Материалы по тегу: intel
|
19.08.2021 [16:00], Игорь Осколков
Intel представила Xeon Sapphire Rapids: четырёхкристалльная SoC, HBM-память, новые инструкции и ускорителиВ рамках Architecture Day компания Intel рассказала о грядущих серверных процессорах Sapphire Rapids, подтвердив большую часть опубликованной ранее информации и дополнив её некоторыми деталями. Intel позиционирует новинки как решение для более широкого круга задач и рабочих нагрузок, чем прежде, включая и популярные ныне микросервисы, контейнеризацию и виртуализацию. Компания обещает, что CPU будут сбалансированы с точки зрения вычислений, работой с памятью и I/O. Новые процессоры, наконец, получили чиплетную, или тайловую в терминологии Intel, компоновку — в состав SoC входят четыре «ядерных» тайла на техпроцессе Intel 7 (10 нм Enhanced SuperFIN). Каждый тайл объединён с соседом посредством EMIB. Их системные агенты, включающие общий на всех L3-кеш объём до 100+ Мбайт, образуют быструю mesh-сеть с задержкой порядка 4-8 нс в одну сторону. Со стороны процессор будет «казаться» монолитным.  Каждые ядро или поток будут иметь свободный доступ ко всем ресурсам соседних тайлов, включая кеш, память, ускорители и IO-блоки. Потенциально такой подход более выгоден с точки зрения внутреннего обмена данными, чем в случае AMD с общим IO-блоком для всех чиплетов, которых в будущих EPYC будет уже 12. Но как оно будет на самом деле, мы узнаем только в следующем году — выход Sapphire Rapids запланирован на первый квартал 2022-го, а массовое производство будет уже во втором квартале.  Ядра Sapphire Rapids базируются на микроархитектуре Golden Cove, которая стала шире, глубже и «умнее». Она же будет использована в высокопроизводительных ядрах Alder Lake, но в случае серверных процессоров есть некоторые отличия. Например, увеличенный до 2 Мбайт на ядро объём L2-кеша или новый набор инструкций AMX (Advanced Matrix Extension). Последний расширяет ИИ-функциональность CPU и позволяет проводить MAC-операции над матрицами, что характерно для такого рода нагрузок.  Для AMX заведено восемь выделенных 2D-регистров объёмом по 1 Кбайт каждый (шестнадцать 64-байт строк). Отдельный аппаратный блок выполняет MAC-операции над тремя регистрами, причём делаться это может параллельно с исполнением других инструкций в остальной части ядра. Настройкой параметров и содержимого регистров, а также перемещением данных занимается ОС. Пока что в процессорах представлен только MAC-блок, но в будущем могут появиться блоки и для других, более сложных операций. 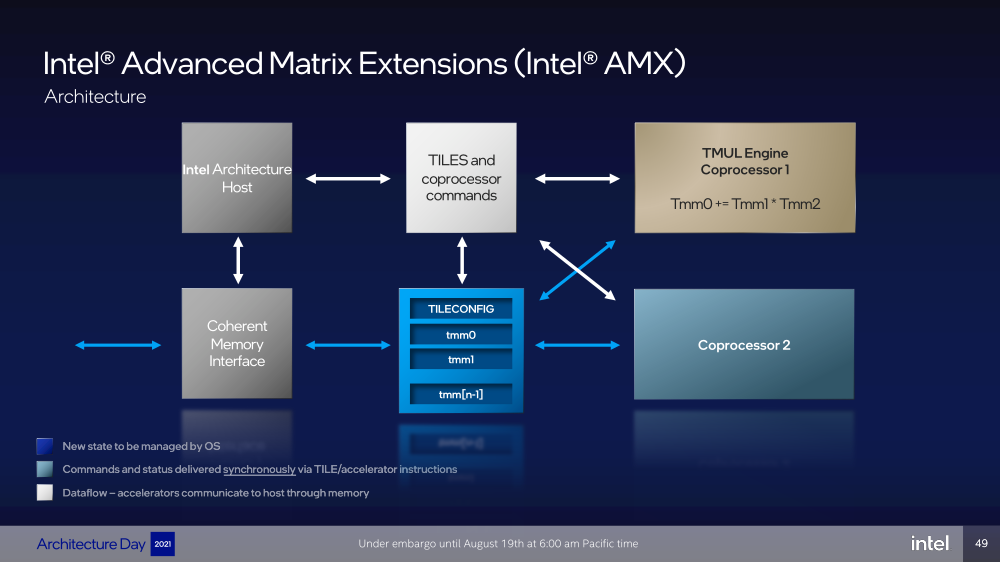 В пике производительность AMX на INT8 составляет 2048 операций на цикл на ядро, что в восемь раз больше, чем при использовании традиционных инструкций AVX-512 (на двух FMA-портах). На BF16 производительность AMX вдвое ниже, но это всё равно существенный прирост по сравнению с прошлым поколением Xeon — Intel всё так же пытается создать универсальные ядра, которые справлялись бы не только с инференсом, но и с обучением ИИ-моделей. Тем не менее, компания говорит, что возможности AMX в CPU будут дополнять GPU, а не напрямую конкурировать с ними.  К слову, именно Sapphire Rapids должен, наконец, сделать BF16 более массовым, поскольку Cooper Lake, где поддержка этого формата данных впервые появилась в CPU Intel, имеет довольно узкую нишу применения. Из прочих архитектурных обновлений можно отметить поддержку FP16 для AVX-512, инструкции для быстрого сложения (FADD) и более эффективного управления данными в иерархии кешей (CLDEMOTE), целый ряд новых инструкций и прерываний для работы с памятью и TLB для виртуальных машин (ВМ), расширенную телеметрию с микросекундными отсчётами и так далее.  Последние пункты, в целом, нужны для более эффективного и интеллектуального управления ресурсами и QoS для процессов, контейнеров и ВМ — все они так или иначе снижают накладные расходы. Ещё больше ускоряют работу выделенные акселераторы. Пока упомянуты только два. Первый, DSA (Data Streaming Accelerator), ускоряет перемещение и передачу данных как в рамках одного хоста, так и между несколькими хостами. Это полезно при работе с памятью, хранилищем, сетевым трафиком и виртуализацией. 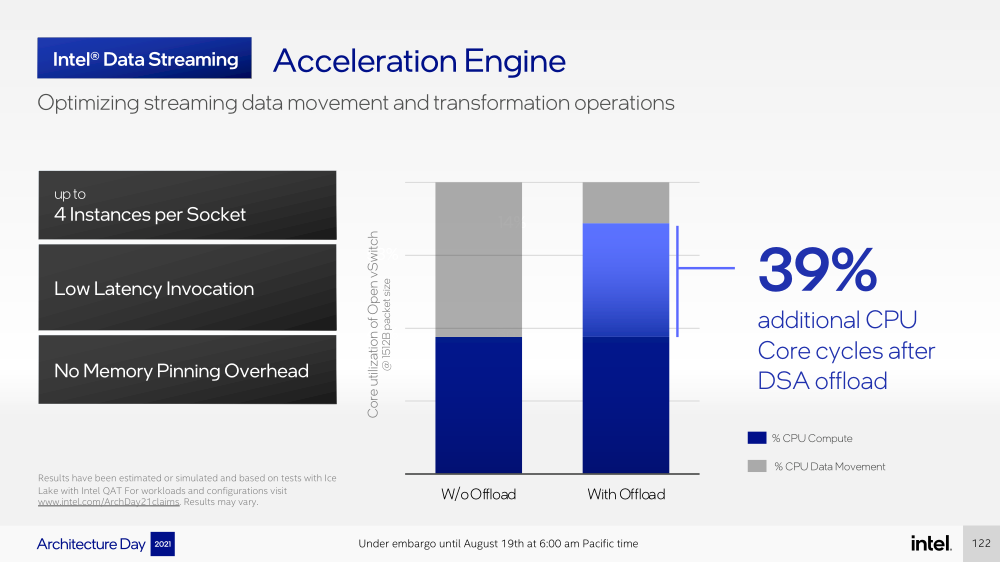 Второй упомянутый ускоритель — это движок QAT (Quick Assist Engine), на который можно возложить операции или сразу цепочки операций (де-)компрессии (до 160 Гбит/с в обе стороны одновременно), хеширования и шифрования (до 400 Гбитс/с) в популярных алгоритмах: AES GCM/XTS, ChaChaPoly, DH, ECC и т.д. Теперь блок QAT стал частью самого процессора, тогда как прежде он был доступен в составе некоторых чипсетов или в виде отдельной карты расширения. Это позволило снизить задержки и увеличить производительность блока. 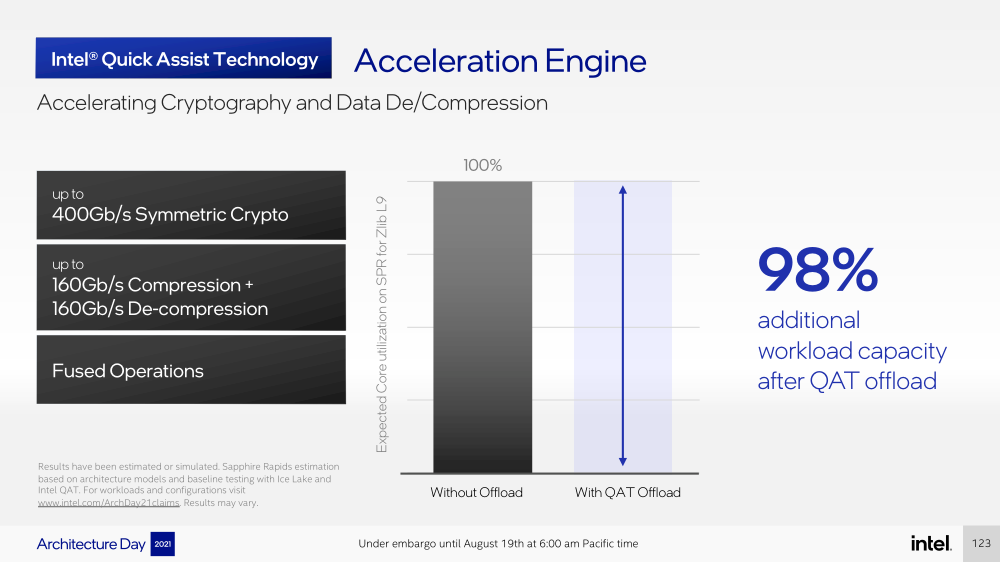 Кроме того, QAT можно будет задействовать, например, для виртуализации или Intel Accelerator Interfacing Architecture (AiA). AiA — это ещё один новый набор инструкций, предназначенный для более эффективной работы с интегрированными и дискретными ускорителями. AiA помогает с управлением, синхронизацией и сигнализацией, что опять таки позволит снизить часть накладных расходов при взаимодействии с ускорителями из пространства пользователя. 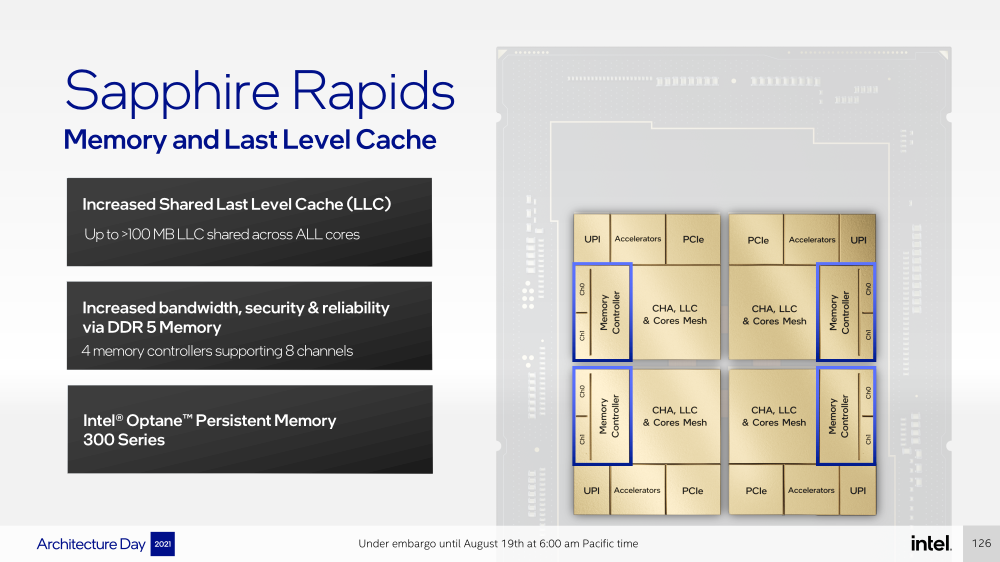 Подсистема памяти включает четыре двухканальных контроллера DDR5, по одному на каждый тайл. Надо полагать, что будут доступные четыре же NUMA-домена. Больше деталей, если не считать упомянутой поддержки следующего поколения Intel Optane PMem 300 (Crow Pass), предоставлено не было. Зато было официально подтверждено наличие моделей с набортной HBM, тоже по одному модулю на тайл. HBM может использоваться как в качестве кеша для DRAM, так и независимо. В некоторых случаях можно будет обойтись вообще без DRAM. 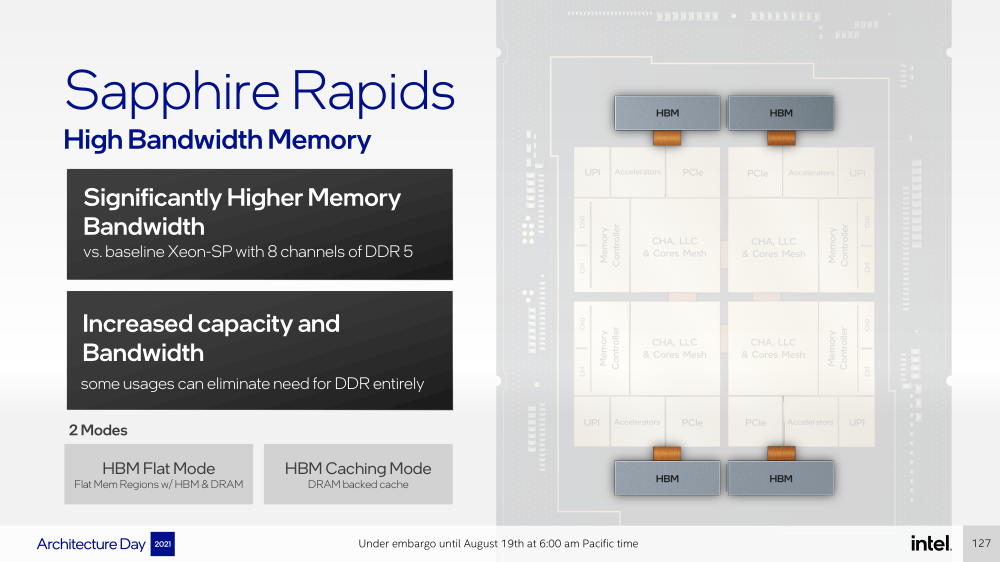 Про PCIe 5.0 и CXL 1.1 (CXL.io, CXL.cache, CXL.memory) добавить нечего, хотя в рамках другого доклада Intel ясно дала понять, что делает ставку на CXL в качестве интерконнекта не только внутри одного узла, но и в перспективе на уровне стойки. Для объединения CPU (бесшовно вплоть до 8S) всё так же будет использоваться шина UPI, но уже второго поколения (16 ГТ/с на линию) — по 24 линии на каждый тайл. 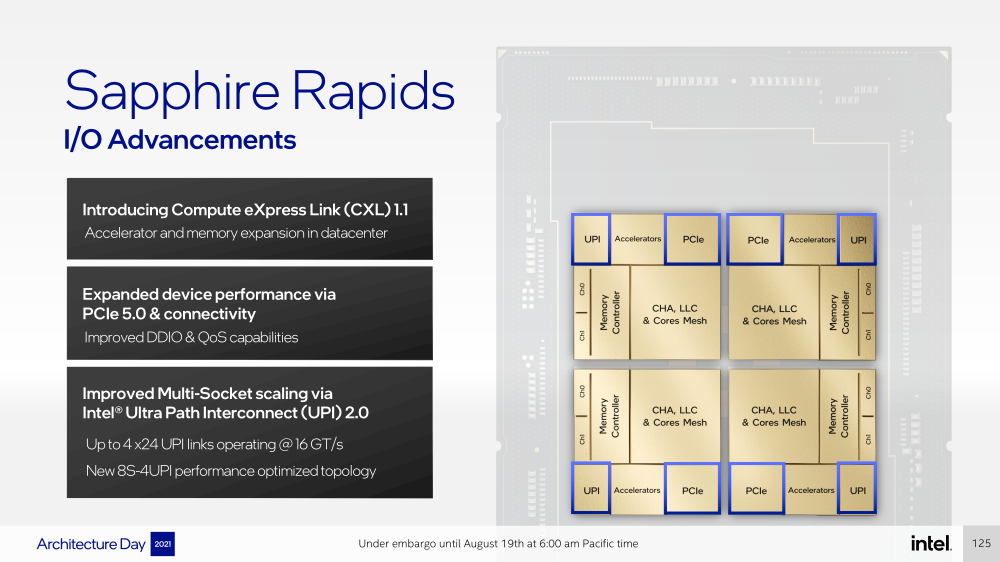 Конкретно для Sapphire Rapids Intel пока не приводит точные данные о росте IPC в сравнении с Ice Lake-SP, ограничиваясь лишь отдельными цифрами в некоторых задачах и областях. Также не был указан и ряд других важных параметров. Однако AMD EPYC Genoa, если верить последним утечкам, даже по чисто количественным характеристикам заметно опережает Sapphire Rapids.
30.07.2021 [21:05], Алексей Степин
Конец эпохи: Intel окончательно прекратила поставки процессоров ItaniumПервая попытка Intel покорить рынок массовых 64-бит систем окончилась неудачей — любопытная сама по себе архитектура Itanium (IA64) была несовместима со сложившейся экосистемой x86. Однако лишь сегодня в истории можно окончательно поставить точку: компания прекратила последние отгрузки процессоров Itanium. Сейчас поддержка 64-бит вычислений привычна и является частью любого достаточно современного процессора. Но так было не всегда: в конце 90-х и начале 2000-х ограничения, накладываемые 32-бит разрядностью хотя и были очевидны, рынок высокопроизводительных 64-бит процессоров для серверов и рабочих станций принадлежал компаниям Sun, Silicon Graphics, DEC и IBM. Все они имели RISC-архитектуру и не имели совместимости с x86. 
Форм-фактор Itanium: нечто среднее между слотовыми Pentium II/III и привычным PGA/LGA Itanium, или IA64, совместная разработка Intel и Hewlett-Packard, должна была вернуть этим компаниям первенство в сфере мощных CPU. И ставка была сделана на уникальную архитектуру EPIC (разновидность VLIW) с явным параллелизмом команд. Сама по себе IA64 обладала рядом преимуществ, однако требовала тонкой проработки ПО на уровне компилятора, поскольку процессоры EPIC во многом полагаются именно на него, а не на аппаратный планировщик. 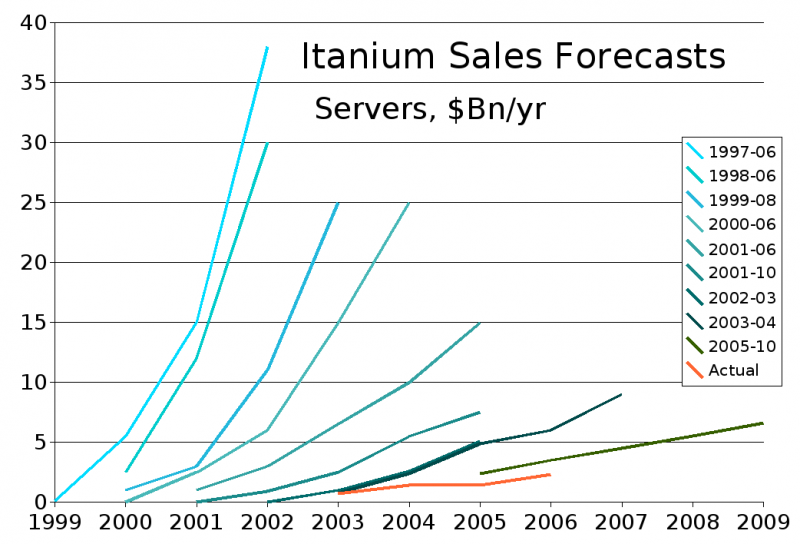
Itanium: радужные надежды и суровая реальность (красная линия) Отказ от последнего позволял потратить освободившийся транзисторный бюджет на более важные, по мнению Intel и HP, цели — например, на увеличение производительности вычислений с плавающей запятой. Но инфраструктура программного обеспечения к моменту анонса Itanium уже была весьма развитой. При этом новое, 64-бит ПО ещё надо было создать и, что гораздо важнее и сложнее, правильным образом оптимизировать, а уже имевшееся на новых CPU работало медленно из-за необходимости эмуляции x86. Компании пытались развивать IA64 до 2017 года, когда были представлены чипы Itanium Kittson с 8 ядрами и частотой до 2,66 ГГц, но то, что затея с новой архитектурой оказалась неудачной, было понятно уже после анонса первых процессоров AMD x86-64, полностью совместимых как с 32-бит, так и с 64-бит приложениями x86. В начале 2021 года Линус Торвальдс объявил о фактической смерти архитектуры и поддержка IA64 была исключена из новых ядер Linux. А сегодня можно говорить об окончательном завершении эры Itanium. 
Раритет: Supermicro i2DML-iG2 в форм-факторе EATX с поддержкой Itanium 2. Найти такую плату почти невозможно Сама Intel ещё в 2019-ом официально поставила на Itanium крест, но из-за сложившейся экосистемы заказы на процессоры принимались вплоть до 30 января 2020 года. А вчера компания официально объявила о прекращении поставок последних партий Itanium. Теперь ещё одна процессорная архитектура стала достоянием истории, хотя HPE формально будет поддерживать её до 2025 года. Сами CPU нередко встречаются на онлайн-аукционах, например, на Ebay, но даже для энтузиастов они малоинтересны — найти подходящую системную плату невероятно сложно, а стоить она может намного дороже самих процессоров, да и форм-фактор имеет специфический.
23.02.2021 [22:23], Андрей Галадей
Вышло обновление ZLUDA v2, открытой реализации CUDA для GPU IntelРанее мы уже писали об экспериментальнои проекте ZLUDA, развивающем открытую реализацию CUDA для GPU Intel, которая позволила бы нативно исполнять CUDA-приложения на ускорителях Intel без каких-либо модификаций. При этом её разработка ведётся независимо и от Intel, и от NVIDIA. Новинка построена на базе интерфейса Intel oneAPI Level Zero, и может работать на картах Intel UHD/Xe с неплохим уровнем производительности. Однако у первой версии был ряд ограничений. Вчера же вышла вторая версия, которая получила ряд улучшений. Кроме того, автор проекта объявил о переходе на модель непрерывного выпуска релизов.  Основной упор в новой версии сделан на улучшение поддержки Geekbench и работы в Windows-окружении. Собственно говоря, автор прямо говорит, что оптимизация под Geekbench пока является основной целью, а другие CUDA-приложения могут не работать. Кроме того, такое ПО, запущенное с помощью ZLUDA будет работать медленнее, чем на картах NVIDIA, в силу разности архитектур GPU и необходимости эмуляции некоторых возможностей. Подробности приведены на странице проекта.
29.01.2021 [17:17], Андрей Галадей
Itanium забыт и заброшен: Линус Торвальдс констатировал смерть архитектурыОдной из проблем и в то же время достоинств Linux является поддержка многих старых архитектур процессоров. Это увеличивает размеры ядра и усложняет сопровождение. Но теперь, похоже, на одну архитектуру станет меньше. В ядре Linux 5.11, как выяснилось, оказалась нарушена поддержка Itanium IA-64. После исправления выяснилось, что это не единственная проблема такого рода, однако истинную причину выяснить не удалось из-за отсутствия доступа к «железу». Так что Линус Торвальдс (Linus Torvalds) в итоге принял решение пометить данную архитектуру как orphaned, то есть заброшенную, и прямо заявил, что она мертва. А это первый шаг к полному исключению её из ядра, как это уже случилось с другим продуктом Intel — Xeon Phi. 
Изображения: wikipedia.org Два последних крупных игрока на рынке Itanium-систем — сама Intel и её клиент HPE — уже давно забросили поддержку этой архитектуры в Linux, да и энтузиасты к ней охладели. И это объяснимо. Последнее поколение Itanium 9700 Kittson вышло в 2017 году, а приём заказов на них прекратился год назад. Поставки формально будут свёрнуты 29 июля 2021 года, но эти CPU с высокой степенью вероятности практически никто не закупил хоть в сколько-то значимых объёмах. 
Несбывшиеся надежды В дистрибутивах же поддержку процессоров убрали давно. Red Hat не поддерживает чипы с RHEL 5, SUSE перестала поддерживать после SUSE Linux 11. Так что теперь поддержка будет осуществляться лишь теми компаниями, которые явно заинтересованы в этом. Разумеется, если такие остались. В своё время спор между Oracle и HPE подорвал репутацию платформы. Впрочем, Linux не является единственным вариантом — поддержка HP-UX, наследника классических UNIX, версии 11i v3 для ряда продуктов HPE будет осуществляться до 31 декабря 2025. Аналогичная ситуация сложилась и вокруг SPARC c Solaris, так как большую часть разработчиков обоих продуктов Oracle уволила ещё в 2017 году. Oracle обязалась сопровождать Solaris 11 максимум до 2034 года. В частности, на днях она выпустила патч безопасности для sudo и восстановила некоторые старые материалы. Однако Solaris 12 мы вряд ли когда-либо увидим. Сейчас компании гораздо более интересны облака, Linux и Arm-процессоры Ampere.
24.11.2020 [18:54], Игорь Осколков
«ВКонтакте» использует FPGA Intel Arria для обработки изображений на летуГод назад на Intel Experience Day 2019 «ВКонтакте» поделилась результатами первых экспериментов по использованию FPGA-ускорителей для обработки изображений на лету. За прошедшее время компания внедрила ПЛИС в свою инфраструктуру, ускорив работу и сэкономив место в хранилище, где уже находится 1,2 Эбайта различного контента. У «ВКонтакте» почти 100 млн активных пользователей, которые ежеминутно загружают порядка 100 Гбайт изображений. Для каждого из них после загрузки генерируется более десятка копий различных формата и размера, которые используются в разных частях социальной сети. Основная проблема в том, что на таких масштабах все эти дополнительные изображения отъедают очень много места — до двух третей от общего объёма. 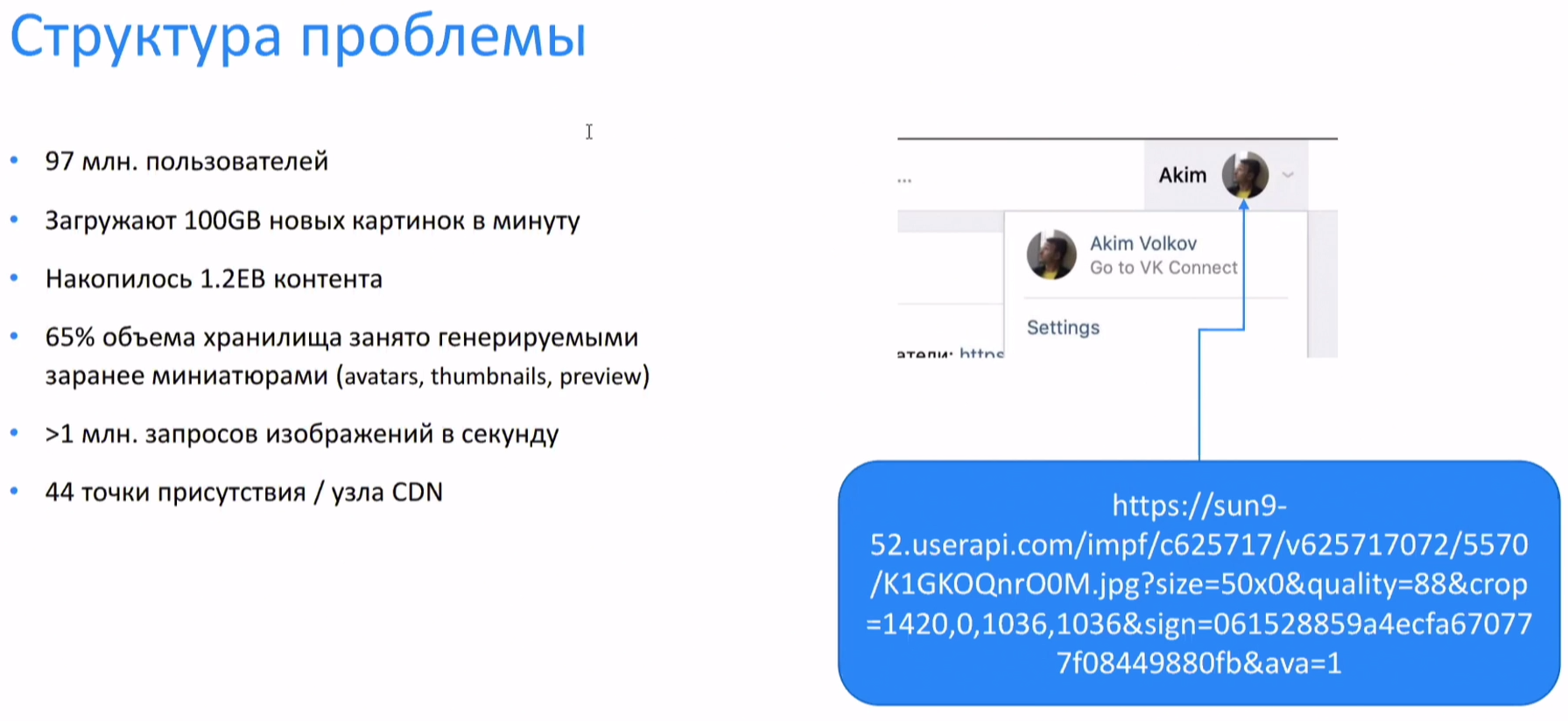 Оптимальнее было бы генерировать их на лету, однако это очень существенная вычислительная нагрузка. Тестовые машины с Intel Xeon E5-2620 v4, которые на тот момент составляли значительную часть серверного парка, могли обработать до 200-220 изображений в секунду, чего явно было недостаточно. Поэтому и было принято решение попробовать для решения этой задачи FPGA, в данном случае это Arria 10. 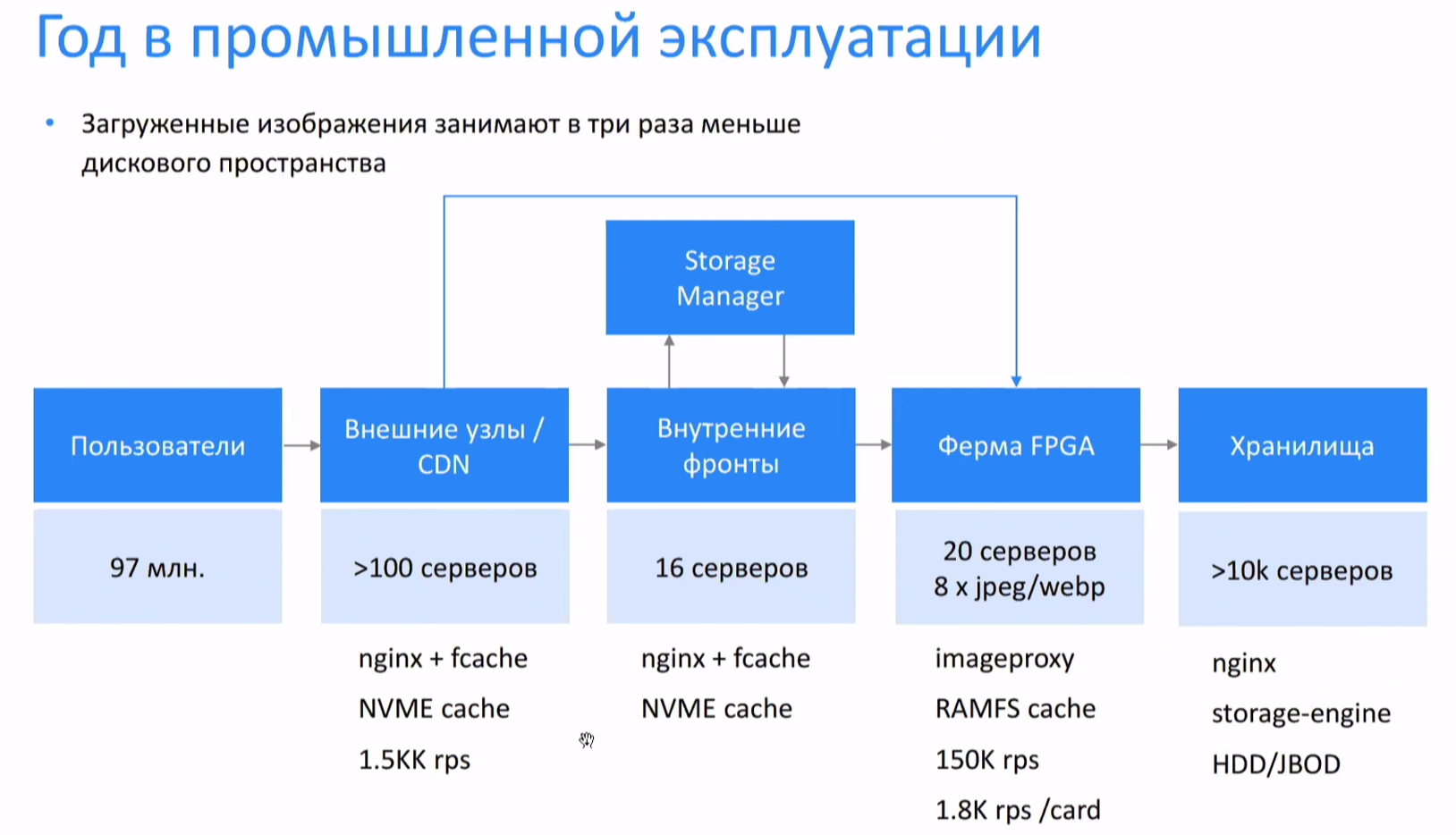 Теперь изображения с нужными характеристиками можно сформировать, указав параметры в URL. Если оно уже не закешировано на одной из конечных точек для отдачи контента, то запрос уходит «вниз» и из хранилища (а это более 10 тыс. серверов) извлекается оригинал и отправляется на FPGA-ферму, которая состоит всего из 20 серверов с ПЛИС, которых достаточно для удовлетворения всех запросов. На FPGA изображения конвертируются и отправляются «наверх», где кешируются и отдаются клиенту. Основными форматами, с которыми работает FPGA-ферма, являются JPEG и WebP, но компания рассматривает и другие, более современные. Кроме того, VK планирует изучить возможности FPGA для декодирования медиафайлов, сжатия данных (zstd) со стороны хранилища, а также опробовать в деле более современные модели ПЛИС.
02.11.2020 [17:56], Илья Коваль
Прощание с Xeon Phi: ядро Linux лишится поддержки MIC-архитектурыФинальная партия Intel Xeon Phi была отгружена летом этого года, хотя сам закат продуктов на базе архитектуры MIC (Many Integrated Core) начался за несколько лет до этого. Теперь же можно сказать, что в их истории поставлена последняя точка — из основной ветки ядра Linux 5.10 поддержка этих процессоров убрана уже в rc2. В ядре Linux поддержка MIC появилась в 2013 году, и Intel очень активно развивала её, почти втрое увеличив объём кодовой базы. Однако в последние годы развитие прекратилось и код остался фактически заброшенным. Связано это, понятное дело, с уходом ускорителей с рынка, где они не стали массовыми, проиграв конкуренцию NVIDIA как в HPC, так и в остальных сегментах.  Intel последовательно отменила выпуск следующего поколения MIC и продуктов всех прошлых поколений Xeon Phi, переключившись на создание универсальной архитектуры GPU. HPC-ускорители на её базе должны появиться в скором времени. Шине Intel Omni-Path, которая была непосредственно интегрирована в некоторые поздние модели Xeon Phi, повезло больше — после отказа Intel разработки были переданы свежесозданной Cornelis Networks. Тем не менее, кое-какое наследие MIC в ядре всё же может сохраниться. Речь идёт подсистеме VOP (VirtIO over PCIe), которая решает некоторые проблемы виртуализации PCI Express и для устройств других вендоров. Однако в текущем она ориентирована только на поддержку продуктов и драйверов Intel, и сможет вернуться в ядро Linux лишь после доработки.
16.10.2020 [23:17], Юрий Поздеев
DPU в стиле Intel: сетевые адаптеры с Xeon D, FPGA, HBM и SSDМир сетевых карт становится умнее. Это следующий шаг в дезагрегации ресурсов центров обработки данных. Наличие расширенных возможностей сетевых карт позволяет разгрузить центральный процессор, при этом специализированные сетевые адаптеры обеспечивают более совершенные функции и безопасность. В этой новости мы познакомим вас сразу с двумя адаптерами: Silicom SmartNIC N5010 и Inventec SmartNIC C5020X. Silicom FPGA SmartNIC N5010 предназначена для систем крупных коммуникационных провайдеров. Операторы все чаще стремятся заменить проприетарные форм-факторы от поставщиков телекоммуникационного оборудования на более стандартные варианты. В рамках этого мы видим, что производители ПЛИС не прочи освоить и эту нишу.  В Silicom FPGA SmartNIC N5010 используется Intel Stratix 10 DX с 8 Гбайт памяти HBM. Поскольку пропускная способность памяти становится все большим аспектом производительности системы, HBM будет продолжать распространяться за пределы графических процессоров и FPGA. В SmartNIC и DPU память HBM может использоваться для размещения индексных таблиц поиска и других функций для интенсивных сетевых нагрузок. Помимо HBM SmartNIC N5010 имеет еще 32 Гбайт памяти DDR4 ECC. SmartNIC N5010 потребляет до 225 Вт, что предполагает несколько вариантов исполнения карты, в том числе и с активным охлаждением.  Самая интересная особенность новой карты — 4 сетевых порта по 100 Гбит/с. На плате SmartNIC N5010 установлены две базовые сетевые карты Intel E810 (Columbiaville). На приведенной схеме можно заметить, что используется интерфейс PCIe Gen4 x16, причем их тут сразу два. Для работы четырех 100GbE-портов уже недостаточно одного интерфейса PCIe 4.0 x16. Второй порт PCIe 4.0 x16 может быть подключен через дополнительный кабель к линиям второго процессора, чтобы избежать межпроцессорного взаимодействия для передачи данных.  Вторая новинка, Inventec FPGA SmartNIC C5020X, совмещает на одной плате процессор Intel Xeon D и FPGA Intel Stratix 10. Этот адаптер предназначен для разгрузки центрального процессора в серверах крупных облачных провайдеров. На плате установлен процессор Intel Xeon D-1612 с 32-Гбайт SSD и 16 Гбайт DDR4, подключение к ПЛИС Intel Stratix 10 DX 1100 осуществляется через PCIe 3.0 x8. Нужно отметить, что FPGA Stratix имеет свои собственные 16 Гбайт памяти DDR4, а также обеспечивает сетевые подключения 25/50 Гбит/с и оснащен интерфейсом PCIe 4.0 x8, через который адаптер подключается к хосту. 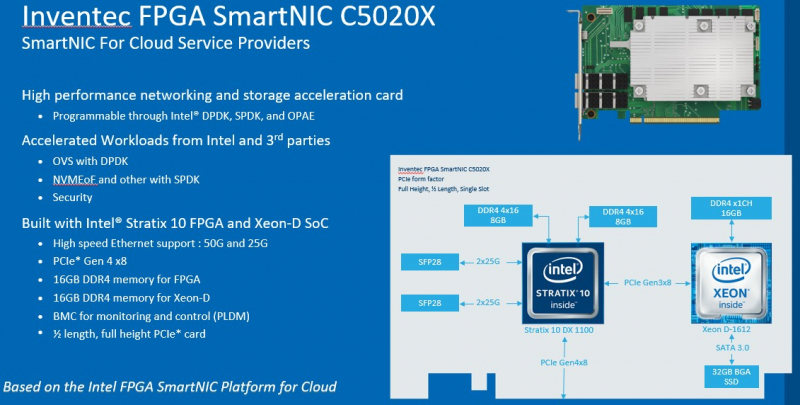 У Inventec уже есть решение на базе Arm (Inventec X250), которое использует ПЛИС Arria 10 GX660 вместе с сетевым адаптером Broadcom Stingray BCM8804, которое имеет аналогичный форм-фактор и TPD не более 75 Вт. Однако для некоторых организаций наличие единой x86 платформы, включая SmartNIC, упрощает развертывание, поэтому вариант C5020X для таких компаний более предпочтителен. Решение получилось очень интересным, однако вряд ли его можно назвать адаптером для массового рынка, как Intel Columbiaville. На примере этого адаптера Intel показала, что может объединить элементы своего портфеля для создания комплексных решений. Inventec FPGA SmartNIC C5020X является хорошей альтернативой предложению на базе Broadcom, что позволит крупным облачным провайдерам диверсифицировать свои платформы.  Несмотря на то, что обе новинки классифицируются как «умные» сетевые адаптеры SmartNIC, вторая, пожалуй, уже ближе к DPU, если сравнивать её с адаптерами NVIDIA DPU, в которых сетевая часть дополнена Arm-процессором и GPU-ускорителем. В данном случае есть и x86-ядра общего назначения, и ускоритель, хотя и на базе ПЛИС. Впрочем, устоявшегося определения DPU и списка критериев соответствия этому классу процессоров пока нет.
23.09.2020 [16:00], Алексей Степин
Intel представила новые 10-нм индустриальные процессоры: от Atom x6000E до Core i7 Tiger LakeНа мероприятии Intel Industrial Summit компания показала новые решения для периферийных вычислений и промышленных систем: платформу Atom x6000E, а также новые процессоры Pentium и Celeron серий N/J и индустриальные версии Core i3/i5/i7 11-го поколения известного как Tiger Lake. Для x6000E, Pentium и Celeron используется классический, «старый» 10 нм, а кристаллы Tiger Lake производятся с использованием «нового» 10 нм, так называемого SuperFIN. Платформа Intel Atom x6000E (Elkhart Lake) универсальна и позволяет решать широкий круг задач. Она может применяться в производящей промышленности и энергетике, в системах управления «умного города», в здравоохранении и медицине и во многих других отраслях, где требуется обработка достаточно серьёзных входных потоков данных в реальном времени. При этом платформа отвечает самым строгим требованиям безопасности.  По сравнению с предыдущими процессорами Atom аналогичного назначения в серии x6000E однопоточная производительность возросла в 1,7 раза, многопоточная — в 1,5 раза, а производительность графической подсистемы вдвое. Для повышенной временной точности в новинках реализована поддержка технологий Intel Time Coordinated Computing (TCC) и Time-Sensitive Networking (TSN).  Как и полагается современной SoC для периферийных вычислений, в составе x6000E имеются блоки критографических ускорителей, а для IoT имеется интегрированный микроконтроллер ARM Cortex-M7, отвечающий за работу Intel Programmable Services Engine (Intel PSE). Он работает независимо от остальных блоков и предоставляет возможности удалённого управления SoC, обработки низкоскоростного ввода-вывода от различных сенсоров, запуск приложений реального времени и синхронизацию. Есть также и чисто аппаратные средства обеспечения ИТ-безопасности, объединённые под именем Intel Safety Island.  Также в целях обеспечения надёжности реализован широкий спектр средств удалённого мониторинга и управления, как в режиме in-band, так и в out-of-band. Включение, выключение, сброс и перезагрузку можно выполнять даже если система в целом не отвечает. Модели Atom x6427FE и x6200FE отвечают стандартам функциональной безопасности IEC 61508 и ISO 13849, они прошли соответствующую сертификацию, так что использовать их можно и в системах жизнеобеспечения, в комплексах управления АЭС или нефтеперабатывающего предприятия. 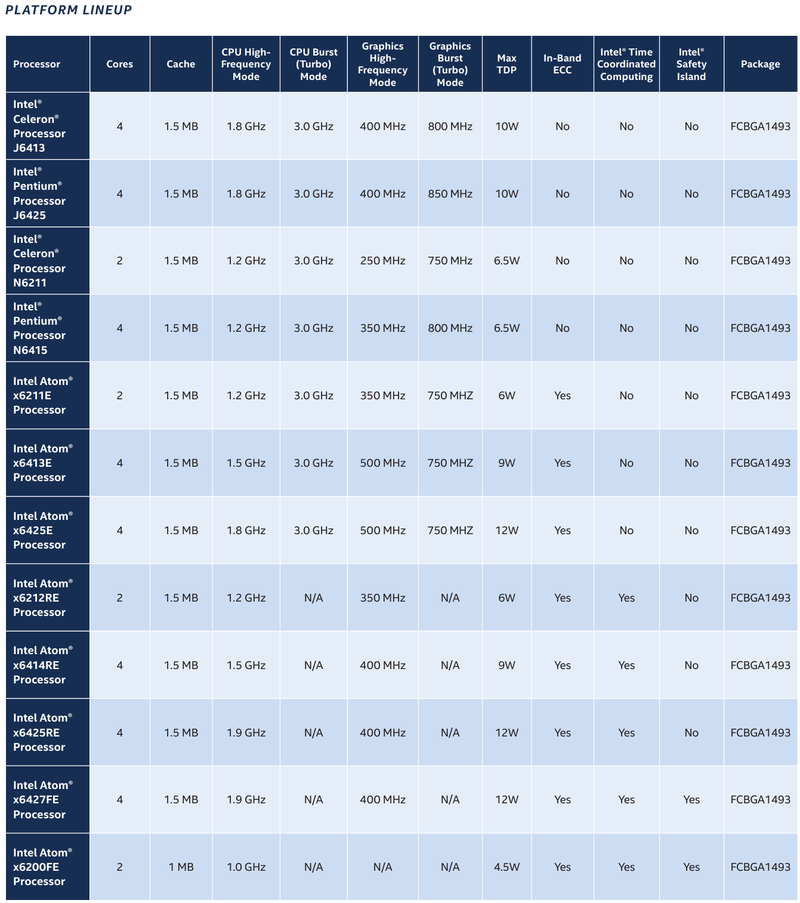 Серия Intel Atom x6000E включает в себя процессоры с двумя или четырьмя ядрами, их частотный диапазон составляет от 1,0 до 1,9 ГГц, в турборежиме частота может временно увеличиваться до 3,0 ГГц. Аналогичные частотные формулы имеют и Pentium/Celeron, базирующиеся на ядрах Tiger Lake (11 поколение). Контроллер памяти может работать либо с LPDDR4x (4×32 бита, максимум 4267 Мт/с, 16 Гбайт при 3200 МГц, всего до 64 Гбайт) или DDR4 (2×64 бита, 3200 Мт/с, максимум 32 Гбайт, всего до 64 Гбайт), есть поддержка in-band ECC для обычных модулей без ECC. Объём кеша составляет 1 Мбайт у самой младшей модели, во всех остальных случаях он равен 1,5 Мбайт. 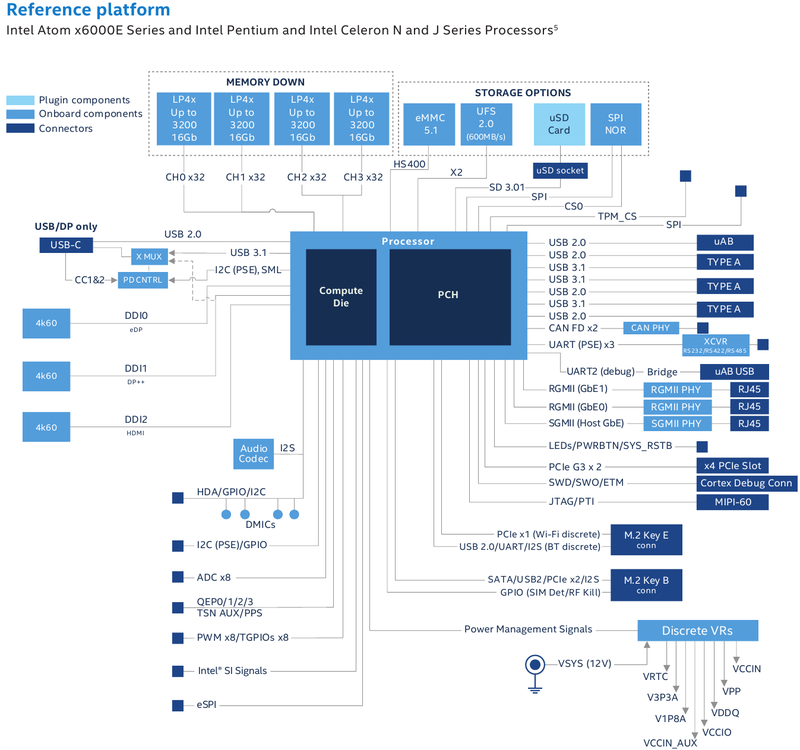 В соответствии с современными требованиями к графике, новинки Atom поддерживают подключение до трёх независимых дисплеев с разрешением 4K при 60 Гц, для этого служат интерфейсы Display Port 1.3 и HDMI 2.0b. Также поддерживается подключение экранов по eDP или MIPI DSI. Сам графический движок Intel UHD Graphics может иметь конфигурацию с 16 или 32 исполнительными блоками, работающими на частоте до 400 МГц, а в турборежиме — и до 800 МГц. Они поддерживают различные режимы вычислений для работы в качестве инференс-системы. Новые SoC Intel выполнены в едином корпусе FCBGA1493, однако под крышкой скрываются два кристалла — вычислительный и PCH. 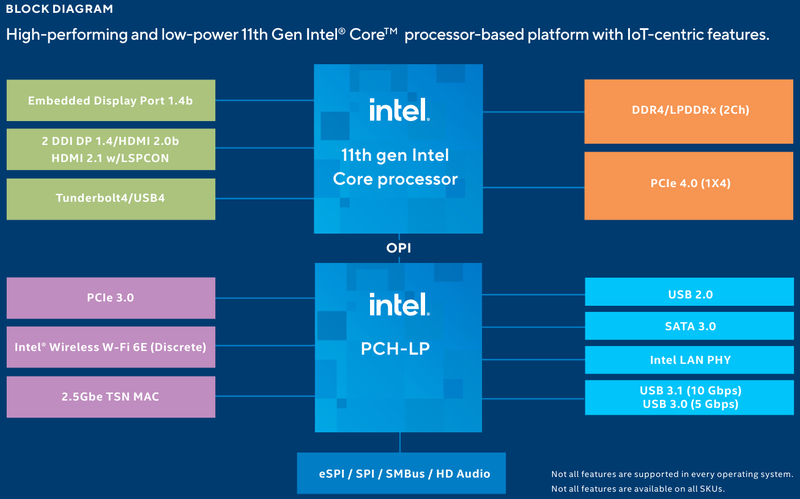 У более мощных процессоров с ядрами Tiger Lake графика тоже намного мощнее, она представлена блоками Iris Xe, которых в составе чипа может быть до 96, к тому же новая графическая архитектура лучше подходит для систем принятия решений (инференс) и задач машинного зрения. Такая графическая подсистема может одновременно обрабатывать до 40 потоков видео в формате 1080p при 30 кадрах в секунду, а выводить — либо четыре потока 4K, либо два, но уже в 8K. Подобные мощности позволяют использовать Tiger Lake в системах, для которых требуется детерминированная, строго синхронизированная по времени работа, либо в гибких системах машинного зрения с ИИ-компонентами. Безопасности способствует возможность полного шифрования содержимого оперативной памяти. 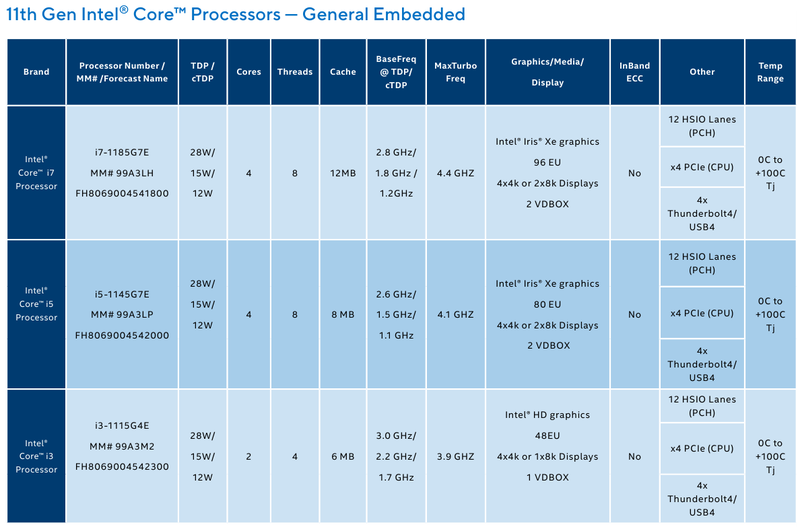 Коммуникационные возможности новых промышленных процессоров Intel также соответствуют требованиям времени: новые SoC несут на борту три MAC-контроллера, способных работать на скорости 2,5 Гбит/с, причём, в моделях с поддержкой TSN обеспечивается режим реального времени с минимальными задержками. Также общение «с внешним миром» происходит посредством 8 линий PCI Express 3.0, четырех портов USB 3.1 и 10 портов USB 2.0. Имеется два порта для подключения флеш-накопителей с интерфейсом UFS 2.0. В референсной платформе Intel реализована и поддержка UART и JTAG (разъём MIPI-60). 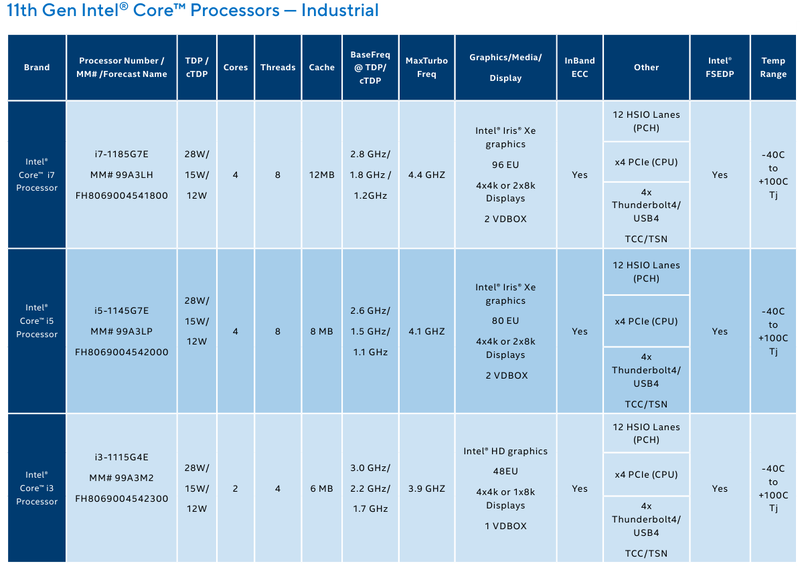 У более мощных Tiger Lake из серий i3/i5/i7 возможности несколько иные: встроенных MAC два, один из которых работает в режиме 1GbE, другой поддерживает cкорость 2,5GbE, в некоторых моделях дополнен поддержкой Time-Sensitive Networking. Поддерживается подключение дискретного сетевого контроллера I225LM/IT. Что касается беспроводной части, то имеется поддержка Wi-Fi со скоростями до 1,73 Гбит/с, а также Bluetooth 5.0. Для расширения инференс-способностей поддерживается подключение дополнительного ускорителя Intel из серии Movidius. Также реализованы стандарты PCIe 4.0 (четыре линии) и Thunderbolt/USB 4 (четыре порта).  Теплопакеты достаточно скромные: от 4,5 до 12 Ватт у Atom, до 28 Ватт у Tiger Lake. Улучшенный техпроцесс позволяет последним быть существенно быстрее аналогичных Core 8 поколения, в зависимости от характера нагрузки это до 23% (однопоточная) или до 19% (многопоточная), а графическая подсистема и вовсе практически в три раза быстрее за счёт новой архитектуры.  Новые процессоры имеют широкий спектр программной поддержки. В первую очередь, это, естественно, Microsoft Windows 10 IoT Enterprise и Yocto Project Linux, разрабатываемая сообществом Yocto совместно с Intel. Поддерживается также запуск Ubuntu, Wind River Linux LTS и Android 10 (только 64-битная версия). Для Tiger Lake также заявлена совместимость с Wind River VxWorks. 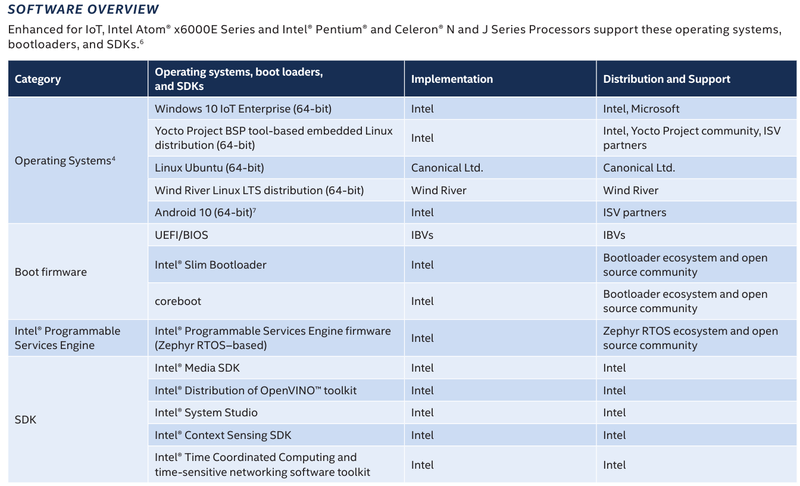 В качестве загрузчика может использоваться как обычный BIOS/UEFI, так и открытые Intel Slim Bootloader и coreboot. Часть, отвечающая за подсистемы безопасности и реального времени, работает под управлением Zephyr RTOS, также открытой. В число партнёров Intel, отвечающих за код BIOS, входят American Metatrends, Thundersoft, Byosoft, Insyde и Phoenix.  Для создания ПО компания предлагает расширенный комплект разработчика: инструменты для реализации Time Coordinated Computing, Intel Media SDK, набор Intel для OpenVINO, Intel System Studio и Intel Context Sensing SDK. Intel понимает всю важность рынка периферийных вычислений, за которым, судя по всему, будущее промышленности: любая производственная задача будет неизбежно порождать серьёзные потоки данных и требовать от системы управления минимальных задержек. Именно поэтому периферийные вычислительные устройства, к которым относятся и новые процессоры Intel, столь важны. Неудивительно, что компания уделяет много внимания как аппаратным возможностям, так и программным компонентам в новой платформе.
18.06.2020 [16:00], Алексей Степин
Intel представила Xeon Cooper Lake, третье поколение Scalable-процессоровКрупнейший в мире производитель процессоров с архитектурой x86, компания Intel, представила новую платформу, нацеленную на быстро растущий рынок машинного обучения, аналитики и периферийных вычислений. Хотя платформа состоит из нескольких компонентов, главным из них являются новые процессоры Intel Xeon Scalable — это уже третье поколение серии Scalable.  Первое поколение Xeon Scalable (Skylake) отличалось наличием поддержки векторных расширений с длиной 512 бит, хотя эта поддержка была наиболее полной в других процессорах с разъёмом LGA 3647, ныне почивших Xeon Phi 72xx. Во втором поколении Xeon Scalable, известном под кодовым именем Cascade Lake, появились расширения AVX-512 VNNI (Vector Neural Network Instructions, они же DL Boost), и это был первый реверанс в сторону машинного обучения со стороны Intel — расширения позволялил работать с INT8 и подходили для инференса.  Третье поколение, получившее имя Cooper Lake, ещё больше продвинулось в сторону поддержки нетипичных для традиционной архитектуры x86 форматов вычислений. Главным нововведением здесь является поддержка формата bfloat16, который часто используется в комплексах машинного обучения и системах принятия решений (инференс). Он требует меньше вычислительных мощностей, нежели традиционные форматы FP32/64, но при этом в большинстве случаев обеспечивает достаточную точность вычислений, а итоговый выигрыш в производительности может быть почти двухкратным.  Популярные фреймворки, такие как TensorFlow и Pytorch, уже давно поддерживают bfloat16, а Intel-оптимизированные версии доступны в комплекте Intel AI Analytics Toolkit. Компания также оптимизировала среды OpenVINO и ONNX с учётом возможностей новых процессоров Xeon Scalable. Собственно говоря, самое главное в Cooper Lake то, что их теперь можно использовать и для обучения нейронных сетей, а не только для инференса. Intel отдельно подчёркивает универсальность новых CPU. 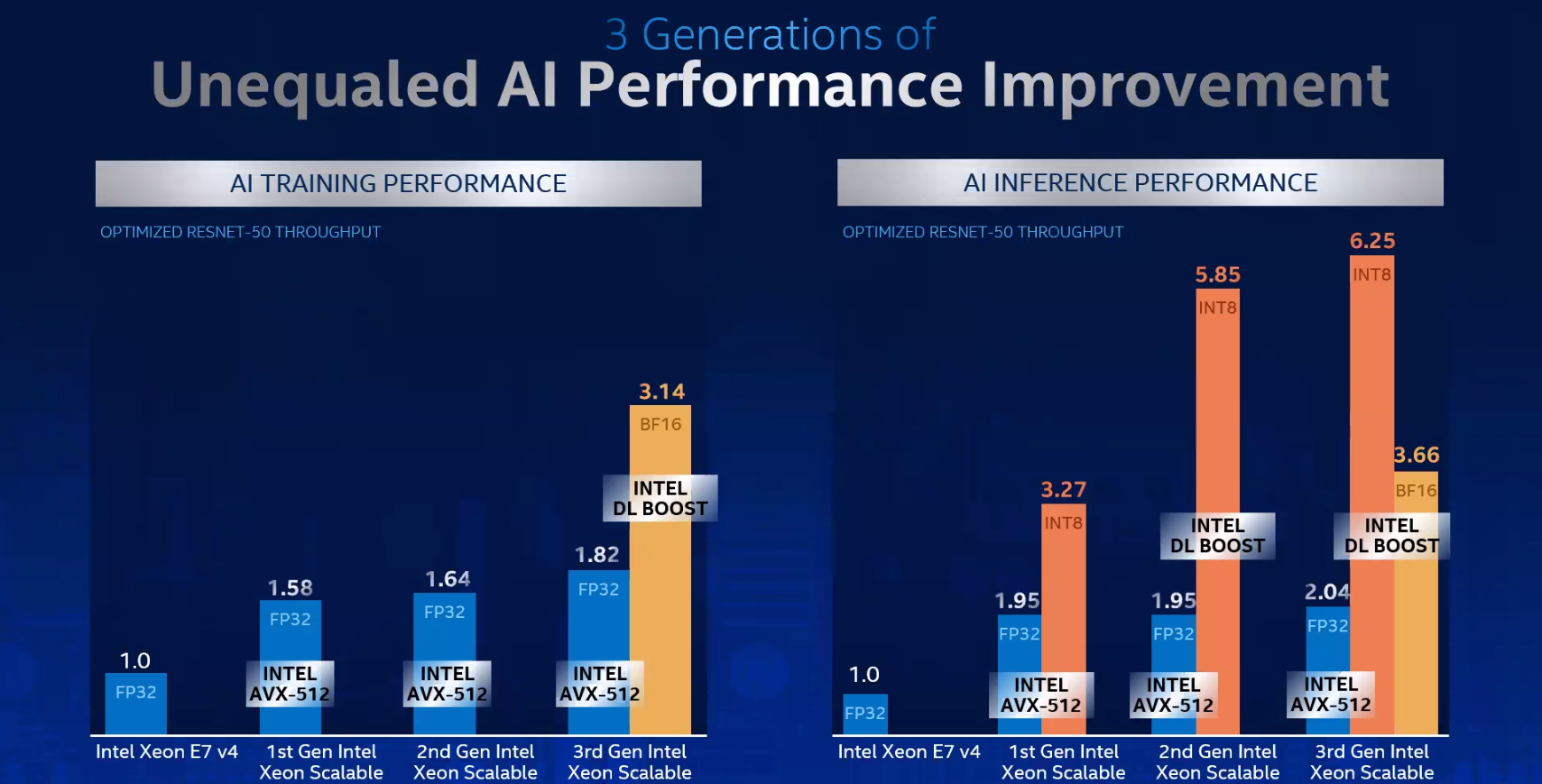 Что касается самих процессоров, то максимальное количество ядер сохранилось, их в серии Xeon Gold 53xx/63xx и Xeon Platinum 83xx по-прежнему 28 при поддержке SMT2. Однако улучшения есть, и достаточно серьёзные. Серия Xeon Platinum поддерживает память до DDR4-3200 (1DPC) и DDR4-2933 (2DPC), хотя младшие пяти- и шеститысячники так же ограничены 2666 и 2933 MT/с. Зато все они поддерживают память Intel Optane DCPMM 2-го поколения. Число каналов память осталось прежним, их шесть. Существенное отличие от Cascade Lake в том, что теперь у всех CPU есть 6 линий UPI — они могут может «бесшовно» устанавливаться в системы с четырьмя или восемью процессорными разъёмами. Другое важное отличие — серия 53xx теперь имеет два FMA-порта для AVX-512, а не один как раньше. Часть новинок поддерживает Intel Speed Select. 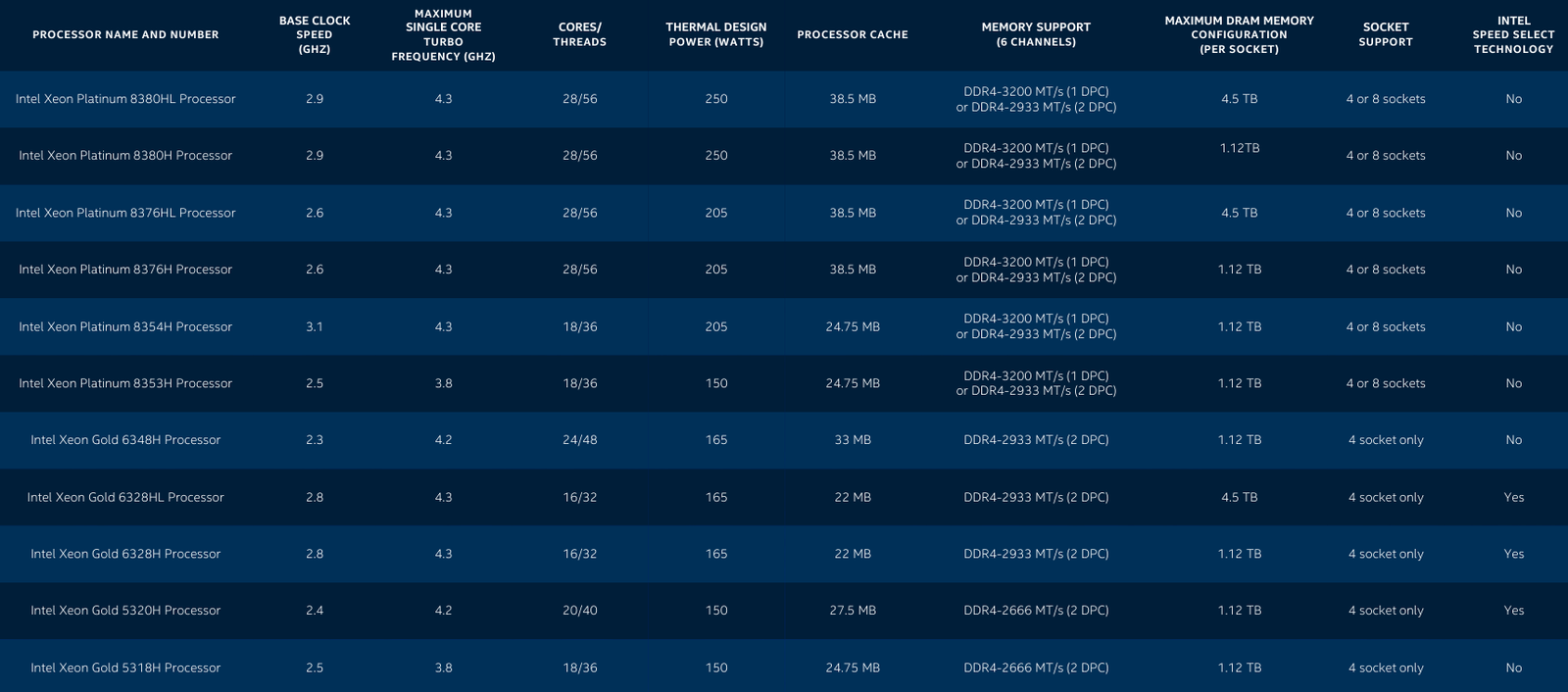 У «ёмких» моделей с суффиксом HL максимальный объём оперативной памяти достиг 4,5 Тбайт, а у базовых H — до 1,12 Тбайт. Несколько подросли тактовые частоты, в серии есть модели с частотной формулой 2,9 ‒ 4,3 ГГц, причём большая часть новинок имеет частоту в турборежиме более 4 ГГц. Исключение — модели с пониженным энергопотреблением. Всё это делает новые процессоры привлекательными для крупных предприятий, облачных провайдеров и гиперскейлеров вообще. Если даже на секунду забыть все новововведения для ИИ, Cooper Lake всё равно останется многосокетной платформой, а это значит, что он подходит для работы с большими СУБД, анализа больших объёмов данных в реальном времени, OLTP и виртуализации. В области 4S/8S-платформ у Intel давно крепкие позиции, так что новинки наверняка приглянутся определённому кругу заказчиков. Но массовыми Cooper Lake в текущем виде не станут. 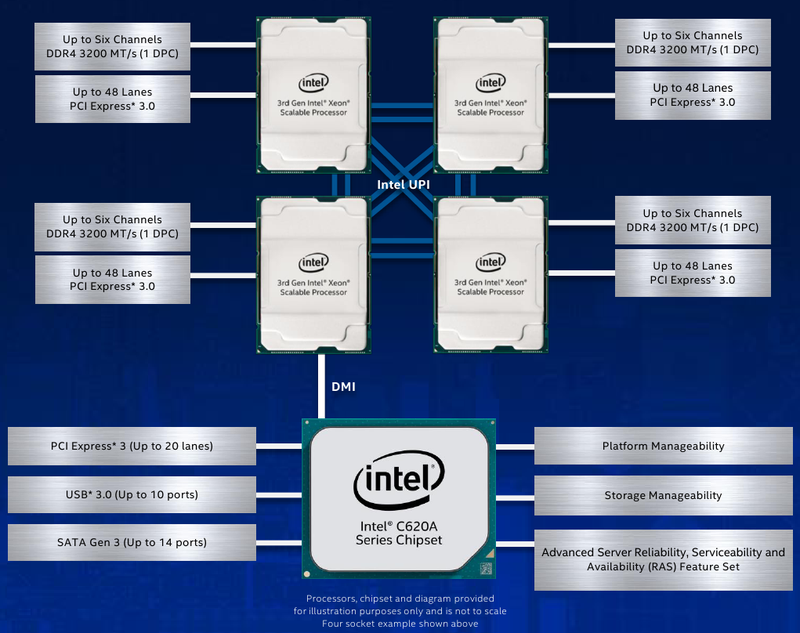 Основной системный чипсет — Intel C620A, то есть обновлённый Lewisburg. В серию пока входит всего три модели, две из которых поддерживают технологию Intel QAT, ускоряющую работы по компресии и шифрованию. Так это обновление уже имеющихся чипсетов, поддержки PCI Express 4.0 нет. Сами процессоры Xeon Scalable третьего поколения по-прежнему могут предоставить в распоряжение системы до 48 линий PCIe 3.0. С учётом того, что ориентированы они на 4-сокетные системы, этого может быть вполне достаточно.  Однако другие процессоры Xeon Scalable «Ice Lake», для одно-двухсокетных платформ Whitley, которые Intel планирует представить позднее в этом году, уже получат поддержку PCI Express 4.0. Также известно, что четвёртое поколение Xeon Scalable под именем Sapphire Rapids получит набор новых матричных расширений (Advanced Matrix Extensions, AMX), которые, вероятно, буду напоминать тензорные ядра. Она увидит свет уже в 2021 году. Для массовых одно- и двухсокетных платформ пока предлагается использовать Cascade Lake Refresh. Вместе с Intel Xeon Cooper Lake компания также анонсировала второе поколение памяти Intel Optane DCPMM 200, накопители Intel D7-P5500 и D7-5600 с интерфейсом PCIe 4.0 и новую FPGA Intel Stratix 10 NX.
24.02.2020 [17:00], Константин Ходаковский
Intel представила семейство процессоров Intel Xeon Cascade Lake RefreshВместе с серией продуктов для инфраструктуры сетей 5G, включающей систему на кристалле Atom P5900 для базовых станций, структурированную платформу ASIC Diamond Mesa для ускорения сетей 5G, серию сетевых контроллеров Ethernet 700 и программное решение OpenNESS для лёгкого развёртывания облачных периферийных микросервисов, корпорация Intel расширила и серию серверных процессоров Intel Xeon Scalable 2-го поколения.  Intel Xeon Scalable 2-го поколения являются основой платформенной инфраструктуры в центрах обработки данных. На сегодняшний день чипов Xeon Scalable продано в общей сложности более 30 миллионов. Появление этих процессоров позволило трансформировать ядро сети: сегодня на их долю приходится 50 % всех виртуализированных окружений по всему миру, а к 2023 году это число дополнительно увеличится.  Как мы уже сообщали, новая серия серверных процессоров Intel включает 18 моделей с более высокими частотами (до 4 ГГц в режиме Turbo Boost), увеличенным количеством ядер и объёмом кеша в различной комбинации этих параметров. Но главное изменение — это существенно сниженная стоимость. Например, Xeon Gold 6238R предложит 28 ядер и базовую частоту 2,2/4 ГГц, тогда как его предшественник в лице Xeon Gold 6238 использует 22 ядра с частотой 2,1/3,7 ГГц при одинаковой стоимости.  Флагманом семейства станет Xeon Gold 6258R с 28 ядрами, поддержкой Hyper-Threading, базовой частотой 2,7 ГГц и уровнем TDP не более 205 Вт. В обозначении моделей новых процессоров, как правило, присутствует литера «R», то есть Refresh. Серия оптимизированных ЦП для высочайшей производительности отдельных ядер теперь представляет собой такой перечень. Все процессоры поддерживают Intel Optane DC Persistent Memory (жирным помечены новые модели):
Серия ЦП, оптимизированных для производительности на Ватт, представляет собой такой перечень. Все процессоры Platinum и Gold поддерживают Intel Optane DC Persistent Memory, а остальные — нет (жирным помечены новые модели):
Также компания представила новый чип в семействе энергоэффективных, рассчитанных на долгий цикл процессоров, — Silver 4210T (10 ядер, 2,3/3,2 ГГц, 13,75 Мбайт, 95 Вт, $554). Как и старая 8-ядерная модель Silver 4209T, новая тоже не поддерживает Intel Optane DC Persistent Memory. И наконец для односокетных серверов, где принципиальную роль играет стоимость, представлена 16-ядерная модель Gold 6208U (2,9/3,9 ГГц, 22 Мбайт, 150 Вт, $989, поддержка Intel Optane DC Persistent Memory). Запуск новых моделей призван сделать предложения Intel более конкурентоспособными по сравнению с 7-нм чипами AMD EPYC Rome — неслучайно затронуты были наиболее ходовые процессоры. Самое производительное (и дорогое) семейство Xeon Platinum 9000 с количеством ядер от 32 до 56 обновлено не было. Повышение показателя цены/производительности — главный повод к запуску Cascade Lake R (снижение наблюдается кратное). В новой серии процессоры разделены между семействами Bronze, Silver и Gold. Неслучайно процессоров Platinum в ней нет: старшие модели, в том числе и 28-ядерный флагман, вошли в семейство Gold. Поэтому Intel законно поставила на «новинки» более низкие ценники. Ранее компания уже серьёзно пересмотрела свои серверные предложения. Она, по сути, отказалась от процессоров серии M, которые, в отличие от стандартных решений, ограниченных объёмом ОЗУ в 1,5 Тбайт, позволяют работать в системах с 2 Тбайт памяти. Клиентам, нуждающимся в таком объёме ОЗУ, теперь предлагается использовать процессоры класса выше — L, поддерживающие уже 4,5 Тбайт. Для этого компания уравняла цены моделей L с M. Впрочем, не все OEM-производители спешат обесценить свои запасы и задерживают снижение цен.  Помимо процессоров Intel также представила 17 обновлённых решений Select Solutions, в которых реализована поддержка этих новых продуктов для ускорения наиболее важных рабочих нагрузок у заказчиков. Ведущие отраслевые производители уже начинают поставки новых платформ на базе Intel Xeon 2-го поколения Refresh. |
|

