Материалы по тегу: cpu
|
10.03.2026 [12:50], Сергей Карасёв
AMD пополнила семейство процессоров Ryzen AI Embedded P100 моделями, насчитывающими до 12 ядерКомпания AMD расширила ассортимент процессоров Ryzen AI Embedded P100, анонсировав модели, насчитывающие до 12 вычислительных ядер. Изделия оптимизированы для применения в промышленном секторе: они подходят для решения широкого спектра ИИ-задач на периферии, включая машинное зрение, автоматизацию, 3D-визуализацию и пр. Чипы Ryzen AI Embedded P100 дебютировали в январе нынешнего года. Изначально были выпущены модели с четырьмя и шестью ядрами. Теперь к ним добавились более производительные решения — процессоры P164/P164i, P174/P174i и P185/P185i с 8, 10 и 12 ядрами соответственно. Используется архитектура Zen 5. Номинальный показатель TDP находится на уровне 28 Вт, величина cTDP варьируется от 15 до 54 Вт. Диапазон рабочих температур простирается от 0 до +105 °C, а у версий с индексом «i» — от -40 до +105 °C. 
Источник изображений: AMD В состав изделий входят графический блок AMD RDNA 3.5 и нейронный узел (NPU) на архитектуре AMD XDNA 2 для ускорения выполнения задач ИИ. Суммарная ИИ-производительность (на уровне процессора) достигает 80 TOPS. Максимальная тактовая частота у новых процессоров составляет 5,0–5,1 ГГц, объём кеша L3 — 16 или 24 Мбайт (см. технические характеристики ниже). Возможно использование оперативной памяти LPDDR5X-8533 или DDR5-5600. Говорится о поддержке 16 линий PCIe 4.0, интерфейсов USB4, USB 3.2, USB 3.1 и USB 2.0. 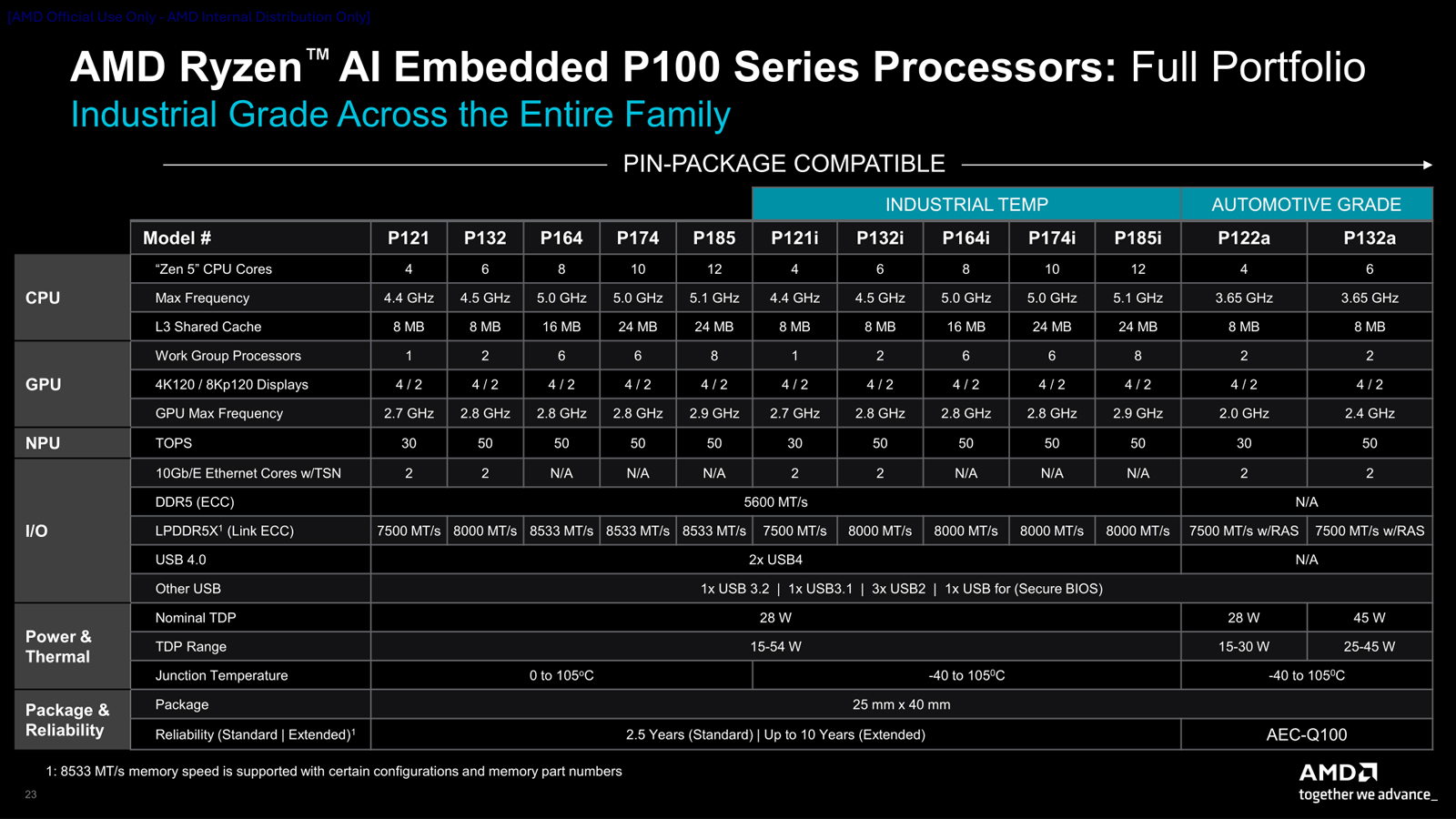 Упомянута совместимость с открытой программной экосистемой AMD ROCm. Процессоры Ryzen AI Embedded P100 рассчитаны на эксплуатацию в круглосуточном режиме. Пробные поставки изделий уже начались, а массовые отгрузки запланированы на июль нынешнего года.
09.03.2026 [16:39], Владимир Мироненко
Ubitium стала на шаг ближе к выпуску универсального RISC-V процессора, заменяющего CPU, GPU, DSP и FPGAНемецкий стартап Ubitium объявил о завершении стадии tape-out (финальный этап проектирования) универсального RISC-V-процессора, изготовленного по 8-нм техпроцессу Samsung Foundry и предназначенного для рынка встроенных вычислительных систем автомобилей, промышленного оборудования и бытовой электроники, включая радарные и многосенсорные сигнальные цепи, аудио и голосовую связь в реальном времени, компьютерное зрение, периферийный ИИ, промышленный человеко-машинный интерфейс (HMI) и т.д. В основе процессора Ubitium лежит «универсальный процессорный массив» (Universal Processing Array) — программно-определяемая система с 256 элементами, объединяющая функции CPU, GPU, DSP и FPGA и способная мгновенно менять режимы выполнения во время работы. Такая унификация позволяет чипу переключаться между режимом работы в качестве CPU общего назначения для обслуживания ОС и режимом работы в качестве ИИ-ускорителя, избегая задержек при передаче данных между отдельными чипами. 
Источник изображения: Ubitium Завершение tape-out на 8-нм техпроцессе Samsung подтверждает работоспособность основного процессорного массива и интерфейса LPDDR5. Для Ubitium доказательство того, что один процессор может обрабатывать общие вычислительные задачи, задачи обработки в реальном времени и задачи ИИ на одном кристалле, является важным шагом на пути к коммерческой жизнеспособности, отметил EE Times. «Это решение претворяет давно существующую концепцию в жизнь», — заявил Мартин Форбах (Martin Vorbach), технический директор Ubitium. «Встроенные системы переросли архитектуры, на которые сегодня опирается отрасль. Консолидация больше не является необязательной. Она неизбежна», — добавил он. Технология, лежащая в основе этого проекта, совершенствовалась более 15 лет. Для её воплощения в жизнь Форбахом совместно с рядом специалистов была создана в 2024 году компания Ubitium. Ускорить разработку позволило привлечение $3,7 млн в рамках посевного раунда в конце прошлого года, который совместно возглавили Runa Capital, Inflection и KBC Focus Fund. Инвестиции позволили Ubitium проверить архитектуру и подготовить наборы для разработки (IDK) для первых клиентов. 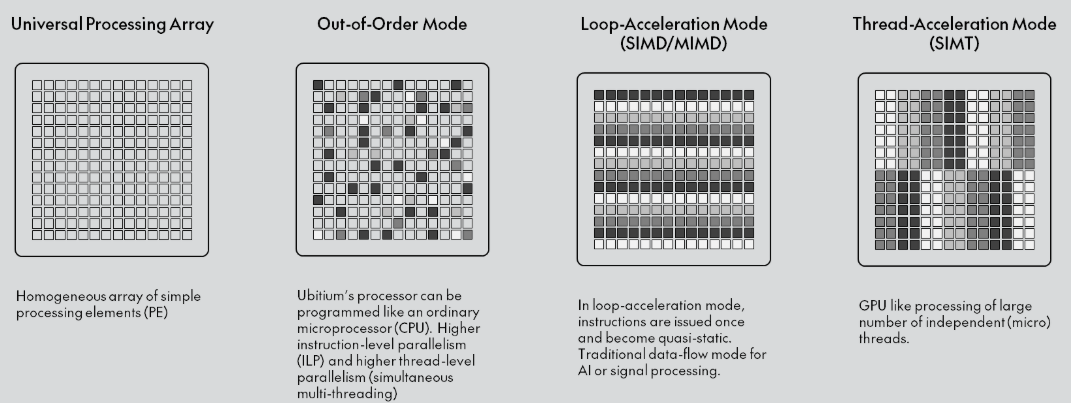
Источник изображения: Ubitium «Индустрия процессоров объёмом $500 млрд построена на жёстких границах между вычислительными задачами», — сказал Хён Шин Чо (Hyun Shin Cho), генеральный директор Ubitium и соучредитель. — Мы стираем эти границы. Наш универсальный процессор делает всё — CPU, GPU, DSP, FPGA — на одном чипе, в одной архитектуре. Это не просто постепенное улучшение. Это смена парадигмы. Это архитектура процессора, которую требует эпоха ИИ». Как отметил EE Times, завершение tape-out продукта — это не просто большая победа для Ubitium. Это также поворотный момент для экосистемы RISC-V. Открытая архитектура RISC-V используется большей частью для создания обычных ядер, которые полагаются на внешние ускорители для сложных рабочих нагрузок. Ubitium расширяет границы использования архитектуры, сохраняя полную совместимость с RISC-V. Процессор поддерживает стандартные наборы инструментов RISC-V для разработки ПО и может работать под управлением Linux и RTOS. Кроме того, унифицированный программный стек устраняет необходимость в компиляторах для конкретного поставщика или проприетарных языках, что позволяет быстро внедрять инновации и сократить время разработки. Компания сотрудничает с Samsung Foundry и ADTechnology для завершения проектирования и с Siemens Digital Industries Software — для проверки микросхемы (pre-silicon validation). Вторая стадия tape-out запланирована на конец этого года, а серийное производство начнётся в 2027 году, сообщила компания.
26.02.2026 [10:12], Сергей Карасёв
AMD анонсировала процессоры EPYC 8005 Sorano для телеком- и периферийного оборудованияКомпания AMD анонсировала процессоры EPYC 8005 с кодовым именем Sorano. Эти чипы предназначены для применения в телекоммуникационном оборудовании, а также в системах на периферии. Изделия EPYC 8005 придут на смену процессорам EPYC 8004 Siena, выпущенным в 2023 году. Эти CPU насчитывают от 8 до 64 вычислительных ядер с поддержкой многопоточности. Показатель TDP варьируется от 80 до 200 Вт. Технические характеристики EPYC 8005 пока полностью не раскрываются. Известно, что новые чипы получат до 84 ядер на архитектуре Zen 5. Максимальный показатель TDP составит 225 Вт. В Sorano реализованы средства оптимизации для операций декодирования с малой плотностью проверок на чётность (LDPC), направленные на снижение задержки и ускорение коррекции ошибок в сетях 5G. 
AMD EPYC 8005 Sorano Как отмечает ресурс The Register, в конструктивном плане решения EPYC 8005 могут состоять из шести чиплетов Zen 5c с оптимизацией по плотности, в которых будут активированы по 14 из 16 ядер. Альтернативный вариант — 12 чиплетов Zen 5 с оптимизацией по частоте, в каждом из которых будут активны семь ядер из восьми.  Новые процессоры ориентированы на односокетные серверы. По заявлениям AMD, чипы обеспечивают высокую производительность при низком энергопотреблении. Изделия спроектированы для сложных условий эксплуатации на периферии сети: они имеют широкий диапазон рабочих температур. Решения EPYC 8005 могут применяться в рамках следующей фазы развития открытых и виртуализированных сетей радиодоступа (RAN). О поддержке процессоров сообщили такие компании, как Ericsson, Samsung Electronics, Supermicro и Wind River.
17.02.2026 [13:57], Владимир Мироненко
Первый европейский суверенный RISC-V-процессор Cinco Ranch изготовлен по техпроцессу Intel 3Лаборатория суперкомпьютерных вычислений (BZL) Национального центра суперкомпьютерных вычислений Барселоны (BSC-CNS) сообщила об успешном запуске тестового чипа Cinco Ranch TC1 на архитектуре RISC-V, изготовленного по передовому техпроцессу Intel 3. В заявлении отмечено, что результаты подтверждают надёжность конструкции и жизнеспособность вычислительной архитектуры на базе открытой платформы RISC-V. «Это достижение является ключевым этапом в процессе разработки чипа и качественным скачком на пути к суверенным суперкомпьютерным технологиям в Европе», — подчеркнула BZL, отметив, что готовый чип предлагает открытую, гибкую альтернативу, свободную от зависимости от проприетарных архитектур крупных транснациональных корпораций. Проект связан с Европейской инициативой по процессорам (EPI), целью которой является разработка отечественных процессоров для будущих европейских суперкомпьютеров и промышленных систем. «Успешная стабильная загрузка Linux и проверка достижения чипом ожидаемых частот подтверждают зрелость конструкции и качество работы, проделанной командами BZL», — говорит исследователь BSC и координатор аппаратной части лаборатории Zettascale в Барселоне. 
Источник изображений: BZL Cinco Ranch TC1 — это первый чип, произведенный в академической среде с использованием 3-нм техпроцесса Intel 3. На этапе проектирования, из-за невозможности прямого доступа к этой технологии, BZL провела внутренние оценки на сопоставимом техпроцессе TSMC N7, что позволило оценить конструкцию перед окончательной реализацией. Сообщается, что структура Cinco Ranch TC1 основана на трёх взаимодополняющих процессорных блоках, предназначенных для совместной работы и охвата различных вычислительных профилей. В чипе используются три блока RISC-V на одном кристалле, каждый из которых ориентировано на специализированные рабочие нагрузки. Три ядра используют микроархитектуры Sargantana, Lagarto Ka и Lagarto Ox, с основным упором на эффективность, векторные нагрузки и скалярную обработку соответственно. Подсистема CPU занимает всего 3,2 мм² на крошечном кристалле площадью 15,2 мм², который также включает высокоскоростные интерфейсы, такие как PCIe 5.0 и DDR5. Для сравнения, площадь CCD восьмиядерного процессора AMD Zen 5 составляет около 71 мм², и для этого чиплета также требуется отдельный кристалл I/O, отметил ресурс HotHardware.com.  Cinco Ranch TC1 был протестирован на оценочной плате Hawk Canyon V2, разработанной Intel для первоначальной проверки чипа после его производства. Следующим этапом станет функциональное тестирование и тестирование производительности, оптимизация ПО и полная проверка системы. В мае 2025 года на Cinco Ranch TC1 (Test Chip 1) была успешно загружена ОС Linux, а в июле 2025 года, после получения партии из 500 чипов, начались работы по характеризации и проверке. Вся партия продемонстрировала высокую функциональную производительность, при этом большинство устройств успешно запустили все три интегрированных процессора чипа. Также результаты тестов подтверждают, что Cinco Ranch TC1 работает на частоте до 1,25 ГГц, что превышает консервативные оценки, сделанные на этапе проектирования. Для BZL и её партнёров это достижение является важной вехой и доказательством того, что разработанные в Европе процессоры с открытой ISA могут быть реализованы на передовых технологиях производства и воплощены в реальных кремниевых решениях. Для Европы — это значимый шаг к технологической автономии в HPC. А для Intel это демонстрация того, что её бизнес может оказывать всестороннюю поддержку передовым внешним клиентам в сложных гетерогенных проектах.
16.02.2026 [10:11], Сергей Карасёв
Китайская Montage Technology выпустила серверные процессоры Jintide на базе Intel Xeon 6Китайская компания Montage Technology, на днях осуществившая первичное публичное размещение акций (IPO) на Гонконгской фондовой бирже, выпустила серверные процессоры Jintide следующего поколения, в основу которых положена архитектура Intel Xeon 6, доработанная под требования заказчиков в КНР. В частности, вышли изделия Jintide C6P, которые фактически представляют собой процессоры Intel Xeon 6 семейства Granite Rapids-SP на базе производительных ядер P-core. Их количество в китайских чипах достигает 86 с возможностью одновременной обработки до 172 потоков инструкций, а максимальный объем кеша L3 составляет 336 Мбайт. Реализована 8-канальная подсистема памяти DDR5 с поддержкой модулей RDIMM-6400 и MRDIMM-8000. Процессоры Jintide C6P могут применяться в одно- и двухсокетных конфигурациях. Говорится о поддержке 88 линий PCIe 5.0 и протокола CXL 2.0. Пропускная способность шины UPI достигает 24 ГТ/с. Обеспечивается полная совместимость с набором инструкций x86. Чипы ориентированы на дата-центры и облачные инфраструктуры с высокой вычислительной нагрузкой. 
Источник изображений: Montage Technology Кроме того, дебютировали решения Jintide C6E — это модифицированные изделия Intel Xeon 6 Sierra Forest-SP с энергоэффективными ядрами E-core: их количество достигает 144. Размер кеша L3 составляет до 108 Мбайт. Процессоры имеют восемь каналов памяти DDR5-6400 и до 88 линий PCIe 5.0. Упомянута поддержка CXL 2.0 и шины UPI с пропускной способностью до 24 ГТ/с. Решения Jintide C6E могут устанавливаться в одно-и двухсокетные системы.  Компания также анонсировала чип Jintide M88STAR5(N), на основе которого реализуются различные функции безопасности. Изделие, использующее технологию Mont-TSSE (Trust & Security System Extension), отвечает за аппаратное шифрование/дешифрование данных в соответствии с местными стандартами и доверенные вычисления. На кристалле присутствуют нескольких генераторов случайных чисел, а общая пропускная способность достигает 160 Гбит/с через PCIe 5.0 х8. Упомянута поддержка стандартов TPM, TCM и TPCM, а также интерфейсов SMBus, I3C, UART, SPI и GPIO. 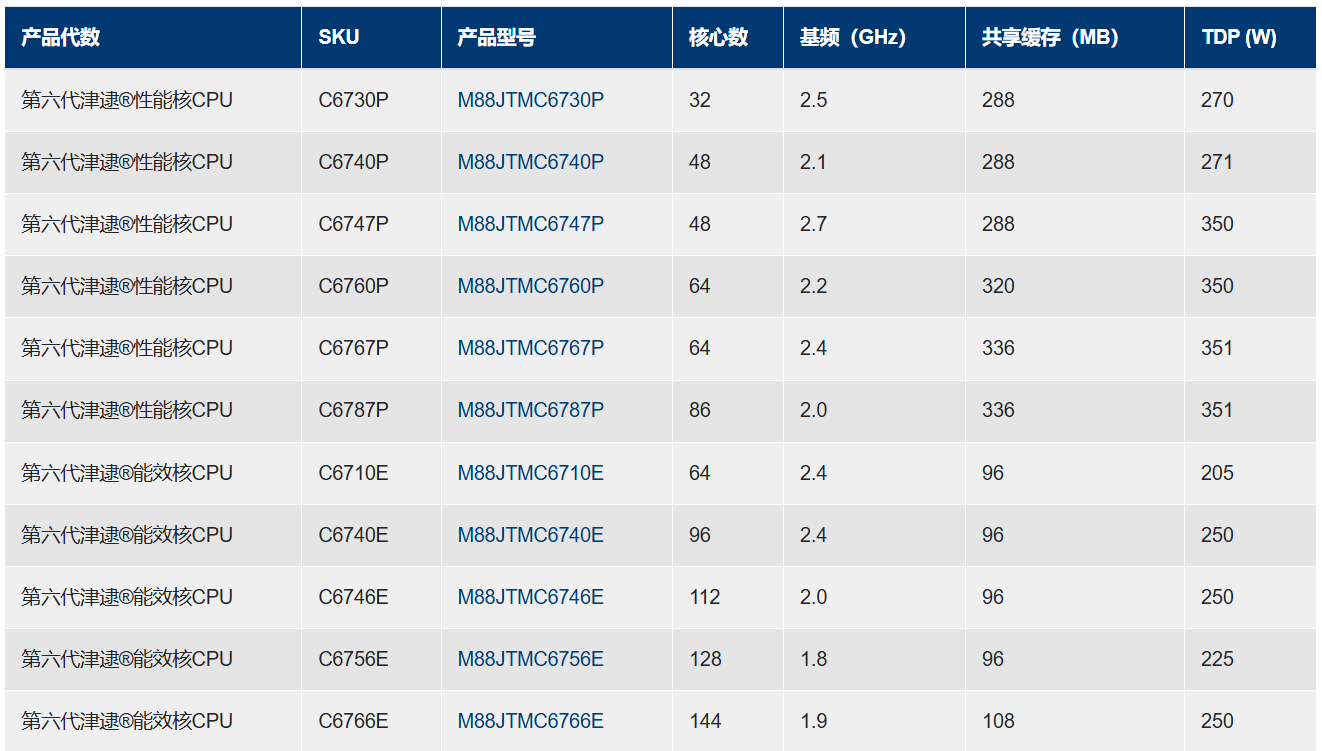 Наконец, Montage Technology представила чип Jintide M88IO3032 IOH (I/O Hub), предназначенный для использования с CPU нового поколения. Изделие обеспечивает поддержку PCIe 3.0, SATA 3.2 (до 20 портов; RAID 0/1/5/10), USB 3.2/2.0 и пр.
05.02.2026 [12:31], Руслан Авдеев
Omdia прогнозирует рост цен на всё более дефицитные серверные CPUВ 2026 году дата-центры могут столкнуться не только с уже имеющимся дефицитом памяти, но и не менее серьёзной проблемой, связанной с ограничением поставок классических серверных процессоров, сообщает The Register со ссылкой на аналитику Omdia. Тем не менее, эксперты ожидают, что поставки будут расти двузначными темпами. В обзоре Cloud and Datacenter Market Snapshot компания Omdia сообщила, что серверных CPU тоже не хватает и это, вероятно, приведёт к росту цен и увеличению общей стоимости вычислительных систем. По мнению экспертов, как минимум отчасти это связано со сложностью переноса объёмов производства между разными техпроцессами. По мере масштабирования планов производителям CPU приходится выпускать продукцию на разных техпроцессах, например 3 нм и 5 нм. При этом перераспределение объёмов производства между разными технологическими линиями — процесс довольно сложный и трудоёмкий. Дефициту может способствовать и более высокий, чем ожидалось, процент брака готовой продукции. 
Источник изображения: Intel Как считает Omdia, в результате цены на серверные процессоры, возможно, вырастут на 10–15 % из-за дефицита предложения. Стоит учесть, что крупнейшие клиенты имеют долгосрочные соглашения с производителями с фиксированными ценами, иначе прогнозы были бы ещё хуже. Вместе с тем акции AMD и Intel упали из-за слабого, по мнению инвесторов, прогноза. Любые проблемы с CPU усугубят непростую ситуацию в цепочке поставок IT-оборудования. На фоне дефицита цены на DRAM-модули в данном квартале, вероятно, почти удвоятся, а цены на память NAND вырастут более чем на 30 %. Обычная DRAM оказалась в дефиците не в последнюю очередь потому, что производители перепрофилировали свои мощности на выпуск высокорентабельных продуктов — HBM-модулей для ИИ-ускорителей. 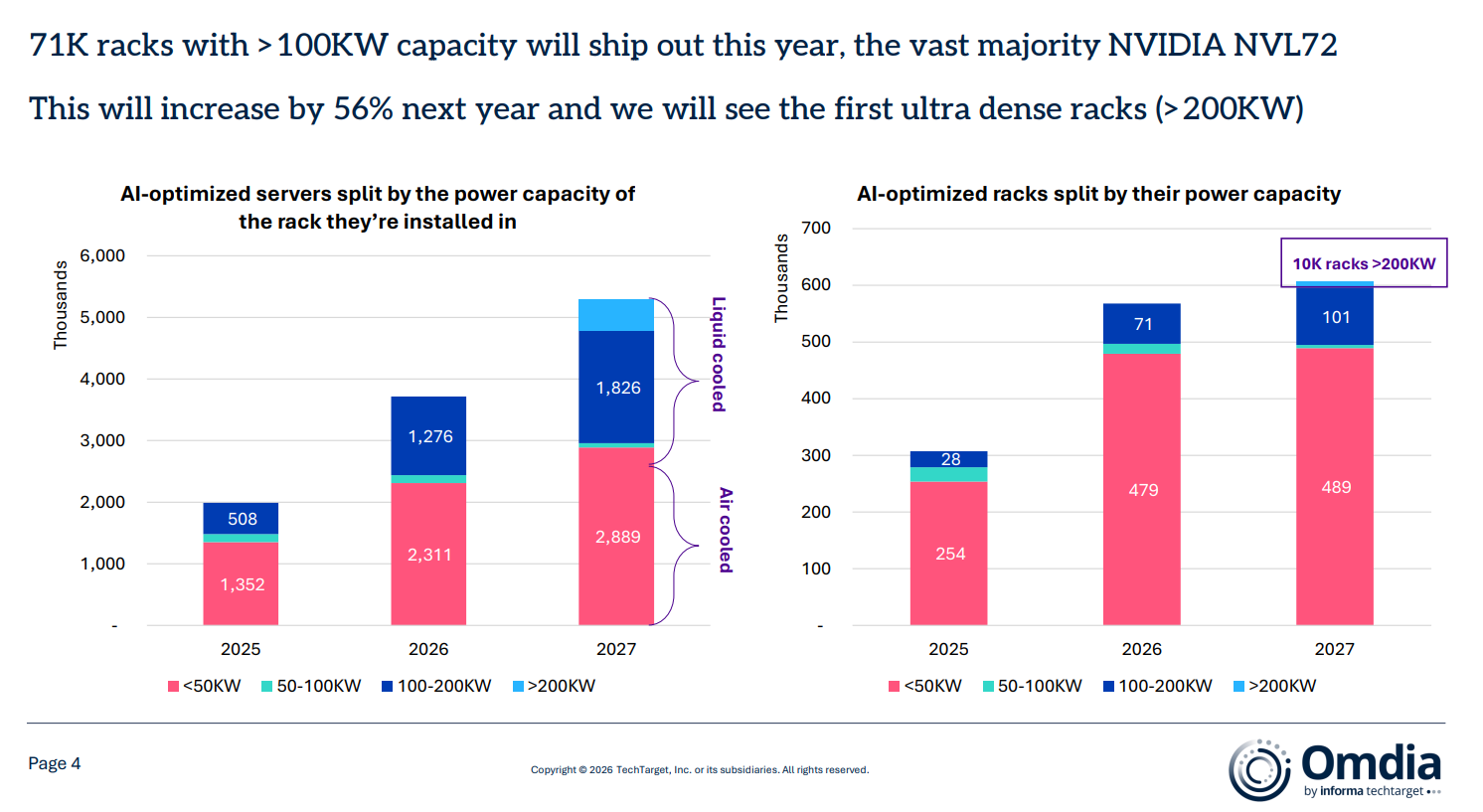
Источник изображения: Omdia Omdia обеспокоена тем, что дефицит оперативной памяти может сказаться на темпах производства серверов, что способно повлиять на сроки завершения уже реализуемых проектов ЦОД. Тем не менее, эксперты прогнозируют рост поставок серверов в 2026 году на 12 %. Основным драйвером выступает «цикл обновления» — необходимость закупки новых серверов общего назначения, что будет способствовать увеличению их поставок. При этом дефицит памяти называется большей угрозой, чем нехватка процессоров. Что касается стоек с серверами на базе ИИ-ускорителей, Omdia предполагает, что в 2026 году будет поставлено не менее 71 тыс. единиц с IT-нагрузкой более 100 кВт, в основном на базе систем NVIDIA NVL72. Благодаря высокому спросу на ИИ-инфраструктуру, Omdia ожидает, что в следующем году спрос увеличится ещё на 56 %, появятся и первые «сверхплотные» стойки мощностью более 200 кВт и дело на этом, вероятно, не закончится.
03.02.2026 [11:33], Сергей Карасёв
86 P-ядер, 128 линий PCIe 5.0 и 8 каналов DDR5-6400/8800: Intel представила чипы Xeon 600 для рабочих станцийКорпорация Intel представила процессоры семейства Xeon 600 для рабочих станций. В основу чипов положена архитектура Xeon 6700P Granite Rapids. Изделия приходят на смену Xeon W-2500/W-3500 (Sapphire/Emerald Rapids), которые дебютировали летом 2024 года. Процессоры Xeon 600 содержат вычислительные ядра Redwood Cove, количество которых варьируется от 12 до 86. Для сравнения, решения Xeon W-3500 насчитывают максимум 60 ядер. Важно отметить, что задействованы исключительно производительные Р-ядра (энергоэффективные Е-ядра в конструкцию не входят). Благодаря технологии многопоточности возможна обработка одновременно до 172 потоков инструкций. Базовая тактовая частота у новых CPU варьируется от 2,0 ГГц до 3,5 ГГц, а частота в турбо-режиме — от 4,6 до 4,9 ГГц. Объём кеша третьего уровня составляет от 48 до 336 Мбайт, показатель TDP — от 150 до 350 Вт. В серию вошли модели с разблокированным множителем для разгона («Х» в обозначении). 
Источник изображений: Intel Чипы Xeon 630 начального уровня предлагает четыре канала памяти DDR5 и 80 линий PCIe 5.0, в то время как более мощные процессоры Xeon 650/670/690 содержат восемь каналов памяти и 128 линий PCIe 5.0. Говорится о возможности использования модулей RDIMM-6400 и MRDIMM-8000 (только Xeon 670/690). Максимально допустимый объём ОЗУ составляет 4 Тбайт. Реализована поддержка CXL 2.0, что позволяет формировать дополнительны пулы памяти. 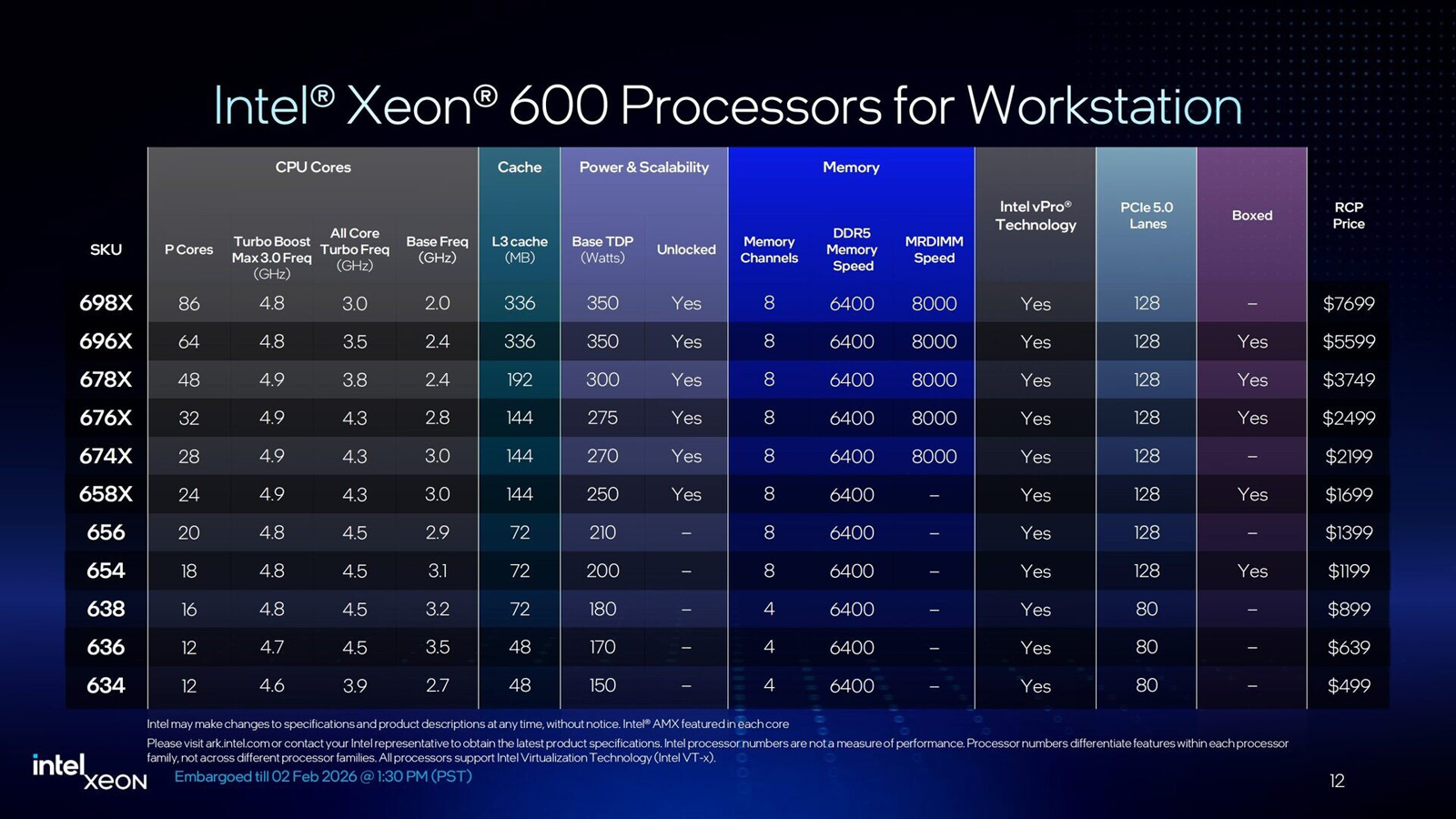 По заявлениям Intel, по сравнению с процессорами для рабочих станций предыдущего поколения прирост производительности в однопоточном режиме у Xeon 600 составляет до 9 %, в многопоточном режиме — до 61 %. Улучшения затронули встроенный аппаратный ускоритель Intel AMX (Advanced Matrix Extensions), предназначенный для повышения производительности в задачах ИИ, глубокого обучения и анализа данных. Если ранее он поддерживал операции INT8 и BFloat16, то теперь добавлен режим FP16. Среди прочего упомянуты технологии Intel vPro Enterprise и Intel Deep Learning Boost.
В паре с процессорами Xeon 600 будет использоваться новый набор логики Intel W890. Для подключения к CPU служит канал DMI 4.0 x8, обеспечивающий пропускную способность немногим менее 16 Гбайт/с. Чипсет предусматривает поддержку интерфейса USB 3.2 Gen 2×2 (20 Гбит/с), портов SATA-3, дополнительных линий PCIe 4.0, сетевых интерфейсов 1GbE и 2,5GbE, а также Wi-Fi 7. 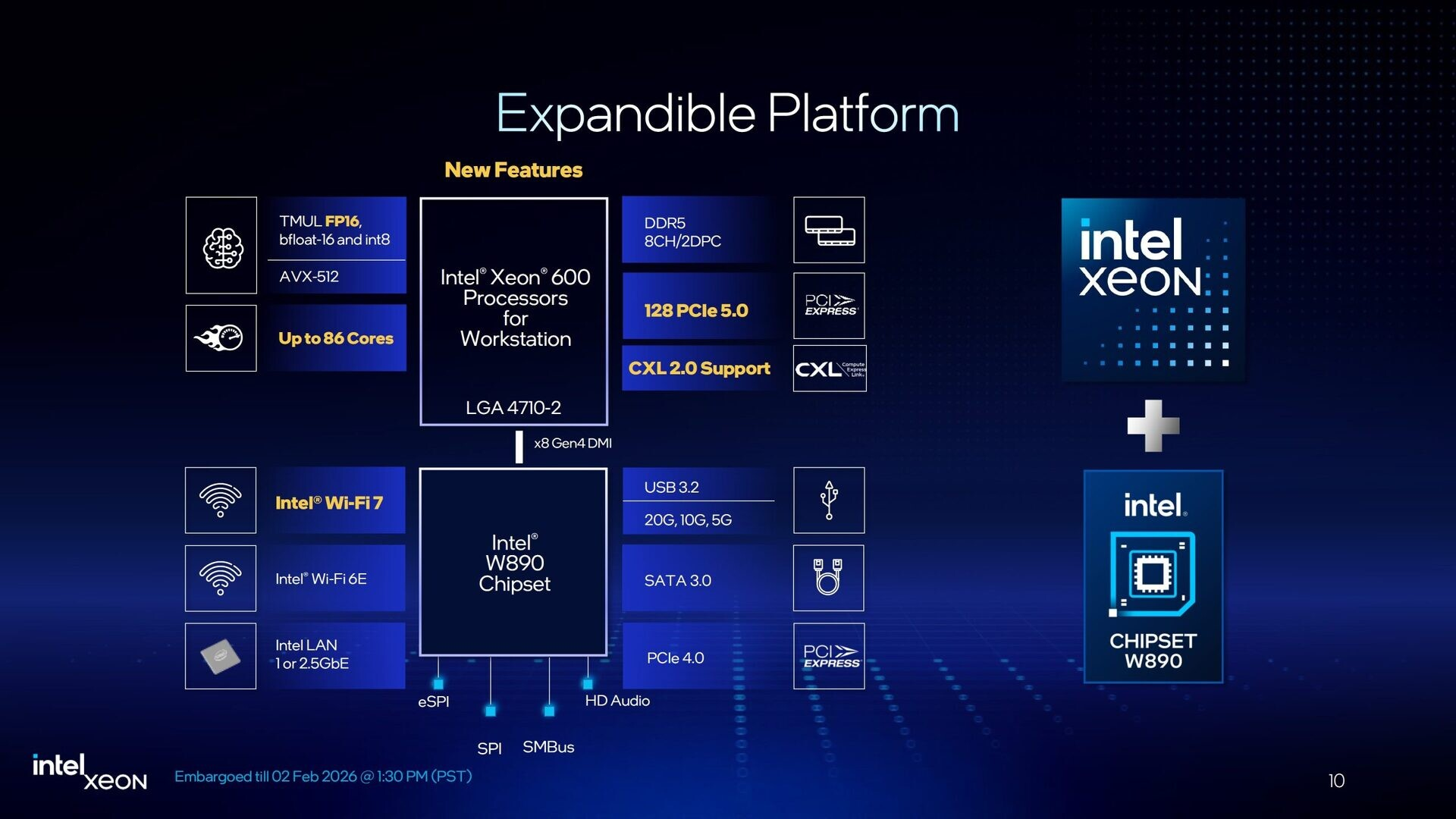 При заказе процессоров Xeon 600 корпорация Intel призывают клиентов убедиться, что новая платформа подходит для их рабочих нагрузок. Чипы поступят в продажу в конце марта по цене от $499 до $7699. Некоторые модели будут доступны в коробочной версии: это изделия Xeon 654 (18 ядер), Xeon 658X (24 ядра), Xeon 676X (32 ядра), Xeon 678X (48 ядер) и Xeon 696X (64 ядра). Материнские платы на чипсете W890 готовят такие компании, как ASUS, Supermicro и Gigabyte. Готовые системы на основе Xeon 600 предложат Dell, HP, Supermicro, Boxx, Pudget Systems и другие поставщики. Вместе с тем, как отмечает The Register, время для анонса Xeon 600 выбрано не совсем удачно. Чипы выходят на рынок на фоне проблем с цепочками поставок, из-за которых резко подскочили цены на память. Так, комплект из восьми модулей DDR5 RDIMM на 32 Гбайт каждый обойдётся более чем в $4000: это примерно на $1500 больше, чем шестью месяцами ранее. Сформировавшаяся ситуация может негативно отразиться на спросе на Xeon 600 среди потребителей.
16.01.2026 [23:14], Владимир Мироненко
NVIDIA добралась до RISC-V: NVLink Fusion пропишется в серверных процессорах SiFiveПродолжая укреплять свои лидирующие позиции на ИИ-рынке NVIDIA не скрывает стремления построить целую экосистему ИИ-платформ с привязкой к своим решениям. Эти усилия активизировались в прошлом году с анонсом технологии NVLink Fusion, позволяющей использовать NVLink в чипах сторонних производителей. Как стало известно, вслед за Arm, Intel и AWS, присоединившимися к программе в прошлом году, экосистема NVLink Fusion пополнилась первым поставщиком чипов на архитектуре RISC-V — компанией SiFive, которая объявила о планах внедрить NVLink Fusion в свои будущие чипы для ЦОД. SiFive отметила, что ИИ-вычисления вступают в фазу, когда архитектурная гибкость и энергоэффективность так же важны, как и пиковая пропускная способность. Нагрузки обучения и инференса растут быстрее, чем энергетические бюджеты, заставляя операторов ЦОД переосмыслить способы подключения и управления CPU, GPU и ASIC. Теперь производительность на Вт и эффективность перемещения данных стали первостепенными ограничениями при проектировании чипов. Патрик Литтл (Patrick Little), президент и генеральный директор SiFive заявил, что ИИ-инфраструктура больше не строится из универсальных компонентов, а разрабатывается совместно с нуля: «Интегрируя NVLink Fusion с высокопроизводительными вычислительными подсистемами SiFive, мы предоставляем клиентам открытую и настраиваемую платформу CPU, которая легко интегрируется с ИИ-инфраструктурой NVIDIA, обеспечивая исключительную эффективность в масштабах ЦОД». 
Источник изображения: SiFive Пресс-релиз SiFive не содержит каких-либо конкретных планов по продуктам, кроме сообщения о добавления поддержки NVLink к «высокопроизводительным решениям для ЦОД» SiFive. Предположительно, речь идёт о чипах платформы Vera Rubin или более поздних, т.е. о NVLink 6. Для SiFive — как поставщика IP-блоков RISC-V CPU — интерес заключается в использовании интерконнекта NVLink-C2C, который обеспечивает высокоскоростную, полностью кеш-когерентную связь между CPU и GPU, и это предпочтительный способ подключения к ускорителям NVIDIA в высокоинтегрированных системах. В рамках экосистемы NVLink Fusion NVIDIA предлагает NVLink-C2C в качестве лицензируемого IP-ядра, что упростит интеграцию шины в будущие чипы SiFive. Для SiFive это может стать конкурентным преимуществом. Кроме того, NVIDIA объявила о поддержке RISC-V — на эту архитектуру портируют CUDA и драйверы, что со временем откроет для компании новые рынки.
06.01.2026 [22:15], Владимир Мироненко
AMD анонсировала чипы Ryzen AI Embedded серий P100 и X100AMD представила процессоры AMD Ryzen AI Embedded серий P100 и X100, сочетающие высокопроизводительные ядра Zen 5, GPU RDNA 3.5 и NPU XDNA 2 для энергоэффективного ускорения ИИ. Процессоры серии P100 ориентированы на автомобильные решения и промышленную автоматизацию, а процессоры серии X100 с большим количеством ядер и повышенной ИИ-производительностью предназначены для более требовательных физических и автономных систем. Процессоры серии P100 с 4–6 ядрами, оптимизированные для цифровых кабин следующего поколения и HMI (человеко-машинных интерфейсов), обеспечивают рендеринг графики в реальном времени для автомобильных информационно-развлекательных дисплеев, взаимодействие на основе ИИ и быстродействие в многодоменных средах. Они обеспечивают до 2,2-кратное повышение производительности в многопоточных и однопоточных задачах по сравнению с предыдущим поколением. 
Источник изображений: AMD via ServeTheHome  Чипы P100 имеют диапазон TDP от 15 Вт до 54 Вт, поддерживают память LPDDR5X и выполнены в BGA-корпусе размером 25 × 40 мм (FP8). Новые чипы с поддержкой работы при температуре от –40 °C до +105 °C созданы для сложных условий эксплуатации в ограниченном пространстве, включая безвентиляторные или полузащищённые конструкции, и рассчитаны на 10 лет работы в режиме 24/7. Чипы поддерживают память DDR5-5600 (ECC) и LPDRR5x-7500/8000 (Link ECC), а также имеют поддержку двух 10GbE-интерфейсов и двух USB4-подключений.  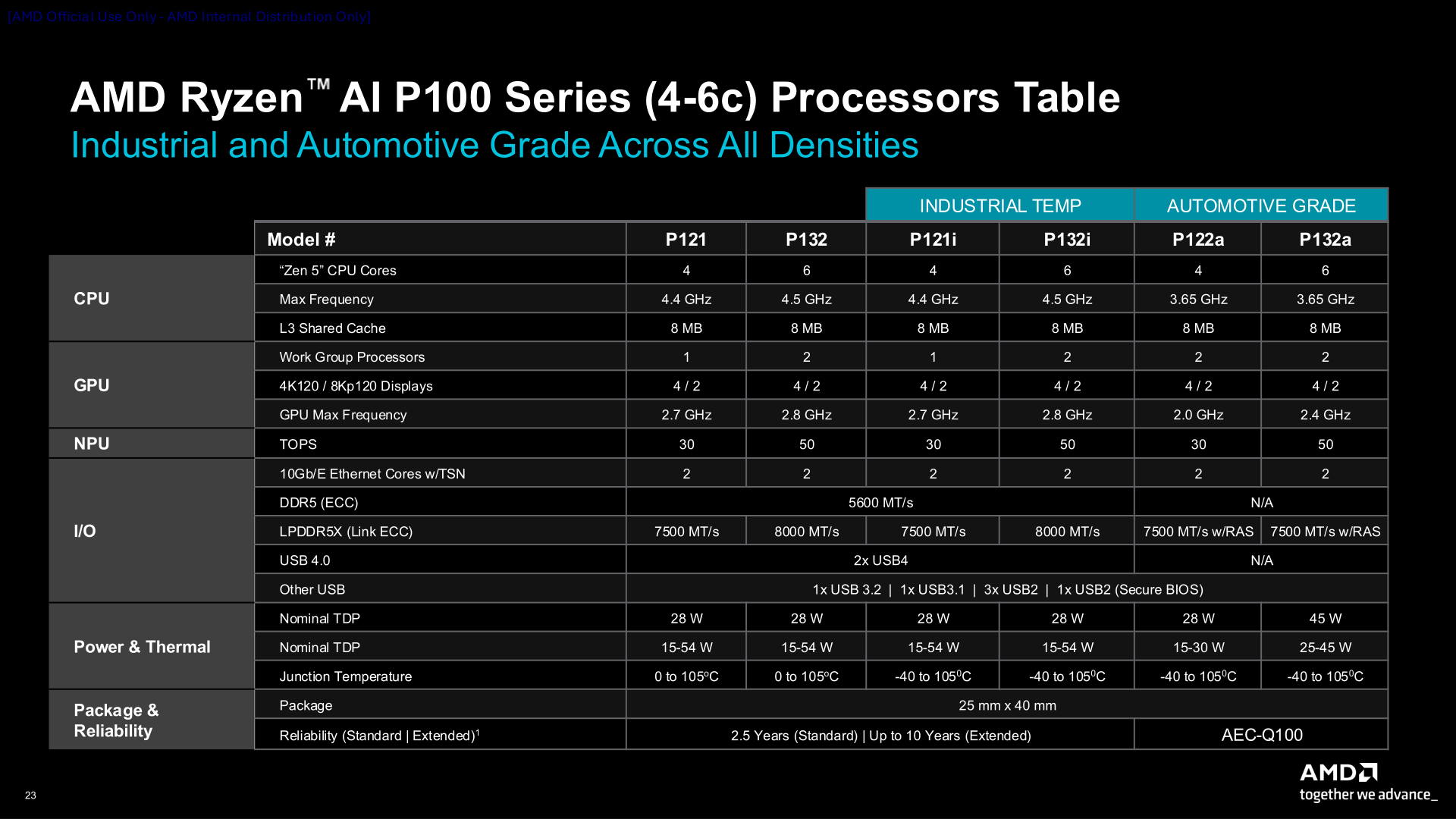 AMD утверждает, что серия P100 обеспечивает до трёх раз большую ИИ-производительность (AI TOPS) по сравнению с серией Ryzen Embedded 8000. Это имеет важное значение для клиентов, модернизирующих существующие системы для достижения более высокой производительности ИИ на Ватт и на плату в целом, отметил ресурс Storagereview. Помимо автомобильного применения компания также ориентирует свои процессоры на вещательное оборудование, промышленные ПК, киоски, медицинские устройства и даже аэрокосмическую отрасль.  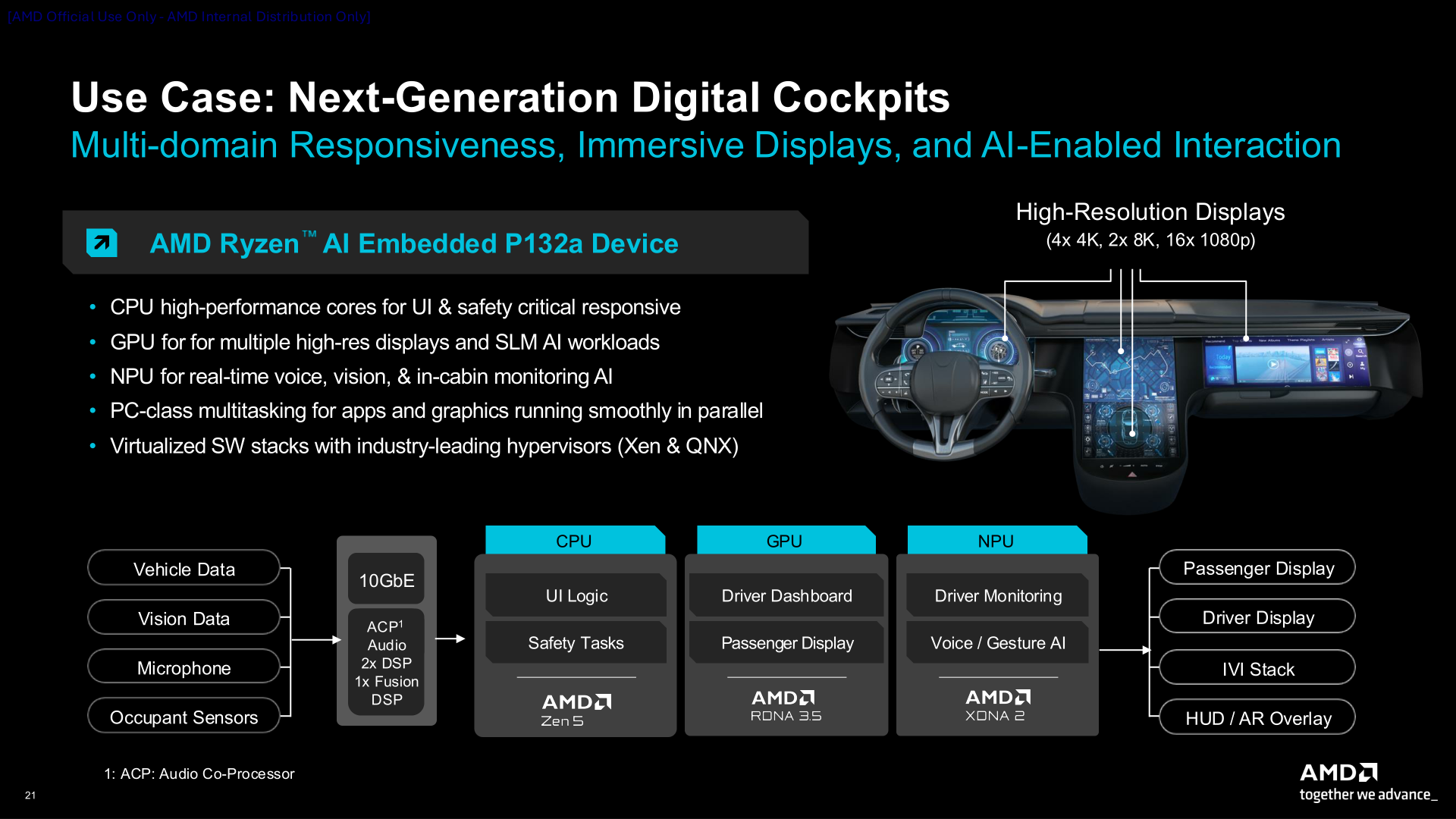 Процессоры Ryzen AI Embedded обеспечивают согласованную среду разработки с унифицированным программным стеком, охватывающим CPU, GPU и NPU. Разработчики получат преимущества от оптимизированных библиотек CPU, открытых стандартных API GPU и архитектуры XDNA. Весь программный стек построен на базе открытой платформы виртуализации Xen, которая обеспечивает безопасную изоляцию нескольких доменов. Это позволяет использовать Yocto или Ubuntu для HMI, FreeRTOS для задач реального времени и Android или Windows для поддержки многофункциональных приложений, которые безопасно работают параллельно. Процессоры AMD Ryzen AI Embedded P100 с 4–6 ядрами, а также инструменты разработки и документация уже доступны для ознакомления избранным клиентам. Начало серийного производства чипов намечено на II квартал, а референсные платы появятся во II половине 2026 года. Процессоры серии P100 с 8–12 ядрами, предназначенные для приложений промышленной автоматизации, начнут поставляться в I квартале. Предоставление образцов процессоров серии X100 с до 16 ядер начнётся в I половине этого года.
19.12.2025 [15:35], Игорь Осколков
Ишь какой «Иртыш»: анонсированы российские 64-ядерные серверные процессоры C664 на китайской архитектуре LoongArchРоссийская компания «Трамплин Электроникс» готовит отечественные 12-нм серверные процессоры «Иртыш» C616, C632 и C664 с 16, 32 и 64 ядрами LAA64 на китайской архитектуре LoongArch. Это последнее поколение ядер Loongson, которые используются в похожих по характеристикам процессорах серии 3C6000. Название CPU выбрано, по-видимому, неспроста, поскольку р. Иртыш берёт своё начало в Китае, а заканчивает свой путь в России. В данном случае ядра лицензированы, топология чипов собственная, имеется конструкторская и прочая документация, что вкупе позволяет записать «Иртыш» в отечественные микросхемы второго уровня. Кроме того, несмотря на уже имеющуюся относительно широкую поддержку LoongArch в популярных открытых проектах, включая ядро Linux и GCC, — в том числе благодаря стараниями и намерением Loongson сделать свою архитектуру третьей по популярности после x86 и Arm, — «Трамплин Электроникс» хочет развивать российское сообщество вокруг LoongArch и всячески популяризировать её, предоставляя техническую и методическую поддержку процессора на русском языке. Компания готовит технологическую ОС и SDK, весь базовый набор для разработки системного ПО, в том числе окружение для кросс-компиляции. 
Источник изображений: «Трамплин Электроникс» На данный момент «Трамплин Электроникс» разработала топологию и низкоскоростные ядра. В разработке находится модуль безопасности, а уже в I квартале следующего года компания намерена передать партнёрам первую партию инженерных образцов новых чипов. Процессоры будут выпускаться на «дружественной фабрике, которая не попадает под санкции», а их корпусировка пока будет производиться в Китае, но со временем этот этап может быть перенесён на территорию РФ. Параллельно компания занимается референсным дизайном плат, в первую очередь для серверов, СХД и т.п., на которые и ориентированы первые чипы.  Собственно LA664 являются 64-бит суперскалярными двухпоточными (SMT2) ядрами с внеочередным исполнением и возможностью обработки до шести инструкций за такт. Каждое ядро содержит четыре целочисленных блока, четыре блока векторных операций (128/256 бит), четыре модуля генерации адресов для доступа к памяти и аппаратный ускоритель фирменных китайских алгоритмов шифрования SM2/3/4. Объём L1i- и L1d-кеша составляет 64 Кбайт, L2-кеша — 256 Кбайт. L3-кеш общий для всех ядер и размер его неизменно составляет 32 Мбайт на чиплет. В UEFI Tianocore EDK2 имеется поддержка Loongarch, так что именно «Трамплин Электроникс» и будет дорабатывать. 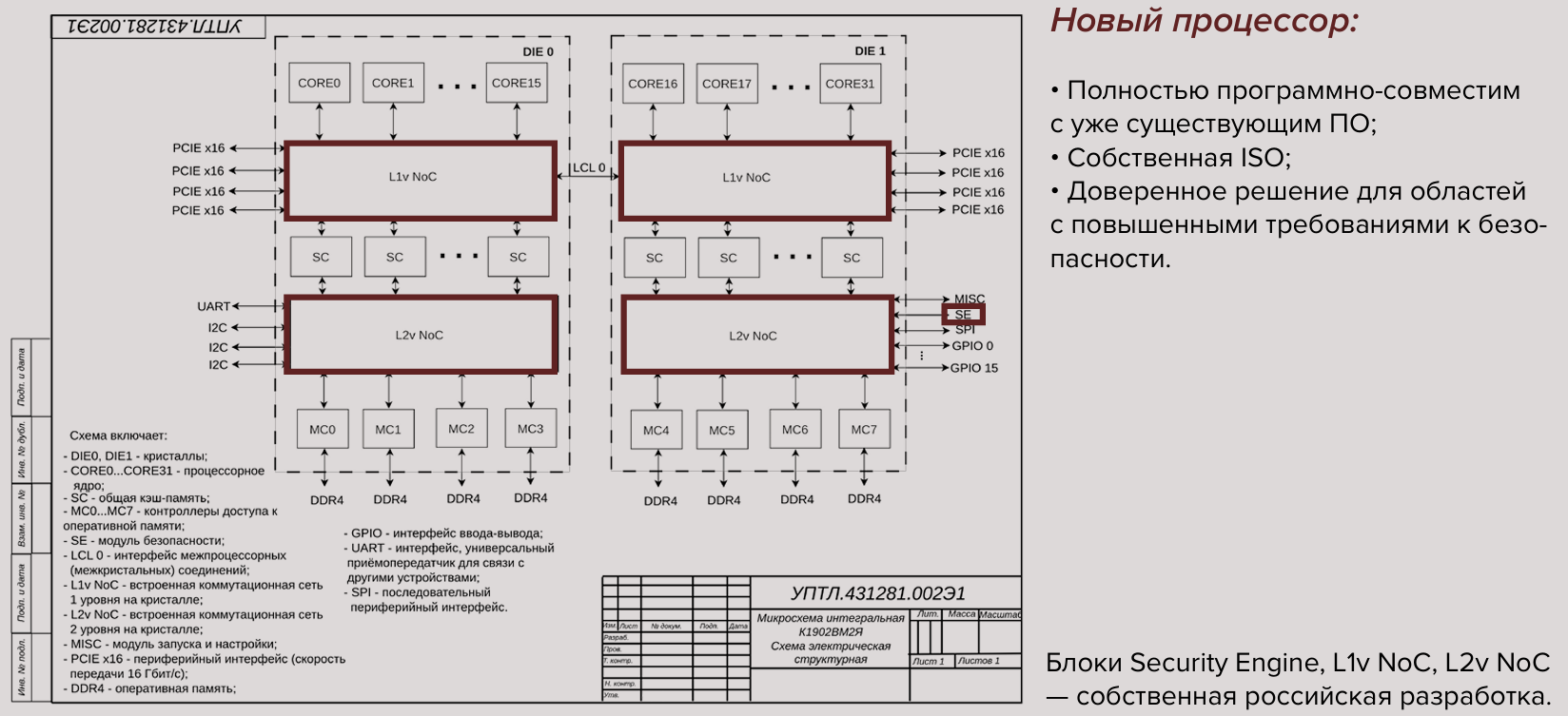 Самый младший процессор «Иртыш» C616 (К1902ВМ1Я) как раз и состоит из одного чиплета с 16 ядрами (16C/32T) на борту и четырьмя каналами памяти DDR4-3200 ECC (до 256 Гбайт), дополненных сопроцессором безопасности на ядре LA264 (Loongson SE). Высокоскоростные интерфейсы включают межпроцессорную когерентную шину DragonChain и 64 линии PCIe 4.0 (четыре x16), низкоскоростные интерфейсы представлены традиционными SPI, UART, S2C, GPIO. При TDP на уровне 100–120 Вт и пиковой частотой 2,2 ГГц (есть динамическое управление питанием и частотой) заявленный уровень FP64-производительности составляет 844,8 Гфлопс.  «Иртыш» C632 (К1902ВМ2Я) состоит из двух чиплетов, включает 32 ядра (32C/64T), 128 линий PCIe 4.0, восемь каналов DDR4-3200 ECC (до 1 Тбайт) и имеет TDP 180–200 Вт. При пиковой частоте 2,1 ГГц его быстродействие составляет до 1612,8 Гфлопс. Наконец, «Иртыш» C664 (К1902ВМ3Я) состоит из четырёх чиплетов, включает 64 ядра (64C/128T), имеет TDP 250–300 Вт, а при пиковой частоте 2 ГГц он «выдаёт» до 3072 Гфлопс. Количество каналов памяти и PCIe-линий у него такое же, как у C632. С C616 и C632 возможно формирование 1S, 2S- и 4S-систем, с C664 — только 1S и 2S. 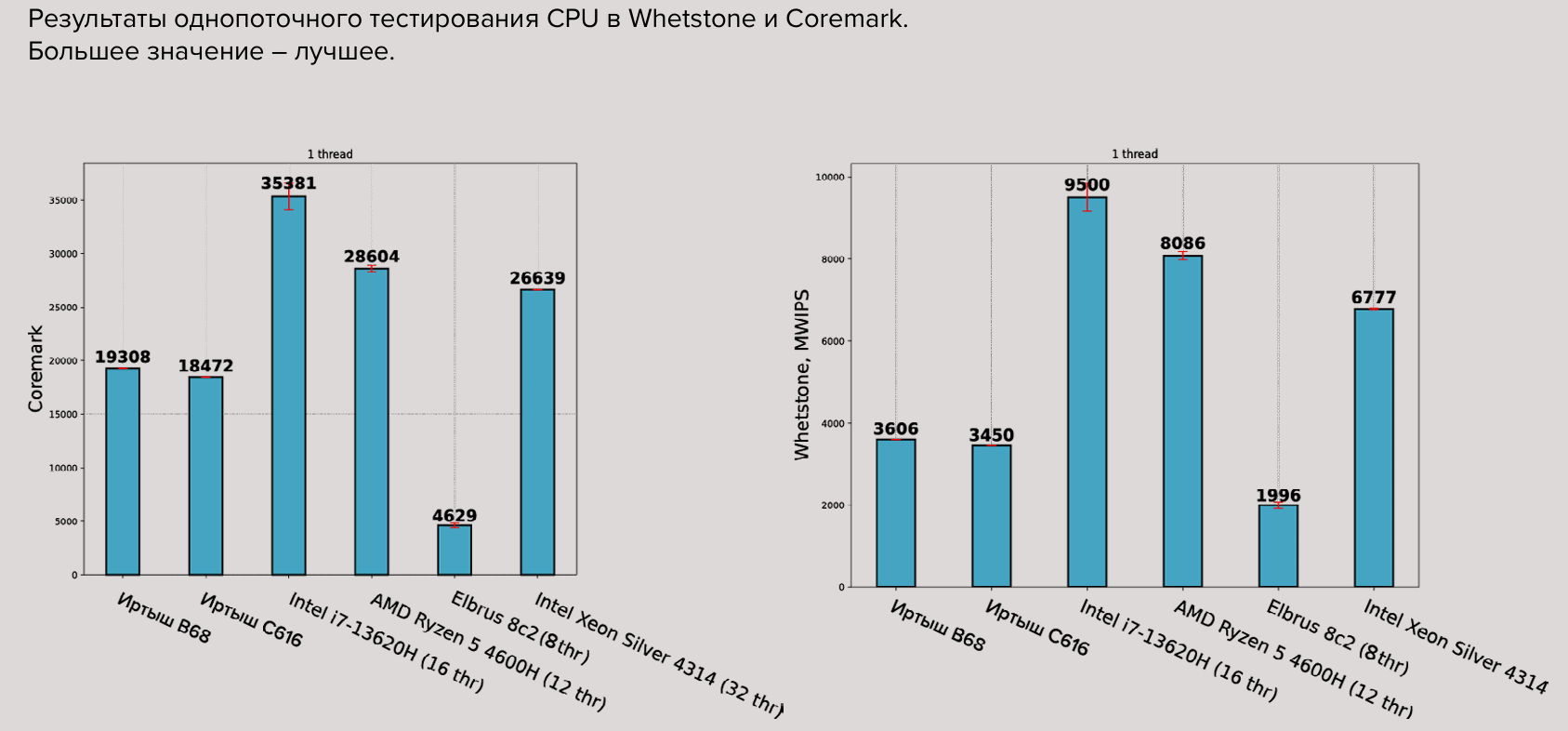 Приведённые характеристики являются предварительными и фактически совпадают с таковыми у Loongson 3C6000 серий S, D и Q соответственно, хотя NoC, связывающая компоненты заявляется как собственная разработка «Трамплин Электроникс». Также утверждается, что «Иртыш» C616, C632 и C664 сравнимы с Intel Xeon Ice Lake-SP Silver 4314, Gold 6338 и Platinum 8380 соответственно (или с их аналогами поколения AMD EPYC Milan). В ноябре «Трамплин Электроникс» совместно с «АСКОН» анонсировали создание первого отечественного ПАК на базе CPU «Иртыш» при участии «Норси-Транс». Ранее «АСКОН» уже портировала свою систему проектирования КОМПАС-3D на процессоры Loongson, а «Базальт СПО» адаптировала ОС «Альт» под архитектуру LoongArch64. Также для LoongArch были сборки ОС «РОСА». |
|


