Материалы по тегу: arm
|
27.02.2025 [12:51], Сергей Карасёв
Представлен Armv9-процессор Cortex-A320 для IoT-устройств с ИИ-функциямиКомпания Arm анонсировала процессор Cortex-A320 — своё первое сверхэффективное изделие семейство Cortex-A, построенное на архитектуре Armv9. Чип ориентирован на периферийные устройства и IoT-оборудование с поддержкой ИИ-функций. В основу новинки положена архитектура версии Armv9.2-A (Harvard) с поддержкой расширений QARMA3, SVE2, MTE, RAS и криптографическими функциями. Объём кеша первого уровня может составлять 32 или 64 Кбайт. Опционально доступен кеш L2 ёмкостью от 128 до 512 Кбайт, тогда как кеш L3 не предусмотрен. Кроме того, существенно ускорена работа с оперативной памятью. Cortex-A320 — это одноядерный процессор с последовательной выборкой 32-битных инструкций. Благодаря многочисленным обновлениям микроархитектуры, таким как предсказание ветвлений и предварительные выборки, достигается повышение эффективности на 50 % по сравнению с Cortex-A520 и увеличение быстродействия на 30 % в SPECINT2K6 по сравнению с Cortex-A35. 
Источник изображения: Arm По заявлениям Arm, процессор Cortex-A320 обеспечивает 10-кратное повышение производительности на операциях машинного обучения по сравнению с Cortex-A35 (на GEMM int8) и 6-кратное повышение по сравнению с Cortex-A53, самым популярным в мире изделием на архитектуре Armv8-A. На сегодняшний день Cortex-A320 — это наиболее эффективное решение серии Cortex-A для задач машинного обучения. На базе Cortex-A320 могут формироваться кластеры, насчитывающие до четырёх ядер. Блок векторной обработки с технологиями NEON и SVE2 может быть индивидуальным для каждого ядра или использоваться связкой из двух ядер, в том числе в четырёхъядерной конфигурации. Благодаря DSU-120T (оптимизированная версия DynamIQ Shared Unit) возможно формирование кластеров исключительно с ядрами Cortex-A320. Кроме того, новинки поддерживают NPU Ethos-U85, которые позволяют автоматически перекидывать обработку неподдерживаемых типов данных и инструкций на SIMD-блоки Cortex-A320. В целом говорится о возможности запуска на новых чипах моделей с более чем 1 млрд параметров. Процессор Cortex-A320 может применяться в самых разных сферах — от умных колонок и интеллектуальных камер наблюдения до автономных транспортных средств и контроллеров служебных роботов. Кроме того, новый процессор подходит для микроконтроллеров с батарейным питанием и устройств, работающих под управлением операционных систем реального времени (RTOS). Реализованы развитые средства обеспечения безопасности, включая Secure EL2 (Exception Level 2).
18.02.2025 [13:56], Сергей Карасёв
Поставки российских процессоров Baikal-S возобновятся в конце 2025 годаКомпания «Байкал Электроникс», по сообщению CNews, получила декларацию о соответствии требованиям технического регламента ЕАЭС на серийный выпуск серверных процессоров Baikal-S и их продажи в России. Поставки чипов, как ожидается, возобновятся в конце 2025 года. Чипы Baikal-S насчитывают 48 ядер Arm Cortex-A75, поддерживают память DDR4-3200 МГц, имеют 80 линий PCIe 4.0 и два интерфейса 1GbE. Первая партия процессоров была получена в конце 2021 года. Изначально предполагалось, что производством изделий займётся TSMC с применением 16-нм технологии. Однако TSMC отказалась обслуживать российских заказчиков, и с выпуском Baikal-S возникли сложности. В результате, летом 2022-го «Байкал Электроникс» отменила производство и продажи этих процессоров. Но в конце 2024 года стало известно о том, что в Россию поступила партия из 1 тыс. чипов Baikal-S. Говорилось, что почти все они достались некой крупной компании с государственным участием. При этом несколько сотен чипов были распределены по госпроектам и проданы другим производителям. И вот теперь сообщается, что выпуск изделий Baikal-S возобновится. 
Источник изображения: «Байкал Электроникс» В документах ЕАЭС в качестве места производства процессоров значится город Красногорск в Московской области, где находится один из офисов «Байкал Электроникс». Но по факту чипы будут изготавливаться на неназванном предприятии в Азии. Участники рынка считают, что изделия Baikal-S будут востребованы прежде всего среди тех отечественных производителей, которым необходимо выполнять «балльные обязательства», чтобы попадать в реестр российской продукции Минпромторга.
14.02.2025 [09:45], Сергей Карасёв
Arm выпустит собственные чипы для ЦОД, а их первым покупателем станет Meta✴Британская компания Arm, 90 % которой принадлежит японскому холдингу SoftBank, выйдет на рынок процессоров для серверов, ориентированных на крупные дата-центры. Как сообщает газета Financial Times, эти изделия дебютируют в текущем году, а их первым заказчиком станет Meta✴ Platforms. Весной 2024 года сообщалось, что Arm намерена разработать собственный ИИ-чип. Тогда говорилось, что его массовый выпуск будет налажен к осени 2025-го на мощностях контрактного производителя. В частности, холдинг SoftBank вёл переговоры на соответствующую тему с TSMC. 
Источник изображения: Arm Как теперь стало известно, первым изделием собственной разработки Arm станет серверный CPU, а не ИИ-чип. Архитектура готовящегося решения предполагает возможность кастомизации под нужды заказчика. Этим воспользуется Meta✴, которая активно расширяет инфраструктуру ЦОД, а перспективе намерена потратить «сотни миллиардов долларов» на развитие ИИ-экосистемы. Рене Хаас (Rene Haas), генеральный директор Arm, отметил, что компания намерена официально представить процессор предстоящим летом. При этом вдаваться в подробности о технических характеристиках изделия он не стал. Выход Arm на рынок аппаратных решений будет означать серьёзное изменение бизнес-модели: ранее компания зарабатывала на лицензировании своих разработок другим участникам рынка, в том числе поставщикам решений для дата-центров и облачных платформ. Вместе с тем в ИИ-сегменте Arm увеличивает выручку путём постоянного повышения лицензионных сборов за свои технологии и благодаря взиманию роялти за каждый чип, продаваемый другими компаниями. Недавно также сообщалось, что SoftBank вскоре может заключить сделку по покупке разработчика серверных Arm-чипов Ampere за $6,5 млрд. Таким образом, японский холдинг и подконтрольная ему британская Arm готовятся составить серьёзную конкуренцию другим игрокам рынка процессоров для серверов. У AWS, Google Cloud и Microsoft Azure уже есть собственные серверные Arm-процесоры: Graviton, Axion и Cobalt 100.
04.02.2025 [11:54], Сергей Карасёв
Крошечная плата RP2350-USB-A за $7 оснащена контроллером Raspberry Pi RP2350В продажу, по сообщению ресурса CNX Software, поступила микроплата Waveshare RP2350-USB-A, в основу которой положен микроконтроллер Raspberry Pi. При подключении к хосту изделие может применяться для эмуляции мыши, клавиатуры или другого USB-устройства. Новинка оснащена чипом Raspberry Pi RP2350A (QFN-60; 7 × 7 мм; 30 × GPIO), который объединяет по два ядра Arm Cortex-M33 (с поддержкой Trustzone) и RISC-V Hazard3 с тактовой частотой 150 МГц (в обоих случаях). Но использовать эти кластеры сообща нельзя: одна из двух пар ядер выбирается при инициализации платы. Объём памяти SRAM составляет 520 Кбайт, SPI Flash — 2 Мбайт (для хранения прошивки). 
Источник изображения: CNX Software Предусмотрены два 9-контактных массива GPIO с поддержкой 2 × UART, 2 × I2C, 2 × SPI, 4 × ADC, 15 × GPIO и пр. Для подачи питания (5 В) и программирования служит порт USB 1.1 Type-C. Имеются кнопки сброса и перезагрузки, а также светодиодный RGB-индикатор. Размеры микроплаты составляют 33 × 17,5 мм. Изделие также получило разъём USB Type-A с программным вводом-выводом (PIO). Это позволяет использовать плату как в качестве USB-устройства, так и в роли хоста. Waveshare предлагает демонстрационные программы на C/C++ и Arduino. Модель RP2350-USB-A доступна для заказа по ориентировочной цене $7. Отметим, что ранее дебютировала мини-плата Pico W5, также выполненная на контроллере Raspberry Pi RP2350. Это решение оборудовано адаптерами Wi-Fi 4 802.11n (частотные диапазоны 2,4 и 5 ГГц) и Bluetooth 5.0 (LE) на основе модуля BW16 (контроллер Realtek RTL8720DN).
17.01.2025 [00:06], Владимир Мироненко
Google представила инстансы C4A с фирменными Titanium SSD и Arm-процессорами AxiomGoogle объявила о доступности инстансов C4A с кастомными накопителями Titanium SSD, специально разработанными для облачных нагрузок, требующих обработки данных в реальном времени, с низкой задержкой и высокой пропускной способностью хранилища. Titanium SSD в составе инстансов C4A, построенных на Arm-процессорах Axion собственной разработки, обеспечивают производительность до 2,4 млн IOPS на операциях случайного чтения, до 10,4 ГиБ/с пропускной способности чтения и до 35 % более низкую задержку доступа по сравнению с SSD предыдущего поколения. Titanium SSD — первое поколение SSD Google, интегрированных с DPU Titanium, обеспечивающей повышение производительности выполнения приложений за счет разгрузки операций по работе с сетью и хранилищем, а также управления. Семейство инстансов C4A на базе процессоров Google Axion обеспечивает до 65 % выше производительность и до 60 % лучше энергоэффективность по сравнению с аналогичными инстансами текущего поколения на базе архитектуры x86. Как сообщает Google, C4A с Titanium SSD обеспечивают самое выгодное в отрасли соотношение цены и производительности для широкого спектра совместимых с Arm универсальных рабочих нагрузок, таких как высокопроизводительные базы данных, аналитические системы, поисковые и рабочие нагрузки, которые выигрывают от кеширования и использования локального хранилища. 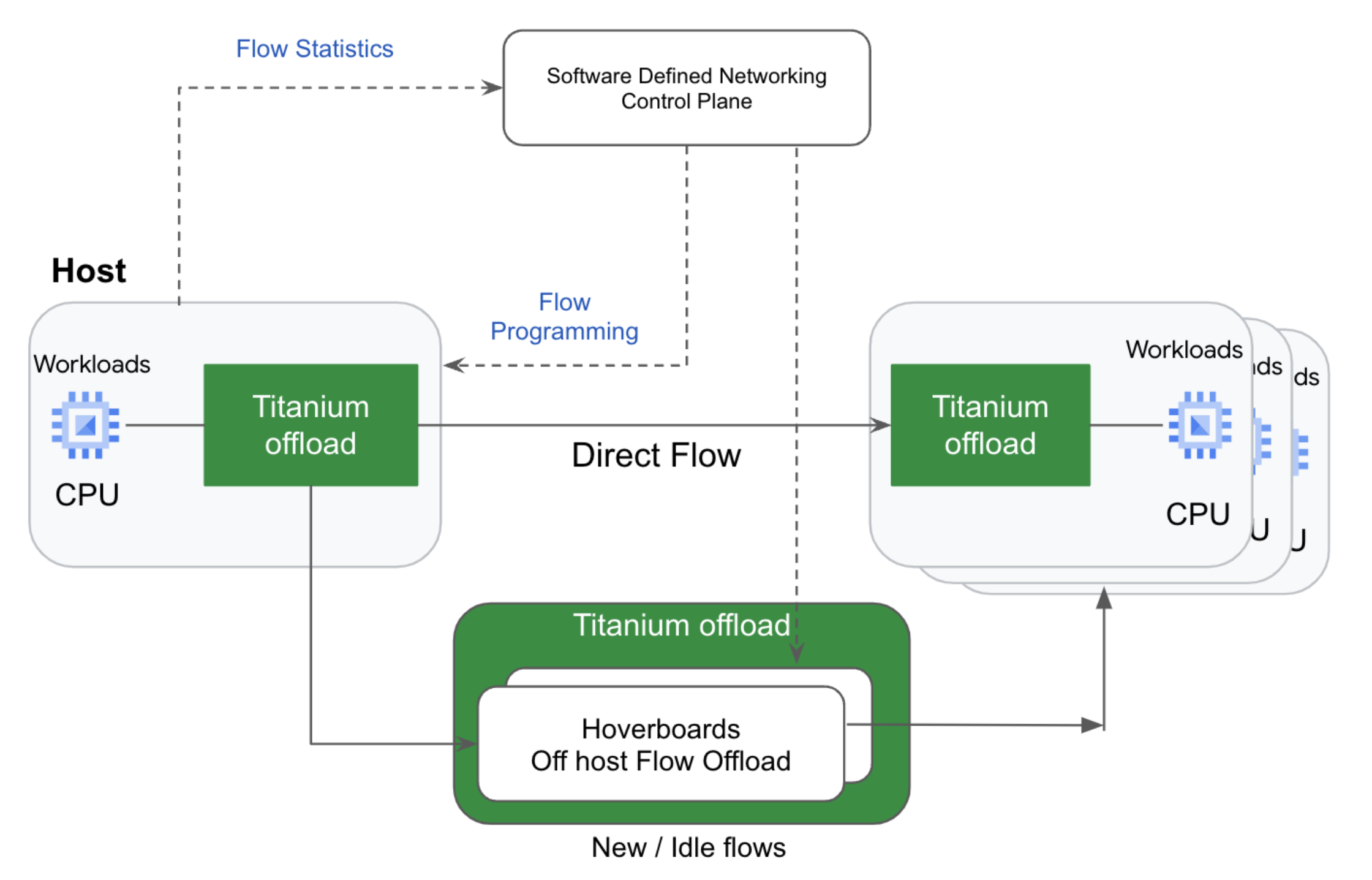
Источник изображения: Google Конфигурация C4A с Titanium SSD включает до 72 vCPU, 576 Гбайт памяти и 6 Тбайт локального хранилища в двух вариантах — Standard (4 Гбайт RAM на vCPU) и High-memory (8 Гбайт/vCPU). Сетевое подключение C4A имеет пропускную способностью до 50 Гбит/с или до 100 Гбит/с. Инстансы также поддерживают новейшее поколение хранилища Balanced и Extreme Hyperdisk с производительностью до 350 тыс. IOPS и пропускной способностью до 5 Гбайт/с на виртуальную машину. Клиенты Google Cloud могут использовать C4A с Titanium SSD для сервисов Compute Engine, Google Kubernetes Engine (GKE), Batch, Dataproc и т.д. Инстансы C4A теперь также доступны в версии превью в Dataflow с поддержкой Cloud SQL, AlloyDB и других сервисов, которые появятся в ближайшее время. C4A доступны по запросу, в качестве спотовых и зарезервированных инстансов, со скидками за обязательное использование (CUD) и FlexCUD в регионах us-central1 (Айова), us-east4 (Вирджиния), us-east1 (Южная Каролина), europe-west1 (Бельгия), europe-west4 (Нидерланды), europe-west3 (Франкфурт), europe-west2 (Лондон) и asia-southeast1 (Сингапур). Вскоре они появятся в других регионах.
14.01.2025 [12:23], Владимир Мироненко
Qualcomm наняла главного архитектора Intel Xeon для разработки серверных Arm-процессоровРесурсу CRN стало известно, что компания Qualcomm наняла Сайлеша Коттапалли (Sailesh Kottapalli) в качестве старшего вице-президента. Ветеран Intel с 28-летним стажем, являвшийся главным архитектором серверных процессоров Xeon, сообщил в понедельник в соцсети в LinkedIn, что он присоединился к Qualcomm после ухода из Intel, поскольку разработчик чипов формирует команду для выхода на рынок CPU для ЦОД. «Возможность внедрять инновации и расти, помогая при этом расширять горизонты, была для меня чрезвычайно привлекательной — возможность, которая выпадает раз в карьере и которую я не мог упустить», — написал Коттапалли в LinkedIn. Это не первая попытка Qualcomm выйти на рынок серверных процессоров. В 2017 году компания выпустила 10-нм 48-ядерные чипы Centriq 2400, но вскоре забросила развитие этого направления. 
Источник изображения: Intel Пост Коттапалли в LinkedIn, ранее занимавшего должность ведущего инженера по чипам Itanium и Xeon в Intel, прежде чем стать главным архитектором Xeon в компании, появился чуть более чем через месяц после того, как стало известно, что у Qualcomm есть подразделение Qualcomm Data Center, которое занимается созданием «высокопроизводительного, энергоэффективного серверного решения». Разработчик чипов раскрыл эту информацию в опубликованной в декабре вакансии архитектора безопасности серверной системы на кристалле (SoC). В ней говорилось, что команда Qualcomm Data Center сосредоточена на создании «эталонных платформ» на основе Snapdragon. Подходящий соискатель возглавит разработку «системной архитектуры для конфиденциальных вычислений в продуктах ЦОД». Конфиденциальные вычисления, позволяющие изолировать данные во время их обработки, стали стандартной функцией в Intel Xeon и AMD EPYC, отметил ресурс CRN. 
Источник изображения: Qualcomm Qualcomm разрабатывает серверные ИИ-ускорители Qualcomm Cloud AI, которые она поставляла таким компаниям, как AWS, HPE и Lenovo. Кроме того, компания сотрудничает с Cerebras, ещё одним разработчиком ИИ-ускорителей. Недавно стало известно о планах компании выпустить ускорители Cloud AI 80 (AIC080) для ИИ-задач. В 2021 году Qualcomm приобрела за $1,4 млрд стартап NUVIA, который изначально занимался серверного Arm-процессора Phoenix. Qualcomm утверждала, что будет использовать технологии NUVIA в ноутбуках, смартфонах, ADAS, AR/VR и т.п., но в прошлом году объявила, что также планирует продолжить разработку серверных процессоров. Из-за поглощения NUVIA между Arm и Qualcomm уже несколько лет идут судебные разбирательства.
09.01.2025 [17:57], Владимир Мироненко
SoftBank и Arm заинтересовались покупкой Ampere, но о переговорах говорить раноЯпонский холдинг SoftBank Group вместе с британской компанией Arm, в которой он владеет 90 % акцией, проявляют интерес к покупке поддерживаемого Oracle стартапа Ampere Computing из Санта-Клары (Калифорния, США), специализирующегося на разработке серверных Arm-процессоров, пишет Bloomberg со ссылкой на информированные источники. По словам источников, на данный момент идёт обсуждение потенциальной сделки и нет гарантий, что дело дойдёт до переговоров. Возможно, что на покупку Ampere найдётся другой претендент. Ранее стало известно, что компания Ampere привлекала финансового консультанта, чтобы обсудить возможные варианты поглощения более крупной компанией. В 2021 году, когда SoftBank планировал инвестировать в компанию, Ampere Computing была оценена в $8 млрд. В какую сумму оценивается рыночная стоимость Ampere Computing на данный момент при обсуждении сделки, выяснить не удалось. Согласно документам, поданным Ampere Computing в регулирующие органы, Oracle инвестировала сотни миллионов долларов в стартап с момента его основания. Oracle заявила в прошлом году, что владеет 29 % стартапа и может снова инвестировать в компанию, чтобы получить полный контроль над производителем чипов. Oracle, по-видимому, является крупнейшим заказчиком продуктов Ampere. 
Источник изображения: Ampere Computing Arm постепенно отходит от лицензирования своих разработок, становясь полноценным производителем чипов. Привлечение инженеров Ampere, многие из которых ранее работали в подразделении Intel по производству серверных чипов, может добавить экспертные знания и импульс для выхода Arm на этот рынок, считает Bloomberg. Основатель и генеральный директор Ampere Рене Джеймс (Renee James), бывший топ-менеджер Intel, рассматривала в 2022 году возможность вывода Ampere на биржу в США. Некоторые эксперты предполагали, что компания изначально ориентировалась на поглощение одним из крупных гиперскейлеров, но в итоге AWS, Google Cloud и Microsoft Azure стали развивать собственные Arm-процесоры Graviton, Axion и Cobalt 100.
19.12.2024 [10:27], Сергей Карасёв
Одноплатный компьютер Radxa Orion O6 формата mini-ITX получил 12-ядерный Arm-процессор с ИИ-ускорителемКомпания Radxa пополнила ассортимент одноплатных компьютеров моделью Orion O6, особенность которой заключается в использовании процессора Cix P1 с 12 вычислительными ядрами Armv9. Новинка выполнена в форм-факторе mini-ITX с габаритами 170 × 170 мм. Чип Cix P1 с архитектурой DynamIQ объединяет квартеты ядер Cortex-A720 с частотой до 2,8 ГГц, Cortex-A720 с частотой до 2,4 ГГц и Cortex-A520 с частотой до 1,8 ГГц. Присутствует GPU-блок Arm Immortalis G720 MC10 с поддержкой Vulkan 1.3, OpenGL ES 3.2, OpenCL 3.0. Возможно декодирование видео 8Kp60 (AV1, H.265, H.264, VP9, VP8, H.263, MPEG4, MPEG2), а также кодирование 8Kp30 (H.265, H.264, VP9, VP8). Встроенный нейропроцессорный движок (NPU) обладает производительностью до 30 TOPS с возможностью работы в режимах INT4/INT8/INT16, FP16/BF16 и TF32. 
Источник изображения: Radxa Объём оперативной памяти LPDDR5-5500 может составлять 8, 16, 32 или 64 Гбайт. Есть слот M.2 Key-M (PCIe 4.0 x4) для NVMe SSD, разъём M.2 Key-E (PCIe 4.0 x2; USB) для адаптера Wi-Fi (Wi-Fi 7/6E + Bluetooth) и слот PCIe x16 (PCIe 4.0 x8) для карты расширения. Присутствует сетевой адаптер 5GbE. Допускается вывод изображения на четыре монитора через интерфейсы HDMI 2.0 (4Kp60), DisplayPort 1.4 (4Kp120), USB Type-C (DisplayPort Alt Mode) и eDP (4Kp60). В оснащение входят по два порта USB 3.2 Gen2 (10 Гбит/с) Type-A и USB 2.0 Type-A, дополнительный порт USB 3.2 Gen2 Type-C с поддержкой Power Delivery, гнездо RJ-45 для сетевого кабеля, 40-контактная колодка GPIO (3 × UART, 2 × I2C, 2 × I2S, 2 × PWM, 1 × SPI, 10 × GPIO), 4-контактный коннектор для вентилятора с ШИМ-управлением. Питание может подаваться через порт USB Type-C (минимум 65 Вт) или АТХ-коннектор. Говорится о совместимости с Debian и Fedora, а в дальнейшем — с Ubuntu, Android, Deepin, Windows и OpenKylin. Цена варьируется от $200 до $450 в зависимости от объёма ОЗУ. Доступность платы гарантирована как минимум до сентября 2029 года.
17.12.2024 [11:50], Сергей Карасёв
Вышла крошечная плата Pico W5 с контроллером Raspberry Pi RP2350, Wi-Fi 4 и Bluetooth 5.0По сообщению ресурса CNX Software, в продажу поступила микроплата Pico W5, построенная на контроллере Raspberry Pi RP2350. Изделие может стать альтернативой устройству Raspberry Pi Pico 2 W, которое дебютировало менее месяца назад. Чип RP2350 содержит по два ядра Arm Cortex-M33 и RISC-V Hazard3 с тактовой частотой 150 МГц. Однако использовать их одновременно нельзя: нужная пара ядер выбирается при инициализации платы. Объём встроенной памяти SRAM составляет 520 Кбайт. Реализована функция Secure Boot (только при использовании блока Arm). Новинка несёт на борту 8 Мбайт памяти QSPI Flash. В оснащение входят адаптеры Wi-Fi 4 802.11n (частотные диапазоны 2,4 и 5 ГГц) и Bluetooth 5.0 (LE) на основе модуля BW16 (контроллер Realtek RTL8720DN). Предусмотрен порт USB Type-C 1.1. 
Источник изображения: CNX Software Крошечная плата Pico W5 располагает 26 контактами GPIO с поддержкой 2 × UART, 2 × SPI, 2 × I2C, 24 × PWM, 4 × ADC. Габариты составляют 51 × 21 мм, масса — 3 г. Питание (5 В) подаётся через коннектор USB Type-C. Диапазон рабочих температур простирается от -10 до +60 °C. Модель Pico W5 поддерживает разработку на базе Arduino и MicroPython. Приобрести новинку можно по ориентировочной цене $7. Столько же стоит оригинальная версия Raspberry Pi Pico 2 W, но это изделие поддерживает Wi-Fi 802.11n только в диапазоне 2,4 ГГц.
12.12.2024 [12:50], Сергей Карасёв
144-ядерный Arm-процессор Fujitsu Monaka получит 3.5D-упаковку от BroadcomКорпорация Fujitsu, по сообщению ресурса Tom's Hardware, продемонстрировала прототип серверного процессора Monaka для дата-центров. Это изделие проектируется с прицелом на НРС-платформы, а также на ЦОД, ориентированные на решение ресурсоёмких задач в области ИИ. О проекте Monaka стало известно в начале 2023 года. Тогда говорилось, что разработка изделия является частью программы, курируемой японской Организацией по развитию новых энергетических и промышленных технологий (NEDO). Процессор основан на архитектуре Arm с набором инструкций Armv9-A и поддержкой масштабируемых векторных расширений SVE2. Как теперь сообщается, для чипа Monaka предусмотрено использование технологии Broadcom 3.5D eXtreme Dimension System in Package (SiP). Конструкция процессора включает четыре 36-ядерных вычислительных чиплета, изготовленных по 2-нм технологии TSMC. Таким образом, суммарное количество ядер достигает 144. Эти чиплеты монтируются поверх «плиток» SRAM с использованием гибридного медного соединения (HCB). Блоки SRAM, выполняющие функции кеш-памяти, производятся по 5-нм техпроцессу TSMC. Кроме того, имеется крупный чиплет ввода-вывода, в состав которого входят контроллеры DDR5 (12 каналов) и PCI Express 6.0/CXL 3.0. 
Источник изображения: Satoshi Matsuoka (X/@ProfMatsuoka) Процессор Monaka нацелен на широкий спектр рабочих нагрузок в дата-центрах. Для чипа не предусмотрено использование памяти HBM — вместо этого будет применяться DDR5, возможно, в реализациях MR-DIMM и MCR-DIMM. Упомянуты расширенные функции безопасности, включая Confidential Computing Architecture (CCA). Monaka предстоит конкурировать с процессорами AMD EPYC и Intel Xeon. Одним из главных преимуществ нового изделия перед этими чипами, по всей видимости, станет более высокая энергетическая эффективность. Fujitsu намерена начать продажи Monaka в течение 2027 финансового года, который у компании продлится с 1 апреля 2026-го до 31 марта 2027-го. |
|

