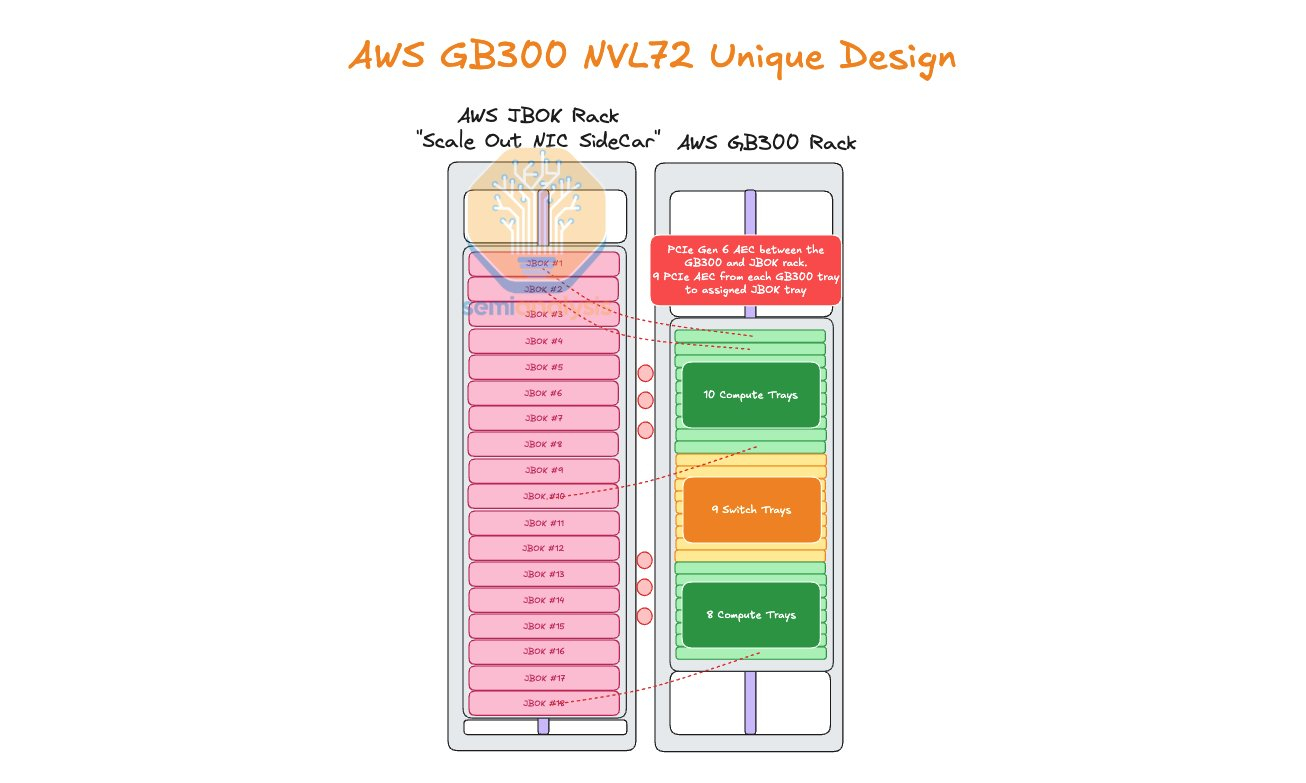
Amazon Web Services (AWS) нашла выход, как использовать собственные Nitro DPU K2v5/6 (EFA) в новейших стоечных системах NVIDIA GB300 NVL72, которые, как считает гиперскейлер, превосходит адаптеры NVIDIA ConnectX-7/8 по производительности. В связи с тем, что в стойках NVIDIA Oberon используются укороченные лотки высотой 1U, AWS размещает NIC в отдельной стойке JBOK, предназначенной только для сетевых карт, пишет SemiAnalysis.
Причина кроется в невозможности установить в 1U сразу девять фирменных адаптеров (8 × EFA + 1 × ENA/EBS). Для серверных систем GB200 NVL предыдущего поколения AWS выбрала вариант NVL36×2, поскольку только в этом случае использовались 2U-узлы, где достаточно места для всех NIC. Однако сдвоенная конфигурация менее эффективна, чем нативная конструкция NVL72. NVIDIA сама была не очень довольна вариантами NVL36. Meta✴, например, и вовсе «растянула» NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждением.
Источник изображения: SemiAnalysis
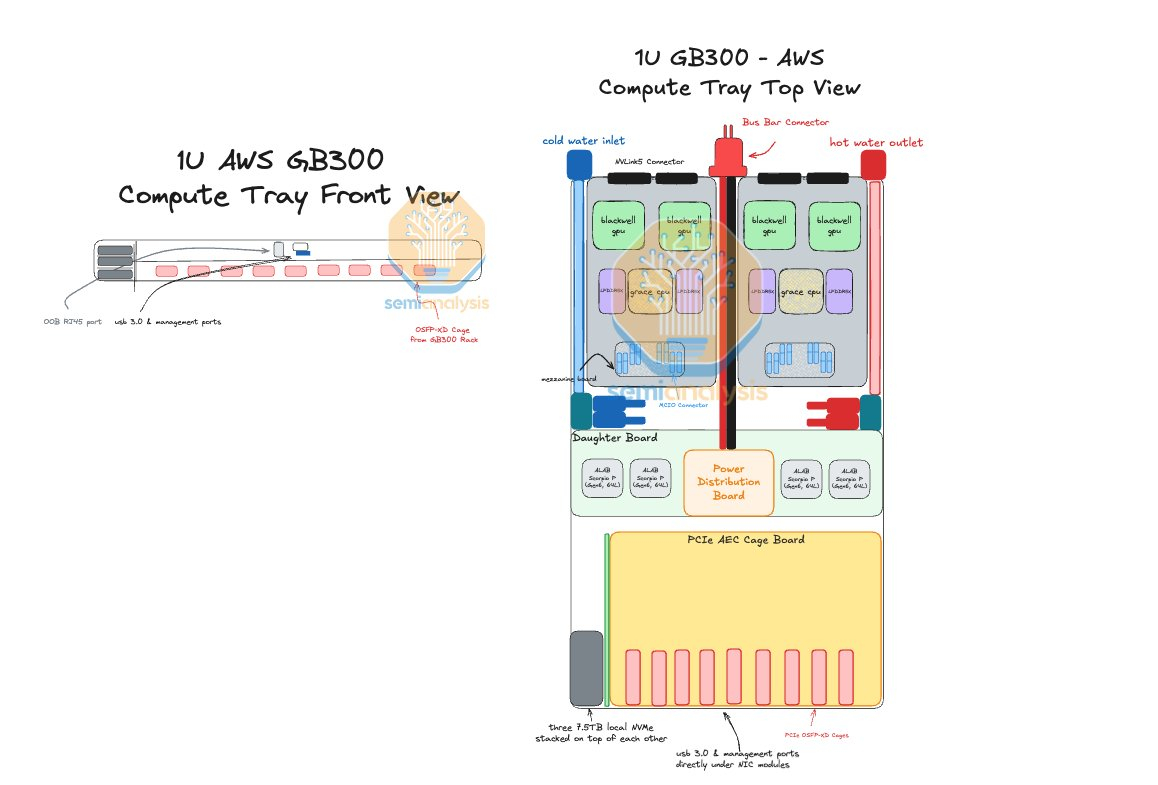
AWS в случае Blackwell Ultra предпочла остановиться на NVL72-варианте, а DPU вынести в отдельную стойку — всего 18 узлов высотой 2U, по 9 NIC в каждом. С узлами NVIDIA они соединены активными электрическими кабелями (AEC) и портами OSFP-XD для передачи сигналов PCIe 6.0. По словам AWS, её адаптеры лучше справляются с нагрузками, чем ConnectX-8 (RoCEv2), что отчасти спорно. В любом случае таким образом компания снижается зависимость от NVIDIA.
Источник изображения: SemiAnalysis
С точки зрения SemiAnalysis, доработка GB300 в AWS помогает устранить единую точку отказа в референсной архитектуре NVIDIA, где каждый ускоритель взаимодействует только с одним сетевым адаптером ConnectX-8, тогда как в конфигурации AWS каждый ускоритель общается с двумя NIC.
У AWS накоплен богатый опыт разработки собственного оборудования для ЦОД. Ранее компания в партнёрстве с Broadcom разрабатывала специализированные сетевые коммутаторы. Также недавно представленные ею EC2-инстансы P6-B200 и P6e-GB200 оснащены собственным сетевым стеком Elastic Fabric Adapter (EFAv4) на базе собственных контроллеров Nitro, который оптимизирует обработку сетевых пакетов и снижает задержки для высокопроизводительных приложений.
Источник:

