"Параллельные вычислительные технологии" — конференция, посвященная... параллельным вычислительным технологиям, как это ни удивительно. Проходит она ежегодно, этот год — уже 11-й в ее истории. Структура программы конференции особо не поменялась, да и авторы пленарных докладов тоже. Так что можно смело изучить материалы с прошлых конференций — они лишь дополнились некоторыми деталями. Совсем уж глобальных изменений не было, поэтому здесь расскажем лишь о некоторых интересных моментах или наблюдениях и самых важных обновлениях. Естественно, большую часть конференции занимали научные доклады, которые через некоторое время будут выложены в архиве, а также практические семинары. Строго говоря, почти все ключевые новинки в области «железа» и технологий крупные производители уже представили на выставке SC16, но есть одно маленькое и приятное исключение.
Исключение это — компания AMD. Конечно, официальный анонс новых серверных CPU Naples состоялся уже больше месяца назад, но на ПаВТ представители компании поделились некоторыми подробностями. Событие отрадное само по себе, потому что фактически года эдак с 2008-го у AMD не получалось составить конкуренцию Intel в области HPC. Связано это было и с преобразованиями внутри компании, и с отказом от собственных фабрик. Сейчас же в арсенале компании есть сразу три производства, предлагающие современный 14-нм техпроцесс: GlobalFoundries, Samsung и TSMC. Уже готовится и следующее поколение серверных CPU, которые будут изготовляться по 7-нм нормам и иметь до 48 ядер. Они появятся в 2018 году.


Собственного интерконнекта, заходящего прямо под крышку CPU, такого как Intel Omni-Path (OPA), у AMD не будет. Во всяком случае, пока. Объясняется это нежеланием ограничивать заказчиков в выборе технологии связи узлов. Впрочем, у грядущих Naples вполне достаточно линий PCI-E, чтобы покрыть и эти нужды. Кроме того, если уж говорить о разнообразии и возможностях выбора, то AMD-то как раз в этом весьма сильна. У компании есть собственные специализированные акселераторы, FPGA-решения, DSP и другие процессоры, а теперь ещё и новое семейство ускорителей серии Radeon Instinct. Например, прямо сейчас AMD занимается аж 14 проектами, связанными только с GPU. Естественно, вся эта гетерогенная структура требует хорошей программной поддержки — это касается и драйверов, и средств разработки, и библиотек. Это у AMD тоже есть — она, напомним, один из ключевых создателей HSA Foundation.
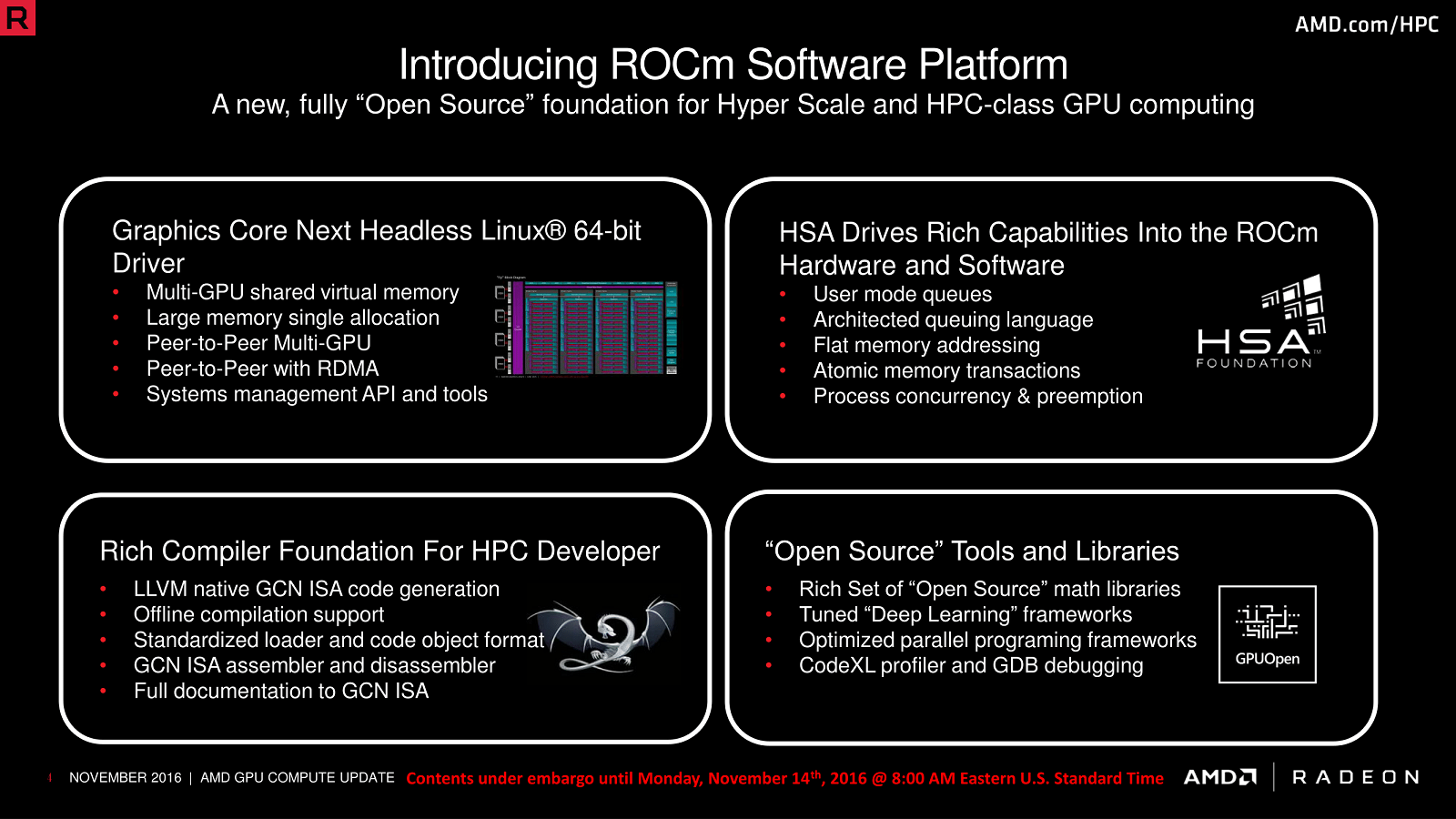

Кроме того, компания в последнее время всё активнее занимается проектами с открытым исходным кодом, плюс к этому очень много важных данных об аппаратных платформах было выложено в свободный доступ. Также AMD поддерживает инициативу GPUOpen, а сама компания предлагает готовую платформу ROCm, которая включает в себя окружение HIP, кросс-платформенный компилятор HCC и поддержку OpenCL. Что важно, в состав HIP входит конвертер CUDA-кода, который, как утверждается, практически в полностью автоматическом режиме преобразует код к такому виду, что его можно беспроблемно заставить работать на «железе» AMD. Более того, говорится, что в некоторых случаях он работает даже быстрее, чем в варианте с CUDA. Всё это дополняется поддержкой современных фреймворков и библиотек, в том числе для модного нынче машинного обучения и ИИ.

Ну это если всё вкратце рассказывать и не вдаваться глубоко в технические подробности — приведённых выше ссылок достаточно для беглого знакомства. На самом деле поддержка софта и разработчиков (в том числе материальная), пожалуй, даже более важны, чем то, что у AMD теперь есть вполне конкурентноспособный и достаточно полный набор «железа» для вычислений — про него компания неизменно говорит, что оно не хуже, а то и лучше аналогов от Intel и NVIDIA, и при этом дешевле. Так что потенциально у AMD есть все шансы склонить многочисленную армию лояльных к конкурентам разработчиков. Правда, некоторые опасения вызывает достаточная высокая ставка на открытый код и работу сообщества вокруг него. Но, кажется, это для AMD сейчас единственно верный путь.

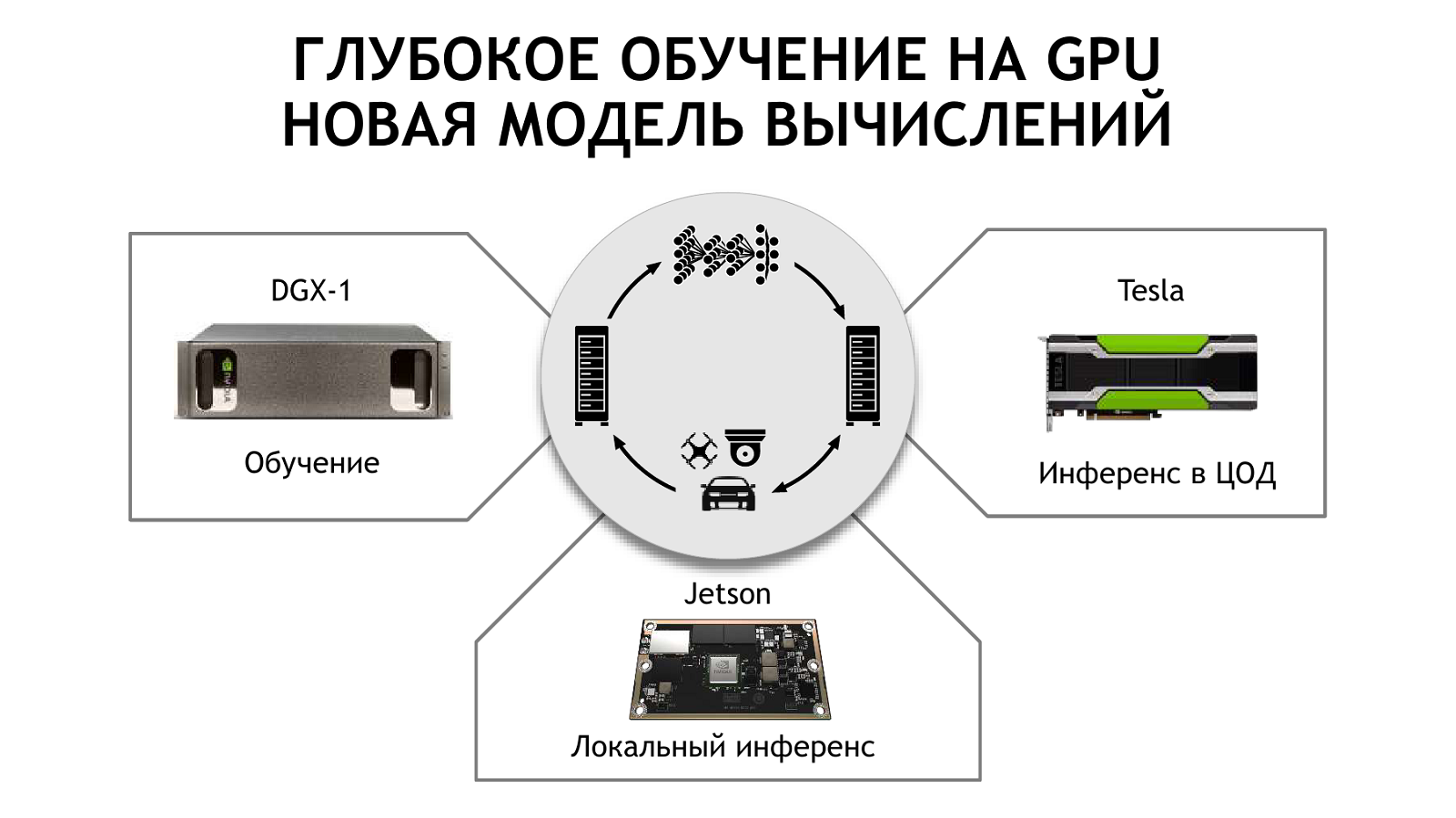
Непростой путь AMD предстоит и потому, что компания уже давно вынуждена работать на два фронта: CPU и GPU (корректнее всё же назвать их просто ускорителями). Впрочем, Intel с NVIDIA теперь тоже не слишком дружелюбно относятся друг к другу. «Зеленые» успели захватить изрядный кусок рейтинга Top500, а заодно выпустить собственный суперкомпьютер SATURNV на базе узлов DGX-1, который, кроме всего прочего, отличается ещё и завидной энергоэффективностью. Достичь успеха в деле HPC NVIDIA помог и взрывной рост интереса к машинному обучению и ИИ — последняя выставка SC была во многом посвящена именно этим технологиям. Про решения NVIDIA в этой области мы говорили в прошлый раз. Впрочем, у NVIDIA есть продукты для ИИ не только под HPC-задачи, но и для встраиваемых систем, что само по себе не менее интересно, а с практической точки зрения — даже полезнее. Речь идёт о серии Jetson — компактных SoC с ARM-ядрами и ускорителями на базе Maxwell, а теперь и Pascal.


Среди отечественных решений на базе NVIDIA Jetson стоит отметить, например, продукты СТРИЖ. Разработчики отказались от традиционного x86-сервера для сбора данных с датчиков, заменив его сверхкомпактным модулем. Из более, скажем так, традиционных применений можно упомянуть системы видеоаналитики, то есть умные видеокамеры, которые снабжены SoC Jetson и которые способны на лету распознавать, например, лица. Такие решения предлагает, в частности, компания Smilart, а про системы наблюдения компании «Вокорд» мы уже когда-то рассказывали — они давно используют ускорители NVIDIA. Распознавание лиц — одна из самых быстро развивающихся технологий, причём важна она и для любых мобильных устройств. Неудивительно, что в неё вкладываются все крупные компании.

Наконец, перейдём к главному виновнику торжества — Intel. Мы уже неоднократно говорили про технологии и решения этой компании на страницах нашего сайта. В качестве базы для ознакомления можно взять прошлогодний рассказ с ПаВТ-2016. Кроме того, ключевым продуктам были посвящены отдельные статьи: про CPU Xeon E5 v4, про интерконнект Intel Omni-Path, про ускорители Xeon Phi KNL и про серию продуктов для машинного обучения, включая FPGA и ускорители Nervana. Что дальше? А дальше следует ждать появления нового поколения CPU Xeon E5 на базе архитектуры Skylake, которое получит инструкции AVX-512, компоненты для аппаратного ускорения типичных задач компресии и шифрования, а также расширенные возможности для мониторинга и управления чипом.

Любопытно, что в этом поколении появятся первые чипы с FPGA и CPU внутри. Первые образцы таких продуктов уже проходят тестирование не только в лабораториях Intel — о подобных решениях задумывается и AMD, а если уж совсем углубиться в историю, то можно вспомнить, что когда-то уже были проекты по связыванию быстрой шиной CPU и FPGA. От себя добавим, что, пожалуй, FPGA не стоит рассматривать как универсальное средство для решения вычислительных проблем. Если проблему быстрого и относительно простого написания кода для них хоть как-то решили конвертацией из OpenCL, то вот со временем сборки готового проекта пока ничего толком не сделать — процесс отладки изрядно отличается от того, к чему привыкли «обычные» программисты.
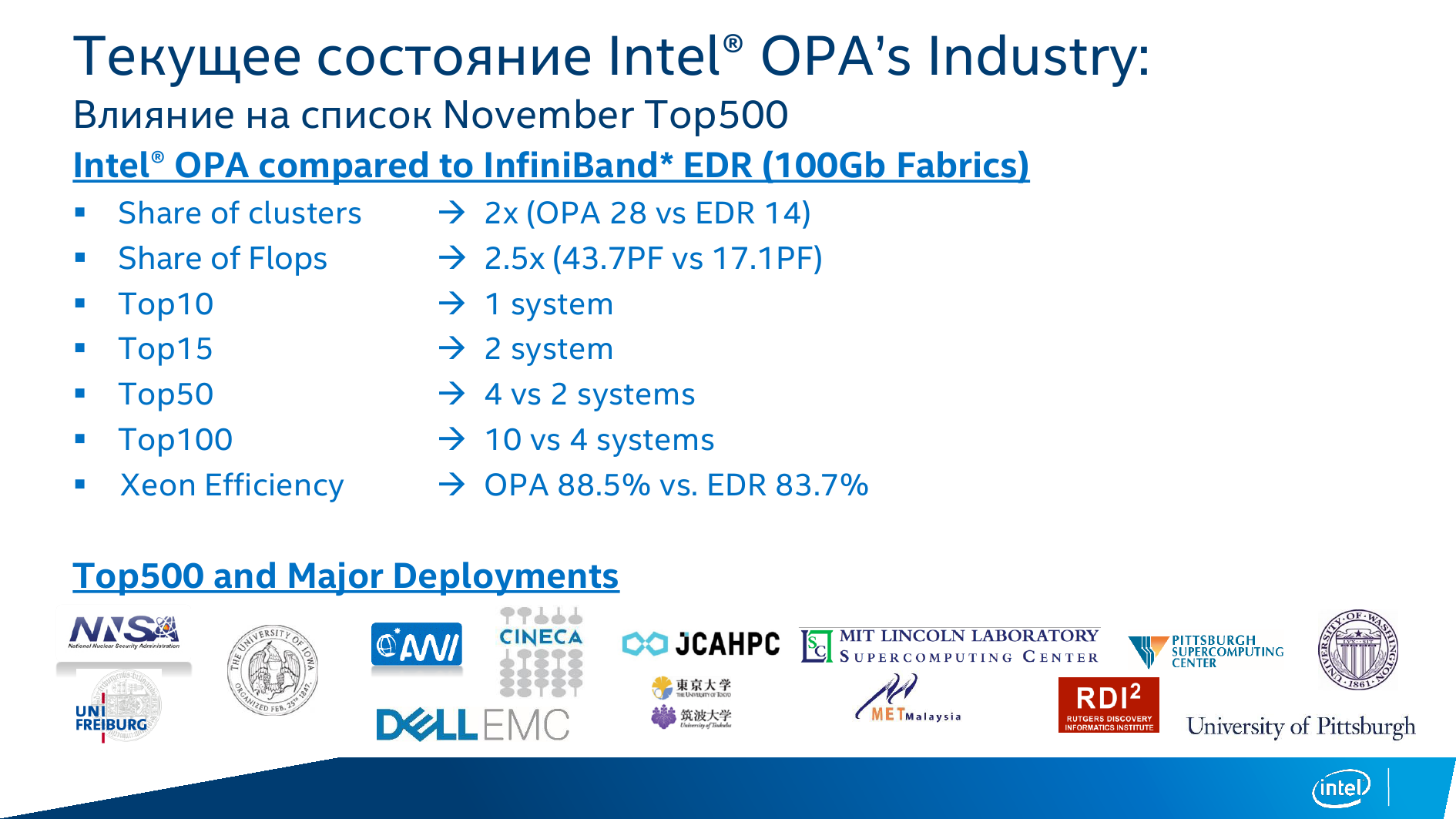
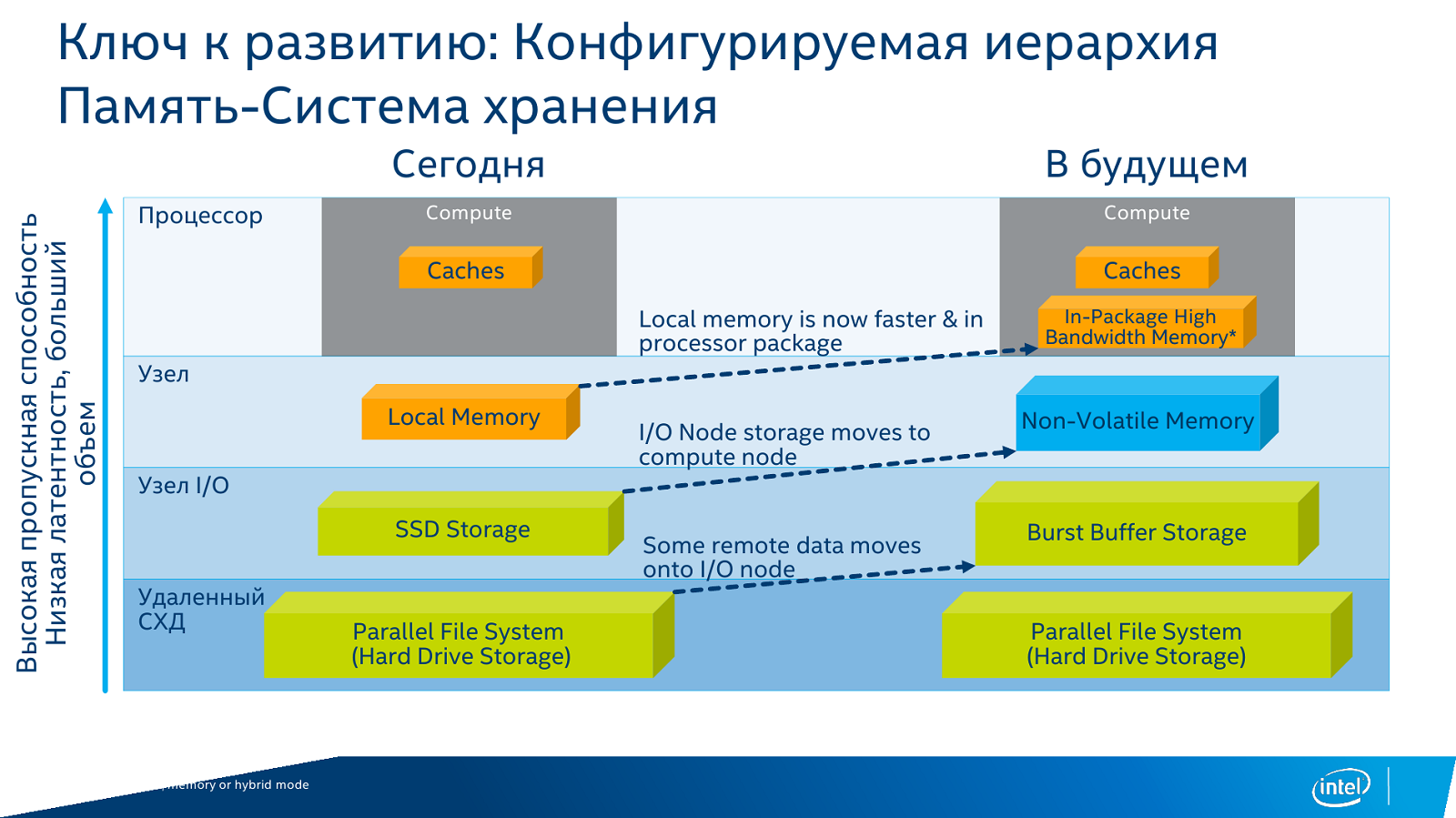
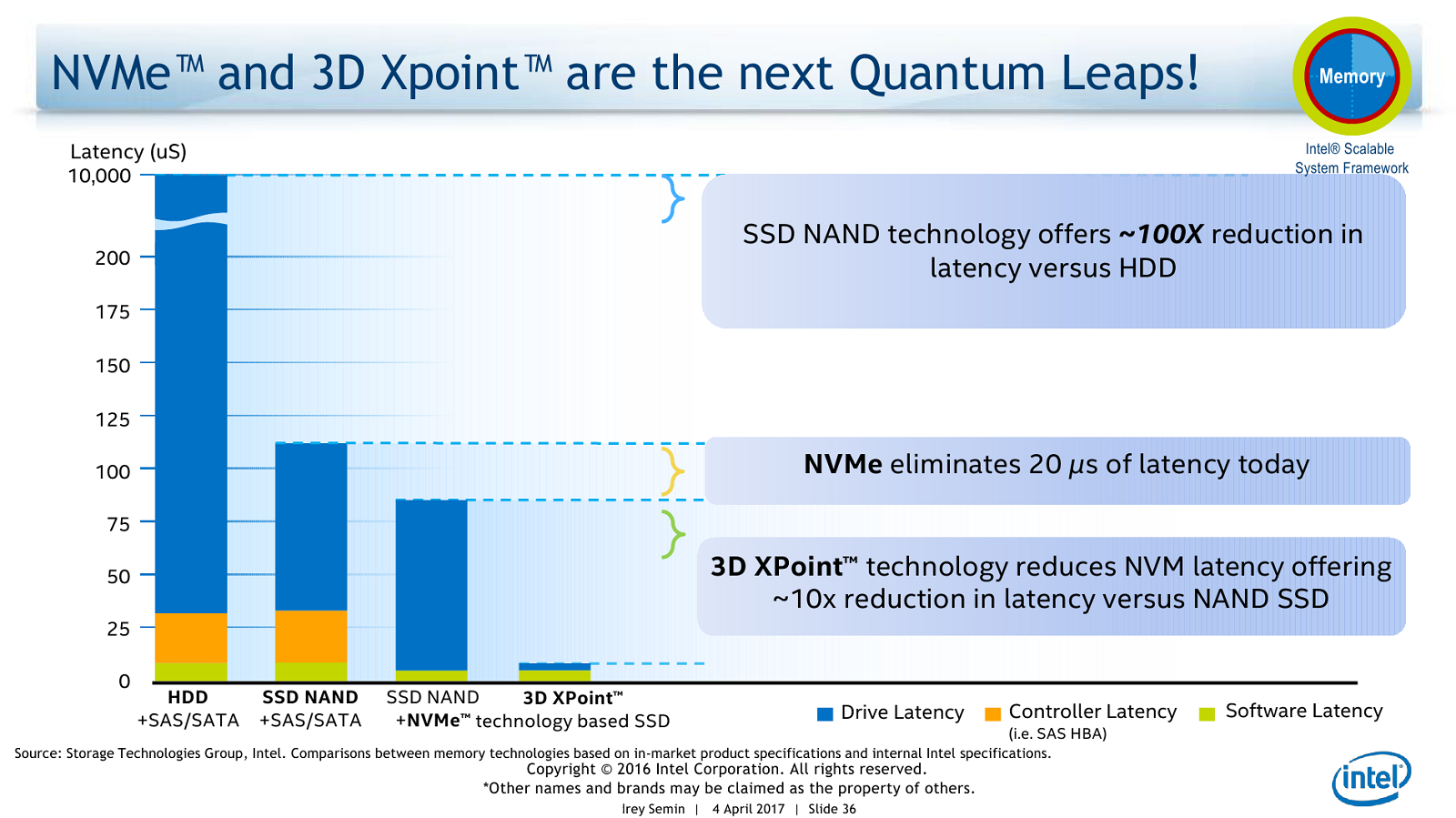
Ещё одно важное дополнение к платформам Intel — это появление первых накопителей на базе технологии Optane. Значимо, собственно говоря, даже не появление коммерческого продукта, а смена иерархии памяти, о чём уже неоднократно говорилось. Вместо традиционной связки «кеш + RAM + локальное хранилище SSD/HDD + удалённая СХД» появляется совсем другая картина. На одной подложке с CPU размещается сверхбыстрая память — в том же Xeon Phi KNL уже есть MCDRAM, которая может быть сконфигурирована и в качестве большого кеша, и в качестве традиционной RAM. Затем идут обычные DIMM-модули, а следом накопители 3D XPoint. Но и тут не всё так просто, потому как 3D XPoint будет и в формате DIMM. И только потом следуют традиционные NAND SSD. Про HDD речь уже не идёт, решений all-flash array всё больше и больше.
Есть у такого движения и ещё одно следствие: на SC 16 компания РСК первой показала работающую технологию NVMe-over-fabric на базе Intel OPA — быстрый нативный доступ к удалённым накопителям. А на ПаВТ-2017 РСК рассказала о возможных гиперконвергентных решениях на её основе.

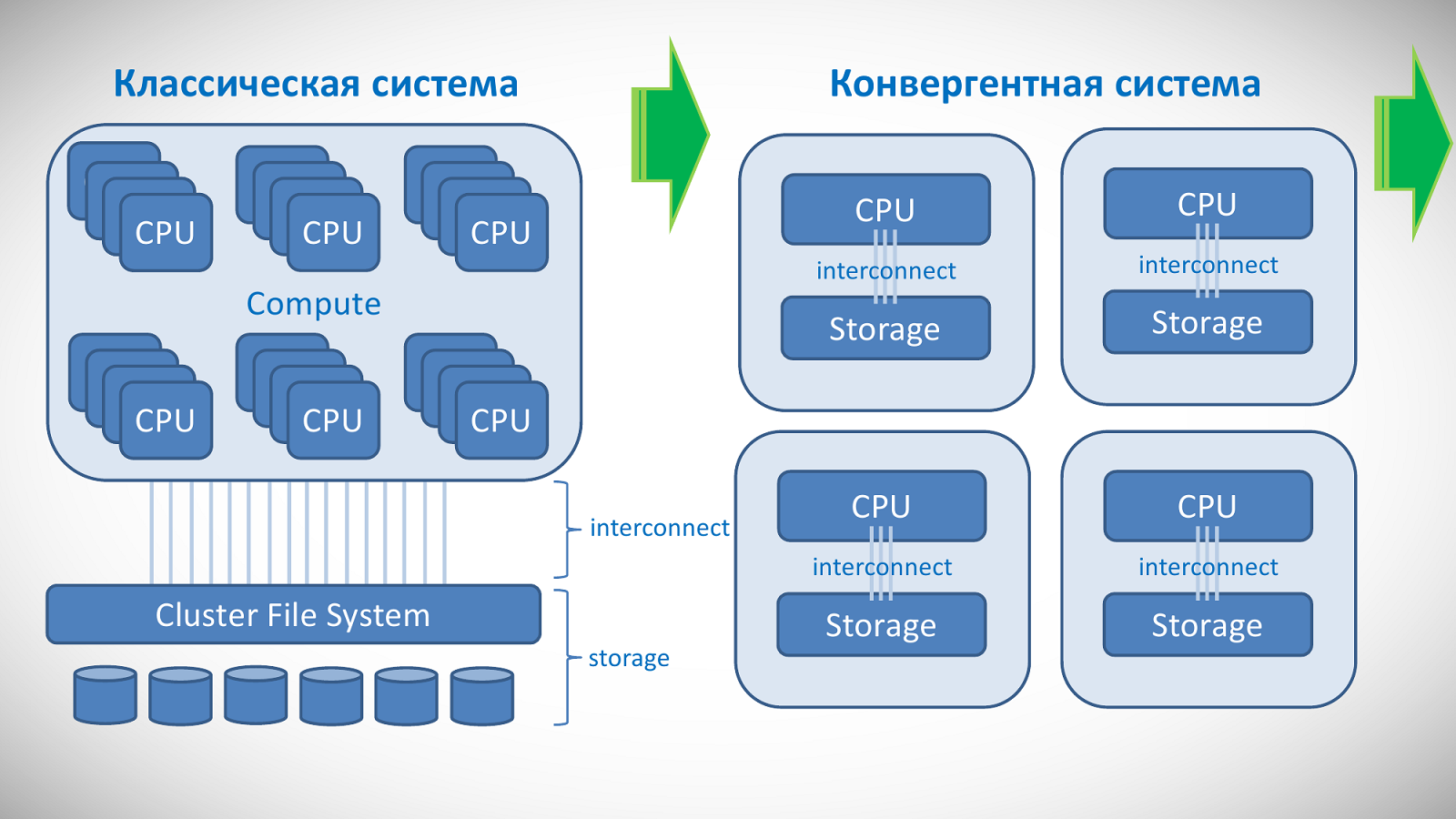
В чём их отличие от других вариантов и преимущества перед ними? Классическая схема, когда вычислительная часть и система хранения данных физически разнесены и соединены интерконнектом, очевидным образом имеет узкое место в виде самого интерконнекта. А скорость ввода-вывода данных для суперкомпьютера крайне важна. Кроме того, есть определённые проблемы в дальнейшем: 1) при расширении придётся перерабатывать не только СХД, но и остальные компоненты; 2) администрировать такие комплексы непросто, так как компоненты производятся совершенно разными компаниями.
Это не значит, что такие системы плохи сами по себе, их пока ещё очень много, однако с течением времени всё больше когда-то отдельных компонентов перебирается внутрь SoC, то есть под крышку CPU. В частности, это приводит к высвобождению линий PCI-E, а их число и так растёт от поколения к поколению. Это, в свою очередь, позволило создать более плотно связанные системы, где каждый узел содержит в себе и накопители, и вычислители, и интерконнект.

Такие конвергентные платформы тоже не новы и уже предлагаются корпоративным заказчикам, однако конфигурация этих узлов довольно жёстко задаётся на этапе проектирования, что для HPC-задач не слишком хорошо. Гиперконвергентные системы похожи, но используют несколько иной подход: в них узлы напоминают обычные серверы, а вот файловая система распределённая — она буквально «размазана» между всеми узлами. Подобные системы легко расширяемы путём добавления новых узлов и к тому же при грамотном подходе позволяют сильно локализовать данные — перенести их поближе к тому узлу, где они будут обрабатываться, что сильно повышает итоговую производительность. Кроме того, хорошо спроектированная система такого рода имеет высокую отказоустойчивость. Подобные системы сейчас активно развиваются, но они опять-таки хороши для корпоративных задач, а не для HPC, по той причине, что от работы ПО — собственно распределённой ФС — сильно зависит итоговая производительность вычислений, да и сама такая ФС может вести себя не слишком предсказуемо в плане отклика и ввода-вывода.
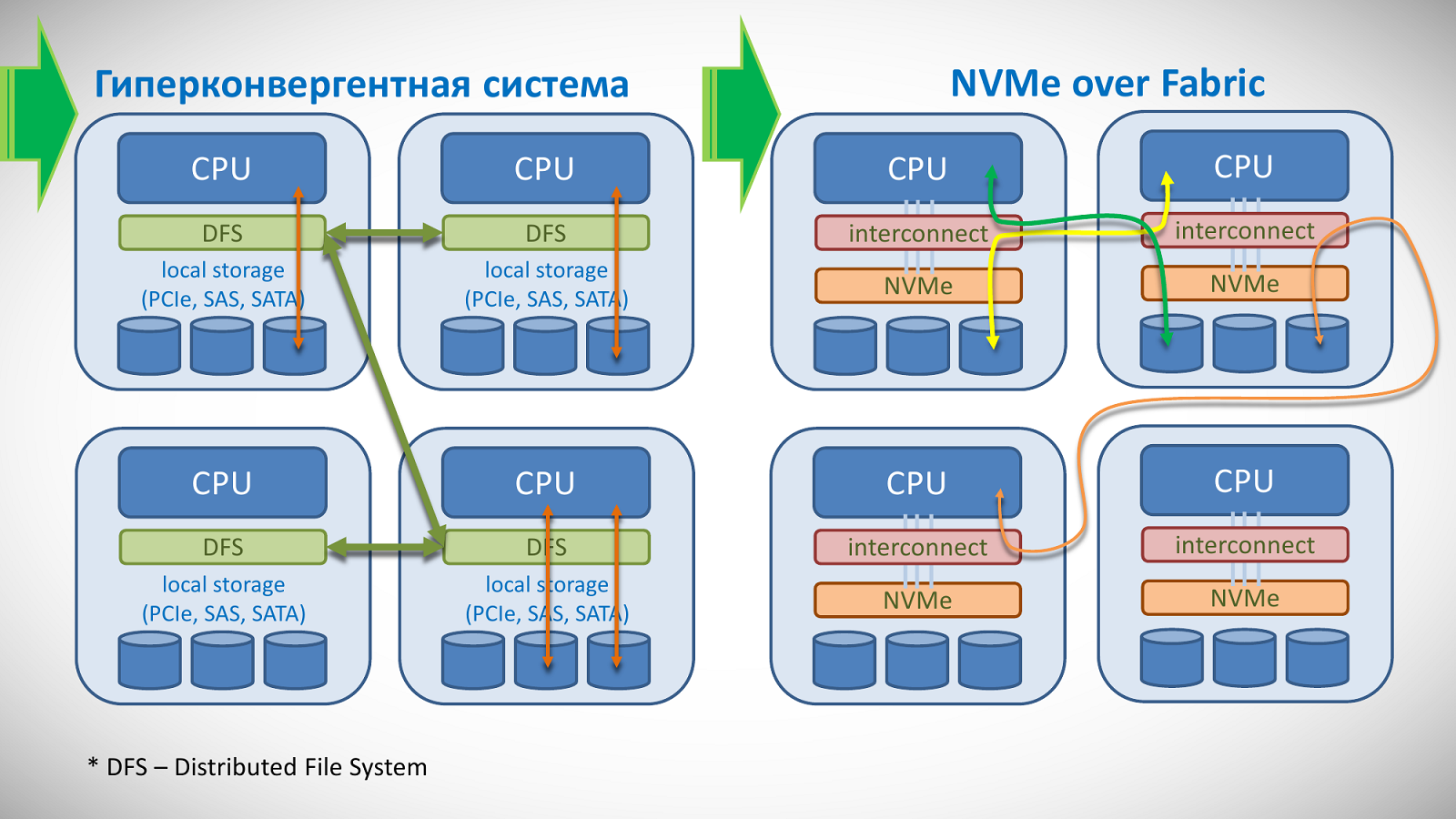
РСК предлагает пойти ещё дальше. Современные интерконнекты (да те же Omni-Path и InfiniBand) позволяют, в частности, напрямую обращаться к PCI-E через фабрику. Фактически для каждого узла все диски видны так, будто они подключены локально. Из этих накопителей можно собирать массивы, причём так, чтобы отключение одного из узлов не влияло бы на целостность данных, — фактически это уже программно-определяемо хранилище (Software Defined Storage, SDS). Естественно, какие-то из них можно и не включать в фабрику, а использовать только локально.
Преимущество такого подхода в том, что обращение к ним происходит на аппаратном уровне и оно предсказуемо, а это существенным образом сказывается на производительности суперкомпьютера в целом. В перспективе, то есть с ростом числа линий PCI-E в процессоре, можно будет установить в каждом узле до 10-16 NVMe-накопителей. Применительно к решениям самой РСК можно получить до полутора тысяч SSD в составе одного шкафа, при этом его вычислительные способности практически не пострадают. Другими путями достичь столь высоких плотности, масштабируемости и вместе с тем конфигурируемости непросто.
Заключение
Ну хорошо, а для чего всё это нужно-то? К чему стремятся HPC-технологии? Не в философском смысле, конечно, — мы-то за мир во всём мире, но вот про этический аспект, как уже неоднократно отмечалось, все разработчики не очень-то любят говорить — в техническом плане. Вернёмся к самой первой иллюстрации. Эта табличка приведена не просто так, это вполне конкретные требования к суперкомпьютерам будущего, которые должны появиться к 2023 году. Данный проект создан Министерством энергетики США, которое к тому же имеет собственное агентство ARPA-E. Надо полагать, что в этом проекте участвуют все крупные игроки HPC-рынка, хотя официально об этом вряд ли кто-то будет говорить. Помимо конкретных цифр, в описании таких машин указан и ряд других направлений исследований, которыми следует озаботиться: технологии связи (интерконнекта) и памяти; система управления данными; новые алгоритмы вычислений; ПО для разработки новых программ; масштабируемость и отказоустойчивость.
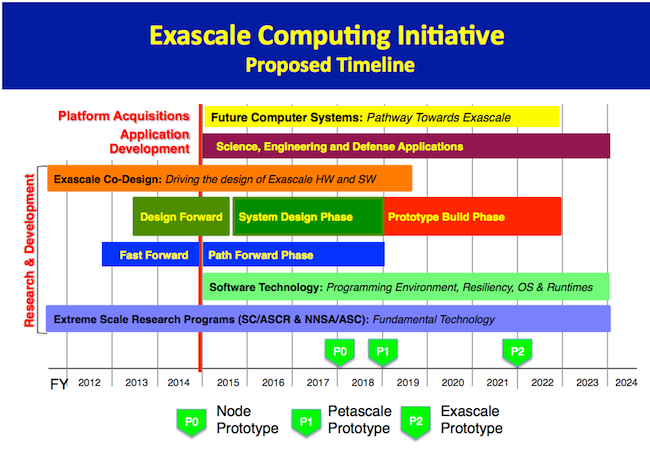
Но есть и ещё одна важная цифра — лимит на энергопотребление: экзафлопсный суперкомпьютер не должен потреблять больше 20 МВт. Нынешний лидер Top500 уже требует почти столько же энергии, чем сильно выделяется на фоне других участников рейтинга, при этом его производительность на порядок меньше требуемой величины. И простым экстенсивным наращиванием числа вычислительных узлов её не добиться. Основная цель, если кратко, сводится к повышению доступности суперкомпьютерных технологий для реальных задач науки и производства. Главная же задача всей этой программы, которую затевает Министерство энергетики США, проста и понятна — сохранить лидерство в области науки и технологий, то есть, по большому счёту, мировое лидерство. Что ж, есть к чему стремиться.

