В начале апреля в Ростове-на-Дону прошла очередная, уже двенадцатая по счёту ежегодная международная научная конференция «Параллельные вычислительные технологии (ПаВТ) — 2018», посвящённая тому, что, собственно говоря, вынесено в её название. Ну и суперкомпьютерным технологиям, в частности. На мероприятии традиционно было представлено множество докладов как прикладного — в большей степени, так и теоретического характера. Все они будут вскоре выложены на сайте конференции. Увы, в этот раз удалось побывать только на пленарных докладах первого дня, которые были объединены одной простой идеей, рассмотренной с нескольких сторон, — нам нужно повышать эффективность использования ресурсов суперкомпьютеров.

Суперкомпьютер Anton (Фото: Wikipedia)
Глобально здесь можно выделить два направления. Во-первых, проблема собственно вычислительной мощности стоит уже не так остро, есть и другие важные аспекты. Во-вторых, уже нет задачи по возможности обходиться малыми ресурсами. Напротив, ресурсов сейчас много, но ведь надо ещё и уметь работать с ними. Конечно, всем надо ещё больше петафлопсов, и побыстрее, но фокус в последнее время сместился в несколько иную сторону. К проблемам, связанным с доступом к данным, к непосредственно интерфейсам. Про заветный показатель в один байт на флоп уже давно особо не вспоминают. На уровне, близком к самим вычислительным блокам, это проблему пытаются решить увеличением числа каналов, объёма и скорости локальной памяти. Это касается и CPU, и ускорителей: первые уже предлагают 6-8 каналов и объём в 1,5-2 Тбайт RAM на один процессорный разъём, у вторых же мы видим всё возрастающие объёмы стековой памяти.
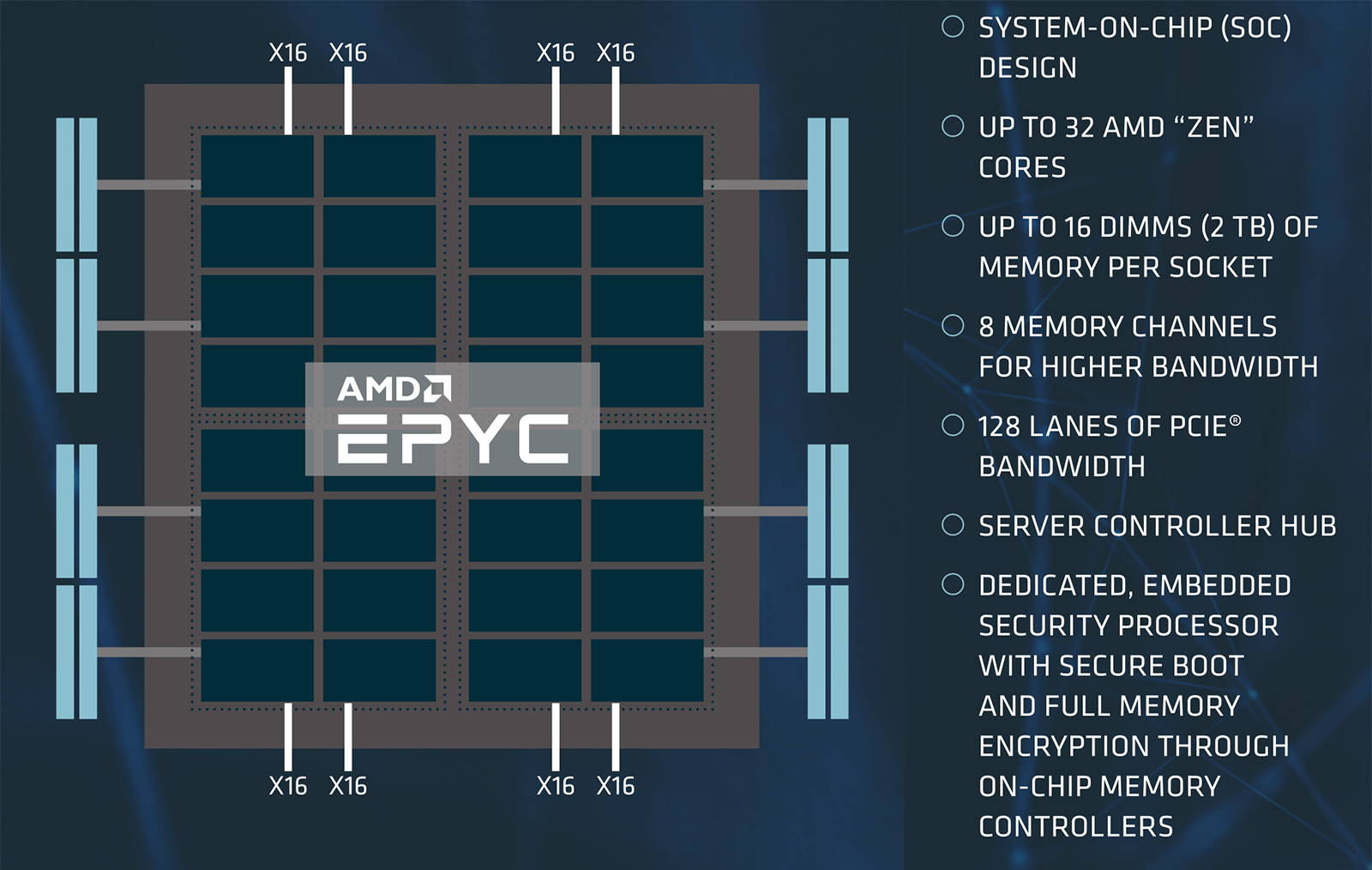
Поднимаемся на уровень выше и видим всё ту же картину — увеличение возможной ввода-вывода. В CPU растёт число линий PCI Express, а NVIDIA, недовольная производительностью PCI-E, развивает собственный интерфейс NVLink. Мы уже неоднократно писали и про то, что PCI-E становится бутылочным горлышком для I/O, и про слишком долгую задержку выхода нового стандарта. Совместимый стандарт (Open)CAPI развивает IBM. Собственно, NVIDIA в своём небольшом докладе на ПаВТ-2018 в очередной раз напомнила о своём широком ассортименте ускорителей: от решений для встраиваемых систем (для самоуправляемых авто, например) до мощных Tesla для HPC и дата-центров. Ну и про универсальность работы с ними за счёт CUDA или OpenACC. Заодно кратко перечислили HPC-новинки GTC 2018, главная из которых, на мой взгляд, — внутренний интерконнект NVSwitch, о котором тоже есть отдельная заметка.

Линии PCI-E нужны для быстрого интерконнекта, то есть для эффективного обмена данными между узлами, и, конечно, для подключения NVMe SSD. Естественно, все «горячие» данные хранятся на all-flash СХД, а теперь ещё и с использованием Optane. Следующий шаг — переход к высокоплотным системам с NVMe-over-fabric, впервые показанным полтора года назад. Про всё это — тоже уже не в первый раз — рассказала Intel в своём докладе. В целом вся концепция развития окончательно была публично сформулирована во время презентации Intel Xeon Skylake-SP и платформы Purley. Речь шла о «перебалансировке» самой платформы. Новые CPU в дополнение к увеличенному числу ядер и смене внутренней шины получили варианты с поддержкой расширенного объёма RAM и встроенным интерфейсом Omni-Path (OPA), став ещё более похожими на Xeon Phi. Кроме того, они же получили новые встроенные средства для работы с хранилищем: Intel Volume Management Device (VMD) для обслуживания NVMe-накопителей и RAID-контроллер VROC.
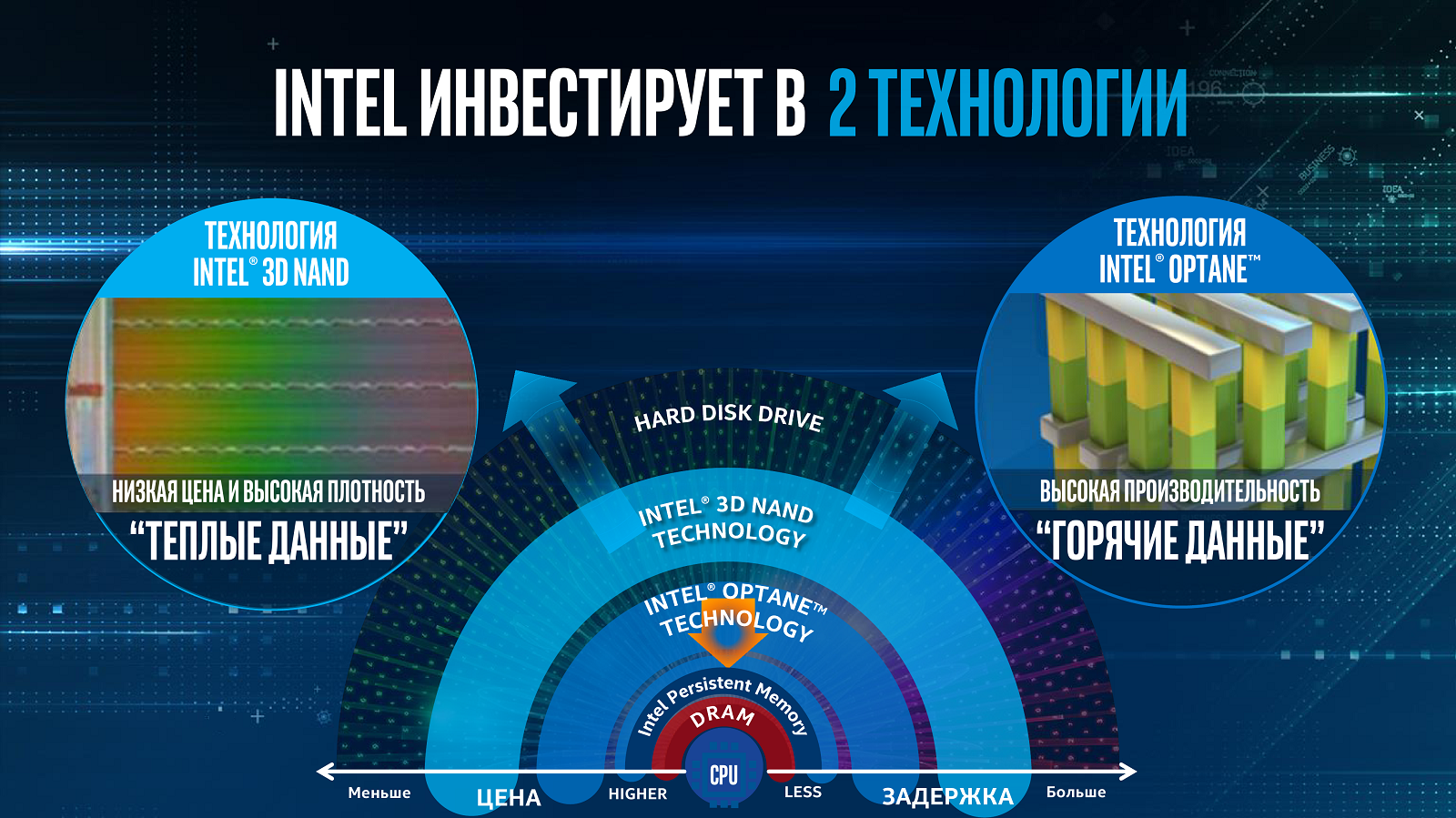
Также в старших чипсетах платформы появилась поддержка сетей до 40 Гбит/с в базовой комплектации, функции для RDMA и аппаратное ускорение некоторых типичных сетевых операций. Всё это вместе и составляет основу для создания программно-определяемых хранилищ (SDS, Software Defined Storage): NVMe-over-fabric вообще и NVMe-over-OPA в частности. AMD же, например, просто предоставляет большее число линий PCI-E (128 в одно- и двухсокетном варианте), оставляя на выбор пользователя набор адаптеров для интерконнекта и/или хранилища. Однако у Intel есть ещё один козырь — модули Optane, которые можно использовать и в качестве отдельного хранилища, и для кеша, и для бесшовного «расширения» основной RAM на всех узлах с помощью Intel Memory Drive Technology. Все эти технологии ещё и сдобрены солидным программным стеком. Так или иначе, всё это указывает на серьёзный сдвиг, переосмысление современных HPC-инсталляций.
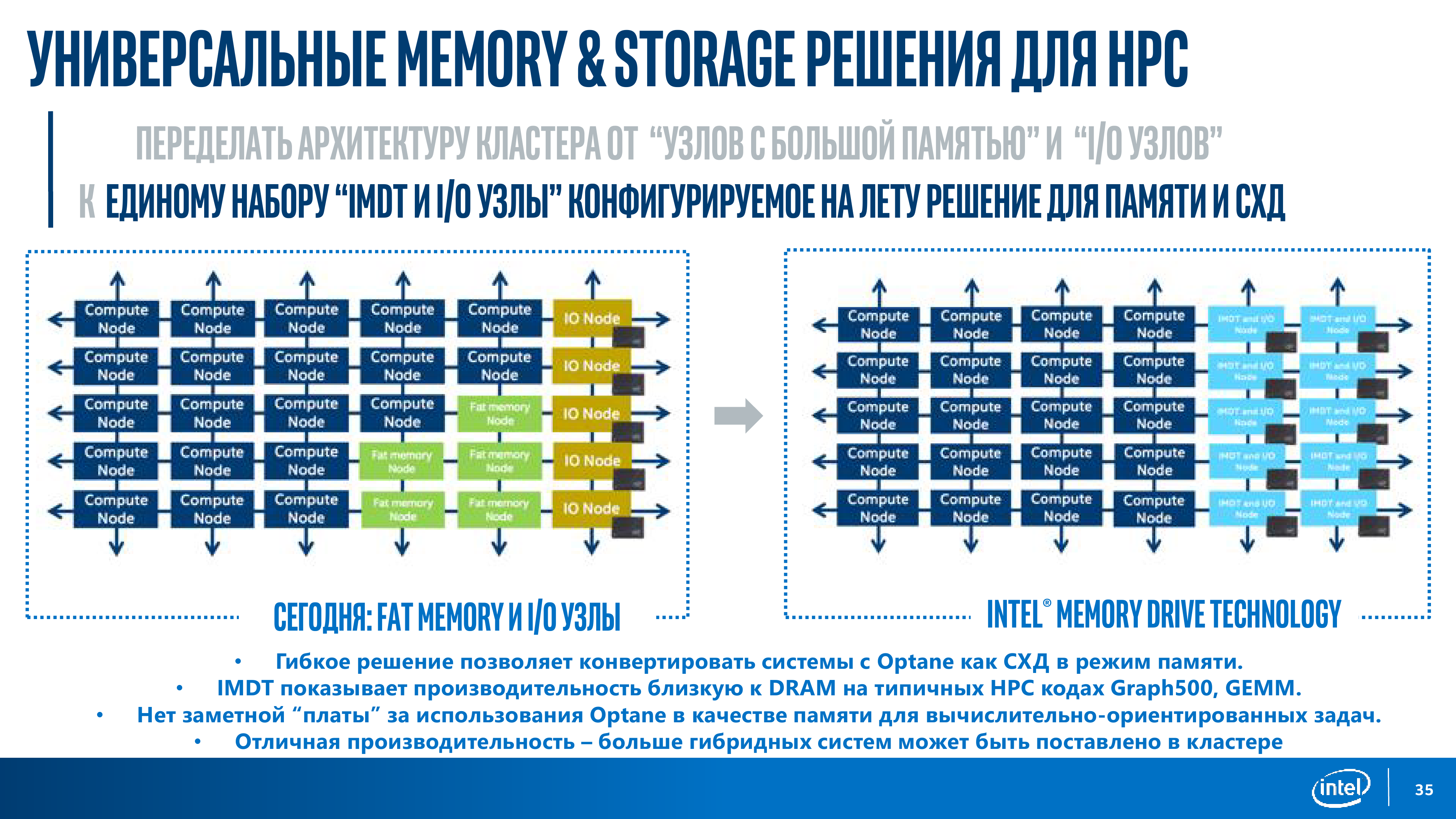
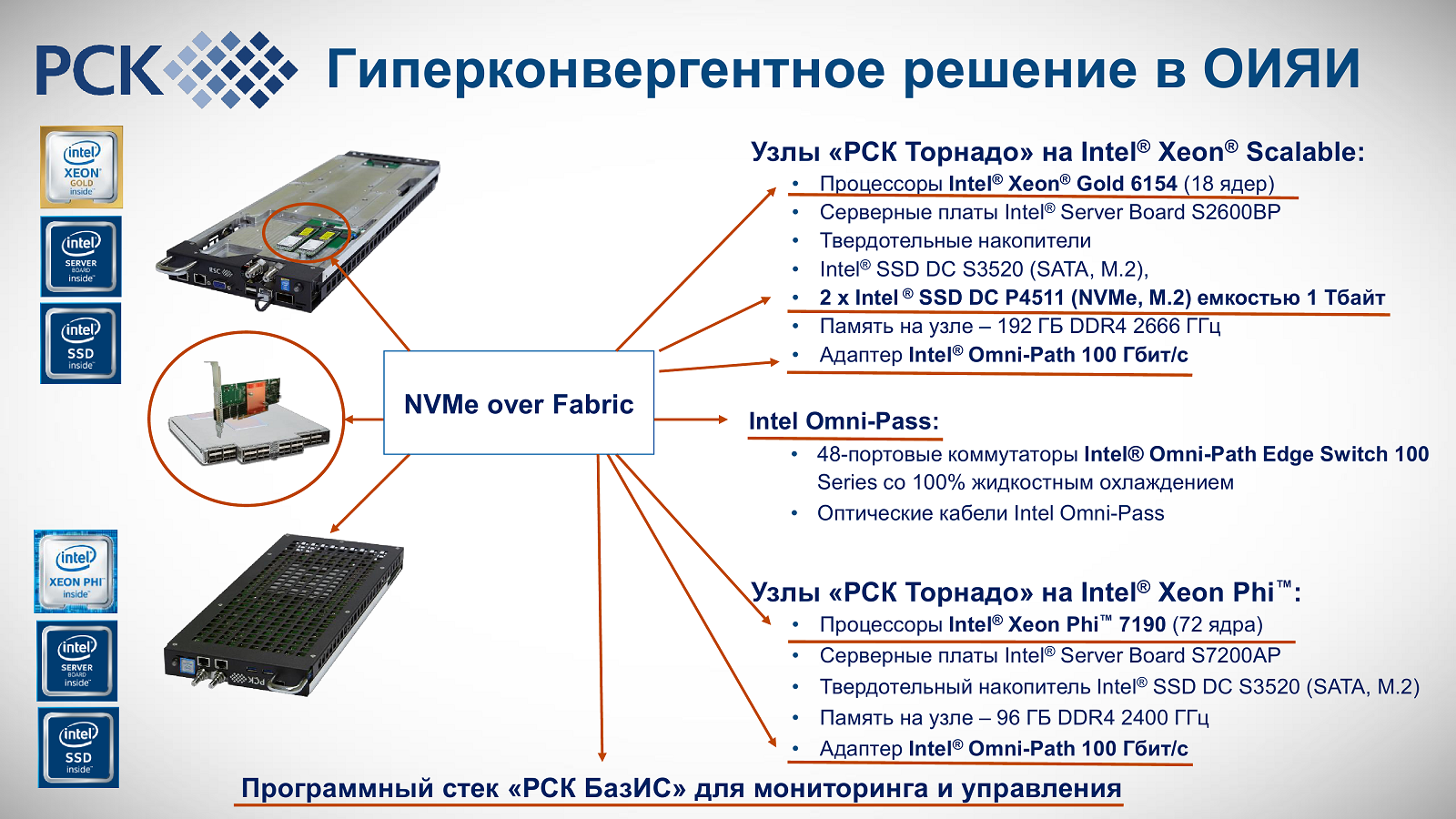
Самый «свежий» суперкомпьютер в России, установленный в ОИЯИ, построен как раз с учётом этих веяний. В последнем списке Топ-50, с объявления которого и началась ПаВТ-2018, он присутствует аж трижды. И это неслучайно, потому что технически у него есть три вычислительных системы: одна на базе классических CPU Intel Xeon Gold 6154 (18 ядер, 36 потоков, 3/3,7 ГГц) + модули с Intel Xeon Phi 7290 (72 ядра, 288 потоков, 1,5/1,7 ГГц) + пять узлов NVIDIA DGX-1 с ускорителями Volta. Таких машин с гетерогенной структурой и современным «железом» в мире сейчас не очень много. Итоговая теоретическая производительность кластера Intel составляет до 1 Пфлос FP32 или 500 Тфлопс FP64. Строго говоря, узлы DGX-1 «живут» отдельно от остальных. А вот Intel-узлы «РСК Торнадо» как раз таки объединены Omni-Path (адаптеры 100 Гбит/с стоят в каждом из них), поверх которой и работает распределённое хранилище на базе NVMe-over-fabric.
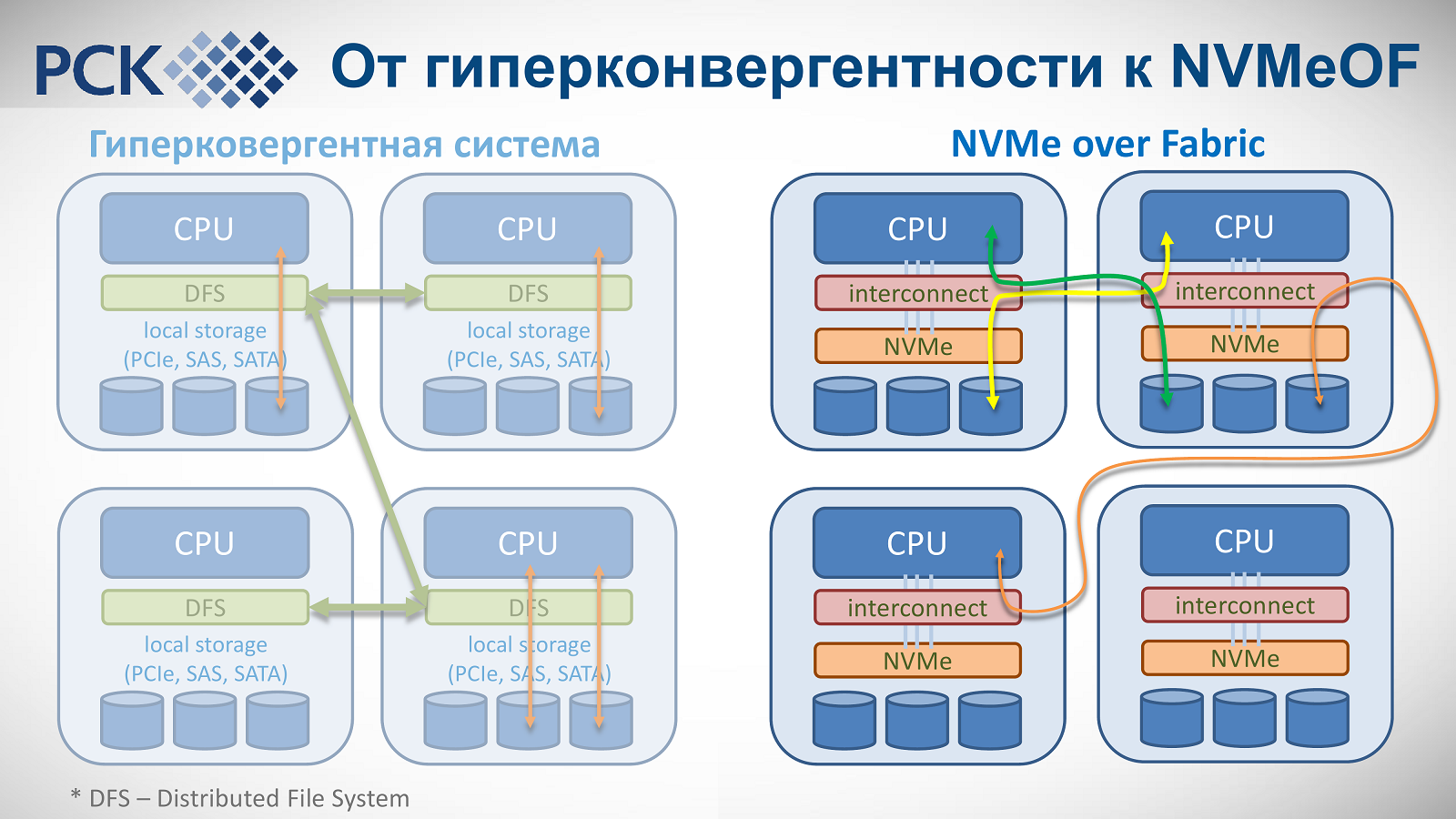
В узлах установлены NVMe-накопители Intel SSD DC P4511 (2 × 1 Тбайт), которые дополнены классическими SATA-дисками Intel SSD DC S3520. Таким образом, например, процессор в одном узле может прозрачно и, что главное, быстро обратиться к накопителю на другом узле. Ну или наоборот, данные можно локализовать в непосредственной близости от самого вычислителя. РСК отдельно отмечает, что коммутатор Omni-Path Edge Switch 100, как и сами узлы и их компоненты, оснащён СЖО с охлаждением горячей водой (+45 °C на входе в узел, в пике до +57 °C). Внешний контур охлаждения использует технологию фрикулинга, которая действенна при температуре атмосферного воздуха ниже +50 °C. Итоговый среднегодовой коэффициент PUE составляет менее 1,06, а в идеальном случае достигает 1,027, что делает суперкомпьютер в ОИЯИ самой энергоэффективной HPC-системой в РФ.
Всё вместе позволяет более эффективно использовать вычислительные и энергоресурсы. Но в этом деле есть и другой, не менее важный аспект. На прошлых конференциях ПаВТ уже звучали доклады об AlgoWiki — «открытой энциклопедии на русском и английском языках по свойствам алгоритмов и особенностям их реализации на различных программно-аппаратных платформах, цель которой в том, чтобы дать исчерпывающее описание алгоритма, которое поможет оценить его потенциал применительно к конкретной параллельной вычислительной платформе». Если говорить проще, то проект посвящён, например, увеличению эффективности работы программ на современных суперкомпьютерах. Руководят проектом В. В. Воеводин (НИВЦ и ВМК МГУ) и Джек Донгарра (Jack Dongarra, соавтор LINPACK и TOP500).
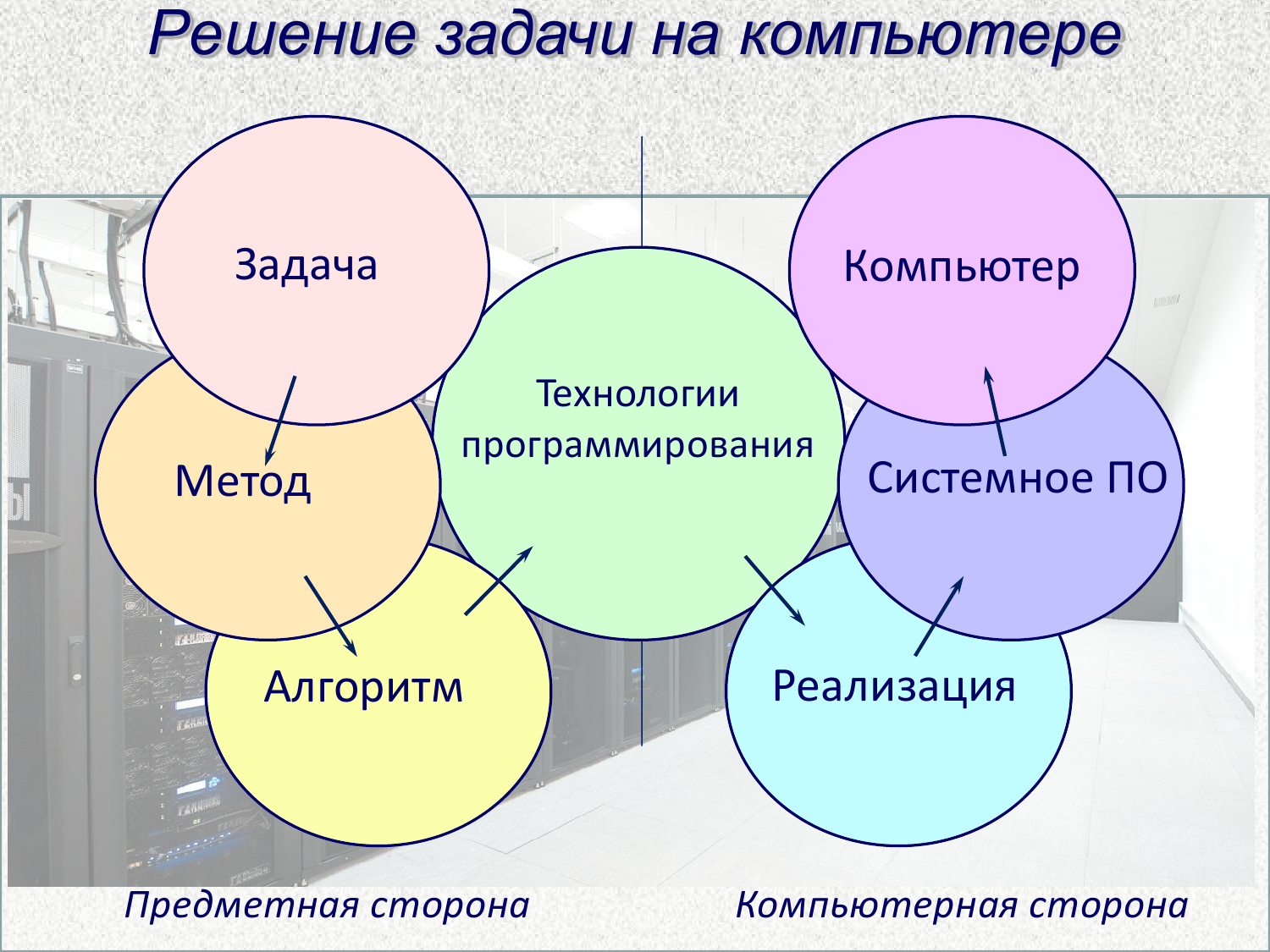
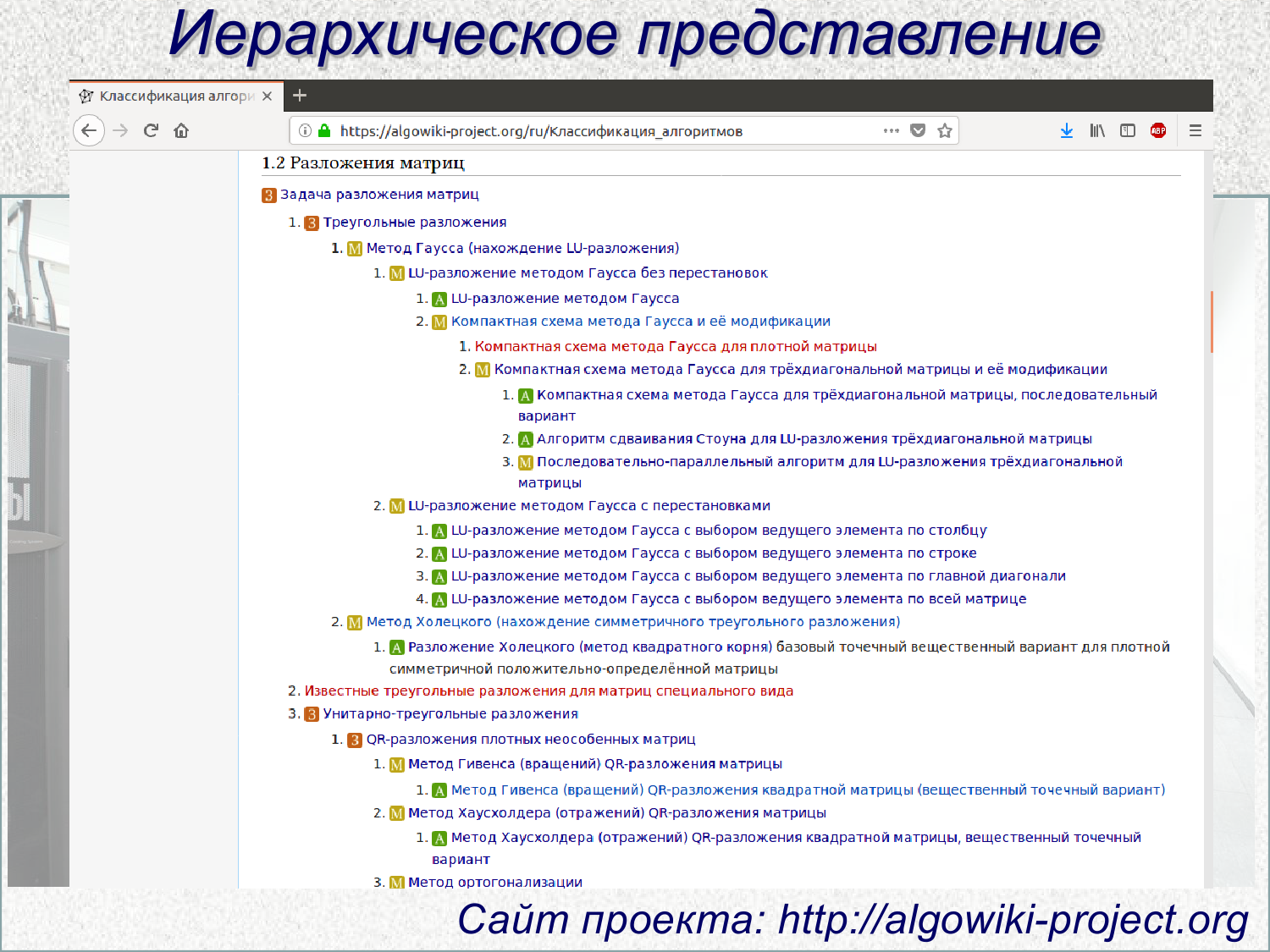
Сейчас исследователи работают над новой классификацией алгоритмов, которая должна помочь программистам в работе с реальными HPC-системами. Гораздо лучше использовать уже проверенные современные решения, чем изобретать свой велосипед. Классификация подразумевает иерархическое построение от задачи, для которой выбирается конкретный метод или методы. Для них, в свою очередь, есть подборка известных алгоритмов, для каждого из которых могут существовать десятки конкретных реализаций, рассчитанных на особенности «железа» и его окружения. В том числе и с учетом нюансов, связанных с вводом-выводом, о которых говорилось выше. На первый взгляд всё это звучит просто, но на практике любая реальная задача разбивается на множество подзадач со своими методами и алгоритмами, которые и сами по себе могут опираться на другие методы и алгоритмы.
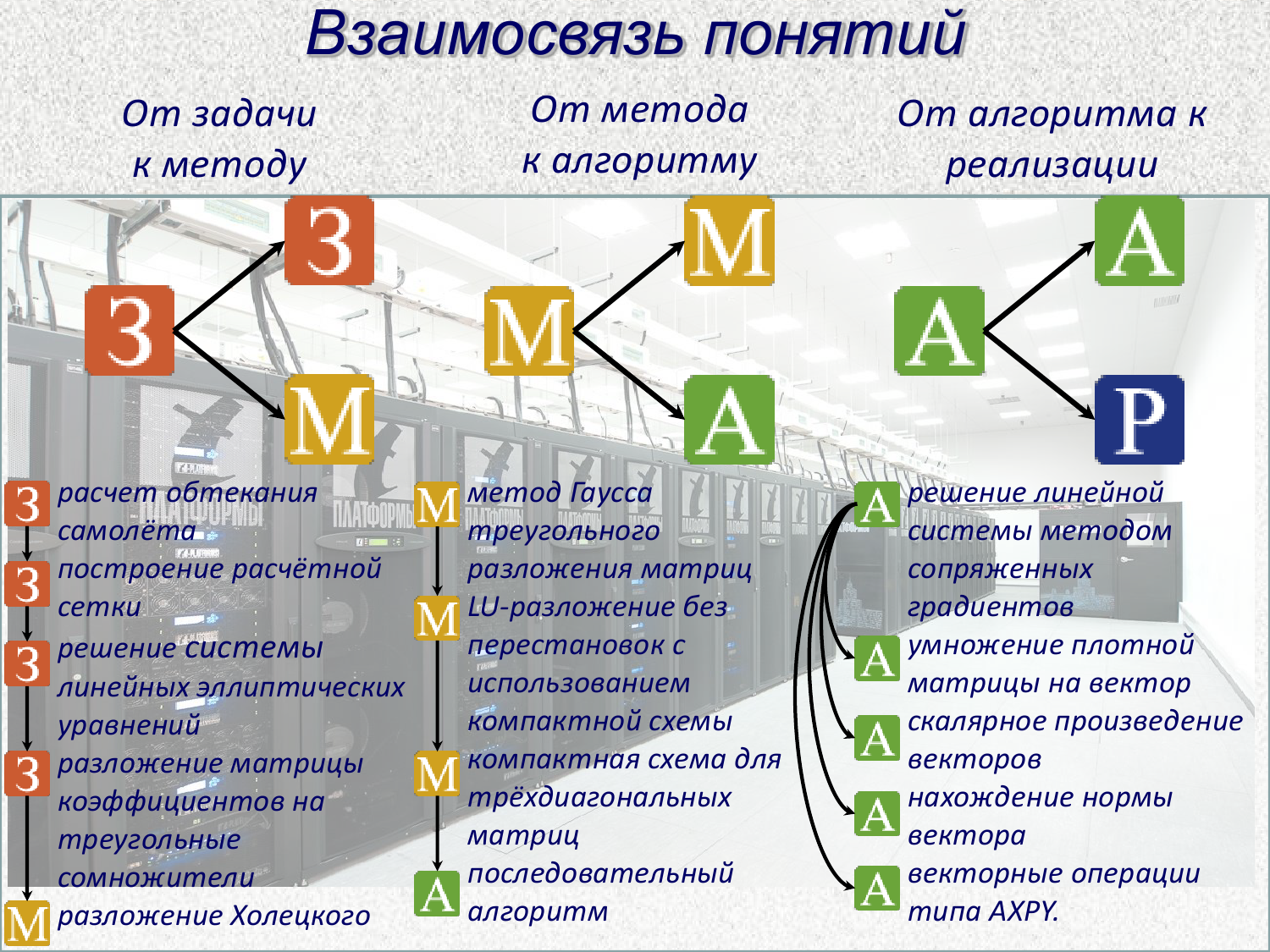
В итоге образуется весьма ветвистое дерево. Может статься, что внутри него есть не один и не два оптимальных пути решения поставленной задачи — и AlgoWiki поможет в этом разобраться. Впрочем, в связи с этим поднимается и другой, более фундаментальный вопрос: нам интересно не только повышение эффективности использования HPC-систем, не менее важно и правильно оценивать эту эффективность. Претензии к TOP500 и к HPL — в частности, к размеру задачи в стандартной версии бенчмарка — звучат уже давно. В качестве альтернативы возник рейтинг Graph500, который ориентирован на оценку работы с большими объёмами данных, что гораздо ближе к практике. У обоих списков есть «зелёные» версии, учитывающие энергоэффективность, а косвенно — и экономическую составляющую работы суперкомпьютера. Наконец, не так давно появился комплексный бенчмарк HPCG, который заметно изменил оценку расстановки сил в мире суперкомпьютеров, что важно в том и числе для имиджа стран.
Авторы AlgoWiki предлагают задуматься, не стоит ли сменить сам подход к подобного рода рейтингам. Не стоит ли отталкиваться от конкретных практических задач и оценивать, насколько хороши они решены как программистами, так и создателями «железа». Похожие мысли на SC’17высказывал Гордон Белл (Gordon Bell), создатель легендарных машин PDP, который уже 30 лет присуждает собственную скромную премию за выдающиеся достижения в области высокопроизводительных вычислений. И далеко не всегда номинанты обладали «железом», лидирующем в том же TOP500. Да и вообще, слышали ли вы когда-нибудь, например, о машинах Anton — узкоспециализированных суперкомпьютерах с уникальной архитектурой? Они используются для расчётов в области молекулярной динамики и применяются медиками и биологами для исследований. Машины эти не очень-то вписываются в имеющиеся HPC-рейтинги, однако приносят реальную пользу на практике. Не это ли важнее всего?

