конференции ISC 2023, как сообщает AnandTech, поделилась информацией о проекте Aurora по созданию суперкомпьютера с производительностью экзафлопсного уровня. Эта система создаётся для Аргоннской национальной лаборатории Министерства энергетики США. Изначально анонс HPC-комплекса Aurora состоялся ещё в 2015 году с предполагаемым запуском в 2018-м: ожидалось, что машина обеспечит быстродействие на уровне 180 Пфлопс. Однако реализация проекта значительно затянулась, а технические параметры платформы неоднократно менялись. Пока что развёрнуты тестовый кластер Sunspot. Как теперь сообщается, в конечной конфигурации Aurora объединит 10 624 узла, каждый из которых будет включать два процессора Xeon Max и шесть ускорителей Ponte Vecchio. Таким образом, общее количество CPU будет достигать 21 248, число GPU — 63 744. Быстродействие FP64, как и было заявлено ранее, превысит 2 Эфлопс. 
Источник изображений: Intel (via AnandTech) Каждый процессор оперирует 64 Гбайт памяти HBM, ускоритель — 128 Гбайт. В сумме это даёт соответственно 1,36 Пбайт и 8,16 Пбайт памяти HBM с пиковой пропускной способностью 30,5 Пбайт/с и 208,9 Пбайт/с. В дополнение система сможет использовать 10,9 Пбайт памяти DDR5 с пропускной способностью до 5,95 Пбайт/с. Вместимость подсистемы хранения данных составит 230 Пбайт со скоростью работы до 31 Тбайт/с.  На сегодняшний день Intel поставила более 10 тыс. «лезвий» для Aurora, а это означает, что практически все узлы готовы к окончательному монтажу. Ввод суперкомпьютера в эксплуатацию намечен на текущий год. Для НРС-платформы готовится специализированная научная модель генеративного ИИ — Generative AI for Science, насчитывающая около 1 трлн параметров. Применять Aurora планируется для решения наиболее ресурсоёмких задач в различных областях.
11.01.2023 [03:00], Игорь Осколков
Асимметричный ответ: Intel официально представила процессоры Xeon Sapphire RapidsIntel официально представила серверные процессоры Xeon семейства Sapphire Rapids (SPR), выход которых изрядно задержался, а также ускорители ранее известные как Ponte Vecchio и теперь объединённые вместе с HBM-версиями SPR в отдельную HPC-серию Max. В этом поколении Intel не смогла догнать AMD EPYC Genoa по числу ядер, числу каналов памяти и линий PCIe, но заготовила ассиметричный, хотя и очень странно реализованный ответ. Всего представлено 52 модели с числом P-ядер от 8 до 60 и с TDP от 125 до 350 Вт. По числу ядер это существенный апгрейд по сравнению с Ice Lake-SP (до 40 ядер), да и IPC вырос у Golden Cove на 15 % в сравнении с Sunny Cove. Но это существенный проигрыш в сравнении с Genoa (до 96 ядер), особенно если учитывать их максимальный TDP в 360 Вт (cTDP до 400 Вт). Правда, у Sapphire Rapids есть ещё и экономичный режим работы, в котором энергопотребление снижается на 20 %, а производительность для некоторых нагрузок — всего на 5 %. 
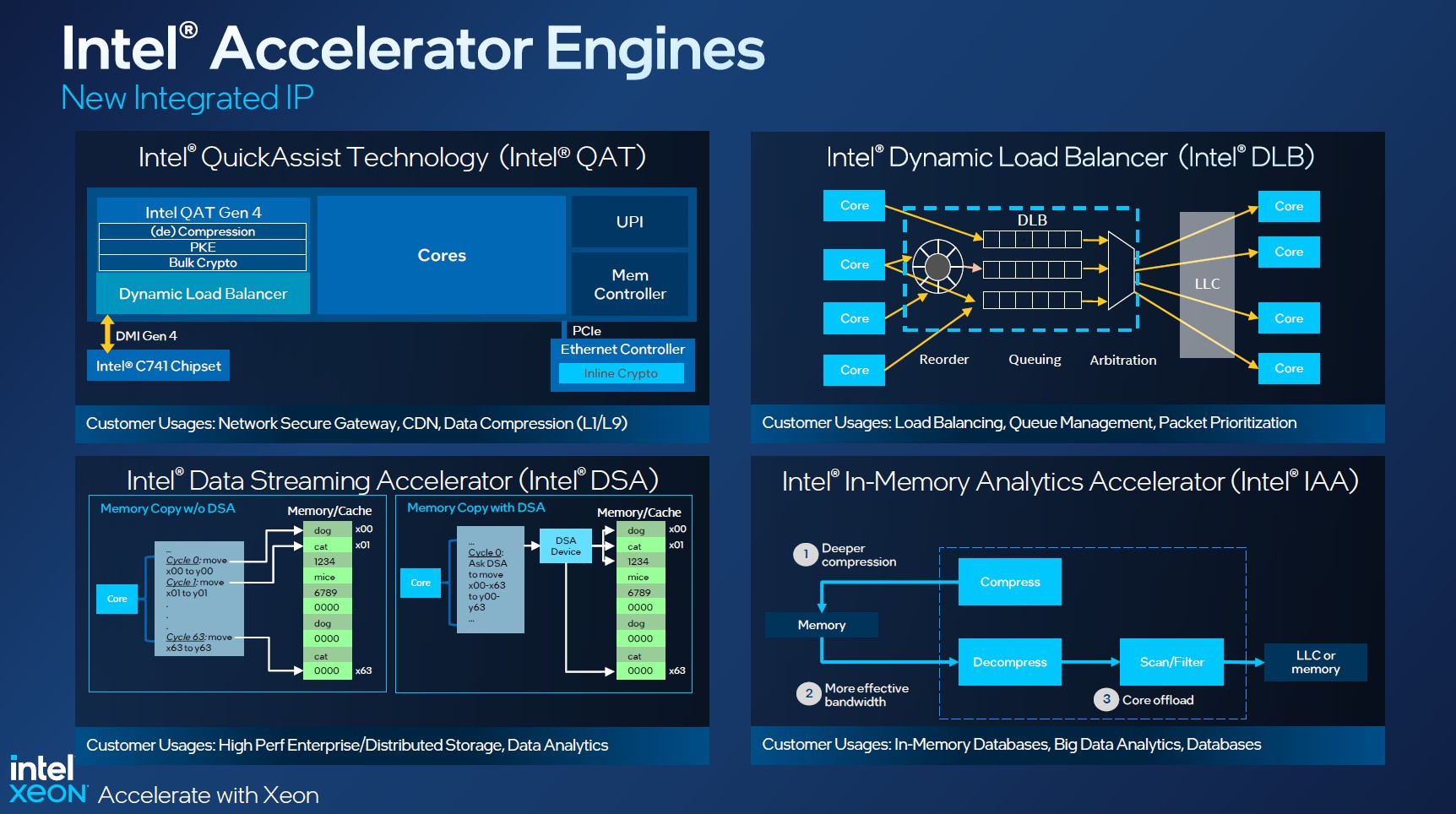
Изображения: Intel Sapphire Rapids предлагают 8 каналов памяти DDR5-4800 (1DPC) и DDR5-4400 (2DPC). 2DPC у Genoa пока что нет. Кроме того, контроллеры поддерживают и модули Optane PMem 300 (Crow Pass), но с учётом того, что производство 3D XPoint прекращено, достаться они могут не всем (впрочем, не всем они и нужны). Ну а маленькая серия Max также включает 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с). Остались и отличия в максимальном объёме SGX-анклавов в зависимости от модели CPU. 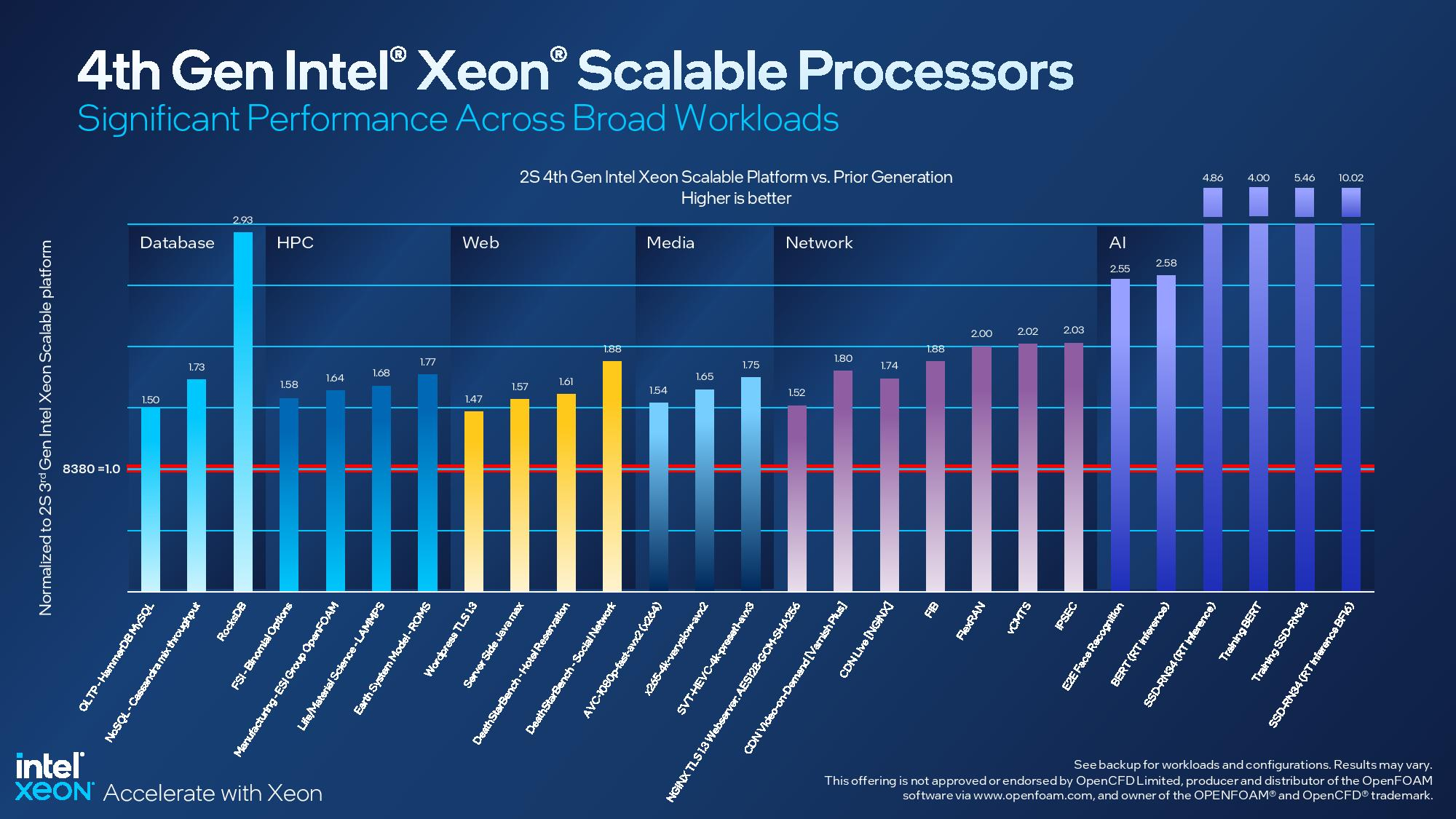 Однако по числу ядер на узел всё равно лидирует Intel. Если AMD поддерживает только 2S-конфигурации, то Intel снова предлагает и 4S, и 8S (а с момента выхода Cooper Lake-SP прошло немало времени) — на процессор доступно до 4 линий UPI 2.0 (16 ГТ/с в сравнении с 11,2 ГТ/с у Ice Lake-SP). В 2S-платформах Sapphire Rapids также формально обгоняет Genoa по числу линий PCIe 5.0, которых тут по 80 шт. на сокет. Формально потому, что в случае Genoa при желании всё же можно получить 160 линий, пожертвовав скоростью шины между CPU, но в односокетном варианте EPYC в любом случае интереснее Xeon.  Без нюансов тут не обошлось. Так, при бифуркации до 8 x2 скорость падает до PCIe 4.0. Зато каждый root-комплекс поддерживает CXL 1.1, тогда как у Genoa CXL есть только у половины! Впрочем, поддержка всё равно ограничена 4x CXL-устройствами на CPU. Что ещё более странно, официально заявлена поддержка только устройств Type 1 и Type 2, но не Type 3, хотя последние весьма пригодились бы в ряде конфигураций, где требуется больше относительно недорогой, пусть и несколько более медленной, RAM. 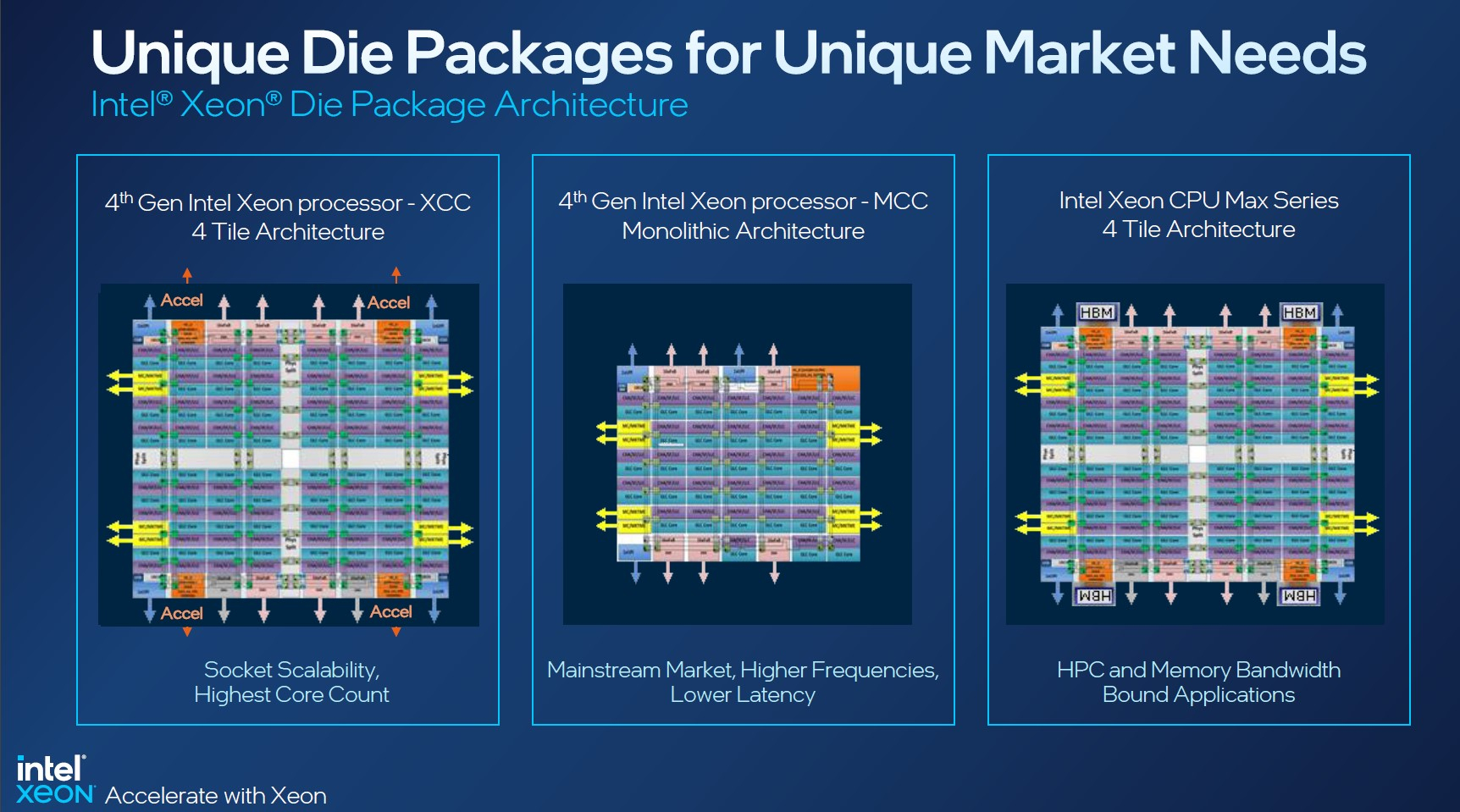 Сохранилось традиционное разделение на серии Platinum (8000), Gold (6000/5000), Silver (4000) и Bronze (3000), к которым теперь добавилась серия Max (9400). Список суффиксов, означающих оптимизацию под те или иные задачи и наличие каких-то особенностей, стал чуть шире: Y (SST-PP 2.0), Q (рассчитаны на работу с СЖО), U (односокетные общего назначения), T (увеличенный жизненный цикл), H (in-memory СУБД, аналитика, виртуализация), N (сетевые решения, в том числе для 5G), облачные P/V/M (IaaS/Paa/медиа), S (СХД и HCI). 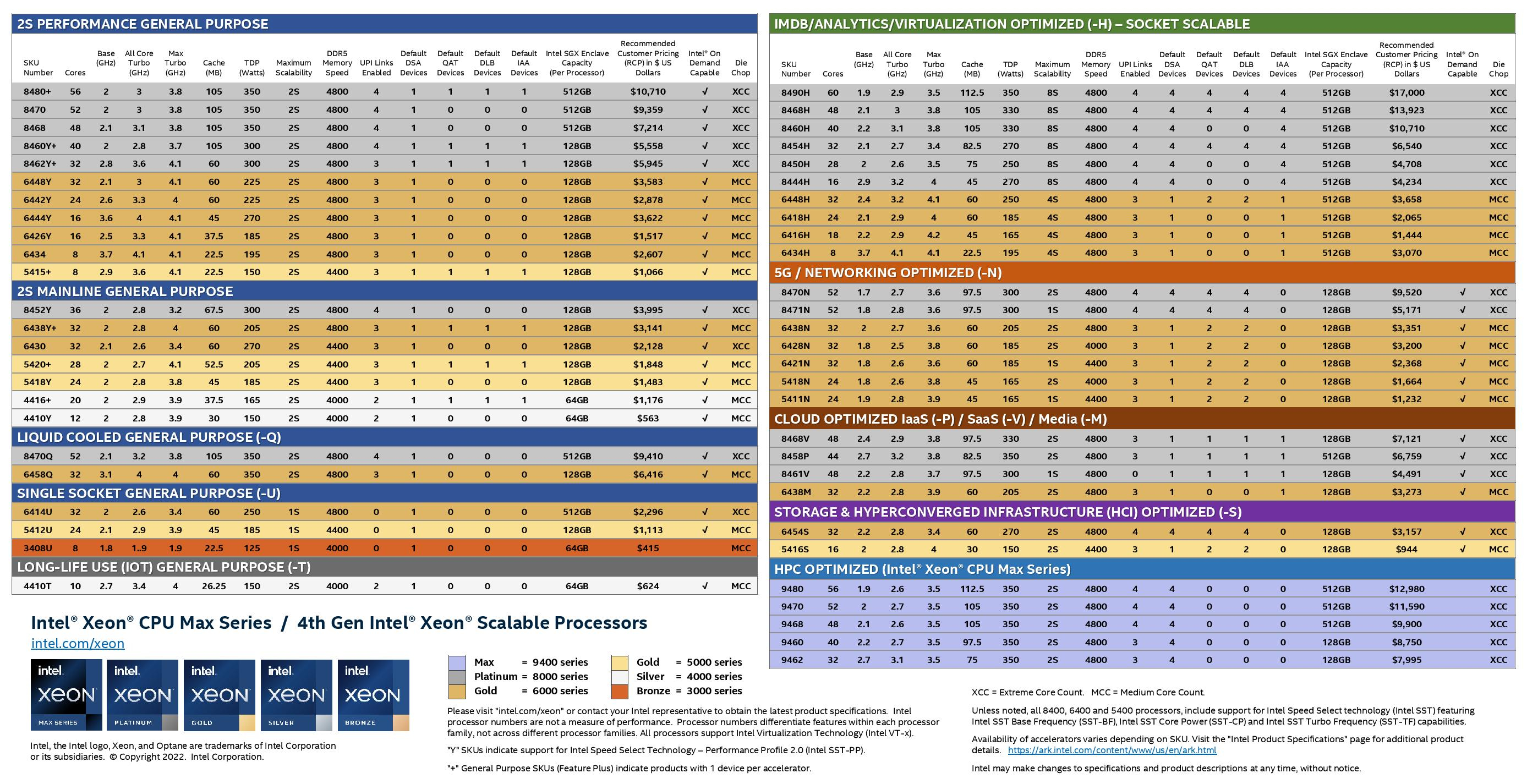 Но некоторые модели также имеют в названии «+». И вот тут начинается самое интересное! Все процессоры получили «традиционную» (в сравнении с Genoa) реализацию AVX-512, включая DL Boost, а также целый новый набор ИИ-инструкций AMX (до 10 раз быстрее обучение и инференс в сравнении с Ice Lake-SP). Есть и всяческие Speed Select, DDIO, TDX, CET и т.д. Но Sapphire Rapids также получили четыре отдельных ускорителя:
 Intel заявляет, что средний прирост производительности Sapphire Rapids в сравнении с Ice Lake-SP составил 1,53 раза. А вот для ряда нагрузок, которые могут задействовать новые ускорители прирост производительности на Вт составляет уже до 2,9 раз! То есть Intel продолжает придерживаться стратегии создания максимально универсальных CPU для различных нагрузок. И действительно, спорить с гибкостью Sapphire Rapids трудно. Но какой ценой это достигается? Т.е. буквально: во сколько это обойдётся заказчику? Ответа пока нет.  Дело в том, что в зависимости от модели отличается число доступных и число активированных ускорителей. Фактически в новом поколении используется два вида кристаллов: XCC, «сшитые» из четырёх отдельных тайлов, и монолитные MCC (до 32 ядер, причём 32-ядерных моделей в серии большинство). У каждого тайла в XCC есть по одному блоку QAT, DSA, DLB и IAA, т.е. суммарно на CPU приходится до четырёх ускорителей каждого типа. В случае MCC может быть по два QAT и DLB и по одному DSA и IAA на процессор. Например, у тех моделей, что помечены «+», активно по одному блоку каждого типа, а минимум один DSA активен есть вообще у всех CPU.  За не активированные по умолчанию ускорители придётся заплатить в рамках программы Intel On Demand (SDSi), причём есть опции как с единовременным платежом за постоянную активацию, так и с оплатой по факту использования (это удобно в случае облаков и платформ по типу HPE Greenlake). Исключением являются H-модели, куда входит и самый дорогой ($17000) 60-ядерный процессор 8490H с полностью разблокированными ускорителями и поддержкой 8S-конфигураций, а также процессоры Max, которым доступно только четыре DSA-блока и 2S-платформы, например, 56-ядерный 9480 ($12980). 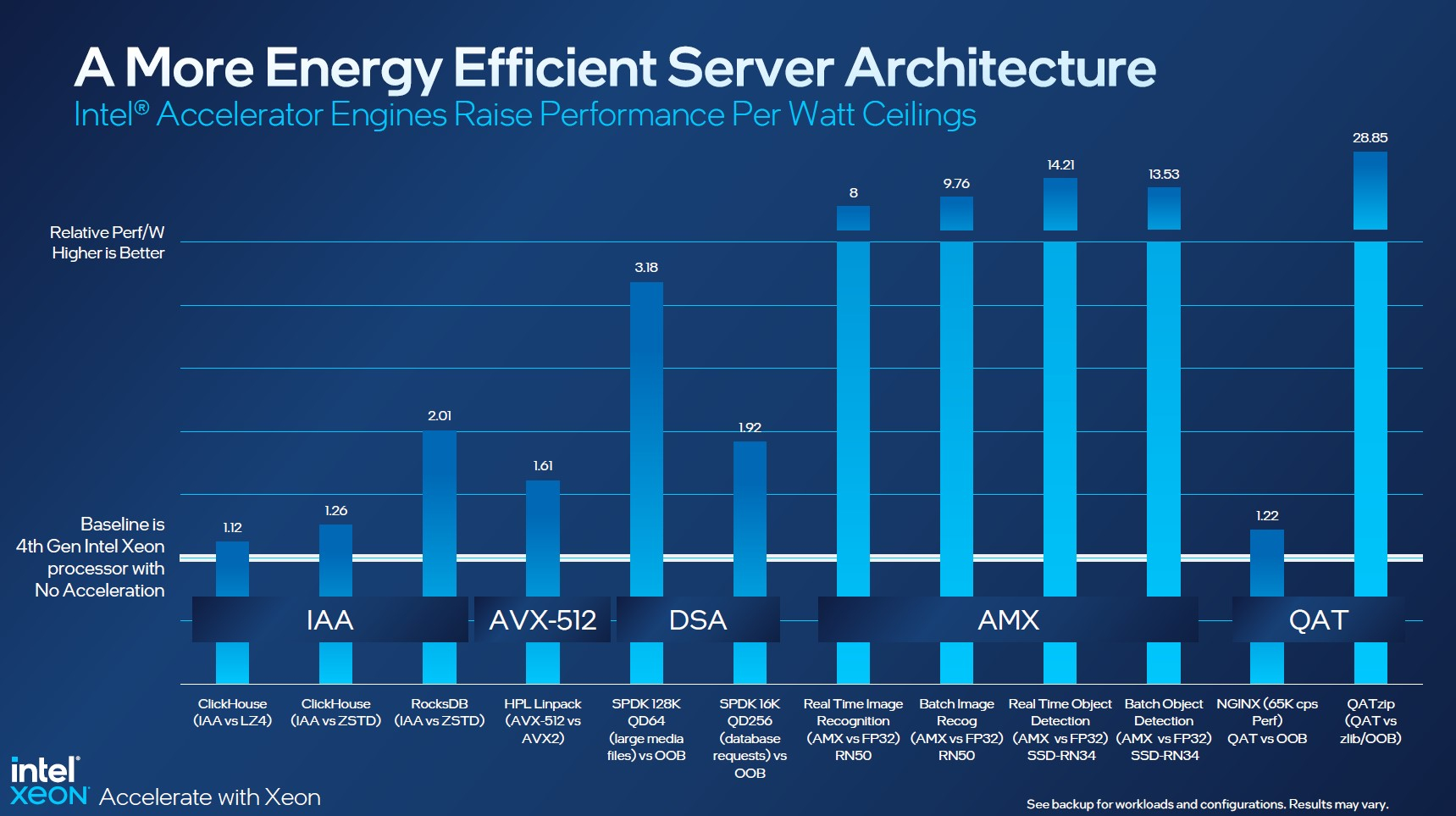 С одной стороны, желание Intel предоставить больше гибкости заказчикам, а заодно чуть увеличить выход годных к продаже процессоров, понятно. С другой — не очень-то и похоже, что CPU без «лишних» ускорителей отдаются с какой-то существенной скидкой. При этом транзисторный бюджет на них всё равно расходуется. Кроме того, есть ещё момент востребованности этих ускорителей и готовности ПО. У Intel есть и опыт ресурсы для помощи разработчикам, но процесс адаптации в любом случае не мгновенен.  Впрочем, у Intel по сравнению с AMD есть и ещё одно важное преимущество — в среднем более высокая доступность процессоров для большинства заказчиков. Так что с Sapphire Rapids может повториться та же история, что с Ice Lake-SP, когда вендоры здесь и сейчас готовы были предложить Intel-платформы.  В целом же, в новом семействе наиболее любопытны Xeon Max, которые, по словам Intel, по сравнению с прошлым поколением в 3,7 раз производительнее в задачах, завязанных на пропускную способность памяти (а это целый пласт HPC-нагрузок), и которые не так уж дороги. Правда, и здесь без приключений не обошлось — несчастный суперкомпьютер Aurora ожидает утомительный апгрейд его 10 тыс. узлов c простых Xeon Sapphire Rapids на Xeon Max — по полчаса на каждый узел.
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 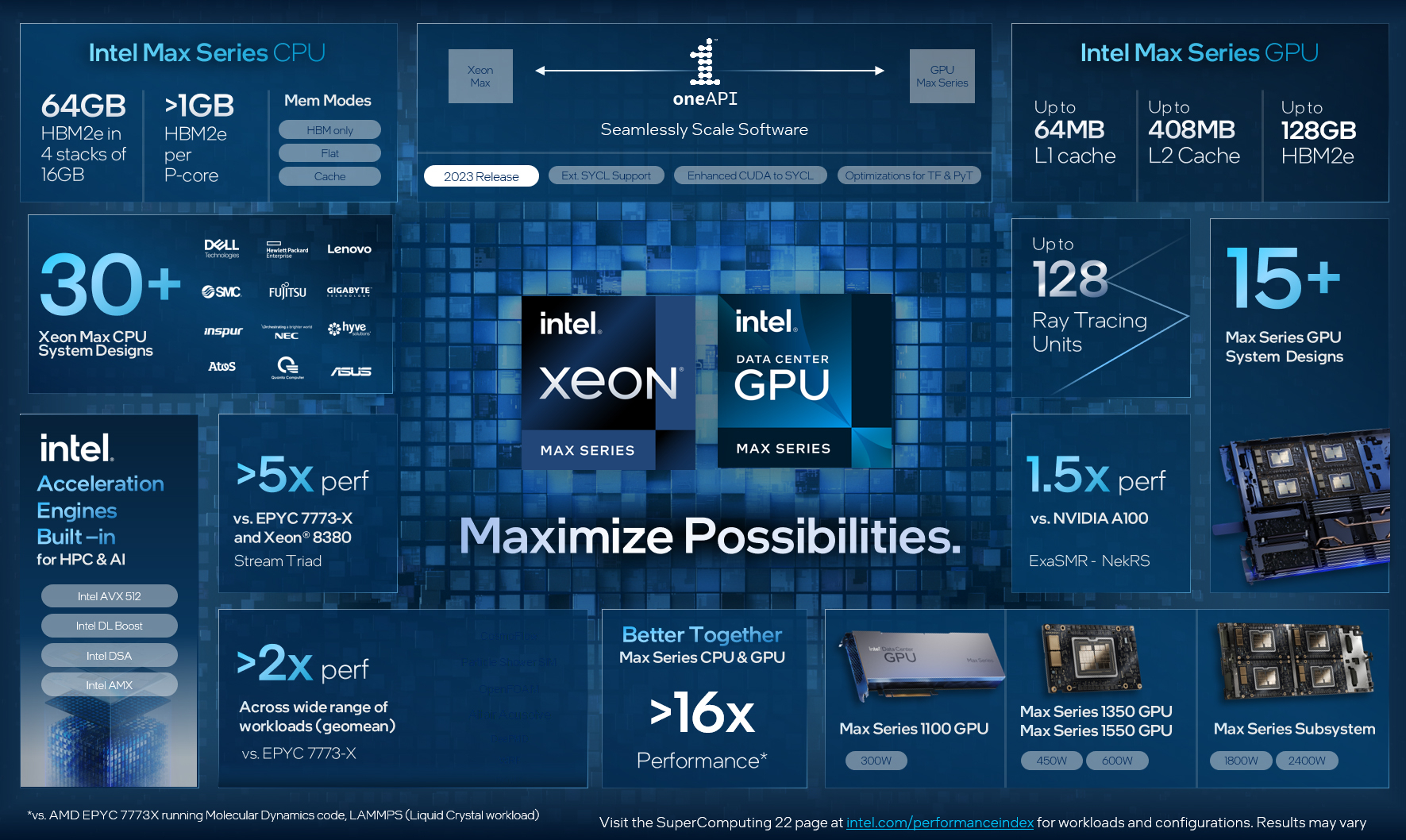
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 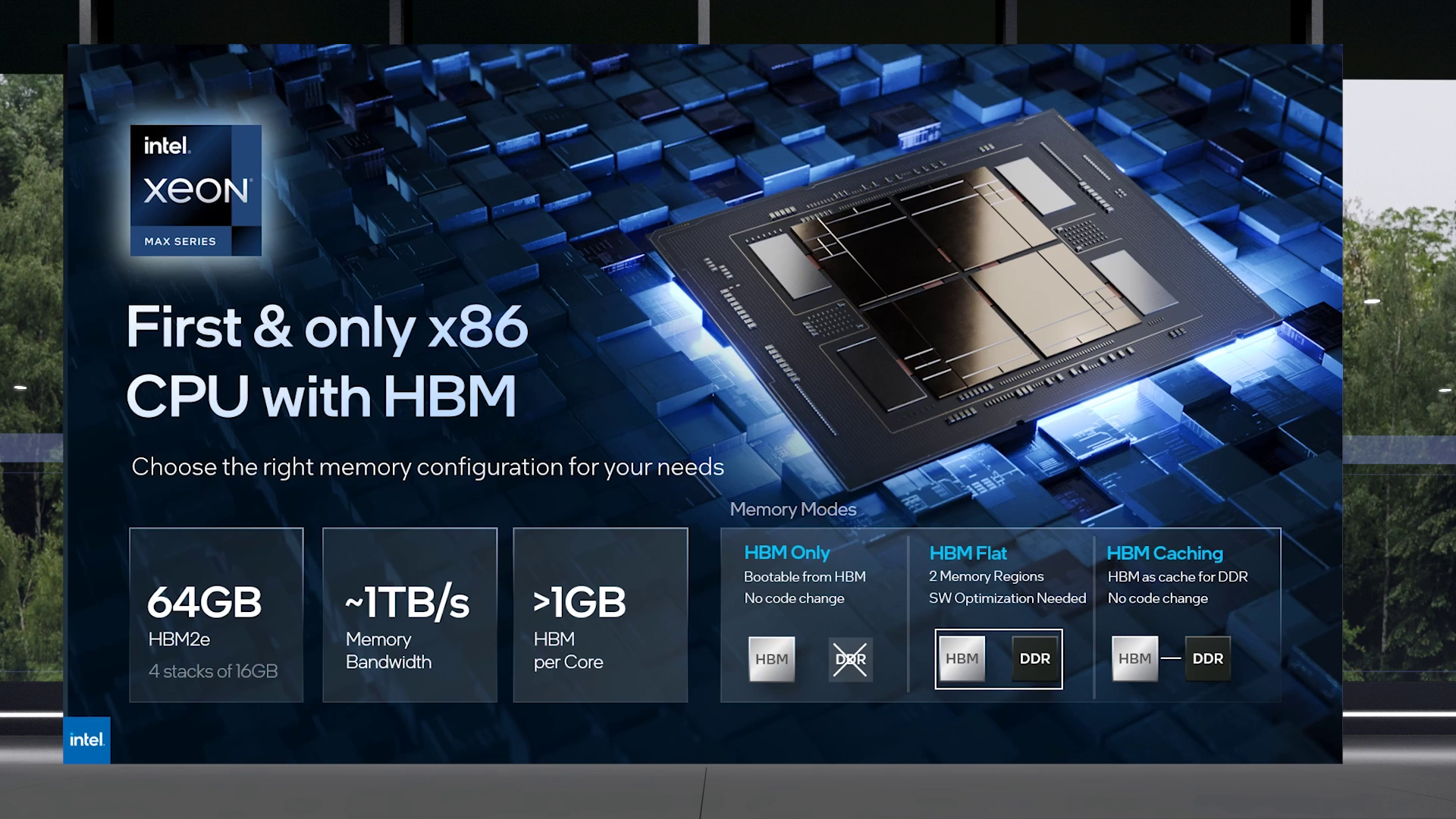 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA. |
|


