Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 6.0. В нём появилось два новых теста — DeepSeek V3 и GPT-OSS 20B, что подчёркивает общеотраслевой переход к разреженным вычислениям, примером которого является архитектура MoE (Mixture-of-Experts).
DeepSeek V3 — крупномасштабная MoE-модель c 671 млрд параметров, из которых 37 млрд активируются для генерации отдельного токена. Она предоставляет стандартизированную платформу для оценки эффективности обучения ведущей модели MoE с открытыми весами. GPT-OSS 20B — MoE-модель c 21 млрд параметров, из которых 3,6 млрд активируются для генерации одного токена. Она позволяет организациям оценивать сложную логику маршрутизации и шаблоны разреженных вычислений, характерные для архитектуры MoE, на аппаратных конфигурациях размером всего в один узел с восемью ускорителями.
Версия MLPerf Training 6.0 установила новые рекорды по разнообразию представленных систем. Участники выложили результаты 95 уникальных систем, использующих тринадцать различных аппаратных ускорителей, 19 различных хост-процессоров и несколько различных программных фреймворков. 60 % систем были многоузловыми. При этом количество представленных облачных систем более чем вдвое больше, чем в раунде 5.1.

Источник изображения: NVIDIA
В раунде MLPerf Training v6.0 представлены заявки от 24 организаций: AMD, ASUSTeK, Azure, Cisco, CoreWeave, Dell, Fujitsu, GigaComputing, Google, HPE, Inventec, Krai, Lambda, MITAC, Nebius, Netweb Technologies India, NVIDIA, Oracle, Quanta Cloud Technologies, SCITIX, Supermicro, tinycorp, TTA и Vultr. «Мы особенно рады приветствовать участников, впервые представляющих свои результаты в MLPerf Training: Inventec, Netweb Technologies India, TTA и Vultr», — сообщил Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons.
NVIDIA вновь стала лидером в новом раунде MLPerf Training, причём во всех тестах, в очередной раз став единственной платформой, которая предоставила результаты по всем тестам. Также NVIDIA была единственной платформой, представившей результаты по новым тестам, при этом система NVIDIA GB300 NVL72 «установила планку производительности благодаря оптимизированным программным стекам NVIDIA и конструкции, объединяющей 72 GPU Blackwell Ultra и 36 CPU Grace с использованием NVLink и NVLink Switch».
В нескольких случаях партнёры NVIDIA масштабировали систему до 8192 ускорителей Blackwell, работающих согласованно в различных ЦОД. Эти результаты подтвердили реальную надёжность платформы Blackwell в масштабируемых кластерных средах, говорит NVIDIA.
Источник изображения: NVIDIA
Для достижения максимальной производительности таких моделей, как DeepSeek-V3, NVIDIA в этом раунде MLPerf Training применила несколько программных оптимизаций, включая использование итерационных графов CUDA для MoE без удаления токенов, применение CuTe DSL для продвинутых операций слияния ядер, алгоритм внимания MXFP8 для повышения производительности без ущерба для качества модели, оптимизацию маршрутизатора и оптимизацию схемы коммуникации 1F1B all-to-all overlap. Также NVIDIA оптимизировала компоновку и баланс параллельных этапов конвейера, минимизируя структурное простаивание.
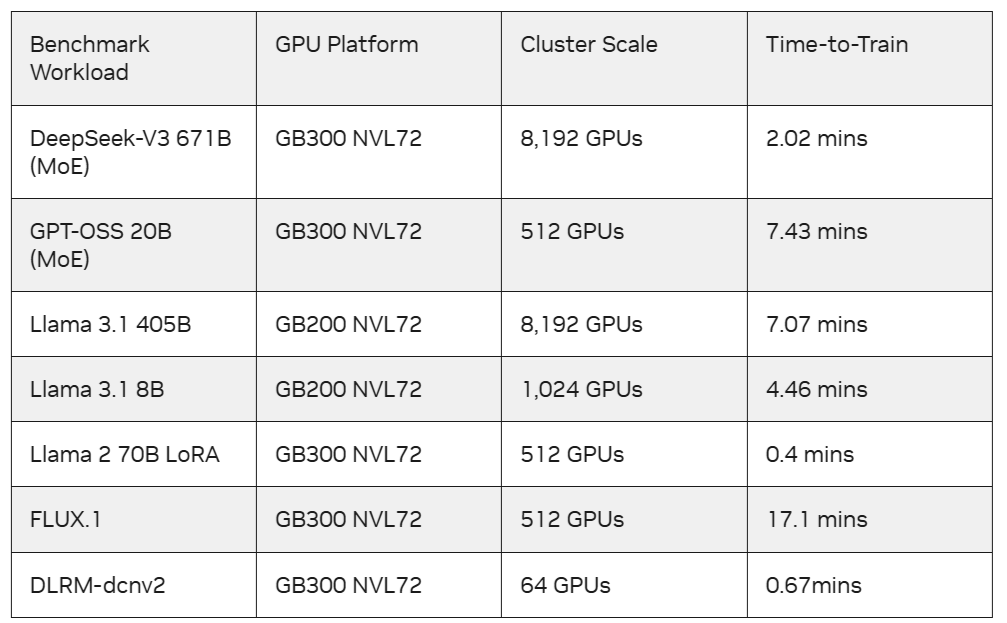
Для обработки DeepSeek-V3 671B компания NVIDIA использовала до 8192 GPU в системах GB200 NVL72, что стало самым масштабным результатом на основе Blackwell в MLPerf Training на сегодняшний день. NVIDIA также представила результаты на 5120 GPU с системами NVIDIA GB200 NVL72 в Llama 3.1 405B, одной из самых крупных LLM плотной архитектуры в этом бенчмарке.
Результаты этого раунда также отражают тесное сотрудничество NVIDIA с компаниями-партнёрами в области системной архитектуры, сетей и ПО. Например, Microsoft Azure масштабировала обучение Llama 3.1 405B до 8192 GPU, используя системы GB200 NVL72, и достигла целевого эталонного значения за 7,07 мин., что является самым быстрым временем обучения для этого бенчмарка. А CoreWeave показала самое быстрое время обучения для DeepSeek-V3 671B, достигнув целевого качества за 2,02 мин. на 8192 GPU в составе GB300 NVL72, объединённых Spectrum-X Ethernet.
Источники:

