Материалы по тегу: компиляторы
|
17.05.2026 [16:24], Владимир Мироненко
Мейнфреймы тоже «поржавеют»: для IBM z готовится поддержка Rust в ядре LinuxЯн Поленски (Jan Polensky) представил первый набор патчей под названием «s390: включение поддержки Rust и добавление необходимой архитектурной привязки», позволяющих реализовать поддержку языка программирования Rust в сборке ядра Linux для мейнфреймов IBM z. Поддержка уже реализована для архитектур x86-64, ARM, ARM64, LoongArch и RISC-V, но не для s390, отметил ресурс Phoronix. И если Fujitsu готова распрощаться с мейнфреймами, то IBM это направление пока забрасывать не планирует. Она даже намерена «подружит» их с Arm. В примечаниях Ян Поленски сообщил, что поддержка Rust на s390 требует небольшого набора специфических для архитектуры компонентов, прежде чем можно будет использовать общую инфраструктуру ядра Rust: недостающие интерфейсы ассемблера, корректировка параметров сборки для избегания конфликтов и т.д. В настоящее время s390 требует «ночные» сборки rustc. Набор патчей затрагивает всего несколько десятков строк кода, поэтому есть надежда, они будут приняты уже в ядро Linux 7.2. Как отметил ресурс The Register, использование нерелизных версий компилятора Rust, включающих самые свежие изменения, экспериментальные функции и новые возможности, что предполагает нестабильную работу, вряд ли будет воспринято с энтузиазмом многими консервативными компаниями, работающими с мейнфреймами. Тем не менее, набор патчей Поленски — значительный шаг. 
Источник изображения: PalePink Green / Unsplash Когда Rust был добавлен в ядро в 2022 году, The Register упомянул проблему, которая редко поднимается где-либо ещё: хотя ядро обычно компилируется с помощью GCC, стандартный компилятор Rust — rustc — основан на LLVM. Список бэкендов LLVM хотя и растёт, но гораздо короче, чем набор из 48 компиляторов GCC. Существует экспериментальный фронтенд GCC для Rust, но он ещё не готов к полноценному использованию. Само ядро Linux поддерживает компиляцию с использованием LLVM с версии ядра 6.9, выпущенной более двух лет назад.
11.11.2025 [13:00], Сергей Карасёв
Стартап Spectral Compute по переносу CUDA-приложений на сторонние платформы получил на развитие $6 млнКомпания Spectral Compute, занимающаяся разработкой программной платформы SCALE для запуска CUDA-приложений на любых GPU-ускорителях, сообщила о проведении посевного раунда финансирования на сумму в $6 млн. Инвестиционная программа проведена при участии Costanoa, Crucible и ряда бизнес-ангелов. Стартап Spectral основан в 2018 году инженерами Майклом Сёндергаардом (Michael Søndergaard), Крисом Китчингом (Chris Kitching), Николасом Томлинсоном (Nicholas Tomlinson) и Франсуа Суше (Francois Souchay). Они обладают богатым опытом работы в сферах НРС, программирования GPU и пр. Штат компании на сегодняшний день насчитывает около 20 человек. Spectral развивает решение SCALE, которое обеспечивает компиляцию исходного кода CUDA напрямую в машинные инструкции для ускорителей на базе GPU, отличных от NVIDIA. На начальном этапе реализована возможность использования CUDA-приложений с изделиями AMD, а в дальнейшем планируется добавить поддержку ускорителей других производителей, включая Intel. Таким образом, компании смогут использовать одну и ту же кодовую базу для оборудования разных поставщиков, формируя кластеры ИИ и НРС на основе любых GPU, а не только решений NVIDIA. 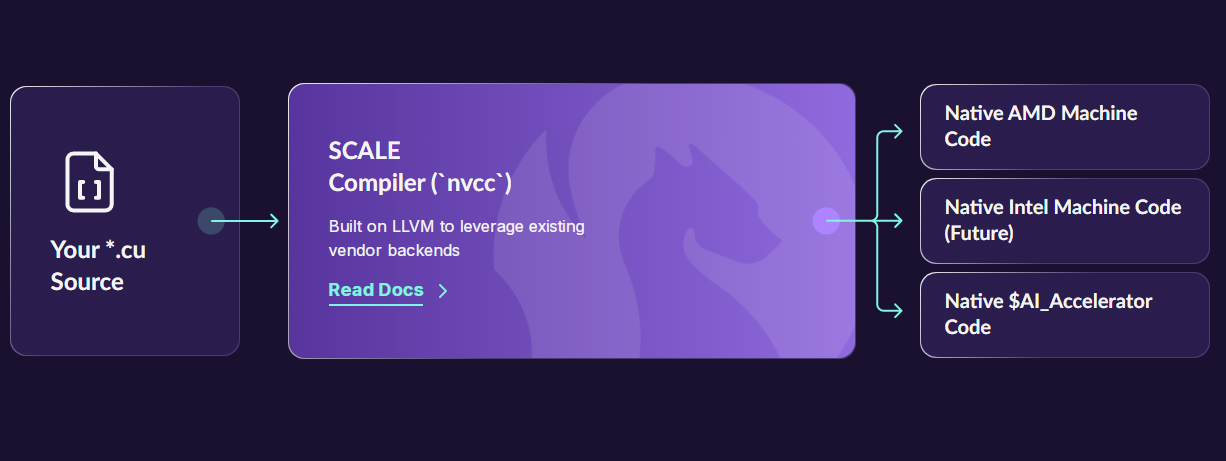
Источник изображения: Spectral Compute «Цель проекта SCALE заключается в том, чтобы предоставить организациям возможность использовать существующий код CUDA на любом графическом процессоре, будь то NVIDIA, AMD, Intel или другие изделия — без потери производительности или дорогостоящего переписывания кода», — говорит Сёндергаард. Привлечённые средства стартап намерен направить на дальнейшее развитие платформы SCALE, а также на увеличение численности персонала.
06.06.2025 [18:46], Руслан Авдеев
AMD продолжает шоппинг: компания купила стартап Brium для борьбы с доминированием NVIDIAВ последние дни компания AMD активно занимается покупками компаний, так или иначе задействованных в разработке ИИ-технологий. Одним из последних событий стала покупка стартапа Brium, специализирующегося на инструментах разработки и оптимизации ИИ ПО, сообщает CRN. AMD, по-видимому, всерьёз обеспокоилась развитием программной экосистемы после того, как выяснилось, что именно ПО не даёт раскрыть весь потенциал ускорителей Instinct. О покупке Brium, в состав которой входят «эксперты мирового класса в области компиляторов и программного обеспечения для ИИ», было объявлено в минувшую среду. Финансовые условия сделки пока не разглашаются. По словам представителя AMD, передовое ПО Brium укрепит возможности IT-гиганта «поставлять в высокой степени оптимизированные ИИ-решения», включающие ИИ-ускорители Instinct, которые играют для компании ключевую роль в соперничестве с NVIDIA. Дополнительная информация изложена в пресс-релизе AMD. В AMD уверены, что разработки Brium в области компиляторных технологий, фреймворков для выполнения моделей и оптимизации ИИ-инференса позволят улучшить эффективность и гибкость ИИ-платформы нового владельца. Главное преимущество, которое AMD видит в Brium — способность стартапа оптимизировать весь стек инференса до того, как модель начинает обрабатываться аппаратным обеспечением. Это позволяет снизить зависимость от конкретных конфигураций оборудования и обеспечивает ускоренную и эффективную работу ИИ «из коробки». В частности, команда Brium «немедленно» внесёт вклад в ключевые проекты вроде OpenAI Triton, WAVE DSL и SHARK/IREE, имеющие решающее значение для более быстрой и эффективной эксплуатации ИИ-моделей на ускорителях AMD Instinct. У технического директора Brium Квентина Коломбета (Quentin Colombet) десятилетний опыт разработки и оптимизации компиляторов для ускорителей в Google, Meta✴ и Apple. 
Источник изображения: AMD Компания сосредоточится на внедрении новых форматов данных вроде MX FP4 и FP6, которые уменьшают объём вычислений и снижают энергопотребление, сохраняя приемлемую точность моделей. В результате разработчики могут добиться более высокой производительности ИИ-моделей, снижая затраты на оборудование и повышая энергоэффективность. Покупка Brium также поможет ускорить создание open source инструментов. Это даст возможность AMD лучше адаптировать свои решения под специфические потребности клиентов из разных отраслей. Так, Brium успешно адаптировала Deep Graph Library (DGL) — фреймворк для работы с графовыми нейронными сетями (GNN) — под платформу AMD Instinct, что дало возможность эффективно запускать передовые ИИ-приложения в области здравоохранения. Такого рода компетенции повышают способность AMD предоставлять оптимальные решения для отраслей с высокой добавленной стоимостью и расширять охват рынка. Brium — лишь одно из приобретений AMD за последние дни для усиления позиций в соперничестве с NVIDIA, доминирование которой на рынке ИИ позволило получить в прошлом году выручку, более чем вдвое превышавшую показатели AMD и Intel вместе взятых. В числе последних покупок — стартап Enosemi, работающий над решениями в сфере кремниевой фотоники, поставщик инфраструктуры ЦОД ZT Systems, а также софтверные стартапы Silo AI, Nod.ai и Mipsology. Кроме того, совсем недавно компания купила команду Untether AI, не став приобретать сам стартап. |
|

