Материалы по тегу: ibm
|
24.08.2019 [06:14], Андрей Галадей
IBM передала наработки по архитектуре Power сообществуКорпорация IBM сообщила, что переводит архитектуру набора команд (ISA) Power в разряд открытых решений. То есть, за неё не нужно будет платить, как это было в последние 6 лет. Отмечается, что с 2013 года действовал консорциум OpenPOWER, который лицензировал связанную с Power интеллектуальную собственность. Но теперь все наработки и патенты будут переданы сообществу безвозмездно. Сама же организация OpenPOWER Foundation будет переподчинена Linux Foundation, что позволит создать площадку для развития архитектуры без привязки к чипмейкеру или иной компании. Как отмечается, OpenPOWER Foundation включает в себя более 350 компаний, а сообществу передали свыше 3 млн строк кода системных прошивок, спецификаций и схем. Всё это позволит создавать Power-совместимые чипы всем желающим. 
pixabay.com Помимо собственно процессоров, компания передала сообществу и смежные технологии для разработки расширений на основе интерфейсов OpenCAPI (Open Coherent Accelerator Processor Interface) и OMI (Open Memory Interface). Первая технология должна устранить «узкие места» во взаимодействии CPU, GPU, ASIC, а также других чипов и контроллеров. Вторая же должна ускорить оперативную память. Это позволит создавать на базе архитектуры Power специализированные чипы для искусственного интеллекта. Важно отметить, что процессоры Power позволяют создавать современные серверы и суперкомпьютеры. К примеру, суперкомпьютеры Summit и Sierra работают как раз на таких чипах. А это, на минуточку, первый и второй номера в мировом рейтинге таких систем. Напомним, на процессорах с архитектурой Power (хотя и специализированных) работали в том числе и консоли Sony PlayStation 3, Xbox 360, а также старые ПК и ноутбуки Apple.
09.07.2019 [16:55], Сергей Юртайкин
IBM официально стала владельцем Red HatВо вторник, 9 июля, IBM сообщила о закрытии сделки по приобретению Red Hat за $34 млрд. За счёт крупнейшей покупки в своей истории IBM сможет усилить облачный бизнес за счёт акцента на гибридные решения. О слиянии IBM и Red Hat было объявлено в конце октября 2018 года. Компании заключили соглашение, по условиям которого IBM заплатила из собственных средств по $190 за каждую акцию Red Hat, что на 60 % больше курса котировок за день до исторического анонса.  Генеральный директор Red Hat Джим Уайтхерст (Jim Whitehurst) будет и дальше руководить компанией вместе со своей командой. При этом Уайтхерст будет подчиняться главе IBM Джинн Рометти (Ginni Rometty). Штаб-квартира Red Hat останется в городе Роли (Северная Каролина, США). Компания, которая стала самостоятельным подразделением IBM, сохранит свои предприятия, бренды и практики. В пресс-релизе, посвящённом закрытию сделки, говорится, что IBM и Red Hat после объединения будут предлагать «гибридную многооблачную платформу следующего поколения», которая «основана на технологиях с открытым исходным кодом, таких как Linux и Kubernetes». По прогнозам Red Hat, операционная система Red Hat Enterprise Linux будет способствовать получению различными компаниями по всему миру более $10 трлн совокупной выручки в 2019 году. Ожидается, что к 2023 году в мире появятся 640 тыс. новых рабочих мест, связанных с технологиями Red Hat. В IBM отметили, что Red Hat продолжит «выстраивать и расширять свои партнёрские отношения, в том числе с такими крупными поставщиками облачных сервисов, как Amazon Web Services, Microsoft Azure, Google Cloud и Alibaba». В последнем квартале перед закрытием сделки с IBM продажи Red Hat составили $934 млн, что на 15 % больше, чем годом ранее.
29.07.2018 [13:00], Геннадий Детинич
Американские ВВС получили самый большой в мире нейроморфный суперкомпьютерЗвучит громко, но это именно так. Лаборатория Air Force Research Laboratory (AFRL) в городе Ром, штат Нью-Йорк, получила в своё распоряжение самый большой в мире компьютер по числу задействованных в системе нейроморфных процессоров IBM TrueNorth. Система представлена полочными компьютерами высотой 4U (7 дюймов) для стандартной серверной стойки. Каждый компьютер располагает 64 процессорами IBM TrueNorth. В пересчёте на человеческие в буквальном смысле единицы измерения мозга — это 64 млн нейронов и 16 млрд синапсов. Всего в стойке может разместиться 512 млн цифровых нейронов. Примерно столько нейронов в коре головного мозга собаки. 
AFRL Система под именем «Blue Raven» на базе IBM TrueNorth для Лаборатории ВВС США представлена пока 64-процессорным решением с общим потреблением 40 Вт. Это, кстати, в 4 раза больше ожидаемого. Аналогичный 16-процессорный компьютер, переданный в 2016 году Ливерморской национальной лаборатории им. Лоуренса, потреблял всего 2,5 Вт или 156 мВт на один процессор. Возможно таким образом была повышена производительность системы, которая при потреблении 70 мВт способна работать с производительностью 46 млрд синаптических операций в секунду. 
IBM По оценкам IBM, работа процессоров TrueNorth с необозначенным датасетом на CIFAR-100 по распознаванию наборов изображений характеризуется производительностью свыше 1500 кадров в секунду с потреблением 200 мВт или свыше 7000 кадров в секунду на ватт. Ускоритель NVIDIA Tesla P4 (Pascal GP104), например, обрабатывает датасет Resnet-50 с производительностью 27 кадров в секунду на ватт. 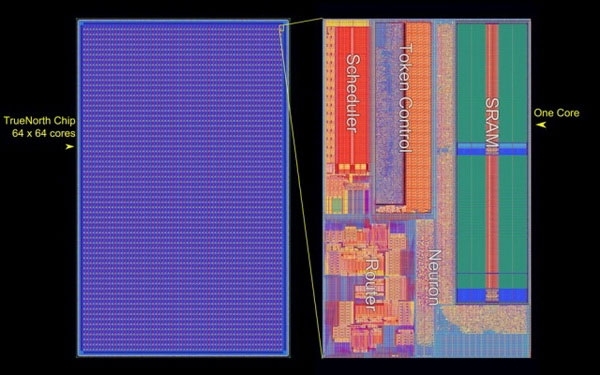
Структура процессора IBM TrueNorth Вообще, в Лаборатории AFRL, похоже, работают увлечённые люди. Новым проектом «Blue Raven» руководит тот же человек (Mark Barnell), который несколько лет назад отметился запуском суперкомпьютера Condor Cluster на базе сотен игровых консолей Sony PlayStation 3. Какими расчётами в AFRL будет заниматься суперкомпьютер с «мозгами» не уточняется. Пока учёные будут изучать круг задач, решаемый подобными системами. Ожидается, что принятая на «вооружение» научным отделом ВВС США вычислительная система обеспечит дальнейшее приоритетное развитие технологий в этой стране.
06.12.2017 [23:45], Сергей Юртайкин
IBM представила первый сервер на процессоре POWER9IBM представила свой первый собственный сервер на процессоре POWER9. Особенность решения под названием IBM Power Systems AC922 заключается в том, что новая аппаратная платформа разработана специально для работы с интенсивными вычислительными нагрузками технологий искусственного интеллекта (ИИ). 
CPU IBM POWER9 В IBM отмечают, что Power 9 позволяет ускорить тренировки фреймворков глубинного обучения обучения почти в четыре раза, благодаря чему клиенты смогут быстрее создавать более точные ИИ-приложения. Утверждается, что новый сервер разработан для получения значительных улучшений производительности всех популярных фреймворков ИИ, таких как Chainer, TensorFlow и Caffe, а также современных баз данных, использующих ускорители, например, Kinetica. 
Сервер IBM Power System AC922 Сервер IBM Power Systems AC922 использует шину PCI-Express 4.0 и технологии NVIDIA NVLink 2.0 и CAPI 2.0/OpenCAPI, способные ускорить пропускную способность в 9,5 раза по сравнению с системами x86 на базе PCI-E 3.0. Это, в частности, позволяет задействовать ускорителям (GPU или FPGA) системную ОЗУ без значительных, по сравнению с прошлыми решениями, потерь производительности, что важно для обработки больших массивов данных. Кроме того, новые поколения карт расширения и ускорителей уже поддерживают эту шину.  IBM Power Systems AC922 создан в нескольких конфигурациях, оснащаемых двумя процессорами POWER9. Стандартные версии включают CPU c 16 (2,6 ГГц, турбо 3,09 ГГц) и 20 (2,0/2,87 ГГц) ядрами (4 потока на ядро), а позже появятся версии с 18- и 22 -ядерными процессорами. Всего в сервере есть 16 слотов для модулей ECC DDR4-памяти, что на текущий момент позволяет оснастить его 1 Тбайт RAM. Для хранения данных предусмотрено два слота для 2,5" SSD/HDD (RAID-контроллера нет).  AC922 может иметь на борту от двух до четырёх ускорителей NVIDIA Tesla V100 форм-фактора SXM2 с памятью 16 Гбайт и шиной NVLink 2.0. В сумме они дают до 500 Тфлопс на расчётах половинной точности. Дополнительные ускорители можно подключить к слотам PCI-E 4.0.  Сервер рассчитан на установку четырёх дополнительных низкопрофильных карт расширения: два слота PCI-E 4.0 x16, один PCI-E 4.0 x8 и один PCI-E 4.0 x4. Все слоты, кроме последнего, также умеют работать с CAPI. Также есть два порта USB 3.0. Поддерживается ОС Red Hat Enterprise Linux 7.4 for Power LE.  Процессоры IBM Power 9, которые нашли применение в IBM Power Systems AC922, легли в основу суперкомпьютеров Summit и Sierra Министерства энергетики США, а также используются компанией Google. Чипы и использующие их системы стали частью совместной работы участников организации OpenPower Foundation, в которую входят IBM, Google, Mellanox, NVIDIA и др. 
Процессор IBM Power 9 «Мы создали уникальную в своём роде систему для работы с технологиями ИИ и когнитивными вычислениями, — говорит старший вице-президент подразделения IBM Cognitive Systems Боб Пиччиано (Bob Picciano). — Серверы на Power 9 являются не только основой самых высокопроизводительных компьютеров, они позволят заказчикам масштабировать невиданные ранее инсайты, что будет способствовать научным прорывам и революционным улучшениям бизнес-показателей».  Сервер имеет стандартное 2U-шасси и оснащается двумя (1+1) блоками питания мощностью 2,2 кВт каждый. Система охлаждения может быть гибридной. Начало продаж IBM Power Systems AC922 намечено на 22 декабря 2017 года. В 2018 году будут доступны конфигурации с шестью ускорителями Tesla и СЖО. 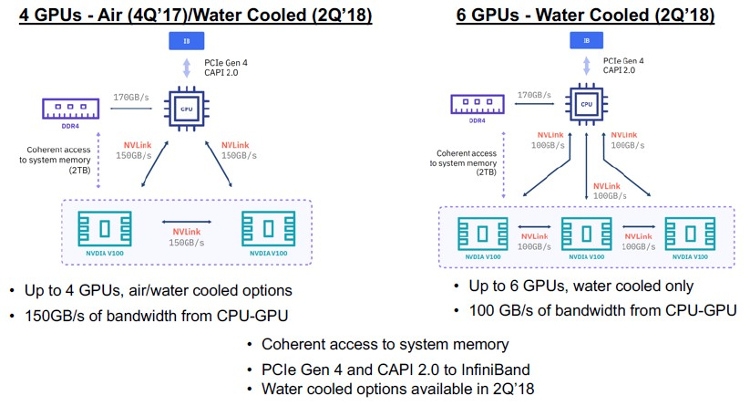
26.08.2016 [15:36], Сергей Карасёв
IBM рассказала о мощных процессорах Power9Корпорация IBM на конференции Hot Chips 28 в Купертино (Калифорния, США) раскрыла довольно подробную информацию о мощных процессорах Power9, которые выйдут на рынок в следующем году. Итак, сообщается, что чипы будут изготавливаться по 14-нанометровой технологии FinFET. Они получат 120 Мбайт кеша третьего уровня и смогут работать с буферизированными и не буферизированными модулями памяти DDR4. 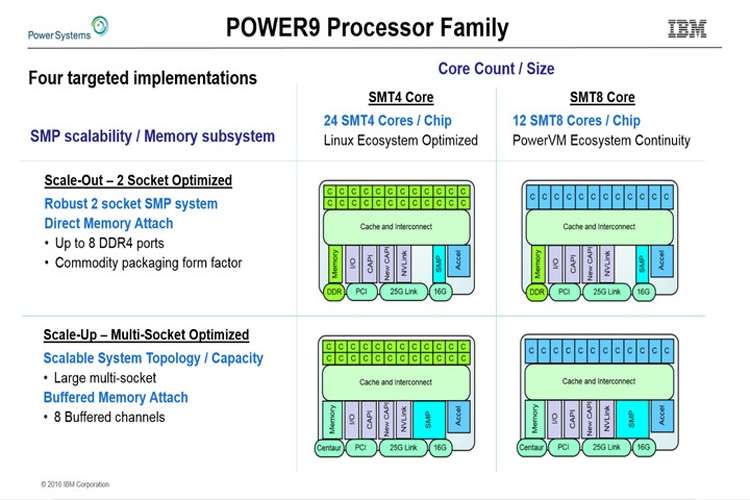 Корпорация IBM готовит несколько модификаций Power9. В частности, говорится об изделиях с 12 вычислительными ядрами, каждое из которых сможет одновременно обрабатывать восемь потоков инструкций. Такие процессоры будут ориентированы прежде всего на системы с виртуализацией. 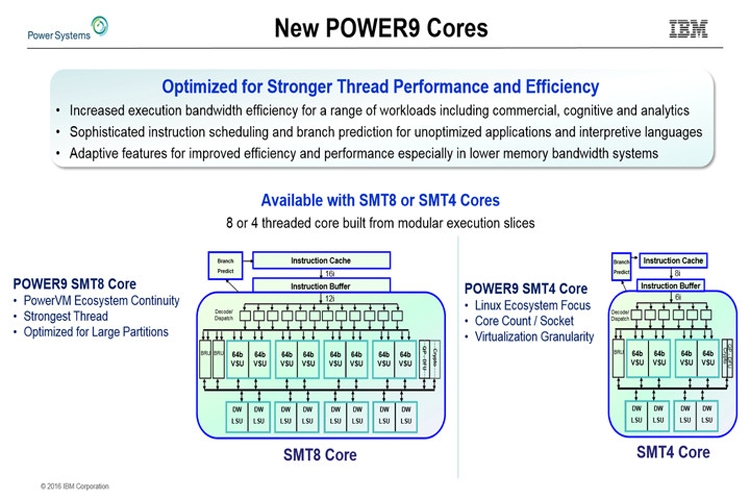 Кроме того, будут выпущены чипы с 24 вычислительными ядрами с поддержкой одновременной обработки четырёх потоков инструкций. Эти решения найдут применение в различных Linux-платформах. 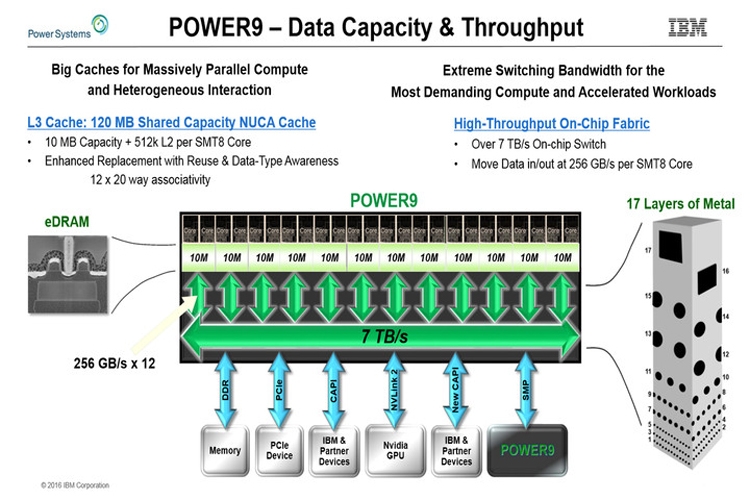 Отмечается, что в Power9 будут реализованы улучшенные средства предсказания ветвлений, что позволит поднять скорость вычислений. Кроме того, говорится о реализации новых инструкций для поддержки будущих перспективных технологий и о 48 линиях PCI Express 4.0. 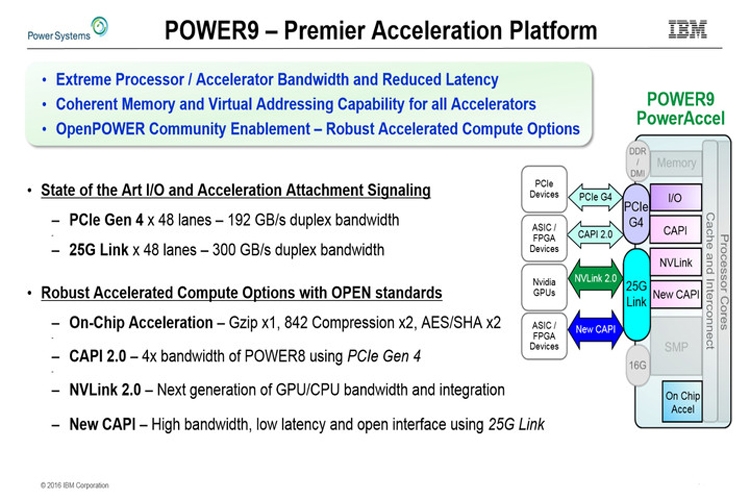 В общей сложности процессоры получат до 8 млрд транзисторов. Они обеспечат существенный прирост производительности по сравнению с изделиями предыдущего поколения. |
|

