Материалы по тегу: big data
|
27.11.2024 [19:42], Руслан Авдеев
Интернет-квартирография: «Телеком Радар» от VK позволит провайдерам оценить качество услуг связиVK обеспечила бизнес-клиентов новым инструментарием. Сервис «Телеком Радар» для телеком-операторов позволяет анализировать качество связи и принимать решения о модернизации инфраструктуры. Пресс-служба компании сообщает, что им смогут воспользоваться операторы широкополосного доступа в Сеть. Так, клиенты получат возможность оценить долю на рынке кабельного интернета в том или ином регионе и, основываясь на полученной статистике, сравнивать уровень своих сервисов с показателями конкурентов, искать проблемы со связью и обеспечивать рост качества услуг для своих клиентов. «Телеком Радар» находится в ведении VK Predict — его используют и крупнейшие операторы мобильной связи для анализа качества соединения в привязке к конкретным локациям. Показатели можно сравнивать с данными конкурентов или определять долю рынка в том или ином регионе. Как сообщают в компании, анализ качества связи основан в первую очередь на параметрах потребления видео, который является не только популярным, но и одним из самых «тяжёлых» видов контента, требующего устойчивого широкополосного соединения. «Телеком Радар» позволяет оценить пользовательский опыт, реальное покрытие сети на местах, а также получить данные, которые помогут оценить необходимость модернизации инфраструктуры. В частности, это позволит сохранить лояльность абонентов и избежать их оттока. 
Источник изображения: VK Predict Как сообщают в VK Predict, точность геопозиционирования «Телеком Радара» даёт возможность определять, в каких населённых пунктах с покрытием не всё благополучно, проверять состояние инфраструктуры, а также спланировать её обновление и оценить итоговый результат. Операторы кабельной инфраструктуры могут распознавать проблемы со связью, например, в многоквартирных домах, в том числе в случае перегрузки сети одним пользователем. Также можно оценить изменение числа абонентов и эффект маркетинговых кампаний, перспективы расширения инфраструктуры по новым адресам и другие параметры. Сервис, как утверждают в компании, оценивает реальный опыт взаимодействия пользователей с продуктами группы VK, в том числе метрики просмотров видео на площадках ВКонтакте и VK Видео. Клиенты получают аналитику на основе агрегированных обезличенных данных. Для аналитики используются как классические программные инструменты, так и ИИ-алгоритмы. В числе ключевых решений не только «Телеком Радар», но и «ГеоКурсор» для анализа разных локаций, а также «Девелопер» для «оптимальной квартирографии» в жилых комплексах. Наконец, Predict AutoML предназначен для конструирования решений на основе алгоритмов машинного обучения без привлечения опытных IT-специалистов. В VK Predict предлагаются и другие бизнес-сервисы.
01.10.2024 [21:45], Владимир Мироненко
«Группа Аренадата» привлекла 2,7 млрд рублей в ходе IPOПАО «Группа Аренадата» (Группа Arenadata), российский разработчик ПО для систем управления и обработки данных, объявило об успешном проведении первичного публичного предложения (IPO), прошедшего по верхней границе ценового диапазона. Сообщается, что «Группа Аренадата» стала первой публичной компанией среди разработчиков системного ПО для работы с данными. Стоимость акции составила 95 руб., а оценка рыночной капитализации компании достигла 19 млрд руб. В ходе IPO со стороны текущих акционеров было предложено 28 млн акций на сумму около 2,7 млрд руб. по цене IPO, включая 2,8 млн акций, которые могут быть использованы для стабилизации цены акций на вторичных торгах в период до 30 дней после начала торгов. В результате IPO акционерами группы стали около 30 тыс. частных инвесторов. Акции были распределены между категориями инвесторов в следующей пропорции: 57 % получили институциональные инвесторы, 27 % — розничные инвесторы и 16 % — партнёры продающих акционеров. Аллокация (распределение акций) розничным инвесторам составила около 5 %. Каждый розничный инвестор получил не менее 1 акции, те, кто подал более 10 заявок, не получили аллокации. 
Источник изображения: «Группа Аренадата» Как отметил в интервью «Агентству Бизнес Новостей» представитель ПАО «Группа Аренадата», на размер аллокации повлиял «размер сделки, повышенный интерес как со стороны институциональных инвесторов — крупнейших УК, инвестиционных фондов, так и со стороны частных инвесторов». По данным «Агентства Бизнес Новостей», в ходе IPO Iva Technologies аллокация среди розничных инвесторов составила 5–10 %, столько же у IT-компании Positive Technologies и 4 % — у «Группы Астра». После выхода на биржу доля акций в свободном обращении (free-float) составит порядка 14 % от акционерного капитал группы. Акции под тикером DATA и ISIN RU000A108ZR8 были включены во второй уровень листинга Московской биржи. Первые торги акциями «Группы Аренадата» прошли сегодня, 1 октября 2024 года. Компания была основана в 2015 году как дочерняя структура IBS, но впоследствии отделилась от родительской компании. В 2017 года компания представила свой первый продукт — Arenadata Hadoop. В дальнейшем на рынок были выведены Arenadata DB, Arenadata QuickMarts, Arenadata Cluster Manager, Arenadata Streaming, Arenadata Postgres и т.д. По состоянию на 2023 году объём данных на платформе Arenadata превысил 60 Пбайт.
24.09.2024 [14:45], Андрей Крупин
VK создала собственную платформу для работы с большими объёмами данных и машинным обучениемЗанимающаяся разработкой корпоративного ПО компания VK Tech (входит в экосистему VK) сообщила о запуске Data Platform — платформы для комплексной работы с большими объёмами данных, нейросетями и искусственным интеллектом. В течение трёх лет в VK намерены инвестировать в новое решение и связанные с ним сервисы до 4 млрд руб. VK Data Platform относится к категории универсальных инструментов Enterprise Data Platform (EDP) и позволяет решать широкий спектр задач: от хранения и обработки данных до выполнения аналитических процессов и разработки моделей машинного обучения. В основу платформы положены собственные разработки компании, в частности, Tarantool и S3-совместимое хранилище Cloud Storage, и доработанные VK технологии, среди которых Trino, PostgreSQL, Airflow и многие другие. 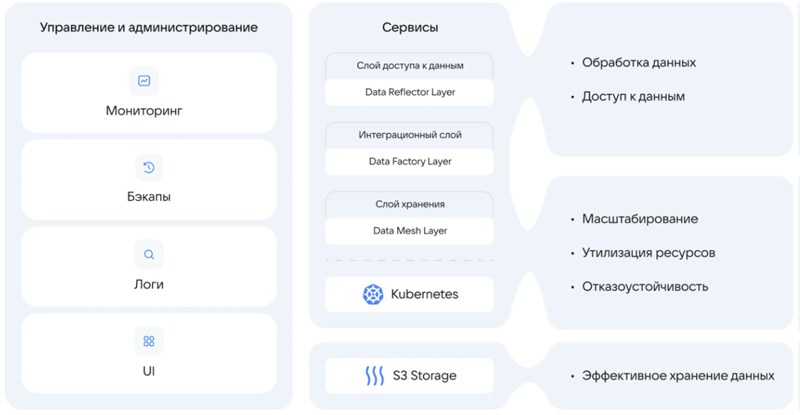
Функциональная архитектура VK Data Platform Компоненты VK Data Platform разворачиваются на основе Kubernetes. Это позволяет динамически распределять вычислительные мощности, эффективно утилизировать аппаратное обеспечение и предоставлять высокий уровень отказоустойчивости. Пользователям доступны централизованные инструменты мониторинга, создания резервных копий данных и графический интерфейс для управления платформой. Платформа может быть развёрнута на различных типах инфраструктуры, включая публичные и частные облака, а также собственные серверы заказчика. В ней предусмотрены типовые архитектуры на основе Data WareHouse, Data Lake, LakeHouse и Data Mesh, MLOps-конвейеров, а также конфигурации для систем с высокой транзакционной нагрузкой. По заверениям разработчика, это позволяет быстро адаптировать её под задачи любой компании и ускоряет интеграцию решения в корпоративный IT-ландшафт.
10.06.2024 [22:02], Владимир Мироненко
Не хочешь конкурировать — купи: Databricks приобрела Tabular за $1+ млрд, чтобы унифицировать озёра данныхАмериканский стартап в сфере аналитики больших данных и машинного обучения Databricks объявил о приобретении компании по управлению данными Tabular. Точная сумма сделки не раскрывается, но глава Databricks Али Годси (Ali Ghodsi) сообщил в интервью CNBC, что стоимость покупки превышает $1 млрд. Соучредители Tabular присоединятся к Databricks, где будут работать над объединением клиентских баз и сообществ Tabular и Databricks. Компания Tabular была основана ими в 2021 году. Она предлагает продукты для управления данными, созданные на основе Apache Iceberg — проекта, которым создатели Tabular занимались в Netflix и позже передали в дар фонду Apache Software Foundation. Iceberg — открытый формат для таблиц сверхбольших данных. Databricks предлагает объектно-ориентированное озеро данных Lakehouse на базе собственного открытого формата Delta Lake. 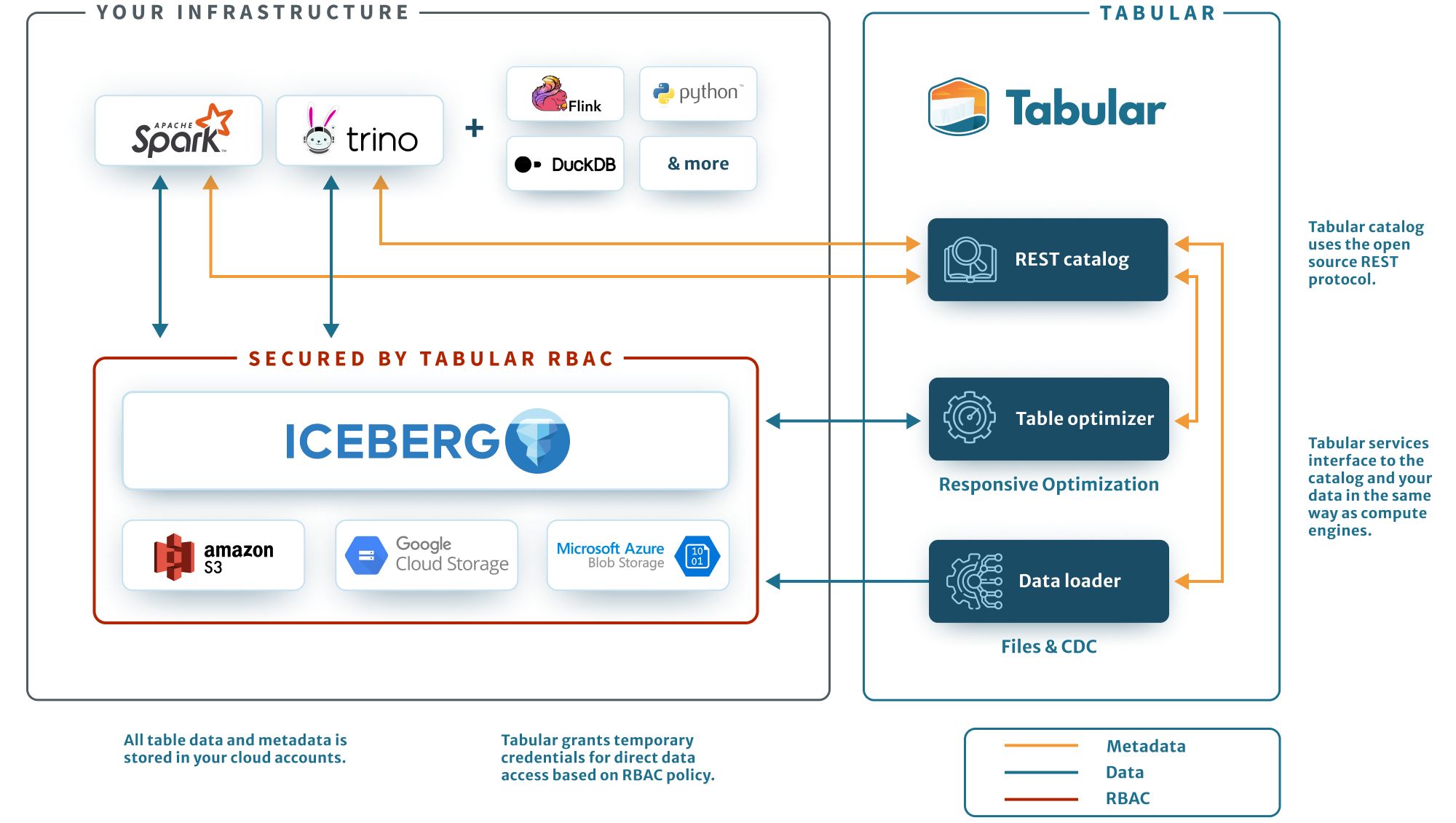
Источник изображения: Tabular С момента создания Delta Lake в проекте приняли участие более 500 разработчиков. Более 10 тысю компаний по всему миру используют Delta Lake для обработки в среднем более 4 Эбайт данных каждый день. Это быстрорастущий бизнес, но Iceberg-решения не менее популярны и конкурируют с решениями Databricks, отметил ресурс Blocks & Files. При этом о полной совместимости между Iceberg и Delta Lake речи не было. Но в 2023 году компания также представила UniForm-таблицы, позволяющие работать с Delta Lake, Iceberg и Hudi. А после поглощения Databricks будет тесно сотрудничать с сообществами Delta Lake и Iceberg для разработки совместимых форматов озёр данных. В краткосрочной перспективе это будет реализовано в рамках Delta Lake UniForm, а в долгосрочной перспективе будет создан единый, открытый и общий стандарт.
09.10.2023 [12:41], Сергей Карасёв
К 2030 году в России может появиться единое доверенное хранилище данныхАНО «Цифровая экономика», по сообщению газеты «Ведомости», предлагает сформировать в России единое доверенное хранилище данных. Предполагается, что такая платформа будет развёрнута к 2030 году, что поможет в развитии государственных сервисов и бизнес-систем. С инициативой выступает группа экспертов, возглавляемая вице-президентом «Ростелекома» Борисом Глазковым. Говорится, что к концу текущего десятилетия «90 % обработанных данных в обезличенном или персонифицированном виде доступны государству, бизнесу и гражданам в едином доверенном источнике для развития data driven госуправления и бизнеса в РФ». 
Источник изображения: pixabay.com Под термином «data driven госуправление» подразумевается разработки и реализации государственной политики, в которой принятие решений и формулирование политических стратегий основаны на обширном сборе, анализе и использовании всевозможных данных. Получаемая из различных источников информация может быть использована для оценки текущей ситуации, выявления проблем и проработки потенциальных решений, а также для анализа воздействия политики на общество. 3 сентября 2023 года президент России Владимир Путин поручил утвердить национальный проект по формированию экономики данных на период до 2030-го. Инициатива предусматривает сбор информации, в том числе с использованием высокочувствительных датчиков на основе квантовых сенсоров. Кроме того, должна быть создана инфраструктура вычислений и хранения данных с использованием отечественных оборудования, технологий и программного обеспечения, в том числе облачных платформ, ЦОД и вычислительных мощностей. Участники рынка говорят, что сбор и обработка огромного объёма данных технически возможны с использованием современных технологий, но требуют мощных вычислительных ресурсов. Для формирования единого хранилища потребуется принятие новых законодательных норм, гарантирующих «безопасность данных и защиту личной конфиденциальности». В целом, проект может помочь в создании отечественного ПО, поскольку разработчикам часто не хватает данных для проверки гипотез и написания более эффективных приложений.
19.09.2023 [00:13], Владимир Мироненко
NeuroBlade интегрирует SQL-ускорители SPU с VeloxСтартап NeuroBlade, специализирующийся на разработке решений для ускорения анализа данных, объявил о сотрудничестве с сообществом Velox компании Meta✴ Platforms с целью интеграции ускорителя SQL Processing Unit (SPU) в новый унифицированный фреймворк для работы с данными. Как отметили в NeuroBlade, полная интеграция SPU NeuroBlade в Velox обеспечивает ускорение обработки данных более чем в 10 раз, помимо трёхкратного повышения производительности, уже достигнутого Velox за счет оптимизации ПО. Цель проекта заключается в том, чтобы дать компаниям возможность эффективно обрабатывать огромные наборы данных, говорится в пресс-релизе. 
Источник изображения: NeuroBlade Элад Сити (Elad Sity), гендиректор и соучредитель NeuroBlade, подчеркнул важность совместных усилий, которые «знаменуют эпоху, когда организации смогут умело управлять растущими объёмами данных, повышать производительность аналитики и получать значительные конкурентные преимущества». Velox представляет собой унифицированный open source движок, который объединяет различные программные оптимизации в области обработки запросов в единую высокопроизводительную библиотеку, а в будущем и в самостоятельный фреймворк. Velox уже совместим с Presto и Apache Spark. Интеграция SPU NeuroBlade в Velox достигается за счёт новых API Velox, которые позволят произвольно переносить выполнение части запросов на ускоритель. Как отмечается в пресс-релизе, CPU с трудом справляются с аналитическими запросами, скорость которых превышает 2–3 Гбайт/с, из-за ограничений в обработке данных и сложности запросов. SPU NeuroBlade позволяет решить эту проблему, поскольку предлагает специализированный процессор, который обеспечивает аппаратную обработку сложных запросов и работу с памятью и хранилищем, что позволяет разгрузить CPU и добиться постоянной пропускной способности при обработке больших данных и снизить задержки.
16.09.2023 [21:34], Сергей Карасёв
Стартап Databricks привлёк ещё $500 млн, что повысило капитализацию компании до $43 млрдСтартап Databricks, разработчик платформы машинного обучения, анализа и обработки данных, сообщил о проведении раунда финансирования Series I: на развитие привлечено дополнительно $500 млн. Таким образом, на сегодняшний день общий объём инвестиций в эту компанию превысил $4 млрд. Databricks предоставляет озеро данных, которое предприятия могут использовать для хранения, организации и анализа больших объемов информации. Стартап также помогает заказчикам в развёртывании собственных приложений на базе генеративного ИИ. Компания основана в 2013 году создателями Apache Spark. 
Источник изображения: Gabby Jones / Bloomberg Отмечается, что Databricks быстро наращивает выручку: по итогам II четверти текущего финансового года, которая была закрыта 31 июля, показатель преодолел знаковый рубеж в $1,5 млрд — это более чем на 50 % превосходит прошлогодний результат. В глобальном масштабе решения Databricks применяют свыше 10 тыс. организаций, включая более половину компаний из списка Fortune 500. Раунд финансирования Series I проведён под руководством T. Rowe Price Associates. В программе также приняли участие Andreessen Horowitz, Baillie Gifford, ClearBridge Investments, Counterpoint Global (Morgan Stanley), Fidelity Management & Research Company, Franklin Templeton, GIC, Octahedron Capital, Tiger Global, Capital One Ventures, Ontario Teachers' Pension Plan и NVIDIA. Прошлый раунд финансирования Databricks был завершён в 2021 году: тогда стартап получил $1,6 млрд, а его рыночная стоимость достигла $38 млрд. Теперь же капитализация оценивается в $43 млрд при стоимости акций на уровне $73,5. |
|

