Лента новостей
|
08.09.2024 [13:23], Сергей Карасёв
Мировой рынок устройств информационной безопасности сократился в штукахКомпания International Data Corporation (IDC) обнародовала результаты исследования глобального рынка устройств информационной безопасности по итогам II квартала 2024 год. Отрасль демонстрирует разнородную динамику: в годовом исчислении продажи несколько возросли в деньгах, но сократились в штуках. Аналитики рассматривают такие продукты, как средства обнаружения и предотвращения вторжений (IPS), брандмауэры и пр. В период с апреля по июнь включительно их продажи составили около $4,25 млрд: это на 0,5 % больше по сравнению с аналогичным периодом 2023-го, когда затраты равнялись $4,23 млрд. Вместе с тем в натуральном выражении отгрузки сократились на 4,3 %, оказавшись на уровне 1 млн единиц. С географической точки зрения Канада и Япония оказались наиболее динамичными регионами с годовым ростом на 15,4 % и 10,3 % соответственно. Вместе с тем в Латинской Америке зафиксирован спад на 10,7 %, на Ближнем Востоке и в Африке — на 17,6 %. Одним из драйверов рынка названа интеграция в продукты сетевой безопасности функций на базе ИИ, которые улучшают производительность оборудования и расширяют его возможности. 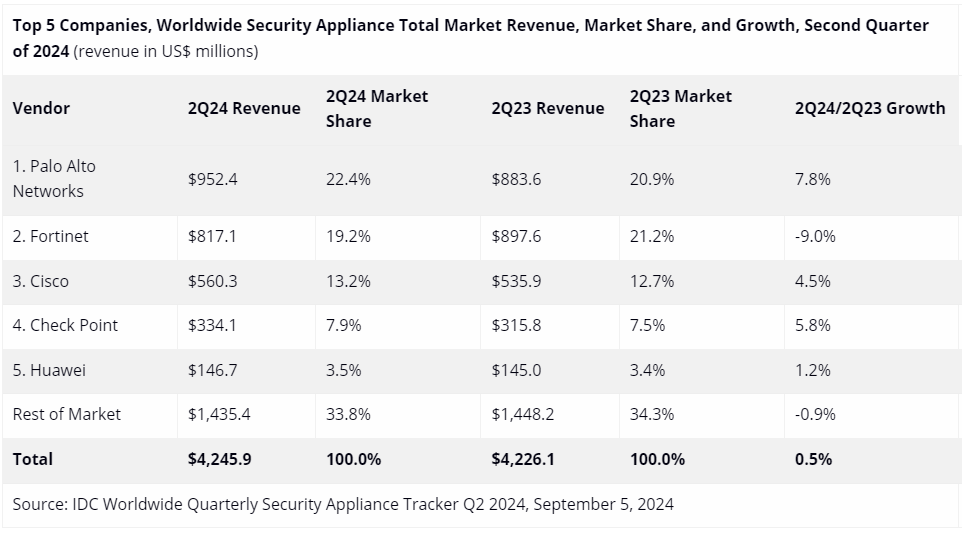
Источник изображения: IDC Лидером мирового рынка во II квартале 2024 года стала компания Palo Alto Networks с $952,4 млн выручки и долей 22,4 % против 20,9 % годом ранее. На втором месте располагается Fortinet с $817,1 млн: у этого поставщика показатель за год ухудшился с 21,2 % до 19,2 %. Замыкает тройку Cisco с $560,3 млн и 13,2 % отрасли, что больше прошлогоднего значения в 12,7 %. Далее идут Check Point и Huawei, которые продемонстрировали продажи в размере $334,1 млн и $146,7 млн соответственно: у первого из этих производителей доля за год поднялась с 7,5 % до 7,9 %, у второго — с 3,4 % до 3,5 %.
08.09.2024 [00:00], Владимир Мироненко
Broadcom столкнулась с самым большим падением акций с 2020 года, но намерена отыграться благодаря ИИ-решениямBroadcom Inc. объявила результаты за III квартал 2024 финансового года, закончившийся 4 августа. Несмотря на то, что в основном показатели были выше прогноза Уолл-стрит, акции компании упали более чем на 10 %, виной чему стал слабый прогноз по направлениям, не касающимся ИИ, пишет Bloomberg. Это было самое большое падение в течение дня за последние четыре года с первых дней пандемии в марте 2020 года. До падения акции компании выросли в этом году на 37 %. В III финансовом квартале выручка Broadcom составила $13,07 млрд, что на 47 % больше результата годичной давности с учётом дохода VMware или на 4 % больше без его учёта при консенсус-прогнозе аналитиков, опрошенных LSEG, в размере $12,97 млрд. При этом у компании были убытки (GAAP) $1,88 млрд или $0,40 на акцию, тогда как год назад у неё была прибыль в $3,3 млрд или $0,77 на акцию. Broadcom объяснила убыток единовременным налоговым резервированием в размере $4,5 млрд, связанным с торговлей правами на интеллектуальную собственность между сегментами компании в рамках управления цепочкой поставок. 
Источник изображений: Broadcom Вместе с тем компания сообщила о скорректированной прибыли (Non-GAAP) в размере $6,12 млрд или $1,24 на акцию, что выше консенсус-прогноза аналитиков в $1,20 на акцию. В отчётном квартале производство полупроводниковых продуктов принесло компании 56 % выручки или $7,27 млрд (рост — 5 %), доход от ПО составил $5,80 млрд (рост — 200 %). Скорректированная EBITDA составила $8,22 млрд или 63 % выручки.  В текущем квартале Broadcom планирует получить выручку в размере $14,0 млрд в то время, как аналитики прогнозируют скорректированную прибыль в размере $1,36 на акцию при ожидаемой выручке $14,04 млрд. Также прогнозируется скорректированная EBITDA в пределах 64% выручки. При этом компания ожидает получить за весь финансовый году $12 млрд выручки от продуктов, связанных с ИИ, что превышает среднюю оценку аналитиков в $11,8 млрд. Но это не спасло Broadcom от падения акций.  Гендиректор Broadcom Хок Тан сообщил, что большинство направлений компании по производству чипов, не связанных с ИИ, находятся на самом низком уровне или уже прошли через него и набирают обороты. Выручка от производства начала последовательно расти, хотя пока остаётся ниже, чем в прошлом году. По словам Тана, заказы — индикатор будущих продаж — выросли на 20%, и нет причин, чтобы производство не вернулось к прежним, более высоким уровням. «В целом мы достигли дна на наших рынках, не связанных с ИИ, и мы ожидаем восстановления в IV квартале, — сказал он в ходе телефонной конференции с участием аналитиков. — Спрос на ИИ остаётся высоким». Хок Тан также заявил, что рынок микросхем ИИ в долгосрочной перспективе перейдёт на индивидуальные внутренние разработки. Это означет отказ от решений NVIDIA, что будет на пользу Broadcom. По словам Тана этот процесс может занять несколько лет. Тан также сообщил, что поставки устройств следующего поколения для «североамериканского клиента» (Apple) позволят увеличить доход Broadcom в сегменте беспроводной связи в IV квартале на 20 %, хотя при этом он останется на уровне прошлого года. Отвечая на вопрос по поводу возможного следующего приобретения на рынке полупроводников, Тан сказал, что в ближайшее время этого не будет, поскольку он занят интеграцией активов VMware, а этот процесс может занять два года.
07.09.2024 [12:34], Сергей Карасёв
MSI выпустила низкопрофильную индустриальную Mini-ITX плату MS-CF13 с чипом Intel Alder Lake-NКомпания MSI анонсировала материнскую плату MS-CF13 типоразмера Mini-ITX, предназначенную для создания различных индустриальных устройств, встраиваемого оборудования, медицинских систем, комплексов видеонаблюдения и пр. Новинка выполнена на аппаратной платформе Intel Alder Lake-N. Изделие получило низкопрофильное исполнение. В зависимости от модификации применяется чип Intel Processor N97 (4 ядра, 4 потока; до 3,6 ГГц; 12 Вт), Core i3-N305 (8 ядер, 8 потоков; до 3,8 ГГц; 15 Вт) или Atom x7425E (4 ядра, 4 потока; до 3,4 ГГц; TDP 12 Вт). Во всех случаях присутствует встроенный контроллер Intel UHD Graphics. Задействовано пассивное охлаждение на основе крупного радиатора. Доступен один слот SO-DIMM для модуля оперативной памяти DDR5-4800 объёмом до 16 Гбайт. В оснащение входят один порт SATA-3 для накопителя, коннектор M.2 B-key 2242/3042/2280 (SATA/PCIe x1, USB 3.2 Gen2, USB 2.0, слот для карты nanoSIM) для сотового модема и разъём M.2 E-key 2230 (PCIe x1, USB 2.0) для адаптера Wi-Fi/Bluetooth. Есть двухпортовый сетевой контроллер Intel I226-V 2.5GbE, звуковой кодек Realtek ALC897, IO-чип Fintek F81966AB-I и ТРМ-контроллер Infineon SLB 9672VU2.0. 
Источник изображения: MSI Материнская плата располагает двумя портами USB 3.2 Gen2, одним портом USB 3.2 Gen1 и одним разъёмом USB 2.0, двумя гнёздами RJ-45 для сетевых кабелей, интерфейсами HDMI, DisplayPort и LVDS для вывода изображения на три дисплея одновременно, аудиогнездом на 3,5 мм. Через внутренние коннекторы можно использовать до шести последовательных портов. Плата имеет размеры 170 × 170 мм. Питание (12 В) подаётся через DC-разъём. Диапазон рабочих температур — от 0 до +60 °C. Заявлена совместимость с Windows 10 IoT Enterprise LTSC, Windows 11 IoT Enterprise и Linux.
07.09.2024 [12:34], Сергей Карасёв
EPAM Systems купила поставщика IT-услуг Neoris за $630 млнАмериканский разработчик ПО с белорусскими корнями EPAM Systems объявил о заключении соглашения по приобретению компании Neoris — поставщика IT-услуг в Латинской Америке. Сумма сделки составляет $630 млн, а её закрытие ожидается в IV квартале 2024 года после получения необходимых разрешений со стороны регулирующих органов. Neoris, основанная в 2000 году мексиканским гигантом по производству строительных материалов Cemex, обслуживает более 400 клиентов из различных отраслей, включая производство, банковское дело, телекоммуникации и розничную торговлю. Компания оказывает услуги в таких сферах, как цифровой опыт, инжиниринг, аналитика данных, машинное обучение, ИИ, цифровые стратегии и пр. 
Источник изображения: Neoris Хотя Neoris работает уже более двух десятилетий, её наиболее активный рост начался во время пандемии COVID-19, когда клиенты ускорили свою цифровую трансформацию. В 2022 году Neoris получила существенные инвестиции от Advent International. Штаб-квартира Neoris располагается в Майами (Флорида, США), а штат насчитывает более 4700 специалистов. В качестве продавцов Neoris выступают фонды, управляемые Advent International. Консультантами в рамках сделки являются Orrick, Simpson Thacher & Bartlett, Creel, García-Cuéllar, Aiza y Enríquez, Martínez, Quintero, Mendoza, Gonzáles, Laguado, & De la Rosa, DLA Piper, Freshfields Bruckhaus Deringer, Pérez-Llorca и Canaccord Genuity. Благодаря этому приобретению EPAM намерена укрепить присутствие в Латинской Америке. Neoris работает в шести странах региона — в Аргентине, Перу, Мексике, Бразилии, Чили и Колумбии. Кроме того, эта компания имеет центры в Чехии, Венгрии и Испании. До сих пор деятельность EPAM в Латинской Америке ограничивалась Колумбией, Мексикой и Доминиканской Республикой.
07.09.2024 [11:41], Сергей Карасёв
Micron представила 12-ярусные чипы HBM3E: 36 Гбайт и 1,2 Тбайт/сКомпания Micron Technology сообщила о начале пробных поставок 12-ярусных (12-Hi) чипов памяти HBM3E, предназначенных для высокопроизводительных ИИ-ускорителей. Изделия проходят квалификацию в экосистеме отраслевых партнёров, после чего начнутся их массовые отгрузки. Новые чипы имеют ёмкость 36 Гбайт, что на 50 % больше по сравнению с существующими 8-слойными вариантами HBM3E (24 Гбайт). При этом, как утверждает Micron, достигается значительно более низкое энергопотребление. Благодаря применению 12-ярусных чипов HBM3E крупные модели ИИ, такие как Llama 2 с 70 млрд параметров, могут запускаться на одном ускорителе. 
Источник изображений: Micron Заявленная пропускная способность превышает 9,2 Гбит/с на контакт, что в сумме обеспечивает свыше 1,2 Тбайт/с. Появление новой памяти поможет гиперскейлерам и крупным операторам дата-центров масштабировать растущие рабочие нагрузки ИИ в соответствии с запросами клиентов. Реализована полностью программируемая функция MBIST (Memory Built-In Self Test), которая способна работать на скоростях, соответствующих системному трафику. Это повышает эффективность тестирования, что позволяет сократить время вывода продукции на рынок и повысить надёжность оборудования. При изготовлении памяти HBM3E компания Micron применяет современные методики упаковки чипов, включая усовершенствованную технологию сквозных соединений TSV (Through-Silicon Via).  Нужно отметить, что о разработке 12-слойных чипов HBM3E ёмкостью 36 Гбайт в начале 2024 года объявила компания Samsung. Эти решения обеспечивают пропускную способность до 1,28 Тбайт/с. По данному показателю, как утверждается, чипы более чем на 50 % превосходят доступные на рынке 8-слойные стеки HBM3. Наконец, старт массового производства 12-Hi модулей HBM3E от SK hynix с ПСП 1,15 Тбайт/с намечен на октябрь.
07.09.2024 [11:32], Сергей Карасёв
Toshiba представила SATA HDD серии N300 вместимостью до 22 Тбайт для NASКорпорация Toshiba анонсировала обновлённое семейство жёстких дисков N300 в форм-факторе LFF с интерфейсом SATA-3. Эти накопители спроектированы для сетевых хранилищ (NAS), а поэтому допускают эксплуатацию в круглосуточном режиме 24/7. Устройства выполнены по технологии традиционной магнитной записи (CMR). В серию вошли модели вместимостью 2, 4, 6, 8, 10, 12, 14, 16, 18, 20 и 22 Тбайт. Объём буфера варьируется от 64 до 512 Мбайт. Частота вращения шпинделя — 7200 об/мин. Скорость чтения информации достигает 281 Мбайт/с, скорость записи — 268 Мбайт/с. 
Источник изображения: Toshiba У модификаций ёмкостью 12 Тбайт и более герметичная камера заполнена гелием, благодаря чему достигается снижение энергопотребления при одновременном повышении плотности хранения данных. HDD подходят для NAS, насчитывающих до восьми дисков. Встроенные датчики угловых колебаний сводят к минимуму возможность распространения вибрации в хранилищах с несколькими отсеками. Кроме того, решения серии N300 отличаются более высокой прочностью, чем обычные HDD. В накопителях реализована фирменная технология Toshiba Dynamic Cache, которая оптимизирует выделение кеша в процессе чтения и записи для повышения производительности. Диапазон рабочих температур в зависимости от модели простирается от 0 до +65 °C или от +5 до +60 °C. Заявленный показатель MTBF (средняя наработка на отказ) — 1 или 1,2 млн часов. На устройства предоставляется трёхлетняя гарантия.
07.09.2024 [00:29], Владимир Мироненко
ИИ на экспорт: ГК Softline открыла во Вьетнаме представительство для продвижения своих решений в регионеГК Softline (ПАО «Софтлайн») сообщила об открытии представительства в Хошимине, главном экономическом центре Вьетнама. В рамках ранее анонсированной стратегии международной экспансии компания выходит на рынки дружественных стран. Ранее также было открыто представительство в ОАЭ для доступа на рынки ближневосточных стран и в Казахстане — для выхода на рынки Центральной Азии. Открытие представительства во Вьетнаме компания объяснила намерением продвигать в регионе портфель собственных продуктов и услуг, в частности отраслевых ИТ-решений на основе ИИ и решений в области информационной безопасности. Кроме того, ГК Softline планирует содействовать расширению присутствия российских вендоров для совместного продвижения технологий в регионе. 
Источник изображения: Chris Slupski / Unsplash Выбор Вьетнама для размещения хаба в Юго-Восточной Азии обусловлен высокими темпами роста цифровизации экономики страны, которая занимает по этому показателю лидирующие позиции в регионе, говорит Softline. Правительство содействует развитию ИТ-отрасли, а компании активно внедряют передовые технологии. В стране реализуется национальная стратегия исследований, разработки и применения ИИ до 2030 года. По данным Всемирного банка, темпы роста цифровой экономика Вьетнама составляют 10 % в год и к 2045 году она может превысить $200 млрд. По словам Softline, прежде чем принять это решение, были проведены собственные рыночные исследования. Также компания приняла участие в профильных выставках и конференциях, на которых представила свои продукты и решения. Отмечено положительное отношение к российским ИТ-решениям и более широкие возможности подбора квалифицированных технических специалистов по сравнению с другими странами региона. Среди населения достаточно высокий уровень владения английским языком, а немало топ-менеджеров заказчиков также владеет русским языком, что упрощает коммуникации.
07.09.2024 [00:14], Владимир Мироненко
HPE увеличила выручку благодаря растущим продажам ИИ-серверов, но в результате валовая прибыль снизилась, а акции компании упалиHewlett Packard Enterprise (HPE) сообщила финансовые результаты III квартала 2024 финансового года, завершившегося 31 июля 2024 года. Выручка компании составила $7,71 млрд, превысив результат аналогичного квартала предыдущего года на 10 % и консенсус-прогноз Zacks на 0,56 %. Скорректированная прибыль на акцию (Non-GAAP) составила $0,50, превысив на 2 % прошлогодний показатель и на 19 % результат предыдущего квартала, а также консенсус-прогноз Zacks в размере $0,46 на акцию и собственный прогноз компании в пределах $0,43–$0,48. Чистая прибыль HPE (GAAP) выросла на 10,3 % до $512 млн с $464 млн годом ранее. Чистая прибыль на акцию (GAAP) составила $0,38, что на 9 % больше год к году и на 58 % больше показателя предыдущего квартала, также превысив собственный прогноз компании в пределах от $0,29 до $0,34 на акцию. Величина ARR (годовой регулярный доход) выросла год к году на 35 % до $1,7 млрд. Подразделение по выпуску серверов принесло $4,28 млрд выручки, что на 35 % больше в годовом исчислении. В то же время выручка подразделения Intelligent Edge упала на 23 % до $1,12 млрд, а у подразделения Hybrid Cloud снизилась на 7 % до $1,3 млрд. Доходы от финансовых сервисов (Financial Services) выросли на 1 % до $879 млн. 
Источник изображений: HPE Продажи традиционных серверов HPE выросли на двузначные числа в процентах как по сравнению с предыдущим кварталом, так и год к году, поскольку спросу способствовал переход на ProLiant 11-го поколения. HPE сообщила, что заказы на серверные системы для ИИ выросли на $1,6 млрд по сравнению с предыдущим кварталом, с $4,6 млрд до $6,2 млрд, а доход от их продаж составил $1,3 млрд. Выручка от систем ИИ теперь составляет 30 % от общего дохода от продаж серверных систем, по сравнению с 10 % годом ранее. Отвечая на вопрос, вытесняют ли ИИ-серверы традиционные серверы ProLiant, гендиректор Антонио Нери (Antonio Neri) сообщил: «Мы не видим признаков каннибализации. Рабочие нагрузки ИИ отличаются и не заменяют традиционные рабочие нагрузки. В частности, корпоративный сегмент продолжает демонстрировать высокий спрос на традиционные серверы». Вместе с тем рост продаж ИИ-серверов оказал отрицательное влияние на валовую прибыль HPE (GAAP), снизившуюся год к году на 420 базисных пункта до 31,6 %, поскольку уровень дохода в этом случае ниже, чем для традиционных серверов. В связи с этим акции компании упали на 3 %. 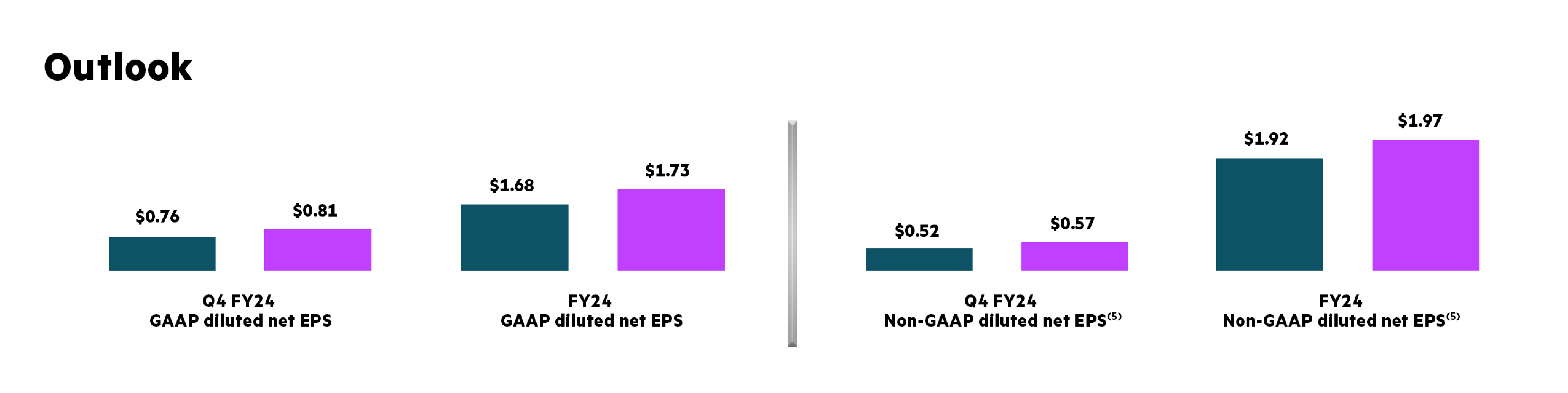 Заказы хранилищ Alletra и гибридных облачных предложений SaaS выросли год к году на двузначные числа в процентах. Количество клиентов облака GreenLake увеличилось почти на 3 тыс. по сравнению с предыдущим кварталом и на 10 тыс. в годовом исчислении — до 37 тыс. В IV финансовом квартале HPE ожидает получить выручку в размере $8,25 млрд +/- $125 млн, что на 12,2 % больше год к году в среднем значении, а также скорректированную прибыль на акцию (non-GAAP) в диапазоне $0,52– $0,57. Прогноз на весь 2024 финансовый год по выручке составляет $29,92 млрд, что на 2,7 % больше, чем в предыдущем финансовом году, а по скорректированной прибыли на акцию (non-GAAP) — $1,92– $1,97.
06.09.2024 [18:36], Сергей Карасёв
3,5″ одноплатный компьютер ECS ADLN-IE1 на базе Intel Alder Lake-N получил два 2.5GbE-портаКомпания ECS анонсировала индустриальный одноплатный компьютер ADLN-IE1, предназначенный для создания систем автоматизации, управления и пр. Изделие выполнено в 3,5″ форм-факторе, а в основу положена аппаратная платформа Intel Alder Lake-N. Новинка располагает одним слотом SO-DIMM для модуля DDR5-4800 (non-ECC) и портом SATA-3 для накопителя. Предусмотрены три коннектора M.2 — для SSD, адаптера Wi-Fi и сотового модема 4G/5G (плюс слот для SIM-карты). В оснащение входят двухпортовый сетевой контроллер 2.5GbE и звуковой кодек Realtek ALC892. 
Источник изображения: ECS Обработкой графики занят интегрированный в CPU ускоритель Intel UHD Graphics. Допускается одновременный вывод изображения на три дисплея — через два интерфейса HDMI (до 3840 × 2160 пикселей) и коннектор LVDS. В набор разъёмов также входят четыре порта USB 3.2 Gen2 Type-A и два гнезда RJ-45 для сетевых кабелей. Через коннекторы на самой плате можно задействовать четыре последовательных порта и два порта USB 2.0. Имеется колодка GPIO. Одноплатный компьютер получает питание через 4-контактный коннектор (в диапазоне 9–36 В). Размеры составляют 146 × 102 мм. Отмечается, что изделие выполнено с применением золотых контактов 15μ и исключительно твердотельных конденсаторов, что повышает надёжность и увеличивает срок службы. Заявлена совместимость с Windows 11. Говорится также о широком диапазоне рабочих температур, но точные значения не приводятся.
06.09.2024 [18:32], Руслан Авдеев
NVIDIA и другие инвесторы вложили $160 млн в оператора ИИ ЦОД Applied DigitalВзрывной рост ИИ сделал индустрию ЦОД одной из самых привлекательных сфер для вложения средств. Как сообщает The Register, NVIDIA совместно с другими инвесторами намерена вложить $160 млн в техасского оператора дата-центров Applied Digital, ранее известного как Applied Blockchain. Это не первый заметный игрок на рынке майнинговых ЦОД, которые переключился на ИИ и получил поддержку NVIDIA. Акции Applied Digital торгуются на Nasdaq, но по данным Silicon Angle, в данном случае компания привлекла финансирование посредством т.н. «частного размещения» (private placement), которое предусматривает прямую передачу акций инвесторам без посредничества биржи. При этом в сделке обычно участвуют заранее одобренные компании. Applied Digital выпустила 49,38 млн акций по $3,24 за каждую. Applied Digital занимается строительством дата-центров с СЖО для высокоплотных вычислений. Компания также сдаёт в аренду кластеры ускорителей, в частности, NVIDIA H200 и A40. Облачное подразделение — довольно весомая часть бизнеса Applied Digital. В финансовом году, закончившемся 31 марта, на его долю пришлось $29 млн из $165,6 млн общей выручки. За четыре последних месяца в эксплуатацию введено четыре новых ИИ-кластера, а ещё два запустят в ближайшие месяцы. 
Источник изображения: Applied Digital В августе Applied Digital объявила о строительстве 400 МВт ёмкостей для неназванного американского облачного оператора. Речь идёт о строящемся 100-МВт кампусе в Эллендейле (Северная Дакота) и двух других объектах. По данным СМИ, $160 млн новых инвестиций потратят на создание основы для раундов долгового финансирования, а оно уже будет истрачено на расширение кампуса ЦОД в Северной Дакоте и облачные инициативы компании. Интересно, что именно в этом штате две неизвестных компании готовы потратить $250 млрд на гигантские ИИ ЦОД. Поскольку передовые ускорители NVIDIA стоят порядка $30-40 тыс. каждый, некоторые операторы вынуждены обращаться за крупными займами. Так, в июле оператор CyrusOne занял $7,9 млрд для покупки новейших ускорителей, не считая $1,8 млрд, привлечённых ещё весной. В мае CoreWeave привлекла $1,1 млрд, а несколькими неделями позже убедила инвесторов одолжить ещё $7,5 млрд. Lambda Labs начала текущий год с раунда финансирования на $320 млн, ещё $500 млн она привлекла весной и теперь планирует закупить десятки тысяч новых ускорителей. Помимо традиционных венчурных инвесторов вроде BlackRock, Magnetar Capital и Coatue, в некоторых из подобных проектов участвует и сама NVIDIA, ранее уже поддерживавшая CoreWeave, которая прославилась тем, что взяла в долг $2,3 млрд под залог ускорителей, чтобы купить ещё больше ускорителей. Мотивация NVIDIA очевидна — продавать ускорители компания сможет до тех пор, пока на них есть спрос, а спрос может обеспечить только строительство новых дата-центров. |
|

