Материалы по тегу: сервер
|
29.02.2024 [12:17], Сергей Карасёв
Iceotope, HPE и Intel представили сервер KUL RAN второго поколения с СЖОКомпании Iceotope, HPE и Intel продемонстрировали на MWC 2024 ряд новинок для телекоммуникационной отрасли и edge-приложений. В частности, представлен сервер KUL RAN второго поколения с эффективной системой жидкостного охлаждения. Edge-сервер KUL RAN первого поколения дебютировал в июне 2023 года. Он предназначен для развёртывания vRAN-платформ, сетей 5G и других сервисов связи. Применена полностью автономная СЖО Iceotope Precision Liquid Cooling. Новая модель KUL RAN выполнена в форм-факторе 2U. В основу положен сервер HPE ProLiant DL110 Gen11 на базе Intel Xeon Sapphire Rapids. Iceotope заявляет, что устройство может эксплуатироваться в «самых суровых условиях». Оно имеет защиту от тепловых ударов, пыли и влаги. Диапазон рабочих температур простирается от -40 до +55 °C. Утверждается, что решение обеспечивает сокращение энергопотребления до 20 % по сравнению со стандартными телеком-серверами, тогда как частота отказов компонентов ниже на 30 %. Устройство KUL RAN второго поколения ориентировано на сети радиодоступа с низкими задержками и edge-задачи.  Iceotope также заявляет, что её технология Precision Liquid Cooling даёт возможность охлаждать процессоры с показателем TDP 1000 Вт и даже выше. Таким образом, система подходит для применения в мощных ИИ-серверах с высокой нагрузкой.
НРЕ показала на MWC 2024 и другие системы для телекоммуникационной отрасли и инфраструктур связи 5G. Это, в частности, сервер ProLiant RL300 Gen11 со 128-ядерным Arm-чипом Ampere. Устройство типоразмера 1U оборудовано десятью фронтальными отсеками для SFF NVMe SSD с интерфейсом PCIe 4.0, тремя слотами расширения PCIe 4.0 и двумя слотами OCP 3.0.
08.01.2024 [00:28], Алексей Степин
Oxide Cloud Computer: переизобретая облакоПубличные облака очень популярны, но не всегда в должной мере отвечают поставленным целям и задачам компании. В то же время, классическая серверная инфраструктура дорога в содержании, хлопотна в настройке и не всегда безопасна — не в последнюю очередь из-за фрагментированности программных и аппаратных архитектур, уходящей корнями в далёкое прошлое. Компания Oxide Computer заявила, что разработанная ею интегрированная платформа должна вернуть компьютерным системам нового поколения холизм, присущий самым ранним вычислительным решениям, когда аппаратное и программное обеспечение создавалось совместно и с взаимным учётом особенностей. Разлад, по мнению Oxide, начался в этой сфере давно — с появлением BIOS, отделившей «железо» от системного ПО. В дальнейшем этот разрыв только нарастал, как и степень закрытости компонентов вкупе со всё большим и большим количеством слоёв абстракций. 
Источник изображений здесь и далее: Oxide Computer Появление UEFI лишь усугубило эту проблему. Причём речь здесь не только о прошивках: можно вспомнить SMM и интеграцию в процессоры «вспомогательных ядер», обслуживающих I/O-подсистемы, но полностью скрытых от системного ПО. По мнению Oxide, такой подход представляет серьёзную угрозу безопасности, поскольку со стороны «железа» операционной системе доступно всё меньше информации об истинных аппаратных возможностях и ресурсах сервера.  Появление BIOS с открытым кодом проблемы не решает — вспомогательные аппаратные компоненты сегодня не просто слишком сложны, но и работают под управлением проприетарных прошивок, а информации в открытом доступе о них крайне мало. Крупные гиперскейлеры борются с этой фрагментацией путём создания собственных, уникальных решений. Oxide Computer же решила распространить этот подход на традиционный корпоративный рынок.  В своих новых системах компания отказалась не только от традиционных прошивок BIOS и UEFI, но и от использования закрытых BMC и сервисных процессоров, равно как и блоков Root-of-Trust (RoT). Вместо них используются чипы STM32H753 и LP55S28, работающие под управлением специально разработанной для этих целей операционной системы Hubris, полностью открытой, написанной на языке Rust. 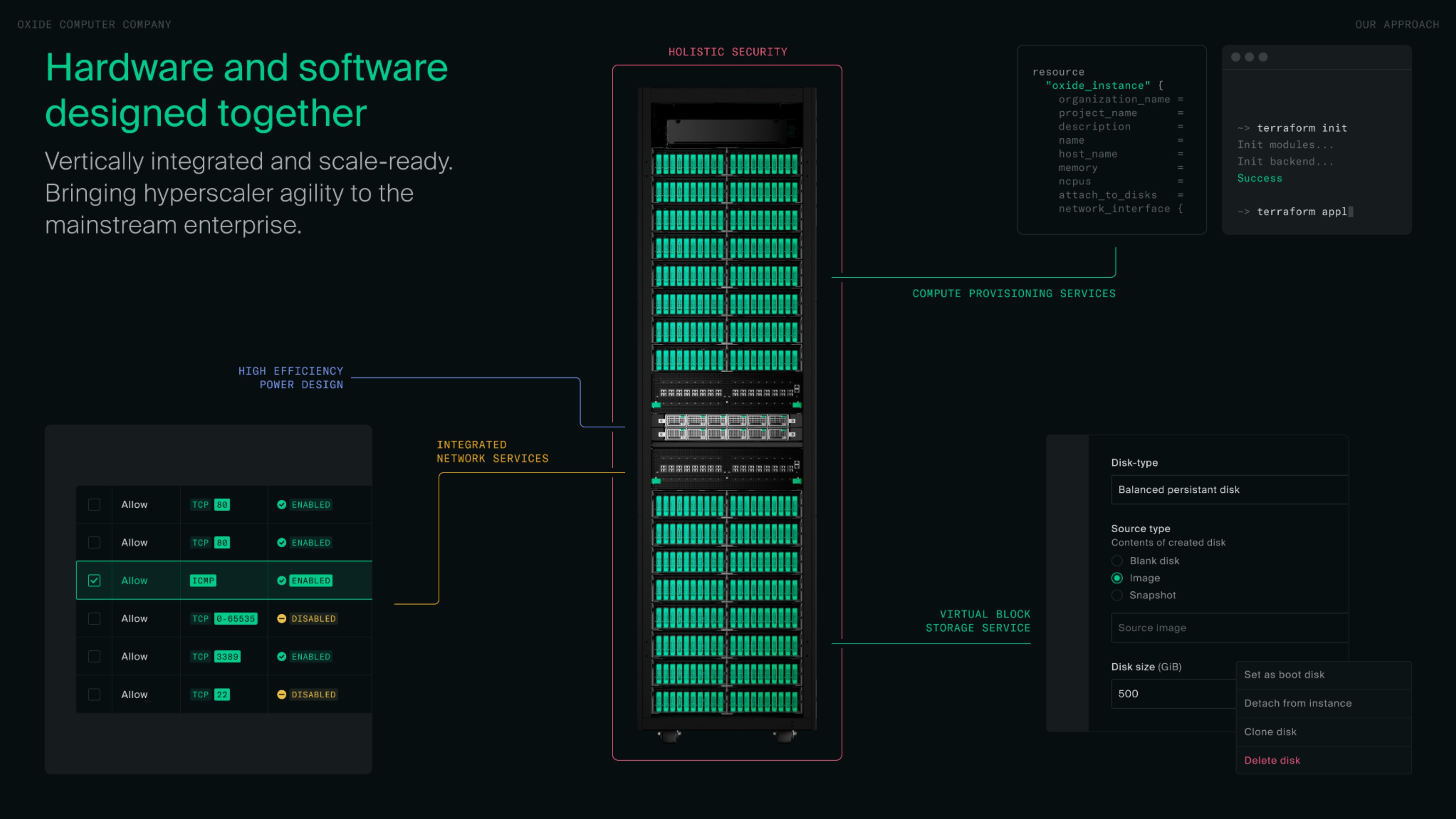 Полностью избавиться от проприетарности на платформе AMD невозможно, поскольку Platform Security Processor (PSP) отвечает за старт и инициализацию процессора и памяти. Но вот дальнейший процесс загрузки управляется не BIOS/UEFI, а фирменной открытой ОС Helios, часть которой «живёт» в SPI-памяти. Helios является своего рода наследницей illumos, восходящей ещё к OpenSolaris. Стек включает гипервизор bhyve, Propolis для работы с VMM, а также Omicron для управления всей платформой в целом на уровне стойки. Естественно, для подсистемы хранения задействованы ZFS-пулы.  Результатом работ Oxide стала платформа под названием Cloud Computer. Для неё не просто было разработано уникальное программное обеспечение — практически с нуля была создана и вся аппаратная часть, от вычислительных узлов до сетевых коммутаторов и подсистемы питания. Об этом компания рассказывает в своём блоге. При этом практически вся программная часть этого программно-аппаратного комплекса открыта, но вот аппаратную часть кому-то со стороны просто так повторить вряд ли удастся.  Oxide позиционирует Cloud Computer в качестве универсальной платформы для частных облаков, обеспечивающей единство архитектуры и удобства конфигурирования с гибкостью и простотой использования публичных облаков. По словам компании, развёртывание облака на базе Oxide Cloud Computer занимает считаные часы, что является заслугой в том числе и уникальной архитектуры новинки. Фактически для первичного запуска системы достаточно подключить питание и сеть.  Платформа (фактически готовая стойка) может включать в себя 16, 24 или 32 вычислительных узла на базе 64-ядерных процессоров AMD EPYC 7713P (Milan) с 512 или 1 Тбайт RAM, что даёт до 2048 ядер и до 32 Тбайт памяти на стойку. Каждый узел имеет 10 U.2-отсеков и комплектуется NVMe SSD объёмом 3,2 Тбайт, так что суммарный объём хранилища может достигать 931,5 Тбайт. В качестве интерконнекта используется 100GbE, в состав системы входит два программируемых коммутатора на базе Intel Tofino 2 (12,8 Тбит/с). В них также применяется ПО Oxide, написанное на P4.  Подсистема хранения использует OpenZFS для построения распределённого блочного хранилища и реализует проактивную защиту данных, быстрое снятие снимков, их преобразование в дисковые образы и обратно, а также многое другое. Шифрование данных обеспечивается на всех уровнях, а за безопасность и хранение ключей отвечает фирменный RoT-контроллер, упомянутый ранее. Полка питания содержит 6 БП (5+1), максимальная потребляемая стойкой мощность не превышает 15 кВт. Питание у системы трёхфазное. Высота стойки Oxide составляет 2354 мм, ширина — стандартные 600 мм, глубина — 1060 мм. Платформа может генерировать почти 61500 BTU/час и нуждается в соответствующем воздушном охлаждении. Система работоспособна при температурах окружающей среды в пределах от +2 до +35 °C при относительно влажности не выше 80 %. Масса стойки составляет до 1145 кг.
06.07.2023 [14:54], Сергей Карасёв
HPE организует в Индии масштабное производство серверовКомпания HPE сообщила о планах организовать в Индии массовое производство ряда серверов. В рамках этого проекта заключено соглашение с индийской фирмой VVDN Technologies о начале выпуска оборудования на предприятии в городе Манесаре в районе Гуруграм штата Харьяна. В течение первых пяти лет HPE планирует произвести высокопроизводительные серверы на сумму около $1 млрд. Инициатива поможет удовлетворить растущий спрос на продукты корпоративного класса со стороны клиентов в Индии, а также укрепит и диверсифицирует глобальную цепочку поставок HPE. Похоже, не слишком удачный поначалу план индийского правительства по привлечению крупных вендоров корпоративного и иного IT-оборудования всё же увенчается успехом. 
Источник изображения: HPE HPE поддерживает масштабную программу цифровой трансформации Индии, сотрудничая с различными государственными ведомствами. В 2019 году компания объявила об инвестициях в размере $500 млн в течение пяти лет для расширения операций и базы сотрудников в Индии. С тех пор HPE создала в стране 2000 новых рабочих мест и открыла несколько новых кампусов и офисов. «Индия является стратегическим рынком для развития бизнеса HPE и внедрения инноваций, а теперь — и для производства. Сегодняшний анонс знаменует собой важную веху для HPE и подтверждает нашу приверженность инициативе правительства "Сделано в Индии"», — сказал Антонио Нери (Antonio Neri), президент и главный исполнительный директор HPE. Отмечается также, что HPE имеет в Индии самую большую команду сотрудников за пределами США. Крупнейший в мире кампус компании в Бангалоре является площадкой для многих проектов HPE по разработке продуктов. Более 4000 учёных, инженеров и исследовательских групп компании базируются в научно-исследовательском центре в этом кампусе.
31.05.2023 [14:23], Сергей Карасёв
Supermicro представила MGX-сервер ARS-221GL-NR с суперчипами NVIDIA GraceКомпания Supermicro официально анонсировала сервер ARS-221GL-NR, построенный на новейшей модульной архитектуре NVIDIA MGX. Решение ориентировано на корпоративных заказчиков, реализующих проекты в области НРС, ИИ, метавселенных и пр. Сервер выполнен в форм-факторе 2U с габаритами 438,4 × 900 × 88 мм. Применена материнская плата Super G1SMH для процессоров NVIDIA Grace CPU Superchip, насчитывающих 144 ядра Arm. Возможна установка до четырёх ускорителей NVIDIA H100. 
Источник изображения: Supermicro Система несёт на борту до 480 Гбайт памяти LPDDR5X-4800. В комплектацию может быть включён адаптер 10GbE NVIDIA ConnectX-7 или Bluefield-3 DPU. Предусмотрены 16 отсеков для накопителей E1.S NVMe с возможностью горячей замены.  В общей сложности есть семь слотов расширения PCIe 5.0 x16 FHFL. Упомянут аналоговый интерфейс D-Sub. Питание обеспечивают блоки мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Диапазон рабочих температур — от +10 до +35 °C. Сервер оборудован системой воздушного охлаждения с шестью вентиляторами, рассчитанными на продолжительную работу под высокими нагрузками.  Компания Supermicro также сообщила о намерении применять в своих продуктах Ethernet-платформу NVIDIA Spectrum-X. Она обеспечивает возможность обслуживания до 256 портов 200GbE (или 64 × 800GbE, или 128 × 400GbE) одним коммутатором.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения.
29.03.2023 [13:40], Сергей Карасёв
Облачный провайдер Scaleway довёл срок эксплуатации серверов до 10 летКомпания Scaleway, владеющая дата-центрами во Франции и предлагающая облачные услуги в других европейских ЦОД, по сообщению Network World, реализует масштабный проект по увеличению срока службы серверов и повышению их производительности в соответствии с меняющимися требованиями заказчиков. Обычно серверы в ЦОД эксплуатируются от трёх до пяти лет, после чего производится их замена на новые. Однако в сложившейся макроэкономической обстановке многие гиперскейлеры, такие как AWS, Google, Meta✴ и Microsoft, вынуждены увеличивать жизненный цикл своего оборудования. Однако Scaleway пошла дальше, увеличив срок службы своих серверов до 7–10 лет. Инициатива Scaleway предусматривает модернизацию приблизительно 14 тыс. серверов. В частности, компания решила отказаться от аппаратных RAID-контроллеров из-за большого количества сбоев, связанных в том числе с элементами питания. Вместо этого будет применяться программный RAID. Кроме того, Scaleway намерена добиться высокого уровня надёжности и производительности серверов посредством трёхэтапного процесса оценки характеристик, тестирования и проверки оборудования. 
Источник изображения: Scaleway Такой подход позволяет убедиться, что серверы действительно соответствуют предполагаемым вариантам использования. Модернизация включает наращивание оперативной памяти. При необходимости могут быть обновлены CPU и другие компоненты, а также прошивки BMC, BIOS и т.д. После апгрейда и проверок серверы перемещаются в ЦОД. Те системы, которые не могут быть модернизированы, идут на запасные части.
19.01.2023 [16:55], Алексей Степин
Dell анонсировала серверы PowerEdge на базе процессоров Sapphire RapidsDell, пусть и с некоторым запозданием, представила сразу несколько модельных рядов серверов на базе новых Intel Xeon Sapphire Rapids. В первую очередь обновление затронуло серию Core, которая получила пять новых моделей: компактный одноюнитовый сервер PowerEdge R660, две вариации PowerEdge R760 высотой 2U, одна из которых, R760xa, рассчитана на установку шести ускорителей: четырёх двухслотовых с теплопакетом 300 Вт в передней корзине и двух компактных (TDP 75 Вт) — в задней. В случае использования только однослотовых плат ускорителей их число можно увеличить до 12, так что это одна из самых высокоплотных и при этом компактных платформ для ускорителей. 
Dell PowerEdge R660/R660xs. Источник изображений: StorageReview Модели R760 и R660 с суффиксом xs относятся к сегменту начального уровня, они лишены некоторых опций, реализованных в основной серии. Также в среди новинок есть серверы PowerEdge R960 и R860 высотой 4U и 2U, интересные тем, что это не двух-, а четырёхпроцессорные системы. В своё время Dell пропустила поколение 4S-платформу на базе Cooper Lake-SP, так что в своём классе это долгожданное обновление. 
Dell PowerEdge R760. Источник изображений: StorageReview Модель Dell PowerEdge C6220 представляет собой модульное шасси высотой 2U c четырьмя вычислительными узлами на базе Sapphire Rapids. Она оснащена фирменной «мультивекторной» системой воздушного охлаждения, достаточно эффективной, чтобы позволить экономию на СЖО. 
Модели начального уровня и модульное шасси PowerEdge C6620 с воздушным охлаждением Для гиперскейлеров компания предлагает Dell HS5610 и HS5620 высотой 1 и 2U соответственно. В этих решениях компания воплотила тенденцию облачных провайдеров к отказу от проприетарных решений: система удалённого управления и мониторинга здесь базируется на OpenBMC и Open Server Manager. Есть среди новинок и модель в башенном форм-факторе, PowerEdge T560. Она поддерживает пару Sapphire Rapids c TDP до 250 Вт и может вмещать 12 полноразмерных накопителей 3,5″, либо 24 — в формате 2,5″. Возможна установка двух полноразмерных ускорителей. 
Серверы PowerEdge с поддержкой NVIDIA SXM5 и Intel Ponte Vecchio Наконец, мощные системы серии XE9680/9640/8640 предназначены для машинного обучения и спроектированы с учётом соответствующих требований. Старшая модель поддерживает установку восьми ускорителей NVIDIA H100 (SXM5), либо восьми A100 (SXM4), а младшая XE8640 — четырёх таких ускорителей. PowerEdge XE9640 интересна ориентацией на использование ускорителей Intel Max (Ponte Vecchio) с поддержкой интерконнекта GPU-GPU. Новые серверы Dell имеют ряд любопытных фирменных особенностей, среди которых выделяется BOSS-N1. Это отдельный RAID-контроллер с поддержкой безопасной загрузки UEFI и предназначенный для установки операционной системы. Как указывает литера N, новинка использует накопители NVMe. Дисковая корзина BOSS-N1 доступна с задней панели сервера и поддерживает функцию горячей замены. 
Источник изображений: StorageReview Не забросила Dell и направление аппаратных RAID-контроллеров, представив в этой серии новинку PERC12, которая, если верить заявлениям, вдвое превосходит по производительности решение предыдущего поколения и вчетверо — показатели PERC10. Контроллер поддерживает PCIe 5.0 и все современные интерфейсы: SATA-3, SAS-4 и NVMe. Также анонсирован контроллер H965e для создания JBOD-массивов с поддержкой SAS-4.
12.01.2023 [17:22], Владимир Мироненко
Civo и Heata предложили британцам устанавливать дома серверы для отопленияПровайдер облачных услуг Civo сообщил о сотрудничестве с компанией Heata с целью обеспечения горячей водой домов в Великобритании за счёт отвода тепла от размещённых локально серверов, подключённых к системам отопления. Heata позиционирует себя как разработчик инновационной экологически чистой распределённой вычислительной сети, которая использует «мусорное» тепло, генерируемое при обработке вычислительных нагрузок, для нагрева воды. Компании планируют запустить совместный пилотный проект, в рамках которого клиентам Civo будет предоставлена возможность опробовать облачные нагрузки в сети Heata. Компании заявили, что это позволит клиентам Civo обеспечить тех, кто столкнулся с нехваткой топлива, бесплатной горячей водой. 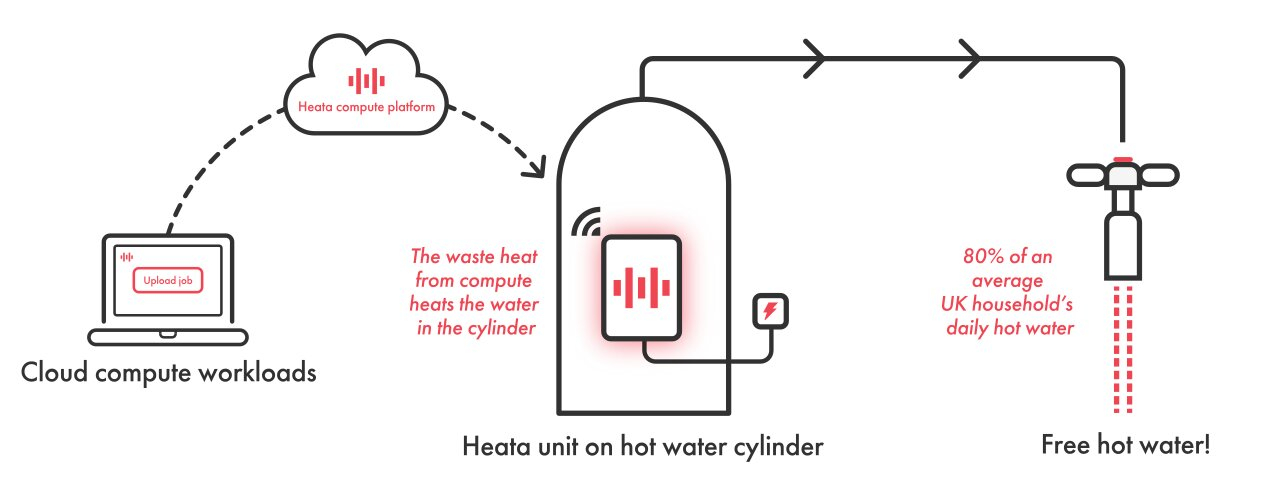
Источник изображения: Heata Компактные серверы Heata (36 × 28 см) устанавливаются на внутридомовых бойлерах. Заказчики платят Heata за обработку своих облачных нагрузок на этих серверах (в пакетном режиме), а отводимое от них тепло используется для нагрева воды в бойлере. Работа системы увязана с существующими системами отопления. Бойлеры были протестированы в сотрудничестве с British Gas. Один такой блок позволяет сократить выбросы углекислого газа на 1 т в год. В настоящее время Heata вместе с Innovate UK занимается определением домов, где будет установлено вычислительное оборудование. Концепция «цифровых бойлеров» не нова. Наиболее известна такими решениями компания Qarnot из Франции, которая недавно привлекла €35 млн инвестиций. А вот компания Nerdalize, занимавшаяся производством «вычислительных» радиаторов, обанкротилась в 2019 году.
12.01.2023 [15:47], Алексей Степин
Atos представила серверы BullSequana SH и edge-платформы EXR и EXD на базе Sapphire RapidsНовые процессоры Intel Xeon с архитектурой Sapphire Rapids навёрстывают упущенное и находят своё место в новых моделях серверов. На этот раз о новинках объявила компания Atos, представившая вычилительную систему BullSequana SH класса HPC и новые серверы в серии EX. Система BullSequana SH является модульной и расширяемой, базовым строительным блоком служит модуль SH20 с двумя процессорам Sapphire Rapids и 32 слотами DDR5 с поддержкой Optane PMem 300. Опциально такой модуль может нести на борту и пару DPU или GPU. До четырёх таких блоков можно объединить в единую систему с 8 процессорами, 32 Тбайт оперативной памяти и 8 ускорителями. Для этого нужны лишь UPI-коннекторы. Однако это не предел: с помощью специального модуля UBox высотой 3U, систему можно расширять и далее, не прибегая к помощи InfiniBand или иных сетей. Модуль UBox содержит внутри два контроллера Intel Ultra Path Interconnect (UPI), что позволяет с помощью одного модуля объединить в единую NUMA-систему до 16 процессоров. С помощью ещё одного UBox это число можно довести до 32 — именно такую конфигурацию имеет старшая модель BullSequana SH320. 
Источник изображений здесь и далее: Atos Все решения в серии SH поддерживают новые модели Xeon с числом ядер от 8 до 60 и частотами до 4,2 ГГц. Каждый модуль располагает двумя (1+1) блоками питания мощностью от 2200 до 3000 Вт, а также 12 вентиляторами с возможностью горячей замены. Для загрузки ОС в каждом модуле имеется 2 слота M.2, но опционально доступны дополнительные модули для установки NVMe-накопителей, а также корзины для GPU и PCIe-устройств с поддержкой горячей замены.  Компания также уделила внимание периферийным вычислениям: для этой сферы предназначены новые серверы BullSequana Edge EXR и EXD в корпусах 1U и 2U соответственно. Системы рассчитаны на использование процессоров Sapphire Rapids с числом ядер не более 24 и теплопакетом, не превышающим 185 Вт. Серверы могут функционировать при температурах от 0 до +45 °C в диапазоне влажности от 5% до 95%. Предусмотрена возможность крепления на стену. 
Модельный ряд BullSequana SH При этом предусмотрена возможность установки широкого ассортимента различных ускорителей — в спецификациях упоминаются NVIDIA T4, L40, H100, A2 и A16. Опционально в состав систем может входить поддержка беспроводных сетей LTE/5G, LoRA и Wi-Fi 6, поэтому серверы отлично подойдут и для развёртывания на периферии беспроводной инфраструктуры нового поколения. 
BullSequana Edge EXD (сверху) и EXR Модель EXR располагает 2 слотами M.2, но может комплектоваться дополнительной корзиной на 6 дисков SATA или 8 NVMe-накопителей, а EXD в некоторых конфигурациях может вмещать до 8 накопителей M.2 NVMe. Обе модели комплектуются двухпортовым 10GbE-контроллером (опционально 25GbE). Все новые системы Atos на базе новых процессоров Intel Xeon обеспечивают высокую степень безопасности благодаря поддержке Atos Root of Trust и Atos Chain-of-Trust.
14.09.2022 [22:28], Игорь Осколков
Arm анонсировала серверные ядра Neoverse V2 Demeter, именно они легли в основу процессоров NVIDIA GraceArm анонсировала новые ядра в серии Neoverse, принадлежащие к семейству Armv9 — Neoverse V2 с кодовым названием Demeter (Деметра). В семействе Neoverse V-ядра относятся к высокопроизводительным решениям, ориентированным на гиперскейлеров, облачных провайдеров и поставщиков HPC-решений. Одним из первых продуктов на базе новой платформы станет 72-ядерный серверный процессор NVIDIA Grace, выход которого запланирован на следующий год. 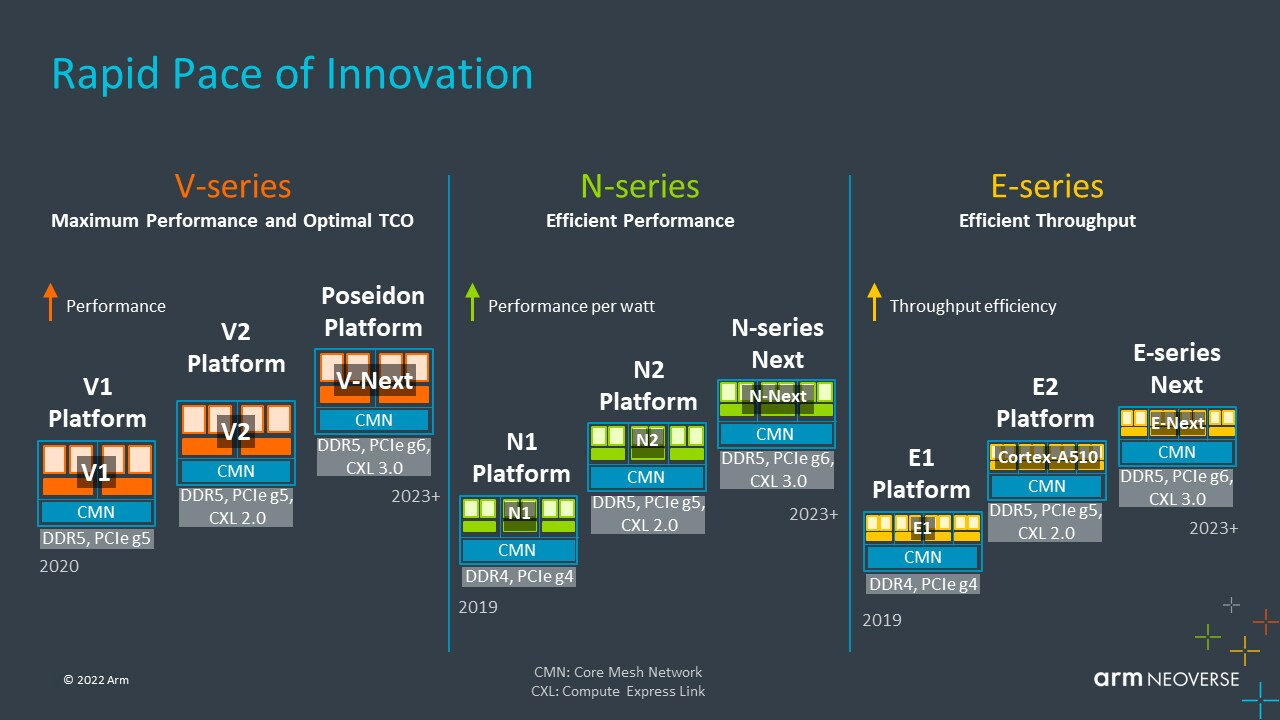
Источник: Arm Arm пока что не приводит точные характеристики V2-ядер, но говорит о возросшей производительности как целочисленных вычислений, так и вычислений с плавающей запятой. Для новинок заявлена поддержка SVE2-инструкций, наличие четырёх 128-бит векторных блоков, а также блоки для работы с матрицами и поддержка BF16/INT8. Кроме того, ядра получат увеличенный до 2 Мбайт L2-кеш, а также новые механизмы аппаратной защиты и, по-видимому, улучшенные криптографические движки. 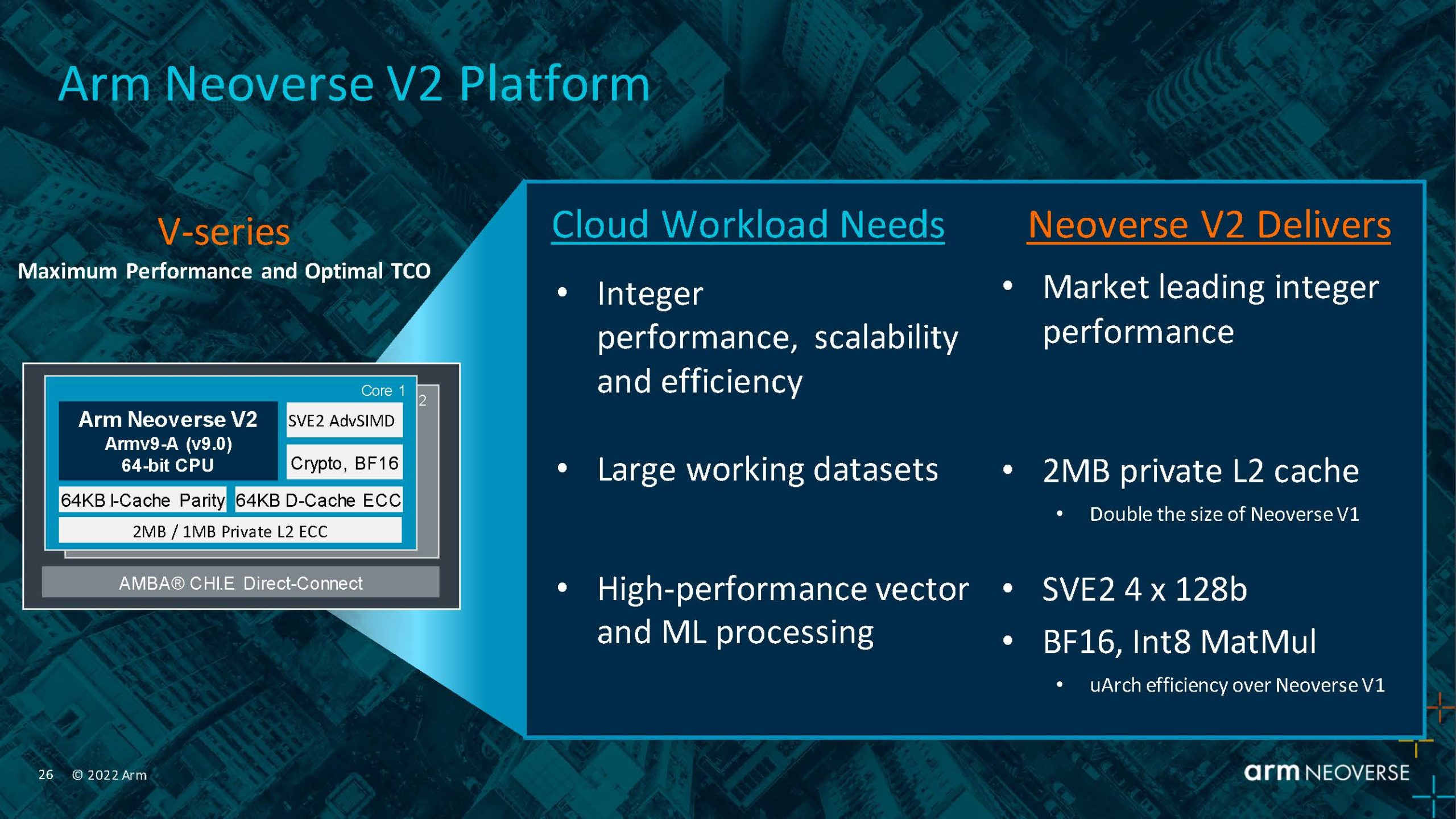
Источник: ServeTheHome  Объединять ядра и кеши будет когерентная mesh-шина CMN-700 с суммарной пропускной способностью до 4 Тбайт/с, которая может обслуживать до 512 Мбайт кеш-памяти. А за обслуживание связей с другими кристаллами всё так же будет отвечать шина AMBA CHI. Будет предложена поддержка (LP)DDR5(X), CXL 2.0, PCIe 5.0 и UCIe. Также Arm пообещала и далее вкладываться в развитие инициативы SystemReady и совместную с партнёрами оптимизацию системного и прикладного ПО — всё ради упрощения перехода конечных пользователей с x86 на Arm. 
Источник: ServeTheHome  Впрочем, как отмечает ServeTheHome, в ходе презентации Arm напирала скорее на прирост эффективности с точки зрения именно целочисленных вычислений, что актуально для облаков. x86-лагерь сдавать позиции в этой области не хочет — конкуренцию Arm составят AMD EPYC Bergamo и Intel Xeon Sierra Forest. Но в 2023 году Arm представит следующее поколение высокопроизводительных ядер Neoverse V3 (Poseidon) c PCIe 6.0 и CXL 3.0, а также «сбалансированную» платформу Neoverse N3 и энергоэффективные ядра Neoverse E следующего поколения. |
|


